Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje vše od přenášení dat až po datovou vědu, analýzy v reálném čase, podnikové zpravodajství a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici v kanálech Azure Data Factory i v kanálech Azure Synapse Analytics. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toků dat.
Transformace zdroje konfiguruje zdroj dat pro tok dat. Při návrhu toků dat je vaším prvním krokem vždy konfigurace transformace zdroje. Pokud chcete přidat zdroj, vyberte na plátně toku dat pole Přidat zdroj .
Každý tok dat vyžaduje aspoň jednu transformaci zdroje, ale k dokončení transformací dat můžete přidat libovolný počet zdrojů. Tyto zdroje můžete spojit společně s transformací spojení, vyhledáváním nebo sjednocením.
Každá zdrojová transformace je přidružená přesně k jedné datové sadě nebo propojené službě. Datová sada definuje tvar a umístění dat, ze kterého chcete zapisovat nebo číst. Pokud používáte datovou sadu založenou na souborech, můžete použít zástupné cardy a seznamy souborů ve zdroji k práci s více než jedním souborem najednou.
Vložené datové sady
Prvním rozhodnutím, které provedete při vytváření transformace zdroje, je to, jestli se informace o zdroji definují uvnitř objektu datové sady nebo v rámci transformace zdroje. Většina formátů je k dispozici pouze v jednom nebo druhém. Informace o použití konkrétního konektoru najdete v příslušném dokumentu konektoru.
Pokud je formát podporován pro vložený i v objektu datové sady, existují výhody obou. Objekty datové sady jsou opakovaně použitelné entity, které je možné použít v jiných tocích dat a aktivitách, jako je kopírování. Tyto opakovaně použitelné entity jsou zvlášť užitečné, když používáte posílené schéma. Datové sady nejsou založené na Sparku. V některých případech může být potřeba přepsat určitá nastavení nebo projekce schématu ve zdrojové transformaci.
Vložené datové sady se doporučují, když používáte flexibilní schémata, jednorázové zdrojové instance nebo parametrizované zdroje. Pokud je zdroj silně parametrizovaný, vložené datové sady umožňují nevytvořit "fiktivní" objekt. Vložené datové sady jsou založené na Sparku a jejich vlastnosti jsou nativní pro tok dat.
Pokud chcete použít vloženou datovou sadu, vyberte požadovaný formát v selektoru typ zdroje. Místo výběru zdrojové datové sady vyberete propojenou službu, ke které se chcete připojit.
Možnosti schématu
Protože vložená datová sada je definovaná uvnitř toku dat, není definované schéma přidružené k vložené datové sadě. Na kartě Projekce můžete importovat schéma zdrojových dat a uložit toto schéma jako zdrojová projekce. Na této kartě najdete tlačítko Možnosti schématu, které umožňuje definovat chování služby zjišťování schémat ADF.
- Použít projektované schéma: Tato možnost je užitečná, pokud máte velký počet zdrojových souborů, které ADF prohledává jako zdroj. Výchozím chováním ADF je zjištění schématu každého zdrojového souboru. Pokud ale máte předdefinované projekce, které už jsou uložené ve zdrojové transformaci, můžete ji nastavit na true a ADF přeskočí automatické zjišťování všech schémat. Když je tato možnost zapnutá, může zdrojová transformace číst všechny soubory mnohem rychleji a použít předdefinované schéma u každého souboru.
- Povolit posun schématu: Zapněte posun schématu, aby tok dat umožňoval nové sloupce, které ještě nejsou definované ve zdrojovém schématu.
- Ověření schématu: Nastavení této možnosti způsobí selhání toku dat, pokud některý sloupec a typ definovaný v projekci neodpovídá zjištěnému schématu zdrojových dat.
- Odvozené typy posunovaných sloupců: Když ADF identifikuje nové posunované sloupce, přetypují se tyto nové sloupce na příslušný datový typ pomocí automatického odvozování typu ADF.
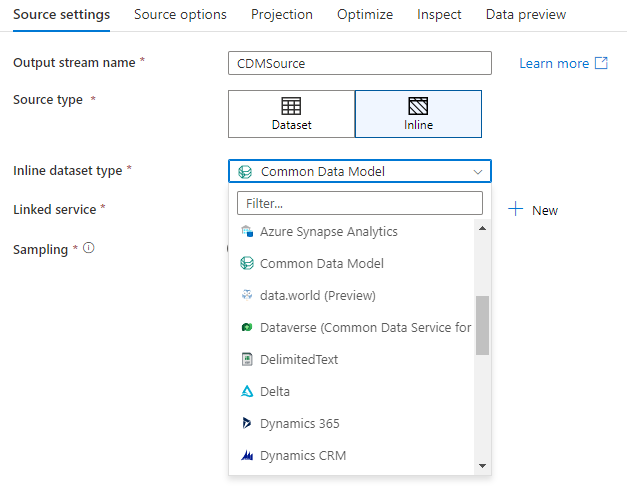
Databáze pracovního prostoru (pouze pracovní prostory Synapse)
V pracovních prostorech Azure Synapse se v transformacích zdroje toku dat nazývá Workspace DBdalší možnost . Díky tomu můžete přímo vybrat databázi pracovního prostoru libovolného dostupného typu jako zdrojová data bez nutnosti dalších propojených služeb nebo datových sad. Databáze vytvořené prostřednictvím šablon databáze Azure Synapse jsou také přístupné, když vyberete databázi pracovního prostoru.
Podporované typy zdrojů
Mapování toku dat se řídí přístupem extrakce, načítání a transformace (ELT) a pracuje s přípravnými datovými sadami, které jsou všechny v Azure. V současné době je možné ve zdrojové transformaci použít následující datové sady.
Nastavení specifická pro tyto konektory se nacházejí na kartě Možnosti zdroje. Příklady skriptů toku dat v těchto nastaveních najdete v dokumentaci ke konektoru.
Kanály Azure Data Factory a Synapse mají přístup k více než 90 nativním konektorům. Pokud chcete zahrnout data z těchto dalších zdrojů do toku dat, použijte aktivitu kopírování k načtení těchto dat do jedné z podporovaných pracovních oblastí.
Nastavení zdroje
Po přidání zdroje nakonfigurujte prostřednictvím Nastavení zdroje. Tady můžete vybrat nebo vytvořit datovou sadu, na kterou váš zdroj ukazuje. Můžete také vybrat možnosti schématu a vzorkování dat.
Hodnoty parametrů pro vývoj datové sady lze nakonfigurovat v nastavení ladění. (Musí být zapnutý režim ladění.)
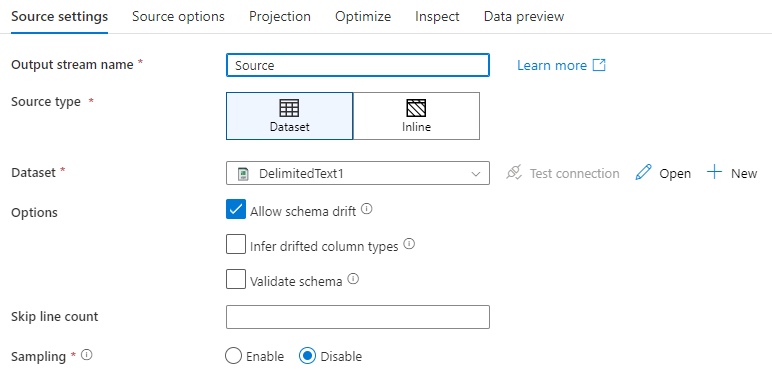
Název výstupního datového proudu: Název zdrojové transformace.
Typ zdroje: Zvolte, jestli chcete použít vloženou datovou sadu nebo existující objekt datové sady.
Testovací připojení: Otestujte, jestli se služba Spark toku dat může úspěšně připojit k propojené službě použité ve zdrojové datové sadě. Aby byla tato funkce povolená, musí být zapnutý režim ladění.
Posun schématu: Posun schématu je schopnost služby zpracovávat flexibilní schémata ve vašich tocích dat nativně, aniž by bylo nutné explicitně definovat změny sloupců.
Zaškrtněte políčko Povolit posun schématu, pokud se zdrojové sloupce často mění. Toto nastavení umožňuje, aby všechna příchozí zdrojová pole procházela transformacemi do jímky.
Výběr možnosti detekovat posunuté typy sloupců dá službě pokyn, aby zjistila a určila datové typy pro každý nově zjištěný sloupec. Pokud je tato funkce vypnutá, všechny posunované sloupce mají typ řetězec.
Ověřit schéma: Pokud je vybráno ověření schématu , tok dat se nepovede spustit, pokud příchozí zdrojová data neodpovídají definovanému schématu datové sady.
Přeskočit počet řádků: Pole Přeskočit počet řádků určuje, kolik řádků se má ignorovat na začátku datové sady.
Vzorkování: Povolte vzorkování , abyste omezili počet řádků z vašeho zdroje. Toto nastavení použijte při testování nebo vzorkování dat ze zdroje pro účely ladění. To je velmi užitečné při spouštění toků dat v režimu ladění z pipeline.
Pokud chcete ověřit, jestli je zdroj správně nakonfigurovaný, zapněte režim ladění a načtěte náhled dat. Další informace naleznete v tématu Režim ladění.
Poznámka:
Když je režim ladění zapnutý, konfigurace omezení počtu řádků v nastavení ladění přepíše nastavení vzorkování ve zdroji během náhledu dat.
Možnosti zdroje
Karta Možnosti zdroje obsahuje nastavení specifická pro vybraný konektor a formát. Další informace a příklady najdete v příslušné dokumentaci ke konektoru. To zahrnuje podrobnosti, jako je úroveň izolace pro tyto zdroje dat, které je podporují (například místní SQL Servery, Azure SQL Database a spravované instance Azure SQL) a další nastavení specifické pro zdroje dat.
Projekce
Podobně jako schémata v datových sadách definuje projekce ve zdroji datové sloupce, typy a formáty ze zdrojových dat. U většiny typů datových sad, jako je SQL a Parquet, je projekce ve zdroji pevná tak, aby odrážela schéma definované v datové sadě, které se bude lišit v závislosti na zdroji. Pokud vaše zdrojové soubory nejsou silně typované (například jednoduché .csv soubory místo souborů Parquet), můžete definovat datové typy pro každé pole při převodu dat ze zdroje. Následující obrázek znázorňuje ukázkovou projekci:
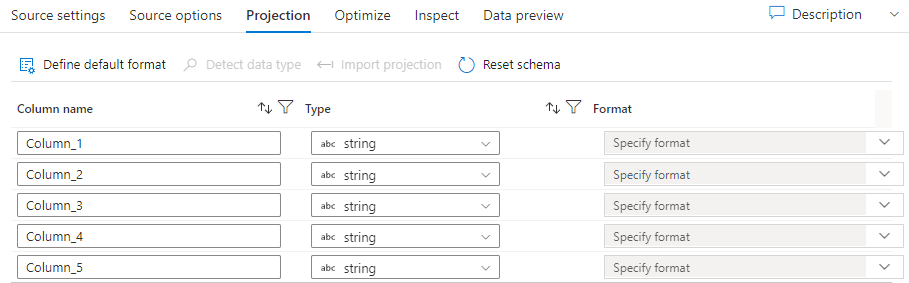
Pokud váš textový soubor nemá definované schéma, vyberte Zjistit datový typ, aby služba mohla vzorkovat a odvodit datové typy. Vyberte Možnost Definovat výchozí formát pro automatické rozpoznávání výchozích formátů dat.
Resetování schématu resetuje projekci na to, co je definováno v odkazované datové sadě.
Přepsat schéma vám umožní upravit projektované datové typy u zdroje, přičemž přepíšete typy dat definované schématem. Datové typy sloupců můžete případně upravit v transformaci odvozeného sloupce, která následuje. Použijte transformaci výběru k úpravě názvů sloupců.
Import schématu
Vyberte tlačítko Importovat schéma na kartě Projekce pro použití aktivního ladicího klastru k vytvoření projekce schématu. Je k dispozici v každém typu zdroje. Import schématu sem přepíše projekci definovanou v datové sadě. Objekt datové sady se nezmění.
Import schématu je užitečný v datových sadách, jako jsou Avro a Azure Cosmos DB, které podporují složité datové struktury, které nevyžadují, aby v datové sadě existovaly definice schématu. U vložených datových sad představuje import schématu jediný způsob, jak odkazovat na metadata sloupců bez posunu schématu.
Optimalizace transformace zdroje
Karta Optimalizovat umožňuje upravovat informace o oddílu v jednotlivých krocích transformace. Ve většině případů použití aktuálního rozložení optimalizuje ideální strukturu rozložení pro zdroj.
Pokud čtete data ze zdroje služby Azure SQL Database, použijte vlastní rozdělení zdroje, které pravděpodobně zajistí nejrychlejší načítání dat. Služba čte velké dotazy paralelním připojením k databázi. Toto zdrojové dělení lze provést ve sloupci nebo pomocí dotazu.
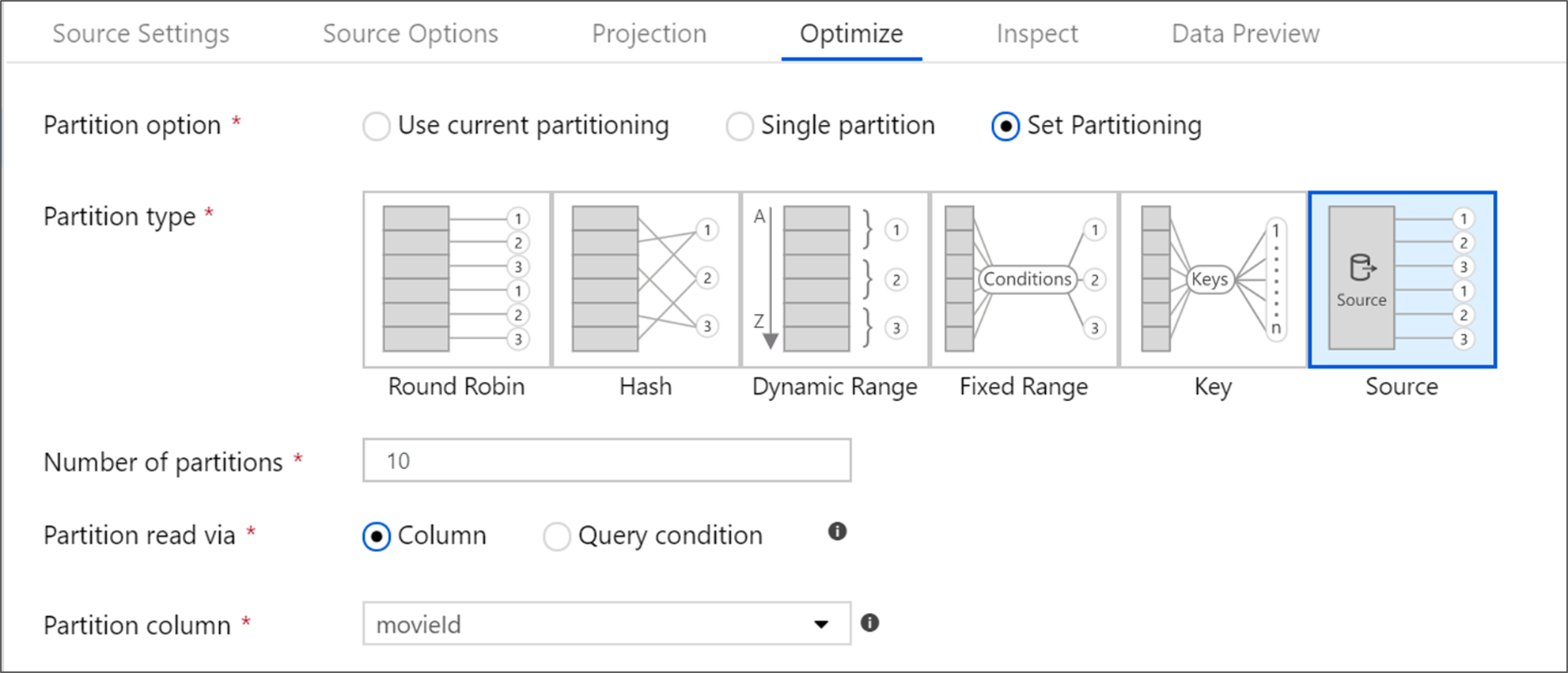
Další informace o optimalizaci v rámci mapování toku dat najdete na kartě Optimalizace.
Související obsah
Začněte vytvářet tok dat s transformací odvozeného sloupce a výběrovou transformací.