aktivita Copy funkce optimalizace výkonu
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje funkce optimalizace výkonu aktivity kopírování, které můžete využít v kanálech Azure Data Factory a Synapse.
Konfigurace funkcí výkonu pomocí uživatelského rozhraní
Když vyberete aktivita Copy na plátně editoru kanálů a zvolíte kartu Nastavení v oblasti konfigurace aktivity pod plátnem, zobrazí se možnosti konfigurace všech funkcí výkonu podrobně popsaných níže.
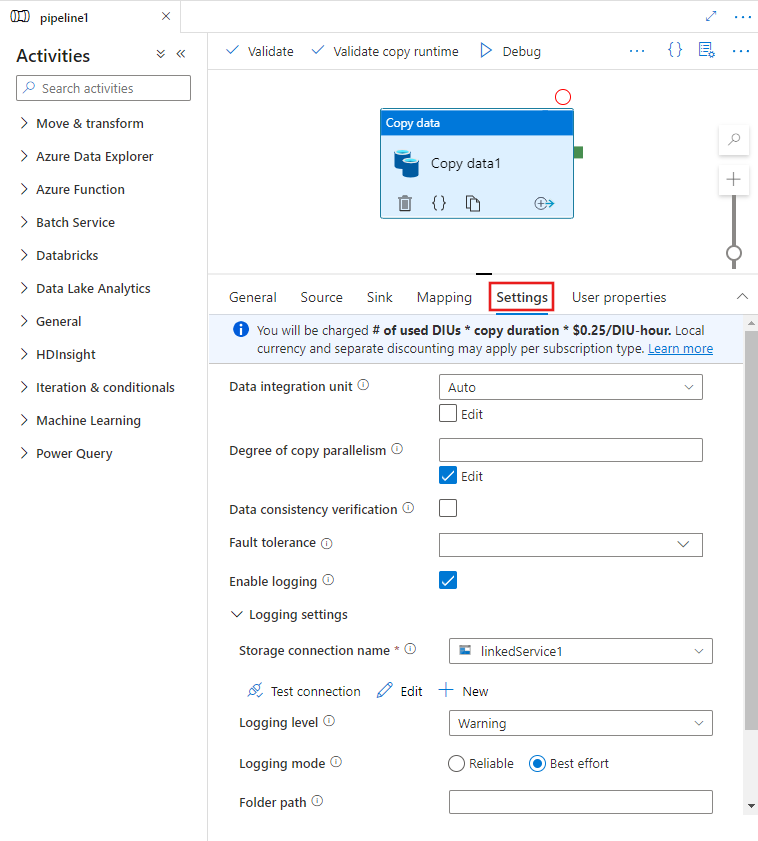
Jednotky integrace dat
Jednotka Integrace Dat je míra, která představuje výkon (kombinaci procesoru, paměti a přidělení síťových prostředků) jedné jednotky v rámci služby. Integrace Dat Jednotka se vztahuje pouze na Prostředí Azure Integration Runtime, ale ne místní prostředí Integration Runtime.
Povolené jednotky DIU umožňují spuštění aktivity kopírování mezi 2 a 256. Pokud není zadáno nebo zvolíte v uživatelském rozhraní možnost Automaticky, služba dynamicky použije optimální nastavení DIU na základě spárování zdroje a datového vzoru jímky. Následující tabulka uvádí podporované rozsahy JEDNOTEK a výchozí chování v různých scénářích kopírování:
| Scénář kopírování | Podporovaný rozsah JEDNOTEK | Výchozí jednotky DIU určené službou |
|---|---|---|
| Mezi úložišti souborů | - Kopírovat z nebo do jednoho souboru: 2-4 - Kopírovat z a do více souborů: 2–256 v závislosti na počtu a velikosti souborů Pokud například kopírujete data ze složky se 4 velkými soubory a rozhodnete se zachovat hierarchii, maximální efektivní DIU je 16; pokud se rozhodnete sloučit soubor, maximální efektivní DIU je 4. |
Mezi 4 a 32 v závislosti na počtu a velikosti souborů |
| Z úložiště souborů do jiného než souborového úložiště | - Kopírování z jednoho souboru: 2-4 - Kopírování z více souborů: 2–256 v závislosti na počtu a velikosti souborů Pokud například kopírujete data ze složky se 4 velkými soubory, maximální efektivní DIU je 16. |
- Kopírování do Azure SQL Database nebo Azure Cosmos DB: mezi 4 a 16 v závislosti na úrovni jímky (DTU/RU) a vzoru zdrojového souboru - Kopírování do Azure Synapse Analytics pomocí příkazu PolyBase nebo COPY: 2 - Jiný scénář: 4 |
| Z jiného úložiště souborů do úložiště souborů | - Kopírování z úložišť dat s podporou možností oddílů (včetně úložišť dat Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server a Teradata): 2–256 při zápisu do složky a 2–4 při zápisu do jednoho souboru. Všimněte si, že každý zdrojový datový oddíl může používat až 4 jednotky DIU. - Další scénáře: 2–4 |
- Kopírování z REST nebo HTTP: 1 - Kopírovat z Amazon Redshift pomocí UNLOAD: 2 - Jiný scénář: 4 |
