Řešení potíží s výkonem aktivity kopírování
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak řešit potíže s výkonem aktivity kopírování ve službě Azure Data Factory.
Po spuštění aktivity kopírování můžete shromažďovat výsledky spuštění a statistiky výkonu v zobrazení monitorování aktivit kopírování. Například:
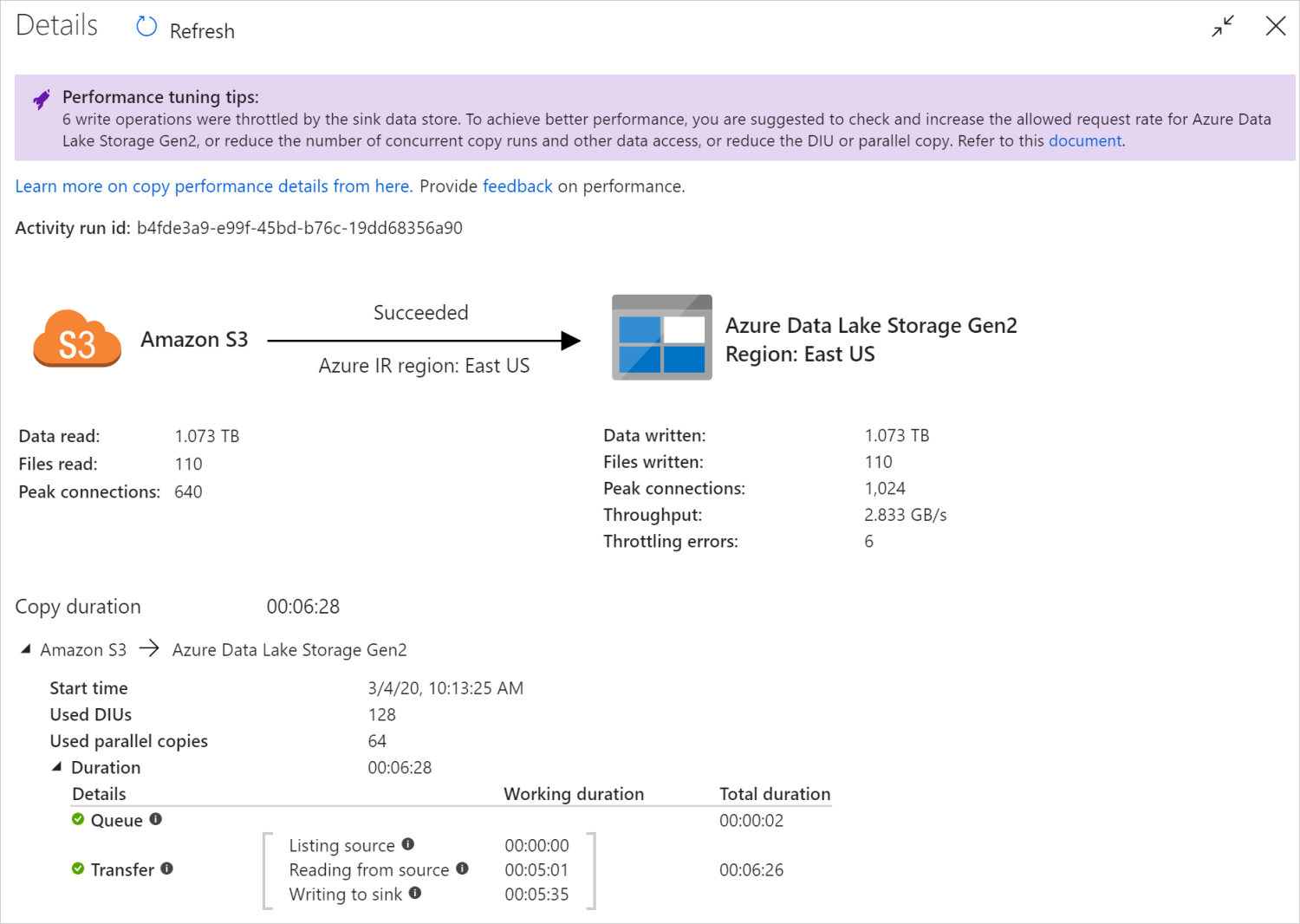
Tipy pro ladění výkonu
V některých scénářích se při spuštění aktivity kopírování v horní části zobrazí tipy pro ladění výkonu, jak je znázorněno v předchozím příkladu. Tipy vám řeknou kritické body, které služba pro toto konkrétní spuštění kopírování identifikovala, spolu s návrhem, jak zvýšit propustnost kopírování. Zkuste provést doporučenou změnu a spusťte kopii znovu.
