Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Registr služby Azure Machine Learning umožňuje spolupracovat napříč pracovními prostory ve vaší organizaci. Pomocí registrů můžete sdílet modely, komponenty a prostředí.
Existují dva scénáře, ve kterých byste chtěli použít stejnou sadu modelů, komponent a prostředí ve více pracovních prostorech:
-
MLOps mezi pracovními prostory: Trénujete model v
devpracovním prostoru a potřebujete ho nasadit dotestpracovních prostorů aprodpracovních prostorů. V takovém případě chcete mít kompletní sledovatelnost mezi koncovými body, na které je model nasazen v pracovních prostorechtestneboprod, a trénovací úlohou, metrikami, kódem, daty a prostředím, které byly použity k trénování modelu v pracovním prostorudev. - Sdílení a opakované použití modelů a kanálů napříč různými týmy: Sdílení a opakované použití zlepšuje spolupráci a produktivitu. V tomto scénáři můžete chtít publikovat natrénovaný model a přidružené komponenty a prostředí, které se používají k jeho trénování do centrálního katalogu. Odsud můžou kolegové z jiných týmů vyhledávat a opakovaně používat prostředky, které jste sdíleli ve svých vlastních experimentech.
V tomto článku se naučíte:
- Vytvořte prostředí a komponentu v registru.
- Pomocí komponenty z registru odešlete úlohu trénování modelu v pracovním prostoru.
- Zaregistrujte natrénovaný model v registru.
- Nasaďte model z registru do online koncového bodu v pracovním prostoru a pak odešlete žádost o odvozování.
Požadavky
Než budete postupovat podle kroků v tomto článku, ujistěte se, že máte následující požadavky:
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Registr služby Azure Machine Learning pro sdílení modelů, komponent a prostředí Pokud chcete vytvořit registr, přečtěte si, jak vytvořit registr.
Pracovní prostor služby Azure Machine Learning. Pokud ho nemáte, vytvořte ho podle kroků v článku Rychlý start: Vytvoření prostředků pracovního prostoru .
Důležité
Oblast (umístění) Azure, ve které pracovní prostor vytvoříte, musí být v seznamu podporovaných oblastí pro registr služby Azure Machine Learning.
Azure CLI a
mlrozšíření nebo sada Azure Machine Learning Python SDK v2:Pokud chcete nainstalovat Azure CLI a rozšíření, přečtěte si téma Instalace, nastavení a použití rozhraní příkazového řádku (v2).
Důležité
Příklady rozhraní příkazového řádku v tomto článku předpokládají, že používáte prostředí Bash (nebo kompatibilní). Například ze systému Linux nebo Subsystém Windows pro Linux.
V příkladech se také předpokládá, že jste pro Azure CLI nakonfigurovali výchozí hodnoty, abyste nemuseli zadávat parametry pro vaše předplatné, pracovní prostor, skupinu prostředků nebo umístění. Pokud chcete nastavit výchozí nastavení, použijte následující příkazy. Nahraďte následující parametry hodnotami pro vaši konfiguraci:
-
<subscription>nahraďte ID vašeho předplatného Azure. - Nahraďte
<workspace>názvem pracovního prostoru služby Azure Machine Learning. - Nahraďte
<resource-group>skupinou prostředků Azure, která obsahuje váš pracovní prostor. - Nahraďte
<location>oblastí Azure, která obsahuje váš pracovní prostor.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Pomocí příkazu můžete zjistit, jaké jsou
az configure -lvaše aktuální výchozí hodnoty.-
Úložiště klonování příkladů
Příklady kódu v tomto článku jsou založené na nyc_taxi_data_regression ukázce v úložišti příkladů. Pokud chcete tyto soubory použít ve vývojovém prostředí, naklonujte úložiště pomocí následujících příkazů a změňte adresáře na příklad:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
V příkladu rozhraní příkazového řádku změňte adresáře na cli/jobs/pipelines-with-components/nyc_taxi_data_regression místní klon úložiště příkladů.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Vytvoření připojení sady SDK
Návod
Tento krok je potřeba jenom při použití sady Python SDK.
