Vytvoření indexeru ve službě Azure AI Search
Pomocí indexeru můžete automatizovat import a indexování dat ve službě Azure AI Search. Indexer je pojmenovaný objekt ve vyhledávací službě, který se připojuje k externímu zdroji dat Azure, čte data a předává ho do vyhledávacího webu pro indexování. Použití indexerů výrazně snižuje množství a složitost kódu, který potřebujete napsat, pokud používáte podporovaný zdroj dat.
Indexery podporují dva pracovní postupy:
Indexování založené na textu, extrakce řetězců a metadat z textového obsahu pro scénáře fulltextového vyhledávání
Indexování založené na dovednostech s využitím předdefinovaných nebo vlastních dovedností, které přidávají integrované strojové učení pro analýzu obrázků a rozsáhlého nezájmového obsahu, extrahování nebo odvozování textu a struktury. Indexování založené na dovednostech umožňuje prohledávat obsah, který není jinak snadno prohledávatelný fulltext. Další informace najdete v tématu Rozšiřování AI ve službě Azure AI Search.
Tento článek se zaměřuje na základní kroky vytvoření indexeru. V závislosti na zdroji dat a pracovním postupu může být potřeba další konfigurace.
Požadavky
Podporovaný zdroj dat obsahující obsah, který chcete ingestovat.
Zdroj dat indexeru, který nastaví připojení k externím datům.
Index vyhledávání, který může přijímat příchozí data.
Buďte pod maximálními limity pro vaši úroveň služby. Úroveň Free umožňuje tři objekty každého typu a 1–3 minuty zpracování indexeru nebo 3–10, pokud existuje sada dovedností.
Vzory indexeru
Při vytváření indexeru je definice jedním ze dvou vzorů: indexování na základě textu nebo rozšiřování AI o dovednosti. Vzory jsou stejné, s tím rozdílem, že indexování založené na dovednostech má více definic.
Příklad indexeru pro indexování na základě textu
Indexování založené na textu pro fulltextové vyhledávání je primárním případem použití indexerů a pro tento pracovní postup indexer vypadá jako v tomto příkladu.
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
Indexery mají následující požadavky:
- Vlastnost
"name", která jednoznačně identifikuje indexer v kolekci indexeru. "dataSourceName"Vlastnost, která odkazuje na objekt zdroje dat. Určuje připojení k externím datům.- Vlastnost
"targetIndexName", která odkazuje na cílový index vyhledávání.
Další parametry jsou volitelné a upravují chování doby běhu, jako je například počet chyb, které se mají přijmout před selháním celé úlohy. Požadované parametry jsou zadány ve všech indexerech a jsou zdokumentované v referenčních informacích k rozhraní REST API.
Indexery specifické pro zdroje dat pro objekty blob, SQL a Azure Cosmos DB poskytují další "configuration" parametry pro chování specifické pro zdroj. Pokud je zdrojem například Blob Storage, můžete nastavit parametr, který filtruje přípony souborů: "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } }. Pokud je zdrojem Azure SQL, můžete nastavit parametr časového limitu dotazu.
Mapování polí se používají k explicitnímu mapování zdrojových a cílových polí v případě nesrovnalostí podle názvu nebo typu mezi polem ve zdroji dat a polem v indexu vyhledávání.
Ve výchozím nastavení se indexer spustí okamžitě, když ho vytvoříte ve vyhledávací službě. Pokud nechcete provádět indexer, nastavte "disabled" při vytváření indexeru hodnotu true.
Můžete také zadat plán nebo nastavit šifrovací klíč pro doplňkové šifrování definice indexeru.
Příklad indexeru pro indexování založené na dovednostech
Indexery také řídí rozšiřování AI. Všechny výše uvedené vlastnosti a parametry pro použití, ale následující dodatečné vlastnosti jsou specifické pro rozšiřování AI: "skillSetName", , "cache""outputFieldMappings".
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
Rozšiřování AI je vlastní předmětnou oblastí a je mimo rozsah tohoto článku. Pokud potřebujete další informace, začněte rozšiřováním AI, sadami dovedností ve službě Azure AI Search, vytvořte sadu dovedností, výstupní pole pro rozšiřování map a povolte ukládání do mezipaměti pro rozšiřování AI.
Příprava externích dat
Indexery pracují s datovými sadami. Když spustíte indexer, připojí se ke zdroji dat, načte data z kontejneru nebo složky, volitelně je serializuje do formátu JSON před předáním do vyhledávacího webu pro indexování. Tato část popisuje požadavky příchozích dat pro indexování na základě textu.
| Zdrojová data | Úlohy |
|---|---|
| Dokumenty JSON | Ujistěte se, že struktura nebo tvar příchozích dat odpovídá schématu indexu vyhledávání. Většina indexů vyhledávání je poměrně plochá, kde kolekce polí se skládá z polí na stejné úrovni. Hierarchické nebo vnořené struktury jsou však možné prostřednictvím složitých polí a kolekcí. |
| Relační | Zadejte ho jako zploštěnou sadu řádků, kde se každý řádek stane úplným nebo částečným vyhledávacím dokumentem v indexu. Pokud chcete zploštět relační data do sady řádků, měli byste vytvořit zobrazení SQL nebo vytvořit dotaz, který vrátí nadřazené a podřízené záznamy ve stejném řádku. Ukázková datová sada předdefinovaných hotelů je například databáze SQL, která má 50 záznamů (jednu pro každý hotel), propojenou se záznamy místností v související tabulce. Dotaz, který zploštějí souhrnná data do sady řádků, vloží všechny informace o místnosti do dokumentů JSON do každého záznamu hotelu. Vložené informace o místnosti jsou vygenerované dotazem, který používá klauzuli FOR JSON AUTO . Další informace o této technice najdete v definování dotazu, který vrací vložený JSON. Toto je jen jeden příklad; můžete najít další přístupy, které vytvoří stejný výsledek. |
| Soubory | Indexer obvykle vytvoří jeden vyhledávací dokument pro každý soubor, kde se prohledávací dokument skládá z polí pro obsah a metadata. V závislosti na typu souboru může indexer někdy analyzovat jeden soubor do více vyhledávacích dokumentů. Například v souboru CSV se každý řádek může stát samostatným vyhledávacím dokumentem. |
Mějte na paměti, že potřebujete načíst pouze prohledávatelná a filtrovatelná data:
- Prohledávatelná data jsou text.
- Filtrovatelná data jsou alfanumerická.
Azure AI Search nemůže prohledávat binární data v žádném formátu, i když dokáže extrahovat a odvodit textové popisy souborů obrázků (viz obohacení AI) a vytvořit prohledávatelný obsah. Podobně lze velký text rozdělit a analyzovat pomocí modelů přirozeného jazyka a najít strukturu nebo relevantní informace a generovat nový obsah, který můžete přidat do hledaného dokumentu.
Vzhledem k tomu, že indexery neřeší problémy s daty, můžou být potřeba jiné formy čištění nebo manipulace s daty. Další informace najdete v dokumentaci k produktu databázového produktu Azure.
Příprava zdroje dat
Indexery vyžadují zdroj dat, který určuje typ, kontejner a připojení.
Ujistěte se, že používáte podporovaný typ zdroje dat.
Vytvořte definici zdroje dat. Následující seznam obsahuje několik nejčastěji používaných zdrojů dat:
Pokud je zdrojem dat databáze, jako je Azure SQL nebo Cosmos DB, povolte sledování změn. Azure Storage má integrované sledování změn prostřednictvím
LastModifiedvlastnosti pro každý objekt blob, soubor a tabulku. Výše uvedené odkazy pro různé zdroje dat vysvětlují, které metody sledování změn jsou podporovány indexery.
Příprava indexu
Indexery také vyžadují index vyhledávání. Vzpomeňte si, že indexery předávají data do vyhledávacího webu pro indexování. Stejně jako indexery mají vlastnosti, které určují chování provádění, schéma indexu má vlastnosti, které hluboce ovlivňují způsob indexování řetězců (analyzují se a tokenizují pouze řetězce).
Začněte vytvořením indexu vyhledávání.
Nastavte kolekci polí a atributy polí.
Pole jsou jedinými receptory vnějšího obsahu. V závislosti na tom, jak jsou pole přiřazena ve schématu, se hodnoty pro každé pole analyzují, tokenizují nebo ukládají jako doslovné řetězce pro filtry, přibližné vyhledávání a dotazy typu.
Indexery můžou při ekvivalentních názvech a typech automaticky mapovat zdrojová pole na cílová pole indexu. Pokud pole nelze implicitně mapovat, nezapomeňte, že můžete definovat explicitní mapování polí, které indexeru říká, jak směrovat obsah.
Zkontrolujte přiřazení analyzátoru v jednotlivých polích. Analyzátory mohou transformovat řetězce. Proto se indexované řetězce můžou lišit od toho, co jste předali. Účinky analyzátorů můžete vyhodnotit pomocí funkce Analyzovat text (REST). Další informace o analyzátorech naleznete v tématu Analyzátory pro zpracování textu.
Při indexování indexer kontroluje pouze názvy a typy polí. Neexistuje žádný ověřovací krok, který zajistí správnost příchozího obsahu pro odpovídající vyhledávací pole v indexu.
Vytvoření indexeru
Až budete připraveni vytvořit indexer ve vzdálené vyhledávací službě, potřebujete klienta vyhledávání. Vyhledávacím klientem může být Azure Portal, klient REST nebo kód, který vytvoří instanci klienta indexeru. Pro počáteční vývoj a testování konceptu doporučujeme azure Portal nebo rozhraní REST API.
Přihlaste se k portálu Azure.
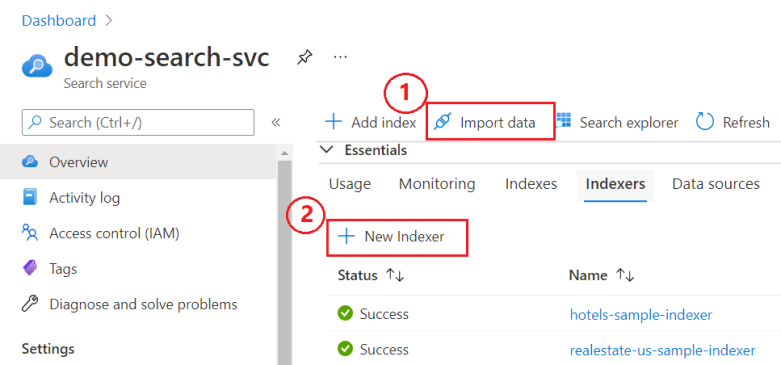
Na stránce Přehled vyhledávací služby vyberte ze dvou možností:
Průvodce importem dat Průvodce je jedinečný v tom, že vytvoří všechny požadované prvky. Jiné přístupy vyžadují předdefinovaný zdroj dat a index.
Nový Indexer, vizuální editor pro zadání definice indexeru.
Následující snímek obrazovky ukazuje, kde najdete tyto funkce na portálu.
Spuštění indexeru
Ve výchozím nastavení se indexer spustí okamžitě, když ho vytvoříte ve vyhledávací službě. Toto chování můžete přepsat nastavením "disabled" na true v definici indexeru. Provádění indexeru je moment pravdy, kde zjistíte, jestli dochází k problémům s propojením, mapováním polí nebo sestavováním sad dovedností.
Indexer můžete spustit několika způsoby:
Spusťte spuštění při vytváření nebo aktualizaci indexeru (výchozí).
Spusťte na vyžádání, pokud nejsou v definici žádné změny, nebo před resetováním pro úplné indexování. Další informace najdete v tématu Spuštění nebo resetování indexerů.
Naplánujte zpracování indexeru pro vyvolání provádění v pravidelných intervalech.
Plánované spouštění se obvykle implementuje, když potřebujete přírůstkové indexování, abyste mohli získat nejnovější změny. Plánování proto závisí na detekci změn.
Indexery jsou jedním z několika subsystémů, které provádějí přesáhlá odchozí volání jiných prostředků Azure. Z hlediska rolí Azure nemají indexery samostatné identity: připojení z vyhledávacího webu k jinému prostředku Azure se provádí pomocí spravované identity přiřazené systémem nebo uživatelem přiřazenou spravovanou identitou vyhledávací služby. Pokud se indexer připojí k prostředku Azure ve virtuální síti, měli byste pro toto připojení vytvořit sdílené privátní propojení . Další informace o zabezpečených připojeních najdete v tématu Zabezpečení ve službě Azure AI Search.
Kontrola výsledků
Monitorujte stav indexeru a zkontrolujte stav. Úspěšné spuštění může stále obsahovat upozornění a oznámení. Nezapomeňte zkontrolovat úspěšná i neúspěšná oznámení o stavu, kde najdete podrobnosti o úloze.
Pro ověření obsahu spusťte dotazy na naplněném indexu, který vrací celé dokumenty nebo vybraná pole.
Detekce změn a vnitřní stav
Pokud váš zdroj dat podporuje detekci změn, může indexer detekovat základní změny v datech a zpracovávat pouze nové nebo aktualizované dokumenty při každém spuštění indexeru a ponechat nezměněný obsah tak, jak je. Pokud historie provádění indexeru říká, že spuštění bylo úspěšné s 0/0 dokumenty zpracované, znamená to, že indexer v podkladovém zdroji dat nenalezl žádné nové nebo změněné řádky nebo objekty blob.
Logika detekce změn je integrovaná do datových platforem. Způsob, jakým indexer podporuje detekci změn, se liší podle zdroje dat:
Azure Storage má integrovanou detekci změn, což znamená, že indexer dokáže rozpoznávat nové a aktualizované dokumenty automaticky. Blob Storage, Azure Table Storage a Azure Data Lake Storage Gen2 označí každou aktualizaci objektu blob nebo řádku datem a časem. Indexer tyto informace automaticky použije k určení dokumentů, které se mají v indexu aktualizovat. Další informace o detekci odstranění najdete v tématu Odstranění detekce pomocí indexerů pro Azure Storage ve službě Azure AI Search.
Cloudové databázové technologie poskytují volitelné funkce detekce změn na svých platformách. U těchto zdrojů dat není detekce změn automatická. Musíte zadat v definici zdroje dat, kterou zásadu použijete:
Indexery sledují poslední dokument, který zpracoval ze zdroje dat, prostřednictvím interní horní meze. Značka se v rozhraní API nikdy nezpřístupní, ale indexer interně sleduje, kde se zastavil. Při indexování se obnoví buď naplánovaným spuštěním, nebo vyvoláním na vyžádání, indexer odkazuje na horní mez, aby mohl pokračovat tam, kde skončil.
Pokud potřebujete vymazat horní značku, která se má přeindexovat úplně, můžete použít resetování indexeru. Pro selektivní přeindexování použijte resetování dovedností nebo resetování dokumentů. Prostřednictvím rozhraní API pro resetování můžete vymazat interní stav a také vyprázdnit mezipaměť, pokud jste povolili přírůstkové rozšiřování. Další pozadí a porovnání jednotlivých možností resetování najdete v tématu Spuštění nebo resetování indexerů, dovedností a dokumentů.
Další kroky
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro