Přístup k Azure Data Lake Storage pomocí Microsoft Entra ID (dříve předávání přihlašovacích údajů Azure Active Directory) (starší verze)
Důležité
Tato dokumentace byla vyřazena a nemusí být aktualizována.
Předávání přihlašovacích údajů je zastaralé od Databricks Runtime 15.0 a bude odebráno v budoucích verzích Databricks Runtime. Společnost Databricks doporučuje upgradovat na katalog Unity. Katalog Unity zjednodušuje zabezpečení a zásady správného řízení vašich dat tím, že poskytuje centrální místo pro správu a auditování přístupu k datům ve více pracovních prostorech ve vašem účtu. Viz téma Co je katalog Unity?.
Pokud chcete zvýšení stavu zabezpečení a zásad správného řízení, obraťte se na tým účtu Azure Databricks a zakažte předávání přihlašovacích údajů ve vašem účtu Azure Databricks.
Poznámka:
Tento článek obsahuje odkazy na termín povolený, termín, který Azure Databricks nepoužívá. Až bude tento termín ze softwaru odstraněn, odstraníme ho i z tohoto článku.
K automatickému ověření přístupu ke službě Azure Data Lake Storage Gen1 z Azure Databricks (ADLS Gen1) a ADLS Gen2 z clusterů Azure Databricks můžete použít stejnou identitu Microsoft Entra ID (dříve Azure Active Directory), kterou používáte pro přihlášení k Azure Databricks. Když povolíte předávání přihlašovacích údajů služby Azure Data Lake Storage pro váš cluster, příkazy, které v clusteru spustíte, můžou číst a zapisovat data ve službě Azure Data Lake Storage, aniž byste museli nakonfigurovat přihlašovací údaje instančního objektu pro přístup k úložišti.
Předávání přihlašovacích údajů Azure Data Lake Storage je podporováno jen u Azure Data Lake Storage Gen1 a Gen2. Azure Blob Storage předávání přihlašovacích údajů nepodporuje.
Tento článek se věnuje následujícím tématům:
- Povolení předávání přihlašovacích údajů pro standardní clustery a clustery s vysokou souběžností
- Konfigurace předávání přihlašovacích údajů a inicializace prostředků úložiště v účtech ADLS
- Přístup k prostředkům ADLS přímo při povolení předávání přihlašovacích údajů
- Přístup k prostředkům ADLS prostřednictvím přípojného bodu při povolení předávání přihlašovacích údajů
- Podporované funkce a omezení při používání předávání přihlašovacích údajů
Poznámkové bloky obsahují příklady použití předávání přihlašovacích údajů s účty úložiště ADLS Gen1 a ADLS Gen2.
Požadavky
- Plán Premium. Podrobnosti o upgradu plánu Standard na plán Premium najdete v článku Upgrade nebo downgrade pracovního prostoru Azure Databricks.
- Účet úložiště Azure Data Lake Storage Gen1 nebo Gen2. Účty úložiště Azure Data Lake Storage Gen2 musí používat hierarchický obor názvů, aby předávání přihlašovacích údajů Azure Data Lake Storage fungovalo. Pokyny k vytvoření nového účtu ADLS Gen2 včetně postupu povolení hierarchického oboru názvů najdete v článku Vytvoření účtu úložiště.
- Správně nakonfigurovaná uživatelská oprávnění pro Azure Data Lake Storage. Správce Azure Databricks musí zajistit, aby uživatelé měli správné role, například Přispěvatel dat objektů blob služby Storage, ke čtení a zápisu dat uložených ve službě Azure Data Lake Storage. Viz Přiřazení role Azure pro přístup k datům objektů blob a front pomocí webu Azure Portal.
- Seznamte se s oprávněními správců pracovního prostoru v pracovních prostorech, které jsou povolené pro předávání, a zkontrolujte stávající přiřazení správců pracovního prostoru. Správci pracovních prostorů můžou spravovat operace pro svůj pracovní prostor, včetně přidávání uživatelů a instančních objektů, vytváření clusterů a delegování dalších uživatelů jako správců pracovních prostorů. Úlohy správy pracovních prostorů, jako je správa vlastnictví úloh a prohlížení poznámkových bloků, můžou udělit nepřímý přístup k datům registrovaným ve službě Azure Data Lake Storage. Správce pracovního prostoru je privilegovaná role, kterou byste měli pečlivě distribuovat.
- Cluster nakonfigurovaný s přihlašovacími údaji ADLS, například přihlašovacími údaji instančního objektu, s předáváním přihlašovacích údajů nemůžete použít.
Důležité
Pokud se nacházíte za bránou firewall, která není nakonfigurovaná tak, aby povolovala provoz do Microsoft Entra ID, nemůžete se ověřit ve službě Azure Data Lake Storage pomocí přihlašovacích údajů Microsoft Entra ID. Azure Firewall standardně blokuje přístup ke službě Active Directory. Pokud chcete povolit přístup, nakonfigurujte značku služby AzureActiveDirectory. Ekvivalentní informace o síťových virtuálních zařízeních najdete pod značkou AzureActiveDirectory v souboru JSON rozsahů IP adres Azure a značek služeb. Další informace najdete v článku Značky služby Azure Firewall a IP adresy Azure pro veřejný cloud.
Doporučení pro protokolování
Identity předávané do úložiště ADLS můžete protokolovat v diagnostických protokolech úložiště Azure. Protokolování identit umožňuje, aby požadavky ADLS byly svázané s jednotlivými uživateli z clusterů Azure Databricks. Zapněte protokolování diagnostiky účtu úložiště a začněte přijímat tyto protokoly:
- Azure Data Lake Storage Gen1: Postupujte podle pokynů v tématu Povolení protokolování diagnostiky pro váš účet Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2: Konfigurace pomocí PowerShellu
Set-AzStorageServiceLoggingPropertypomocí příkazu Jako verzi zadejte hodnotu 2.0, protože položka protokolu ve formátu 2.0 obsahuje v požadavku hlavní název uživatele.
Povolení předávání přihlašovacích údajů služby Azure Data Lake Storage pro cluster s vysokou souběžností
Clustery s vysokou souběžností můžou sdílet více uživatelů. Podporují pouze Python a SQL s předáváním přihlašovacích údajů azure Data Lake Storage.
Důležité
Povolení předávání přihlašovacích údajů služby Azure Data Lake Storage pro cluster s vysokou souběžností blokuje všechny porty v clusteru s výjimkou portů 44, 53 a 80.
- Při vytváření clusteru nastavte režim clusteru na vysokou souběžnost.
- V části Upřesnit možnosti vyberte Povolit předávání přihlašovacích údajů pro přístup k datům na úrovni uživatele a povolte pouze příkazy Pythonu a SQL.

Povolení předávání přihlašovacích údajů služby Azure Data Lake Storage pro cluster Úrovně Standard
Standardní clustery s předáváním přihlašovacích údajů jsou omezené na jednoho uživatele. Standardní clustery podporují Python, SQL, Scala a R. V Databricks Runtime 10.4 LTS a novějších je sparklyr podporován.
Při vytváření clusteru musíte přiřadit uživatele, ale může ho upravit uživatel s oprávněními CAN MANAGE kdykoli a nahradit tak původního uživatele.
Důležité
Aby uživatel přiřazený ke clusteru mohl spouštět příkazy v clusteru, musí mít alespoň oprávnění PŘIPOJIT KE clusteru. Správci pracovního prostoru a tvůrce clusteru mají oprávnění SPRAVOVAT, ale nemůžou spouštět příkazy v clusteru, pokud nejsou určeným uživatelem clusteru.
- Při vytváření clusteru nastavte režim clusteru na standard.
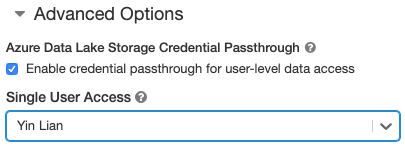
- V části Upřesnit možnosti vyberte Povolit předávání přihlašovacích údajů pro přístup k datům na úrovni uživatele a v rozevíracím seznamu Přístup s jedním uživatelem vyberte uživatelské jméno.
Vytvoření kontejneru
Kontejnery poskytují způsob, jak uspořádat objekty v účtu úložiště Azure.
Přístup ke službě Azure Data Lake Storage přímo pomocí předávání přihlašovacích údajů
Po konfiguraci předávání přihlašovacích údajů Azure Data Lake Storage a vytváření kontejnerů úložiště můžete přistupovat k datům přímo v Azure Data Lake Storage Gen1 pomocí adl:// cesty a Azure Data Lake Storage Gen2 pomocí abfss:// cesty.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Nahraďte
<storage-account-name>názvem účtu úložiště ADLS Gen1.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Nahraďte
<container-name>názvem kontejneru v účtu úložiště ADLS Gen2. - Nahraďte
<storage-account-name>názvem účtu úložiště ADLS Gen2.
Připojení služby Azure Data Lake Storage k DBFS pomocí předávání přihlašovacích údajů
K tomu, co je DBFS, můžete připojit účet služby Azure Data Lake Storage nebo do ní složku. Připojení je ukazatel na úložiště datového jezera, takže data se nikdy nesynchronizují místně.
Když připojíte data pomocí clusteru s povoleným předáváním přihlašovacích údajů služby Azure Data Lake Storage, bude jakékoli čtení nebo zápis do přípojného bodu používat vaše přihlašovací údaje k ID Microsoft Entra. Tento přípojný bod bude viditelný pro ostatní uživatele, ale jedinými uživateli, kteří budou mít přístup pro čtení a zápis, jsou ti, kteří:
- Přístup k podkladovému účtu úložiště Azure Data Lake Storage
- Použití clusteru s povoleným předáváním přihlašovacích údajů služby Azure Data Lake Storage
Azure Data Lake Storage Gen1
Pokud chcete připojit prostředek Azure Data Lake Storage Gen1 nebo složku uvnitř, použijte následující příkazy:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Nahraďte
<storage-account-name>názvem účtu úložiště ADLS Gen2. - Nahraďte
<mount-name>názvem zamýšleného přípojného bodu v DBFS.
Azure Data Lake Storage Gen2
Pokud chcete připojit systém souborů Azure Data Lake Storage Gen2 nebo složku uvnitř, použijte následující příkazy:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Nahraďte
<container-name>názvem kontejneru v účtu úložiště ADLS Gen2. - Nahraďte
<storage-account-name>názvem účtu úložiště ADLS Gen2. - Nahraďte
<mount-name>názvem zamýšleného přípojného bodu v DBFS.
Upozorňující
Nezadávejte přístupové klíče účtu úložiště ani přihlašovací údaje instančního objektu pro ověření v přípojovém bodu. To by ostatním uživatelům poskytlo přístup k systému souborů pomocí těchto přihlašovacích údajů. Účelem předávání přihlašovacích údajů služby Azure Data Lake Storage je zabránit tomu, abyste tyto přihlašovací údaje museli používat a zajistili, že přístup k systému souborů bude omezený na uživatele, kteří mají přístup k podkladovému účtu Azure Data Lake Storage.
Zabezpečení
Je bezpečné sdílet clustery s předáváním přihlašovacích údajů služby Azure Data Lake Storage s ostatními uživateli. Budete izolovaní od sebe a nebudete moct číst ani používat přihlašovací údaje ostatních.
Podporované funkce
| Funkce | Minimální verze modulu runtime Databricks | Notes |
|---|---|---|
| Python a SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Přihlašovací údaje se předávají jenom v případě, že se cesta DBFS přeloží na umístění ve službě Azure Data Lake Storage Gen1 nebo Gen2. Pro cesty DBFS, které se přeloží na jiné systémy úložiště, použijte jinou metodu k zadání vašich přihlašovacích údajů. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| ukládání do mezipaměti disku | 5.5 | |
| PySpark ML API | 5.5 | Následující třídy ML nejsou podporovány: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Proměnné všesměrových vysílání | 5.5 | V PySparku platí omezení velikosti definovaných uživatelem definovaných funkcí Pythonu, protože velké uživatelem definované funkce se odesílají jako proměnné všesměrového vysílání. |
| Knihovny s vymezeným poznámkovým blokem | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| Spuštění poznámkového bloku Databricks z jiného poznámkového bloku | 6.1 | |
| PySpark ML API | 6.1 | Všechny podporované třídy PySpark ML. |
| Metriky clusteru | 6.1 | |
| Databricks Connect | 7.3 | Předávání se podporuje v clusterech úrovně Standard. |
Omezení
Předávání přihlašovacích údajů služby Azure Data Lake Storage nepodporuje následující funkce:
%fs(místo toho použijte ekvivalentní příkaz dbutils.fs ).- Pracovní postupy Databricks
- Referenční informace k rozhraní REST API služby Databricks
- Katalog Unity
- Řízení přístupu k tabulkám Oprávnění udělená předáváním přihlašovacích údajů služby Azure Data Lake Storage je možné použít k obejití jemně odstupňovaných oprávnění seznamů ACL tabulek, zatímco dodatečná omezení seznamů ACL tabulky omezují některé výhody, které získáte z předávání přihlašovacích údajů. Konkrétně:
- Pokud máte oprávnění Microsoft Entra ID pro přístup k datovým souborům, které jsou základem konkrétní tabulky, budete mít úplná oprávnění k této tabulce prostřednictvím rozhraní RDD API bez ohledu na omezení, která jsou na ně umístěna prostřednictvím seznamů ACL tabulek.
- Oprávnění seznamů ACL tabulek budou omezena pouze při použití rozhraní DATAFrame API. Pokud se pokusíte číst soubory přímo pomocí rozhraní API datového rámce, zobrazí se upozornění na to, že nemáte oprávnění
SELECTk žádnému souboru, i když byste je mohli číst přímo prostřednictvím rozhraní RDD API. - Nebudete moct číst z tabulek, které využívají jiné systémy souborů než Azure Data Lake Storage, i když máte oprávnění seznamu ACL tabulky ke čtení tabulek.
- Následující metody pro objekty SparkContext (
sc) a SparkSession (spark):- Zastaralé metody
- Metody, jako
addFile()je aaddJar()které by uživatelům bez oprávnění správce umožňovaly volat kód Scala. - Jakákoli metoda, která přistupuje k jinému systému souborů než Azure Data Lake Storage Gen1 nebo Gen2 (pro přístup k jiným systémům souborů v clusteru s povoleným předáváním přihlašovacích údajů azure Data Lake Storage, použijte jinou metodu pro zadání přihlašovacích údajů a prohlédněte si část o důvěryhodných systémech souborů v části Řešení potíží).
- Stará rozhraní API systému Hadoop (
hadoopFile()ahadoopRDD()). - Rozhraní API pro streamování, protože předávané přihlašovací údaje vyprší, i když byl stream stále spuštěný.
- Připojení DBFS (
/dbfs) jsou k dispozici pouze v Databricks Runtime 7.3 LTS a vyšší. Přípojné body s nakonfigurovaným předáváním přihlašovacích údajů nejsou prostřednictvím této cesty podporovány. - Azure Data Factory.
- MLflow v clusterech s vysokou souběžností
- balíček pythonu azureml-sdk v clusterech s vysokou souběžností
- Životnost předávacích tokenů Microsoft Entra ID není možné prodloužit pomocí zásad životnosti tokenů Microsoft Entra ID. V důsledku toho pokud odešlete příkaz do clusteru, který trvá déle než hodinu, selže, pokud se prostředek Azure Data Lake Storage dostane za značku 1 hodiny.
- Pokud používáte Hive 2.3 a vyšší, nemůžete do clusteru přidat oddíl s povoleným předáváním přihlašovacích údajů. Další informace najdete v příslušné části řešení potíží.
Ukázkové poznámkové bloky
Následující poznámkové bloky ukazují předávání přihlašovacích údajů služby Azure Data Lake Storage pro Azure Data Lake Storage Gen1 a Gen2.
Poznámkový blok předávání Azure Data Lake Storage Gen1
Předávací poznámkový blok Azure Data Lake Storage Gen2
Řešení potíží
py4j.security.Py4JSecurityException: ... není na seznamu povolených
Tato výjimka se vyvolá v případě, že použijete metodu, kterou služba Azure Databricks explicitně neoznačila jako bezpečnou pro clustery s předáváním přihlašovacích údajů ve službě Azure Data Lake Storage. Ve většině případů to znamená, že daná metoda může uživateli v clusteru s předáváním přihlašovacích údajů ve službě Azure Data Lake Storage umožnit přístup k přihlašovacím údajům jiného uživatele.
org.apache.spark.api.python.PythonSecurityException: Cesta ... používá nedůvěryhodný systém souborů.
Tato výjimka se vyvolá, když se pokusíte o přístup k systému souborů, který cluster Azure Data Lake Storage s předáváním přihlašovacích údajů nepovažuje za bezpečný. Použití nedůvěryhodného systému souborů může uživateli v clusteru s předáváním přihlašovacích údajů azure Data Lake Storage umožnit přístup k přihlašovacím údajům jiného uživatele, takže zakážeme používání všech systémů souborů, o které si nejsme jistí, že se bezpečně používají.
Pokud chcete v clusteru Azure Data Lake Storage s předáváním přihlašovacích údajů nakonfigurovat sadu důvěryhodných systémů souborů, nastavte konfigurační klíč Sparku spark.databricks.pyspark.trustedFilesystems v tomto clusteru na čárkami oddělený seznam názvů tříd, které jsou důvěryhodnými implementacemi org.apache.hadoop.fs.FileSystem.
Přidání oddílu selže s povoleným AzureCredentialNotFoundException předáváním přihlašovacích údajů
Pokud se při použití Hive 2.3–3.1 pokusíte přidat oddíl do clusteru s povoleným předáváním přihlašovacích údajů, dojde k následující výjimce:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Chcete-li tento problém vyřešit, přidejte oddíly v clusteru bez povoleného předávání přihlašovacích údajů.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro