Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento kurz vás provede nastavením rozšíření Databricks pro Visual Studio Code a poté spuštěním Pythonu v clusteru Azure Databricks a jako úlohu Azure Databricks ve vašem vzdáleném pracovním prostoru. Viz rozšíření Databricks pro Visual Studio Code.
Požadavky
Tento kurz vyžaduje:
- Nainstalovali jste rozšíření Databricks pro Visual Studio Code. Viz Instalujte rozšíření Databricks pro Visual Studio Code.
- Máte vzdálený cluster Azure Databricks, který můžete použít. Poznamenejte si název clusteru. Pokud chcete zobrazit dostupné clustery, klikněte na bočním panelu pracovního prostoru Azure Databricks na Compute. Viz Výpočty.
Krok 1: Vytvoření nového projektu Databricks
V tomto kroku vytvoříte nový projekt Databricks a nakonfigurujete připojení ke vzdálenému Azure Databricks pracovnímu prostoru.
- Spusťte Visual Studio Code a potom klikněte na Soubor > Otevřít složku a otevřete nějakou prázdnou složku na místním vývojovém počítači.
- Na bočním panelu klikněte na ikonu loga Databricks . Tím se otevře rozšíření Databricks.
- V zobrazení Konfigurace klepněte na tlačítko Vytvořit konfiguraci.
- Otevře se paleta příkazů pro konfiguraci pracovního prostoru Databricks. Pro Databricks Host zadejte nebo vyberte svou per-workspace URL, například
https://adb-1234567890123456.7.azuredatabricks.net. - Vyberte profil ověřování pro projekt. Viz Nastavte autorizaci pro rozšíření Databricks pro Visual Studio Code.
Krok 2: Přidání informací o clusteru do rozšíření Databricks a spuštění clusteru
Když už máte otevřené zobrazení Konfigurace, klikněte na Vybrat cluster nebo klikněte na ikonu ozubeného kola (Konfigurovat cluster).
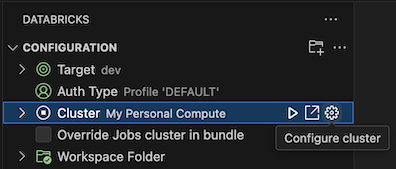
Na paletě příkazů vyberte název clusteru, který jste vytvořili dříve.
Pokud ještě není spuštěný, klikněte na ikonu přehrávání (Spustit cluster).
Krok 3: Vytvoření a spuštění kódu Python
Vytvořte místní soubor kódu Python: na bočním panelu klikněte na ikonu složky (Explorer).
V hlavní nabídce klikněte na Soubor > Nový soubor a zvolte soubor Python. Pojmenujte soubor demo.py a uložte ho do kořenového adresáře projektu.
Do souboru přidejte následující kód a pak ho uložte. Tento kód vytvoří a zobrazí obsah základního datového rámce PySpark:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Klikněte na ikonu Spustit v Databricks vedle seznamu karet editoru a potom klikněte na Nahrát a spustit soubor. Výstup se zobrazí v zobrazení konzoly ladění.
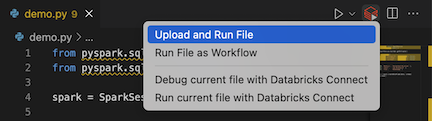
Případně v zobrazení Průzkumníka klikněte pravým tlačítkem myši na
demo.pysoubor a potom klikněte na Spustit v Databricks>Nahrát a spustit soubor.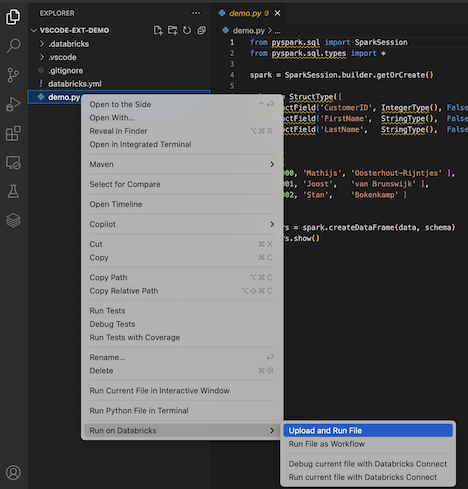
Krok 4: Spuštění kódu jako úlohy
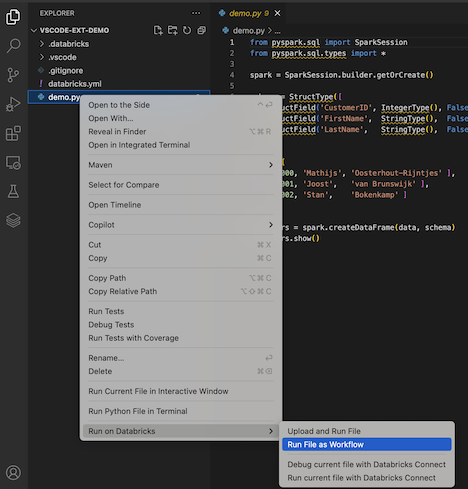
Pokud chcete spustit demo.py jako úlohu, klikněte na ikonu Spustit v Databricks vedle seznamu karet editoru a potom klikněte na Spustit soubor jako pracovní postup. Výstup se zobrazí na samostatné kartě editoru vedle editoru souborů demo.py.
![]()
Případně klikněte pravým tlačítkem myši na demo.py soubor na panelu Průzkumník a potom vyberte Spustit v Databricks> nebo Spustit soubor jako pracovní postup.
Další kroky
Teď, když jste úspěšně použili rozšíření Databricks pro Visual Studio Code k nahrání místního souboru Python a jeho vzdálenému spuštění, můžete také:
- Prozkoumejte prostředky a proměnné deklarativní automatizace pomocí uživatelského rozhraní rozšíření. Viz funkce rozšíření deklarativních balíčků automatizace.
- Spuštění nebo ladění kódu Python pomocí Databricks Connect Viz kód Debug pomocí Databricks Connect pro rozšíření Databricks pro Visual Studio Code.
- Spusťte soubor nebo poznámkový blok jako Azure Databricks úlohu. Viz Spuštění souboru nebo poznámkového bloku v clusteru jako úlohy v Azure Databricks pomocí rozšíření Databricks pro Visual Studio Code.
- Spouštět testy pomocí
pytestpříkazu . Viz Spuštění testů Python pomocí rozšíření Databricks pro Visual Studio Code.