Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tento článek je součástí sedmidílné série, která obsahuje pokyny k migraci z Oracle na Azure Synapse Analytics. Tento článek se zaměřuje na osvědčené postupy pro návrh a výkon.
Overview
Vzhledem k nákladům a složitosti údržby a upgradu starších místních prostředí Oracle chce mnoho stávajících uživatelů Oracle využívat inovace poskytované moderními cloudovými prostředími. Cloudová prostředí typu infrastruktura jako služba (IaaS) a platforma jako služba (PaaS) umožňují delegovat úlohy, jako je údržba infrastruktury a vývoj platforem, na poskytovatele cloudu.
Tip
Více než jen databáze – prostředí Azure zahrnuje komplexní sadu funkcí a nástrojů.
I když Oracle a Azure Synapse Analytics jsou databáze SQL, které používají techniky MPP (Massively Parallel Processing) k dosažení vysokého výkonu dotazů na mimořádně velkých objemech dat, existují některé základní rozdíly v přístupu:
Starší systémy Oracle se často instalují místně a používají relativně drahý hardware, zatímco Azure Synapse je cloudový a používá úložiště a výpočetní prostředky Azure.
Upgradování konfigurace Oracle je významný úkol zahrnující další fyzický hardware a potenciálně zdlouhavé předělání konfigurace databáze nebo vysypání a znovu načtení. Vzhledem k tomu, že úložiště a výpočetní prostředky jsou v prostředí Azure oddělené a mají možnost elastického škálování, je možné tyto prostředky nezávisle škálovat směrem nahoru nebo dolů.
Podle potřeby můžete azure Synapse pozastavit nebo změnit jeho velikost, abyste snížili využití prostředků a náklady.
Microsoft Azure je globálně dostupné, vysoce zabezpečené a škálovatelné cloudové prostředí, které zahrnuje Azure Synapse a ekosystém podpůrných nástrojů a možností. Další diagram shrnuje ekosystém Azure Synapse.

Azure Synapse poskytuje špičkový výkon relačních databází pomocí technik, jako je MPP a automatická paměťová cache. Výsledky těchto technik si můžete prohlédnout v nezávislých benchmarkových testech, jako je například nedávno uskutečněný test od GigaOm, který porovnává Azure Synapse s dalšími oblíbenými nabídkami cloudového datového skladu. Zákazníci, kteří migrují do prostředí Azure Synapse, vidí mnoho výhod, mezi které patří:
Vyšší výkon a cena/výkon.
Zvýšená flexibilita a kratší doba do dosažení hodnoty.
Rychlejší nasazení serveru a vývoj aplikací
Elastická škálovatelnost – platíte jenom za skutečné využití.
Improved security/compliance.
Snížení nákladů na úložiště a zotavení po havárii
Nižší celkové náklady na vlastnictví (TCO), lepší řízení nákladů a optimalizované provozní výdaje (OPEX).
Pokud chcete tyto výhody maximalizovat, migrujte nová nebo existující data a aplikace na platformu Azure Synapse. V mnoha organizacích migrace zahrnuje přesun existujícího datového skladu ze starší místní platformy, jako je Oracle, do Azure Synapse. Proces migrace na vysoké úrovni zahrnuje tyto kroky:
Preparation 🡆
Definujte rozsah – co se má migrovat.
Sestavte inventář dat a procesů pro migraci.
Definujte změny datového modelu (pokud existuje).
Definujte mechanismus extrakce zdrojových dat.
Identifikujte vhodné nástroje a funkce Azure a třetích stran, které se mají použít.
Začněte personál školit na nové platformě brzy.
Nastavte cílovou platformu Azure.
Migration 🡆
Začněte malé a jednoduché.
Automatizovat všude, kde je to možné.
Využijte integrované nástroje a funkce Azure ke snížení úsilí o migraci.
Migrujte metadata pro tabulky a zobrazení.
Migrujte historická data, která mají být udržována.
Migrace nebo refaktoring uložených procedur a obchodních procesů
Migrujte nebo refaktorujte procesy přírůstkového načítání ETL/ELT.
Post migration
Monitorujte a dokumentujte všechny fáze procesu.
Využijte získané zkušenosti k vytvoření šablony pro budoucí migrace.
Přepracujte datový model, pokud je to nutné, s využitím nového výkonu a škálovatelnosti platformy.
Otestujte aplikace a nástroje pro dotazy.
Proveďte srovnávací testy a optimalizujte výkon dotazů.
Tento článek obsahuje obecné informace a pokyny pro optimalizaci výkonu při migraci datového skladu z existujícího prostředí Oracle do Azure Synapse. Cílem optimalizace výkonu je dosáhnout stejného nebo lepšího výkonu datového skladu v Azure Synapse po migraci.
Design considerations
Migration scope
Při přípravě migrace z prostředí Oracle zvažte následující volby migrace.
Volba zatížení pro počáteční migraci
Starší prostředí Oracle se obvykle v průběhu času vyvíjela tak, aby zahrnovala více předmětných oblastí a smíšených úloh. Při rozhodování o tom, kde začít s projektem migrace, vyberte oblast, ve které budete moct:
Prokažte životaschopnost migrace do Azure Synapse tím, že rychle doručíte výhody nového prostředí.
Umožňuje interním technickým pracovníkům získat relevantní zkušenosti s procesy a nástroji, které budou používat při migraci jiných oblastí.
Vytvořte šablonu pro další migrace, která je specifická pro zdrojové prostředí Oracle a aktuální nástroje a procesy, které už existují.
Dobrý kandidát na počáteční migraci z Oracle podpora prostředí předchozí položky a:
Implementuje úlohu BI/Analytics místo úlohy online zpracování transakcí (OLTP).
Má datový model, například hvězdicové nebo sněhové vločkové schéma, které je možné migrovat s minimálními úpravami.
Tip
Vytvořte inventář objektů, které je potřeba migrovat, a zdokumentujte proces migrace.
Objem migrovaných dat v počáteční migraci by měl být dostatečně velký, aby ukázal možnosti a výhody prostředí Azure Synapse, ale neměl by být příliš velký, aby bylo možné rychle předvést hodnotu. Velikost v rozsahu 1–10 terabajtů je typická.
Počátečním přístupem k projektu migrace je minimalizace rizika, úsilí a času potřebného k tomu, abyste rychle viděli výhody cloudového prostředí Azure. Následující přístupy omezují rozsah počáteční migrace pouze na datová tržiště a nezabývá se širšími aspekty migrace, jako je migrace ETL a historická migrace dat. Tyto aspekty však můžete řešit v pozdějších fázích projektu, jakmile se migrovaná vrstva datového tržiště znovu naplní daty a požadovanými procesy sestavení.
Migrace metodou "lift and shift" vs. fázovaný přístup
Obecně platí, že existují dva typy migrace bez ohledu na účel a rozsah plánované migrace: metodu "lift and shift", jak je, a fázovaný přístup, který zahrnuje změny.
Přenést a posunout
Při migraci metodou "lift and shift" se stávající datový model, jako je hvězdicové schéma, migruje na novou platformu Azure Synapse beze změny. Tento přístup minimalizuje riziko a dobu migrace tím, že snižuje práci potřebnou k realizaci výhod přechodu do cloudového prostředí Azure. Migrace pomocí metody "lift and shift" je vhodná pro následující scénáře:
- Máte existující prostředí Oracle s jedním datovým skladem, které se má migrovat, nebo
- Máte stávající prostředí Oracle s daty, která jsou již v dobře navrženém hvězdicovém nebo vločkovém schématu, nebo
- Jste pod časovými a nákladovými tlaky, abyste přešli do moderního cloudového prostředí.
Tip
"Lift and shift je dobrý výchozí bod, i když následné fáze provedou změny datového modelu."
Fázovaný přístup, který zahrnuje změny
Pokud se starší datový sklad vyvinul po dlouhou dobu, budete ho možná muset znovu vytvořit, aby se zachovaly požadované úrovně výkonu. Možná budete muset znovu zapracovat na podporu nových dat, jako jsou streamy Internetu věcí (IoT). V rámci procesu opětovného přípravy migrujte do Azure Synapse, abyste získali výhody škálovatelného cloudového prostředí. Migrace může zahrnovat změnu v podkladovém datovém modelu, například přechod z modelu Inmon do trezoru dat.
Microsoft doporučuje přesunout stávající datový model tak, jak je, do Azure a využít výkon a flexibilitu prostředí Azure k použití změn v opětovném inženýrství. Díky tomu můžete pomocí funkcí Azure provádět změny, aniž by to mělo vliv na stávající zdrojový systém.
Použití zařízení Microsoftu k implementaci migrace řízené metadaty
Proces migrace můžete automatizovat a orchestrovat pomocí funkcí prostředí Azure. Tento přístup minimalizuje dopad na výkon v existujícím prostředí Oracle, které už může běžet blízko své kapacity.
Pomocník s migrací SQL Serveru (SSMA) pro Oracle může automatizovat mnoho částí procesu migrace, včetně některých funkcí a procedurálního kódu. SSMA podporuje Azure Synapse jako cílové prostředí.

SSMA pro Oracle vám může pomoct s migrací datového skladu Nebo datového tržiště Oracle do Azure Synapse. SSMA je navržený tak, aby automatizoval proces migrace tabulek, zobrazení a dat z existujícího prostředí Oracle.
Azure Data Factory je cloudová služba pro integraci dat, která podporuje vytváření pracovních postupů řízených daty v cloudu, které orchestrují a automatizují přesun a transformaci dat. Data Factory můžete použít k vytváření a plánování pracovních postupů řízených daty (kanály), které ingestují data z různorodých úložišť dat. Data Factory může zpracovávat a transformovat data pomocí výpočetních technologií, jako Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics a Azure Machine Learning.
Službu Data Factory je možné použít k migraci dat ve zdroji do cíle Azure SQL. Tento přesun offline dat pomáhá výrazně snížit výpadky migrace.
Azure Database Migration Services vám může pomoct naplánovat a provést migraci z prostředí, jako je Oracle.
Pokud plánujete ke správě procesu migrace použít zařízení Azure, vytvořte metadata se seznamem všech tabulek dat, které se mají migrovat, a jejich umístění.
Rozdíly v návrhu mezi Oraclem a Azure Synapse
Jak už bylo zmíněno dříve, existují některé základní rozdíly v přístupu mezi databázemi Oracle a Azure Synapse Analytics. SSMA pro Oracle nejen pomáhá překlenout tyto mezery, ale také automatizovat migraci. I když SSMA není nejúčinnějším přístupem pro velmi velké objemy dat, je užitečné pro menší tabulky.
Více databází vs. jedna databáze a schémata
Prostředí Oracle často obsahuje více samostatných databází. Například mohou existovat samostatné databáze pro příjem a přechodné tabulky dat, základní tabulky skladu a datové tržiště, někdy označovaná jako sémantická vrstva. Zpracování v kanálech ETL nebo ELT může implementovat propojení mezi databázemi a přesouvat data mezi samostatnými databázemi.
Prostředí Azure Synapse naproti tomu obsahuje jednu databázi a používá schémata k oddělení tabulek do logicky samostatných skupin. Doporučujeme použít řadu schémat v cílové databázi Azure Synapse k napodobení samostatných databází migrovaných z prostředí Oracle. Pokud prostředí Oracle již používá schémata, budete možná muset při přesunutí existujících tabulek a zobrazení Oracle do nového prostředí použít novou konvenci vytváření názvů. Například můžete zřetězit existující schémata a názvy tabulek Oracle do nového názvu tabulky Azure Synapse a poté použít názvy schémat v novém prostředí pro zachování původních názvů samostatných databází. I když můžete pomocí zobrazení SQL nad podkladovými tabulkami udržovat logické struktury, existuje potenciální nevýhoda tohoto přístupu:
Zobrazení v Azure Synapse jsou jen pro čtení, takže všechny aktualizace dat musí probíhat v podkladových základních tabulkách.
Možná už existuje jedna nebo více vrstev zobrazení a přidání další vrstvy zobrazení může ovlivnit výkon.
Tip
Zkombinujte více databází do jedné databáze v rámci Azure Synapse a použijte názvy schémat k logickému oddělení tabulek.
Table considerations
Když migrujete tabulky mezi různými prostředími, obvykle migrují pouze nezpracovaná data a metadata, která je fyzicky popisují. Jiné databázové prvky ze zdrojového systému, například indexy, se obvykle nemigrují, protože v novém prostředí můžou být zbytečné nebo implementované jinak.
Optimalizace výkonu ve zdrojovém prostředí, například indexy, označují, kde můžete v novém prostředí přidat optimalizaci výkonu. Pokud například dotazy ve zdrojovém prostředí Oracle často používají bitové mapované indexy, které naznačují, že by se měl vytvořit neskupený index v rámci Azure Synapse. Jiné nativní techniky optimalizace výkonu, jako je replikace tabulek, můžou být vhodnější než přímé vytvoření indexu podobného typu. SSMA pro Oracle je možné použít k poskytování doporučení pro migraci pro distribuci tabulek a indexování.
Tip
Existující indexy označují kandidáty pro indexování v migrovaném skladu.
Nepodporované typy databázových objektů Oracle
Funkce specifické pro Oracle je často možné nahradit funkcemi Azure Synapse. Některé databázové objekty Oracle se ale v Azure Synapse přímo nepodporují. Následující seznam nepodporovaných databázových objektů Oracle popisuje, jak v Azure Synapse dosáhnout ekvivalentní funkce.
Různé možnosti indexování: v Oracle, několik možností indexování, jako jsou bitové mapované indexy, indexy založené na funkcích a indexy domén, nemají v Azure Synapse žádný přímý ekvivalent.
Můžete zjistit, které sloupce jsou indexovány a podle typu indexu:
Dotazování na tabulky a zobrazení systémového katalogu, například
ALL_INDEXES,DBA_INDEXES,USER_INDEXESaDBA_IND_COL. Můžete použít předdefinované dotazy v Oracle SQL Developer, jak je znázorněno na následujícím snímku obrazovky.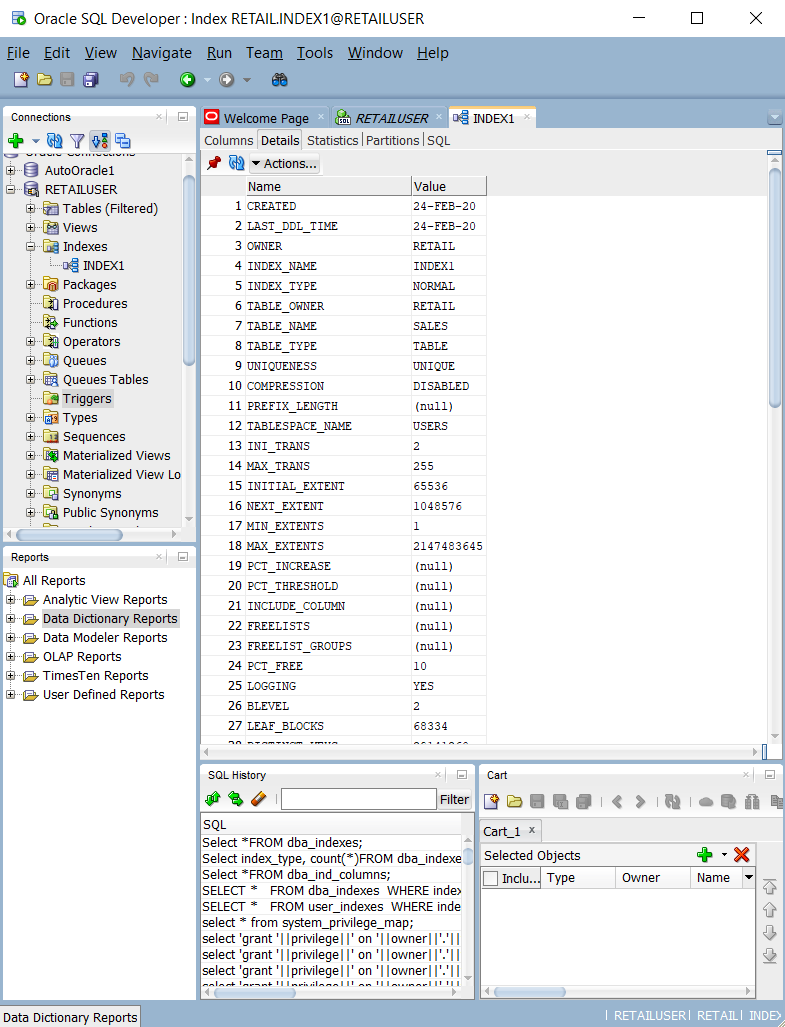
Nebo spuštěním následujícího dotazu vyhledejte všechny indexy daného typu:
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';Dotazování na zobrazení
dba_index_usagenebov$object_usagepři povoleném monitorování Tato zobrazení můžete dotazovat ve vývojáři Oracle SQL, jak je znázorněno na následujícím snímku obrazovky.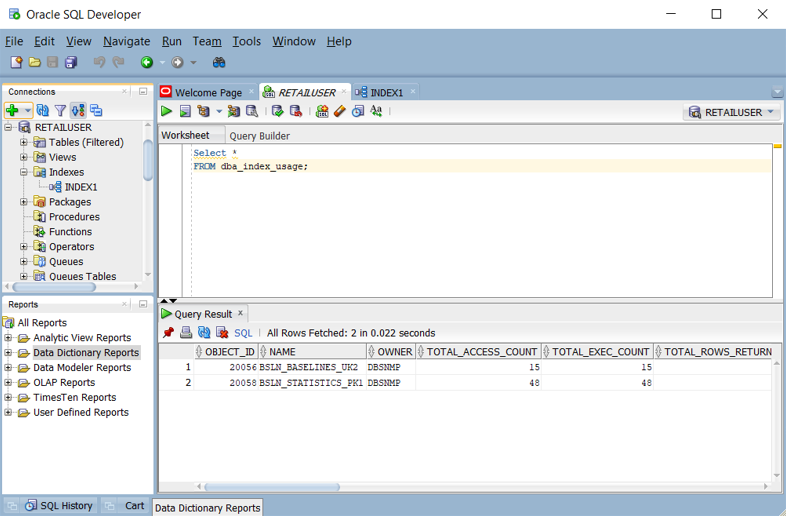
Indexy založené na funkcích, kde index obsahuje výsledek funkce v podkladových sloupcích dat, nemají v Azure Synapse žádný přímý ekvivalent. Doporučujeme nejprve migrovat data a pak ve službě Azure Synapse spouštět dotazy Oracle, které používají indexy založené na funkcích k měření výkonu. Pokud výkon těchto dotazů ve službě Azure Synapse není přijatelný, zvažte vytvoření sloupce, který obsahuje předem počítanou hodnotu, a pak tento sloupec indexujte.
Když nakonfigurujete prostředí Azure Synapse, dává smysl implementovat pouze indexy v použití. Azure Synapse v současné době podporuje typy indexů uvedené tady:
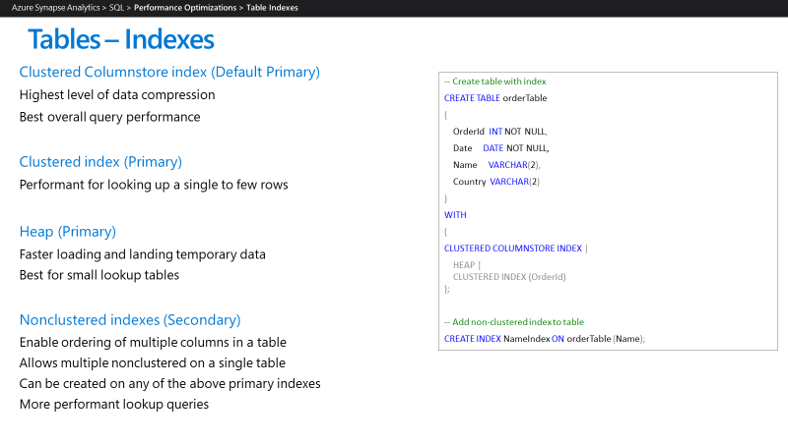
Díky funkcím Azure Synapse, jako je paralelní zpracování dotazů a ukládání dat do mezipaměti v paměti, je pravděpodobné, že pro aplikace datového skladu je k dosažení cílů výkonu vyžadováno méně indexů. Ve službě Azure Synapse doporučujeme použít následující typy indexů:
Clusterované columnstore indexy: Pokud nejsou pro tabulku zadány žádné možnosti indexu, Azure Synapse standardně vytvoří clusterovaný columnstore index. Clusterované tabulky columnstore nabízejí nejvyšší úroveň komprese dat, nejlepší celkový výkon dotazů a obecně mají lepší výkon než tabulky s clusterovaným indexem nebo haldou. Clusterovaný index columnstore je obvykle nejlepší volbou pro velké tabulky. Když vytváříte tabulku, vyberte clusterovaný columnstore, pokud si nejste jistí, jak tabulku indexovat. Existují však některé scénáře, kdy clusterované indexy columnstore nejsou nejlepší volbou:
- Tabulky s předem seřazenými daty podle klíče řazení můžou těžit z eliminace segmentu umožněné uspořádanými clusterovanými indexy columnstore.
- Tabulky s datovými typy varchar(max), nvarchar(max) nebo varbinary(max), protože clusterovaný index columnstore tyto datové typy nepodporuje. Místo toho zvažte použití haldy nebo clusterovaného indexu.
- Tabulky s dočasnými daty, protože tabulky columnstore mohou být méně efektivní než heap tabulky nebo dočasné tabulky.
- Malé tabulky s méně než 100 miliony řádků. Místo toho zvažte použití tabulek haldy.
Uspořádané clusterované indexy columnstore: Povolením efektivního odstranění segmentů zajišťují uspořádané clusterované indexy columnstore ve vyhrazených fondech Azure Synapse SQL mnohem rychlejší výkon tím, že neberou v úvahu velké objemy uspořádaných dat, které neodpovídají predikátu dotazu. Načtení dat do seřazené tabulky CCI může trvat déle než do nesetříděné tabulky CCI kvůli operaci třídění dat, ale dotazy mohou běžet rychleji se seřazenými CCI. Další informace o seřazených clusterovaných columnstore indexech najdete v tématu Ladění výkonu pomocí seřazeného clusterovaného columnstore indexu.
Clusterované a neclusterované indexy: Clusterované indexy můžou překonat clusterované columnstore indexy, pokud je potřeba rychle načíst jeden řádek. U dotazů, kde musí vyhledávání na jednom řádku nebo jen na několika řádcích probíhat extrémní rychlostí, zvažte použití clusterového nebo neclusterovaného sekundárního indexu. Nevýhodou použití clusterovaného indexu je, že výhody budou mít pouze dotazy s vysoce selektivním filtrem ve sloupci clusterovaného indexu. Pokud chcete zlepšit filtrování u jiných sloupců, můžete do ostatních sloupců přidat neclusterovaný index. Každý index, který přidáte do tabulky, ale využívá více místa a zvyšuje dobu načítání zpracování.
Heap tabulky: Když dočasně ukládáte data ve službě Azure Synapse, můžete zjistit, že použití heap tabulky zrychluje celkový proces. Důvodem je to, že načítání dat do halda tabulky je rychlejší než načítání dat do indexové tabulky a v některých případech může být následně čteno z mezipaměti. Pokud načítáte data pouze ke zpracování před prováděním dalších transformací, je mnohem rychlejší je načíst do heap tabulky než do tabulky s clusterovaným columnstore indexem. Načítání dat do dočasné tabulky je také rychlejší než načtení tabulky do trvalého úložiště. U malých vyhledávacích tabulek s méně než 100 miliony řádků je halda tabulky obvykle správnou volbou. Tabulky columnstore clusteru začínají dosahovat optimální komprese, pokud obsahují více než 100 milionů řádků.
Clusterované tabulky: Tabulky Oracle je možné uspořádat tak, aby se řádky tabulky, ke kterým se často přistupuje společně (na základě společné hodnoty), fyzicky ukládaly dohromady, aby se při načítání dat snížil počet vstupně-výstupních operací disku. Oracle také poskytuje možnost hash-cluster pro jednotlivé tabulky, která aplikuje hodnotu hash na klíč clusteru a fyzicky ukládá řádky se stejnou hodnotou hash. Pokud chcete vypsat clustery v databázi Oracle, použijte dotaz
SELECT * FROM DBA_CLUSTERS;. Pokud chcete zjistit, jestli je tabulka v clusteru, použijteSELECT * FROM TAB;dotaz, který zobrazuje název tabulky a ID clusteru pro každou tabulku.V Azure Synapse můžete dosáhnout podobných výsledků pomocí materializovaných a/nebo replikovaných tabulek, protože tyto typy tabulek minimalizují vstupně-výstupní operace v době běhu dotazu.
Materializovaná zobrazení: Oracle podporuje materializovaná zobrazení a doporučuje použít jednu nebo více pro velké tabulky s mnoha sloupci, kde se v dotazech pravidelně používá jenom několik sloupců. Materializovaná zobrazení se při aktualizaci dat v základní tabulce automaticky aktualizují systémem.
V roce 2019 Microsoft oznámil, že Azure Synapse bude podporovat materializovaná zobrazení se stejnými funkcemi jako v Oracle. Materializovaná zobrazení jsou nyní předběžnou funkcí v Azure Synapse.
Triggery v databázi: V Oracle je možné trigger nakonfigurovat tak, aby se automaticky spouštěl, když dojde k aktivační události. Aktivační události můžou být:
Příkaz jazyka DML (Data Manipulat Language), například
INSERT,UPDATEneboDELETE, běží v tabulce. Pokud jste definovali trigger, který se aktivuje před příkazemINSERTv tabulce zákazníka, aktivuje se aktivační událost jednou před vložením nového řádku do tabulky zákazníka.Spustí se příkaz DDL, například
CREATEneboALTER. Tento trigger se často používá pro účely auditování k zaznamenání změn schématu.Systémová událost, například spuštění nebo vypnutí databáze Oracle.
Událost uživatele, například přihlášení nebo odhlášení.
Seznam triggerů definovaných v databázi Oracle můžete získat dotazem na pohledy
ALL_TRIGGERS,DBA_TRIGGERSneboUSER_TRIGGERS. Následující snímek obrazovky ukazujeDBA_TRIGGERSdotaz ve vývojáři Oracle SQL.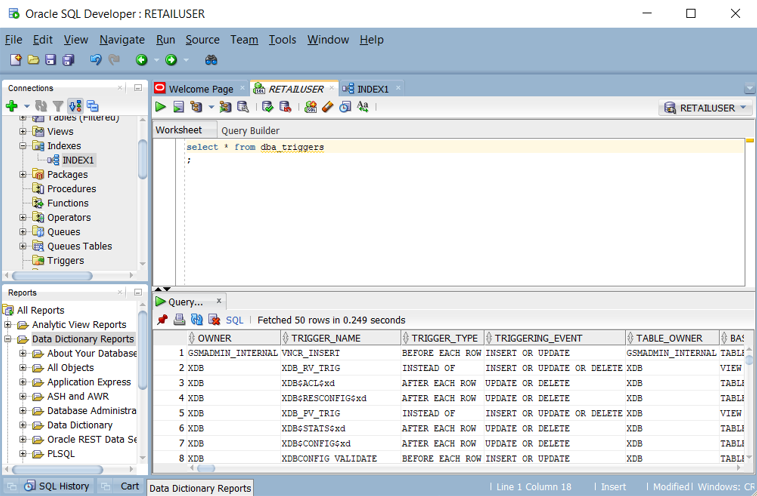
Azure Synapse nepodporuje triggery databází Oracle. Můžete ale přidat ekvivalentní funkce pomocí služby Data Factory, i když to bude vyžadovat refaktoring procesů, které používají triggery.
Synonyma: Oracle podporuje definování synonym jako alternativních názvů pro několik typů databázových objektů. Mezi tyto typy objektů patří: tabulky, zobrazení, sekvence, procedury, uložené funkce, balíčky, materializovaná zobrazení, objekty schématu tříd Java, uživatelem definované objekty nebo jiné synonymum.
Azure Synapse v současné době nepodporuje definování synonym, i když synonyma v Oracle odkazuje na tabulku nebo zobrazení, můžete v Azure Synapse definovat zobrazení tak, aby odpovídalo alternativnímu názvu. Pokud synonymum v Oracle odkazuje na funkci nebo uloženou proceduru, můžete v Azure Synapse vytvořit jinou funkci nebo uloženou proceduru s názvem, který odpovídá synonymu, který volá cíl.
Uživatelem definované typy: Oracle podporuje uživatelem definované objekty, které můžou obsahovat řadu jednotlivých polí, z nichž každá má vlastní definici a výchozí hodnoty. Tyto objekty lze odkazovat v definici tabulky stejným způsobem jako předdefinované datové typy jako
NUMBERneboVARCHAR. Seznam uživatelsky definovaných typů v databázi Oracle můžete získat dotazem na zobrazeníALL_TYPES,DBA_TYPESneboUSER_TYPES.Azure Synapse v současné době nepodporuje uživatelem definované typy. Pokud data, která potřebujete migrovat, zahrnují uživatelsky definované datové typy, buď je "zploštět" do konvenční definice tabulky, nebo pokud jsou pole dat, normalizujte je v samostatné tabulce.




Mapování datových typů Oracle
Většina datových typů Oracle má v Azure Synapse přímý ekvivalent. Následující tabulka uvádí doporučený přístup pro mapování datových typů Oracle na Azure Synapse.
| Datový typ Oracle | Datový typ Azure Synapse |
|---|---|
| BFILE | Not supported. Mapa na VARBINARY (MAX). |
| BINARY_FLOAT | Not supported. Namapujte na FLOAT. |
| BINARY_DOUBLE | Not supported. Namapovat na DOUBLE. |
| binární rozsáhlý objekt | Nepodporuje se přímo. Nahraďte hodnotou VARBINARY(MAX). |
| CHAR | CHAR |
| CLOB | Nepodporuje se přímo. Nahraďte za VARCHAR(MAX). |
| DATE | DATUM v Oracle může obsahovat také informace o čase. V závislosti na použití mapovat na DATUM nebo ČASOVÉ RAZÍTKO. |
| DECIMAL | DECIMAL |
| DOUBLE | PRECISION DOUBLE |
| FLOAT | FLOAT |
| INTEGER | INT |
| ČASOVÝ INTERVAL OD ROKU DO MĚSÍCE | Datové typy INTERVAL nejsou podporované. K výpočtům kalendářních dat použijte funkce porovnání kalendářních dat, jako je NAPŘÍKLAD DATEDIFF nebo DATEADD. |
| INTERVAL OD DNE DO SEKUNDY | Datové typy INTERVAL nejsou podporované. K výpočtům kalendářních dat použijte funkce porovnání kalendářních dat, jako je NAPŘÍKLAD DATEDIFF nebo DATEADD. |
| LONG | Not supported. Mapování na VARCHAR(MAX). |
| LONG RAW | Not supported. Mapování na VARBINARY(MAX). |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | FLOAT |
| NCLOB | Nepodporuje se přímo. Nahraďte hodnotou NVARCHAR(MAX). |
| NUMERIC | NUMERIC |
| Datové typy medií ORD | Not supported |
| RAW | Not supported. Mapovat na VARBINARY. |
| REAL | REAL |
| ROWID | Not supported. Mapuje se na identifikátor GUID, který je podobný. |
| Geoprostorové datové typy SDO | Not supported |
| SMALLINT | SMALLINT |
| TIMESTAMP | DATETIME2 nebo funkce CURRENT_TIMESTAMP() |
| ČASOVÉ RAZÍTKO S LOKÁLNÍ ČASOVOU ZÓNOU | Not supported. Mapování na DATETIMEOFFSET |
| ČASOVÉ RAZÍTKO S ČASOVÝM PÁSMEM | Nepodporuje se, protože TIME je uložen pomocí standardního času bez posunu časového pásma. |
| URIType | Not supported. Uložte v VARCHAR. |
| UROWID | Not supported. Mapuje se na identifikátor GUID, který je podobný. |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | Not supported. Ukládejte data XML do VARCHAR. |
Oracle také podporuje definování uživatelem definovaných objektů, které mohou obsahovat řadu jednotlivých polí, z nichž každý má vlastní definici a výchozí hodnoty. Na tyto objekty pak lze odkazovat v definici tabulky stejným způsobem jako předdefinované datové typy jako NUMBER nebo VARCHAR. Azure Synapse v současné době nepodporuje uživatelem definované typy. Pokud data, která potřebujete migrovat, zahrnují uživatelsky definované datové typy, buď je "zploštět" do konvenční definice tabulky, nebo pokud jsou pole dat, normalizujte je v samostatné tabulce.
Tip
Vyhodnoťte počet a typ nepodporovaných datových typů během fáze přípravy migrace.
Dodavatelé třetích stran nabízejí nástroje a služby pro automatizaci migrace, včetně mapování datových typů. Pokud je nástroj ETL třetí strany již používán v prostředí Oracle, použijte tento nástroj k implementaci všech požadovaných transformací dat.
Rozdíly v syntaxi SQL DML
Mezi Oracle SQL a Azure Synapse T-SQL existují rozdíly v syntaxi SQL. Tyto rozdíly jsou podrobně popsány v tématu Minimalizace problémů SQL pro migrace Oracle. V některých případech můžete migraci DML automatizovat pomocí nástrojů Microsoftu, jako je SSMA pro Oracle a Azure Database Migration Services nebo produktů a služeb pro migraci třetích stran .
Funkce, uložené procedury a sekvence
Při migraci datového skladu z vyspělého prostředí, jako je Oracle, budete pravděpodobně muset migrovat jiné prvky než jednoduché tabulky a zobrazení. Zkontrolujte, jestli nástroje v prostředí Azure můžou nahradit funkce funkcí, uložených procedur a sekvencí, protože je obvykle efektivnější používat integrované nástroje Azure, než je překódovat pro Azure Synapse.
V rámci přípravné fáze vytvořte inventář objektů, které je potřeba migrovat, definujte metodu pro jejich zpracování a přidělte příslušné prostředky v plánu migrace.
Nástroje Microsoftu, jako je SSMA pro Oracle a Azure Database Migration Services nebo produkty a služby migrace třetích stran , můžou automatizovat migraci funkcí, uložených procedur a sekvencí.
Následující části dále popisují migraci funkcí, uložených procedur a sekvencí.
Functions
Stejně jako většina databázových produktů podporuje Oracle systémové a uživatelem definované funkce v rámci implementace SQL. Při migraci starší verze databázové platformy do Azure Synapse je obvykle možné migrovat běžné systémové funkce beze změny. Některé systémové funkce můžou mít trochu odlišnou syntaxi, ale všechny požadované změny je možné automatizovat. Seznam funkcí v databázi Oracle můžete získat dotazováním ALL_OBJECTS pohledu s příslušnou WHERE klauzulí. Pomocí Oracle SQL Developer můžete získat seznam funkcí, jak je znázorněno na následujícím snímku obrazovky.

V případě systémových funkcí Oracle nebo libovolných uživatelem definovaných funkcí, které nemají v Azure Synapse žádný ekvivalent, překódujte tyto funkce pomocí cílového jazyka prostředí. Uživatelem definované funkce Oracle jsou kódované v PL/SQL, Javě nebo C. Azure Synapse používá jazyk Transact-SQL k implementaci uživatelem definovaných funkcí.
Stored procedures
Většina moderních databázových produktů podporuje ukládání procedur v databázi. Oracle pro tento účel poskytuje jazyk PL/SQL. Uložená procedura obvykle obsahuje příkazy SQL i procedurální logiku a vrací data nebo stav. Seznam uložených procedur v databázi Oracle můžete získat dotazováním ALL_OBJECTS zobrazení s příslušnou WHERE klauzulí. Pomocí Oracle SQL Developer můžete získat seznam uložených procedur, jak je znázorněno na dalším snímku obrazovky.

Azure Synapse podporuje uložené procedury pomocí T-SQL, takže budete muset překódovat všechny migrované uložené procedury v daném jazyce.
Sequences
V Oracle je sekvence pojmenovaný databázový objekt vytvořený pomocí CREATE SEQUENCE. Sekvence poskytuje jedinečné číselné hodnoty prostřednictvím CURRVAL metod a NEXTVAL metod. Vygenerovaná jedinečná čísla můžete použít jako náhradní hodnoty klíče pro primární klíče.
Azure Synapse neimplementuje CREATE SEQUENCE, ale můžete implementovat sekvence pomocí sloupců IDENTITY nebo kódu SQL, který vygeneruje další pořadové číslo v řadě.
Extrahování metadat a dat z prostředí Oracle
Generování jazyka definice dat
Standard ANSI SQL definuje základní syntaxi příkazů DDL (Data Definition Language). Některé příkazy DDL, například CREATE TABLE a CREATE VIEW, jsou společné pro Oracle i Azure Synapse, ale také poskytují funkce specifické pro implementaci, jako je indexování, distribuce tabulek a možnosti dělení.
Existující oracle CREATE TABLE a CREATE VIEW skripty můžete upravit, abyste dosáhli ekvivalentních definic v Azure Synapse. K tomu možná budete muset použít upravené datové typy a odebrat nebo upravit klauzule specifické pro Oracle, například TABLESPACE.
Tabulky systémového katalogu v prostředí Oracle určují aktuální tabulku a definici zobrazení. Na rozdíl od dokumentace spravované uživatelem se informace o katalogu systému vždy dokončí a synchronizují s aktuálními definicemi tabulek. K informacím katalogu systému můžete přistupovat pomocí nástrojů, jako je Oracle SQL Developer. Oracle SQL Developer může generovat CREATE TABLE příkazy DDL, které můžete upravit a vytvářet ekvivalentní tabulky v Azure Synapse.
Nebo můžete pomocí SSMA pro Oracle migrovat tabulky z existujícího prostředí Oracle do Azure Synapse. SSMA pro Oracle použije mapování odpovídajících datových typů a doporučené typy tabulek a distribucí, jak je znázorněno na následujícím snímku obrazovky.

K dosažení podobných výsledků můžete také použít nástroje pro migraci a ETL třetích stran , které zpracovávají informace o katalogu systémů.
Extrakce dat z Oracle
Nezpracovaná data tabulky z tabulek Oracle můžete extrahovat do plochých souborů s oddělovači, jako jsou soubory CSV, pomocí standardních nástrojů Oracle SQL Developer, SQL*Plus a SQLcl. Pak můžete komprimovat ploché soubory s oddělovači pomocí gzipu a nahrát komprimované soubory do azure Blob Storage pomocí nástrojů AzCopy nebo datového přenosu Azure, jako je Azure Data Box.
Extrahujte data tabulky co nejefektivněji – zejména při migraci velkých tabulek faktů. V případě tabulek Oracle použijte paralelismus k maximalizaci propustnosti extrakce. Paralelismus můžete dosáhnout spuštěním více procesů, které jednotlivě extrahují diskrétní segmenty dat, nebo pomocí nástrojů schopných automatizovat paralelní extrakci prostřednictvím dělení.
Tip
Používejte paralelismus pro nejúčinnější extrakci dat.
Pokud je k dispozici dostatečná šířka pásma sítě, můžete extrahovat data z místního systému Oracle přímo do tabulek Azure Synapse nebo Azure Blob Data Storage. K tomu použijte procesy služby Data Factory, službu Azure Database Migration Service nebo migraci dat třetích stran nebo produkty ETL.
Extrahované datové soubory by měly obsahovat oddělený text ve formátu CSV, ORC nebo Parquet.
Další informace o migraci dat a ETL z prostředí Oracle naleznete v tématu Migrace dat, ETL a načítání pro migrace Oracle.
Doporučení k výkonu pro migrace Oracle
Cílem optimalizace výkonu je po migraci do Azure Synapse stejný nebo lepší výkon datového skladu.
Podobnosti v konceptech přístupu ladění výkonu
Mnoho konceptů ladění výkonu pro databáze Oracle platí pro databáze Azure Synapse. For example:
Pomocí distribuce dat můžete sloučit data, která se mají připojit ke stejnému uzlu zpracování.
Pokud chcete ušetřit místo v úložišti a zrychlit zpracování dotazů, použijte nejmenší datový typ pro daný sloupec.
Zajistěte, aby sloupce, které mají být spojené, měly stejný datový typ, aby bylo možné optimalizovat zpracování spojení a snížit potřebu transformací dat.
Abyste optimalizátoru pomohli vytvořit nejlepší plán provádění, ujistěte se, že jsou statistiky aktuální.
Monitorujte výkon pomocí integrovaných databázových funkcí, abyste měli jistotu, že se prostředky efektivně používají.
Tip
Upřednostněte seznámení se s možnostmi ladění Azure Synapse na začátku migrace.
Rozdíly v přístupu ladění výkonu
Tato část popisuje rozdíly implementace optimalizace výkonu nízké úrovně mezi Oracle a Azure Synapse.
Možnosti distribuce dat
Kvůli výkonu byla služba Azure Synapse navržena s architekturou s více uzly a používá paralelní zpracování. Pokud chcete optimalizovat výkon tabulek v Azure Synapse, můžete definovat možnost distribuce dat v CREATE TABLE příkazech pomocí příkazu DISTRIBUTION . Můžete například zadat tabulku distribuovanou hodnotou hash, která distribuuje řádky tabulky mezi výpočetní uzly pomocí deterministické hashové funkce. Mnoho implementací Oracle, zejména starších místních systémů, tuto funkci nepodporuje.
Na rozdíl od Oracle podporuje Azure Synapse místní spojení mezi malou tabulkou a velkou tabulkou prostřednictvím replikace malých tabulek. Představte si například malou tabulku dimenzí a velkou tabulku faktů v rámci modelu hvězdicového schématu. Azure Synapse může replikovat menší tabulku dimenzí napříč všemi uzly, aby se zajistilo, že hodnota jakéhokoli spojovacího klíče pro velkou tabulku má odpovídající místně dostupný řádek dimenze. Náklady na replikaci tabulky dimenzí jsou poměrně nízké pro malou tabulku dimenzí. U velkých dimenzionálních tabulek je vhodnější použít přístup hash distribuce. Další informace o možnostech distribuce dat najdete v pokynech k návrhu pro použití replikovaných tabulek a pokynů k návrhu distribuovaných tabulek.
Tip
Distribuce hodnot hash zlepšuje výkon dotazů u velkých tabulek faktů. Distribuce kruhového dotazování je užitečná pro zlepšení rychlosti načítání.
Distribuci hodnot hash je možné použít u více sloupců pro rovnoměrnější distribuci základní tabulky. Rozdělení s více sloupci vám umožní zvolit až osm sloupců pro distribuci. To nejen snižuje nerovnoměrnou distribuci dat v průběhu času, ale také zlepšuje výkon dotazů.
Note
Distribuce s více sloupci je aktuálně ve verzi Preview pro Azure Synapse Analytics. Pomocí funkce CREATE MATERIALIZED VIEW, CREATE TABLE a CREATE TABLE AS SELECT můžete použít distribuci s více sloupci.
Distribution Advisor
V Azure Synapse SQL je možné přizpůsobit způsob distribuce každé tabulky. Strategie distribuce tabulek podstatně ovlivňuje výkon dotazů.
Distribuční poradce je nová funkce v Synapse SQL, která analyzuje dotazy a doporučuje nejlepší distribuční strategie pro tabulky za účelem zlepšení výkonu dotazů. Dotazy, které má poradce zvážit, můžete poskytnout nebo je získat z vašich historických záznamů dostupných u DMV.
Podrobnosti a příklady použití distribučního poradce najdete v tématu Poradce pro distribuci v Azure Synapse SQL.
Data indexing
Azure Synapse podporuje několik možností indexování definovaných uživatelem, které mají v porovnání s mapami zón spravovaných systémem v Oracle jinou operaci a využití. Další informace o různých možnostech indexování v Azure Synapse najdete v tématu Indexy vyhrazených tabulek fondu SQL.
Definice indexů ve zdrojovém prostředí Oracle poskytují užitečnou informaci o využití dat a kandidátských sloupcích pro indexování v prostředí Azure Synapse. Obvykle nebudete muset migrovat všechny indexy ze starší verze prostředí Oracle, protože Azure Synapse se příliš nespoléhá na indexy a implementuje následující funkce pro dosažení vynikajícího výkonu:
Paralelní zpracování dotazů.
Ukládání dat a sad výsledků do paměti a mezipaměti.
Distribuce dat, například replikace malých tabulek dimenzí, aby se snížil počet vstupně-výstupních operací.
Data partitioning
V podnikovém datovém skladu můžou tabulky faktů obsahovat miliardy řádků. Dělení optimalizuje údržbu a dotazování těchto tabulek jejich rozdělením do samostatných částí, aby se snížil objem zpracovávaných dat. V Azure Synapse příkaz CREATE TABLE definuje specifikaci dělení tabulky.
K rozdělení můžete použít pouze jedno pole v tabulce. Toto pole je často datové pole, protože řada dotazů se filtruje podle data nebo rozsahu dat. Dělení tabulky je možné změnit po počátečním načtení pomocí CREATE TABLE AS příkazu (CTAS) k opětovnému vytvoření tabulky s novou distribucí. Podrobnou diskuzi o dělení ve službě Azure Synapse najdete v tématu Dělení tabulek ve vyhrazeném fondu SQL.
PolyBase nebo COPY INTO pro načítání dat
PolyBase podporuje efektivní načítání velkých objemů dat do datového skladu pomocí paralelních načítání datových proudů. Další informace najdete v tématu Strategie načítání dat PolyBase.
FUNKCE COPY INTO také podporuje příjem dat s vysokou propustností a:
- Načítání dat ze všech souborů ve složce a podsložkách
- Načítání dat z více umístění ve stejném účtu úložiště Pomocí cest oddělených čárkami můžete zadat více umístění.
- Azure Data Lake Storage (ADLS) a úložiště Azure Blob Storage
- Formáty souborů CSV, PARQUET a ORC
Tip
Doporučeným způsobem načítání dat je použití COPY INTO společně s formátem souboru PARQUET.
Workload management
Spouštění smíšených úloh může představovat problémy s prostředky v zaneprázdněných systémech. Úspěšné schéma správy úloh efektivně spravuje prostředky, zajišťuje vysoce efektivní využití prostředků a maximalizuje návratnost investic (ROI). Klasifikace úloh, důležitost úloh a izolace úloh poskytují větší kontrolu nad tím, jak úlohy využívají systémové prostředky.
Průvodce správou úloh popisuje techniky analýzy úlohy, správu a monitorování důležitosti úloh a postup převodu třídy prostředků na skupinu úloh. Pomocí portálu Azure a T-SQL dotazů na DMV monitorujte pracovní zátěž, abyste zajistili efektivní využití příslušných prostředků.
Next steps
Další informace o ETL a načítání během migrace Oracle najdete v dalším článku této série: Migrace dat, ETL a načítání během migrací Oracle.