Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
CREATE TABLE AS SELECT (CTAS) je jednou z nejdůležitějších dostupných funkcí T-SQL. Je to plně paralelizovaná operace, která vytváří novou tabulku na základě výstupu příkazu SELECT. CTAS je nejjednodušší a nejrychlejší způsob, jak vytvořit kopii tabulky.
Například použijte CTAS k:
- Znovu vytvořte tabulku s jiným sloupcem distribuce hashů.
- Znovu vytvořte tabulku tak, jak byla replikována.
- Vytvořte index columnstore jen pro některé sloupce v tabulce.
- Dotazujte nebo importujte externí data.
Poznámka:
Protože CREATE TABLE AS SELECT (CTAS) přidává k možnostem vytváření tabulky, toto téma se snaží téma CREATE TABLE neopakovat. Místo toho popisuje rozdíly mezi CTAS a CREATE TABLE.
- CTAS je podporován ve skladu Microsoft Fabric. Prohlédněte si Fabric verzi článku CREATE TABLE AS SELECT.
- Tato syntaxe není podporována bezserverovým fondem SQL ve službě Azure Synapse Analytics.
-
CREATE TABLE AS SELECT(CTAS) je podporován ve skladu Microsoft Fabric. Pro více informací viz verze tohoto článku v Fabric Data Warehouse.
Syntaxe
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Arguments
Pro více informací viz sekce Argumenty v CREATE TABLE.
Možnosti sloupce
column_name [ ,...n ]
Názvy sloupců neumožňují volby sloupců VYTVOŘIT TABULKU, které jsou zmíněny v .CREATE TABLE Místo toho můžete zadat volitelný seznam jednoho nebo více názvů sloupců pro novou tabulku. Sloupce v nové tabulce používají zadané názvy. Při zadávání názvů sloupců musí počet sloupců v seznamu sloupců odpovídat počtu sloupců ve výsledcích výběru. Pokud nezadáte žádné názvy sloupců, použije nová cílová tabulka názvy sloupců ve výsledcích příkazu select.
Nemůžete zadat žádné další možnosti sloupců, jako jsou datové typy, kolace nebo nullability. Každý z těchto atributů je odvozen z výsledků SELECT tvrzení. Pomocí příkazu SELECT však můžete změnit atributy. Například viz Použít CTAS ke změně atributů sloupců.
Možnosti rozdělení tabulek
Pro podrobnosti a pochopení, jak vybrat nejlepší sloupec distribuce, viz sekce Možnosti rozdělení v tabulce v CREATE TABLE. Pro doporučení, kterou distribuci zvolit pro tabulku na základě skutečného využití nebo ukázkových dotazů, viz Distribution Advisor v Azure Synapse SQL.
DISTRIBUTION
=
HASH (distribution_column_name) | ROUND_ROBIN | REPLIKOVAT
Příkaz CTAS vyžaduje distribuční možnost a nemá výchozí hodnoty. To se liší od CREATE TABLE, která má výchozí nastavení.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
Rozděluje řádky na základě hash hodnot až osmi sloupců, což umožňuje rovnoměrnější rozložení základních dat tabulky, snižuje časové zkreslení dat a zlepšuje výkon dotazů.
Poznámka:
- Pro povolení této funkce změňte úroveň kompatibility databáze na 50 tímto příkazem. Pro více informací o nastavení úrovně kompatibility databáze viz ALTER DATABASE SCOPED CONFIGURATION. Příklad:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Pro deaktivaci funkce multi-column distribution (MCD) spusťte tento příkaz pro změnu úrovně kompatibility databáze na AUTO. Například:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;Stávající tabulky MCD zůstanou, ale stanou se nečitelnými. Dotazy přes MCD tabulky vrátí tuto chybu:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Pro opětovné získání přístupu k MCD tabulkám tuto funkci znovu povolte.
- Pro načtení dat do tabulky MCD použijte příkaz CTAS a zdrojem dat musí být tabulky Synapse SQL.
