konektory Power Query (Preview – vyřazeno)
Důležité
Podpora konektoru Power Query byla představena jako chráněná verze Public Preview v rámci dodatečných podmínek použití pro Microsoft Azure Preview, ale nyní se ukončila. Pokud máte řešení vyhledávání, které používá konektor Power Query, proveďte migraci na alternativní řešení.
Migrace do 28. listopadu 2022
Verze Preview konektoru Power Query byla oznámena v květnu 2021 a nebude pokračovat ve všeobecné dostupnosti. Pro Snowflake a PostgreSQL jsou k dispozici následující pokyny k migraci. Pokud používáte jiný konektor a potřebujete pokyny k migraci, použijte e-mailové kontaktní informace uvedené v registraci ve verzi Preview a požádejte o pomoc nebo otevřete lístek podpory Azure.
Požadavky
- Účet služby Azure Storage. Pokud ho nemáte, vytvořte si účet úložiště.
- Azure Data Factory. Pokud ho nemáte, vytvořte si Data Factory. Informace o souvisejících nákladech najdete v tématu Ceny kanálů služby Data Factory před implementací. Projděte si také ceny služby Data Factory prostřednictvím příkladů.
Migrace datového kanálu Snowflake
Tato část vysvětluje, jak zkopírovat data z databáze Snowflake do indexu Azure Cognitive Search. Neexistuje žádný proces pro přímé indexování ze Snowflake do Azure Cognitive Search, takže tato část obsahuje přípravnou fázi, která kopíruje obsah databáze do kontejneru objektů blob služby Azure Storage. Pak indexujete z přípravného kontejneru pomocí kanálu Služby Data Factory.
Krok 1: Načtení informací o databázi Snowflake
Přejděte na Snowflake a přihlaste se ke svému účtu Snowflake. Účet Snowflake vypadá jako https://< account_name.snowflakecomputing.com>.
Po přihlášení shromážděte v levém podokně následující informace. Tyto informace použijete v dalším kroku:
- V části Data vyberte Databáze a zkopírujte název zdroje databáze.
- V Správa vyberte Uživatelé & Role a zkopírujte jméno uživatele. Ujistěte se, že má uživatel oprávnění ke čtení.
- V Správa vyberte Účty a zkopírujte hodnotu LOCATOR účtu.
- Z adresy URL Snowflake, podobně jako
https://app.snowflake.com/<region_name>/xy12345/organization). zkopírujte název oblasti. Například vhttps://app.snowflake.com/south-central-us.azure/xy12345/organizationsouboru jesouth-central-us.azurenázev oblasti . - V Správa vyberte Sklady a zkopírujte název skladu přidruženého k databázi, kterou použijete jako zdroj.
Krok 2: Konfigurace propojené služby Snowflake
Přihlaste se k Azure Data Factory Studio pomocí svého účtu Azure.
Vyberte datová továrna a pak vyberte Pokračovat.
V nabídce vlevo vyberte ikonu Spravovat .

V části Propojené služby vyberte Nový.

V pravém podokně ve vyhledávání v úložišti dat zadejte "snowflake". Vyberte dlaždici Snowflake a pak Pokračovat.

Vyplňte formulář Nová propojená služba daty, která jste shromáždili v předchozím kroku. Název účtu obsahuje hodnotu LOCATOR a oblast (například ).
xy56789south-central-us.azure
Po dokončení formuláře vyberte Test připojení.
Pokud je test úspěšný, vyberte Vytvořit.
Krok 3: Konfigurace datové sady Snowflake
V nabídce vlevo vyberte ikonu Autor .
Vyberte Datové sady a pak vyberte nabídku Akce datových sad se třemi tečkami (
...).
Vyberte Nová datová sada.

V pravém podokně ve vyhledávání v úložišti dat zadejte "snowflake". Vyberte dlaždici Snowflake a pak Pokračovat.

V části Nastavit vlastnosti:
- Vyberte propojenou službu, kterou jste vytvořili v kroku 2.
- Vyberte tabulku, kterou chcete importovat, a pak vyberte OK.

Vyberte Uložit.
Krok 4: Vytvoření nového indexu v Azure Cognitive Search
Ve službě Azure Cognitive Search vytvořte nový index se stejným schématem, jaký jste aktuálně nakonfigurovali pro data Snowflake.
Index, který aktuálně používáte pro konektor Snowflake Power Connector, můžete změnit účel. V Azure Portal vyhledejte index a pak vyberte Definice indexu (JSON). Vyberte definici a zkopírujte ji do textu nového požadavku na index.

Krok 5: Konfigurace propojené služby Azure Cognitive Search
V nabídce vlevo vyberte Spravovat ikona.
V části Propojené služby vyberte Nový.
V pravém podokně zadejte do vyhledávání v úložišti dat "search". Vyberte dlaždici Azure Search a pak Pokračovat.

Vyplňte hodnoty Nová propojená služba :
- Zvolte předplatné Azure, ve kterém se nachází vaše služba Azure Cognitive Search.
- Zvolte službu Azure Cognitive Search, která má indexer konektoru Power Query.
- Vyberte Vytvořit.

Krok 6: Konfigurace datové sady Azure Cognitive Search
V nabídce vlevo vyberte Možnost Vytvořit ikona.
Vyberte Datové sady a pak vyberte nabídku Akce datových sad se třemi tečkami (
...).
Vyberte Nová datová sada.
V pravém podokně zadejte do vyhledávání v úložišti dat "search". Vyberte dlaždici Azure Search a pak Pokračovat.

V části Nastavit vlastnosti:
Vyberte Uložit.
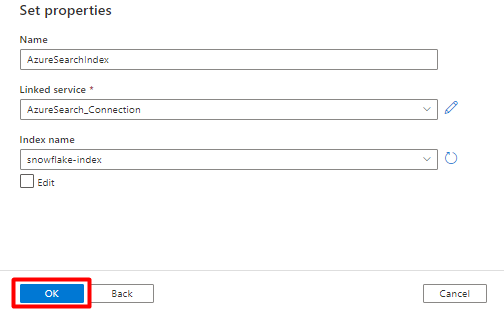
Krok 7: Konfigurace propojené služby Azure Blob Storage
V nabídce vlevo vyberte Spravovat ikona.
V části Propojené služby vyberte Nový.
V pravém podokně do vyhledávání v úložišti dat zadejte "storage". Vyberte dlaždici Azure Blob Storage a vyberte Pokračovat.

Vyplňte nové hodnoty propojené služby :
Zvolte Typ ověřování: IDENTIFIKÁTOR URI SAS. Pouze tento typ ověřování lze použít k importu dat ze Snowflake do Azure Blob Storage.
Vygenerujte adresu URL SAS pro účet úložiště, který budete používat k přípravě. Vložte adresu URL SAS objektu blob do pole ADRESA URL SAS.
Vyberte Vytvořit.

Krok 8: Konfigurace datové sady úložiště
V nabídce vlevo vyberte Ikona Autor .
Vyberte Datové sady a pak vyberte nabídku Se třemi tečkami () Akce datových sad (
...).
Vyberte Nová datová sada.
V pravém podokně do vyhledávání v úložišti dat zadejte "storage". Vyberte dlaždici Azure Blob Storage a vyberte Pokračovat.

Vyberte Formát oddělovačeText a vyberte Pokračovat.
V části Nastavit vlastnosti:
V části Propojená služba vyberte propojenou službu vytvořenou v kroku 7.
V části Cesta k souboru zvolte kontejner, který bude jímkou pro přípravný proces, a vyberte OK.

V oddělovači řádků vyberte Kanál řádků (\n).
Zaškrtněte políčko První řádek jako záhlaví .
Vyberte Uložit.

Krok 9: Konfigurace kanálu
V nabídce vlevo vyberte Ikona Autor .
Vyberte Pipelines (Kanály) a pak vyberte nabídku Se třemi tečkami () Akce kanálů (
...).
Vyberte Nový kanál.

Vytvořte a nakonfigurujte aktivity služby Data Factory , které kopírují ze Snowflake do kontejneru Azure Storage:
Rozbalte přesunout & transformační oddíl a přetáhněte aktivitu Kopírování dat na prázdné plátno editoru kanálu.

Otevřete kartu Obecné . Přijměte výchozí hodnoty, pokud nepotřebujete přizpůsobit provádění.
Na kartě Zdroj vyberte tabulku Snowflake. U zbývajících možností ponechte výchozí hodnoty.

Na kartě Jímka :
Vyberte Datová sada s oddělovači úložištěText vytvořená v kroku 8.
Do pole Přípona souboru přidejte .csv.
U zbývajících možností ponechte výchozí hodnoty.

Vyberte Uložit.
Nakonfigurujte aktivity, které kopírují z objektu blob služby Azure Storage do indexu vyhledávání:
Rozbalte přesunout & transformační oddíl a přetáhněte aktivitu Kopírování dat na prázdné plátno editoru kanálu.

Na kartě Obecné přijměte výchozí hodnoty, pokud nepotřebujete přizpůsobit provádění.
Na kartě Zdroj :
- Vyberte Datová sada s oddělovači úložištěText vytvořená v kroku 8.
- V poli Typ cesty k souboru vyberte Cesta k souboru se zástupným znakem.
- Ve všech zbývajících polích ponechte výchozí hodnoty.
Na kartě Jímka vyberte index Azure Cognitive Search. U zbývajících možností ponechte výchozí hodnoty.

Vyberte Uložit.
Krok 10: Konfigurace pořadí aktivit
V editoru plátna kanálu vyberte malý zelený čtverec na okraji dlaždice aktivity kanálu. Přetažením do aktivity Indexy z účtu úložiště do Azure Cognitive Search nastavte pořadí provádění.
Vyberte Uložit.

Krok 11: Přidání triggeru kanálu
Výběrem možnosti Přidat trigger naplánujte spuštění kanálu a vyberte Nový/Upravit.

V rozevíracím seznamu Zvolit trigger vyberte Nový.

Zkontrolujte možnosti triggeru pro spuštění kanálu a vyberte OK.

Vyberte Uložit.
Vyberte Publikovat.

Migrace datového kanálu PostgreSQL
Tato část vysvětluje, jak zkopírovat data z databáze PostgreSQL do indexu Azure Cognitive Search. Neexistuje žádný proces pro přímé indexování z PostgreSQL do Azure Cognitive Search, takže tato část obsahuje přípravnou fázi, která kopíruje obsah databáze do kontejneru objektů blob služby Azure Storage. Pak indexujete z přípravného kontejneru pomocí kanálu Data Factory.
Krok 1: Konfigurace propojené služby PostgreSQL
Přihlaste se k Azure Data Factory Studio pomocí svého účtu Azure.
Zvolte data factory a vyberte Pokračovat.
V nabídce vlevo vyberte ikonu Spravovat .
V části Propojené služby vyberte Nový.
V pravém podokně zadejte do hledání v úložišti dat "postgresql". Vyberte dlaždici PostgreSQL , která představuje umístění databáze PostgreSQL (Azure nebo jiné) a vyberte Pokračovat. V tomto příkladu se databáze PostgreSQL nachází v Azure.

Vyplňte nové hodnoty propojené služby :
V části Metoda výběru účtu vyberte Zadat ručně.
Na stránce Přehled Azure Database for PostgreSQL v Azure Portal vložte do příslušných polí následující hodnoty:
- Přidejte název serveru do plně kvalifikovaného názvu domény.
- Přidejte uživatelské jméno Správa do pole Uživatelské jméno.
- Přidat databázi do názvu databáze.
- Do pole Uživatelské jméno zadejte Správa uživatelské jméno.
- Vyberte Vytvořit.

Krok 2: Konfigurace datové sady PostgreSQL
V nabídce vlevo vyberte Možnost Vytvořit ikona.
Vyberte Datové sady a pak vyberte nabídku Akce datových sad se třemi tečkami (
...).
Vyberte Nová datová sada.
V pravém podokně zadejte do vyhledávání v úložišti dat "postgresql". Vyberte dlaždici Azure PostgreSQL . Vyberte Pokračovat.

Vyplňte hodnoty Nastavit vlastnosti :
Zvolte propojenou službu PostgreSQL vytvořenou v kroku 1.
Vyberte tabulku, kterou chcete importovat nebo indexovat.
Vyberte OK.

Vyberte Uložit.
Krok 3: Vytvoření nového indexu v Azure Cognitive Search
Ve službě Azure Cognitive Search vytvořte nový index se stejným schématem, jaký používáte pro data PostgreSQL.
Index, který aktuálně používáte pro power connector PostgreSQL, můžete změnit účel. V Azure Portal vyhledejte index a pak vyberte Definice indexu (JSON). Vyberte definici a zkopírujte ji do textu nového požadavku na index.

Krok 4: Konfigurace propojené služby Azure Cognitive Search
V nabídce vlevo vyberte ikonu Spravovat .
V části Propojené služby vyberte Nový.
V pravém podokně zadejte do vyhledávání v úložišti dat "search". Vyberte dlaždici Azure Search a pak Pokračovat.
Vyplňte hodnoty Nová propojená služba :
- Zvolte předplatné Azure, ve kterém se nachází vaše služba Azure Cognitive Search.
- Zvolte službu Azure Cognitive Search, která má indexer konektoru Power Query.
- Vyberte Vytvořit.
Krok 5: Konfigurace datové sady Azure Cognitive Search
V nabídce vlevo vyberte Možnost Vytvořit ikona.
Vyberte Datové sady a pak vyberte nabídku Akce datových sad se třemi tečkami (
...).
Vyberte Nová datová sada.
V pravém podokně zadejte do vyhledávání v úložišti dat "search". Vyberte dlaždici Azure Search a pak Pokračovat.
V části Nastavit vlastnosti:
Vyberte Uložit.
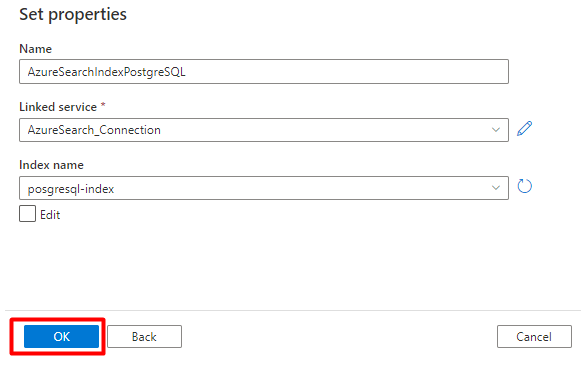
Krok 6: Konfigurace propojené služby Azure Blob Storage
V nabídce vlevo vyberte Spravovat ikona.
V části Propojené služby vyberte Nový.
V pravém podokně ve vyhledávání v úložišti dat zadejte "úložiště". Vyberte dlaždici Azure Blob Storage a vyberte Pokračovat.
Vyplňte hodnoty Nová propojená služba :
Zvolte Typ ověřování: IDENTIFIKÁTOR URI SAS. Pouze tuto metodu lze použít k importu dat z PostgreSQL do Azure Blob Storage.
Vygenerujte adresu URL SAS pro účet úložiště, který budete používat k přípravě, a zkopírujte pole Adresa URL SAS objektu blob do adresy URL SAS.
Vyberte Vytvořit.

Krok 7: Konfigurace datové sady úložiště
V nabídce vlevo vyberte Možnost Vytvořit ikona.
Vyberte Datové sady a pak vyberte nabídku Akce datových sad se třemi tečkami (
...).
Vyberte Nová datová sada.
V pravém podokně ve vyhledávání v úložišti dat zadejte "úložiště". Vyberte dlaždici Azure Blob Storage a vyberte Pokračovat.
Vyberte Formát s oddělovačiText a vyberte Pokračovat.
V části Oddělovač řádků vyberte Odřádkování (\n).
Zaškrtněte políčko První řádek jako záhlaví .
Vyberte Uložit.

Krok 8: Konfigurace kanálu
V nabídce vlevo vyberte Možnost Vytvořit ikona.
Vyberte Pipelines (Kanály) a pak vyberte nabídku Pipelines Actions () se třemi tečkami (
...).
Vyberte Nový kanál.
Vytvořte a nakonfigurujte aktivity služby Data Factory , které kopírují z PostgreSQL do kontejneru Azure Storage.
Rozbalte část Přesunout & transformaci a přetáhněte aktivitu kopírování dat na plátno prázdného editoru kanálu.

Otevřete kartu Obecné a přijměte výchozí hodnoty, pokud nepotřebujete upravit provádění.
Na kartě Zdroj vyberte tabulku PostgreSQL. U zbývajících možností ponechte výchozí hodnoty.

Na kartě Jímka :
Vyberte datovou sadu Storage DelimitedText PostgreSQL nakonfigurovanou v kroku 7.
Do pole Přípona souboru přidejte .csv
U zbývajících možností ponechte výchozí hodnoty.

Vyberte Uložit.
Nakonfigurujte aktivity, které kopírují z Azure Storage do indexu vyhledávání:
Rozbalte část Přesunout & transformaci a přetáhněte aktivitu kopírování dat na plátno prázdného editoru kanálu.

Na kartě Obecné ponechte výchozí hodnoty, pokud nepotřebujete přizpůsobit provádění.
Na kartě Zdroj :
- Vyberte zdrojovou datovou sadu úložiště nakonfigurovanou v kroku 7.
- V poli Typ cesty k souboru vyberte Cesta k souboru se zástupným znakem.
- Ve všech zbývajících polích ponechte výchozí hodnoty.

Na kartě Jímka vyberte index Azure Cognitive Search. U zbývajících možností ponechte výchozí hodnoty.

Vyberte Uložit.
Krok 9: Konfigurace pořadí aktivit
V editoru plátna kanálu vyberte malý zelený čtvereček na okraji aktivity kanálu. Přetažením do aktivity Indexy z účtu úložiště do Azure Cognitive Search nastavíte pořadí provádění.
Vyberte Uložit.

Krok 10: Přidání triggeru kanálu
Výběrem možnosti Přidat trigger naplánujte spuštění kanálu a vyberte Nový/Upravit.

V rozevíracím seznamu Zvolit aktivační událost vyberte Nový.
Zkontrolujte možnosti triggeru pro spuštění kanálu a vyberte OK.

Vyberte Uložit.
Vyberte Publikovat.

Starší verze obsahu pro verzi Preview konektoru Power Query
Konektor Power Query se používá spolu s indexerem vyhledávání k automatizaci příjmu dat z různých zdrojů dat, včetně těch od jiných poskytovatelů cloudu. K načtení dat používá Power Query.
Mezi podporované zdroje dat ve verzi Preview patří:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Objekty Salesforce
- Sestavy Salesforce
- Smartsheet
- Snowflake
Podporované funkce
Power Query konektory se používají v indexerech. Indexer v Azure Cognitive Search je prohledávací modul, který extrahuje prohledávatelná data a metadata z externího zdroje dat a naplní index na základě mapování pole na pole mezi indexem a zdrojem dat. Tento přístup se někdy označuje jako model vyžádání obsahu, protože služba načítá data, aniž byste museli psát kód, který přidá data do indexu. Indexery poskytují uživatelům pohodlný způsob, jak indexovat obsah ze zdroje dat, aniž by museli psát vlastní prohledávací modul nebo model nabízení.
Indexery, které odkazují Power Query zdroje dat, mají stejnou úroveň podpory sad dovedností, plánů, logiky detekce změn s vysokou hladinou a většinu parametrů, které podporují ostatní indexery.
Požadavky
I když už tuto funkci nemůžete používat, měla ve verzi Preview následující požadavky:
Azure Cognitive Search službu v podporované oblasti.
Registrace verze Preview. Tato funkce musí být povolená na back-endu.
Azure Blob Storage účet, který slouží jako zprostředkovatel vašich dat. Data budou proudit z vašeho zdroje dat, pak do Blob Storage a pak do indexu. Tento požadavek existuje pouze u počátečního chráněného náhledu.
Regionální dostupnost
Verze Preview byla k dispozici pouze u vyhledávacích služeb v následujících oblastech:
- Střední USA
- East US
- USA – východ 2
- USA – středosever
- Severní Evropa
- Středojižní USA
- USA – středozápad
- West Europe
- USA – západ
- Západní USA 2
Omezení verze Preview
Tato část popisuje omezení, která jsou specifická pro aktuální verzi Preview.
Načítání binárních dat ze zdroje dat se nepodporuje.
Ladicí relace se nepodporuje.
Začínáme používat Azure Portal
Azure Portal poskytuje podporu pro konektory Power Query. Pomocí vzorkování dat a čtení metadat v kontejneru může Průvodce importem dat v Azure Cognitive Search vytvořit výchozí index, mapovat zdrojová pole na cílová pole indexu a načíst index v rámci jedné operace. V závislosti na velikosti a složitosti zdrojových dat můžete mít provozní index fulltextového vyhledávání v řádu minut.
Následující video ukazuje, jak nastavit konektor Power Query v Azure Cognitive Search.
Krok 1 – Příprava zdrojových dat
Ujistěte se, že zdroj dat obsahuje data. Průvodce importem dat čte metadata a provádí vzorkování dat k odvození schématu indexu, ale také načte data ze zdroje dat. Pokud data chybí, průvodce se zastaví a vrátí chybu.
Krok 2 – Spuštění průvodce importem dat
Po schválení verze Preview vám tým Azure Cognitive Search poskytne odkaz na Azure Portal, který používá příznak funkce, abyste měli přístup ke konektorům Power Query. Otevřete tuto stránku a výběrem možnosti Importovat data spusťte průvodce z panelu příkazů na stránce Azure Cognitive Search služby.
Krok 3 – Výběr zdroje dat
V této verzi Preview můžete získat data z několika zdrojů dat. Všechny zdroje dat, které používají Power Query, budou na dlaždici obsahovat Power Query Využívající technologii. Vyberte zdroj dat.

Po výběru zdroje dat vyberte Další: Konfigurace dat a přejděte k další části.
Krok 4 – Konfigurace dat
V tomto kroku nakonfigurujete připojení. Každý zdroj dat bude vyžadovat jiné informace. Další podrobnosti o tom, jak se připojit k datům, najdete v dokumentaci k Power Query.
Po zadání přihlašovacích údajů pro připojení vyberte Další.
Krok 5 – Výběr dat
Průvodce importem zobrazí náhled různých tabulek, které jsou dostupné ve vašem zdroji dat. V tomto kroku zkontrolujete jednu tabulku obsahující data, která chcete importovat do indexu.

Po výběru tabulky vyberte Další.
Krok 6 – Transformace dat (volitelné)
Power Query konektory poskytují bohaté uživatelské rozhraní, které umožňuje manipulovat s daty, abyste mohli do indexu odesílat správná data. Můžete odebrat sloupce, filtrovat řádky a mnoho dalšího.
Před importem do Azure Cognitive Search není nutné data transformovat.

Další informace o transformaci dat pomocí Power Query najdete v tématu Použití Power Query v Power BI Desktop.
Po transformaci dat vyberte Další.
Krok 7 – Přidání úložiště objektů blob v Azure
Konektor Power Query Preview v současné době vyžaduje, abyste zadali účet úložiště objektů blob. Tento krok existuje pouze u počátečního chráněného náhledu. Tento účet úložiště objektů blob bude sloužit jako dočasné úložiště pro data, která se přesunou ze zdroje dat do indexu Azure Cognitive Search.
Doporučujeme poskytnout účet úložiště s úplným přístupem připojovací řetězec:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Připojovací řetězec můžete získat z Azure Portal tak, že přejdete do okna > Nastavení > účtu úložiště Klíče (pro účty úložiště Classic) nebo Přístupové klíče nastavení > (pro účty úložiště Azure Resource Manager).
Po zadání názvu zdroje dat a připojovací řetězec vyberte Další: Přidat kognitivní dovednosti (volitelné).
Krok 8 – přidání kognitivních dovedností (volitelné)
Rozšíření AI je rozšíření indexerů, které se dají použít k lepšímu vyhledávání obsahu.
Můžete přidat jakékoli obohacení, které vašemu scénáři přidají výhodu. Po dokončení vyberte Další: Přizpůsobit cílový index.
Krok 9 – Přizpůsobení cílového indexu
Na stránce Index byste měli vidět seznam polí s datovým typem a řadu zaškrtávacích políček pro nastavení atributů indexu. Průvodce může vygenerovat seznam polí na základě metadat a vzorkováním zdrojových dat.
Atributy můžete hromadně vybrat tak, že zaškrtnete políčko v horní části sloupce atributu. Pro všechna pole, která se mají vrátit do klientské aplikace a která mají být předmětem zpracování fulltextového vyhledávání, zvolte Možnost Načítání a Prohledávatelné. Všimněte si, že celá čísla nejsou fulltextová nebo přibližná prohledávatelná (čísla se vyhodnocují doslovně a často jsou užitečná ve filtrech).
Další informace najdete v popisu atributů indexu a analyzátorů jazyka.
Udělejte si chvilku a zkontrolujte své výběry. Po spuštění průvodce se vytvoří fyzické datové struktury a nebudete moct upravovat většinu vlastností těchto polí bez vyřazení a opětovného vytvoření všech objektů.

Po dokončení vyberte Další: Vytvořit indexer.
Krok 10 – vytvoření indexeru
Poslední krok vytvoří indexer. Pojmenování indexeru umožňuje, aby existoval jako samostatný prostředek, který můžete naplánovat a spravovat nezávisle na indexu a objektu zdroje dat vytvořeném ve stejné sekvenci průvodce.
Výstupem Průvodce importem dat je indexer, který prochází zdroj dat a importuje vybraná data do indexu na Azure Cognitive Search.
Při vytváření indexeru můžete volitelně zvolit spuštění indexeru podle plánu a přidat detekci změn. Pokud chcete přidat detekci změn, určete sloupec "vysoká značka vody".

Po vyplnění této stránky vyberte Odeslat.
Zásady detekce vysokých znamék změn
Tato zásada detekce změn závisí na sloupci "vysoká značka vody", který zachycuje verzi nebo čas poslední aktualizace řádku.
Požadavky
- Všechna vložení určují hodnotu sloupce.
- Všechny aktualizace položky také změní hodnotu sloupce.
- Hodnota tohoto sloupce se zvyšuje s každým vložením nebo aktualizací.
Nepodporované názvy sloupců
Názvy polí v indexu Azure Cognitive Search musí splňovat určité požadavky. Jedním z těchto požadavků je, že některé znaky, jako je "/", nejsou povolené. Pokud název sloupce v databázi nesplňuje tyto požadavky, detekce schématu indexu nerozpozná váš sloupec jako platný název pole a neuvidíte tento sloupec uvedený jako navrhované pole pro váš index. Za normálních okolností by tento problém vyřešilo použití mapování polí , ale mapování polí se na portálu nepodporuje.
Pokud chcete indexovat obsah ze sloupce v tabulce, který má nepodporovaný název pole, přejmenujte sloupec během fáze transformace dat v procesu importu dat. Sloupec s názvem Fakturační kód nebo PSČ můžete například přejmenovat na PSČ. Přejmenováním sloupce ho detekce schématu indexu rozpozná jako platný název pole a přidá ho jako návrh do definice indexu.
Další kroky
Tento článek vysvětluje, jak vyžádat data pomocí konektorů Power Query. Vzhledem k tomu, že tato funkce Preview je ukončena, vysvětluje také, jak migrovat existující řešení do podporovaného scénáře.
Další informace o indexerech najdete v tématu Indexery v Azure Cognitive Search.