| Mezi nesouborovými úložišti | - Kopírování z úložišť dat s podporou možností oddílů (včetně úložišť dat Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server a Teradata): 2–256 při zápisu do složky a 2–4 při zápisu do jednoho souboru. Všimněte si, že každý zdrojový datový oddíl může používat až 4 jednotky DIU. - Další scénáře: 2–4 |
- Kopírování z REST nebo HTTP: 1 - Jiný scénář: 4 |
Jednotky DIU používané pro každé spuštění kopírování můžete zobrazit v zobrazení monitorování aktivit kopírování nebo výstupu aktivity. Další informace najdete v tématu aktivita Copy monitorování. Chcete-li toto výchozí nastavení přepsat, zadejte hodnotu vlastnosti dataIntegrationUnits následujícím způsobem. Skutečný počet jednotek DIU, které operace kopírování používá za běhu, je roven nebo menší než nakonfigurovaná hodnota v závislosti na vašem vzoru dat.
Naúčtujete vám počet použitých jednotek DIU * doba trvání kopírování * jednotková cena za jednotku/hodina DIU. Podívejte se na aktuální ceny zde. Místní měna a samostatné slevy se můžou uplatnit na typ předplatného.
Příklad:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Škálovatelnost místního prostředí Integration Runtime
Pokud chcete dosáhnout vyšší propustnosti, můžete vertikálně navýšit kapacitu nebo vertikálně navýšit kapacitu místního prostředí IR:
- Pokud procesor a dostupná paměť na uzlu místního prostředí IR nejsou plně využité, ale provádění souběžných úloh dosahuje limitu, měli byste vertikálně navýšit kapacitu zvýšením počtu souběžných úloh, které se můžou spouštět na uzlu. Pokyny najdete tady .
- Pokud je na druhé straně procesor vysoké na uzlu místního prostředí IR nebo je dostupná paměť nízká, můžete přidat nový uzel, který pomáhá škálovat zatížení napříč několika uzly. Pokyny najdete tady .
Všimněte si, že v následujících scénářích může provádění aktivity s jednou kopií využívat několik uzlů místního prostředí IR:
- Zkopírujte data z úložišť založených na souborech v závislosti na počtu a velikosti souborů.
- Kopírování dat z úložiště dat s podporou možností oddílů (včetně Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Serveru a Teradata) v závislosti na počtu datových oddílů.
Paralelní kopírování
Paralelní kopírování (parallelCopies vlastnost v definici JSON aktivita Copy nebo Degree of parallelism nastavení na kartě Nastavení vlastností aktivita Copy v uživatelském rozhraní) u aktivity kopírování můžete nastavit paralelismus, který má aktivita kopírování použít. Tuto vlastnost si můžete představit jako maximální počet vláken v aktivitě kopírování, která se čtou ze zdroje nebo zapisují do úložišť dat jímky paralelně.
Paralelní kopie je orthogonální pro Integrace Dat jednotky nebo uzly ir v místním prostředí. Počítá se ve všech uzlech DIU nebo v místním prostředí IR.
Pro každé spuštění aktivity kopírování služba ve výchozím nastavení dynamicky použije optimální nastavení paralelního kopírování na základě páru zdrojové jímky a datového vzoru.
Tip
Výchozí chování paralelní kopie obvykle poskytuje nejlepší propustnost, která je automaticky určená službou na základě páru zdrojových jímek, datového vzoru a počtu jednotek DIU nebo počtu procesorů/paměti/uzlů místního prostředí IR. Informace o řešení potíží s výkonem aktivity kopírování při ladění paralelního kopírování
Následující tabulka uvádí chování paralelního kopírování:
| Scénář kopírování | Chování paralelního kopírování |
|---|---|
| Mezi úložišti souborů | parallelCopies určuje paralelismus na úrovni souboru. Blok dat v rámci každého souboru se provádí automaticky a transparentně. Je navržená tak, aby používala nejvhodnější velikost bloku dat pro daný typ úložiště dat k paralelnímu načtení dat. Skutečný počet paralelních kopií, které aktivita kopírování používá za běhu, není větší než počet souborů, které máte. Pokud je chování kopírování mergeFile do jímky souborů, aktivita kopírování nemůže využít paralelismus na úrovni souboru. |
| Z úložiště souborů do jiného než souborového úložiště | – Při kopírování dat do Azure SQL Database nebo Azure Cosmos DB závisí výchozí paralelní kopírování také na úrovni jímky (počet DTU/RU). – Při kopírování dat do tabulky Azure je výchozí paralelní kopírování 4. |
| Z jiného úložiště souborů do úložiště souborů | – Při kopírování dat z úložiště dat s podporou možností oddílů (včetně Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS pro SQL Server a Teradata), výchozí paralelní kopírování je 4. Skutečný počet paralelních kopií, které aktivita kopírování používá za běhu, není větší než počet oddílů dat, které máte. Při použití místního prostředí Integration Runtime a kopírování do Azure Blob/ADLS Gen2 si všimněte, že maximální efektivní paralelní kopírování je 4 nebo 5 na uzel IR. – V jiných scénářích se paralelní kopírování neprojeví. I když je zadaný paralelismus, nepoužije se. |
| Mezi nesouborovými úložišti | – Při kopírování dat do Azure SQL Database nebo Azure Cosmos DB závisí výchozí paralelní kopírování také na úrovni jímky (počet DTU/RU). – Při kopírování dat z úložiště dat s podporou možností oddílů (včetně Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS pro SQL Server a Teradata), výchozí paralelní kopírování je 4. – Při kopírování dat do tabulky Azure je výchozí paralelní kopírování 4. |
Pokud chcete řídit zatížení počítačů, které hostují vaše úložiště dat, nebo ladit výkon kopírování, můžete přepsat výchozí hodnotu a zadat hodnotu vlastnosti parallelCopies . Hodnota musí být celé číslo větší nebo rovno 1. V době běhu používá aktivita kopírování hodnotu, která je menší nebo rovna hodnotě, kterou jste nastavili.
Když zadáte hodnotu vlastnosti parallelCopies , vezměte v úvahu zvýšení zatížení úložiště dat zdroje a jímky. Pokud je aktivita kopírování oprávněná, zvažte také zvýšení zatížení místního prostředí Integration Runtime. K tomuto zvýšení zatížení dochází zejména v případě, že máte více aktivit nebo souběžných spuštění stejných aktivit, které běží ve stejném úložišti dat. Pokud si všimnete, že úložiště dat nebo místní prostředí Integration Runtime je zahlcené zatížením, snižte parallelCopies hodnotu, aby se zatížení uvolnilo.
Příklad:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Fázovaná kopie
Při kopírování dat ze zdrojového úložiště dat do úložiště dat jímky se můžete rozhodnout použít úložiště objektů blob Azure nebo Azure Data Lake Storage Gen2 jako dočasné pracovní úložiště. Příprava je užitečná zejména v následujících případech:
- Chcete ingestovat data z různých úložišť dat do Azure Synapse Analytics prostřednictvím PolyBase, kopírovat data z/do Snowflake nebo ingestovat data z Amazon Redshift/HDFS výkonně. Další podrobnosti najdete tady:
- Nechcete otevírat jiné porty než port 80 a port 443 v bráně firewall kvůli firemním zásadám IT. Když například kopírujete data z místního úložiště dat do služby Azure SQL Database nebo Azure Synapse Analytics, musíte pro bránu Windows Firewall i podnikovou bránu firewall aktivovat odchozí komunikaci TCP na portu 1433. V tomto scénáři může fázovaná kopie využít výhod místního prostředí Integration Runtime k první zkopírování dat do přípravného úložiště přes PROTOKOL HTTP nebo HTTPS na portu 443 a pak načíst data z přípravného prostředí do služby SQL Database nebo Azure Synapse Analytics. V tomto toku nemusíte povolovat port 1433.
