Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak shromažďovat statistiky o kontejnerech pomocí inventáře služby Azure Blob Storage spolu s Azure Databricks.
V tomto návodu se naučíte, jak:
- Vytvořte sestavu inventarizace
- Vytvoření pracovního prostoru a poznámkového bloku Azure Databricks
- Přečtěte inventární soubor blobů
- Získejte počet a celkovou velikost objektů blob, snímků a verzí.
- Získání počtu blobů podle typu blobu a typu obsahu
Prerequisites
Předplatné Azure – vytvoření účtu zdarma
Účet úložiště Azure – vytvoření účtu úložiště
Ujistěte se, že vaše uživatelská identita má přiřazenou roli Storage Blob Data Contributor.
Vytvořte sestavu inventarizace
Povolte pro svůj účet úložiště sestavy inventáře blobů. Viz Povolení sestav inventáře objektů blob služby Azure Storage.
Použijte následující nastavení konfigurace:
| Setting | Value |
|---|---|
| Název pravidla | blobinventory |
| Container | <název kontejneru> |
| Typ objektu pro inventarizaci | Blob |
| Typy objektů blob | Blokové bloby, stránkové bloby a přidávací bloby |
| Subtypes | zahrnout verze blobu, zahrnout snímky, zahrnout smazané bloby |
| Pole inventáře Blob | All |
| Četnost inventáře | Daily |
| Formát exportu | formát CSV |
Možná budete muset počkat až 24 hodin po aktivaci inventurních zpráv, než bude vaše první zpráva vygenerována.
Konfigurace Azure Databricks
V této části vytvoříte pracovní prostor a poznámkový blok Azure Databricks. Později v tomto kurzu vložíte fragmenty kódu do buněk poznámkového bloku a pak je spustíte, aby se shromáždily statistiky kontejneru.
Vytvořte pracovní prostor Azure Databricks. Viz Vytvoření pracovního prostoru Azure Databricks.
Vytvořte nový poznámkový blok. Viz Vytvoření poznámkového bloku.
Jako výchozí jazyk poznámkového bloku zvolte Python.
Přečtěte inventární soubor blobů
Zkopírujte a vložte následující blok kódu do první buňky, ale tento kód zatím nespustíte.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')V tomto bloku kódu nahraďte následující hodnoty:
<storage-account-name>Nahraďte zástupnou hodnotu názvem vašeho účtu úložiště.Nahraďte hodnotu zástupného symbolu
<storage-account-key>klíčem vašeho účtu úložiště.Nahraďte hodnotu zástupného symbolu kontejnerem, který obsahuje zprávy inventáře.
<blob-inventory-file-name>Zástupný text nahraďte plně kvalifikovaným názvem souboru inventáře (například:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).Pokud má váš účet hierarchický obor názvů, nastavte proměnnou
hierarchical_namespace_enablednaTrue.
Stisknutím tlačítka Spustit spusťte kód v této buňce.
Získání počtu a velikosti blobů
Do nové buňky vložte následující kód:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Buňku spustíte stisknutím tlačítka Spustit.
Notebook zobrazuje počet blobů v kontejneru a počet bajtů, které zabírají v tomto kontejneru.

Získání počtu a velikosti snímků
Do nové buňky vložte následující kód:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Buňku spustíte stisknutím tlačítka Spustit.
Sešit zobrazuje počet snímků a celkový počet bajtů obsazených snímky blob.

Získání počtu a velikosti verzí
Do nové buňky vložte následující kód:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Stisknutím kombinace kláves SHIFT+ENTER buňku spusťte.
Poznámkový blok zobrazuje počet verzí objektů blob a celkový počet bajtů obsazených verzemi objektů blob.

Získání počtu objektů podle typu blobu
Do nové buňky vložte následující kód:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Stisknutím kombinace kláves SHIFT+ENTER buňku spusťte.
Notebook zobrazuje počet typů blobů podle typu.

Získání počtu objektů blob podle typu obsahu
Do nové buňky vložte následující kód:
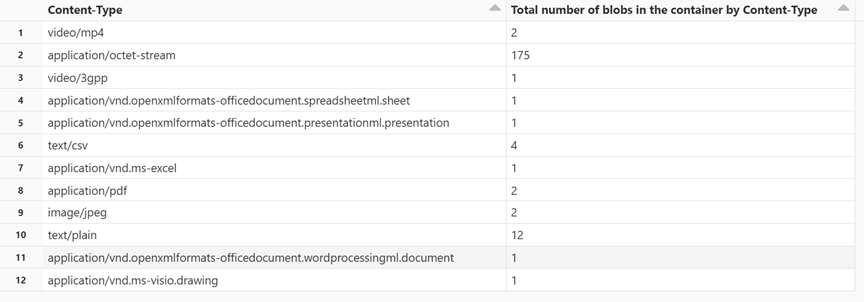
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Stisknutím kombinace kláves SHIFT+ENTER buňku spusťte.
Poznámkový blok zobrazuje počet blobů přidružených k každému typu obsahu.
Ukončení clusteru
Abyste se vyhnuli zbytečné fakturaci, ukončete výpočetní prostředek. Viz ukončení výpočetní instance.
Další kroky
Naučte se používat Azure Synapse k výpočtu počtu blobů a celkové velikosti blobů v jednotlivých kontejnerech. Zobrazení výpočtu počtu objektů blob a celkové velikosti jednotlivých kontejnerů s využitím inventáře služby Azure Storage
Naučte se generovat a vizualizovat statistiky, které popisují kontejnery a bloby. Podívejte se na návod: Analýza přehledů inventáře blob
Zjistěte, jak optimalizovat náklady na základě analýzy objektů blob a kontejnerů. Podívejte se na tyto články:
Plánování a správa nákladů na službu Azure Blob Storage
Odhad nákladů na archivaci dat
Optimalizace nákladů automatickou správou životního cyklu dat