Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Copilot v Microsoft Fabric je technologie pro usnadnění generování AI, která má za cíl vylepšit možnosti analýzy dat na platformě Fabric. Tento článek vám pomůže pochopit, jak Copilot v rámci Fabric funguje, a poskytne vám základní pokyny a úvahy o tom, jak jej můžete nejlépe využít.
Poznámka:
Možnosti copilotu se v průběhu času vyvíjejí. Pokud máte v úmyslu používat Copilot, ujistěte se, že budete mít přehled o měsíčních aktualizacích Fabricu a jakýchkoli změnách nebo oznámeních ohledně zkušeností s Copilotem.
Tento článek vám pomůže pochopit, jak Copilot in Fabric funguje, včetně architektury a nákladů. Informace v tomto článku vám a vaší organizaci pomohou efektivně používat a spravovat Copilot. Tento článek je primárně zaměřen na:
Ředitelé nebo manažeři BI a analýzy: Rozhodovací pracovníci, kteří zodpovídají za dohled nad BI programem a strategií a kteří rozhodují, zda povolit a využívat Copilot ve Fabric nebo jiné nástroje AI.
Správci služby Fabric: Lidé v organizaci, kteří dohlížejí na Microsoft Fabric a na různé úlohy. Správci Fabric dohlížejí na to, kdo může používat Copilot pro každou z těchto úloh ve Fabric, a sledují, jak využití Copilotu ovlivňuje dostupnou kapacitu Fabric.
Datová architekti: Lidé zodpovědní za navrhování, sestavování a správu platforem a architektury, které podporují data a analýzy v organizaci. Datové architekty zvažují použití Copilotu v návrhu architektury.
Týmy CENTER OF Excellence (COE), IT a BI: Týmy, které jsou zodpovědné za usnadnění úspěšného přijetí a používání datových platforem, jako je Fabric v organizaci. Tyto týmy a jednotlivci můžou využívat nástroje umělé inteligence, jako je Například Copilot, ale také podpora a mentorování samoobslužných uživatelů v organizaci, aby je mohli využívat i oni.
Přehled fungování Copilotu ve službě Fabric
Copilot in Fabric funguje podobně jako ostatní Microsoft Copiloty, jako je Microsoft 365 Copilot, Microsoft Security Copilot a Copiloty a generativní AI v Power Platform. Existuje však několik aspektů, které jsou specifické pro to, jak ve Fabric funguje Copilot.
Diagram přehledu procesů
Následující diagram znázorňuje přehled fungování Copilotu ve Fabricu.
Poznámka:
Následující diagram znázorňuje obecnou architekturu Copilotu ve Fabric. V závislosti na konkrétní úloze a zkušenostech ale můžou být přidání nebo rozdíly.
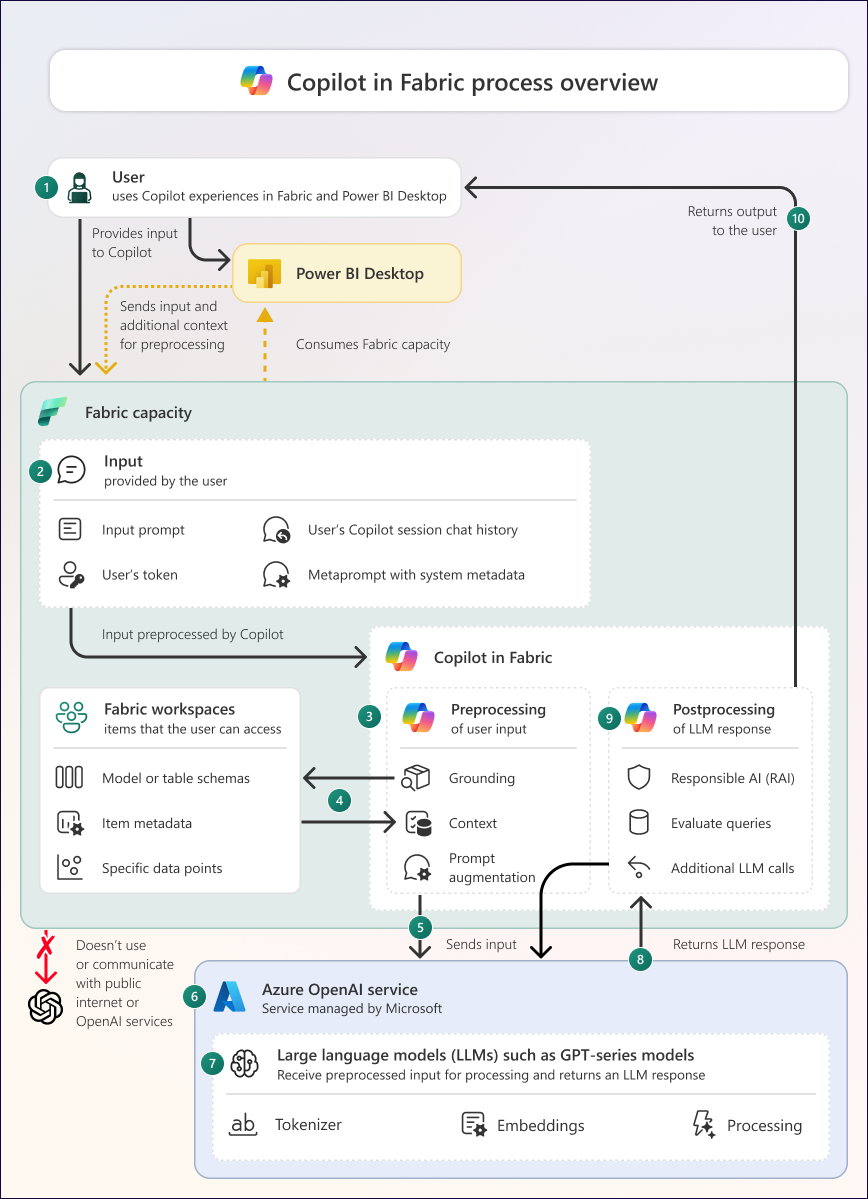
Diagram se skládá z následujících částí a procesů:
| Položka | Popis |
|---|---|
| 1 | Uživatel poskytne vstup pro Copilot ve službě Fabric, Power BI Desktop nebo mobilní aplikaci Power BI. Vstupem může být zapsaná výzva nebo jiná interakce, která vygeneruje výzvu. Všechny interakce s Copilotem jsou specifické pro uživatele. |
| 2 | Vstup obsahuje informace, které zahrnují prompt, token uživatele a kontext, jako je historie chatu relace Copilot uživatele a meta-prompt s metadaty systému, včetně toho, kde je uživatel a co dělá ve Fabric nebo Power BI Desktop. |
| 3 | Copilot zpracovává předběžné a následné zpracování uživatelských vstupů a odpovědí modelu velkého jazyka (LLM), v uvedeném pořadí. Určité konkrétní kroky provedené během předběžného zpracování a následného zpracování závisí na tom, které prostředí Copilotu používá jednotlivec. Copilot musí být povolen správcem Fabricu v nastavení klienta, aby jej bylo možné používat. |
| 4 | Během předběžného zpracování provede Copilot ověření a načte další kontextové informace, aby byla vyšší specificita a užitečnost konečné odpovědi LLM. Podkladová data můžou zahrnovat metadata (například schéma z lakehouse nebo sémantického modelu) nebo datové body z položek v pracovním prostoru, nebo historii chatu z aktuální relace se Copilotem. Copilot načte pouze zakládací data, ke kterým má uživatel přístup. |
| 5 | Výsledkem předběžného zpracování jsou konečné vstupy: finální prompt a základní data. Která data se odesílají, závisí na konkrétním prostředí Copilotu a na tom, o jaká uživatel žádá. |
| 6 | Copilot odešle vstup do služby Azure OpenAI. Tuto službu spravuje Microsoft a uživatel ji nemůže konfigurovat. Azure OpenAI nevytrénuje modely s vašimi daty. Pokud není Azure OpenAI ve vaší geografické oblasti k dispozici a povolili jste nastavení Data odesílaná do Azure OpenAI mohou být zpracovávána mimo geografickou oblast vaší kapacity, hranici dodržování předpisů nebo národní cloudovou instanci, pak může Copilot odesílat vaše data mimo tyto geografické oblasti. |
| 7 | Azure OpenAI hostuje LLMy, jako je řada modelů GPT. Azure OpenAI nepoužívá veřejné služby ani rozhraní API OpenAI a OpenAI nemá přístup k vašim datům. Tyto LLM tokenizují vstup a používají vkládání ze svých trénovacích dat ke zpracování vstupů do odpovědi. LLM jsou omezené v rozsahu a měřítku trénovacích dat. Azure OpenAI obsahuje konfiguraci, která určuje, jak LLM zpracuje vstup a jakou odpověď vrátí. Zákazníci si tuto konfiguraci nemůžou zobrazit ani změnit. Volání služby OpenAI se provádí prostřednictvím Azure, a ne přes veřejný internet. |
| 8 | Odpověď LLM je odeslána z Azure OpenAI do Copilotu ve Fabricu. Tato odpověď se skládá z textu, což může být přirozený jazyk, kód nebo metadata. Odpověď může obsahovat nepřesné nebo málo kvalitní informace. Je to také ne deterministické, což znamená, že pro stejný vstup může být vrácena jiná odpověď. |
| 9 | Copilot dodatečně zpracovává odpověď LLM. Následné zpracování zahrnuje filtrování pro zodpovědnou umělou inteligenci, ale také zpracování odpovědí modelů LLM a vytvoření konečného výstupu pro Copilot. Konkrétní kroky prováděné během následného zpracování závisí na prostředí Copilotu pro individuální použití. |
| 10 | Copilot vrátí uživateli konečný výstup. Uživatel před použitím zkontroluje výstup, protože výstup neobsahuje žádnou informaci o spolehlivosti, přesnosti nebo důvěryhodnosti. |
Následující části popisují pět kroků v procesu Copilotu znázorněném v předchozím diagramu. Tento postup podrobně vysvětluje, jak Copilot přechází ze vstupu uživatele na výstup uživatele.
Krok 1: Uživatel poskytuje vstup do Copilotu
Pokud chcete použít Copilot, musí uživatel nejprve odeslat vstup. Tento vstup může být napsaná výzva, kterou uživatel odešle sám, nebo může být výzvou vygenerovanou copilotem, když uživatel vybere interaktivní prvek v uživatelském rozhraní. V závislosti na konkrétním úkolu v rámci platformy Fabric, položce a zkušenosti s Copilotem, kterou uživatel používá, existují různé způsoby, jak poskytnout vstup Copilotu.
Následující části popisují několik příkladů, jak uživatel může poskytnout vstupy do Copilotu.
Vstup prostřednictvím panelu chatu Copilot
S mnoha zážitky Copilot na platformě Fabric můžete rozšířit panel chatu Copilot pro interakci s Copilotem pomocí přirozeného jazyka, stejně jako byste komunikovali s chatbotem nebo službou pro zasílání zpráv. Na panelu chatu Copilot můžete napsat výzvu přirozeného jazyka popisující akci, kterou chcete provést. Případně panel chatu Copilot může obsahovat tlačítka s navrhovanými výzvami, které můžete vybrat. Interakce s těmito tlačítky způsobí, že Copilot vygeneruje odpovídající výzvu.
Následující obrázek ukazuje příklad použití panelu chatu Copilot k položení datové otázky týkající se sestavy Power BI.

Poznámka:
Pokud používáte prohlížeč Microsoft Edge, můžete tam mít také přístup ke Copilotu. Copilot v Edgi také může otevřít panel chatu Copilot (nebo boční panel) v prohlížeči. Copilot v Edge nemůže interagovat ani používat žádnou z funkcí Copilot ve Fabric. I když oba Copiloty mají podobné uživatelské prostředí, Copilot v Edge je zcela oddělený od Copilot ve Fabric.
Vstup prostřednictvím automaticky otevíraných oken závislých na kontextu
V určitých prostředích můžete výběrem ikony Copilot aktivovat automaticky otevírané okno pro interakci s Copilotem. Mezi příklady patří použití Copilotu v zobrazení dotazu DAX nebo v zobrazení skriptování TMDL v Power BI Desktopu. Toto vyskakovací okno obsahuje oblast pro zadání výzvy v přirozeném jazyce (podobně jako panel chatu Copilot) a také kontextová tlačítka, která vám můžou vygenerovat výzvu. Toto okno může také obsahovat výstupní informace, jako jsou vysvětlení dotazů DAX nebo konceptů při použití Copilotu v zobrazení dotazu DAX.
Následující obrázek ukazuje příklad uživatele používajícího prostředí Copilot v zobrazení dotazu DAX, který vysvětluje dotaz, který vygeneroval pomocí Copilotu v Power BI.

Typy uživatelských vstupů
Vstupy copilotu můžou být z napsané výzvy nebo tlačítka v uživatelském rozhraní:
Napsaná výzva: Uživatel může na panel chatu Copilot napsat výzvu nebo v jiných prostředích Copilotu, jako je zobrazení dotazu DAX v Power BI Desktopu. Písemné výzvy vyžadují, aby uživatel odpovídajícím způsobem vysvětlil instrukce nebo otázku pro Copilot. Uživatel může například položit otázku týkající se sémantického modelu nebo sestavy při použití Copilotu v Power BI.
Knoflík: Uživatel může vybrat tlačítko na panelu chatu Copilot nebo v jiných prostředích Copilot a zadat vstup. Copilot pak vytvoří výzvu na základě výběru uživatele. Tato tlačítka mohou být počátečním vstupem do Copilotu, například návrhy na panelu chatu Copilot. Tato tlačítka se ale můžou objevit i během relace, když Copilot nabídne návrhy nebo žádosti o objasnění. Dotaz, který Copilot vygeneruje, závisí na kontextu, jako je například historie chatu aktuální relace. Příkladem zadání pomocí tlačítka je situace, kdy požádáte Copilot o návrhy synonym pro pole modelu nebo popisy pro parametry modelu.
Kromě toho můžete poskytovat vstupy v různých službách nebo aplikacích:
Tkanina: Z webového prohlížeče můžete použít Copilot in Fabric. Toto je jediný způsob, jak použít Copilot pro všechny položky, které vytváříte, spravujete a používáte v prostředí Fabric.
Power BI Desktop: Funkci Copilot v Power BI Desktopu můžete použít se sémantickými modely a sestavami. Patří sem prostředí Copilot pro vývoj a spotřebu pro úlohu Power BI v rámci Fabricu.
Mobilní aplikace Power BI: Funkci Copilot můžete použít v mobilní aplikaci Power BI, pokud je sestava v podporovaném pracovním prostoru (nebo v aplikaci připojené k tomu pracovnímu prostoru) se zapnutým Copilotem.
Poznámka:
Pokud chcete použít Copilot s Power BI Desktopem, musíte Nakonfigurovat Power BI Desktop tak, aby používal spotřebu Copilotu z podporovaného pracovního prostoru podporovaného kapacitou Fabric. Pak můžete použít Copilot s sémantickými modely publikovanými do libovolného pracovního prostoru, včetně pracovních prostorů Pro a PPU.
I když nemůžete změnit výzvy, které Copilot generuje, když vyberete tlačítko s napsanými výzvami, můžete klást otázky a poskytovat pokyny pomocí přirozeného jazyka. Jedním z nejdůležitějších způsobů, jak zlepšit výsledky, které získáváte s Copilotem, je psát jasné a popisné výzvy, které přesně vyjádří, co chcete udělat.
Vylepšení psaných výzev pro Copilot
Srozumitelnost a kvalita výzvy, kterou uživatel odešle do Copilotu, může ovlivnit užitečnost výstupu, který uživatel obdrží. Co představuje dobrou napsanou výzvu, závisí na konkrétním prostředí copilotu, které používáte; Existují však některé techniky, které můžete použít pro všechna prostředí, aby se vaše výzvy obecně zlepšily.
Tady je několik způsobů, jak vylepšit výzvy, které odešlete do Copilotu:
Použijte anglické jazykové výzvy: Funkce Copilotu dnes fungují nejlépe v angličtině. Je to proto, že korpus trénovacích dat pro tyto LLMs je většinou angličtina. Jiné jazyky nemusí fungovat stejně. Můžete se pokusit psát výzvy v jiných jazycích, ale pro nejlepší výsledky doporučujeme psát a odesílat výzvy pro angličtinu.
Buďte specifická: Vyhněte se nejednoznačnosti nebo vágnosti v otázkách a pokynech. Uveďte dostatečné podrobnosti k popisu úlohy, kterou má Copilot provést, a výstup, který očekáváte.
Zadejte kontext: V případě potřeby uveďte relevantní kontext výzvy, včetně toho, co chcete udělat nebo na jakou otázku chcete odpovědět výstupem. Důležité složky dobré výzvy mohou například zahrnovat:
- Cíl: Jaký výstup má Copilot dosáhnout.
- Kontext: Co máte v úmyslu udělat s tímto konkrétním výstupem a proč.
- Očekávání: Jak očekáváte, bude výstup vypadat.
- Zdroj: Jaká data nebo pole Copilot by měly používat.
Používejte slovesa: Jednoznačně uvádějte konkrétní akce, které má Copilot provést, například "vytvořte stránku sestavy" nebo "filtrovat na klíčové účty zákazníků".
Použijte správnou a relevantní terminologii: Explicitně si projděte příslušné termíny v příkazovém řádku, jako jsou názvy funkcí, polí nebo tabulek, typy vizuálů nebo technická terminologie. Vyhněte se chybně napsaným znakům, zkratkám nebo zkratkám a nadbytečné gramatikě nebo atypickým znakům, jako jsou znaky Unicode nebo emoji.
Iterace a řešení potíží: Pokud se očekávaný výsledek nezobrazí, zkuste upravit výzvu a znovu ji odeslat, abyste zjistili, jestli se tím výstup nezlepší. Některá prostředí Copilotu také poskytují tlačítko Opakovat pro opětovné odeslání stejné výzvy a vyhledání jiného výsledku.
Důležité
Zvažte, zda uživatele nejprve nevyškolit k psaní dobrých výzev, než jim povolíte Copilot. Zajistěte, aby uživatelé pochopili rozdíl mezi jasnou výzvou, která může vést k užitečným výsledkům, a nejasnou výzvou, která ne.
Copilot a mnoho dalších nástrojů LLM jsou také ne deterministické. To znamená, že dva uživatelé, kteří odesílali stejnou výzvu, která používají stejná podkladová data, mohou získat různé výsledky. Tento ne determinismus je podstatou základní technologie generující umělé inteligence a je důležitým aspektem, pokud očekáváte nebo potřebujete deterministické výsledky, jako je odpověď na otázku dat, například "Co jsou prodeje v srpnu 2021?"
Další vstupní informace, které Copilot používá při předběžném zpracování
Kromě vstupu, který uživatel poskytuje, copilot také načte další informace, které používá při předběžném zpracování během dalšího kroku. Mezi tyto informace patří:
Token uživatele. Copilot nefunguje pod systémovým účtem ani autoritou. Všechny informace odeslané a používané společností Copilot jsou specifické pro uživatele; Copilot nemůže uživateli povolit zobrazení nebo přístup k položkám nebo datům, ke kterým ještě nemá oprávnění k zobrazení.
Historie chatu Copilot pro aktuální sezení. U chatovacích prostředí nebo panelu chatu Copilot vždy poskytuje Copilot historii chatu pro použití při předběžném zpracování v rámci kontextu podkladových dat. Copilot si nepamatuje ani nepoužívá historii chatu z předchozích relací.
Meta-výzva se systémovými metadaty. Meta-prompt poskytuje další kontext o tom, kde se uživatel nachází a co dělá ve Fabric nebo Power BI Desktop. Tyto informace metaobtázové výzvy se používají při předběžném zpracování k určení dovednosti nebo nástroje Copilotu, které by měly použít k zodpovězení otázky uživatele.
Jakmile uživatel odešle svůj vstup, Copilot pokračuje k dalšímu kroku.
Krok 2: Copilot předzpracovává vstup
Před odesláním výzvy do služby Azure OpenAI ji Copilot předzpracovává. Předběžné zpracování představuje všechny akce, které zpracovává Copilot mezi tím, kdy přijímá vstup a kdy se tento vstup zpracuje ve službě Azure OpenAI. Předzpracování je nezbytné, aby byl výstup copilotu specifický a vhodný pro vaše pokyny nebo otázky.
Nelze ovlivnit, jaké předzpracování provádí Copilot. Je ale důležité porozumět předběžnému zpracování, abyste věděli, jaká data Copilot používá a jak je získává. To se týká pochopení nákladů na Copilot ve Fabric a při řešení potíží s tím, proč generuje nesprávný nebo neočekávaný výsledek.
Návod
V určitých scénářích můžete také upravovat položky tak, aby byla jejich data lépe strukturována pro použití Copilota. Příkladem je provádění lingvistického modelování v sémantickém modelu nebo přidání synonym a popisů do sémantických měr a sloupců modelu.
Následující diagram znázorňuje, co se stane během předzpracování pomocí Copilota ve Fabric.
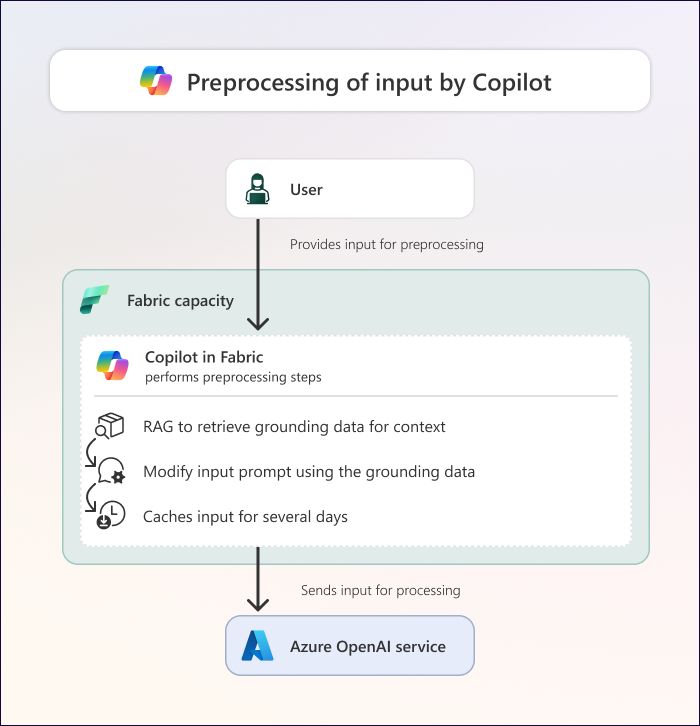
Po přijetí uživatelského vstupu provádí Copilot předběžné zpracování, což zahrnuje následující kroky:
Zakotvení: Copilot provádí generování s rozšířeným vyhledáváním (RAG) ke shromažďování podkladových dat. Základní data zahrnují relevantní informace z aktuálního kontextu, ve kterém používáte Copilot v prostředí Fabric. Podkladová data můžou zahrnovat kontext, například:
- Historie chatu z aktuální relace s Copilotem.
- Metadata o položce Fabric, kterou používáte s Copilotem (jako je schéma sémantického modelu nebo lakehouse, nebo metadata z vizuálu sestavy).
- Konkrétní datové body, například datové body zobrazené ve vizuálu sestavy. Metadata sestavy ve vizuální konfiguraci také obsahují datové body.
- Meta-výzvy, které jsou doplňkovými pokyny poskytované pro každý zážitek, aby pomohly zajistit konkrétnější a konzistentnější výstup.
Rozšíření výzvy: V závislosti na scénáři Copilot přepíše (nebo rozšíří) výzvu na základě vstupních a kontextových dat. Rozšířená výzva by měla být lepší a více si uvědomovat kontext než původní vstupní výzva.
Ukládání do mezipaměti: V určitých scénářích Copilot ukládá vaši výzvu a podkladová data do mezipaměti na 48 hodin. Ukládání výzvy do mezipaměti zajistí, že opakované výzvy vrátí stejné výsledky, zatímco jsou uloženy v mezipaměti, vrátí tyto výsledky rychleji a že nevyužíváte kapacitu Fabrič jen pro opakování výzvy ve stejném kontextu. Ukládání do mezipaměti probíhá na dvou různých místech:
- Mezipaměť prohlížeče uživatele.
- První back-endová mezipaměť v domovské oblasti tenanta, kde je uložená pro účely auditování. Ve službě Azure OpenAI ani v umístění grafických procesorů nejsou uložená žádná data. Další informace o ukládání do mezipaměti ve službě Microsoft Fabric najdete v whitepaperu o zabezpečení Microsoft Fabric.
Odesílání vstupu do Azure OpenAI: Copilot odešle rozšířenou výzvu a relevantní podkladová data do služby Azure OpenAI.
Když Copilot provádí uzemnění, shromažďuje pouze informace z dat nebo položek, ke kterým má uživatel normální přístup. Copilot respektuje role pracovního prostoru, oprávnění položek a zabezpečení dat. Copilot také nemůže získat přístup k datům od jiných uživatelů; interakce s Copilotem jsou specifické pro každého jednotlivého uživatele.
Data, která Copilot shromažďuje během procesu inicializace a které Azure OpenAI zpracovává, závisí na konkrétním prostředí Copilotu, které používáte. Další informace naleznete v tématu Jaká data copilot používá a jak se zpracovávají?.
Po dokončení předběžného zpracování a po odeslání vstupu do Azure OpenAI může služba Azure OpenAI zpracovat tento vstup a vytvořit odpověď a výstup odeslaný zpět do Copilotu.
Krok 3: Azure OpenAI zpracuje výzvu a vygeneruje výstup
Všechna prostředí Copilotu využívají službu Azure OpenAI.
Vysvětlení služby Azure OpenAI
Copilot používá Azure OpenAI ( nikoli veřejně dostupné služby OpenAI) ke zpracování všech dat a vrácení odpovědi. Jak už bylo zmíněno dříve, tuto odpověď vytvořilo LLM. LLMs jsou specifický přístup k "úzké" umělé inteligenci, který se zaměřuje na použití hloubkového učení k hledání a reprodukování vzorů v nestrukturovaných datech; konkrétně text. Text v tomto kontextu zahrnuje přirozený jazyk, metadata, kód a jakékoli další sémanticky smysluplné uspořádání znaků.
Copilot v současné době používá kombinaci modelů GPT, včetně řady Modelů GpT (Generative Pre-Trained Transformer) z OpenAI.
Poznámka:
Modely, které copilot používá, nemůžete zvolit ani změnit, včetně použití jiných základních modelů nebo vlastních modelů. Copilot ve Fabric používá různé modely. Není také možné změnit nebo nakonfigurovat službu Azure OpenAI tak, aby se s využitím Copilotu v Fabric chovala odlišně. tuto službu spravuje Microsoft.
Modely používané Copilotem ve Fabric v současné době nepoužívají žádné další úpravy. Modely místo toho spoléhají na zakotvení dat a meta-podněty k vytvoření konkrétnějších a užitečnějších výstupů.
Modely používané Copilotem ve Fabric v současné době nepoužívají žádné další úpravy. Modely místo toho spoléhají na zakotvení dat a meta-podněty k vytvoření konkrétnějších a užitečnějších výstupů.
Microsoft hostuje modely OpenAI v prostředí Microsoft Azure a služba nepracuje s veřejnými službami openAI (například ChatGPT nebo veřejná rozhraní API OpenAI). Vaše data se nepoužívají k trénování modelů a nejsou k dispozici pro ostatní zákazníky. Další informace najdete ve službě Azure OpenAI.
Principy tokenizace
Je důležité, abyste porozuměli tokenizaci, protože náklady Copilota v rámci Fabric (které určují, kolik kapacity Fabric Copilot spotřebuje), jsou určeny počtem tokenů, které pocházejí z vašich vstupů a výstupů Copilota.
Aby bylo možné zpracovat textový vstup z Copilotu, azure OpenAI musí nejprve tento vstup převést na číselnou reprezentaci. Klíčovým krokem v tomto procesu je tokenizace, což je dělení vstupního textu do různých menších částí, označovaných jako tokeny. Token je sada společně se vyskytujících znaků a jedná se o nejmenší jednotku informací, kterou LLM používá k vytvoření výstupu. Každý token má odpovídající číselné ID, které se stane slovníkem LLM pro kódování a použití textu jako čísel. Existují různé způsoby, jak tokenizovat text a různé LLMs tokenizují vstupní text různými způsoby. Azure OpenAI používá Byte-Pair Encoding (BPE), což je metoda tokenizace dílčího slova.
Pokud chcete lépe porozumět tomu, co je token a jak se výzva rozpadá na tokeny, považte následující příklad. Tento příklad ukazuje vstupní výzvu a její tokeny, odhadované pomocí tokenizátoru platformy OpenAI (pro GPT4). Pod zvýrazněnými tokeny v textu výzvy je pole (nebo seznam) ID číselných tokenů.

V příkladu každé jiné barevné zvýraznění označuje jeden token. Jak už bylo zmíněno dříve, Azure OpenAI používá tokenizaci subword , takže token není slovo, ale také není znakem nebo pevným počtem znaků. Například "sestava" je jeden token, ale "." je také.
Pokud chcete znovu zopakovat, měli byste pochopit, co token je, protože náklady na Copilot (nebo jeho rychlost spotřeby kapacity Fabric) jsou určeny tokeny. Pochopení toho, co je token a jak se vytvářejí vstupní a výstupní tokeny, vám proto pomůže pochopit a předvídat, jak využití Copilotu vede ke spotřebě jednotek CU Fabric. Další informace o nákladech na Copilot v Fabric najdete v příslušné části dále v tomto článku.
Copilot ve Fabric používá vstupní i výstupní tokeny, jak je znázorněno v následujícím diagramu.

Copilot vytvoří dva různé druhy tokenů:
- Vstupní tokeny jsou výsledkem tokenizace konečné výzvy i všech podkladových dat.
- Výsledkem výstupních tokenů je tokenizace odpovědi LLM.
Některé funkce Copilotu vedou k několika voláním LLM. Například při pokládání otázek týkajících se dat o modelech a reportech může první odpověď LLM představovat dotaz vyhodnocený proti sémantickému modelu. Copilot pak znovu odešle výsledek tohoto vyhodnoceného dotazu do Azure OpenAI a požádá o souhrn, který Azure OpenAI vrátí s jinou odpovědí. Tato další volání LLM mohou být zpracována a odpovědi LLM kombinované během kroku následného zpracování.
Poznámka:
S Copilotem ve Fabric, s výjimkou změn u psaného vstupního pokynu, můžete optimalizovat pouze vstupní a výstupní tokeny úpravou konfigurace relevantních položek, jako je skrytí sloupců v sémantickém modelu nebo snížení počtu vizuálů nebo stránek v reportu. Před odesláním do Azure OpenAI pomocí Copilotu nemůžete zachytávat ani upravovat podkladová data.
Porozumět zpracování
Je důležité pochopit, jak LLM v Azure OpenAI zpracovává vaše data a vytváří výstup, abyste lépe pochopili, proč získáte určité výstupy z Copilotu a proč byste je měli před dalším použitím nebo rozhodováním kriticky ohodnotit.
Poznámka:
Tento článek obsahuje jednoduchý základní přehled o tom, jak llmy, které Copilot používá (například GPT) fungují. Technické podrobnosti a hlubší porozumění tomu, jak modely GPT zpracovávají vstupy, aby vytvořily odpověď, nebo o jejich architektuře, si přečtěte výzkumné práce Attention Is All You Need (2017) od Ashish Vaswani a dalších a Language Models are Few-Shot Learners (2020) od Tom Browna a kolektivu.
Účelem copilotu (a obecně LLM) je poskytnout kontextově vhodný, užitečný výstup na základě vstupu, který uživatel poskytuje, a dalších relevantních podkladových dat. LLM to dělá tím, že interpretuje význam tokenů v podobném kontextu, jak je vidět v jejich trénovacích datech. Abychom získali smysluplné sémantické porozumění tokenům, vytrénovali jsme LLM na masivní datové sady, o kterých se myslelo, že se skládá z informací o autorských právech i ve veřejné doméně. Tato trénovací data jsou však omezená z hlediska aktuálnosti obsahu, kvality a rozsahu, což vytváří omezení pro LLM a nástroje, které je používají, například Copilot. Další informace o těchto omezeních viz Porozumění omezením Copilota a LLM dále v tomto článku.
Sémantický význam tokenu je zachycen v matematické konstrukci, která se označuje jako embedding, což změní tokeny na husté vektory skutečných čísel. Jednoduše řečeno, embeddingy poskytují LLM sémantický význam daného tokenu na základě ostatních tokenů kolem něj. Tento význam závisí na trénovacích datech LLM. Představte si tokeny, jako jsou jedinečné stavební bloky, zatímco vkládání pomáhá LLM vědět, jaký blok se má použít.
LLM v Azure OpenAI zpracuje váš vstup pomocí tokenů a embeddingů a vygeneruje odpověď. Toto zpracování je výpočetně náročný úkol, který vyžaduje významné prostředky, což je místo, odkud náklady pocházejí. LLM generuje svou odpověď token po tokenu, přičemž každý token vybírá na základě vypočítané pravděpodobnosti z kontextu vstupu. Každý vygenerovaný token se také přidá do existujícího kontextu před vytvořením dalšího tokenu. Konečná odpověď LLM proto musí být vždy text, který může Copilot později postprocesovat, aby vytvořil užitečnější výstup pro uživatele.
Je důležité porozumět několika klíčovým aspektům této vygenerované odpovědi:
- Není to deterministické; stejný vstup může vytvořit jinou odpověď.
- Uživatel ji může interpretovat jako nízkou kvalitu nebo nesprávnou v kontextu.
- Je založeno na trénovacích datech LLM, která jsou ve svém rozsahu omezená a konečná.
Pochopte omezení Copilotu a LLMs
Je důležité pochopit a uznat omezení Copilotu a základních technologií, které používá. Pochopení těchto omezení vám pomůže získat hodnotu z Copilotu a zároveň zmírnit rizika spojená s jeho používáním. Aby bylo možné efektivně používat Copilot v rámci Fabric, měli byste porozumět praktickým scénářům a možnostem využití, které této technologii nejlépe vyhovují.
Při použití Copilotu ve Fabric je důležité mít na paměti následující aspekty:
Copilot ve Fabric není deterministický. S výjimkou případů, kdy se dotaz a jeho výstup ukládají do mezipaměti, může stejný vstup vytvořit různé výstupy. Když přijmete rozsah možných výstupů, jako je stránka sestavy, vzor kódu nebo souhrn, není to takový problém, protože můžete tolerovat a dokonce očekávat různorodost v odpovědi. V případě scénářů, kdy očekáváte pouze jednu správnou odpověď, ale možná budete chtít zvážit alternativní přístup ke Copilotu.
Copilot v rámci technologie Fabric může vytvářet výstupy nízké kvality nebo nepřesné: Stejně jako je tomu u všech nástrojů LLM je možné, že Copilot vytvoří výstupy, které nemusí být správné, očekávané nebo vhodné pro váš scénář. To znamená, že byste se měli vyhnout použití Copilot ve Fabric s citlivými daty nebo ve vysoce rizikových oblastech. Neměli byste například používat výstupy Copilotu k zodpovězení otázek na data týkajících se důležitých obchodních procesů ani k vytváření datových řešení, která by mohla ovlivnit osobní nebo kolektivní pohodu jednotlivců. Uživatelé by měli před použitím zkontrolovat a ověřit výstupy Copilotu.
Copilot nemá žádné znalosti o "přesnosti" nebo "pravdivosti": Výstupy, které Copilot poskytuje, nezoznačují důvěryhodnost, spolehlivost ani podobné mínění. Základní technologie zahrnuje rozpoznávání vzorů a nedokáže vyhodnotit kvalitu nebo užitečnost svých výstupů. Uživatelé by měli výstupy kriticky vyhodnotit předtím, než tyto výstupy použijí v jiné práci nebo rozhodování.
Copilot nemůže uvažovat, chápat váš záměr ani znát kontext nad rámec svých vstupních údajů: Zatímco uzemnění Copilotu zajišťuje, že výstupy jsou konkrétnější, samotné uzemnění nemůže poskytnout Copilotu všechny potřebné informace k zodpovězení vašich otázek. Pokud například pomocí Copilotu vygenerujete kód, Copilot stále neví, co s tímto kódem budete dělat. To znamená, že kód může fungovat v jednom kontextu, ale ne v jiném a uživatelé musí buď upravit výstup, nebo jejich výzvu k vyřešení.
Výstupy copilotu jsou omezené trénovacími daty LLM, které používá: V určitých prostředích Copilotu, například těch, ve kterých generujete kód, můžete chtít, aby Copilot vygeneroval kód pomocí nově vydané funkce nebo vzoru. Pokud ale v trénovacích datech modelů GPT, které Copilot používá, nejsou příklady toho, nebude tento postup moci efektivně provést. K tomu dochází také v případě, že se pokusíte použít Copilot na kontexty, které jsou v trénovacích datech řídké, například při použití Copilotu s editorem TMDL v Power BI Desktop. V těchto případech byste měli být obzvláště ostražití a kritičtí vůči nekvalitním nebo nepřesným výstupům.
Výstraha
Aby se zmírnila rizika těchto omezení a úvah, a s ohledem na to, že Copilot, LLMs a generativní AI jsou nově vznikající technologie, neměli byste používat Copilot ve Fabric pro autonomní, vysoce rizikové nebo kritické obchodní procesy a rozhodování.
Další informace najdete v doprovodných materiálech zabezpečení pro LLM.
Jakmile služba Azure OpenAI zpracuje vstup a vytvoří odpověď, vrátí tuto odpověď jako výstup do Copilotu.
Krok 4: Copilot provádí následné zpracování výstupu
Po přijetí odpovědi z Azure OpenAI provede Copilot další následné zpracování, aby se zajistilo, že je odpověď vhodná. Účelem následného zpracování je vyfiltrovat nevhodný obsah.
Pokud chcete provést následné zpracování, může Copilot provádět následující úlohy:
Zodpovědné kontroly umělé inteligence: Zajištění toho, aby Copilot odpovídal zodpovědným standardům AI v Microsoftu. Další informace naleznete v tématu Co bych měl vědět používat Copilot zodpovědně?
Filtrování pomocí moderování obsahu Azure: Filtrováním odpovědí zajistíte, že Copilot vrátí pouze odpovědi vhodné pro scénář a prostředí. Tady je několik příkladů, jak Copilot provádí filtrování pomocí moderování obsahu Azure:
- Nezamýšlené nebo nesprávné použití: Moderování obsahu zajišťuje, že ho nebudete moct používat v nezamýšlených nebo nesprávných způsobech, jako je kladení otázek na jiná témata mimo rozsah úlohy, položky nebo prostředí, které používáte.
- Nevhodné nebo urážlivé výstupy: Copilot zabraňuje výstupům, které by mohly obsahovat nepřijatelný jazyk, termíny nebo fráze.
- Pokusy o injekci výzvy: Copilot zabraňuje injekci výzvy, kde se uživatelé pokoušejí skrýt rušivé instrukce ve vkládaných datech, jako jsou názvy objektů, popisy nebo komentáře ke kódu v sémantickém modelu.
Omezení specifická pro scénáře: V závislosti na tom, které prostředí Copilotu používáte, můžou být před obdržením výstupu další kontroly a zpracování odpovědi LLM. Tady je několik příkladů, jak Copilot vynucuje omezení specifická pro konkrétní scénáře:
- Analyzátory kódu: Vygenerovaný kód může být vložen analyzátorem, který vyfiltruje odpovědi a chyby s nízkou kvalitou, aby se zajistilo, že se kód spustí. K tomu dochází při generování dotazů DAX pomocí Copilotu v zobrazení dotazu DAX v Power BI Desktopu.
- Ověření vizuálů a sestav: Copilot kontroluje, že se vizuály a sestavy můžou vykreslit před jejich vrácením ve výstupu. Copilot neověřuje, jestli jsou výsledky přesné nebo užitečné, nebo jestli výsledný dotaz vyprší (a vygeneruje chybu).
Zpracování a použití odpovědi: Přijetí odpovědi a přidání dalších informací nebo jeho použití v jiných procesech k poskytnutí výstupu uživateli. Tady je několik příkladů, jak může Copilot zpracovávat a používat odpověď během následného zpracování:
- Vytvoření stránky sestavy Power BI: Copilot kombinuje odpověď LLM (metadata vizuálu sestavy) s jinými metadaty sestavy, čímž vzniká nová stránka sestavy. Copilot může také použít motiv Copilot , pokud jste ještě v sestavě nevytvořili žádné vizuály. Téma není součástí odpovědi LLM a zahrnuje obrázek pozadí, barvy a vizuální styly. Pokud jste vytvořili vizuály, pak motiv Copilot nebude použit a místo toho bude použit motiv, který jste už aplikovali. Při změně stránky sestavy Copilot také odstraní existující stránku a nahradí ji novou stránkou s aplikovanými úpravami.
- Dotazy k datům Power BI: Copilot vyhodnotí dotaz na sémantický model.
- Návrh kroku transformace toku dat datové továrny Gen2: Copilot upraví metadata položky pro vložení nového kroku a úpravu dotazu.
Další volání LLM: V některých scénářích může Copilot provádět další volání LLM pro obohacení výstupu. Například Copilot může odeslat výsledek vyhodnoceného dotazu do LLM jako nový vstup a požádat o vysvětlení. Toto vysvětlení přirozeného jazyka je pak společně s výsledkem dotazu zahrnuto ve výstupu, který uživatel vidí na panelu chatu Copilot.
Pokud je obsah ve výstupu vyfiltrovaný, copilot buď znovu odešle novou, upravenou výzvu, nebo vrátí standardní odpověď.
Znovu odešlete novou výzvu: Pokud odpověď nesplňuje omezení specifická pro konkrétní scénář, copilot vytvoří další upravenou výzvu k dalšímu pokusu. Za některých okolností může Copilot navrhnout několik nových výzev, které má uživatel vybrat před odesláním výzvy k vygenerování nového výstupu.
Standardní odpověď: Standardní odpověď v tomto případě značí obecnou chybu. V závislosti na scénáři může Copilot poskytnout další informace, které uživatele povedou k vytvoření dalšího vstupu.
Poznámka:
Není možné zobrazit původní, filtrované odpovědi z Azure OpenAI, ani změnit standardní odpovědi nebo chování Copilota. Spravuje ho Microsoft.
Po dokončení následného zpracování vrátí funkce Copilot uživateli výstup.
Krok 5: Copilot vrátí výstup uživateli.
Výstup pro uživatele může mít formu přirozeného jazyka, kódu nebo metadat. Tato metadata se obvykle vykreslují v uživatelském rozhraní aplikace Fabric nebo Power BI Desktop, například když Copilot vrátí vizuál Power BI nebo navrhne stránku sestavy. V některých prostředích Power BI může uživatel poskytovat vstupy i výstupy do Copilotu prostřednictvím mobilní aplikace Power BI.
Obecně platí, že výstupy můžou buď umožnit zásah uživatele, nebo být plně autonomní a nepovolit uživateli změnit výsledek.
Zásah uživatele: Tyto výstupy umožňují uživateli upravit výsledek před vyhodnocením nebo zobrazením. Mezi příklady výstupů, které umožňují zásah uživatele, patří:
- Generování kódu, jako jsou dotazy DAX nebo SQL, které si uživatel může nechat nebo spustit.
- Generování popisů měr v sémantickém modelu, které si uživatel může zvolit, zachovat, upravit nebo odstranit.
Autonomní: Tyto výstupy uživatel nemůže změnit. Kód se může vyhodnotit přímo vůči položce Fabricu, nebo text nelze v podokně upravovat. Mezi příklady autonomních výstupů patří:
- Odpovědi na datové otázky týkající se sémantického modelu nebo sestavy na panelu chatu Copilot, který automaticky vyhodnotí dotazy na model a zobrazí výsledek.
- Souhrny nebo vysvětlení kódu, položek nebo dat, které automaticky vyberou, co se má shrnout a vysvětlit, a zobrazit výsledek.
- Vytvoření stránky sestavy, která automaticky vytvoří stránku a vizuály v sestavě.
V některých případech může Copilot v rámci výstupu také navrhnout další, následnou výzvu, například žádost o objasnění nebo jiný návrh. To je obvykle užitečné, když uživatel chce vylepšit výsledek nebo pokračovat v práci na konkrétním výstupu, jako je vysvětlení konceptu pro pochopení generovaného kódu.
Výstupy z Copilotu můžou obsahovat obsah s nízkou kvalitou nebo nepřesným obsahem.
Copilot nemá žádný způsob, jak vyhodnotit nebo označit užitečnost nebo přesnost svých výstupů. Proto je důležité, aby uživatelé sami zhodnotili Copilot při každém jeho použití.
Pokud chcete zmírnit rizika nebo problémy vyplývající z halucinací LLM ve Copilotu, zvažte následující rady:
Trénujte uživatele, aby používali Copilot a další podobné nástroje, které využívají LLM. Zvažte jejich trénování v následujících tématech:
- Co Copilot umí a nemůže dělat.
- Kdy použít Copilot a kdy jej nepoužít.
- Jak psát lepší výzvy
- Řešení potíží s neočekávanými výsledky
- Jak ověřit výstupy pomocí důvěryhodných online zdrojů, technik nebo prostředků.
Před povolením použití těchto položek otestujte položky pomocí Copilotu. Některé položky vyžadují určité přípravné úkoly, aby zajistily, že dobře fungují s Copilotem.
Vyhněte se použití Copilotu v autonomních, vysoce rizikových nebo obchodních rozhodovacích procesech.
Důležité
Kromě toho si projděte doplňkové podmínky preview pro Fabric, které zahrnují podmínky použití pro preview služby Microsoft Generative AI. I když můžete vyzkoušet a experimentovat s těmito funkcemi preview, doporučujeme, abyste funkce Copilot ve verzi Preview nepoužívali v produkčních řešeních.
Ochrana osobních údajů, zabezpečení a zodpovědná AI
Microsoft se zavazuje zajistit, aby naše systémy AI byly řízeny našimi zásadami AI a zodpovědnými standardy AI. Pro podrobný přehled se podívejte na Ochrana osobních údajů, zabezpečení a zodpovědné použití Copilotu v rámci Fabric. Podrobné informace specifické pro Azure OpenAI najdete také v tématu Data, ochrana osobních údajů a zabezpečení pro službu Azure OpenAI .
Přehled konkrétně pro každou úlohu Fabric najdete v následujících článcích:
- Zodpovědné použití ve službě Data Factory
- Zodpovědné použití v oblasti datových věd a datových inženýrů
- Zodpovědné použití v datových skladech
- Zodpovědné použití v Power BI
- Zodpovědné použití v Real-Time Intelligence
Náklady na Copilot v platformě Fabric
Na rozdíl od jiných microsoft Copilots nevyžaduje Copilot in Fabric další licence na uživatele ani licence na kapacitu. Spíše Copilot ve Fabric využívá vaše dostupné jednotky kapacity Fabric (CU). Rychlost spotřeby Copilot je určena počtem tokenů ve vašich vstupech a výstupech, když jej použijete v různých prostředích Fabric.
Pokud máte kapacitu Fabric, používáte buď průběžnou platbu , nebo rezervovanou instanci. V obou případech spotřeba Copilotu funguje stejně. Ve scénáři s průběžnými platbami se vám účtuje za každou sekundu, kdy je vaše kapacita aktivní, dokud kapacitu nepozastavíte. Fakturační sazby nemají žádný vztah k využití vašich jednotek CU infrastruktury; platíte stejnou částku, pokud je kapacita plně využitá nebo zcela nevyužitá. Proto Copilot nemá přímé náklady ani vliv na fakturaci Azure. Místo toho Copilot sdílí dostupné jednotky CU, které používají i jiné úlohy a položky v rámci infrastruktury Fabric, a pokud je využíváte příliš mnoho, uživatelé budou mít nižší výkon a omezování. Je také možné vstoupit do stavu dluhu CU označovaného jako převod do dalšího období. Další informace o omezování a přenášení najdete v tématu Spouštěče omezení a fáze omezení.
Následující části vysvětlují, jak byste měli porozumět a spravovat spotřebu Copilotu ve Fabricu.
Poznámka:
Další informace naleznete v tématu Copilot in Fabric consumption.
Spotřeba copilotu ve Fabric je určena tokeny.
Copilot spotřebovává vaše dostupné Fabric CUs, které se běžně označují jako kapacita, výpočet nebo zdroje. Spotřeba se určuje vstupními a výstupními tokeny při jeho použití. Pokud chcete zkontrolovat, můžete porozumět vstupním a výstupním tokenům v důsledku tokenizace následujících:
- Vstupní tokeny: Tokenizace vstupního textového pokynu a referenčních dat.
- Výstupní tokeny: Tokenizace odpovědi Azure OpenAI na základě vstupu Výstupní tokeny jsou třikrát dražší než vstupní tokeny.
Počet vstupních tokenů můžete omezit pomocí kratších výzev, ale nemůžete řídit, jaké uzemnění data Copilot používá k předběžnému zpracování, nebo počet výstupních tokenů, které LLM v Azure OpenAI vrací. Můžete například očekávat, že prostředí pro vytváření sestav pro Copilot v Power BI bude mít vysokou míru spotřeby, protože může používat základní data (například schéma modelu) a vytvářet rozsáhlý výpis (metadata sestavy).
Vstupy, výstupy a uzemnění dat se převedou na tokeny.
Pokud chcete zopakovat předchozí část tohoto článku, je důležité pochopit proces tokenizace , abyste věděli, jaké druhy vstupů a výstupů mají nejvyšší spotřebu.
Optimalizace tokenů příkazů pravděpodobně nebude mít významný vliv na vaše náklady na Copilot. Například počet tokenů v písemné výzvě uživatele je obvykle mnohem menší než tokeny uzemnění dat a výstupů. Copilot zpracovává uzemnění dat a výstupů samostatně; tyto tokeny nemůžete optimalizovat ani ovlivnit. Například při použití Copilotu v Power BI může Copilot použít schéma z sémantického modelu nebo metadat ze sestavy jako podkladová data během předběžného zpracování. Tato metadata pravděpodobně zahrnují mnohem více tokenů než vaše počáteční výzva.
Copilot provádí různé optimalizace systému za účelem snížení vstupních a výstupních tokenů. Tyto optimalizace závisí na prostředí Copilotu, které používáte. Mezi příklady optimalizací systému patří:
Snížení schématu: Copilot neodesílá celé schéma sémantického modelu nebo tabulky lakehouse. Místo toho používá vkládání k určení sloupců, které se mají odeslat.
Rozšíření výzvy: Při přepsání výzvy během předběžného zpracování se Copilot pokusí vytvořit poslední výzvu, která vrátí konkrétnější výsledek.
Kromě toho existují různé optimalizace uživatelů, které můžete implementovat, abyste omezili, jaká základní data může Copilot vidět a používat. Tyto optimalizace uživatelů závisí na položce a prostředí, které používáte. Mezi příklady optimalizací uživatelů patří:
Skrytí polí nebo označení tabulek jako soukromých v sémantickém modelu: Žádné skryté nebo soukromé objekty nebudou brány v úvahu Copilotem.
Skrytí stránek sestavy nebo vizuálů: Podobně všechny skryté stránky sestavy nebo vizuály, které jsou skryté za záložkou sestavy, nejsou Copilotem brány v úvahu.
Návod
Optimalizace uživatelů jsou účinné hlavně pro zlepšení užitečnosti výstupů Copilot, a ne optimalizace nákladů na Copilot. Další informace najdete v článcích specifických pro různé úlohy a prostředí Copilot.
Nemáte žádný přehled o procesu tokenizace a můžete ovlivnit pouze vstupní a výstupní tokeny. Proto je nejúčinnějším způsobem, jak spravovat spotřebu Copilotu a vyhnout se omezování, správa používání Copilotu.
Copilot je proces na pozadí, který je optimalizovaný.
Souběžné použití Copilotu v systému Fabric, když ho současně používá mnoho jednotlivců, zpracovává proces označovaný jako vyhlazování. Ve Fabricu je spotřeba CU u každé operace klasifikované jako operace na pozadí rozložena do 24hodinového období, počínaje časem operace až po přesně 24 hodin později. To je na rozdíl od interaktivních operací, jako jsou sémantické dotazy, které jednotlivci pokládají při použití sestavy Power BI, a které nejsou vyhlazovány.
Poznámka:
Pro zjednodušení vašeho porozumění, operace na pozadí a interaktivní operace klasifikují různé události, ke kterým dochází v systému Fabric pro účely fakturace. Nemusí nutně souviset s tím, jestli je položka nebo funkce interaktivní pro uživatele nebo se děje na pozadí, protože jejich jména mohou naznačovat.
Například, pokud nyní použijete 48 CUs s operací na pozadí, povede to k okamžité spotřebě 2 CUs a dále každou hodinu ke spotřebě 2 CUs po dobu následujících 24 hodin. Pokud použijete 48 jednotek CU s interaktivní operací, bude výsledkem pozorovaných 48 jednotek CU, které se teď používají, a nemá žádný vliv na budoucí spotřebu. Pokud je vaše použití Copilotu nebo jiných Fabric úloh dostatečně vysoké, vyhlazování ale také znamená, že v daném okně můžete potenciálně nashromáždit spotřebu výpočetních jednotek (CU).
Pokud chcete lépe porozumět vyhlazování a jeho účinkům na spotřebu CU v rámci Fabric, zvažte následující diagram.

Diagram znázorňuje příklad scénáře s vysokým souběžným využitím interaktivní operace (která není vyhlazená). Interaktivní operace překročí limit řízení (dostupnou kapacitu Fabric) a přejde do režimu přenosu. Jedná se o scénář bez vyhlazování. Naproti tomu operace na pozadí, jako je Copilot, mají spotřebu rozloženou do 24 hodin. Následné operace v daném 24hodinovém intervalu se naskládají a přispívají k celkové kumulativní spotřebě v daném období. Ve vyhlazeném scénáři tohoto příkladu by procesy na pozadí, jako je Copilot, přispěly k budoucí spotřebě CU, ale neaktivovaly omezování ani nepřekračovaly žádné limity.
Monitorování spotřeby Copilotu ve Fabricu
Administrátoři služby Fabric můžou pomocí aplikace Microsoft Fabric Capacity Metrics monitorovat, kolik Copilot využívá kapacity vaší služby Fabric. Správce služby Fabric může v aplikaci zobrazit rozpis podle aktivity a uživatele, což mu pomáhá s identifikací jednotlivců a oblastí, na které by se měl během období vysoké spotřeby zaměřit.
Návod
Místo zvažování abstraktních výpočtů, jako jsou tokeny k CU, doporučujeme zaměřit se na procento kapacity Fabric, kterou jste využili. Tato metrika je nejjednodušší pochopit a reagovat na ni, protože jakmile dosáhnete 100% využití, můžete zaznamenat omezování.
Tyto informace najdete na stránce časového bodu aplikace.
Poznámka:
Když pozastavíte kapacitu, vyhlazené využití se sloučí do časového bodu, kdy se kapacita pozastaví. Výsledkem této komprimace vyhlazené spotřeby je nárůst pozorované spotřeby, který neodráží skutečné spotřeby. Tato špička často vytváří oznámení a upozornění, že jste vyčerpali dostupnou kapacitu služby Fabric, ale to jsou falešné poplachy.
Zmírnění vysokého využití a omezování
Copilot využívá jednotky CU Fabricu, a přestože probíhá vyhlazování, můžete narazit na situace s vysokým využitím, což vede k vysoké spotřebě a omezování dalších vašich úloh v rámci Fabricu. V následujících částech najdete některé strategie, které můžete použít ke zmírnění vlivu na kapacitu Fabricu v tomto scénáři.
Školení a seznam povolených uživatelů
Důležitým způsobem, jak zajistit efektivní přijetí jakéhokoli nástroje, je poskytnout uživatelům dostatečné mentoring a školení a postupně zpřístupňovat nástroje podle toho, jak uživatelé dokončují tato školení. Efektivní školení je preventivní opatření, které předchází vysokému využití a omezování tím, že uživatele učí, jak efektivně používat Copilot a co nedělat.
Kontrolu nad tím, kdo může používat Copilot ve Fabric, můžete nejlépe zajistit vytvořením seznamu povolených uživatelů, kteří mají přístup k této funkci, z nastavení tenanta Fabric. To znamená, že povolíte Copilota v prostředí Fabric jenom pro uživatele, kteří patří do konkrétních skupin zabezpečení. V případě potřeby můžete pro každou úlohu Fabric vytvořit samostatné skupiny zabezpečení, kde můžete funkci Copilot povolit, abyste získali přesnější kontrolu nad tím, kdo může používat prostředí Copilot. Další informace o vytváření skupin zabezpečení najdete v tématu Vytvoření, úprava nebo odstranění skupiny zabezpečení.
Jakmile do nastavení tenanta Copilot přidáte konkrétní skupiny zabezpečení, můžete seskupit školení pro onboarding pro uživatele. Školicí kurz Copilotu by měl zahrnovat základní témata, například následující.
Návod
Zvažte vytvoření přehledového školení pro základní koncepty LLM a generování umělé inteligence, ale pak vytvořte školení specifické pro úlohy pro uživatele. Ne každý člověk se musí dozvědět o všech úlohách Fabricu, pokud pro něj nejsou nezbytně relevantní.
LLM: Vysvětlete základy toho, co je LLM a jak funguje. Neměli byste se zabývat technickými podrobnostmi, ale měli byste vysvětlit koncepty, jako jsou výzvy, uzemnění a tokeny. Můžete také vysvětlit, jak mohou velké jazykové modely (LJM) získávat význam z vstupních dat a vytvářet odpovědi odpovídající kontextu díky svým tréninkovým datům. Výuka uživatelů této technologie jim pomáhá pochopit, jak technologie funguje a co může a nemůže dělat.
K čemu slouží Copilot a další nástroje pro generování AI: Měli byste vysvětlit, že Copilot není autonomní agent a není určený k nahrazení lidí v jejich úkolech, ale měl by rozšířit jednotlivce, aby mohli provádět své aktuální úkoly lépe a rychleji. Měli byste také zdůraznit případy, kdy copilot není vhodný, pomocí konkrétních příkladů a vysvětlit, jaké další nástroje a informace můžou jednotlivci použít k řešení problémů v těchto scénářích.
Jak kriticky ohodnocet výstupy Copilotu: Je důležité, abyste uživatele seznámili s tím, jak můžou ověřovat výstupy copilotu. Toto ověřování závisí na prostředí copilotu, které používají, ale obecně byste měli zdůraznit následující body:
- Než ho použijete, zkontrolujte každý výstup.
- Vyhodnoťte a zeptejte se sami sebe, jestli je výstup správný nebo ne.
- Přidejte komentáře k vygenerovanému kódu, abyste pochopili, jak funguje. Případně požádejte Copilot o vysvětlení pro tento kód, pokud je to nutné, a s důvěryhodnými zdroji porovnejte toto vysvětlení.
- Pokud výstup způsobí neočekávaný výsledek, vyřešte potíže s různými výzvami nebo provedením ručního ověření.
Rizika a omezení LLM a generativní umělé inteligence: Měli byste vysvětlit klíčová rizika a omezení Copilota, LLM a generativní umělé inteligence, jako jsou ta zmíněná v tomto článku:
- Nejsou deterministické.
- Neposkytují žádnou indikaci ani záruky přesnosti, spolehlivosti nebo pravdivosti.
- Mohou halucinovat a vytvářet nepřesné nebo málo kvalitní výstupy.
- Nemůžou generovat informace, které se nacházejí mimo rozsah trénovacích dat.
Kde najít Copilot ve Fabric: Poskytněte A základní přehled o různých úlohách, položkách a prostředích Copilotu, které může někdo použít.
Škálování kapacity
Když dojde k omezování ve Fabric kvůli spotřebě copilota nebo jiným operacím, můžete kapacitu dočasně škálovat (nebo změnit velikost) na vyšší SKU. Jedná se o reaktivní opatření, které dočasně zvyšuje vaše náklady, aby zmírnilo krátkodobé problémy způsobené omezováním nebo přenosem. To je užitečné zejména v případě, že dochází ke zpomalení hlavně kvůli operacím na pozadí, protože spotřeba (a tím dopad) může být rozložená do 24hodinového období.
Strategie rozdělené kapacity
Ve scénářích, ve kterých očekáváte vysoké využití Copilotu ve Fabric (například ve velkých organizacích), můžete zvážit izolování spotřeby Copilotu od vašich ostatních úloh ve Fabric. Ve scénáři s rozdělenou kapacitou zabráníte tomu, aby spotřeba Copilot negativně ovlivnila jiné úlohy infrastruktury tím, že povolíte Copilot pouze na samostatné SKU F64 nebo vyšší, které používáte pouze pro vyhrazené použití Copilot. Tato strategie rozdělené kapacity vytváří vyšší náklady, ale může usnadnit správu a řízení využití Copilotu.
Návod
Některá prostředí Copilotu můžete použít s položkami v jiných kapacitách, které nepodporují nebo nepovolují Copilot. V Power BI Desktopu můžete například propojit pracovní prostor s kapacitou Fabric SKU F64, ale poté se připojit k sémantickému modelu v pracovním prostoru F2 nebo PPU. Pak můžete v Power BI Desktopu použít prostředí Copilotu a spotřeba Copilotu ovlivní jenom skladovou položku F64.
Následující diagram znázorňuje příklad strategie rozdělení kapacity, která izoluje spotřebu Copilotu při zkušenostech, jako je tomu v Copilotu v Power BI Desktopu.

Řešení rozdělené kapacity můžete použít také přiřazením spotřeby Copilotu k samostatné kapacitě. Přiřazení spotřeby Copilotu k samostatné kapacitě zajišťuje, že vysoké využití Copilotu nemá vliv na ostatní úlohy Infrastruktury a na důležité obchodní procesy, které na nich závisejí. Použití jakékoli strategie rozdělené kapacity samozřejmě vyžaduje, abyste už měli dvě nebo více skladových položek F64 nebo vyšší. Proto tato strategie nemusí být spravovatelná pro menší organizace nebo organizace s omezeným rozpočtem na výdaje na datové platformy.
Bez ohledu na to, jak se rozhodnete spravovat Copilot, je nejdůležitější sledovat spotřebu Copilotu v kapacitě Fabric.