Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Tip
Generace 1 datových toků Power BI je nyní v zastaralém stavu a nebude dále rozvíjena s novými funkcemi. Místo vytváření vlastního řídicího panelu monitorování poskytuje tok dat Gen2 integrované sledování aktualizací prostřednictvím centra monitorování v Microsoft Fabric s informacemi o stavu v reálném čase, době trvání a podrobnostech o chybách. Další informace o upgradu existujících toků dat najdete v tématu Upgrade z Toku dat Gen1 na Tok dat Gen2.
Toky dat Power BI umožňují připojení, transformaci, kombinování a distribuci dat pro podřízenou analýzu. Klíčovým prvkem toků dat je proces aktualizace, který použije kroky transformace vytvořené v tocích dat a aktualizuje data v samotných položkách.
Abyste porozuměli době spuštění, výkonu a tomu, jestli z toku dat získáváte maximum, můžete si po aktualizaci toku dat stáhnout historii aktualizací.
Vysvětlení aktualizací
Pro toky dat platí dva typy aktualizací:
úplná, která provede úplné vyprázdnění a opětovné načtení dat.
Přírůstkové (pouze pro Prémiovou verzi)zpracovává podmnožinu vašich dat podle časových pravidel, které nakonfigurujete a které jsou vyjádřeny jako filtr. Filtr sloupce kalendářního data dynamicky rozděluje data do rozsahů ve službě Power BI. Po nakonfigurování přírůstkové aktualizace tok dat automaticky změní váš dotaz tak, aby zahrnoval filtrování podle data. Automaticky vygenerovaný dotaz můžete upravit pomocí rozšířeného editoru v Power Query a doladit nebo přizpůsobit aktualizaci. Pokud používáte vlastní službu Azure Data Lake Storage, uvidíte časové řezy dat na základě nastavených zásad aktualizace.
Poznámka
Další informace o přírůstkové aktualizaci a jejím fungování najdete v tématu Použití přírůstkové aktualizace s toky dat.
Přírůstková aktualizace umožňuje v Power BI velké toky dat s následujícími výhodami:
Aktualizace jsou po první aktualizaci rychlejší, a to z důvodu následujících faktů:
- Power BI aktualizuje poslední N oddíly určené uživatelem (kde oddíl znamená den/týden/měsíc, atd.) nebo
- Power BI aktualizuje jenom data, která je potřeba aktualizovat. Například aktualizace pouze posledních pěti dnů 10letého sémantického modelu.
- Power BI aktualizuje pouze data, která se změnila, pokud uvedete sloupec, který se má zkontrolovat pro změny.
Aktualizace jsou spolehlivější – už není nutné udržovat dlouhotrvající připojení k nestálým zdrojovým systémům.
Spotřeba prostředků se snižuje – méně dat pro aktualizaci snižuje celkovou spotřebu paměti a dalších prostředků.
Kdykoli je to možné, Power BI využívá paralelní zpracování na oddílech, což může vést k rychlejším aktualizacím.
Pokud v některém z těchto scénářů selže aktualizace, data se neaktualizují. Data můžou být zastaralá, dokud se nejnovější aktualizace neskončí, nebo je můžete aktualizovat ručně a pak se můžou dokončit bez chyby. K aktualizaci dochází u oddílu nebo entity, takže pokud přírůstková aktualizace selže nebo u entity dojde k chybě, nedojde k celé transakci aktualizace. Jinými slovy, pokud oddíl (zásady přírůstkové aktualizace) nebo entita selže v datovém toku; celá operace aktualizace selže a žádná data nejsou aktualizována.
Principy a optimalizace aktualizací
Pokud chcete lépe pochopit, jak funguje operace aktualizace toku dat, projděte si historie aktualizace toku dat tím, že přejdete na některý z vašich toků dat. Vyberte Další možnosti (...) pro tok dat. Potom zvolte Nastavení > Obnovit historii. Také můžete vybrat tok dat v pracovním prostoru . Potom zvolte Další možnosti (...) > Obnovit historii.
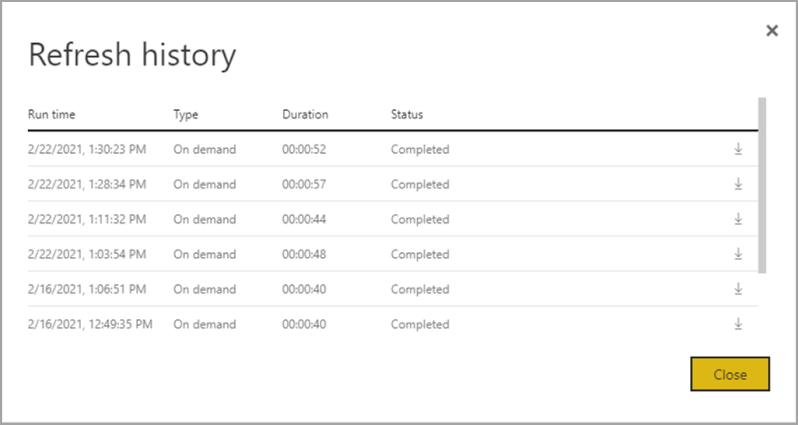
Historie aktualizace poskytuje přehled o aktualizacích, včetně jejich typu – na vyžádání nebo naplánovaných, délky trvání a stavu spuštění. Pokud chcete zobrazit podrobnosti ve formě souboru CSV, vyberte ikonu pro stažení úplně vpravo od řádku popisu aktualizace. Stažený CSV soubor obsahuje atributy popsané v následující tabulce. Aktualizace Premium poskytují více informací díky rozšířeným možnostem výpočetního výkonu a toků dat, na rozdíl od toků dat Pro, které fungují ve sdílené kapacitě. Některé z následujících metrik jsou například k dispozici pouze v Premium.
| Položka | Popis | Pro | Premium |
|---|---|---|---|
| Požadováno dne | Časová aktualizace byla naplánovaná nebo bylo nyní kliknuto na aktualizaci, obojí v místním čase. | ✔ | ✔ |
| Název toku dat | Název vašeho toku dat | ✔ | ✔ |
| Stav aktualizace toku dat | Možné stavy jsou dokončené, neúspěšné nebo přeskočené (pro entitu). Případy použití, jako jsou propojené entity, jsou důvody, proč se může přeskočit. | ✔ | ✔ |
| Název entity | Název tabulky | ✔ | ✔ |
| Název oddílu | Tato položka závisí na tom, jestli je tok dat prémiový nebo ne, a na tom, jestli je Pro zobrazeno jako NA, protože nepodporuje přírůstkové aktualizace. Premium zobrazuje hodnotu FullRefreshPolicyPartition nebo IncrementalRefreshPolicyPartition-[DateRange]. | ✔ | |
| Stav aktualizace | Stav aktualizace jednotlivé entity nebo oddílu, který poskytuje stav pro daný časový řez dat, která se aktualizují. | ✔ | ✔ |
| Čas zahájení | V Premium je tato položka čas, kdy byl tok dat zařazen do fronty pro zpracování pro entitu nebo oddíl. Tato doba se může lišit, pokud toky dat mají závislosti a potřebují počkat na zahájení zpracování sady výsledků upstreamového toku dat. | ✔ | ✔ |
| Koncový čas | Koncový čas je čas dokončení entity toku dat nebo oddílu, pokud je to možné. | ✔ | ✔ |
| Trvání | Celkový uplynulý čas aktualizace toku dat vyjádřený v HH:MM:SS. | ✔ | ✔ |
| Zpracované řádky | U dané entity nebo oddílu je počet naskenovaných nebo zapsaných řádků modulem toků dat. Tato položka nemusí vždy obsahovat data na základě provedené operace. Data se můžou vynechat, když se výpočetní modul nepoužívá nebo když používáte bránu, protože se tam zpracovávají data. | ✔ | |
| Zpracované bajty | U dané entity nebo oddílu jsou data zapsaná modulem toků dat vyjádřená v bajtech. Při použití brány u tohoto konkrétního toku dat nejsou tyto informace k dispozici. |
✔ | |
| Maximální závazek (KB) | Maximální použití paměti je špičková hodnota využití paměti užitečná pro diagnostiku selhání z nedostatku paměti, pokud dotaz M není optimalizován. Pokud používáte bránu pro tento konkrétní tok dat, tyto informace nejsou k dispozici. |
✔ | |
| Čas procesoru | U dané entity nebo oddílu je čas vyjádřený v HH:MM:SS, který modul toků dat strávil prováděním transformací. Pokud používáte bránu pro tento konkrétní tok dat, tyto informace nejsou k dispozici. |
✔ | |
| Doba čekání | Na základě pracovního zatížení v kapacitě Premium je čas, který daná entita nebo oddíl strávila ve stavu čekání. | ✔ | |
| Výpočetní modul | U dané entity nebo oddílu podrobně popisuje, jak operace aktualizace používá výpočetní modul. Jedná se o následující hodnoty: -SODÍK -Složený -Mezipaměti - Uloženo do mezipaměti + Složené Tyto prvky jsou podrobněji popsány dále v tomto článku. |
✔ | |
| Chyba | V případě potřeby je podrobná chybová zpráva popsaná pro každou entitu nebo oddíl. | ✔ | ✔ |
Pokyny k aktualizaci toku dat
Statistika aktualizace poskytuje cenné informace, které můžete použít k optimalizaci a urychlení výkonu toků dat. V následujících částech popisujeme některé scénáře, co je potřeba hlídat a jak optimalizovat na základě poskytnutých informací.
Orchestrace
Použití toků dat ve stejném pracovním prostoru umožňuje přímou orchestraci. Můžete mít například toky dat A, B a C v jednom pracovním prostoru a řetězení, jako je A > B > C. Pokud zdroj (A) aktualizujete, aktualizují se také podřízené entity. Pokud ale aktualizujete jazyk C, musíte aktualizovat ostatní nezávisle. Pokud přidáte do toku dat B nový zdroj dat (který není součástí A), nebudou se tato data aktualizovat jako součást orchestrace.
Můžete chtít zřetězit položky, které neodpovídají spravované orchestraci, kterou Power BI provádí. V těchto scénářích můžete použít rozhraní API a/nebo použít Power Automate. Informace o programové aktualizaci najdete v dokumentaci k rozhraní API a ve skriptu PowerShell . K dispozici je konektor Power Automate, který umožňuje tento postup bez psaní kódu. Můžete si prohlédnout podrobné ukázky, včetně konkrétních návodů k sekvenčním aktualizacím.
Monitorování
Pomocí vylepšených statistik aktualizace popsaných výše v tomto článku můžete získat podrobné informace o aktualizaci toku dat. Pokud byste ale chtěli zobrazit toky dat s přehledem aktualizací pro celého tenanta nebo pracovního prostoru, třeba k vytvoření řídicího panelu monitorování, můžete použít rozhraní API nebo šablon Power Automate. Podobně pro případy použití, jako je odesílání jednoduchých nebo složitých oznámení, můžete použít konektor Power Automate nebo vytvořit vlastní aplikaci pomocí rozhraní API.
Chyby časového limitu
Je ideální optimalizovat dobu potřebnou k provádění scénářů extrakce, transformace a načítání (ETL). V Power BI platí následující případy:
- Některé konektory mají explicitní nastavení časového limitu, které můžete nakonfigurovat. Další informace najdete v oddílu Konektory v Power Query.
- Toky dat Power BI, které používají Power BI Pro, můžou mít také časové limity pro dlouhotrvající dotazy v rámci entity nebo toků dat samotné. Toto omezení v pracovních prostorech Power BI Premium neexistuje.
Pokyny k vypršení časového limitu
Prahové hodnoty časového limitu pro toky dat Power BI Pro jsou:
- Dvě hodiny na úrovni jednotlivých entit.
- Tři hodiny během celé úrovně toku dat
Pokud máte například tok dat se třemi tabulkami, nemůže trvat déle než dvě hodiny a v případě, že doba trvání překročí tři hodiny, vyprší časový limit celého toku dat.
Pokud dochází k vypršení časových limitů, zvažte optimalizaci dotazů toku dat a zvažte použití posouvání dotazů ve zdrojových systémech.
Samostatně zvažte upgrade na Premium na uživatele, který se na tyto časové limity nevztahují a nabízí vyšší výkon z důvodu mnoha funkcí Power BI Premium na uživatele.
Dlouhé doby trvání
Aktualizace složitých nebo velkých toků dat může trvat déle, protože můžou být špatně optimalizované toky dat. Následující části obsahují pokyny ke zmírnění dlouhých dob aktualizace.
Pokyny pro dlouhé doby trvání aktualizace
Prvním krokem ke zlepšení dlouhých dob aktualizace toků dat je sestavení toků dat podle osvědčených postupů. Mezi významné vzory patří:
- Použijte propojené entity pro data, která je možné použít později v jiných transformacích.
- Použití počítaných entit k ukládání dat do mezipaměti, což snižuje zatížení načítání dat a příjmu dat ve zdrojových systémech.
- Rozdělte data do přípravných toků dat a transformačních toků dat; oddělte ETL do různých toků dat.
- Optimalizace rozbalovacích tabulkových operací.
- Postupujte podle pokynů pro komplexní toky dat.
Dále vám může pomoct vyhodnotit, jestli můžete použít přírůstkovou aktualizaci.
Použití přírůstkové aktualizace může zlepšit výkon. Při odesílání dotazů pro operace aktualizace je důležité, aby se filtry oddílů předávaly zdrojovému systému. Pokud chcete protlačení filtrování dolů, znamená to, že zdroj dat by měl podporovat skládání dotazů, nebo můžete obchodní logiku vyjádřit pomocí funkce či jiných prostředků, které mohou Power Query pomoci eliminovat a filtrovat soubory nebo složky. Většina zdrojů dat, které podporují dotazy SQL, podporuje posouvání dotazů a některé datové kanály OData můžou také podporovat filtrování.
Zdroje dat, jako jsou ploché soubory, objekty blob a rozhraní API, ale obvykle nepodporují filtrování. V případech, kdy back-end zdroje dat nepodporuje filtr, nejde ho odeslat dolů. V takových případech modul mash-up kompenzuje a aplikuje filtr místně, což může vyžadovat načtení úplného sémantického modelu ze zdroje dat. Tato operace může způsobit pomalé přírůstkové aktualizace a v případě použití může dojít k výpadku prostředků ve službě Power BI nebo v místní bráně dat.
Vzhledem k různým úrovním podpory posouvání dotazů pro každý zdroj dat byste měli provést ověření, abyste zajistili, že je logika filtru zahrnutá do zdrojových dotazů. Aby to bylo snazší, Power BI se pokusí provést toto ověření za vás pomocí indikátorů skládání kroků pro Power Query Online. Mnohé z těchto optimalizací jsou zkušenosti během návrhu, ale po obnovení máte příležitost analyzovat a optimalizovat výkon obnovení.
Nakonec zvažte optimalizaci prostředí. Prostředí Power BI můžete optimalizovat vertikálním navýšením kapacity, správnou velikostí bran dat a snížením latence sítě pomocí následujících optimalizací:
Pokud používáte kapacity dostupné v Power BI Premium nebo Premium na uživatele, můžete zvýšit výkon zvýšením instance Premium nebo přiřazením obsahu k jiné kapacitě.
Brána se vyžaduje vždy, když Power BI potřebuje přístup k datům, která nejsou k dispozici přímo přes internet. Na místní server nebo virtuální počítač můžete nainstalovat místní datovou bránu .
- Pokud chcete porozumět pracovním zátěžím brány a doporučením pro velikost, přečtěte si velikost místní datové brány.
- Zvažte také přenos dat nejprve do přípravného toku dat, a jejich následné odkazování v dalších krocích pomocí propojených a vypočítaných entit.
Latence sítě může ovlivnit výkon aktualizace zvýšením času potřebného pro žádosti o připojení ke službě Power BI a doručení odpovědí. Tenanti v Power BI se přiřazují ke konkrétní oblasti. Pokud chcete zjistit, kde se nachází váš tenant, přečtěte si téma Vyhledání výchozí oblasti pro vaši organizaci. Když uživatelé z tenanta přistupují ke službě Power BI, jejich žádosti se vždy směrují do této oblasti. Když se požadavky dostanou do služby Power BI, může služba posílat další požadavky, například do podkladového zdroje dat nebo do brány dat , které se také vztahují na latenci sítě.
- Nástroje, jako je Azure Speed Test, poskytují informace o latenci sítě mezi klientem a oblastí Azure. Obecně platí, že pokud chcete minimalizovat dopad latence sítě, snažte se udržovat zdroje dat, brány a cluster Power BI co nejblíže. Umístění ve stejné oblasti je vhodnější. Pokud je latence sítě problém, zkuste vyhledat brány a zdroje dat blíže ke clusteru Power BI tak, že je umístíte do virtuálních počítačů hostovaných v cloudu.
Vysoký čas procesoru
Pokud zaznamenáte vysoký čas procesoru, pravděpodobně máte nákladné transformace, které nejsou zjednodušeny. Vysoká doba procesoru je způsobená počtem použitých kroků nebo typem transformací, které vytváříte. Každá z těchto možností může mít za následek vyšší dobu aktualizace.
Pokyny pro vysoký čas procesoru
Pro optimalizaci vysokého času procesoru existují dvě možnosti.
Nejprve použijte posouvání dotazů v samotném zdroji dat, což by mělo snížit zatížení výpočetního modulu toku dat přímo. Posouvání dotazů ve zdroji dat umožňuje zdrojovému systému většinu práce. Tok dat pak může předávat dotazy v nativním jazyce zdroje, místo aby po počátečním dotazu musel provádět všechny výpočty v paměti.
Ne všechny zdroje dat mohou provádět skládání dotazů a i když je skládání dotazů možné, mohou existovat toky dat, které provádějí určité transformace, jež nelze složit do zdroje. V takových případech je vylepšený výpočetní modul schopností, kterou Power BI zavádí, aby potenciálně zlepšila výkon až o 25krát, konkrétně pro transformace.
Použití výpočetního modulu k maximalizaci výkonu
I když má Power Query přehled o posouvání dotazů v době návrhu, sloupec výpočetního modulu poskytuje podrobnosti o tom, jestli se používá samotný interní modul. Výpočetní modul je užitečný, když máte složitý tok dat a provádíte transformace v paměti. Tato situace spočívá v tom, že vylepšená statistika aktualizace může být užitečná, protože sloupec výpočetního modulu poskytuje podrobnosti o tom, zda byl samotný modul použit.
Následující části obsahují pokyny k používání výpočetního modulu a jeho statistiky.
Varování
Během návrhu může indikátor skládání v editoru ukázat, že dotaz se při využívání dat z jiného toku dat nepřeloží. Zkontrolujte zdrojový tok dat, pokud je povolené rozšířené výpočetní prostředí a ujistěte se, že je povolené posouvání na zdrojovém toku dat.
Pokyny ke stavu výpočetního modulu
Zapnutí vylepšeného výpočetního modulu a pochopení různých stavů je užitečné. Vylepšený výpočetní modul interně používá k čtení a ukládání dat databázi SQL. Nejlepší je, aby se vaše transformace spouštěly na tomto dotazovacím engine. Následující odstavce poskytují různé situace a pokyny k tomu, co dělat pro každou z nich.
NA – Tento stav znamená, že se výpočetní modul nepoužíval, a to z následujících důvodů:
- Používáte toky dat Power BI Pro.
- Výpočetní modul jste explicitně vypnuli.
- Používáte posouvání dotazů ve zdroji dat.
- Provádíte složité transformace, které nemůžou využívat modul SQL, který se používá k urychlení dotazů.
Pokud zažíváte dlouhé trvání a stále se zobrazuje stav NA, ujistěte se, že je zapnutý a že není omylem vypnutý. Jedním z doporučených vzorů je použití přípravných toků dat k počátečnímu načtení dat do služby Power BI a následnému sestavení toků dat nad daty, jakmile budou v přípravném toku dat. Tento model může snížit zatížení zdrojových systémů a společně s výpočetním modulem zvýšit rychlost transformací a zvýšit výkon.
Uložené v mezipaměti – Pokud se zobrazí stav uložené v mezipaměti, data datového toku byla uložena ve výpočetním enginu a je možné na ně odkazovat jako na součást jiného dotazu. Tato situace je ideální, pokud ji používáte jako propojenou entitu, protože výpočetní modul ukládá tato data do mezipaměti pro použití v podřízené části. Data uložená v mezipaměti nemusí být ve stejném toku dat několikrát aktualizována. Tato situace je také potenciálně ideální, pokud ji chcete použít pro DirectQuery.
Při ukládání do mezipaměti má počáteční vliv na výkon při přijímání dat později přínos, a to ve stejném toku dat nebo v jiném toku dat v rámci stejného pracovního prostoru.
Pokud máte pro entitu dlouhou dobu trvání, zvažte vypnutí výpočetního enginu. Pokud chcete entitu uložit do mezipaměti, Power BI ji zapíše do úložiště a do SQL. Pokud se jedná o entitu s jedním použitím, výhody výkonu pro uživatele nemusí stát za nevýhodu dvojitého zpracování.
zhutněný – zhutněný znamená, že tok dat mohl pro čtení dat využívat výpočetní prostředky SQL. Počítaná entita použila tabulku z SQL ke čtení dat a použitý JAZYK SQL souvisí s konstrukty jejich dotazu.
Složený stav se zobrazí, pokud při používání místních nebo cloudových zdrojů dat nejprve načtete data do přípravného toku dat a poté na ně odkazujete v tomto toku dat. Tento stav platí jenom pro entity, které odkazují na jinou entitu. To znamená, že vaše dotazy byly spuštěny nad SQL enginem a mohou být vylepšeny pomocí SQL výpočtů. Pokud chcete zajistit, aby modul SQL zpracovává vaše transformace, použijte transformace, které podporují skládání SQL, jako je sloučení (spojení), seskupení podle (agregace) a akce připojení (sjednocení) v Editoru dotazů.
Cached + Folded – Když uvidíte uloženo v mezipaměti a složeno, je pravděpodobné, že aktualizace dat je optimalizovaná, protože máte entitu, která odkazuje na jinou entitu a je zmíněna jinou entitou na vyšší úrovni. Tato operace také běží nad SQL a jako taková má také potenciál pro zlepšení pomocí výpočetních schopností SQL. Abyste měli jistotu, že dosáhnete nejlepšího možného výkonu, použijte transformace, které podporují skládání SQL, jako je sloučení (spojení), seskupení podle (agregace) a akce připojení (sjednocení) v Editoru dotazů.
Pokyny pro optimalizaci výkonu výpočetního modulu
Následující kroky umožňují úlohám aktivovat výpočetní modul a tím vždy zvýšit výkon.
počítané a propojené entity ve stejném pracovním prostoru:
Pro příjem datse zaměřte na co nejrychlejší načtení dat do úložiště, použijte filtry pouze v případě, že zmenší celkovou sémantickou velikost modelu. Nechte logiku transformace oddělenou od tohoto kroku. Dále rozdělte transformaci a obchodní logiku do samostatného toku dat ve stejném pracovním prostoru. Použijte propojené nebo počítané entity. Tím umožníte, aby motor/stroj aktivoval a urychlil vaše výpočty. Pro jednoduchou analogii je to jako příprava jídla v kuchyni: příprava jídla je obvykle samostatný a odlišný krok od shromažďování surovin a předpoklad pro umístění jídla do trouby. Podobně je potřeba logiku připravit samostatně, abyste mohli využít výhod výpočetního modulu.
Ujistěte se, že provádíte operace, které se skládají, jako jsou sloučení, spojení, převod a další.
Také vytvářet toky dat v rámci publikovaných pokynů a omezení.
Když je výpočetní modul zapnutý, ale výkon je pomalý:
Při zkoumání scénářů, ve kterých je výpočetní modul zapnutý a dochází ke špatnému výkonu, proveďte následující kroky:
- Omezte počítané a propojené entity, které existují v celém pracovním prostoru.
- Pokud je vaše počáteční aktualizace provedena se zapnutým výpočetním strojem, data se zapíší do jezera u a do mezipaměti u. Výsledkem tohoto dvojitého zápisu jsou aktualizace pomalejší.
- Pokud máte tok dat propojující se s více toky dat, nezapomeňte naplánovat čas aktualizací zdrojových toků dat tak, aby se tyto toky dat neaktualizovaly současně.
Důležité informace a omezení
Licence Power BI Pro má limit aktualizace toků dat 8 aktualizací za den.