- CTAS na cílových tabulkách MCD HEAP není podporován. Místo toho použijte INSERT SELECT jako řešení pro načtení dat do tabulek MCD HEAP.
- Použití SSMS pro generování skriptu pro tvorbu MCD tabulek je v současnosti podporováno i po SSMS verzi 19.
Pro podrobnosti a pochopení, jak vybrat nejlepší sloupec distribuce, viz sekce Možnosti rozdělení v tabulce v CREATE TABLE.
Pro doporučení na nejlepší distribuci podle vašich pracovních zátěží navštivte Synapse SQL Distribution Advisor (Preview).
Možnosti rozdělení tabulek
Příkaz CTAS vytváří nerozdělenou tabulku ve výchozím nastavení, i když je zdrojová tabulka rozdělená. Pro vytvoření rozdělené tabulky s příkazem CTAS musíte zadat možnost partition.
Podrobnosti viz sekce Možnosti rozdělení tabulky v .CREATE TABLE
Příkaz SELECT
Příkaz SELECT je zásadním rozdílem mezi CTAS a CREATE TABLE.
WITH
common_table_expression
Určuje dočasnou pojmenovanou sadu výsledků označovanou jako běžný výraz tabulky (CTE). Další informace najdete v tématu WITH common_table_expression (Transact-SQL).
SELECT
select_criteria
Naplní novou tabulku výsledky příkazu SELECT. select_criteria je tělo příkazu SELECT, které určuje, která data se mají zkopírovat do nové tabulky. Informace o příkazech SELECT naleznete v tématu SELECT (Transact-SQL).
Nápověda k dotazu
Uživatelé mohou nastavit MAXDOP na celočíselnou hodnotu, aby mohli řídit maximální stupeň paralelismu. Když je MAXDOP nastaven na 1, dotaz je vykonán jedním vláknem.
Povolení
CTAS vyžaduje SELECT povolení ke všem objektům odkazovaným v select_criteria.
Pro oprávnění k vytvoření tabulky viz Oprávnění v CREATE TABLE.
Poznámky
Podrobnosti viz Obecné poznámky v CREATE TABLE.
Limity a omezení
Pro více podrobností o omezeních a omezeních viz Omezení a omezení v CREATE TABLE.
Uspořádaný clusterovaný index columnstore lze vytvořit na sloupcích jakýchkoli datových typů podporovaných v Azure Synapse Analytics kromě sloupců řetězců.
NASTAVIT POČET ŘÁDKŮ (Transact-SQL) nemá vliv na CTAS. Chcete-li dosáhnout podobného chování, použijte top (Transact-SQL).
CTAS tuto funkci nepodporuje
OPENJSONjako součást tvrzení.SELECTAlternativně použijteINSERT INTO ... SELECT. Například:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Chování při uzamčení
Pro podrobnosti viz Locking Behavior v CREATE TABLE.
Performance
Pro tabulku distribuovanou hashem můžete použít CTAS k výběru jiného sloupce distribuce, abyste dosáhli lepšího výkonu pro spojení a agregace. Pokud není vaším cílem zvolit jiný sloupec distribuce, dosáhnete nejlepšího výkonu CTAS, pokud specifikujete stejný sloupec distribuce, protože se tak vyhnete přerozdělení řádků.
Pokud používáte CTAS k vytváření tabulky a výkon není faktorem, můžete specifikovat ROUND_ROBIN , abyste se vyhnuli rozhodování o distribučním sloupci.
Aby se předešlo přesunu dat v dalších dotazech, můžete za cenu zvýšení úložiště specifikovat REPLICATE načtení plné kopie tabulky na každém Compute uzlu.
Příklady kopírování tabulky
A. Použijte CTAS ke zkopírování tabulky
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Možná jedním z nejběžnějších využití CTAS je vytvoření kopie tabulky, abyste mohli změnit DDL. Pokud jste například původně vytvořili tabulku jako a ROUND_ROBIN nyní ji chcete změnit na tabulku distribuovanou ve sloupci, CTAS tak byste změnili sloupec distribuce.