Vytvořte připojení klienta k pracovnímu prostoru Azure Machine Learning i registru:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Vytvoření prostředí v registru
Prostředí definují kontejner Dockeru a závislosti Pythonu potřebné ke spouštění trénovacích úloh nebo nasazování modelů. Další informace o prostředích najdete v následujících článcích:
Návod
Stejný příkaz az ml environment create rozhraní příkazového řádku lze použít k vytvoření prostředí v pracovním prostoru nebo registru. Spuštění příkazu příkazem --workspace-name vytvoří prostředí v pracovním prostoru, zatímco spuštěním příkazu --registry-name vytvoříte prostředí v registru.
Vytvoříme prostředí, které používá image Dockeru python:3.8 a nainstaluje balíčky Pythonu potřebné ke spuštění trénovací úlohy pomocí architektury SciKit Learn. Pokud jste naklonovali úložiště příkladů a nacházíte se ve složce cli/jobs/pipelines-with-components/nyc_taxi_data_regression, měli byste být schopni zobrazit definiční soubor env_train.yml prostředí, který odkazuje na soubor env_train/DockerfileDockeru .
env_train.yml Obsah je následující:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Vytvořte prostředí následujícím az ml environment create způsobem:
az ml environment create --file env_train.yml --registry-name <registry-name>
Pokud se zobrazí chyba, že prostředí s tímto názvem a verzí již v registru existuje, můžete pole version upravit env_train.yml nebo zadat jinou verzi v rozhraní příkazového řádku, která přepíše hodnotu verze v env_train.yml.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Návod
version=$(date +%s) funguje jenom v Linuxu. Pokud to nepomůže, nahraďte $version náhodným číslem.
name Poznamenejte si a version prostředí z výstupu az ml environment create příkazu a použijte je s az ml environment show příkazy následujícím způsobem. Při vytváření komponenty v registru budete potřebovat komponentu name a version v další části.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Návod
Pokud jste použili jiný název nebo verzi prostředí, nahraďte parametry --name odpovídajícím --version způsobem.
Můžete také použít az ml environment list --registry-name <registry-name> k výpisu všech prostředí v registru.
Můžete procházet všechna prostředí v studio Azure Machine Learning. Nezapomeňte přejít do globálního uživatelského rozhraní a vyhledat položku Registry .

Vytvoření komponenty v registru
Komponenty jsou opakovaně použitelné stavební bloky kanálů Machine Learning ve službě Azure Machine Learning. Kód, příkaz, prostředí, vstupní rozhraní a výstupní rozhraní jednotlivých kroků kanálu můžete zabalit do komponenty. Potom můžete komponentu znovu použít napříč několika kanály, aniž byste se museli starat o přenos závislostí a kódu pokaždé, když napíšete jiný kanál.
Vytvoření komponenty v pracovním prostoru umožňuje použít tuto komponentu v libovolné úloze kanálu v daném pracovním prostoru. Vytvoření komponenty v registru umožňuje použít tuto komponentu v libovolném kanálu v libovolném pracovním prostoru ve vaší organizaci. Vytváření komponent v registru je skvělý způsob, jak vytvářet modulární opakovaně použitelné nástroje nebo sdílené trénovací úkoly, které můžou používat k experimentování různými týmy ve vaší organizaci.
Další informace o součástech najdete v následujících článcích:
Jak používat komponenty v kanálech (SDK)
Důležité
Registr podporuje pouze pojmenované prostředky (data, model, komponenta, prostředí). Pokud chcete odkazovat na prostředek v registru, musíte ho nejprve vytvořit v registru. Zejména pro případ součásti kanálu, pokud chcete odkazovat komponentu nebo prostředí v komponentě kanálu, musíte nejprve vytvořit komponentu nebo prostředí v registru.
Ujistěte se, že jste ve složce cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Najdete soubor train.yml definice komponenty, který obsahuje trénovací skript train_src/train.py Scikit Learn a připravené prostředíAzureML-sklearn-0.24-ubuntu18.04-py37-cpu. Místo kurátorovaných prostředí používáme prostředí Scikit Learn vytvořené v předchozím kroku. Pole můžete upravit environment tak train.yml , aby odkazovat na prostředí Scikit Learn. Výsledný definiční soubor train.yml komponenty je podobný následujícímu příkladu:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Pokud jste použili jiný název nebo verzi, obecnější reprezentace vypadá takto: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, proto nezapomeňte nahradit a <registry-name><sklearn-environment-name><sklearn-environment-version> odpovídajícím způsobem. Potom spuštěním az ml component create příkazu vytvořte komponentu následujícím způsobem.
az ml component create --file train.yml --registry-name <registry-name>
Návod
Stejný příkaz az ml component create rozhraní příkazového řádku můžete použít k vytvoření komponent v pracovním prostoru nebo registru. Spuštění příkazu s příkazem --workspace-name vytvoří komponentu v pracovním prostoru, zatímco spuštění příkazu s příkazem --registry-name vytvoří komponentu v registru.
Pokud nechcete název prostředí upravovat train.yml, můžete název prostředí v rozhraní příkazového řádku přepsat následujícím způsobem:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Návod
Pokud se zobrazí chyba, že název komponenty již v registru existuje, můžete buď upravit verzi v train.yml rozhraní příkazového řádku, nebo ji přepsat náhodnou verzí.
name Poznamenejte si a version komponentu z výstupu az ml component create příkazu a použijte je s az ml component show příkazy následujícím způsobem. Při vytváření úlohy trénování v pracovním prostoru budete potřebovat a nameversion v další části.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
Můžete také použít az ml component list --registry-name <registry-name> k výpisu všech komponent v registru.
Můžete procházet všechny komponenty v studio Azure Machine Learning. Nezapomeňte přejít do globálního uživatelského rozhraní a vyhledat položku Registry .

Spuštění úlohy kanálu v pracovním prostoru pomocí komponenty z registru
Při spuštění úlohy kanálu, která používá komponentu z registru, jsou výpočetní prostředky a trénovací data pro pracovní prostor místní. Další informace o spouštění úloh najdete v následujících článcích:
- Spouštění úloh (CLI)
- Spouštění úloh (SDK)
- Úlohy kanálu s komponentami (CLI)
- Úlohy kanálu s komponentami (SDK)
Spustíme úlohu zpracování dat s trénovací komponentou Scikit Learn vytvořenou v předchozí části k vytrénování modelu. Zkontrolujte, že jste ve složce cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Trénovací datová sada se nachází ve data_transformed složce.
component Upravte oddíl v části train_jobsingle-job-pipeline.yml souboru tak, aby odkazovat na trénovací komponentu vytvořenou v předchozí části. Výsledek single-job-pipeline.yml je následující:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
Klíčovým aspektem je, že tento kanál se bude spouštět v pracovním prostoru pomocí komponenty, která není v konkrétním pracovním prostoru. Komponenta je v registru, který lze použít s jakýmkoli pracovním prostorem ve vaší organizaci. Tuto trénovací úlohu můžete spustit v jakémkoli pracovním prostoru, ke kterému máte přístup, aniž byste se museli starat o zpřístupnění trénovacího kódu a prostředí v tomto pracovním prostoru.
Upozorňující
- Před spuštěním úlohy datového kanálu se ujistěte, že pracovní prostor, ve kterém úlohu spouštíte, je v oblasti Azure, která je podporovaná registrem, ve kterém jste vytvořili komponentu.
- Ověřte, že má pracovní prostor výpočetní cluster s názvem
cpu-clusternebo upravtecomputepole podjobs.train_job.computenázvem vašeho výpočetního prostředí.
Spusťte úlohu kanálu pomocí az ml job create příkazu.
az ml job create --file single-job-pipeline.yml
Návod
Pokud jste nenakonfigurovali výchozí pracovní prostor a skupinu prostředků, jak je vysvětleno v části Požadavky, musíte zadat parametry --workspace-name a --resource-group, aby az ml job create fungovalo.
Případně můžete přeskočit úpravy single-job-pipeline.yml a přepsat název komponenty používaný train_job v rozhraní příkazového řádku.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Vzhledem k tomu, že komponenta použitá v úloze trénování se sdílí prostřednictvím registru, můžete ji odeslat do libovolného pracovního prostoru, ke kterému máte přístup ve vaší organizaci, a to i v různých předplatných. Pokud máte například dev-workspacetest-workspace a prod-workspacespuštění trénovací úlohy v těchto třech pracovních prostorech je stejně snadné jako spuštění tří az ml job create příkazů.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
V studio Azure Machine Learning výběrem odkazu na koncový bod ve výstupu úlohy zobrazte úlohu. Tady můžete analyzovat trénovací metriky, ověřit, že úloha používá komponentu a prostředí z registru, a zkontrolovat natrénovaný model.
name Poznamenejte si úlohu z výstupu nebo vyhledejte stejné informace z přehledu úlohy v studio Azure Machine Learning. Tyto informace budete potřebovat ke stažení natrénovaného modelu v další části o vytváření modelů v registru.

Vytvoření modelu v registru
V této části se dozvíte, jak vytvářet modely v registru. Další informace o správě modelů ve službě Azure Machine Learning najdete v tématu Správa modelů. Podíváme se na dva různé způsoby vytvoření modelu v registru. První je z místních souborů. Zadruhé je zkopírování modelu zaregistrovaného v pracovním prostoru do registru.
V obou možnostech vytvoříte model s formátem MLflow, který vám pomůže nasadit tento model pro odvozování bez psaní kódu odvozování.
Vytvoření modelu v registru z místních souborů
Stáhněte si model, který je k dispozici jako výstup train_job , nahrazením <job-name> názvu z úlohy z předchozí části. Model spolu se soubory metadat MLflow by měl být k dispozici v souboru ./artifacts/model/.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Návod
Pokud jste nenakonfigurovali výchozí pracovní prostor a skupinu prostředků, jak je vysvětleno v části Požadavky, musíte zadat parametry --workspace-name a --resource-group, aby az ml model create fungovalo.
Upozorňující
Výstup az ml job list je předán do sed. Funguje to jenom v linuxových prostředích. Pokud používáte Windows, spusťte az ml job list --parent-job-name <job-name> --query [0].name a odstraňte všechny uvozovky, které vidíte v názvu úlohy vlaku.
Pokud nemůžete stáhnout model, najdete ukázkový model MLflow natrénovaný úlohou trénování v předchozí části ve cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ složce.
Vytvořte model v registru:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Návod
- Použijte náhodné číslo pro parametr
version, pokud obdržíte chybu, že název modelu a verze již existují. - Stejný příkaz
az ml model createrozhraní příkazového řádku můžete použít k vytváření modelů v pracovním prostoru nebo registru. Spuštění příkazu příkazem--workspace-namevytvoří model v pracovním prostoru, zatímco spuštění příkazu s příkazem--registry-namevytvoří model v registru.
Sdílení modelu z pracovního prostoru do registru
V tomto pracovním postupu nejprve vytvoříte model v pracovním prostoru a pak ho nasdílíte do registru. Tento pracovní postup je užitečný, pokud chcete model před sdílením otestovat v pracovním prostoru. Můžete ho například nasadit do koncových bodů a vyzkoušet odvozování s některými testovacími daty a pak model zkopírovat do registru, pokud všechno vypadá dobře. Tento pracovní postup může být také užitečný, když vyvíjíte řadu modelů pomocí různých technik, architektur nebo parametrů a chcete upřednostnit pouze jeden z nich do registru jako produkčního kandidáta.
Ujistěte se, že máte název úlohy kanálu z předchozí části a nahraďte ji v příkazu pro načtení názvu trénovací úlohy. Pak model zaregistrujete z výstupu trénovací úlohy do pracovního prostoru. Všimněte si, jak --path parametr odkazuje na výstup train_job s syntaxí azureml://jobs/$train_job_name/outputs/artifacts/paths/model .
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Návod
- Pokud se zobrazí chyba, že název a verze modelu již existuje, použijte pro parametr
versionnáhodné číslo. - Pokud jste nenakonfigurovali výchozí pracovní prostor a skupinu prostředků, jak je vysvětleno v části Požadavky, musíte zadat parametry
--workspace-namea--resource-group, abyaz ml model createfungovalo.
Poznamenejte si název a verzi modelu. Pokud je model zaregistrovaný v pracovním prostoru, můžete ho ověřit tak, že ho přejdete v uživatelském rozhraní studia nebo pomocí az ml model show --name nyc-taxi-model --version $model_version příkazu.
Dále model sdílíte z pracovního prostoru do registru.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Návod
- Pokud jste ho
az ml model createv příkazu změnili, nezapomeňte použít správný název a verzi modelu. - Výše uvedený příkaz obsahuje dva volitelné parametry --share-with-name a --share-with-version. Pokud tento nový model nezadá, bude mít stejný název a verzi jako model, který se sdílí.
namePoznamenejte si model aversionz výstupuaz ml model createpříkazu a použijte je s následujícímiaz ml model showpříkazy. Při nasazení modelu do online koncového bodu k odvozování budete potřebovatnamemodel aversionv další části.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
Můžete také použít az ml model list --registry-name <registry-name> k výpisu všech modelů v registru nebo procházení všech komponent v uživatelském rozhraní studio Azure Machine Learning. Ujistěte se, že přejdete do globálního uživatelského rozhraní a vyhledáte centrum Registry.
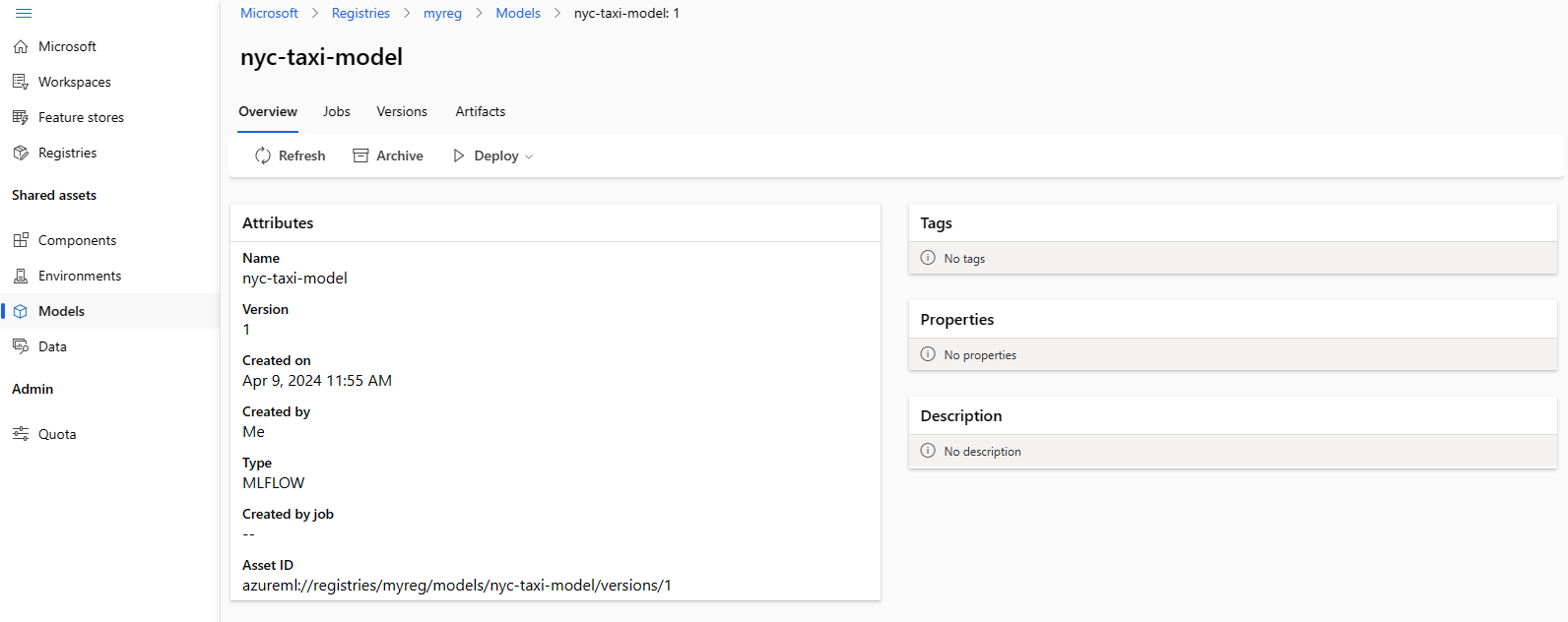
Následující snímek obrazovky ukazuje model v registru v studio Azure Machine Learning. Pokud jste vytvořili model z výstupu úlohy a zkopírovali ho z pracovního prostoru do registru, uvidíte, že model obsahuje odkaz na úlohu, která model natrénovala. Pomocí odkazu můžete přejít na trénovací úlohu a zkontrolovat kód, prostředí a data použitá k trénování modelu.
Nasazení modelu z registru do online koncového bodu v pracovním prostoru
V poslední části nasadíte model z registru do online koncového bodu v pracovním prostoru. Můžete se rozhodnout nasadit libovolný pracovní prostor, ke kterým máte přístup ve vaší organizaci, za předpokladu, že umístění pracovního prostoru je jedním z umístění podporovaných registrem. Tato funkce je užitečná, pokud jste model vytrénovali v dev pracovním prostoru a teď potřebujete model nasadit do pracovního prostoru nebo test do prod pracovního prostoru a současně zachovat informace rodokmenu týkající se kódu, prostředí a dat používaných k trénování modelu.
Online koncové body umožňují nasadit modely a odesílat žádosti o odvozování prostřednictvím rozhraní REST API. Další informace najdete v tématu Nasazení a určení skóre modelu strojového učení pomocí online koncového bodu.
Vytvořte online koncový bod.
az ml online-endpoint create --name reg-ep-1234
model: Aktualizujte řádek deploy.yml dostupný ve cli/jobs/pipelines-with-components/nyc_taxi_data_regression složce tak, aby odkazovat na název a verzi modelu z podrobného kroku. Vytvořte online nasazení do online koncového bodu. Níže deploy.yml je uveden odkaz.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Vytvořte online nasazení. Dokončení nasazení trvá několik minut.
az ml online-deployment create --file deploy.yml --all-traffic
Načtěte identifikátor URI bodování a odešlete ukázkový požadavek na bodování. Ukázková data pro žádost o bodování jsou k dispozici ve scoring-data.jsoncli/jobs/pipelines-with-components/nyc_taxi_data_regression složce.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Návod
-
curlpříkaz funguje jenom v Linuxu. - Pokud jste nenakonfigurovali výchozí pracovní prostor a skupinu prostředků, jak je vysvětleno v části Požadavky, budete muset zadat
--workspace-namea--resource-groupparametry pro fungováníaz ml online-endpointpříkazů aaz ml online-deploymentpříkazů.
Vyčištění prostředků
Pokud nasazení nepoužíváte, měli byste ho odstranit, abyste snížili náklady. Následující příklad odstraní koncový bod a všechna základní nasazení:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait