Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO:
![]() Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
Azure Cosmos DB for PostgreSQL (využívající rozšíření databáze Citus do PostgreSQL)
V tomto kurzu se pomocí služby Azure Cosmos DB for PostgreSQL naučíte:
- Vytváření horizontálních oddílů distribuovaných pomocí hodnot hash
- Zobrazení umístění horizontálních oddílů tabulky
- Identifikace nerovnoměrné distribuce
- Vytváření omezení distribuovaných tabulek
- Spouštění dotazů na distribuovaná data
Požadavky
Tento kurz vyžaduje spuštěný cluster se dvěma pracovními uzly. Pokud nemáte spuštěný cluster, postupujte podle kurzu vytvoření clusteru a vraťte se k tomuto clusteru .
Data distribuovaná pomocí hodnoty hash
Distribuce řádků tabulky mezi více serverů PostgreSQL je klíčovou technikou škálovatelných dotazů ve službě Azure Cosmos DB for PostgreSQL. Více uzlů může obsahovat více dat než tradiční databáze a v mnoha případech může paralelně používat pracovní procesory ke spouštění dotazů. Koncept tabulek distribuovaných pomocí hash se označuje také jako horizontální dělení na základě řádků.
V části Požadavky jsme vytvořili cluster se dvěma pracovními uzly.
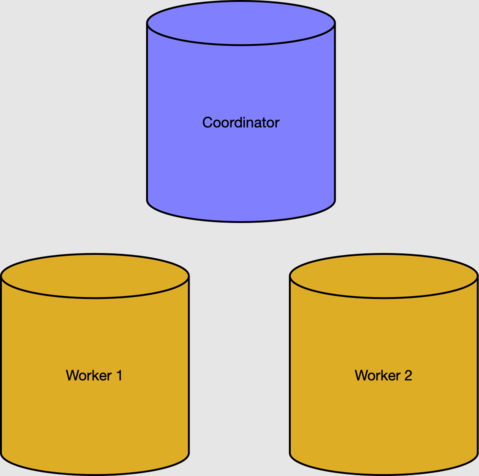
Tabulky metadat koordinačního uzlu sledují pracovní procesy a distribuovaná data. Aktivní pracovníky můžeme zkontrolovat v tabulce pg_dist_node.
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
Poznámka:
Názvy uzlů ve službě Azure Cosmos DB for PostgreSQL jsou interní IP adresy ve virtuální síti a skutečné adresy, které vidíte, se mohou lišit.
Řádky, segmenty a umístění
Abychom mohli používat prostředky procesoru a úložiště pracovních uzlů, musíme distribuovat data tabulek v celém clusteru. Distribuce tabulky přiřadí každý řádek logické skupině označované jako shard. Vytvořte tabulku a která bude distribuována:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB for PostgreSQL přiřadí každý řádek horizontálnímu oddílu na základě hodnoty distribučního sloupce, který jsme v našem případě určili, že má být email. Každý řádek bude v přesně jednom horizontálním oddílu a každý horizontální oddíl může obsahovat více řádků.
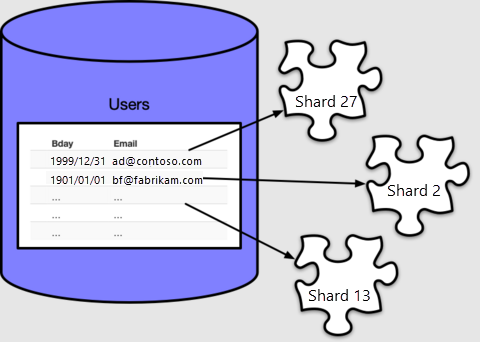
Ve výchozím nastavení create_distributed_table() činí 32 horizontálních oddílů, jak vidíme počítáním v tabulce metadat pg_dist_shard:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB for PostgreSQL používá pg_dist_shard tabulku k přiřazení řádků k shardům na základě hashe hodnoty v distribučním sloupci. Podrobnosti o hashování nejsou pro tento kurz důležité. Důležité je, abychom viděli, které hodnoty se mapují na ID fragmentů.
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
Mapování řádků na shardy je čistě logické. Fragmenty musí být přiřazeny konkrétním pracovním uzlům pro úložiště v tom, co Azure Cosmos DB pro PostgreSQL nazývá umístění fragmentů.
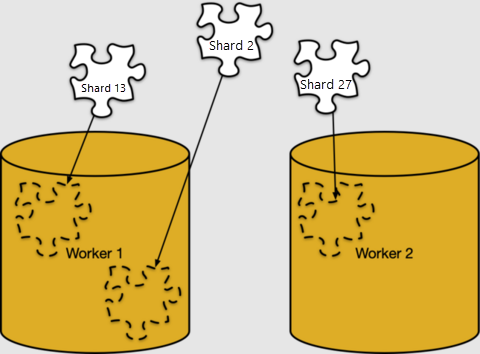
Můžeme se podívat na umístění fragmentů v pg_dist_placement. Spojení s ostatními tabulkami metadat, které jsme viděli, ukazuje, kde se nachází každý fragment.
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
Nerovnoměrná distribuce dat
Cluster funguje nejefektivněji, když data umístíte rovnoměrně na uzly pracovníků a když související data umístíte na stejné pracovníky. V této části se zaměříme na první část, jednotnost umístění.
Abychom si to ukázali, pojďme pro naši users tabulku vytvořit ukázková data:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
Abychom viděli velikosti shardů, můžeme spouštět funkce velikosti tabulky na shardech.
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
Vidíme, že horizontální oddíly mají stejnou velikost. Už jsme viděli, že umístění jsou rovnoměrně rozdělená mezi pracovníky, takže můžeme odvodit, že pracovní uzly mají zhruba stejný počet řádků.
Řádky v našem users příkladu se rovnoměrně distribuují, protože vlastnosti distribučního sloupce, email.
- Počet e-mailových adres byl větší nebo roven počtu shardů.
- Počet řádků na e-mailovou adresu byl podobný (v našem případě přesně jeden řádek na adresu, protože jsme deklarovali klíč e-mailu).
Jakákoli volba tabulky a distribučního sloupce, ve kterém selže některá vlastnost, skončí nerovnoměrnou velikostí dat u pracovních procesů, tj. nerovnoměrné distribuce dat.
Přidání omezení do distribuovaných dat
Použití služby Azure Cosmos DB for PostgreSQL umožňuje i nadále využívat bezpečnost relační databáze, včetně omezení databáze. Existuje však omezení. Vzhledem k povaze distribuovaných systémů nebude Azure Cosmos DB for PostgreSQL kontrolovat jedinečná omezení nebo referenční integritu mezi pracovními uzly.
Podívejme se na příklad tabulky users se související tabulkou.
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
Kvůli efektivitě distribuujeme books stejným způsobem jako users: e-mailovou adresou vlastníka. Distribuce podle podobných hodnot sloupců se nazývá kolokace.
Neměli jsme problém s distribucí knih s cizím klíčem pro uživatele, protože klíč byl v distribučním sloupci. Měli bychom ale potíže s vytvářením isbn klíče:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
V distribuované tabulce je nejlepší, aby sloupce byly jedinečné modulo distribučního sloupce:
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
Výše uvedené omezení pouze zajišťuje, že isbn je jedinečné pro každého uživatele. Další možností je vytvořit knihy jako referenční tabulku místo distribuované tabulky a vytvořit samostatnou distribuovanou tabulku asociující knihy s uživateli.
Dotazování distribuovaných tabulek
V předchozích částech jsme viděli, jak jsou řádky distribuované tabulky umístěny v shardách na pracovních uzlech. Většinou nepotřebujete vědět, jak nebo kde jsou data uložená v clusteru. Azure Cosmos DB for PostgreSQL má distribuovaný exekutor dotazů, který automaticky rozděluje běžné dotazy SQL. Spouští je paralelně na pracovních uzlech v blízkosti dat.
Můžeme například spustit dotaz, abychom našli průměrný věk uživatelů a zacházeli s distribuovanou users tabulkou jako s normální tabulkou v koordinátoru.
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
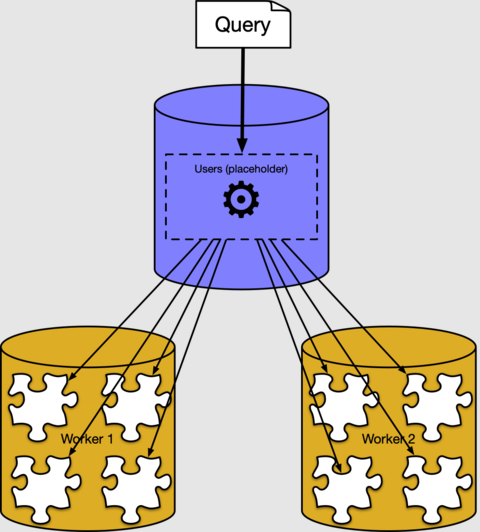
Na pozadí vytvoří exekutor Azure Cosmos DB for PostgreSQL samostatný dotaz pro každý fragment, spustí je na pracovních uzlech a zkombinuje výsledek. Pokud použijete příkaz PostgreSQL EXPLAIN, uvidíte ho:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
Výstup ukazuje příklad plánu provedení fragmentu dotazu běžícího na shardu 102040 (tabulka users_102040 na workeru 10.0.0.21). Ostatní fragmenty se nezobrazují, protože jsou podobné. Vidíme, že pracovní uzel prochází dílčí tabulky a použije agregaci. Koordinační uzel kombinuje agregace pro konečný výsledek.
Další kroky
V tomto kurzu jsme vytvořili distribuovanou tabulku a dozvěděli jsme se o jejích shardech a umístěních. Viděli jsme výzvu k používání omezení jedinečnosti a cizího klíče a nakonec jsme viděli, jak distribuované dotazy fungují na vysoké úrovni.
- Přečtěte si více o typech tabulek v Azure Cosmos DB for PostgreSQL
- Získejte další tipy pro výběr distribučního sloupce.
- Informace o výhodách kolokace tabulek