- Někdy trvá nějakou dobu, než se provede hybridní přesun dat (to znamená kopírování z místního úložiště dat do cloudového úložiště dat) přes pomalé síťové připojení. Pokud chcete zvýšit výkon, můžete pomocí fázované kopie komprimovat data místně, aby přesun dat do přípravného úložiště dat v cloudu trvalo méně času. Potom můžete před načtením do cílového úložiště dat dekomprimovat data v přípravném úložišti.
Jak fázovaná kopie funguje
Při aktivaci pracovní funkce se nejprve zkopírují data ze zdrojového úložiště dat do přípravného úložiště (přineste si vlastní objekt blob Azure nebo Azure Data Lake Storage Gen2). V dalším kroku se data zkopírují z přípravného úložiště dat do úložiště dat jímky. Aktivita kopírování automaticky spravuje dvoufázový tok a po dokončení přesunu dat také vyčistí dočasná data z přípravného úložiště.

Potřebujete udělit oprávnění k odstranění vaší služby Azure Data Factory v přípravném úložišti, aby se dočasná data po spuštění aktivity kopírování mohly vyčistit.
Při aktivaci přesunu dat pomocí přípravného úložiště můžete určit, jestli chcete, aby se data před přesunutím ze zdrojového úložiště dat do přípravného úložiště zkomprimovala a před přesunem dat z dočasného nebo přípravného úložiště dat do úložiště dat jímky dekomprimovala.
V současné době nemůžete kopírovat data mezi dvěma úložišti dat připojenými prostřednictvím různých místního prostředí, a to ani bez fázované kopie. Pro takový scénář můžete nakonfigurovat dvě explicitně zřetězený aktivity kopírování, které se mají kopírovat ze zdroje do přípravného prostředí, a pak z přípravného do jímky.
Konfigurace
Nakonfigurujte nastavení enableStaging v aktivitě kopírování a určete, jestli se mají data před načtením do cílového úložiště dat fázovat v úložišti. Když nastavíte funkci enableStaging na TRUE, zadejte další vlastnosti uvedené v následující tabulce.
| Vlastnost | Popis | Default value | Požaduje se |
|---|---|---|---|
| enableStaging | Určete, jestli chcete kopírovat data prostřednictvím dočasného přípravného úložiště. | False | No |
| linkedServiceName | Zadejte název propojené služby Azure Blob Storage nebo Azure Data Lake Storage Gen2 , která odkazuje na instanci služby Storage, kterou používáte jako dočasné přípravné úložiště. | – | Ano, pokud je možnost enableStaging nastavená na hodnotu TRUE |
| path | Zadejte cestu, kterou chcete obsahovat fázovaná data. Pokud cestu nezadáte, služba vytvoří kontejner pro ukládání dočasných dat. | – | No |
| enableCompression | Určuje, jestli se mají data před zkopírováním do cíle komprimovat. Toto nastavení snižuje objem přenášených dat. | False | No |
Poznámka:
Pokud použijete fázovanou kopii s povolenou kompresí, není podporované ověřování instančního objektu nebo MSI pro přípravnou propojenou službu objektů blob.
Tady je ukázková definice aktivity kopírování s vlastnostmi popsanými v předchozí tabulce:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Dopad fakturace fázované kopie
Účtují se vám poplatky na základě dvou kroků: doba trvání kopírování a typ kopírování.
- Při použití přípravy během cloudové kopie, která kopíruje data z cloudového úložiště dat do jiného cloudového úložiště dat, obě fáze zmocněné prostředím Azure Integration Runtime se vám budou účtovat [součet doby trvání kopírování pro krok 1 a krok 2] x [cena za jednotku kopírování cloudu].
- Při použití přípravy během hybridní kopie, která kopíruje data z místního úložiště dat do cloudového úložiště dat, jedna fáze je vybavená místním prostředím Integration Runtime, účtují se vám poplatky za [dobu trvání hybridní kopie] x [cena za jednotku hybridní kopie] + [doba trvání kopírování cloudu] x [cena jednotky cloudové kopie] x [cena jednotky kopírování cloudu].
Související obsah
Podívejte se na další články o aktivitě kopírování: