Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto kurzu se dozvíte, jak rozšířit data ve službě Azure Synapse Analytics pomocí služeb Azure AI. K analýze mínění použijete možnosti analýzy textu v jazyce Azure AI .
Uživatel ve službě Azure Synapse může vybrat tabulku, která obsahuje textový sloupec pro obohacení mínění. Tato mínění můžou být kladná, negativní, smíšená nebo neutrální. Vrátí se také pravděpodobnost.
Tento kurz zahrnuje:
- Postup získání datové sady tabulky Spark, která obsahuje textový sloupec pro analýzu mínění
- Použití průvodce v Azure Synapse k obohacení dat pomocí služby Analýzy textu v Azure AI Language.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Pracovní prostor Azure Synapse Analytics s účtem úložiště Azure Data Lake Storage Gen2 nakonfigurovaným jako výchozí úložiště. Musíte být Storage Blob Data Contributor systému souborů Data Lake Storage Gen2, se kterým pracujete.
- Fond Sparku v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Vytvoření fondu Sparku v Azure Synapse.
- Kroky předkonfigurace popsané v kurzu: Konfigurace služeb Azure AI v Azure Synapse
Přihlaste se k portálu Azure Portal.
Přihlaste se k portálu Azure.
Vytvoření tabulky Spark
Pro účely tohoto kurzu budete potřebovat tabulku Sparku.
Stáhněte si soubor FabrikamComments.csv, který obsahuje datovou sadu pro analýzu textu.
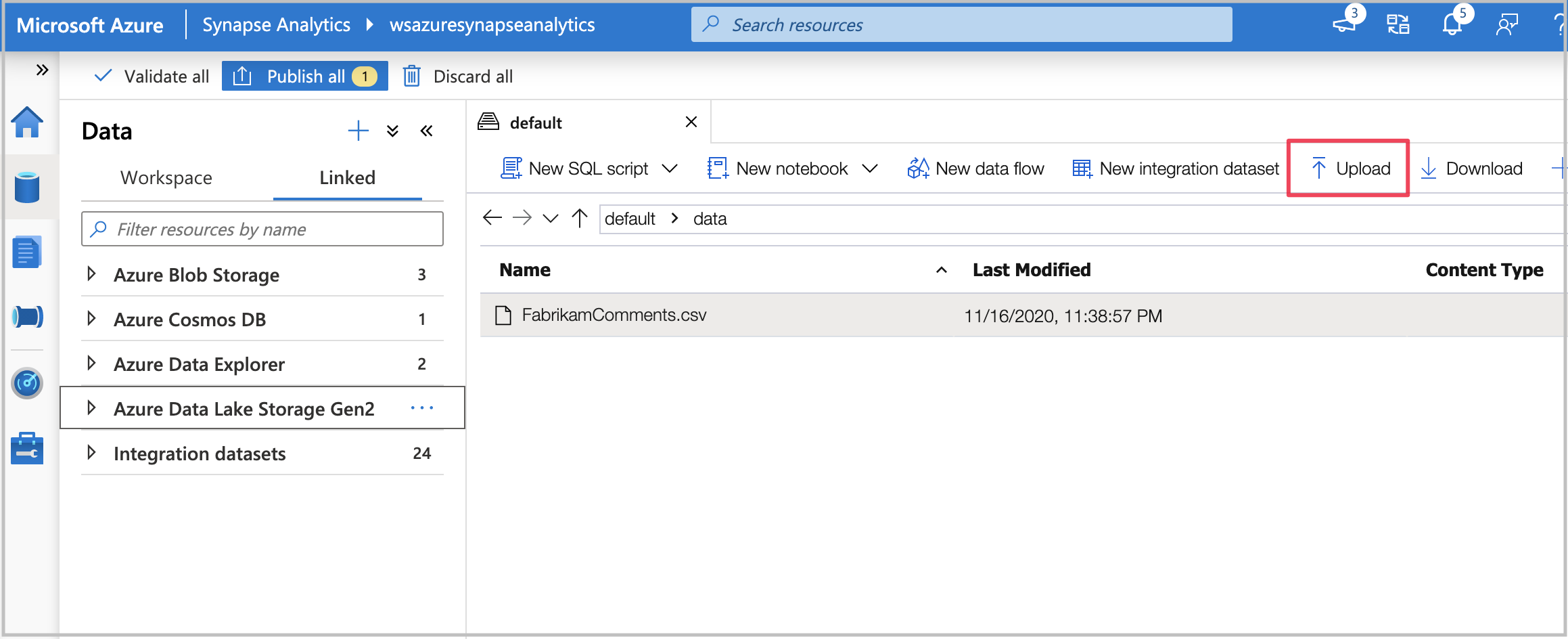
Ve službě Synapse Analytics otevřete svůj účet úložiště v části Data a Propojené.
Nahrajte soubor do účtu úložiště Azure Synapse v Data Lake Storage Gen2.
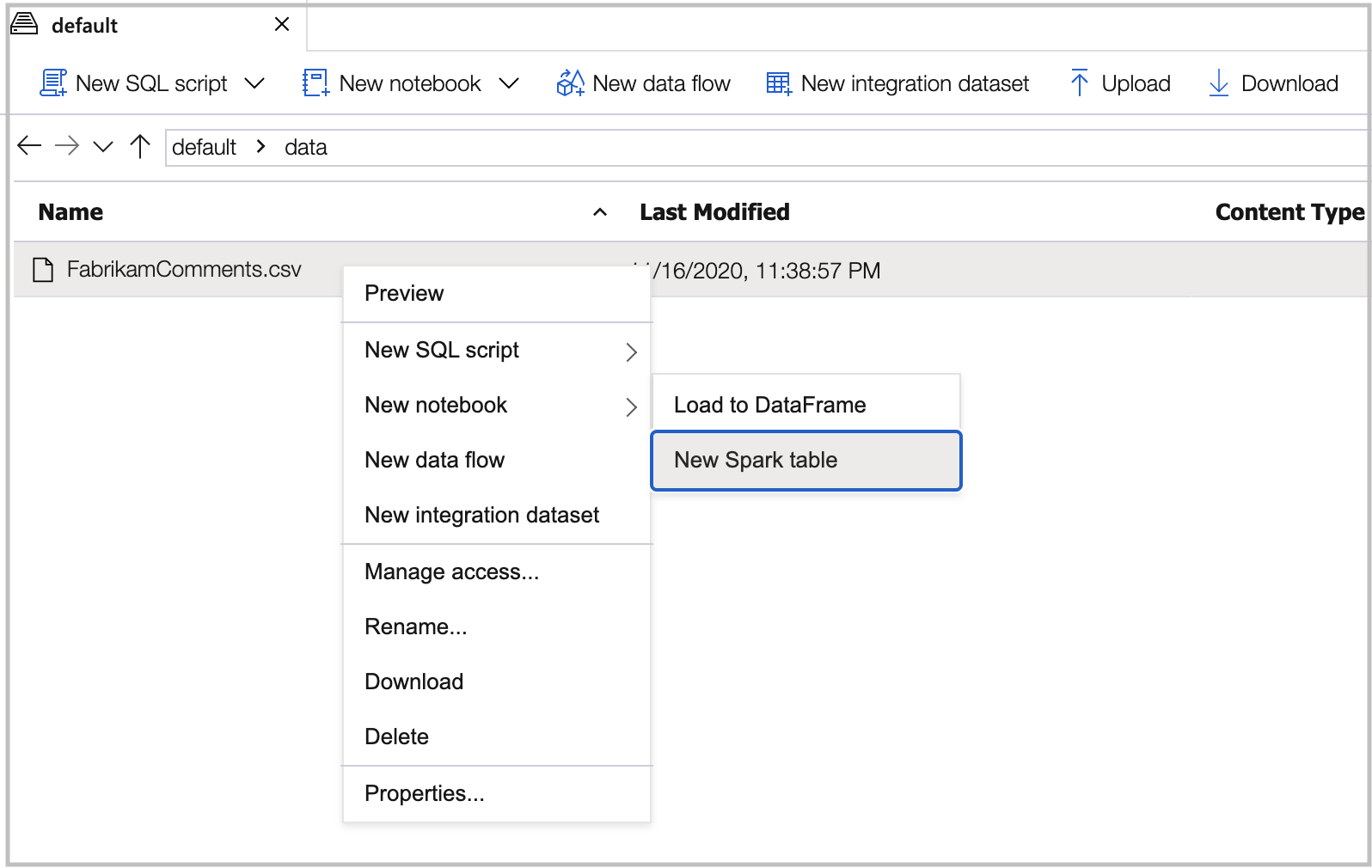
Ze souboru .csv vytvořte tabulku Sparku tak, že na soubor kliknete pravým tlačítkem a vyberete Nový poznámkový blok>.
Nastavte
header=Truea pojmenujte tabulku v buňce kódu. Potom poznámkový blok spusťte ve fondu Sparku.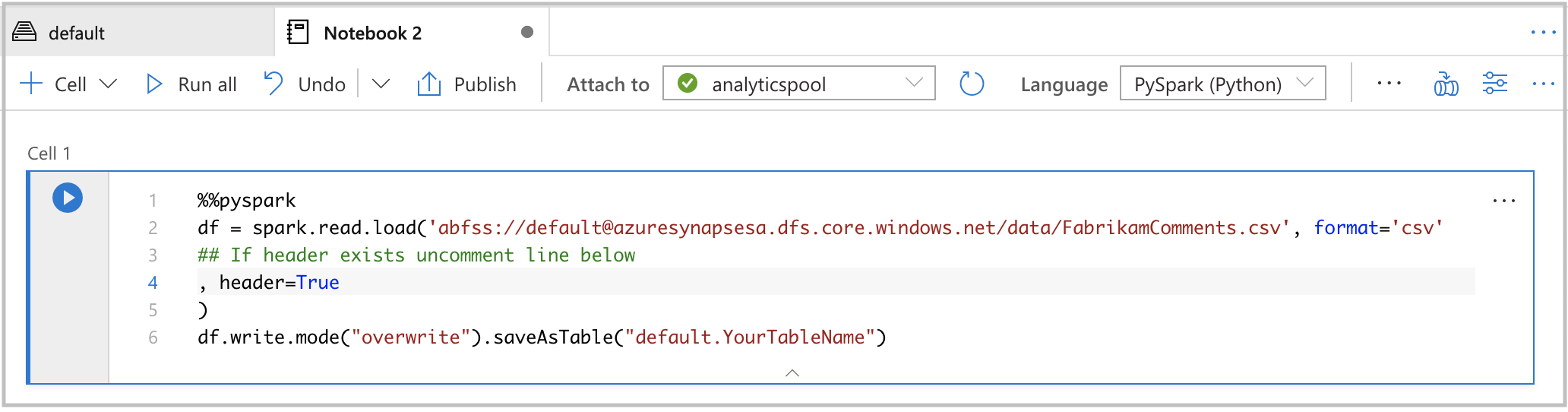
%%pyspark df = spark.read.load('abfss://default@azuresynapsesa.dfs.core.windows.net/data/FabrikamComments.csv', format='csv' ## If a header exists, uncomment the line below , header=True ) df.write.mode("overwrite").saveAsTable("default.YourTableName")
Otevření průvodce službami Azure AI
Na kartě Pracovní prostor na datové stránce ve vaší výchozí tabulce lake klikněte pravým tlačítkem myši na tabulku Spark vytvořenou v předchozím postupu.
Výběrem možnosti Strojové učení>Předpověď modelem otevřete průvodce.
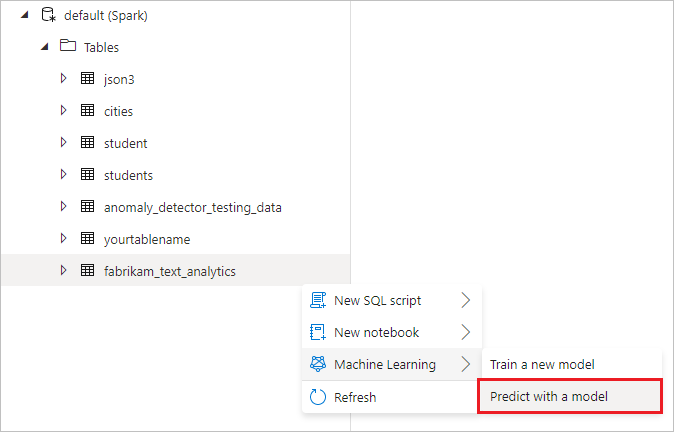
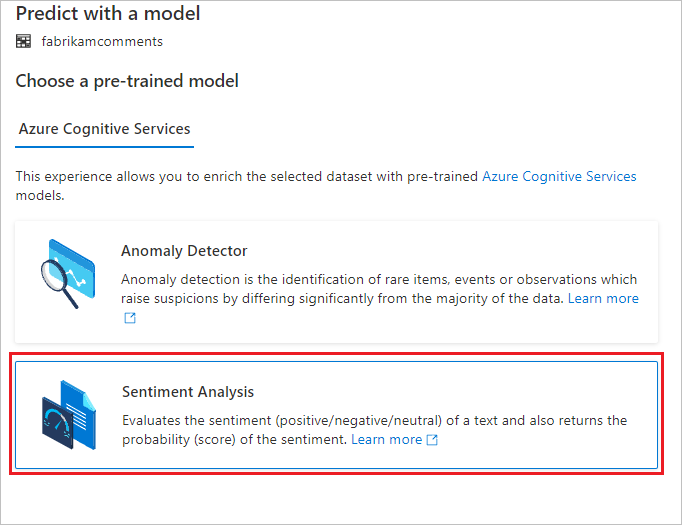
Zobrazí se konfigurační panel a zobrazí se výzva k výběru předem natrénovaného modelu. Vyberte Analýzu mínění.
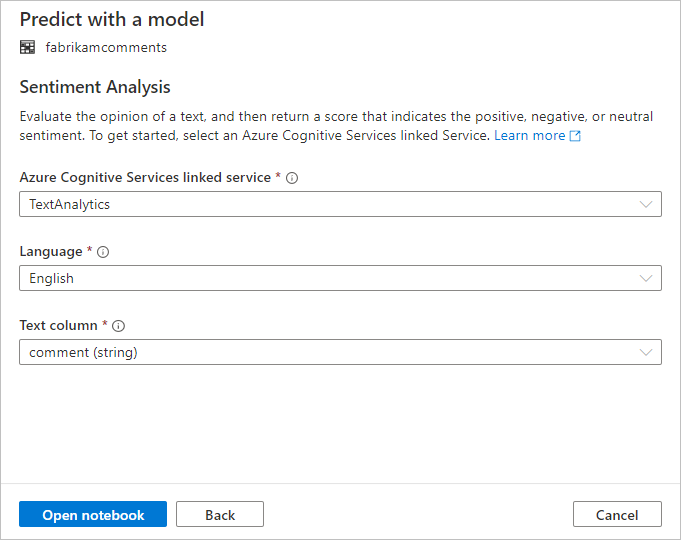
Konfigurace analýzy mínění
Dále nakonfigurujte analýzu mínění. Vyberte následující podrobnosti:
- Propojená služba Azure Cognitive Services: V rámci předpokládaných kroků jste vytvořili propojenou službu ke své službě Azure AI. Vyberte ho tady.
- Jazyk: Jako jazyk textu, u kterého chcete provést analýzu mínění, vyberte angličtinu .
- Textový sloupec: Jako textový sloupec v datové sadě, který chcete analyzovat, vyberte komentář (řetězec) a určete mínění.
Až budete hotovi, vyberte Otevřít poznámkový blok. Tím se vygeneruje poznámkový blok s kódem PySpark, který provádí analýzu mínění se službami Azure AI.
Spusťte poznámkový blok
Poznámkový blok, který jste právě otevřeli, používá knihovnu SynapseML pro připojení ke službám Azure AI. Propojená služba Azure AI, kterou jste zadali, vám umožňuje bezpečně odkazovat na službu Azure AI z tohoto rozhraní, aniž by byly odhaleny jakékoliv tajné údaje.
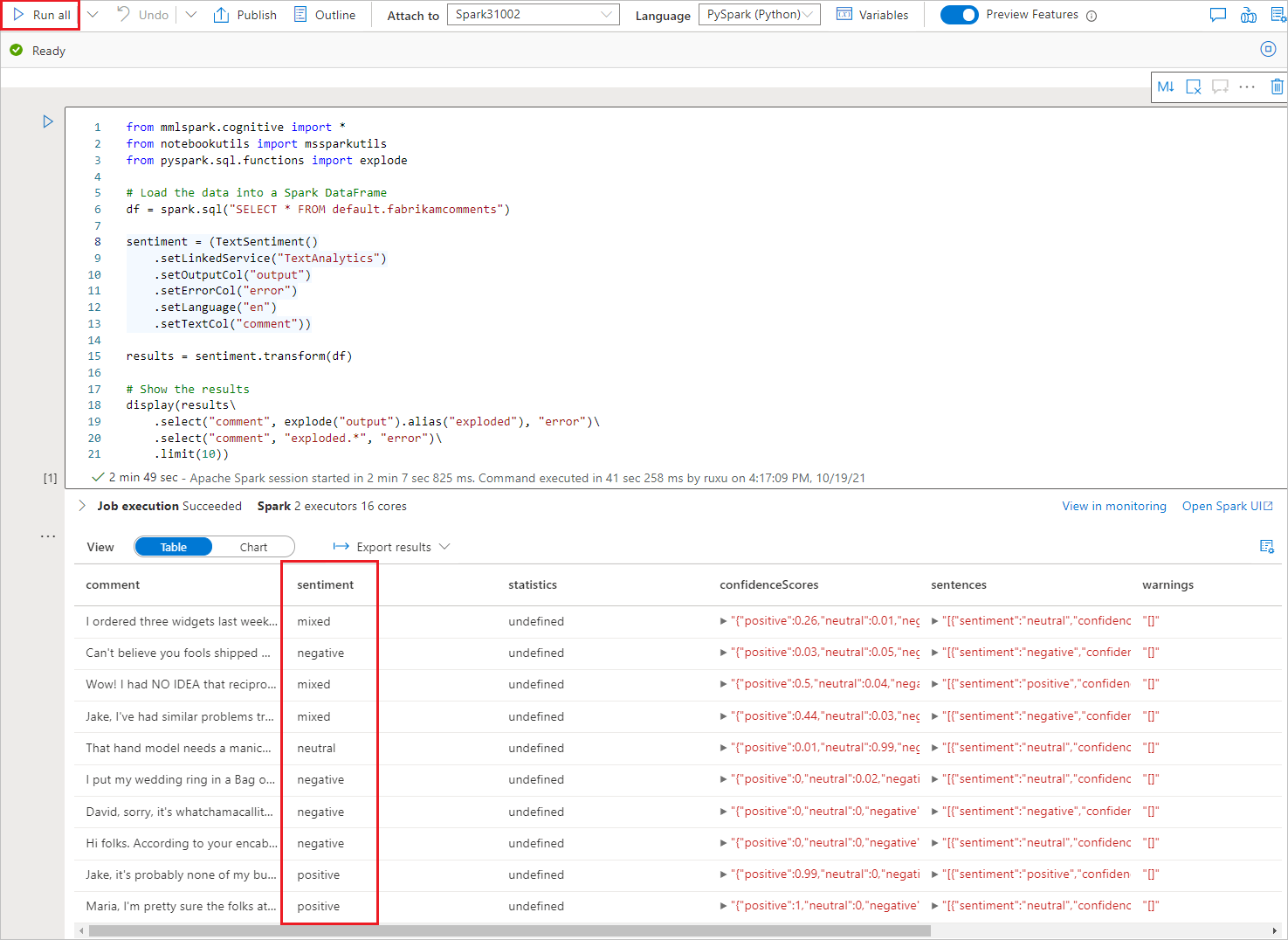
Teď můžete spustit všechny buňky, abyste data obohatili míněním. Vyberte Spustit vše.
Mínění se vrátí jako kladné, záporné, neutrální nebo smíšené. Získáte také pravděpodobnosti podle mínění. Přečtěte si další informace o analýze mínění ve službách Azure AI.