Jako referenci v současné době tipy pro ladění výkonu poskytují návrhy pro následující případy:
| Kategorie | Tipy pro ladění výkonu |
|---|---|
| Konkrétní úložiště dat | Načítání dat do Azure Synapse Analytics: Pokud se nepoužívá, doporučujeme použít Příkaz PolyBase nebo COPY. |
| Kopírování dat z nebo do Azure SQL Database: pokud je DTU pod vysokým využitím, doporučujeme upgradovat na vyšší úroveň. | |
| Kopírování dat ze služby Azure Cosmos DB nebo do služby Azure Cosmos DB: Pokud je RU pod vysokým využitím, doporučujeme upgradovat na větší RU. | |
| Kopírování dat z tabulky SAP: Při kopírování velkého množství dat doporučujeme využít možnost oddílu konektoru SAP k povolení paralelního zatížení a zvýšení maximálního počtu oddílů. | |
| Ingestování dat z Amazon Redshift: pokud se nepoužívá, doporučujeme použít funkci UNLOAD. | |
| Omezování úložiště dat | Pokud během kopírování dojde k omezení počtu operací čtení a zápisu úložištěm dat, navrhněte kontrolu a zvýšení povolené frekvence požadavků pro úložiště dat nebo snižte souběžnou úlohu. |
| Prostředí Integration Runtime | Pokud používáte místní prostředí Integration Runtime (IR) a aktivitu kopírování čeká dlouho ve frontě, dokud není k dispozici prostředek pro spuštění prostředí IR, navrhněte horizontální navýšení nebo navýšení kapacity prostředí IR. |
| Pokud používáte prostředí Azure Integration Runtime , které je v neoptimální oblasti, což vede k pomalému čtení a zápisu, doporučujeme nakonfigurovat použití prostředí IR v jiné oblasti. | |
| Odolnost proti chybám | Pokud nakonfigurujete odolnost proti chybám a přeskočení nekompatibilních řádků způsobí nízký výkon, doporučujeme zajistit kompatibilitu dat zdroje a jímky. |
| Fázovaná kopie | Pokud je nakonfigurovaná fázovaná kopie, ale pro pár zdrojové jímky není užitečná, doporučujeme ji odebrat. |
| Obnovit | Když se aktivita kopírování obnoví z posledního bodu selhání, ale po původním spuštění změníte nastavení DIU, nové nastavení DIU se neprojeví. |
Vysvětlení podrobností o spuštění aktivity kopírování
Podrobnosti o spuštění a doby trvání v dolní části zobrazení monitorování aktivity kopírování popisují klíčové fáze, kterými aktivita kopírování prochází (viz příklad na začátku tohoto článku), což je užitečné zejména při řešení potíží s výkonem kopírování. Kritickým bodem spuštění kopie je ta, která má nejdelší dobu trvání. Informace o řešení potíží s aktivitou kopírování v prostředí Azure IR najdete v následující tabulce v definici jednotlivých fází a naučte se řešit potíže s aktivitou kopírování v místním prostředí IR s těmito informacemi.
| Fáze | Popis |
|---|---|
| Fronta | Uplynulý čas do skutečného spuštění aktivity kopírování v prostředí Integration Runtime. |
| Skript předběžného kopírování | Uplynulý čas mezi aktivitou kopírování počínaje prostředím IR a dokončením aktivity kopírování, která spouští skript předběžného kopírování v úložišti dat jímky. Použijte při konfiguraci skriptu předběžného kopírování pro databázové jímky, například při zápisu dat do služby Azure SQL Database před zkopírováním nových dat. |
| Přepojit | Uplynulý čas mezi koncem předchozího kroku a prostředím IR, který přenáší všechna data ze zdroje do jímky. Všimněte si dílčích kroků v rámci paralelního spuštění přenosu a některé operace se teď nezobrazují, například parsování nebo generování formátu souboru. - Čas na první bajt: Čas uplynulý mezi koncem předchozího kroku a časem, kdy ir přijme první bajt ze zdrojového úložiště dat. Platí pro jiné než souborové zdroje. - Zdroj výpisu: Doba strávená výčet zdrojových souborů nebo datových oddílů. Druhá možnost se použije při konfiguraci možností oddílů pro zdroje databáze, například při kopírování dat z databází, jako je Oracle/SAP HANA/Teradata/Netezza/atd. -Čtení ze zdroje: Doba strávená načítáním dat ze zdrojového úložiště dat. - Zápis do jímky: Doba strávená zápisem dat do úložiště dat jímky. Všimněte si, že některé konektory tuto metriku v tuto chvíli nemají, včetně Azure AI Search, Azure Data Exploreru, Azure Table Storage, Oracle, SQL Serveru, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Řešení potíží s aktivitou kopírování v Azure IR
Podle kroků ladění výkonu naplánujte a proveďte test výkonnosti pro váš scénář.
Pokud výkon aktivity kopírování nesplňuje vaše očekávání, při řešení potíží s jednou aktivitou kopírování spuštěnou v prostředí Azure Integration Runtime se zobrazí tipy pro ladění výkonu zobrazené v zobrazení monitorování kopírování, použijte návrh a zkuste to znovu. Jinak porozumíte podrobnostem o provádění aktivity kopírování, zkontrolujte, která fáze má nejdelší dobu trvání, a pomocí následujících pokynů zvyšte výkon kopírování:
Skript předběžného kopírování má dlouhou dobu trvání: Znamená to, že dokončení skriptu před kopírováním spuštěného v databázi jímky trvá dlouho. Vylaďte zadanou logiku skriptu předběžného kopírování, abyste zvýšili výkon. Pokud potřebujete další pomoc s vylepšováním skriptu, obraťte se na databázový tým.
"Přenos – doba na první bajt" má dlouhou pracovní dobu: znamená to, že vrácení jakýchkoli dat ve zdrojovém dotazu trvá dlouho. Zkontrolujte a optimalizujte dotaz nebo server. Pokud potřebujete další pomoc, obraťte se na tým úložiště dat.
"Přenos – výpis zdroje" má dlouhou pracovní dobu: znamená to, že výčet zdrojových souborů nebo zdrojových datových oddílů databáze je pomalý.
Pokud při kopírování dat ze zdroje založeného na souborech použijete filtr se zástupnými znamé bloky pro cestu ke složce nebo název souboru (
wildcardFolderPathnebowildcardFileName) nebo použijete filtr času poslední změny souboru (modifiedDatetimeStartnebomodifiedDatetimeEnd), všimněte si, že tento filtr by způsobil aktivitu kopírování se seznamem všech souborů v zadané složce na straně klienta a pak filtr použijte. Tento výčet souborů se může stát kritickým bodem zejména v případě, že pravidlo filtru splňuje jenom malá sada souborů.Zkontrolujte, jestli můžete kopírovat soubory na základě cesty nebo názvu souboru v oddílu datetime. Tímto způsobem se nezatěžuje výpis zdrojové strany.
Zkontrolujte, jestli místo toho můžete použít nativní filtr úložiště dat, konkrétně "předponu" pro Amazon S3/Azure Blob Storage/Azure Files a listAfter/listBefore pro ADLS Gen1. Tyto filtry jsou filtry úložiště dat na straně serveru a měly by mnohem lepší výkon.
Zvažte rozdělení jedné velké datové sady na několik menších datových sad a nechte tyto úlohy kopírování běžet souběžně při každém řešení části dat. Můžete to udělat pomocí funkce Lookup/GetMetadata + ForEach + Copy. Obecně se podívejte na kopírování souborů z více kontejnerů nebo k migraci dat z AmazonU S3 do šablon řešení ADLS Gen2 .
Zkontrolujte, jestli služba hlásí chybu omezování zdroje nebo jestli je vaše úložiště dat ve stavu vysokého využití. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
Použijte Prostředí Azure IR ve stejné oblasti nebo blízko zdrojového úložiště dat.
"Přenos – čtení ze zdroje" má dlouhou dobu trvání práce:
Osvědčený postup načítání dat specifických pro konektor, pokud se použije. Například při kopírování dat z Amazon Redshift nakonfigurujte použití Redshift UNLOAD.
Zkontrolujte, jestli služba hlásí chybu omezování ve zdroji nebo jestli je vaše úložiště dat pod vysokým využitím. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
Zkontrolujte vzor zdroje a jímky kopírování:
Pokud vzor kopírování podporuje více než 4 Integrace Dat jednotky (DIU) – podrobnosti najdete v této části, obecně můžete zkusit zvýšit výkon jednotek DIU.
Jinak zvažte rozdělení jedné velké datové sady na několik menších datových sad, aby mohly souběžné úlohy kopírování zpracovávat data po částech. Můžete to udělat pomocí funkce Lookup/GetMetadata + ForEach + Copy. Podívejte se na kopírování souborů z více kontejnerů, migraci dat z AmazonU S3 na ADLS Gen2 nebo hromadné kopírování pomocí šablon řešení řídicí tabulky jako obecný příklad.
Použijte Prostředí Azure IR ve stejné oblasti nebo blízko zdrojového úložiště dat.
"Přenos - zápis do jímky" má dlouhou pracovní dobu:
Osvědčený postup načítání dat specifických pro konektor, pokud se použije. Například při kopírování dat do Azure Synapse Analytics použijte příkaz PolyBase nebo COPY.
Zkontrolujte, jestli služba hlásí chybu omezování v jímce nebo jestli je vaše úložiště dat pod vysokým využitím. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
Zkontrolujte vzor zdroje a jímky kopírování:
Pokud vzor kopírování podporuje více než 4 Integrace Dat jednotky (DIU) – podrobnosti najdete v této části, obecně můžete zkusit zvýšit výkon jednotek DIU.
Jinak postupně vylaďte paralelní kopie, mějte na paměti, že příliš mnoho paralelních kopií může dokonce poškodit výkon.
Prostředí Azure IR použijte ve stejné oblasti nebo blízko oblasti úložiště dat jímky.
Řešení potíží s aktivitou kopírování v místním prostředí IR
Podle kroků ladění výkonu naplánujte a proveďte test výkonnosti pro váš scénář.
Pokud výkon kopírování nesplňuje vaše očekávání, při řešení potíží s jednou aktivitou kopírování spuštěnou v prostředí Azure Integration Runtime se zobrazí tipy pro ladění výkonu zobrazené v zobrazení monitorování kopírování, použijte návrh a zkuste to znovu. Jinak porozumíte podrobnostem o provádění aktivity kopírování, zkontrolujte, která fáze má nejdelší dobu trvání, a pomocí následujících pokynů zvyšte výkon kopírování:
"Fronta" trvala dlouho: Znamená to, že aktivita kopírování čeká dlouhou dobu ve frontě, dokud vaše místní prostředí IR nemá prostředek ke spuštění. Zkontrolujte kapacitu a využití prostředí IR a vertikálně navyšte nebo navyšte kapacitu podle vašich úloh.
"Přenos – doba na první bajt" má dlouhou pracovní dobu: znamená to, že vrácení jakýchkoli dat ve zdrojovém dotazu trvá dlouho. Zkontrolujte a optimalizujte dotaz nebo server. Pokud potřebujete další pomoc, obraťte se na tým úložiště dat.
"Přenos – výpis zdroje" má dlouhou pracovní dobu: znamená to, že výčet zdrojových souborů nebo zdrojových datových oddílů databáze je pomalý.
Zkontrolujte, jestli má počítač místního prostředí IR nízkou latenci připojení ke zdrojovému úložišti dat. Pokud je váš zdroj v Azure, můžete pomocí tohoto nástroje zkontrolovat latenci počítače místního prostředí IR do oblasti Azure, tím méně tím lépe.
Pokud při kopírování dat ze zdroje založeného na souborech použijete filtr se zástupnými znamé bloky pro cestu ke složce nebo název souboru (
wildcardFolderPathnebowildcardFileName) nebo použijete filtr času poslední změny souboru (modifiedDatetimeStartnebomodifiedDatetimeEnd), všimněte si, že tento filtr by způsobil aktivitu kopírování se seznamem všech souborů v zadané složce na straně klienta a pak filtr použijte. Tento výčet souborů se může stát kritickým bodem zejména v případě, že pravidlo filtru splňuje jenom malá sada souborů.Zkontrolujte, jestli můžete kopírovat soubory na základě cesty nebo názvu souboru v oddílu datetime. Tímto způsobem se nezatěžuje výpis zdrojové strany.
Zkontrolujte, jestli místo toho můžete použít nativní filtr úložiště dat, konkrétně "předponu" pro Amazon S3/Azure Blob Storage/Azure Files a listAfter/listBefore pro ADLS Gen1. Tyto filtry jsou filtry úložiště dat na straně serveru a měly by mnohem lepší výkon.
Zvažte rozdělení jedné velké datové sady na několik menších datových sad a nechte tyto úlohy kopírování běžet souběžně při každém řešení části dat. Můžete to udělat pomocí funkce Lookup/GetMetadata + ForEach + Copy. Obecně se podívejte na kopírování souborů z více kontejnerů nebo k migraci dat z AmazonU S3 do šablon řešení ADLS Gen2 .
Zkontrolujte, jestli služba hlásí chybu omezování zdroje nebo jestli je vaše úložiště dat ve stavu vysokého využití. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
"Přenos – čtení ze zdroje" má dlouhou dobu trvání práce:
Zkontrolujte, jestli má počítač místního prostředí IR nízkou latenci připojení ke zdrojovému úložišti dat. Pokud je váš zdroj v Azure, můžete pomocí tohoto nástroje zkontrolovat latenci počítače místního prostředí IR do oblastí Azure, tím méně tím lépe.
Zkontrolujte, jestli má počítač místního prostředí IR dostatečnou šířku pásma pro efektivní čtení a přenos dat. Pokud je vaše zdrojové úložiště dat v Azure, můžete pomocí tohoto nástroje zkontrolovat rychlost stahování.
Podívejte se na trend využití procesoru a paměti místního prostředí IR na webu Azure Portal –> na stránce s přehledem datové továrny nebo pracovního prostoru> Synapse. Pokud je využití procesoru vysoké nebo dostupné paměti, zvažte vertikální navýšení nebo navýšení kapacity ir.
Osvědčený postup načítání dat specifických pro konektor, pokud se použije. Příklad:
Při kopírování dat z Oracle, Netezza, Teradata, SAP HANA, SAP Table a SAP Open Hubu povolte paralelní kopírování dat v možnostech oddílu dat.
Při kopírování dat z HDFS nakonfigurujte použití DistCp.
Při kopírování dat z Amazon Redshiftu nakonfigurujte použití Funkce UNLOAD Redshift.
Zkontrolujte, jestli služba hlásí chybu omezování ve zdroji nebo jestli je vaše úložiště dat pod vysokým využitím. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
Zkontrolujte vzor zdroje a jímky kopírování:
Pokud kopírujete data z úložišť dat s podporou možností oddílů, zvažte postupné ladění paralelních kopií, mějte na paměti, že výkon může dokonce poškodit příliš mnoho paralelních kopií.
Jinak zvažte rozdělení jedné velké datové sady na několik menších datových sad, aby mohly souběžné úlohy kopírování zpracovávat data po částech. Můžete to udělat pomocí funkce Lookup/GetMetadata + ForEach + Copy. Podívejte se na kopírování souborů z více kontejnerů, migraci dat z AmazonU S3 na ADLS Gen2 nebo hromadné kopírování pomocí šablon řešení řídicí tabulky jako obecný příklad.
"Přenos - zápis do jímky" má dlouhou pracovní dobu:
Osvědčený postup načítání dat specifických pro konektor, pokud se použije. Například při kopírování dat do Azure Synapse Analytics použijte příkaz PolyBase nebo COPY.
Zkontrolujte, jestli má počítač místního prostředí IR nízkou latenci připojení k úložišti dat jímky. Pokud je vaše jímka v Azure, můžete pomocí tohoto nástroje zkontrolovat latenci počítače místního prostředí IR do oblasti Azure, tím méně tím lépe.
Zkontrolujte, jestli má počítač místního prostředí IR dostatečnou odchozí šířku pásma pro přenos a efektivní zápis dat. Pokud je úložiště dat jímky v Azure, můžete pomocí tohoto nástroje zkontrolovat rychlost nahrávání.
Zkontrolujte, jestli trend využití procesoru a paměti místního prostředí IR na webu Azure Portal –> vaše datová továrna nebo pracovní prostor Synapse –> – přehled. Pokud je využití procesoru vysoké nebo dostupné paměti, zvažte vertikální navýšení nebo navýšení kapacity ir.
Zkontrolujte, jestli služba hlásí chybu omezování v jímce nebo jestli je vaše úložiště dat pod vysokým využitím. Pokud ano, snižte zatížení v úložišti dat nebo zkuste kontaktovat správce úložiště dat, aby zvýšil limit omezování nebo dostupný prostředek.
Zvažte postupné ladění paralelních kopií, mějte na paměti, že příliš mnoho paralelních kopií může dokonce poškodit výkon.
Výkon konektoru a prostředí IR
Tato část popisuje některé příručky pro řešení potíží s výkonem pro konkrétní typ konektoru nebo prostředí Integration Runtime.
Doba provádění aktivit se liší pomocí prostředí Azure IR vs. Azure VNet IR
Doba provádění aktivity se liší, když je datová sada založená na jiném prostředí Integration Runtime.
Příznaky: Jednoduše přepnutí rozevíracího seznamu propojené služby v datové sadě provádí stejné aktivity kanálu, ale má výrazně odlišné časy spuštění. Pokud je datová sada založená na prostředí Managed Virtual Network Integration Runtime, trvá to v průměru více času, než je spuštění založené na výchozím prostředí Integration Runtime.
Příčina: Kontrola podrobností o spuštění kanálu vidíte, že pomalý kanál běží v prostředí IR spravované virtuální sítě (virtual network), zatímco normální kanál běží v Prostředí Azure IR. Spravované prostředí VNet IR na základě návrhu trvá delší dobu fronty než Azure IR, protože si neservírujeme jeden výpočetní uzel na instanci služby, takže je potřeba zahřívat každou aktivitu kopírování a dochází k ní především u připojení k virtuální síti místo prostředí Azure IR.
Nízký výkon při načítání dat do služby Azure SQL Database
Příznaky: Kopírování dat do služby Azure SQL Database se změní na pomalé.
Příčina: Hlavní příčina problému se většinou aktivuje kritickým bodem na straně služby Azure SQL Database. Tady je několik možných příčin:
Úroveň Azure SQL Database není dostatečně vysoká.
Využití DTU služby Azure SQL Database se blíží 100 %. Můžete monitorovat výkon a zvážit upgrade úrovně služby Azure SQL Database.
Indexy nejsou správně nastaveny. Odeberte všechny indexy před načtením dat a po dokončení načtení je znovu vytvořte.
WriteBatchSize není dostatečně velký, aby odpovídal velikosti řádku schématu. Pokuste se zvětšit vlastnost problému.
Místo hromadného vložení se používá uložená procedura, u které se očekává horší výkon.
Časový limit nebo nízký výkon při analýze velkého excelového souboru
Příznaky:
Když vytváříte excelovou datovou sadu a importujete schéma z připojení/ úložiště, náhledu dat, seznamu nebo aktualizací listů, může dojít k chybě časového limitu, pokud je excelový soubor velký.
Při kopírování dat z velkého excelového souboru (>= 100 MB) do jiného úložiště dat můžete zaznamenat nízký výkon nebo problém s OOM.
Příčina:
Pro operace, jako je import schématu, zobrazení náhledu dat a výpis listů v datové sadě aplikace Excel, je časový limit 100 s a statický. U velkého excelového souboru se tyto operace nemusí dokončit v rámci hodnoty časového limitu.
Aktivita kopírování načte celý soubor aplikace Excel do paměti a pak vyhledá zadaný list a buňky pro čtení dat. Toto chování je způsobeno podkladovou sadou SDK, která služba používá.
Řešení:
Pro import schématu můžete vygenerovat menší ukázkový soubor, což je podmnožina původního souboru, a místo importu schématu z připojení nebo úložiště zvolte import schématu z ukázkového souboru.
Pro výpis listu můžete v rozevíracím seznamu listu kliknout na Upravit a místo toho zadat název listu nebo index.
Pokud chcete zkopírovat velký excelový soubor (>100 MB) do jiného úložiště, můžete použít Tok dat zdroj Excelu, který sport streaming čte a funguje lépe.
Problém S objektem OOM při čtení velkých souborů JSON/Excel/XML
Příznaky: Při čtení velkých souborů JSON/Excel/XML se během provádění aktivity setkáte s problémem s nedostatkem paměti (OOM).
Příčina:
- Pro velké soubory XML: Problém OOM čtení velkých souborů XML je záměrně. Příčinou je, že celý soubor XML musí být načten do paměti, protože se jedná o jeden objekt, pak je schéma odvozeno a data se načtou.
- U velkých excelových souborů: Problém OOM při čtení velkých excelových souborů je záměrně. Příčinou je, že použitá sada SDK (POI/NPOI) musí číst celý excelový soubor do paměti a pak odvodit schéma a získat data.
- U velkých souborů JSON: Problém OOM při čtení velkých souborů JSON je záměrně, když je soubor JSON jediným objektem.
Doporučení: Při řešení vašeho problému použijte jednu z následujících možností.
- Možnost 1: Zaregistrujte online místní prostředí Integration Runtime s výkonným počítačem (s vysokým využitím procesoru a paměti) pro čtení dat z velkého souboru prostřednictvím aktivity kopírování.
- Možnost 2: Použijte optimalizovaný cluster paměti a velké velikosti (například 48 jader) ke čtení dat z velkého souboru prostřednictvím aktivity mapování toku dat.
- Možnost 3: Rozdělte velký soubor na malé a pak ke čtení složky použijte aktivitu toku kopírování nebo mapování dat.
- Možnost 4: Pokud jste při kopírování složky XML/Excel/JSON zablokovali nebo splňujete problém S objektem OOM, použijte aktivitu foreach + aktivitu toku dat kopírování/mapování v kanálu ke zpracování jednotlivých souborů nebo podsložek.
- Možnost 5: Ostatní:
- Pro XML použijte aktivitu poznámkového bloku s clusterem optimalizovaným pro paměť ke čtení dat ze souborů, pokud má každý soubor stejné schéma. Spark má v současné době různé implementace pro zpracování XML.
- Pro JSON použijte různé formuláře dokumentu (například jeden dokument, dokument na řádek a pole dokumentů) v nastavení JSON v části mapování zdroje toku dat. Pokud je obsah souboru JSON dokument na řádek, spotřebovává velmi málo paměti.
Další odkazy
Tady jsou reference k monitorování výkonu a ladění některých podporovaných úložišť dat:
- Azure Blob Storage: Cíle škálovatelnosti a výkonu pro úložiště objektů blob a kontrolní seznam výkonu a škálovatelnosti pro úložiště objektů blob.
- Azure Table Storage: Cíle škálovatelnosti a výkonu pro table storage a kontrolní seznam výkonu a škálovatelnosti pro Table Storage.
- Azure SQL Database: Můžete monitorovat výkon a kontrolovat procento jednotky DTU (Database Transaction Unit).
- Azure Synapse Analytics: Jeho schopnost se měří v jednotkách datového skladu (DWU). Viz Správa výpočetního výkonu ve službě Azure Synapse Analytics (přehled).
- Azure Cosmos DB: Úrovně výkonu ve službě Azure Cosmos DB
- SQL Server: Monitorování a ladění výkonu
- Místní souborový server: Ladění výkonu pro souborové servery
Související obsah
Podívejte se na další články o aktivitě kopírování:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro