Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Sledování je proces ukládání relevantních informací o experimentech. V tomto článku se dozvíte, jak používat MLflow pro sledování experimentů a běhů v pracovních prostorech Azure Machine Learning.
Některé metody dostupné v rozhraní API MLflow nemusí být dostupné, když používáte Azure Machine Learning. Pro podrobnosti o podporovaných a nepodporovaných operacích se podívejte na matrici podpory pro dotazování spuštění a experimentů. Informace o podporovaných funkcích MLflow ve službě Azure Machine Learning najdete také v článku MLflow a Azure Machine Learning.
Poznámka:
- Pokud chcete sledovat experimenty spuštěné v Azure Databricks, přečtěte si téma Sledování experimentů strojového učení Azure Databricks pomocí MLflow a Azure Machine Learning.
- Pokud chcete sledovat experimenty spuštěné ve službě Azure Synapse Analytics, přečtěte si téma Sledování experimentů Azure Synapse Analytics ML pomocí MLflow a Azure Machine Learning.
Požadavky
Máte předplatné Azure a bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pokud chcete spouštět příkazy Azure CLI a Pythonu, nainstalujte Azure CLI v2 a sadu Azure Machine Learning SDK v2 pro Python. Rozšíření
mlpro Azure CLI se automaticky nainstaluje při prvním spuštění příkazu Azure Machine Learning CLI.
Nainstalujte balíček MLflow SDK
mlflowa modul plug-in Azure Machine Learningazureml-mlflowpro MLflow:pip install mlflow azureml-mlflowNávod
Můžete použít balíček
mlflow-skinny, který je lehký balíček MLflow bez závislostí na sql storage, serveru, uživatelském rozhraní nebo datové vědě. Tento balíček doporučujeme uživatelům, kteří primárně potřebují funkce sledování a protokolování MLflow, ale ne úplnou sadu funkcí, včetně nasazení.Vytvořte pracovní prostor Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření prostředků, které potřebujete, abyste mohli začít. Zkontrolujte přístupová oprávnění , která potřebujete k provádění operací MLflow ve vašem pracovním prostoru.
Pokud chcete provádět vzdálené sledování nebo sledovat experimenty spuštěné mimo Azure Machine Learning, nakonfigurujte MLflow tak, aby odkazovali na identifikátor URI sledování pracovního prostoru Azure Machine Learning. Další informace o připojení MLflow k pracovnímu prostoru najdete v tématu Konfigurace MLflow pro Azure Machine Learning.
Konfigurace experimentu
MLflow uspořádává informace v experimentech a bězích. Spuštění se nazývají úlohy ve službě Azure Machine Learning. Ve výchozím nastavení se zapisují protokoly do automaticky vytvořeného experimentu s názvem Výchozí, ale můžete určit, který experiment chcete sledovat.
Pro interaktivní trénování, například v poznámkovém bloku Jupyter, použijte příkaz mlflow.set_experiment()MLflow . Například následující fragment kódu konfiguruje experiment:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Konfigurace spuštění
Azure Machine Learning sleduje trénovací úlohy v tom, co MLflow nazývá běhy. Pomocí běhů zaznamenejte veškeré zpracování, které vaše úloha provádí.
Když pracujete interaktivně, MLflow začne sledovat trénovací rutinu hned po protokolování informací, které vyžadují aktivní spuštění. Pokud je například povolená funkce automatického protokolování MLflow, spustí se sledování MLflow při protokolování metriky nebo parametru nebo spuštění trénovacího cyklu.
Obvykle je ale užitečné spustit spuštění explicitně, zejména pokud chcete zachytit celkový čas experimentu v poli Doba trvání . Chcete-li explicitně spustit proces, použijte mlflow.start_run().
Bez ohledu na to, jestli spuštění spustíte ručně nebo ne, budete nakonec muset spuštění zastavit, aby MLflow věděl, že je spuštění experimentu hotové a může označit stav spuštění jako Dokončeno. Chcete-li zastavit spuštění, použijte mlflow.end_run().
Následující kód spustí spuštění ručně a ukončí ho na konci poznámkového bloku:
mlflow.start_run()
# Your code
mlflow.end_run()
Nejlepší je spustit běhy ručně, abyste nezapomněli je ukončit. Paradigma správce kontextu můžete použít k tomu, abyste si vzpomněli na ukončení spuštění.
with mlflow.start_run() as run:
# Your code
Když spustíte nové spuštění pomocí mlflow.start_run(), může být užitečné zadat run_name parametr, který se později přeloží na název spuštění v uživatelském rozhraní služby Azure Machine Learning. Tento postup vám pomůže rychleji identifikovat běh.
with mlflow.start_run(run_name="hello-world-example") as run:
# Your code
Povolte automatické logování MLflow
Metriky, parametry a soubory můžete protokolovat ručně pomocí MLflow a také můžete spoléhat na funkci automatického protokolování MLflow. Každá architektura strojového učení podporovaná MLflow určuje, co se má automaticky sledovat.
Pokud chcete povolit automatické protokolování, vložte před trénovací kód následující kód:
mlflow.autolog()
Zobrazení metrik a artefaktů v pracovním prostoru
Metriky a artefakty z protokolování MLflow se sledují ve vašem pracovním prostoru. Můžete je zobrazit a získat k nim přístup v nástroji Azure Machine Learning Studio nebo k nim přistupovat prostřednictvím kódu programu pomocí sady MLflow SDK.
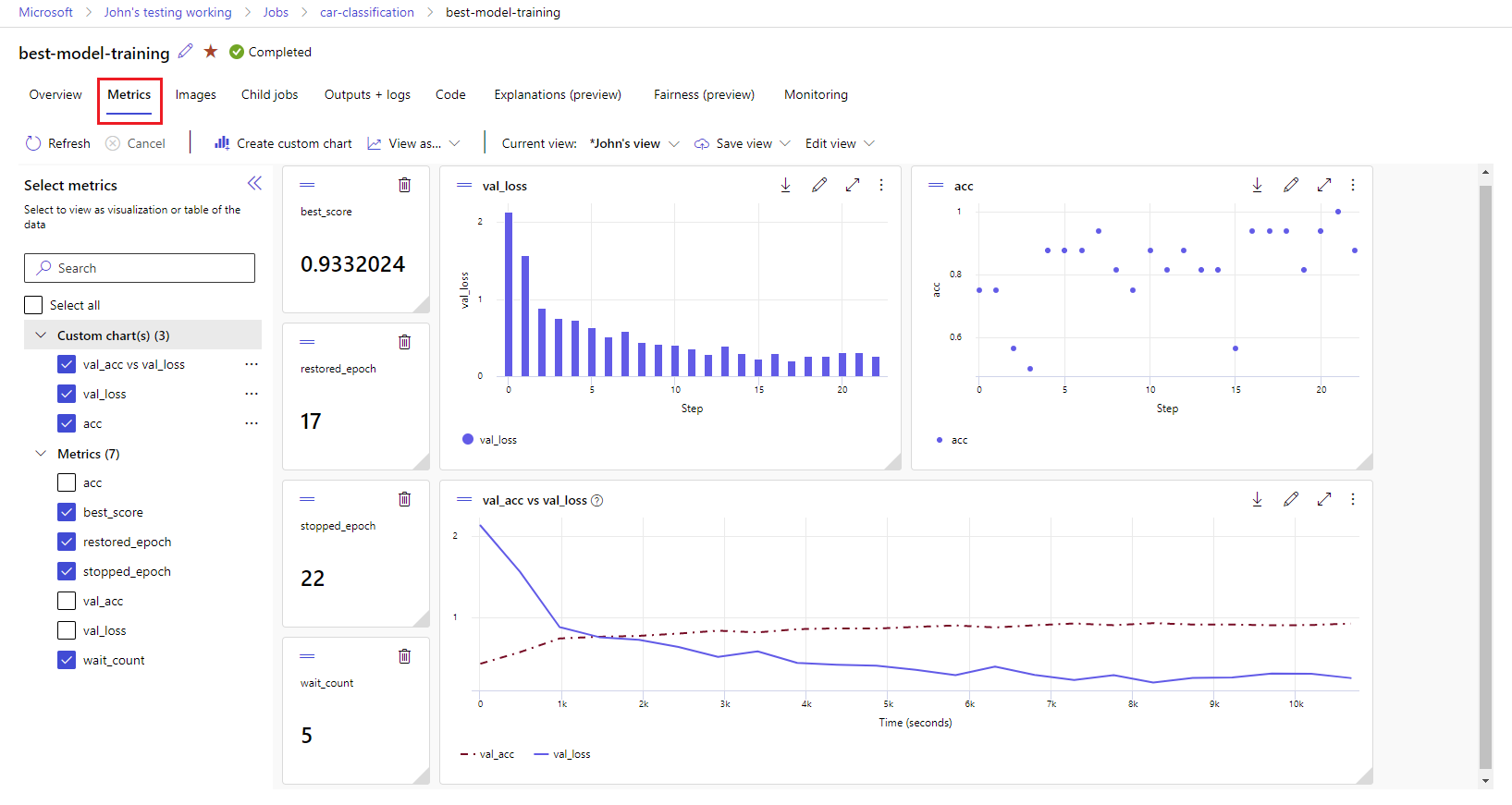
Chcete-li zobrazit metriky a artefakty ve Studiu:
Na stránce Úlohy v pracovním prostoru vyberte název experimentu.
Na stránce podrobností experimentu vyberte kartu Metriky .
Vyberte protokolované metriky pro vykreslení grafů na pravé straně stránky. Grafy můžete přizpůsobit použitím vyhlazení, změnou barvy nebo vykreslením více metrik v jednom grafu. Můžete také změnit velikost a změnit uspořádání rozložení.
Po vytvoření požadovaného zobrazení ho uložte pro budoucí použití a nasdílejte ho s ostatními členy týmu pomocí přímého odkazu.

Pokud chcete získat přístup k metrikám, parametrům a artefaktům prostřednictvím kódu programu pomocí sady MLflow SDK, použijte mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Návod
Předchozí příklad vrátí pouze poslední hodnotu dané metriky. Pokud chcete načíst všechny hodnoty dané metriky, použijte metodu mlflow.get_metric_history . Další informace o načítání hodnot metrik najdete v tématu Získání parametrů a metrik ze spuštění.
Pokud chcete stáhnout artefakty, které jste protokolovali, například soubory a modely, použijte mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Další informace o tom, jak načíst nebo porovnat informace z experimentů a spuštění ve službě Azure Machine Learning pomocí MLflow, najdete v tématu Dotazování a porovnání experimentů a spuštění pomocí MLflow.