Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak snadno rozšířit data ve službě Azure Synapse Analytics pomocí služeb Azure AI. K vyhledání anomálií použijete Detektor anomálií Azure AI. Uživatel ve službě Azure Synapse může jednoduše vybrat tabulku pro obohacení detekce anomálií.
Tento kurz zahrnuje:
- Postup získání datové sady tabulky Spark, která obsahuje data časových řad
- Použití uživatelského prostředí průvodce v Azure Synapse k obohacení dat pomocí Detektoru anomálií.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Pracovní prostor Azure Synapse Analytics s účtem úložiště Azure Data Lake Storage Gen2 nakonfigurovaným jako výchozí úložiště. Musíte být přispěvatelem dat objektů blob úložiště systému souborů Data Lake Storage Gen2, se kterým pracujete.
- Pool Sparku v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Vytvoření fondu Sparku v Azure Synapse.
- Dokončení kroků před konfigurací v kurzu Konfigurace služeb Azure AI v Azure Synapse
Přihlaste se k portálu Azure Portal.
Přihlaste se k portálu Azure.
Vytvoření tabulky Spark
Pro účely tohoto kurzu potřebujete tabulku Sparku.
Vytvořte poznámkový blok PySpark a spusťte následující kód.
from pyspark.sql.functions import lit
df = spark.createDataFrame([
("1972-01-01T00:00:00Z", 826.0),
("1972-02-01T00:00:00Z", 799.0),
("1972-03-01T00:00:00Z", 890.0),
("1972-04-01T00:00:00Z", 900.0),
("1972-05-01T00:00:00Z", 766.0),
("1972-06-01T00:00:00Z", 805.0),
("1972-07-01T00:00:00Z", 821.0),
("1972-08-01T00:00:00Z", 20000.0),
("1972-09-01T00:00:00Z", 883.0),
("1972-10-01T00:00:00Z", 898.0),
("1972-11-01T00:00:00Z", 957.0),
("1972-12-01T00:00:00Z", 924.0),
("1973-01-01T00:00:00Z", 881.0),
("1973-02-01T00:00:00Z", 837.0),
("1973-03-01T00:00:00Z", 9000.0)
], ["timestamp", "value"]).withColumn("group", lit("series1"))
df.write.mode("overwrite").saveAsTable("anomaly_detector_testing_data")
Ve výchozí databázi Spark by se teď měla zobrazit tabulka Spark s názvem anomaly_detector_testing_data .
Otevření průvodce službami Azure AI
Klikněte pravým tlačítkem myši na tabulku Sparku vytvořenou v předchozím kroku. Vyberte Strojové učení>Předpovědět modelem pro otevření průvodce.
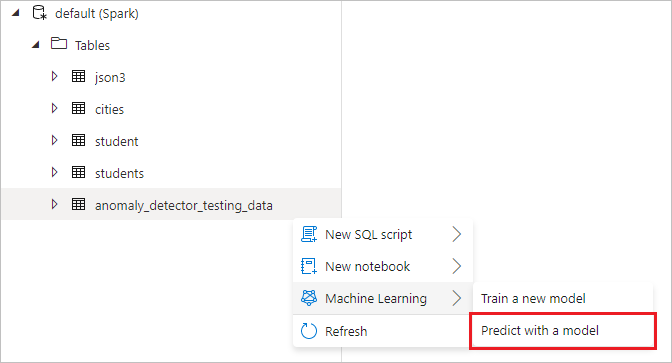
Zobrazí se konfigurační panel a zobrazí se výzva k výběru předem natrénovaného modelu. Vyberte Detektor anomálií.
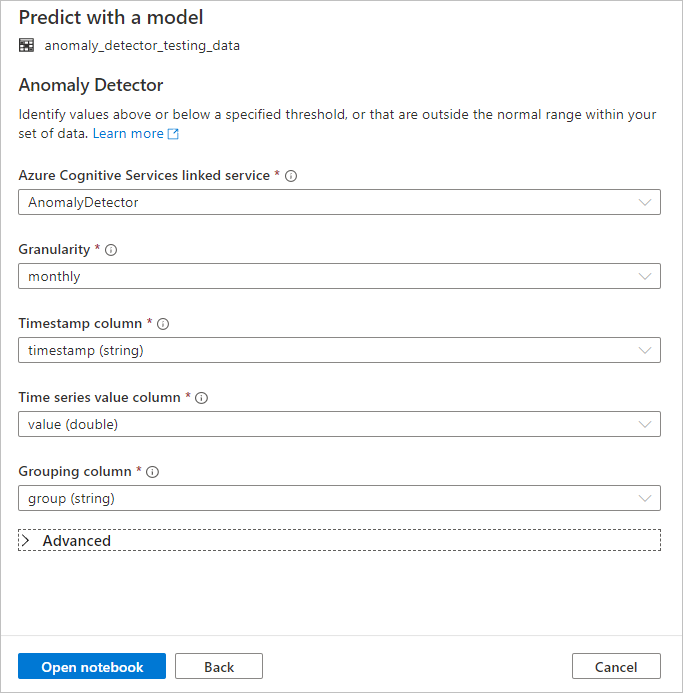
Konfigurace Detektor anomálií
Zadejte následující podrobnosti ke konfiguraci Detektor anomálií:
Propojená služba Azure Cognitive Services: V rámci kroků předpokladů jste vytvořili propojenou službu s vaší službou Azure AI. Vyberte ho tady.
Granularita: Míra, jak často jsou vaše data vzorkována. Zvolte každý měsíc.
Sloupec časového razítka: Sloupec, který představuje čas řady. Zvolte časové razítko (řetězec).
Sloupec hodnoty časové řady: Sloupec, který udává hodnotu řady v čase určeném sloupcem časového razítka. Zvolte hodnotu (double).
Seskupování sloupce: Sloupec, který seskupuje řadu. To znamená, že všechny řádky, které mají stejnou hodnotu v tomto sloupci, by měly tvořit jednu časnou řadu. Zvolte skupinu (řetězec).
Až budete hotovi, vyberte Otevřít poznámkový blok. Tím se vygeneruje poznámkový blok s kódem PySpark, který k detekci anomálií používá služby Azure AI.
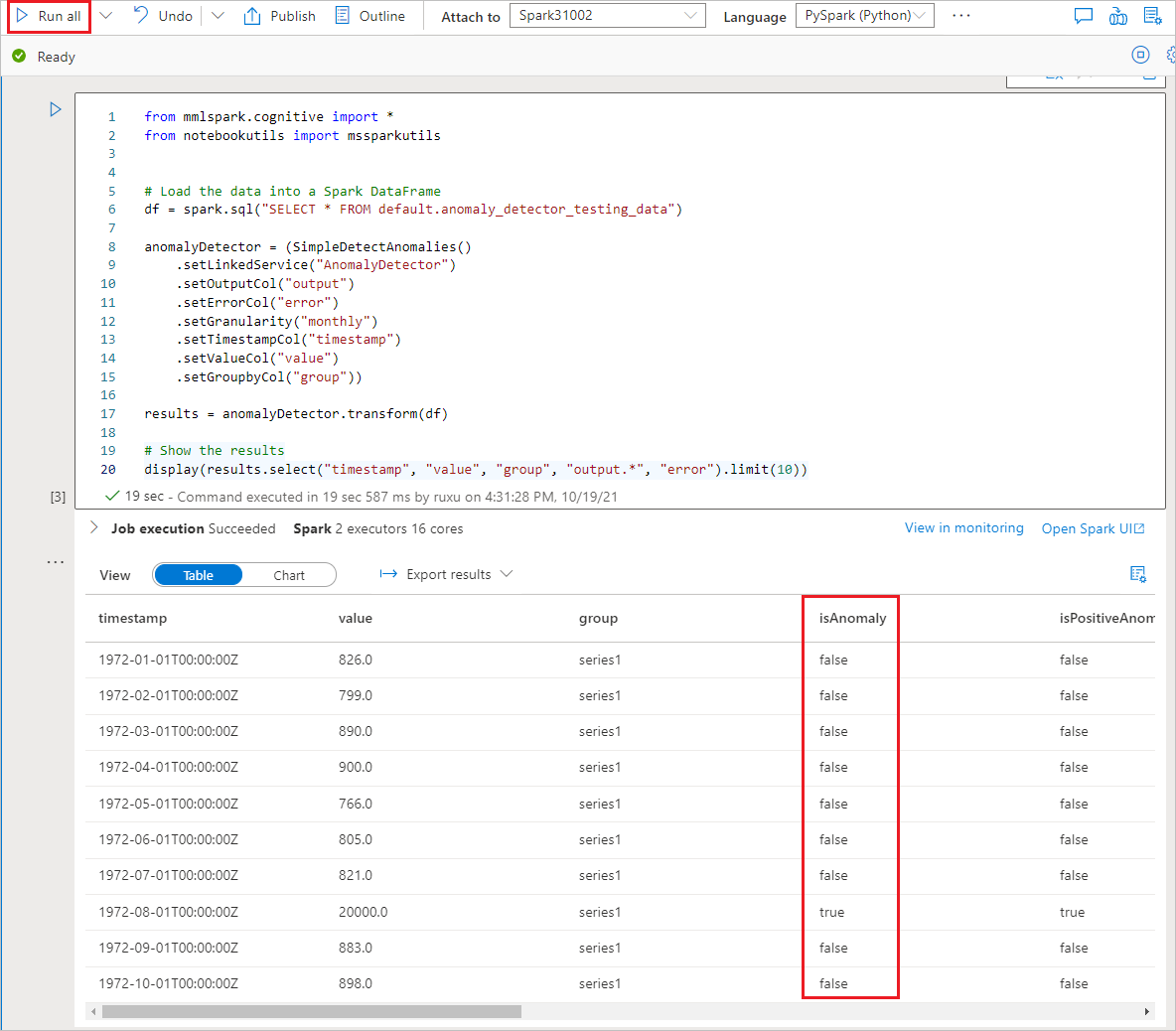
Spusťte poznámkový blok
Poznámkový blok, který jste právě otevřeli, používá knihovnu SynapseML pro připojení ke službám Azure AI. Poskytnutá propojená služba Azure AI vám umožňuje bezpečně odkazovat na vaši službu Azure AI z tohoto prostředí bez odhalení jakýchkoli tajemství.
Teď můžete spustit všechny buňky pro detekci anomálií. Vyberte Spustit vše. Přečtěte si další informace o Detektor anomálií ve službách Azure AI.