Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Důležité
Databricks Connect pro Databricks Runtime 12.2 LTS a starší verze je zastaralý. Databricks Runtime 12.2 LTS a všechny starší verze LTS dosáhly konce podpory. Místo toho použijte Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší . Informace o migraci z Databricks Connect pro Databricks Runtime 12.2 LTS a níže na Databricks Connect pro Databricks Runtime 13.3 LTS a novější najdete v tématu Migrace do Databricks Connect pro Python nebo Migrace na Databricks Connect pro Scala.
Databricks Connect umožňuje připojit k clusterům Azure Databricks oblíbené integrované vývojové prostředí, jako jsou Visual Studio Code a PyCharm, servery poznámkových bloků a další vlastní aplikace.
Tento článek vysvětluje, jak Databricks Connect funguje, vás provede postupem, jak začít pracovat s Databricks Connect, vysvětluje, jak řešit problémy, ke kterým může dojít při používání Databricks Connect, a rozdíly mezi spuštěním pomocí Databricks Connect a spuštěním v poznámkovém bloku Azure Databricks.
Přehled
Databricks Connect je klientská knihovna pro Databricks Runtime. Umožňuje psát úlohy pomocí rozhraní Spark API a spouštět je vzdáleně v clusteru Azure Databricks místo v místní relaci Sparku.
Například při spuštění příkazu spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame pomocí Databricks Connect se logické znázornění příkazu odešle na server Spark spuštěný v Azure Databricks za účelem spuštění ve vzdáleném clusteru.
Pomocí Databricks Connect můžete:
- Spouštějte rozsáhlé úlohy Sparku z libovolné aplikace Python, R, Scala nebo Java. Kdekoli můžete
import pyspark,require(SparkR)neboimport org.apache.spark, nyní můžete spouštět úlohy Sparku přímo z aplikace, aniž byste museli instalovat pluginy IDE nebo používat skripty pro odesílání Spark. - Krokujte a ladte kód v integrovaném vývojovém prostředí (IDE) i při práci se vzdáleným clusterem.
- Iterujte rychle při vývoji knihoven. Po změně závislostí knihoven Pythonu nebo Java v Databricks Connect nemusíte cluster restartovat, protože každá klientská relace je izolovaná od sebe v clusteru.
- Vypněte nečinné clustery bez ztráty úloh. Vzhledem k tomu, že je klientská aplikace oddělená od clusteru, nemá to vliv na restartování nebo upgrady clusteru, což by normálně způsobilo ztrátu všech proměnných, sad RDD a objektů datového rámce definovaných v poznámkovém bloku.
Poznámka:
Pro vývoj v Pythonu s využitím dotazů SQL doporučuje Databricks místo Databricks Connect používat konektor SQL Databricks pro Python . Konektor SQL Databricks pro Python je jednodušší nastavit než Databricks Connect. Databricks Connect také analyzuje a plánuje úlohy, které běží na místním počítači, zatímco úlohy běží na vzdálených výpočetních zdrojích. To může obzvláště ztížit odstraňování chyb během běhu. Konektor SQL Databricks pro Python odesílá dotazy SQL přímo do vzdálených výpočetních prostředků a načte výsledky.
Požadavky
Tato část uvádí požadavky pro Databricks Connect.
Podporují se pouze následující verze databricks Runtime:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Na svém vývojovém počítači musíte nainstalovat Python 3 a podverze vaší klientské instalace Pythonu musí být stejná jako podverze verze Pythonu vašeho clusteru Azure Databricks. Následující tabulka uvádí verzi Pythonu nainstalovanou s jednotlivými moduly Databricks Runtime.
Verze modulu Databricks Runtime Verze Pythonu 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3.7 Databricks důrazně doporučuje, abyste pro každou verzi Pythonu, kterou používáte s Databricks Connect, aktivovalo virtuální prostředí Pythonu. Virtuální prostředí Pythonu pomáhají zajistit, abyste společně používali správné verze Pythonu a Databricks Connect. To může pomoct zkrátit dobu strávenou řešením souvisejících technických problémů.
Pokud například ve vývojovém počítači používáte venv a váš cluster používá Python 3.9, musíte vytvořit prostředí s danou
venvverzí. Následující ukázkový příkaz vygeneruje skripty pro aktivacivenvprostředí pomocí Pythonu 3.9 a tento příkaz pak tyto skripty umístí do skryté složky pojmenované.venvv aktuálním pracovním adresáři:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvPokud chcete tyto skripty použít k aktivaci tohoto
venvprostředí, přečtěte si, jak venvs fungují.Pokud jako další příklad používáte Conda na vývojovém počítači a váš cluster používá Python 3.9, musíte vytvořit prostředí Conda s danou verzí, například:
conda create --name dbconnect python=3.9Pokud chcete aktivovat prostředí Conda s tímto názvem prostředí, spusťte
conda activate dbconnectpříkaz .Verze hlavní a vedlejší balíčku Databricks Connect musí vždy odpovídat verzi Databricks Runtime. Databricks doporučuje vždy používat nejnovější balíček Databricks Connect, který odpovídá vaší verzi Databricks Runtime. Pokud například používáte cluster Databricks Runtime 12.2 LTS, musíte také použít balíček
databricks-connect==12.2.*.Poznámka:
Podívejte se na poznámky k vydání Databricks Connect pro seznam dostupných verzí Databricks Connect a aktualizací údržby.
Java Runtime Environment (JRE) 8. Klient byl testován pomocí OpenJDK 8 JRE. Klient nepodporuje Javu 11.
Poznámka:
Pokud se ve Windows zobrazí chyba, že Databricks Connect nemůže najít winutils.exe, přečtěte si téma Nejde najít winutils.exe ve Windows.
Nastavení klienta
Provedením následujících kroků nastavte místního klienta pro Databricks Connect.
Poznámka:
Než začnete nastavovat místního klienta Databricks Connect, musíte splnit požadavky pro Databricks Connect.
Krok 1: Instalace klienta Databricks Connect
Po aktivaci virtuálního prostředí odinstalujte PySpark spuštěním
uninstallpříkazu. To je povinné, protožedatabricks-connectbalíček je v konfliktu s PySpark. Podrobnosti najdete v tématu Konfliktní instalace PySpark. Pokud chcete zkontrolovat, jestli je PySpark už nainstalovaný, spusťteshowpříkaz.# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkPokud je vaše virtuální prostředí stále aktivované, nainstalujte klienta Databricks Connect spuštěním
installpříkazu.--upgradePomocí možnosti upgradujte jakoukoli existující instalaci klienta na zadanou verzi.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Poznámka:
Databricks doporučuje, abyste k
databricks-connect==X.Y.*připojili notaci „dot-asterisk“ místodatabricks-connect=X.Y, abyste měli jistotu, že je nainstalován nejnovější balíček.
Krok 2: Konfigurace vlastností připojení
Shromážděte následující parametry konfigurace.
Adresa URL pro jednotlivé pracovní prostory Azure Databricks. Toto je totožné s
https://, následuje hostname serveru pro váš klastr; Přečtěte si Získání podrobností o připojení pro výpočetní prostředek Azure Databricks.Váš osobní přístupový token Azure Databricks nebo token Microsoft Entra ID (dříve Azure Active Directory).
- Pro předávání přihlašovacích údajů Azure Data Lake Storage (ADLS) musíte použít token ID Microsoft Entra. Předávání přihlašovacích údajů Microsoft Entra ID je podporováno pouze v clusterech úrovně Standard s Databricks Runtime 7.3 LTS a vyšším a není kompatibilní s ověřováním služebního účtu.
- Další informace o ověřování pomocí tokenů ID Microsoft Entra naleznete v tématu Ověřování pomocí tokenů ID Microsoft Entra.
ID vaší klasické výpočetní jednotky. Z adresy URL můžete získat klasické VÝPOČETNÍ ID. Tady je ID
1108-201635-xxxxxxxx. Viz také Adresa URL a ID výpočetního prostředku.
Jedinečné ID organizace pro váš pracovní prostor Viz Získání identifikátorů pro objekty pracovního prostoru.
Port, ke kterému se Databricks Connect připojuje ve vašem clusteru. Výchozí port je
15001. Pokud je váš cluster nakonfigurovaný tak, aby používal jiný port, například8787který byl uveden v předchozích pokynech pro Azure Databricks, použijte nakonfigurované číslo portu.
Následujícím způsobem nakonfigurujte připojení.
Můžete použít rozhraní příkazového řádku, konfigurace SQL nebo proměnné prostředí. Priorita metod konfigurace od nejvyšších po nejnižší je: konfigurační klíče SQL, rozhraní příkazového řádku a proměnné prostředí.
CLI
Spusťte
databricks-connect.databricks-connect configureLicenční text se zobrazí:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Přijměte licenci a zadejte hodnoty konfigurace. V případě hostitele Databricks a tokenu Databricks zadejte adresu URL pracovního prostoru a osobní přístupový token, který jste si poznamenali v kroku 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Pokud se zobrazí zpráva, že token ID Microsoft Entra je příliš dlouhý, můžete ponechat pole Token Databricks prázdné a ručně zadat token do
~/.databricks-connect.
Konfigurace SQL nebo proměnné prostředí Následující tabulka ukazuje konfigurační klíče SQL a proměnné prostředí, které odpovídají vlastnostem konfigurace, které jste si poznamenali v kroku 1. K nastavení konfiguračního klíče SQL použijte
sql("set config=value"). Například:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parametr Konfigurační klíč SQL Název proměnné prostředí Hostitel Databricks spark.databricks.service.address DATABRICKS_ADDRESS Databricks Token spark.databricks.service.token DATABRICKS_API_TOKEN ID clusteru spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID Kód organizace spark.databricks.service.orgId DATABRICKS_ORG_ID Přístav spark.databricks.service.port DATABRICKS_PORT
Pokud je vaše virtuální prostředí stále aktivované, otestujte připojení k Azure Databricks následujícím způsobem.
databricks-connect testPokud není spuštěný cluster, který jste nakonfigurovali, test cluster spustí a zůstane spuštěný, dokud nedosáhne nastavené doby pro automatické ukončení. Výstup by měl vypadat zhruba takto:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiPokud se nezobrazí žádné chyby související s připojením (
WARNzprávy jsou v pořádku), pak jste se úspěšně připojili.
Použití Databricks Connect
Tato část popisuje, jak nakonfigurovat preferované IDE nebo server poznámkového bloku tak, aby používal klienta pro Databricks Connect.
V této části:
- JupyterLab
- Klasický poznámkový blok Jupyter
- PyCharm
- SparkR a RStudio Desktop
- sparklyr a RStudio Desktop
- IntelliJ (Scala nebo Java)
- PyDev v Eclipse
- Zatmění
- SBT
- Spark shell
JupyterLab
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete používat Databricks Connect s JupyterLabem a Pythonem, postupujte podle těchto pokynů.
Pokud chcete nainstalovat JupyterLab s aktivovaným virtuálním prostředím Pythonu, spusťte z terminálu nebo příkazového řádku následující příkaz:
pip3 install jupyterlabPokud chcete spustit JupyterLab ve webovém prohlížeči, spusťte z aktivovaného virtuálního prostředí Pythonu následující příkaz:
jupyter labPokud se JupyterLab nezobrazí ve webovém prohlížeči, zkopírujte adresu URL, která začíná vaším virtuálním prostředím
localhost,127.0.0.1a zadejte ji do adresního řádku webového prohlížeče.Vytvořte nový notebook: v JupyterLabu klikněte na Soubor > Nový > Notebook v hlavní nabídce, vyberte Python 3 (ipykernel) a klikněte na Vybrat.
Do první buňky poznámkového bloku zadejte ukázkový kód nebo vlastní kód. Pokud používáte vlastní kód, musíte alespoň vytvořit instanci instance
SparkSession.builder.getOrCreate(), jak je znázorněno v ukázkovém kódu.Pokud chcete poznámkový blok spustit, klikněte na Spustit > Spustit všechny buňky.
Pokud chcete ladit poznámkový blok, klikněte na ikonu brouka (Povolit ladící nástroj) vedle Python 3 (ipykernel) na panelu nástrojů poznámkového bloku. Nastavte jeden nebo více bodů přerušení a potom klikněte na Spustit > Spustit všechny buňky.
Chcete-li vypnout JupyterLab, klepněte na tlačítko Soubor > vypnout. Pokud proces JupyterLab stále běží v terminálu nebo příkazovém řádku, ukončete tento proces stisknutím
Ctrl + ca zadáním potvrďtey.
Konkrétnější pokyny pro ladění najdete v tématu Debugger.
Klasický poznámkový blok Jupyter
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Konfigurační skript pro Databricks Connect automaticky přidá balíček do konfigurace projektu. Pokud chcete začít v jádru Pythonu, spusťte:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Pokud chcete povolit zkratku %sql pro spouštění a vizualizaci dotazů SQL, použijte následující fragment kódu:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete použít Databricks Connect se sadou Visual Studio Code, postupujte takto:
Ověřte, že je nainstalované rozšíření Pythonu.
Otevřete paletu příkazů (Command+Shift+P v macOS a Ctrl+Shift+P ve Windows/Linuxu).
Vyberte interpret Pythonu. Přejděte do > předvoleb > kódu a zvolte nastavení Pythonu.
Spusťte
databricks-connect get-jar-dir.Přidejte adresář vrácený příkazem do JSON nastavení uživatele v části
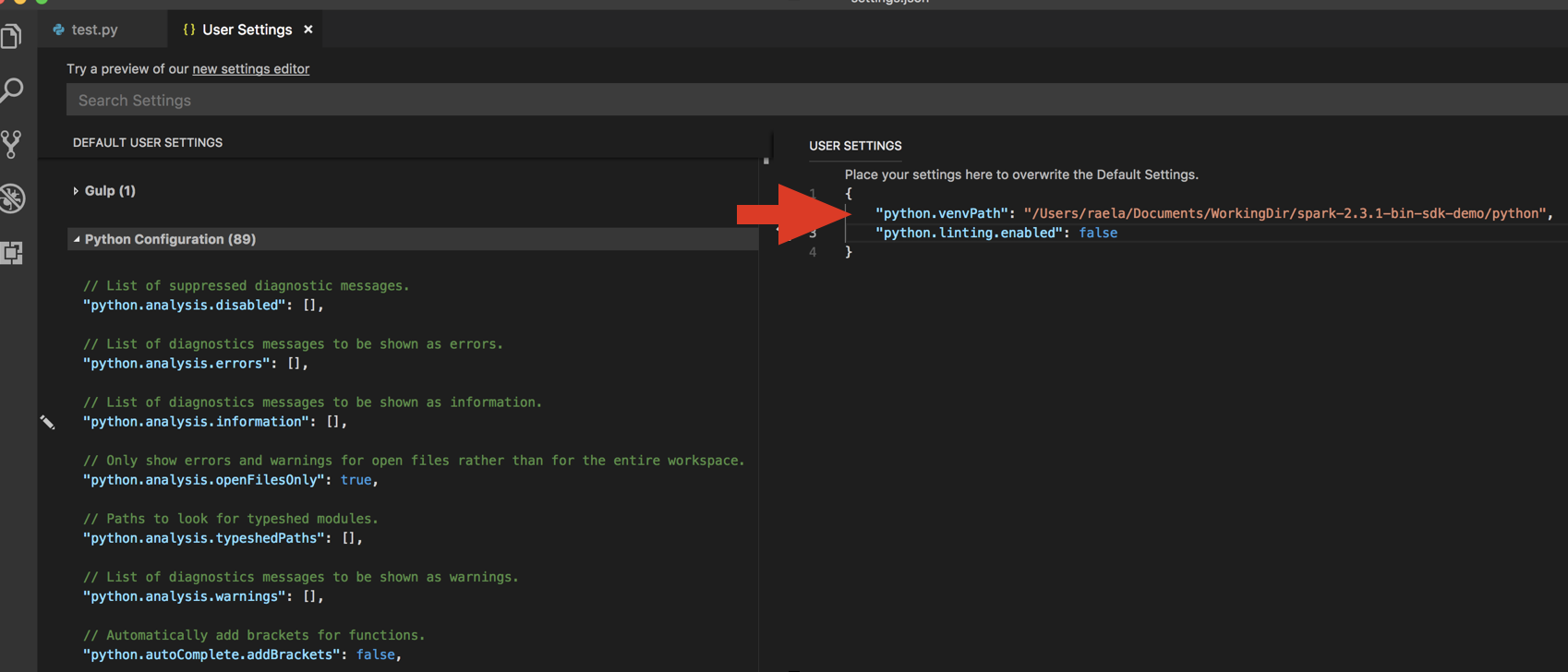
python.venvPath. Tato možnost by se měla přidat do konfigurace Pythonu.Zakažte linter. Klikněte na ... na pravé straně a upravte nastavení JSON. Upravená nastavení jsou následující:
Pokud běžíte ve virtuálním prostředí, což je doporučený způsob vývoje pro Python ve VS Code, v Paletě příkazů zadejte
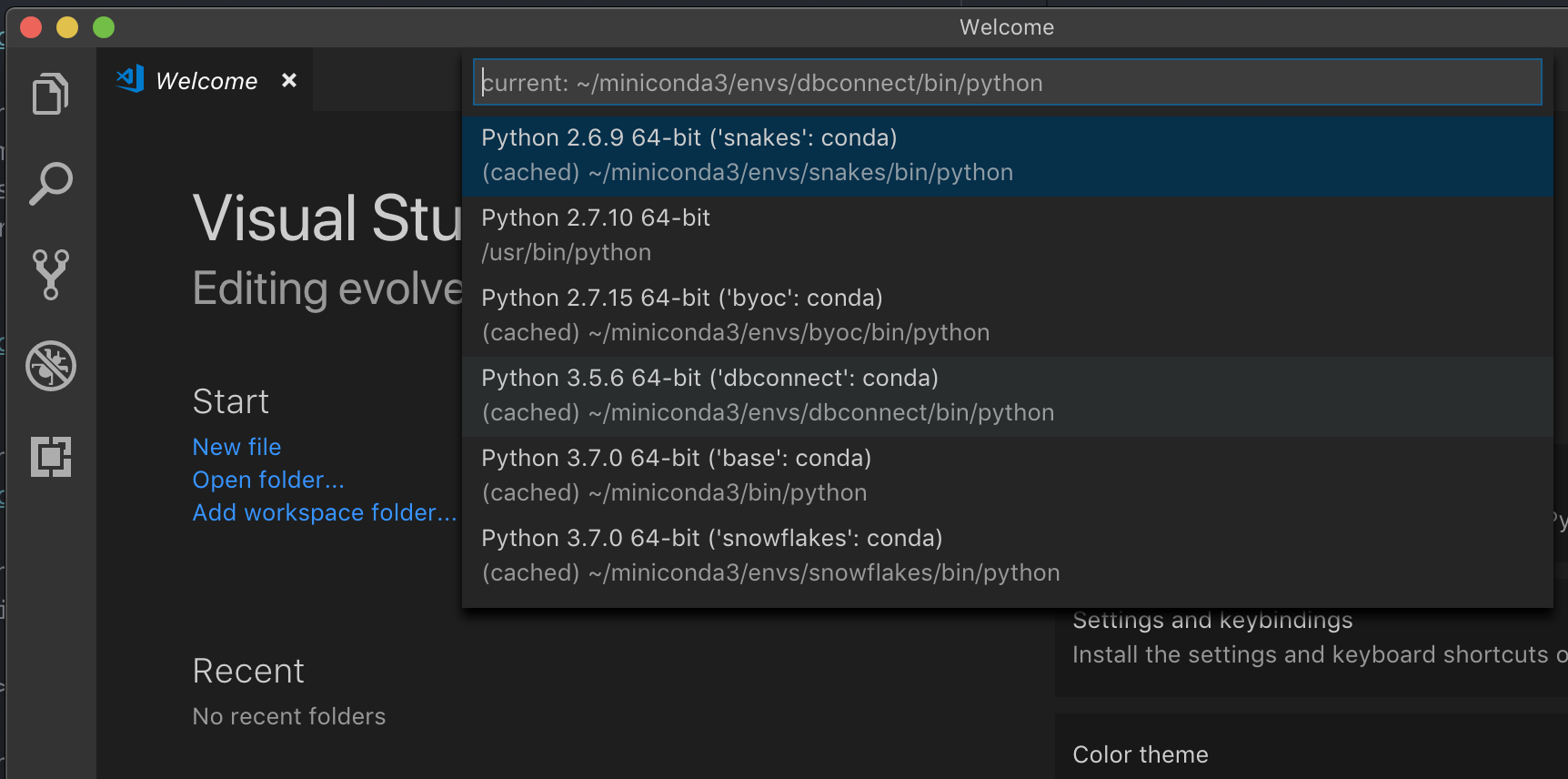
select python interpretera nasměrujte na prostředí, které odpovídá verzi Pythonu ve vašem clusteru.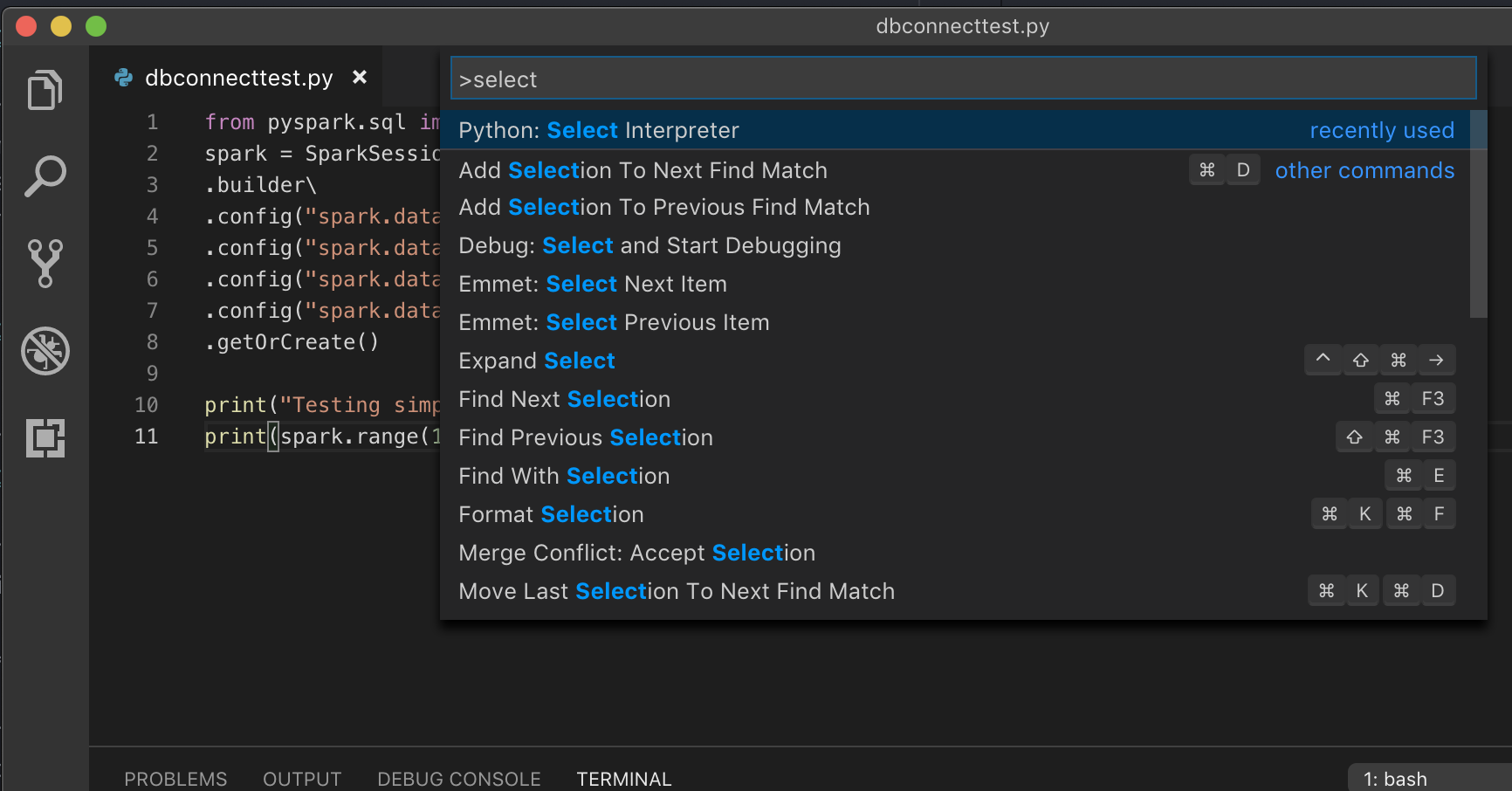
Pokud je váš cluster například Python 3.9, vaše vývojové prostředí by mělo být Python 3.9.
PyCharm
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Konfigurační skript pro Databricks Connect automaticky přidá balíček do konfigurace projektu.
Klastry Python 3
Při vytváření projektu PyCharm vyberte Existující interpret. V rozevírací nabídce vyberte prostředí Conda, které jste vytvořili (viz Požadavky).
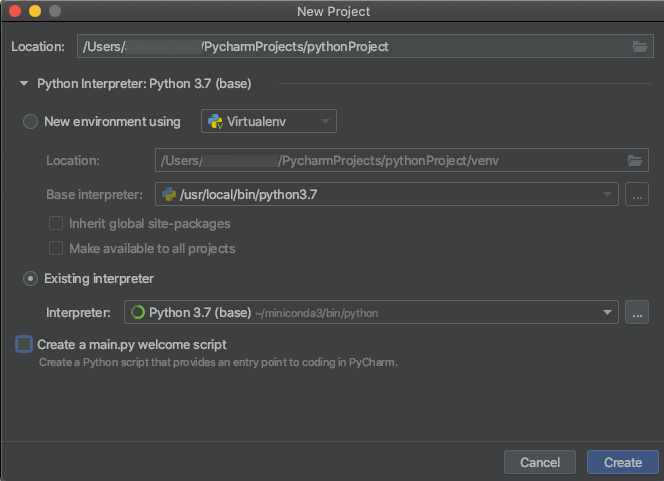
Přejděte do Spustit > Úpravy konfigurací.
Přidejte
PYSPARK_PYTHON=python3jako proměnnou prostředí.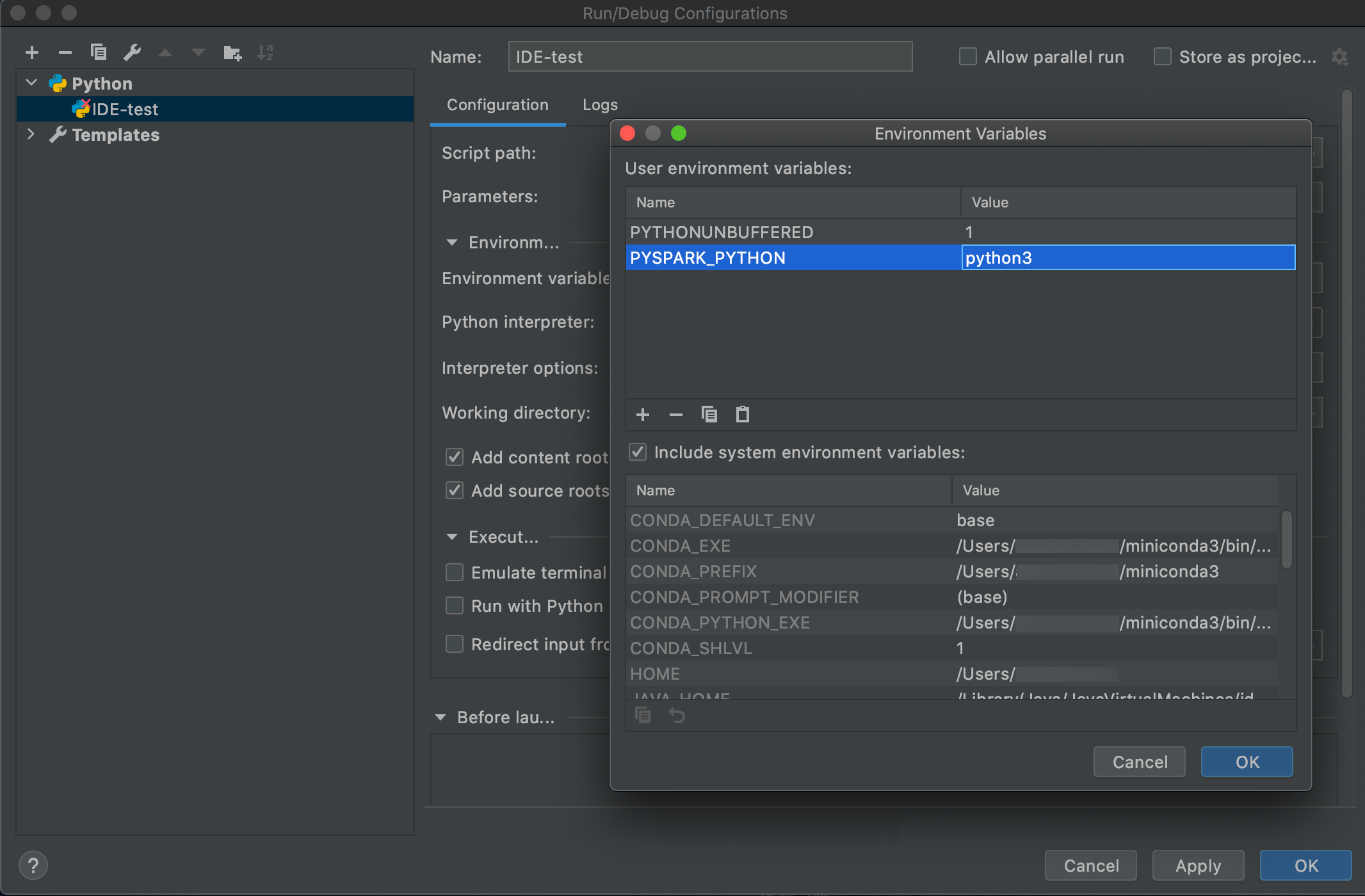
SparkR a RStudio Desktop
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete používat Databricks Connect se SparkR a RStudio Desktopem, postupujte takto:
Stáhněte a rozbalte opensourcovou distribuci Sparku do vývojového počítače. Zvolte stejnou verzi jako v clusteru Azure Databricks (Hadoop 2.7).
Spusťte
databricks-connect get-jar-dir. Tento příkaz vrátí cestu jako/usr/local/lib/python3.5/dist-packages/pyspark/jars. Zkopírujte cestu jednoho adresáře nad cestou k souboru JAR, například/usr/local/lib/python3.5/dist-packages/pyspark, což jeSPARK_HOMEadresář.Nakonfigurujte cestu knihovny Spark a domovskou stránku Sparku tak, že je přidáte na začátek skriptu R. Nastavte
<spark-lib-path>do adresáře, do kterého jste rozbalili opensourcový balíček Spark v kroku 1. Nastavte<spark-home-path>do adresáře Databricks Connect z kroku 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Zahajte relaci Sparku a začněte spouštět příkazy SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr a RStudio Desktop
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Důležité
Tato funkce je ve verzi Public Preview.
Můžete zkopírovat kód závislý na sparklyr, který jste vyvinuli místně pomocí Databricks Connect, a spustit ho v poznámkovém bloku Azure Databricks nebo na hostovaném serveru RStudio ve vašem pracovním prostoru Azure Databricks s minimálními nebo žádnými změnami kódu.
V této části:
Požadavky
- sparklyr 1.2 nebo vyšší.
- Databricks Runtime 7.3 LTS nebo vyšší s odpovídající verzí Databricks Connect.
Instalace, konfigurace a používání sparklyru
V RStudio Desktopu nainstalujte sparklyr 1.2 nebo novější z CRAN nebo nainstalujte nejnovější hlavní verzi z GitHubu.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Aktivujte prostředí Pythonu s nainstalovanou správnou verzí Databricks Connect a spuštěním následujícího příkazu v terminálu získejte
<spark-home-path>:databricks-connect get-spark-homeSpusťte relaci Spark a spusťte příkazy sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countZavřete připojení.
spark_disconnect(sc)
Zdroje informací
Další informace najdete v README repozitáři GitHubu sparklyr.
Příklady kódu najdete v tématu sparklyr.
omezení sparklyr a RStudio Desktop
Následující funkce nejsou podporovány:
- sparklyr streaming API
- sparklyr ML APIe
- rozhraní API broom
- csv_file režim serializace
- Spark submit
IntelliJ (Scala nebo Java)
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete použít Databricks Connect s IntelliJ (Scala nebo Java), postupujte takto:
Spusťte
databricks-connect get-jar-dir.Nasměrujte závislosti na adresář vrácený příkazem. Přejděte do souborů > struktury projektu > modulů > závislostí > znaménko '+' > souborů JAR nebo adresářů.
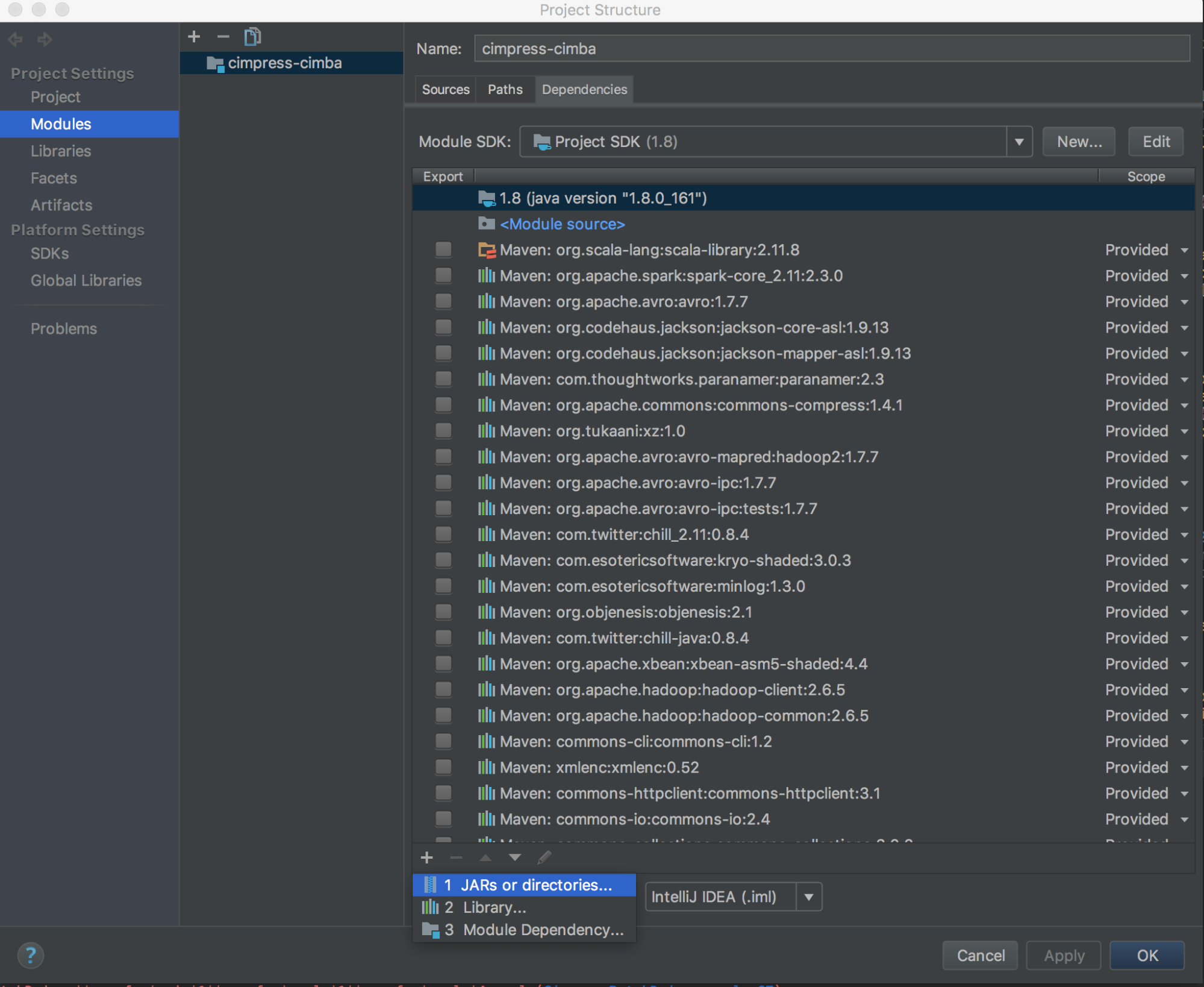
Abyste se vyhnuli konfliktům, důrazně doporučujeme odebrat z classpathu všechny ostatní instalace Sparku. Pokud to není možné, ujistěte se, že JARy, které přidáte, jsou na začátku cesty ke třídě. Konkrétně musí být před jakoukoli jinou nainstalovanou verzí Sparku (jinak použijete některou z těchto ostatních verzí Sparku, spustíte ji místně nebo vyvoláte
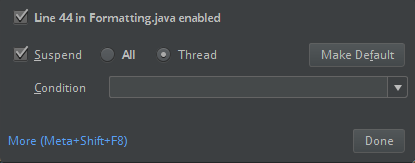
ClassDefNotFoundError).Zkontrolujte nastavení možnosti breakoutu v IntelliJ. Výchozí hodnota je Vše a způsobí selhání sítě z důvodu vypršení časového limitu, pokud nastavíte body přerušení při ladění. Nastavte ho na Vlákno, aby se zabránilo zastavení síťových vláken na pozadí.
PyDev v Eclipse
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete používat Databricks Connect a PyDev s Eclipse, postupujte podle těchto pokynů.
- Spusťte Eclipse.
- Vytvořte projekt: klikněte na Soubor > Nový > Projekt > PyDev > PyDev projekt, a potom klikněte na Další.
- Zadejte název projektu.
- V případě obsahu Projectu zadejte cestu k vašemu virtuálnímu prostředí Pythonu.
- Klikněte na Prosím, nakonfigurujte interpret, než budete pokračovat.
- Klepněte na tlačítko Ruční konfigurace.
- Klepněte na Nový > a procházejte nebo vyberte soubor exe python/pypy.
- Vyhledejte a vyberte úplnou cestu k interpretu Pythonu, na který odkazuje virtuální prostředí, a potom klikněte na Otevřít.
- V dialogovém okně Vyberte interpreta klepněte na tlačítko OK.
- V dialogovém okně Výběr je třeba klepněte na tlačítko OK.
- V dialogovém okně Předvolby klikněte na Použít a zavřít.
- V dialogovém okně Projekt PyDev klepněte na tlačítko Dokončit.
- Klikněte na Otevřít perspektivu.
- Přidejte do projektu soubor kódu Pythonu (
.py), který obsahuje ukázkový kód nebo vlastní kód. Pokud používáte vlastní kód, musíte alespoň vytvořit instanci instanceSparkSession.builder.getOrCreate(), jak je znázorněno v ukázkovém kódu. - Když máte otevřený soubor kódu Pythonu, nastavte všechny zarážky, u kterých chcete, aby se kód při spuštění pozastavil.
- Klikněte na Spustit > spuštění nebo Spustit > ladění.
Konkrétnější pokyny ke spuštění a ladění najdete v tématu Spuštění programu.
Eclipse
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete použít Databricks Connect a Eclipse, postupujte takto:
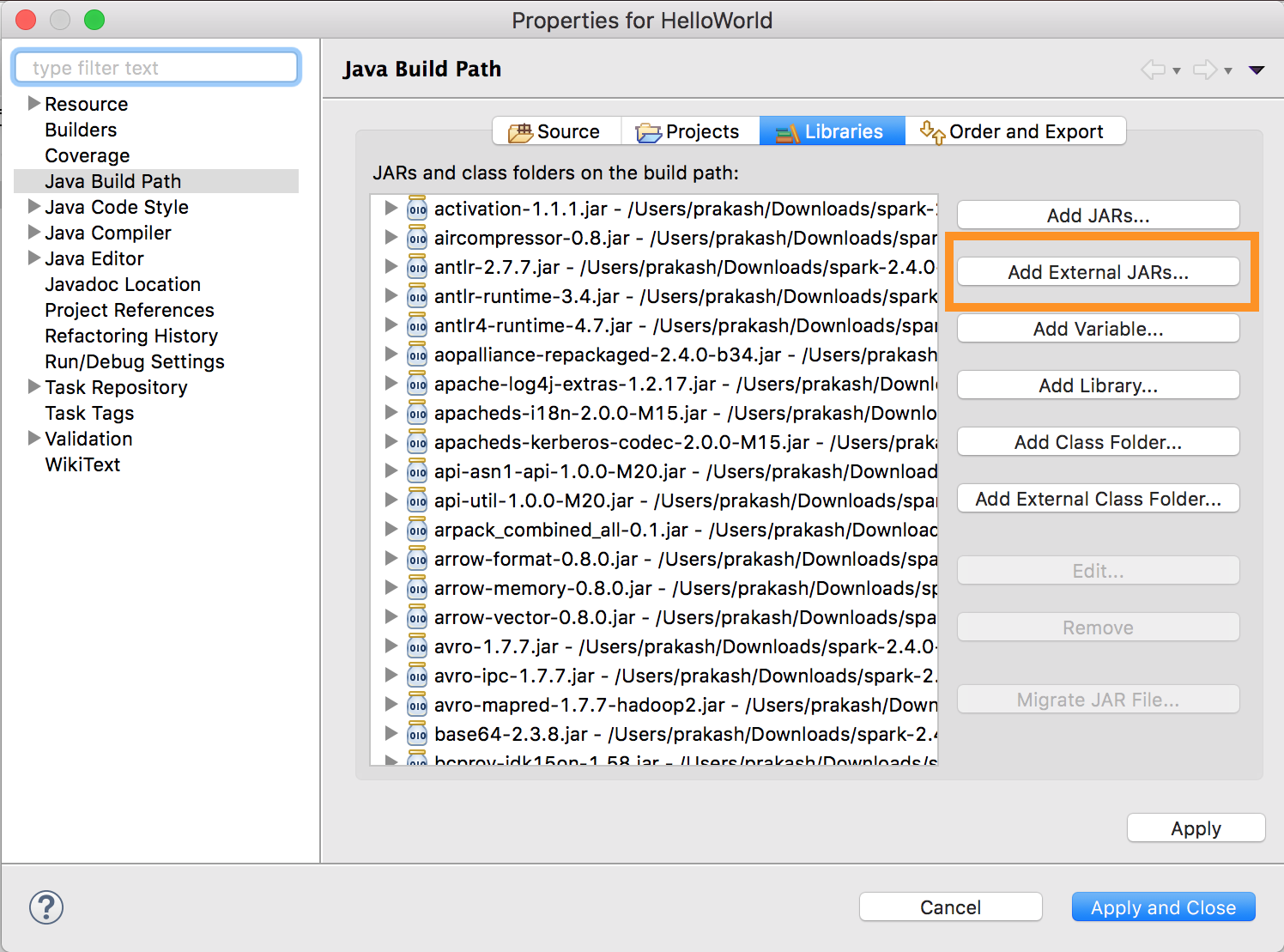
Spusťte
databricks-connect get-jar-dir.Nasměrujte externí konfiguraci jars na adresář vrácený příkazem. Přejděte do nabídky > Projekt -> Vlastnosti > Java Build Path > Knihovny > Přidat externí JARy.
Abyste se vyhnuli konfliktům, důrazně doporučujeme odebrat z classpathu všechny ostatní instalace Sparku. Pokud to není možné, ujistěte se, že JARy, které přidáte, jsou na začátku cesty ke třídě. Konkrétně musí být před jakoukoli jinou nainstalovanou verzí Sparku (jinak použijete některou z těchto ostatních verzí Sparku, spustíte ji místně nebo vyvoláte
ClassDefNotFoundError).
SBT
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete použít Databricks Connect s SBT, musíte nakonfigurovat soubor build.sbt, aby odkazoval na Databricks Connect JARs namísto obvyklé závislosti knihovny Spark. Provedete to pomocí direktivy unmanagedBase v následujícím ukázkovém souboru sestavení, který předpokládá aplikaci Scala, která má com.example.Test hlavní objekt:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Prostředí Sparku
Poznámka:
Než začnete používat Databricks Connect, musíte splnit požadavky a nastavit klienta pro Databricks Connect.
Pokud chcete použít Databricks Connect s prostředím Spark a Pythonem nebo Scalou, postupujte podle těchto pokynů.
Po aktivaci virtuálního prostředí se ujistěte, že se příkaz
databricks-connect testúspěšně spustil v Nastaveníklienta .S aktivovaným virtuálním prostředím spusťte prostředí Spark. V případě Pythonu
pysparkspusťte příkaz. V případě Scaly spusťtespark-shellpříkaz.# For Python: pyspark# For Scala: spark-shellZobrazí se prostředí Spark, například pro Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Pro Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>-
Použijte předdefinované
sparkproměnné k reprezentaciSparkSessionspuštěného clusteru, například pro Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsPro Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rows Pokud chcete prostředí Spark zastavit, stiskněte
Ctrl + dneboCtrl + znebo spusťte příkazquit()neboexit()pro Python nebo:q:quitjazyk Scala.
Příklady kódu
Tento jednoduchý příklad kódu dotazuje zadanou tabulku a pak zobrazí prvních 5 řádků zadané tabulky. Pokud chcete použít jinou tabulku, upravte volání na spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Tento delší příklad kódu dělá toto:
- Vytvoří datový rámec v paměti.
- Vytvoří tabulku s názvem
zzz_demo_temps_tableve schématudefault. Pokud tabulka s tímto názvem již existuje, tabulka se nejprve odstraní. Pokud chcete použít jiné schéma nebo tabulku, upravte voláníspark.sql,temps.write.saveAsTable, nebo obojí. - Uloží obsah datového rámce do tabulky.
-
SELECTSpustí dotaz na obsah tabulky. - Zobrazí výsledek dotazu.
- Odstraní tabulku.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Práce se závislostmi
Hlavní třída nebo soubor Pythonu obvykle budou obsahovat další závislosti JARs a soubory. Takové závislosti JAR a soubory můžete přidat voláním sparkContext.addJar("path-to-the-jar") nebo sparkContext.addPyFile("path-to-the-file"). Pomocí rozhraní můžete také přidat soubory Egg a soubory addPyFile() ZIP. Když pokaždé spustíte kód ve svém integrovaném vývojovém prostředí, nainstalují se do clusteru JAR soubory a ostatní soubory závislostí.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Uživatelem definované funkce Pythonu a Javy
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Přístup k nástrojům Databricks
Tato část popisuje, jak používat Databricks Connect pro přístup k nástrojům Databricks.
Referenční modul dbutils.fs můžete použít k použití nástrojů dbutils.secrets a dbutils.
Podporované příkazy jsou dbutils.fs.cp, , dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirsdbutils.fs.mvdbutils.fs.putdbutils.fs.rmdbutils.secrets.getdbutils.secrets.getBytes, dbutils.secrets.list, . dbutils.secrets.listScopes
Viz nástroj systému souborů (dbutils.fs) nebo spusťte dbutils.fs.help() nástroj Tajné kódy (dbutils.secrets) nebo spusťte dbutils.secrets.help().
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Pokud používáte Databricks Runtime 7.3 LTS nebo novější, pro přístup k modulu DBUtils způsobem, který funguje místně i v clusterech Azure Databricks, použijte následující get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
V opačném případě použijte následující get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Kopírování souborů mezi místními a vzdálenými systémy souborů
Můžete použít dbutils.fs ke kopírování souborů mezi klientem a vzdálenými systémy souborů. Schéma file:/ odkazuje na místní systém souborů v klientovi.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Maximální velikost souboru, kterou lze tímto způsobem přenést, je 250 MB.
Povolte dbutils.secrets.get.
Kvůli omezením zabezpečení je možnost volání dbutils.secrets.get ve výchozím nastavení zakázaná. Pokud chcete tuto funkci pro váš pracovní prostor povolit, obraťte se na podporu Azure Databricks.
Nastavení konfigurací Hadoopu
Na klientovi můžete nastavit konfigurace Hadoop pomocí rozhraní spark.conf.set API, které platí pro operace SQL a DataFrame. Konfigurace Hadoopu nastavené na sparkContext musí být nastaveny v konfiguraci clusteru nebo pomocí poznámkového bloku. Důvodem je to, že konfigurace nastavené na sparkContext nejsou svázané s uživatelskými relacemi, ale vztahují se na celý cluster.
Řešení problému
Spusťte databricks-connect test, abyste zkontrolovali problémy s připojením. Tato část popisuje některé běžné problémy, se kterými se můžete setkat se službou Databricks Connect a jak je vyřešit.
V této části:
- Neshoda verzí Pythonu
- Server není povolený
- Konfliktní instalace PySparku
-
Konfliktní
SPARK_HOME -
Konfliktní nebo chybějící
PATHpoložka pro binární soubory - Konfliktní nastavení serializace v clusteru
-
Ve Windows nejde najít
winutils.exe - Syntaxe názvu souboru, názvu adresáře nebo popisku svazku ve Windows je nesprávná.
Neshoda verzí Pythonu
Zkontrolujte, jestli verze Pythonu, kterou používáte místně, má alespoň stejnou podverzi jako verze v clusteru (například 3.9.16 versus 3.9.15 je OK, nebo 3.9 versus 3.8 ne).
Pokud máte místně nainstalovaných více verzí Pythonu, ujistěte se, že Databricks Connect používá správnou verzi, a to nastavením PYSPARK_PYTHON proměnné prostředí (například PYSPARK_PYTHON=python3).
Server není povolený
Ujistěte se, že cluster má povolený server Spark s spark.databricks.service.server.enabled true. V protokolu ovladačů by se měly zobrazit následující řádky, pokud se jedná o:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Konfliktní instalace PySpark
Balíček databricks-connect je v konfliktu s PySpark. Obě instalace způsobí chyby při inicializaci kontextu Sparku v Pythonu. To se může projevit několika způsoby, včetně chyb "stream poškozený" nebo "třída nenalezena". Pokud máte v prostředí Pythonu nainstalovaný PySpark, před instalací databricks-connect se ujistěte, že je odinstalovaný. Po odinstalaci PySpark nezapomeňte plně znovu nainstalovat balíček Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Konfliktní SPARK_HOME
Pokud jste na svém počítači dříve použili Spark, je možné, že integrované vývojové prostředí (IDE) použije některou z těchto dalších verzí Sparku místo Sparku Databricks Connect. To se může projevit několika způsoby, včetně chyb "stream poškozený" nebo "třída nenalezena". Podívejte se, jakou verzi Sparku používáte, a to tak, že zkontrolujete hodnotu SPARK_HOME proměnné prostředí:
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Rozlišení
Pokud je SPARK_HOME nastavená na jinou verzi Sparku, než je verze v klientovi, měli byste zrušit nastavení proměnné SPARK_HOME a zkusit to znovu.
Zkontrolujte nastavení proměnných prostředí v prostředí IDE, ve skriptech nebo souborech .bashrc, .zshrcnebo .bash_profile, a na všech dalších místech, kde mohou být proměnné prostředí nastaveny. Pravděpodobně budete muset ukončit a restartovat integrované vývojové prostředí ,aby se vyprázdnil starý stav, a pokud problém přetrvává, budete možná muset vytvořit nový projekt.
Neměli byste nastavovat SPARK_HOME na novou hodnotu; zrušení jeho nastavení by mělo být dostačující.
Konfliktní nebo chybějící PATH položka pro binární soubory
Je možné, že je vaše cesta nakonfigurovaná tak, aby příkazy spark-shell jako spouštěly některé jiné dříve nainstalované binární soubory místo těch, které jsou součástí Databricks Connect. To může způsobit selhání databricks-connect test. Měli byste se ujistit, že binární soubory Databricks Connect mají přednost, nebo odeberte dříve nainstalované binární soubory.
Pokud nemůžete spouštět příkazy, jako je spark-shell, je také možné, že PATH nebyla automaticky nastavena pip3 install a budete muset přidat instalační adresář bin do PATH ručně. Databricks Connect s IDEs je možné použít i v případě, že to není nastavené.
databricks-connect test Příkaz ale nebude fungovat.
Konfliktní nastavení serializace v clusteru
Pokud se při spuštění databricks-connect test zobrazí chyby "poškozený datový proud", může to být způsobeno nekompatibilními konfiguracemi serializace clusteru. Například nastavení spark.io.compression.codec konfigurace může způsobit tento problém. Pokud chcete tento problém vyřešit, zvažte odebrání těchto konfigurací z nastavení clusteru nebo nastavení konfigurace v klientovi Databricks Connect.
Ve Windows nejde najít winutils.exe
Pokud používáte Databricks Connect ve Windows a podívejte se na:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Podle pokynů nakonfigurujte cestu Hadoop ve Windows.
Syntaxe názvu souboru, názvu adresáře nebo popisku svazku ve Windows je nesprávná.
Pokud používáte Windows a Databricks Connect a podívejte se na:
The filename, directory name, or volume label syntax is incorrect.
Java nebo Databricks Connect byly nainstalovány do adresáře s mezerou v cestě. Můžete to obejít tak, že buď nainstalujete do cesty k adresáři bez mezer, nebo nakonfigurujete cestu pomocí krátkého názvu.
Ověřování pomocí tokenů MICROSOFT Entra ID
Poznámka:
Následující informace platí jenom pro Databricks Connect verze 7.3.5 až 12.2.x.
Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší v současné době nepodporuje tokeny ID Microsoft Entra.
Pokud používáte Databricks Connect verze 7.3.5 až 12.2.x, můžete se ověřit pomocí tokenu MICROSOFT Entra ID místo osobního přístupového tokenu. Tokeny ID Microsoft Entra mají omezenou životnost. Když vyprší platnost tokenu ID Microsoft Entra, databricks Connect selže s chybou Invalid Token .
Pro Databricks Connect verze 7.3.5 až 12.2.x můžete zadat token ID Microsoft Entra ve spuštěné aplikaci Databricks Connect. Vaše aplikace potřebuje získat nový přístupový token a nastavit ho na spark.databricks.service.token konfigurační klíč SQL.
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Po aktualizaci tokenu může aplikace dál používat stejné SparkSession a všechny objekty a stav vytvořené v kontextu relace. Aby nedocházelo k přerušovaným chybám, databricks doporučuje zadat nový token před vypršením platnosti starého tokenu.
Životnost tokenu Microsoft Entra ID můžete prodloužit tak, aby se zachovala během provádění aplikace. Uděláte to tak, že k autorizační aplikaci Microsoft Entra ID, kterou jste použili k získání přístupového tokenu, připojte tokenLifetimePolicy s odpovídajícím způsobem dlouhou životností.
Poznámka:
Microsoft Entra ID passthrough používá dva tokeny: přístupový token Microsoft Entra ID, který byl dříve popsán ve verzích Databricks Connect 7.3.5 až 12.2.x, a token pro ADLS passthrough pro konkrétní prostředek, který Databricks generuje při zpracování požadavku. Životnost passthrough tokenů ADLS se nedá prodloužit pomocí zásad životnosti tokenů Microsoft Entra ID. Pokud odešlete příkaz do clusteru, který trvá déle než hodinu, selže, pokud po uplynutí této doby přistupuje k prostředku ADLS.
Omezení
- Strukturované streamování
- Spuštění libovolného kódu, který není součástí úlohy Sparku ve vzdáleném clusteru
- Nativní rozhraní SCALA, Python a R API pro operace tabulky Delta (například
DeltaTable.forPath) se nepodporují. Podporuje se však rozhraní SQL API (spark.sql(...)) s operacemi Delta Lake a rozhraním Spark API (napříkladspark.read.load) v tabulkách Delta. - Zkopírujte do.
- Použití funkcí SQL, funkcí Pythonu nebo UDF Scala, které jsou součástí katalogu serveru. Místně zavedené funkce Scala a Python však fungují.
- Apache Zeppelin 0.7.x a novější.
- , Připojení ke clusterům pomocí řízení přístupu k tabulkám.
- Připojení ke clusterům s povolenou izolací procesů (jinými slovy, kde
spark.databricks.pyspark.enableProcessIsolationje nastavená natrue). - Příkaz Delta
CLONESQL - Globální dočasné pohledy
-
Koalas a
pyspark.pandas. -
CREATE TABLE table AS SELECT ...Příkazy SQL nefungují vždy. Místo toho použijtespark.sql("SELECT ...").write.saveAsTable("table").
- Předávání přihlašovacích údajů Microsoft Entra ID je podporováno pouze na standardních clusterech s modulem Databricks Runtime 7.3 LTS a novějším a není kompatibilní s ověřováním služebního principu.
- Následující referenční informace k nástrojům Databricks
dbutils: