Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Poznámka:
Tento článek popisuje Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší.
Databricks Connect umožňuje připojit oblíbená prostředí IDE, jako jsou PyCharm, servery poznámkových bloků a další vlastní aplikace, k výpočetním prostředkům Azure Databricks. Podívejte se, co je Databricks Connect?
Tento článek ukazuje, jak rychle začít používat Databricks Connect pro Python pomocí PyCharmu.
- Verzi jazyka R tohoto článku najdete v tématu Databricks Connect pro R.
- Informace o verzi Scala tohoto článku najdete v tématu Databricks Connect pro Scala.
Výukový program
V následujícím kurzu vytvoříte projekt v PyCharm, nainstalujete Databricks Connect pro Databricks Runtime 13.3 LTS a novější a spustíte jednoduchý kód na výpočetních prostředcích v pracovním prostoru Databricks z PyCharm. Další informace a příklady najdete v tématu Další kroky.
Požadavky
K dokončení tohoto kurzu musíte splnit následující požadavky:
- Váš cílový pracovní prostor Azure Databricks musí mít povolený katalog Unity.
- Máte nainstalovaný PyCharm . Tento kurz byl testován s PyCharm Community Edition 2023.3.5. Pokud používáte jinou verzi nebo edici PyCharm, můžou se následující pokyny lišit.
- Vaše místní prostředí a výpočetní prostředky splňují požadavky na verzi instalace Databricks Connect pro Python .
- Pokud používáte klasické výpočetní prostředky, budete potřebovat ID clusteru. Pokud chcete získat ID clusteru, klikněte v pracovním prostoru na bočním panelu na Compute a potom na název clusteru. V adresní řádku webového prohlížeče zkopírujte řetězec znaků mezi
clustersadresou URL aconfigurationdo adresy URL.
Krok 1: Konfigurace ověřování Azure Databricks
V tomto kurzu se k autentizaci vašeho pracovního prostoru Azure Databricks používá autentizace U2M (uživatel-počítač) a konfigurační profil Azure Databricks. Pokud chcete použít jiný typ ověřování, přečtěte si téma Konfigurace vlastností připojení.
Konfigurace ověřování OAuth U2M vyžaduje rozhraní příkazového řádku Databricks. Informace o instalaci rozhraní příkazového řádku Databricks najdete v tématu Instalace nebo aktualizace rozhraní příkazového řádku Databricks.
Následujícím způsobem zahajte ověřování OAuth U2M:
Spusťte správu tokenů OAuth lokálně pomocí Databricks CLI spuštěním následujícího příkazu pro každý cílový pracovní prostor.
V následujícím příkazu nahraďte
<workspace-url>adresou URL služby Azure Databricks pro jednotlivé pracovní prostory, napříkladhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Návod
Pokud chcete s Databricks Connect používat bezserverové výpočetní prostředky, přečtěte si téma Konfigurace připojení k bezserverovým výpočetním prostředkům.
Rozhraní příkazového řádku Databricks vás vyzve k uložení informací, které jste zadali jako konfigurační profil Azure Databricks. Stisknutím klávesy
Enterpotvrďte navrhovaný název profilu nebo zadejte název nového nebo existujícího profilu. Všechny existující profily se stejným názvem se přepíšou informacemi, které jste zadali. Profily můžete použít k rychlému přepnutí kontextu ověřování napříč několika pracovními prostory.Seznam existujících profilů získáte tak, že v samostatném terminálu nebo příkazovém řádku použijete rozhraní příkazového řádku Databricks ke spuštění příkazu
databricks auth profiles. Pokud chcete zobrazit existující nastavení konkrétního profilu, spusťte příkazdatabricks auth env --profile <profile-name>.Ve webovém prohlížeči dokončete pokyny na obrazovce, abyste se přihlásili k pracovnímu prostoru Azure Databricks.
V seznamu dostupných clusterů, které se zobrazí v terminálu nebo příkazovém řádku, vyberte cílový cluster Azure Databricks v pracovním prostoru pomocí šipky nahoru a dolů a stiskněte
Enter. Pokud chcete filtrovat seznam dostupných clusterů, můžete také zadat libovolnou část zobrazovaného názvu clusteru.Pokud chcete zobrazit aktuální hodnotu tokenu OAuth profilu a nadcházející časové razítko vypršení platnosti tokenu, spusťte jeden z následujících příkazů:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Pokud máte více profilů se stejnou
--hosthodnotou, možná budete muset zadat možnosti--hosta-pspolečně, aby rozhraní příkazového řádku Databricks našlo správné odpovídající informace o tokenu OAuth.
Krok 2: Vytvoření projektu
- Spusťte PyCharm.
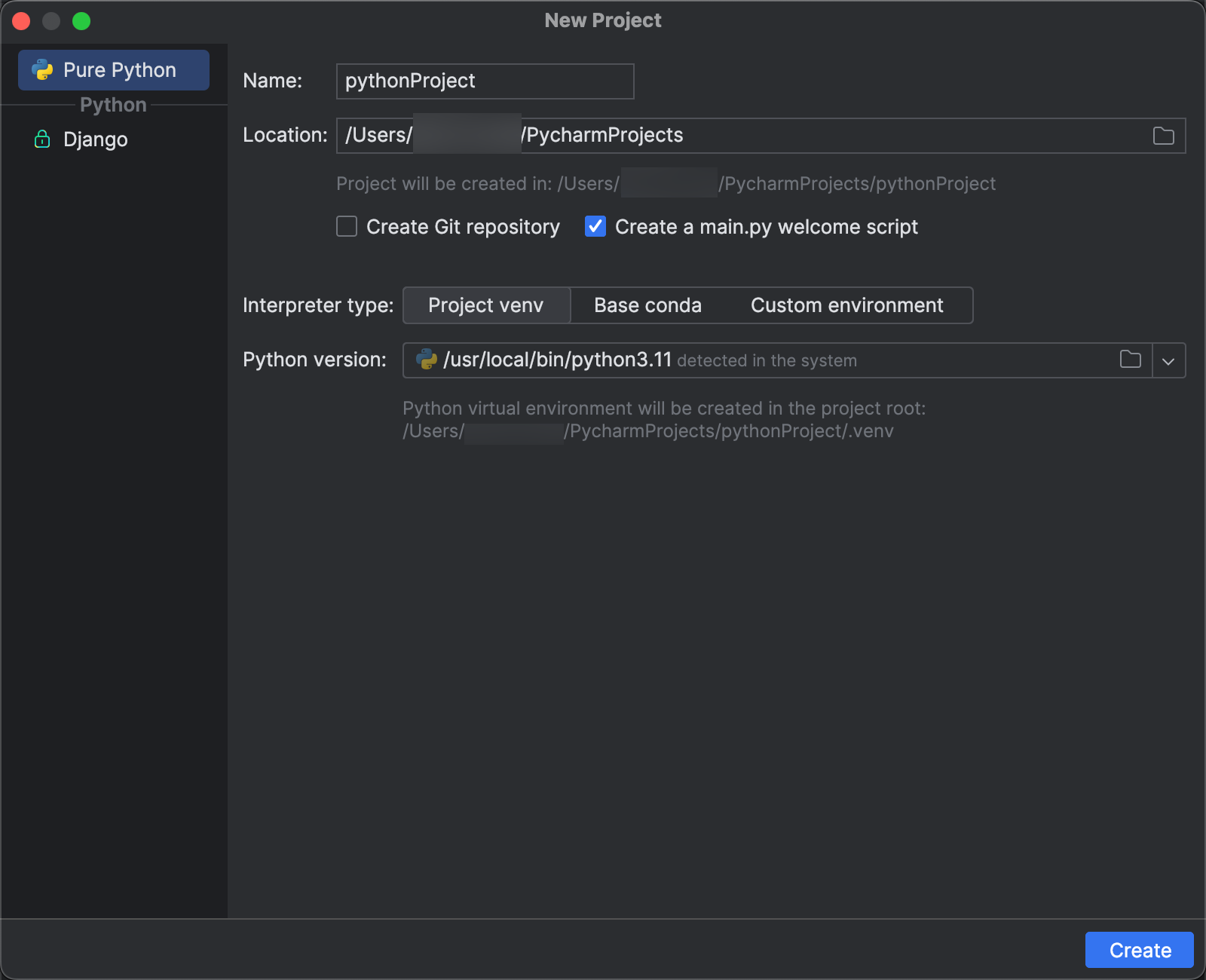
- V hlavní nabídce klikněte na Soubor > nový projekt.
- V dialogovém okně Nový projekt klikněte na Pure Python.
- V části Umístění klikněte na ikonu složky a podle pokynů na obrazovce zadejte cestu k novému projektu Pythonu.
- Ponechte vybranou možnost Vytvořit main.py uvítací skript.
- Pro typ interpreta klikněte na Project venv.
- Rozbalte verze Pythonu a pomocí ikony složky nebo rozevíracího seznamu určete cestu k interpretu Pythonu podle předchozích požadavků.
- Klikněte na Vytvořit.
Krok 3: Přidání balíčku Databricks Connect
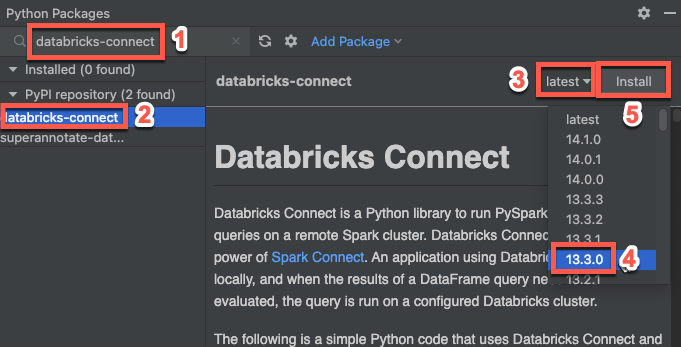
- V hlavní nabídce PyCharm klepněte na příkaz Zobrazit > nástroj Windows > Python Packages.
- Do vyhledávacího pole zadejte
databricks-connect. - V seznamu úložiště PyPI
klikněte na databricks-connect . - V nejnovějším rozevíracím seznamu podokna výsledků vyberte verzi, která odpovídá verzi Databricks Runtime vašeho clusteru. Pokud má váš cluster například nainstalovaný Databricks Runtime 14.3, vyberte 14.3.1.
- Klikněte na Instalovat balíček.
- Po instalaci balíčku můžete zavřít okno Python Packages.
Krok 4: Přidání kódu
V okně nástroje Project klikněte pravým tlačítkem na kořenovou složku projektu a klikněte na Nový > soubor Pythonu.
Zadejte
main.pya poklikejte na Pythonový soubor.Do souboru zadejte následující kód a v závislosti na názvu konfiguračního profilu ho uložte.
Pokud má váš konfigurační profil z kroku 1 název
DEFAULT, zadejte do souboru následující kód a pak soubor uložte:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Pokud váš konfigurační profil z kroku 1 není pojmenovaný
DEFAULT, zadejte do souboru následující kód. Zástupný symbol<profile-name>nahraďte názvem konfiguračního profilu z kroku 1 a pak soubor uložte:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Krok 5: Spuštění kódu
- Spusťte cílový cluster ve vzdáleném pracovním prostoru Azure Databricks.
- Po spuštění clusteru v hlavní nabídce klikněte na Spustit 'main'>.
- V okně nástroje Spustit (Zobrazit > nástroj Windows > Spustit) v hlavním podokně karty Spustit se zobrazí prvních 5 řádků
samples.nyctaxi.trips.
Krok 6: Ladění kódu
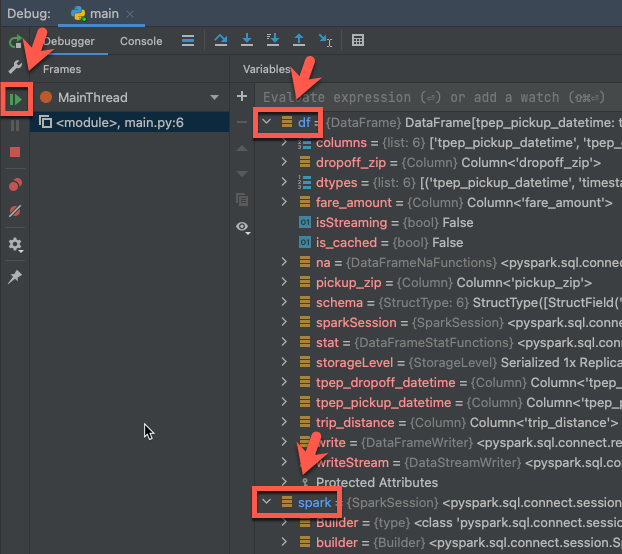
- Pokud je cluster stále spuštěný, klikněte v předchozím kódu na okraj vedle
df.show(5)a nastavte zarážku. - V hlavní nabídce klikněte na Spustit ladění 'main'>.
- V okně Debug nástroje (Zobrazit > Okna nástrojů > Debug), v podokně Proměnné na kartě Debugger, rozbalte uzly proměnných df a spark a procházejte informace o proměnných kódu
dfaspark. - Na bočním panelu okna nástroje Ladění klikněte na zelenou šipku (Resume Program).
- V podokně Konzola na kartě Ladicí program se zobrazí prvních 5 řádků
samples.nyctaxi.trips.
Další kroky
Další informace o službě Databricks Connect najdete v článcích, jako jsou následující:
- Pokud chcete použít jiný typ ověřování, přečtěte si téma Konfigurace vlastností připojení.
- Použijte Databricks Connect s dalšími prostředími IDEs, servery poznámkových bloků a prostředím Spark.
- Pokud chcete zobrazit další jednoduché příklady kódu, podívejte se na příklady kódu pro Databricks Connect pro Python.
- Pokud chcete zobrazit složitější příklady kódu, podívejte se na ukázkové aplikace pro úložiště Databricks Connect v GitHubu, konkrétně:
- Pokud chcete používat nástroje Databricks s Databricks Connect, přečtěte si téma Nástroje Databricks s Databricks Connect pro Python.
- Pokud chcete migrovat z Databricks Connect pro Databricks Runtime 12.2 LTS a níže na Databricks Connect pro Databricks Runtime 13.3 LTS a vyšší, přečtěte si téma Migrace na Databricks Connect pro Python.
- Viz také informace o řešení potíží a omezeních.