Databricks Connect pro Scala
Poznámka:
Tento článek popisuje Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší.
Tento článek ukazuje, jak rychle začít pracovat s Databricks Connect pomocí Scala s IntelliJ IDEA a modulem plug-in Scala.
- Informace o verzi Pythonu tohoto článku najdete v tématu Databricks Connect pro Python.
- Verzi jazyka R tohoto článku najdete v tématu Databricks Connect pro R.
Databricks Connect umožňuje připojit k clusterům Azure Databricks oblíbená prostředí IDE, jako jsou IntelliJ IDEA, servery poznámkových bloků a další vlastní aplikace. Podívejte se, co je Databricks Connect?
Kurz
Pokud chcete tento kurz přeskočit a místo toho použít jiné integrované vývojové prostředí (IDE), přečtěte si další kroky.
Požadavky
K dokončení tohoto kurzu musíte splnit následující požadavky:
Váš cílový pracovní prostor a cluster Azure Databricks musí splňovat požadavky na konfiguraci clusteru pro Databricks Connect.
Musíte mít k dispozici ID clusteru. Pokud chcete získat ID clusteru, klikněte v pracovním prostoru na bočním panelu na Compute a potom na název clusteru. V adresní řádku webového prohlížeče zkopírujte řetězec znaků mezi
clustersadresou URL aconfigurationdo adresy URL.Na vývojovém počítači máte nainstalovanou sadu Java Development Kit (JDK). Databricks doporučuje, aby verze instalace sady JDK, kterou používáte, odpovídala verzi sady JDK ve vašem clusteru Azure Databricks. Následující tabulka uvádí verzi sady JDK pro každý podporovaný modul Databricks Runtime.
Verze modulu Databricks Runtime Verze sady JDK 13.3 LTS - 15.0,
13.3 ML LTS - 15.0 MLJDK 8 Poznámka:
Pokud nemáte nainstalovanou sadu JDK nebo máte na vývojovém počítači více instalací sady JDK, můžete nainstalovat nebo zvolit konkrétní sadu JDK později v kroku 1. Volba instalace sady JDK, která je nižší nebo vyšší než verze sady JDK ve vašem clusteru, může způsobit neočekávané výsledky nebo se váš kód nemusí vůbec spustit.
Máte nainstalovaný IntelliJ IDEA. Tento kurz byl testován v IntelliJ IDEA Community Edition 2023.3.6. Pokud používáte jinou verzi nebo edici IntelliJ IDEA, můžou se následující pokyny lišit.
Máte nainstalovaný modul plug-in Scala pro IntelliJ IDEA.
Krok 1: Konfigurace ověřování Azure Databricks
V tomto kurzu se k ověřování v pracovním prostoru Azure Databricks používá ověřování uživatele na počítač (U2M) Azure Databricks a konfigurační profil Azure Databricks. Pokud chcete místo toho použít jiný typ ověřování, přečtěte si téma Konfigurace vlastností připojení.
Konfigurace ověřování OAuth U2M vyžaduje rozhraní příkazového řádku Databricks následujícím způsobem:
Pokud ještě není nainstalovaný, nainstalujte rozhraní příkazového řádku Databricks následujícím způsobem:
Linux, macOS
Pomocí Homebrew nainstalujte Rozhraní příkazového řádku Databricks spuštěním následujících dvou příkazů:
brew tap databricks/tap brew install databricksWindows
K instalaci rozhraní příkazového řádku Databricks můžete použít winget, Chocolatey nebo Subsystém Windows pro Linux (WSL). Pokud nemůžete použít
winget, Chocolatey nebo WSL, měli byste tento postup přeskočit a místo toho použít příkazový řádek nebo PowerShell k instalaci rozhraní příkazového řádku Databricks ze zdroje .Poznámka:
Instalace Rozhraní příkazového řádku Databricks s Chocolatey je experimentální.
Pokud chcete použít
wingetk instalaci rozhraní příkazového řádku Databricks, spusťte následující dva příkazy a restartujte příkazový řádek:winget search databricks winget install Databricks.DatabricksCLIPokud chcete k instalaci rozhraní příkazového řádku Databricks použít Chocolatey, spusťte následující příkaz:
choco install databricks-cliPoužití WSL k instalaci rozhraní příkazového řádku Databricks:
Nainstalujte
curlazipprostřednictvím WSL. Další informace najdete v dokumentaci k operačnímu systému.Pomocí WSL nainstalujte rozhraní příkazového řádku Databricks spuštěním následujícího příkazu:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Spuštěním následujícího příkazu ověřte, že je nainstalované rozhraní příkazového řádku Databricks, které zobrazuje aktuální verzi nainstalovaného rozhraní příkazového řádku Databricks. Tato verze by měla být 0.205.0 nebo vyšší:
databricks -vPoznámka:
Pokud spustíte
databricks, ale zobrazí se chyba, napříkladcommand not found: databricksnebo pokud spustítedatabricks -va zobrazí se číslo verze 0.18 nebo nižší, znamená to, že váš počítač nemůže najít správnou verzi spustitelného souboru rozhraní příkazového řádku Databricks. Pokud chcete tento problém vyřešit, přečtěte si téma Ověření instalace rozhraní příkazového řádku.
Následujícím způsobem zahajte ověřování OAuth U2M:
Pomocí rozhraní příkazového řádku Databricks zahajte správu tokenů OAuth místně spuštěním následujícího příkazu pro každý cílový pracovní prostor.
V následujícím příkazu nahraďte
<workspace-url>adresou URL služby Azure Databricks pro jednotlivé pracovní prostory, napříkladhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Rozhraní příkazového řádku Databricks vás vyzve k uložení informací, které jste zadali jako konfigurační profil Azure Databricks. Stisknutím klávesy
Enterpotvrďte navrhovaný název profilu nebo zadejte název nového nebo existujícího profilu. Všechny existující profily se stejným názvem se přepíšou informacemi, které jste zadali. Profily můžete použít k rychlému přepnutí kontextu ověřování napříč několika pracovními prostory.Pokud chcete získat seznam všech existujících profilů, v samostatném terminálu nebo příkazovém řádku spusťte příkaz
databricks auth profilespomocí rozhraní příkazového řádku Databricks . Pokud chcete zobrazit existující nastavení konkrétního profilu, spusťte příkazdatabricks auth env --profile <profile-name>.Ve webovém prohlížeči dokončete pokyny na obrazovce, abyste se přihlásili k pracovnímu prostoru Azure Databricks.
V seznamu dostupných clusterů, které se zobrazí v terminálu nebo příkazovém řádku, vyberte cílový cluster Azure Databricks v pracovním prostoru pomocí šipky nahoru a šipky dolů a stiskněte
Enter. Pokud chcete filtrovat seznam dostupných clusterů, můžete také zadat libovolnou část zobrazovaného názvu clusteru.Pokud chcete zobrazit aktuální hodnotu tokenu OAuth profilu a nadcházející časové razítko vypršení platnosti tokenu, spusťte jeden z následujících příkazů:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Pokud máte více profilů se stejnou
--hosthodnotou, možná budete muset zadat--hostspolečně možnosti a-ppomoct rozhraní příkazového řádku Databricks najít správné odpovídající informace o tokenu OAuth.
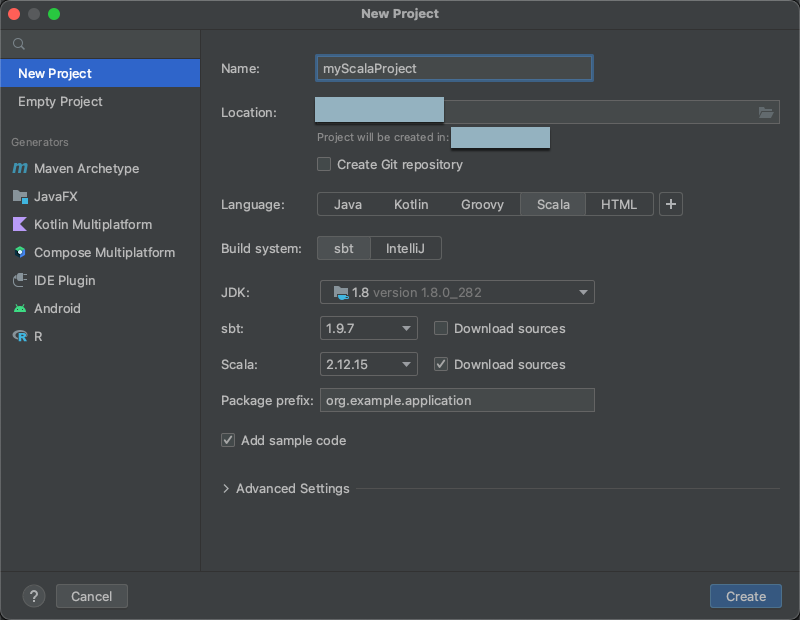
Krok 2: Vytvoření projektu
Spusťte IntelliJ IDEA.
V hlavní nabídce klikněte na Soubor > nový > projekt.
Dejte projektu nějaký smysluplný název.
V části Umístění klikněte na ikonu složky a podle pokynů na obrazovce zadejte cestu k novému projektu Scala.
V případě jazyka klikněte na Scala.
V případě systému sestavení klikněte na tlačítko sbt.
V rozevíracím seznamu JDK vyberte existující instalaci sady JDK na vývojovém počítači, která odpovídá verzi sady JDK v clusteru, nebo vyberte Stáhnout sadu JDK a podle pokynů na obrazovce stáhněte sadu JDK, která odpovídá verzi sady JDK ve vašem clusteru.
Poznámka:
Volba instalace sady JDK, která je vyšší nebo nižší než verze sady JDK ve vašem clusteru, může způsobit neočekávané výsledky nebo se váš kód nemusí vůbec spustit.
V rozevíracím seznamu sbt vyberte nejnovější verzi.
V rozevíracím seznamu Scala vyberte verzi Scala, která odpovídá verzi Scala ve vašem clusteru. Následující tabulka uvádí verzi Scala pro každý podporovaný modul Databricks Runtime:
Verze modulu Databricks Runtime Verze Scala 13.3 LTS - 15.0,
13.3 ML LTS - 15.0 ML2.12.15 Poznámka:
Volba verze Scala, která je nižší nebo vyšší než verze Scala ve vašem clusteru, může způsobit neočekávané výsledky nebo se váš kód nemusí vůbec spustit.
Ujistěte se, že je zaškrtnuté políčko Stáhnout zdroje vedle scaly .
Jako předponu balíčku zadejte hodnotu předpony balíčku pro zdroje projektu, například
org.example.application.Ujistěte se, že je zaškrtnuté políčko Přidat vzorový kód .
Klikněte na Vytvořit.
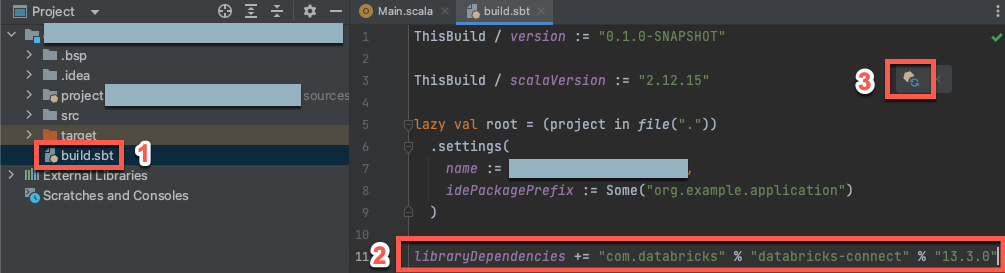
Krok 3: Přidání balíčku Databricks Connect
Když otevřete nový projekt Scala, otevřete v okně nástroje Project (View > Tool Windows > Project) soubor s názvem
build.sbtv cíli názvu> projektu.Na konec
build.sbtsouboru přidejte následující kód, který deklaruje závislost projektu na konkrétní verzi knihovny Databricks Connect pro Scala:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Nahraďte
14.3.1verzí knihovny Databricks Connect, která odpovídá verzi Databricks Runtime ve vašem clusteru. Čísla verzí knihovny Databricks Connect najdete v centrálním úložišti Maven.Kliknutím na tlačítko Načíst sbt změní ikonu oznámení a aktualizujte projekt Scala novým umístěním knihovny a závislostí.
Počkejte, až
sbtindikátor průběhu v dolní části integrovaného vývojového prostředí zmizí. Dokončenísbtprocesu načítání může trvat několik minut.
Krok 4: Přidání kódu
V okně nástroje Project otevřete soubor s názvem
Main.scalasrc main > scala src>>.Nahraďte veškerý existující kód v souboru následujícím kódem a pak soubor uložte v závislosti na názvu vašeho konfiguračního profilu.
Pokud má váš konfigurační profil z kroku 1 název
DEFAULT, nahraďte veškerý existující kód v souboru následujícím kódem a pak soubor uložte:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Pokud váš konfigurační profil z kroku 1 není pojmenovaný
DEFAULT, nahraďte veškerý existující kód v souboru následujícím kódem. Zástupný symbol<profile-name>nahraďte názvem konfiguračního profilu z kroku 1 a pak soubor uložte:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Krok 5: Spuštění kódu
- Spusťte cílový cluster ve vzdáleném pracovním prostoru Azure Databricks.
- Po spuštění clusteru v hlavní nabídce klikněte na Spustit > "Main".
- V okně nástroje Spustit (Zobrazit > nástroj Windows > Spustit) se na kartě Hlavní zobrazí prvních 5 řádků
samples.nyctaxi.tripstabulky.
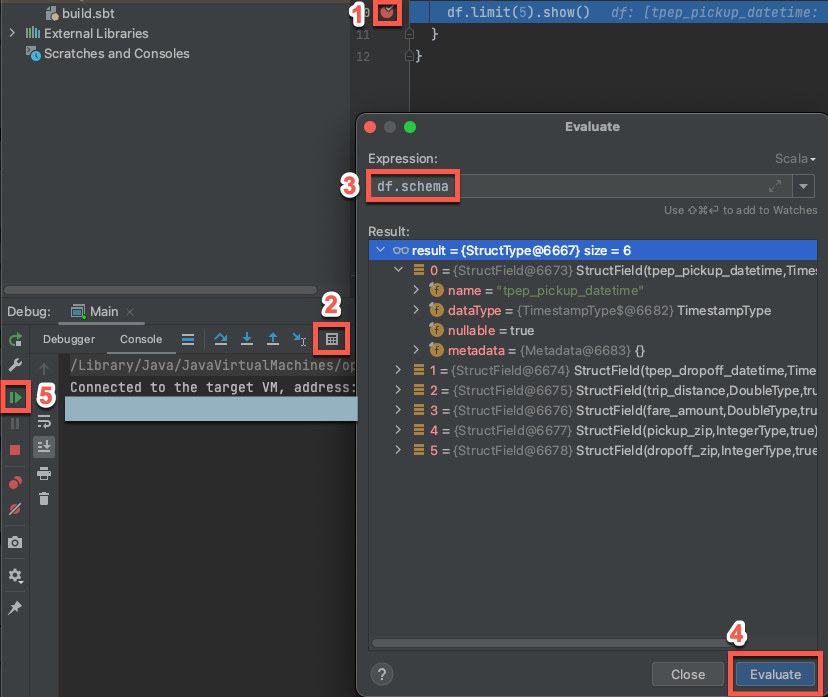
Krok 6: Ladění kódu
- Když je cílový cluster stále spuštěný, klikněte v předchozím kódu na hřbet vedle
df.limit(5).show()a nastavte zarážku. - V hlavní nabídce klikněte na Spustit > ladění Main.
- V okně nástroje Ladění (Zobrazit > nástroj Windows > Ladění) na kartě Konzola klikněte na ikonu kalkulačky (Vyhodnocení výrazu).
- Zadejte výraz
df.schemaa kliknutím na Vyhodnotit zobrazte schéma datového rámce. - Na bočním panelu okna nástroje Ladění klikněte na zelenou šipku (Resume Program).
- V podokně Konzola se zobrazí prvních 5 řádků
samples.nyctaxi.tripstabulky.
Další kroky
Další informace o službě Databricks Connect najdete v článcích, jako jsou následující:
Pokud chcete použít jiné typy ověřování Azure Databricks než osobní přístupový token Azure Databricks, přečtěte si téma Konfigurace vlastností připojení.
Pokud chcete použít jiné prostředí IDE, přečtěte si následující informace:
Pokud chcete zobrazit další jednoduché příklady kódu, podívejte se na příklady kódu pro Databricks Connect pro Scala.
Pokud chcete zobrazit složitější příklady kódu, podívejte se na ukázkové aplikace pro úložiště Databricks Connect v GitHubu, konkrétně:
Pokud chcete migrovat z Databricks Connect pro Databricks Runtime 12.2 LTS a níže na Databricks Connect pro Databricks Runtime 13.3 LTS a novější, přečtěte si téma Migrace na Databricks Connect pro Scala.
Viz také informace o řešení potíží a omezeních.