CTAS lze také použít ke změně rozdělení, indexování nebo typů sloupců.
Řekněme, že jste vytvořili tuto tabulku zadáním HEAP a použitím výchozího typu rozdělení .ROUND_ROBIN
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Nyní chcete vytvořit novou kopii této tabulky s indexem clustered columnstore, abyste mohli využít výkon clusterovaných columnstore tabulek. Také chcete tuto tabulku rozdělit na , ProductKey protože očekáváte spojení v tomto sloupci a chcete se vyhnout pohybu dat během spojení na ProductKey. Nakonec byste měli přidat i partitioning OrderDateKey , abyste mohli rychle mazat stará data tím, že odstraníte staré oddíly. Tady je CTAS příkaz, který by zkopíroval vaši starou tabulku do nové tabulky:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Nakonec můžete přejmenovat své stoly tak, abyste zařadili nový stůl, a pak ten starý zrušit.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Příklady sloupcových možností
B. Použijte CTAS ke změně atributů sloupců
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Tento příklad používá CTAS ke změně datových typů, neplatnosti a třídění pro několik sloupců v tabulce DimCustomer2 .
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
Jako poslední krok můžete použít RENAME (Transact-SQL) k přepnutí názvů tabulek. To dělá z DimCustomer2 novou tabulku.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Příklady rozložení tabulek
C. Použijte CTAS ke změně metody rozdělení tabulky
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Tento jednoduchý příklad ukazuje, jak změnit způsob rozdělení pro tabulku. Pro ukázání mechaniky, jak to udělat, změní tabulku distribuovanou hash na systém s každým a poté tabulku opět na rozdělenou tabulku s hashem. Konečná tabulka odpovídá původní tabulce.
Ve většině případů není nutné měnit tabulku distribuovanou hashem na tabulku s round-robin. Častěji možná budete muset změnit tabulku s round-robin na tabulku distribuovanou hashem. Například můžete nejprve načíst novou tabulku v round-robin a později ji přesunout do hash-distribuované tabulky, abyste dosáhli lepšího výkonu spojení.
Tento příklad využívá databázi AdventureWorksDW s ukázkami. Pro načtení verze Azure Synapse Analytics viz Quickstart: Create and query a dedicated SQL pool (formerly SQL DW) in Azure Synapse Analytics pomocí Azure portálu.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Poté ji změňte zpět na hash distribuovanou tabulku.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Použijte CTAS k převodu tabulky na replikovanou tabulku
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Tento příklad platí pro převod tabulek round-robin nebo hash-distribuovaných tabulek na replikovanou tabulku. Tento konkrétní příklad posouvá předchozí metodu změny typu rozdělení o krok dál. Protože DimSalesTerritory je to dimenze a pravděpodobně menší tabulka, můžete se rozhodnout tabulku znovu vytvořit tak, jak je replikovaná, abyste se vyhnuli pohybu dat při spojování s jinými tabulkami.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Použijte CTAS k vytvoření tabulky s menším počtem sloupců
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Následující příklad vytváří rozdělenou tabulku round-robin s názvem myTable (c, ln). Nová tabulka má pouze dva sloupce. Pro názvy sloupců používá sloupcové aliasy v příkazu SELECT.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Příklady dotazových nápověd
F. Použijte dotazovací nápovědu s příkazem CREATE TABLE AS SELECT (CTAS)
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Tento dotaz ukazuje základní syntaxi pro použití hint query join s příkazem CTAS. Po odeslání dotazu Azure Synapse Analytics aplikuje strategii hash join při generování plánu dotazu pro každou jednotlivou distribuci. Pro více informací o nápovědě k dotazu hash join viz OPTION Clause (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Příklady externích tabulek
G. Použijte CTAS k importu dat z Azure Blob storage
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Pro import dat z externí tabulky použijte CREATE TABLE AS SELECT pro výběr z externí tabulky. Syntaxe pro výběr dat z externí tabulky do Azure Synapse Analytics je stejná jako syntaxe pro výběr dat z běžné tabulky.
Následující příklad definuje externí tabulku dat v Azure Blob Storage účtu. Poté použije CREATE TABLE AS SELECT pro výběr z externí tabulky. Tím se importují data z textově oddělených souborů Azure Blob Storage a data se ukládají do nové tabulky Azure Synapse Analytics.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Použijte CTAS k importu Hadoop dat z externí tabulky
Platí na: Analytický platformový systém (PDW)
Pro import dat z externí tabulky stačí použít CREATE TABLE AS SELECT pro výběr z externí tabulky. Syntaxe pro výběr dat z externí tabulky do Analytics Platform System (PDW) je stejná jako syntaxe pro výběr dat z běžné tabulky.
Následující příklad definuje externí tabulku na Hadoop clusteru. Poté použije CREATE TABLE AS SELECT pro výběr z externí tabulky. Tím se importují data z textově oddělených souborů Hadoop a ukládají se do nové tabulky Analytics Platform System (PDW).
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Příklady použití CTAS jako náhrada SQL Server kódu
Použijte CTAS k obejití některých nepodporovaných funkcí. Kromě možnosti spustit kód v datovém skladu obvykle přepis stávajícího kódu pro CTAS zlepší výkon. To je důsledek jeho plně paralelizovaného designu.
Poznámka:
Zkuste nejdřív myslet na "CTAS". Pokud si myslíte, že problém můžete vyřešit pomocí něj CTAS , pak je to obecně nejlepší způsob, jak k němu přistoupit – i když tím píšete více dat.
I. Používejte CTAS místo SELECT.. DO
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
SQL Server kód obvykle používá SELECT.. INTO pro vyplnění tabulky výsledky příkazu SELECT. Toto je příklad SQL Server SELECT.. Prohlášení IN.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Tato syntax není podporována v Azure Synapse Analytics a Parallel Data Warehouse. Tento příklad ukazuje, jak přepsat předchozí SELECT.. Prohlášení INTO jako prohlášení CTAS. Můžete si vybrat jakoukoli z možností DISTRIBUCE popsaných v syntaxi CTAS. Tento příklad používá ROUND_ROBIN metodu rozdělení.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Použijte CTAS ke zjednodušení příkazů ke sloučení
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Merge příkazy lze alespoň částečně nahradit použitím CTAS. Můžete konsolidovat a INSERTUPDATE the do jednoho tvrzení. Jakékoli smazané záznamy by musely být uzavřeny ve druhém příkazu.
Následuje příklad UPSERT :
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. Explicitně uveďte typ dat a neplatnost výstupu
Platí na: Azure Synapse Analytics and Analytics Platform System (PDW)
Při migraci kódu SQL Server do Azure Synapse Analytics můžete narazit na tento typ kódovacího vzoru:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Instinktivně byste si mohli myslet, že byste měli tento kód převést do CTAS, a měli byste pravdu. Nicméně je tu skrytý problém.
Následující kód NEDÁVÁ stejný výsledek:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Všimněte si, že sloupec "result" přenáší další hodnoty datového typu a neplatnosti výrazu. To může vést k jemným rozdílům hodnot, pokud nejste opatrní.
Zkuste jako příklad následující:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
Hodnota uložená pro výsledek je jiná. Jakmile se přetrvávaná hodnota ve sloupci výsledků použije v jiných výrazech, chyba se stává ještě významnější.
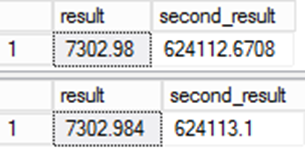
To je důležité pro migraci dat. I když je druhý dotaz možná přesnější, je tu problém. Data by se lišila ve srovnání se zdrojovým systémem, což vede k otázkám integrity při migraci. Tohle je jeden z těch vzácných případů, kdy je "špatná" odpověď skutečně ta správná!
Důvod, proč vidíme tento rozdíl mezi těmito dvěma výsledky, je implicitní typové odlištění. V prvním příkladu tabulka definuje sloupec. Když je řádek vložen, dochází k implicitní převodu typu. Ve druhém příkladu neexistuje implicitní převod typu, protože výraz definuje datový typ sloupce. Všimněte si také, že sloupec ve druhém příkladu byl definován jako sloupec NULLable, zatímco v prvním příkladu tomu tak nebylo. Když byla tabulka vytvořena v prvním příkladu, byla nulovatelnost explicitně definována. Ve druhém příkladu to bylo ponecháno na výrazu a ve výchozím nastavení to vedlo k definici NULL .
Pro vyřešení těchto problémů musíte explicitně nastavit konverzi typu a nullability v SELECT části příkazu CTAS . Tyto vlastnosti nelze nastavit v části Create Table.
Tento příklad ukazuje, jak kód opravit:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Všimněte si následujícího příkladu:
- Mohlo by se použít CAST nebo CONVERT.
- ISNULL se používá k vynucení NULLability, ne k KOALESCE.
- ISNULL je nejvzdálenější funkce.
- Druhá část ISNULL je konstanta,
0.
Poznámka:
Aby byla nulovatelnost správně nastavena, je nezbytné ji použít ISNULL , a ne COALESCE.
COALESCE není deterministickou funkcí, a proto bude výsledek výrazu vždy NULLovatelný.
ISNULL je jiný. Je deterministický. Proto pokud je druhá část ISNULL funkce konstanta nebo literál, výsledná hodnota NEBUDE NULL.
Tento tip není užitečný jen pro zajištění integrity vašich výpočtů. Je to také důležité pro přepínání oddílů tabulek. Představte si, že máte tuto tabulku definovanou jako svůj fakt:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Nicméně pole hodnoty je vypočítaný výraz, není součástí zdrojových dat.
Pro vytvoření rozdělené datové sady zvažte následující příklad:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
Dotaz běžel bez problémů. Problém nastává, když se pokusíte provést přepnutí oddílu. Definice tabulek nesedí. Pro vytvoření definic tabulek je třeba upravit CTAS.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Vidíte tedy, že konzistence typů a udržování vlastností nulovatelnosti na CTAS je dobrá inženýrská nejlepší praxe. Pomáhá to udržet integritu ve výpočtech a také zajišťuje, že přepínání oddílů je možné.
L. Vytvořte uspořádaný index shlukovaného úložiště sloupců pomocí MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Související obsah
- VYTVOŘIT EXTERNÍ ZDROJ DAT (Transact-SQL)
- VYTVOŘENÍ EXTERNÍHO FORMÁTU SOUBORU (Transact-SQL)
- VYTVOŘIT EXTERNÍ TABULKU (Transact-SQL)
- VYTVOŘIT EXTERNÍ TABULKU JAKO SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNÍ STŮL (Transact-SQL)
- ZMĚNIT TABULKU (Transact-SQL)
- ZMĚNA EXTERNÍHO STOLU (Transact-SQL)
platí pro:![]() Warehouse v Microsoft Fabric
Warehouse v Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) je jednou z nejdůležitějších dostupných funkcí T-SQL. Je to plně paralelizovaná operace, která vytváří novou tabulku na základě výstupu příkazu SELECT. CTAS je nejjednodušší a nejrychlejší způsob, jak vytvořit kopii tabulky.
Například použijte CTAS ve skladu v Microsoft Fabric k:
- Vytvořte kopii tabulky s některými sloupci zdrojové tabulky.
- Vytvořte tabulku, která je výsledkem dotazu, jenž spojuje další tabulky.
Pro více informací o používání CTAS ve vašem skladu v Microsoft Fabric viz Ingest dat do vašeho skladu pomocí Transact-SQL.
Poznámka:
Protože CREATE TABLE AS SELECT (CTAS) přidává na možnostech vytváření tabulky, toto téma se snaží neopakovat téma VYTVOŘIT TABULKU. Místo toho popisuje rozdíly mezi CTAS a CREATE TABLE.
Syntaxe
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
) WITH (CLUSTER BY [ ,... n ])
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Arguments
Podrobnosti o běžných argumentech viz Argumenty v CREATE TABLE pro Microsoft Fabric.
S (SHLUK [ ,... n])
Klauzule CLUSTER BY pro shlukování dat ve Fabric Data Warehouse vyžaduje, aby byl pro datové shlukování specifikován alespoň jeden sloupec a maximálně čtyři sloupce.
Pro více informací viz Data clustering in Fabric Data Warehouse.
Příkaz SELECT
Toto SELECT tvrzení je zásadním rozdílem mezi CTAS a CREATE TABLE.
VYBERTE select_criteria
Novou tabulku vyplní výsledky z příkazu SELECT .
select_criteria je tělo příkazu SELECT , které určuje, která data zkopírovat do nové tabulky. Pro informace o SELECT výkazech viz SELECT (Transact-SQL).
Poznámka:
V Microsoft Fabric není použití proměnných v CTAS povoleno.
Povolení
CTAS vyžaduje SELECT povolení ke všem objektům odkazovaným v select_criteria.
Pro oprávnění k vytvoření tabulky viz Oprávnění v CREATE TABLE.
Poznámky
Podrobnosti viz Obecné poznámky v CREATE TABLE.
Limity a omezení
Při použití CTAS se datové typy cílové tabulky odvozují ze sady SELECT výsledků příkazu. Pokud se některý sloupec v sadě výsledků přeloží na datový typ, který není pro úložiště tabulek podporovaný, operace CTAS selže. Toto omezení platí pro trvalé tabulky (tabulky s podporou Parquet), kde lze zapisovat pouze podporované datové typy. Některé datové typy můžou být platné ve výrazech dotazu a průběžných výsledcích, ale nejsou podporovány pro sloupce tabulky. Seznam podporovaných a nepodporovaných datových typů pro tabulky najdete v tématu Data types in Fabric Data Warehouse.
NASTAVIT POČET ŘÁDKŮ (Transact-SQL) nemá vliv na CTAS. Chcete-li dosáhnout podobného chování, použijte top (Transact-SQL).
Další podrobnosti a další omezení, která platí pro CTAS, naleznete v tématu Omezení a omezení v CREATE TABLEtématu .
Chování při uzamčení
Pro podrobnosti viz Locking Behavior v CREATE TABLE.
Příklady kopírování tabulky
Další informace o používání CTAS ve službě Warehouse v Microsoft Fabric najdete v tématu Ingestování dat do vašeho skladu v Microsoft Fabric pomocí jazyka Transact-SQL.
A. Použijte CTAS ke změně atributů sloupců
Tento příklad používá CTAS ke změně datových typů a neplatnosti pro několik sloupců v tabulce DimCustomer2 .
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Použijte CTAS k vytvoření tabulky s menším počtem sloupců
Následující příklad vytváří tabulku s názvem myTable (c, ln). Nová tabulka má pouze dva sloupce. Pro názvy sloupců používá sloupcové aliasy v příkazu SELECT.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Používejte CTAS místo SELECT.. DO
SQL Server kód obvykle používá SELECT.. INTO pro vyplnění tabulky výsledky příkazu SELECT. Toto je příklad SQL Server SELECT.. Prohlášení IN.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
Tento příklad ukazuje, jak přepsat předchozí SELECT.. Prohlášení INTO jako prohlášení CTAS.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Použijte CTAS ke zjednodušení příkazů ke sloučení
Merge příkazy lze alespoň částečně nahradit použitím CTAS. Můžete konsolidovat a INSERTUPDATE the do jednoho tvrzení. Jakékoli smazané záznamy by musely být uzavřeny ve druhém příkazu.
Následuje příklad UPSERT :
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
D. Vytvoření tabulky s clusteringem dat
Použijte následující příkaz k vytvoření nové tabulky pomocí CREATE TABLE AS SELECT (CTAS) s určeným sloupcem pro shlukování dat:
CREATE TABLE nyctlc_With_DataClustering
WITH (CLUSTER BY (lpepPickupDatetime))
AS SELECT * FROM nyctlc;
Pro více informací viz Data clustering in Fabric Data Warehouse.