Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Návod
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od pohybu dat až po datovou vědu, business intelligence, analýzy v reálném čase a reporting. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
V tomto kurzu vytvoříte datovou továrnu pomocí uživatelského rozhraní služby Azure Data Factory. Kanál v této datové továrně kopíruje data z Úložiště objektů blob v Azure do databáze ve službě Azure SQL Database. Schéma konfigurace v tomto kurzu se vztahuje na kopírování z úložiště dat založeného na souborech do relačního úložiště dat. Seznam úložišť dat podporovaných jako zdroje a jímky najdete v tabulce podporovaných úložišť dat .
Poznámka:
Pokud se službou Data Factory začínáte, přečtěte si téma Úvod do služby Azure Data Factory.
V tomto kurzu budete provádět následující kroky:
- Vytvořte datovou továrnu.
- Vytvořte datový tok s aktivitou kopírování.
- Testovací spuštění kanálu
- Spusťte potrubí ručně.
- Spusťte proces dle rozvrhu.
- Monitorování spuštění aktivit a kanálu
- Zakažte nebo odstraňte naplánovanou aktivační událost.
Požadavky
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet Azure , než začnete.
- Účet úložiště Azure. Úložiště objektů blob používáte jako zdrojové úložiště dat. Pokud účet úložiště nemáte, přečtěte si téma Vytvoření účtu úložiště Azure , kde najdete postup jeho vytvoření.
- azure SQL Database. Databázi použijete jako cílové úložiště dat. Pokud ve službě Azure SQL Database nemáte databázi, přečtěte si téma Vytvoření databáze ve službě Azure SQL Database , kde najdete postup jeho vytvoření.
Vytvoření objektu blob a tabulky SQL
Teď si připravte úložiště Blob Storage a databázi SQL Database pro tento kurz, a to podle těchto kroků.
Vytvoření zdrojového objektu blob
Spusťte Poznámkový blok. Zkopírujte následující text a uložte ho jako souboremp.txt :
FirstName,LastName John,Doe Jane,DoePřesuňte tento soubor do složky označované jako vstup.
Ve službě Blob Storage vytvořte kontejner s názvem adftutorial . Nahrajte vstupní složku se souborememp.txt do tohoto kontejneru. K těmto úlohám můžete použít Azure Portal nebo nástroje, jako je Průzkumník služby Azure Storage .
Vytvoření tabulky SQL jímky
K vytvoření tabulky dbo.emp v databázi použijte následující skript SQL:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Povolte službám Azure přístup k SQL Serveru. Ujistěte se, že je pro SQL Server zapnutýpovolený přístup ke službám Azure, aby služba Data Factory mohla zapisovat data do SQL Serveru. Pokud chcete toto nastavení ověřit a zapnout, přejděte na SQL Server v Azure portálu a vyberte Zabezpečení>Sítě> povolit Vybrané sítě> a zaškrtněte Povolit službám a prostředkům Azure přístup k tomuto serveru v části Výjimky.
Vytvoření datové továrny
V tomto kroku vytvoříte datovou továrnu a spustíte uživatelské rozhraní služby Data Factory, ve kterém v této datové továrně vytvoříte kanál.
Otevřete Microsoft Edge nebo Google Chrome. Uživatelské rozhraní služby Data Factory podporují v současnosti jenom webové prohlížeče Microsoft Edge a Google Chrome.
V nabídce vlevo vyberte Vytvořit prostředek>Analytika>Datová továrna.
Na stránce Vytvořit datovou továrnu na kartě Základy vyberte předplatné Azure, ve kterém chcete vytvořit datovou továrnu.
V případě skupiny prostředků proveďte jeden z následujících kroků:
a. V rozevíracím seznamu vyberte existující skupinu prostředků.
b) Vyberte Vytvořit nový a zadejte název nové skupiny prostředků.
Další informace o skupinách prostředků najdete v tématu Použití skupin prostředků ke správě prostředků Azure.
V části Oblast vyberte umístění datové továrny. Vaše úložiště dat můžou být v jiné oblasti než vaše datová továrna, pokud je potřeba.
V části Název musí být název datové továrny Azure globálně jedinečný. Pokud se zobrazí chybová zpráva týkající se hodnoty názvu, zadejte jiný název datové továrny. (například vašenázevADFDemo). Pravidla pojmenování artefaktů služby Data Factory najdete v tématu Pravidla pojmenování služby Data Factory.
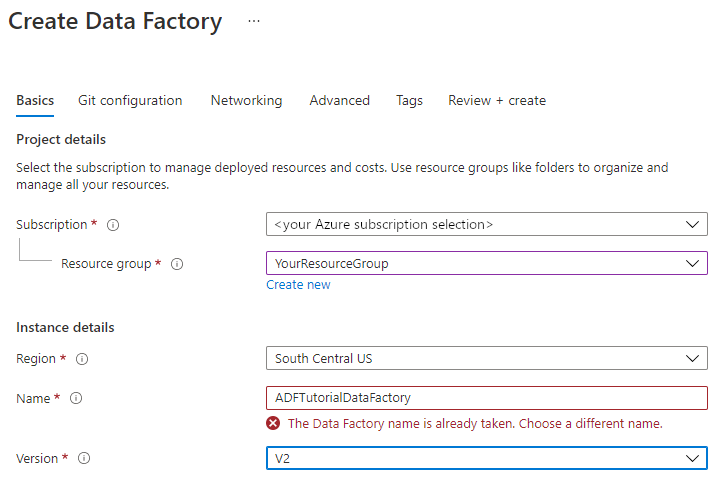
V části Verze vyberte V2.
Nahoře vyberte kartu konfigurace Gitu a zaškrtněte políčko Konfigurovat Git později .
Vyberte Zkontrolovat a vytvořit a po úspěšném ověření vyberte Vytvořit .
Po vytvoření se v Centru oznámení zobrazí oznámení. Výběrem možnosti Přejít k prostředku přejděte na stránku Data Factory.
Na dlaždici Azure Data Factory Studio vyberte Spustit Studio.
Vytvořit kanál
V tomto kroku vytvoříte v datové továrně kanál s aktivitou kopírování. Aktivita kopírování kopíruje data z úložiště Blob Storage do databáze SQL Database.
Na domovské stránce vyberte Orchestrate.
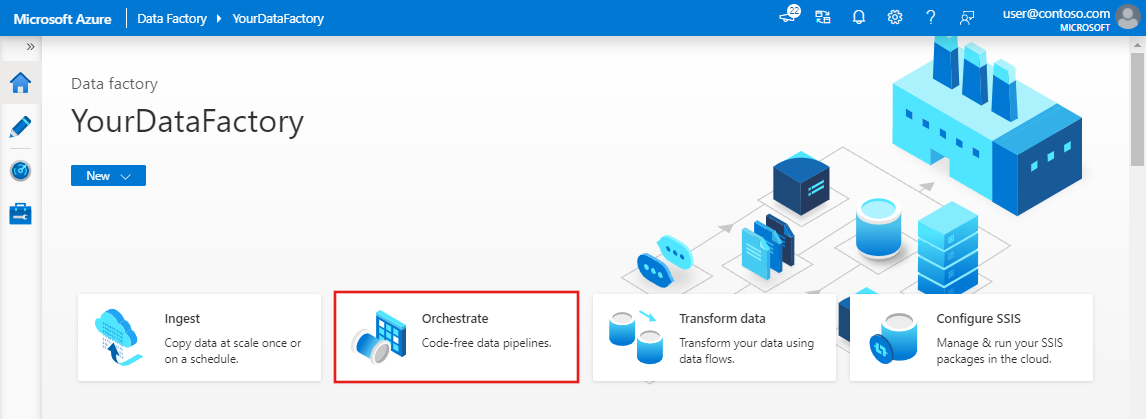
Na panelu Obecné v části Vlastnosti zadejte CopyPipeline pro Název. Potom panel sbalte kliknutím na ikonu Vlastnosti v pravém horním rohu.
V Panelu nástrojů Aktivity rozbalte kategorii Přesunout a Transformovat a přetáhněte aktivitu Kopírování dat z panelu nástrojů na plochu návrháře kanálu. Zadejte copyFromBlobToSql pro název.
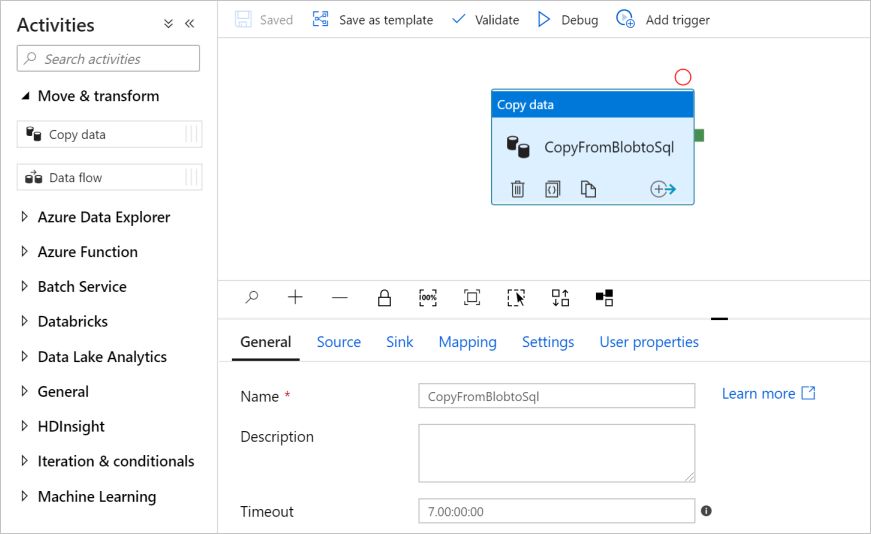
Konfigurace zdroje
Návod
V tomto kurzu použijete klíč účtu jako typ ověřování pro zdrojové úložiště dat, ale v případě potřeby můžete zvolit další podporované metody ověřování: identifikátor URI SAS, instanční objekt a spravovanou identitu . Podrobnosti najdete v odpovídajících částech tohoto článku . Pokud chcete bezpečně ukládat tajné kódy pro úložiště dat, doporučuje se také použít Azure Key Vault. Podrobné ilustrace najdete v tomto článku .
Přejděte na kartu Zdroj . Vyberte + Nový a vytvořte zdrojovou datovou sadu.
V dialogovém okně Nová datová sada vyberte Azure Blob Storage a pak vyberte Pokračovat. Zdrojová data jsou v úložišti objektů blob, takže pro zdrojovou datovou sadu vyberete Azure Blob Storage .
V dialogovém okně Vybrat formát zvolte Text s oddělovači a pak vyberte Pokračovat.
V dialogovém okně Nastavit vlastnosti zadejte SourceBlobDataset pro název. Zaškrtněte políčko u prvního řádku jako záhlaví. V textovém poli Propojená služba vyberte + Nový.
V dialogovém okně Nová propojená služba (Azure Blob Storage) zadejte jako název službu AzureStorageLinkedService a v seznamu názvů účtů úložiště vyberte svůj účet úložiště. Otestujte připojení a výběrem možnosti Vytvořit nasaďte propojenou službu.
Po vytvoření propojené služby se vrátí zpět na stránku Nastavit vlastnosti . Vedle cesty k souboru vyberte Procházet.
Přejděte do složky adftutorial/input , vyberte emp.txt soubor a pak vyberte OK.
Vyberte OK. Automaticky přejde na stránku kanálu. Na kartě Zdroj potvrďte, že je vybrána položka SourceBlobDataset. Pokud chcete zobrazit náhled dat na této stránce, vyberte Náhled dat.
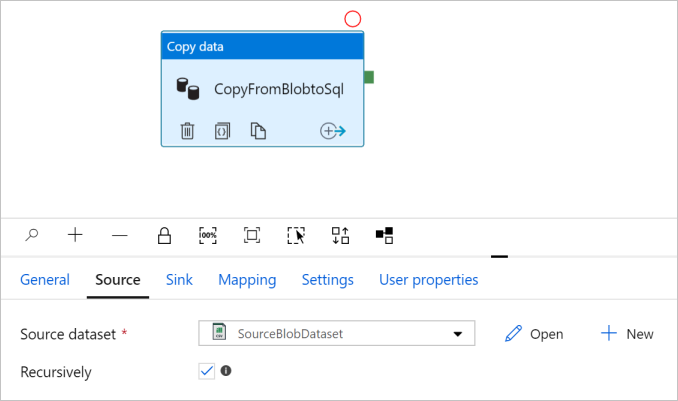
Konfigurace jímky
Návod
V tomto kurzu použijete ověřování SQL jako typ ověřování pro úložiště pro ukládání dat, ale můžete v případě potřeby zvolit také jiné podporované metody ověřování: Hlavní služba a Spravovaná Identita. Podrobnosti najdete v odpovídajících částech tohoto článku . Pokud chcete bezpečně ukládat tajné kódy pro úložiště dat, doporučuje se také použít Azure Key Vault. Podrobné ilustrace najdete v tomto článku .
Přejděte na kartu Jímka a výběrem + Nový vytvořte datovou sadu jímky.
V dialogovém okně Nová datová sada zadejte do vyhledávacího pole "SQL" pro filtrování konektorů, vyberte Azure SQL Database a pak vyberte Pokračovat.
V dialogovém okně Nastavit vlastnosti zadejte outputSqlDataset pro název. V rozevíracím seznamu Propojená služba vyberte + Nový. Datová sada musí být přidružená k propojené službě. Propojená služba má připojovací řetězec, který služba Data Factory používá pro připojení ke službě SQL Database za běhu a určuje, kam se data zkopírují.
V dialogovém okně Nová propojená služba (Azure SQL Database) proveďte následující kroky:
a. V části Název zadejte AzureSqlDatabaseLinkedService.
b) V části Název serveru vyberte instanci SQL Serveru.
c) V části Název databáze vyberte databázi.
d. V části Uživatelské jméno zadejte jméno uživatele.
e. V části Heslo zadejte heslo uživatele.
f. Výběrem možnosti Test připojení otestujte připojení.
gram Výběrem možnosti Vytvořit nasadíte propojenou službu.
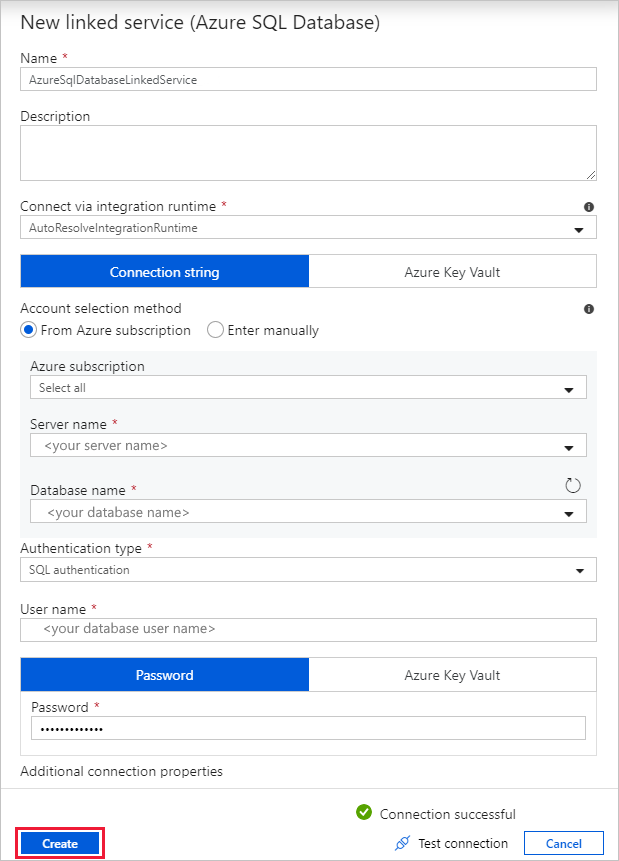
Automaticky přejde do dialogového okna Nastavit vlastnosti . V tabulce vyberte Zadat ručně a zadejte [dbo].[emp]. Pak vyberte OK.
Přejděte na kartu s potrubím a v datové sadě pro odtok ověřte, že je vybrána OutputSqlDataset.
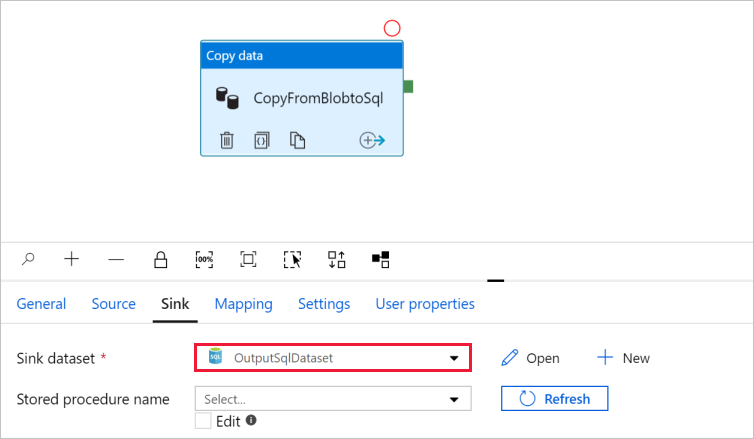
Volitelně můžete schéma zdroje namapovat na odpovídající schéma cíle pomocí mapování schématu v aktivitě kopírování.
Ověření kanálu
Chcete-li potrubí ověřit, vyberte na panelu nástrojů Ověřit.
Kód JSON přidružený ke kanálu můžete zobrazit kliknutím na Kód v pravém horním rohu.
Ladění a publikování kanálu
Před publikováním artefaktů (propojených služeb, datových sad a kanálu) do služby Data Factory nebo vlastního úložiště Gitu Azure Repos můžete kanál odladit.
Chcete-li ladit potrubí, na panelu nástrojů vyberte Ladit. Stav spuštění kanálu se zobrazí na panelu Výstup ve spodní části okna.
Po úspěšném spuštění kanálu vyberte na horním panelu nástrojů možnost Publikovat vše. Touto akcí publikujete vytvořené entity (datové sady a kanály) do služby Data Factory.
Počkejte, dokud se nezobrazí zpráva o úspěšném publikování oznámení. Chcete-li zobrazit oznámení, vyberte Zobrazit oznámení v pravém horním rohu (tlačítko zvonku).
Ruční aktivace kanálu
V tomto kroku ručně aktivujete kanál, který jste publikovali v minulém kroku.
Na panelu nástrojů vyberte Přidat aktivační událost a pak vyberte Aktivovat.
Na stránce spuštění procesu vyberte OK.
Přejděte na kartu Monitorování na levé straně. Zobrazí se stav ručně aktivovaného spuštění kanálu. Pomocí odkazů ve sloupci NÁZEV KANÁLU můžete zobrazit podrobnosti o aktivitě a znovu spustit kanál.

Pokud chcete zobrazit spuštění aktivit spojené se spuštěním kanálu, vyberte odkaz CopyPipeline ve sloupci NÁZEV KANÁLU. V tomto příkladu je jenom jedna aktivita, takže v seznamu uvidíte jenom jednu položku. Podrobnosti o operaci kopírování získáte tak, že najedete myší na aktivitu a
ve sloupci NÁZEV AKTIVITY vyberte odkaz Podrobnosti (ikona brýle). Výběrem možnosti Všechny běhy kanálu v horní části se vrátíte do zobrazení Spuštění kanálu. Pokud chcete zobrazení aktualizovat, vyberte Aktualizovat.

Ověřte, že jsou do tabulky emp v databázi přidány dva další řádky.

Aktivace kanálu podle plánu
V tomto kroku vytvoříte pro kanál aktivační událost plánovače. Tato aktivační událost spouští kanál podle zadaného plánu (například každou hodinu nebo každý den). Tady nastavíte trigger tak, aby se spouštěl každou minutu až do zadaného koncového data a času.
Přejděte na kartu Autor na levé straně nad kartou monitoru.
Přejděte do vaší pipeline, na panelu nástrojů vyberte Spoušť a poté zvolte Nový/Upravit.
V dialogovém okně Přidat triggery vyberte Vybrat aktivační událost a vyberte + Nový.
V okně Nový trigger proveďte následující kroky:
a. V části Název zadejte RunEveryMinute.
b) Aktualizujte počáteční datum triggeru. Pokud je datum před aktuálním datem a časem, trigger se začne projevit po publikování změny.
c) V části Časové pásmo vyberte rozevírací seznam.
d. Nastavte opakování na každých 1 minut.
e. Zaškrtněte políčko Zadat koncové datum a aktualizujte část Konec na několik minut po aktuálním datu a čase. Aktivační událost se aktivuje pouze po publikování změn. Pokud nastavíte jenom pár minut od sebe a nepublikujete ho do té míry, nezobrazí se spuštění triggeru.
f. U možnosti Aktivováno vyberte Ano.
gram Vyberte OK.
Důležité
S každým spuštěním kanálu jsou spojené určité náklady, takže nastavte koncové datum správně.
Na stránce Upravit aktivační událost zkontrolujte upozornění a pak vyberte Uložit. Kanál v tomto příkladu nepoužívá žádné parametry.
Výběrem možnosti Publikovat vše publikujte změnu.
Přejděte na kartu Monitor na levé straně a zobrazte spuštěné pipeline.

Pokud chcete přepnout ze zobrazení Spuštění kanálu na zobrazení Spuštění triggerů, vyberte Spuštění triggerů na levé straně okna.
V seznamu se zobrazí spuštění aktivační události.
Ověřte, že do tabulky emp jsou vkládány dva řádky za minutu pro každé spuštění kanálu až do zadaného koncového času.
Zakázání triggeru
Chcete-li zakázat spouštěč, který jste vytvořili a spouští se každou minutu, postupujte takto:
Na levé straně vyberte podokno Spravovat .
V části Autor vyberte Triggery.
Najeďte myší na trigger RunEveryMinute , který jste vytvořili.
- Výběrem tlačítka Zastavit zakažte spuštění triggeru.
- Výběrem tlačítka Odstranit zakažte a odstraňte trigger.
Výběrem možnosti Publikovat vše uložte provedené změny.
Související obsah
Kanál v této ukázce kopíruje data z jednoho umístění do jiného umístění v úložišti Blob Storage. Naučili jste se:
- Vytvoření datové továrny
- Vytvoření kanálu s aktivitou kopírování
- Testovací spuštění kanálu
- Ruční aktivace kanálu
- Aktivace kanálu podle plánu
- Monitorování spuštění aktivit a kanálu
- Zakažte nebo odstraňte naplánovanou aktivační událost.
Přejděte k dalšímu kurzu, kde se naučíte kopírovat data z místního prostředí do cloudu:
Další informace o kopírování dat do nebo z Azure Blob Storage a Azure SQL Database najdete v těchto příručkách ke konektorům: