Informationen zum Bereitstellen von Meta Llama-Modellen mit Azure KI Studio.
Wichtig
Einige der in diesem Artikel beschriebenen Features sind möglicherweise nur in der Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Artikel erfahren Sie mehr über die Meta Llama Modelle. Sie erfahren auch, wie Sie Azure KI Studio verwenden, um Modelle aus diesem Set entweder für serverlose APIs mit nutzungsbasierter Bezahlung oder für verwaltete Computeressourcen bereitzustellen.
Wichtig
Lesen Sie mehr über die Ankündigung von Meta Llama 3-Modellen, die jetzt im Azure KI-Modellkatalog verfügbar sind, im Microsoft Tech Community Blog und Meta Announcement Blog.
Meta Llama 3-Modelle und -Tools sind eine Sammlung von vortrainierten und optimierten generativen Textmodellen mit 8 Milliarden bis 70 Milliarden Parametern. Die Modellfamilie enthält außerdem optimierte Versionen, die für Dialoganwendungsfälle mit Reinforcement Learning from Human Feedback (RLHF), genannt Meta-Llama-3-8B-Instruct und Meta-Llama-3-70B-Instruct. Sehen Sie sich die folgenden GitHub-Beispiele an, um Integrationen mit LangChain, LiteLLM, OpenAI und der Azure API zu erkunden.
Bereitstellen von Meta Llama-Modellen als serverlose API
Bestimmte Modelle aus dem Modellkatalog können als serverlose API mit nutzungsbasierter Bezahlung bereitgestellt werden. So können Sie sie als API nutzen, ohne sie in Ihrem Abonnement zu hosten, und gleichzeitig die für Unternehmen erforderliche Sicherheit und Compliance gewährleisten. Für diese Bereitstellungsoption ist kein Kontingent aus Ihrem Abonnement erforderlich.
Meta Llama 3-Modelle werden als serverlose API mit nutzungsbasierter Bezahlung über den Microsoft Azure Marketplace bereitgestellt, und für sie gelten möglicherweise zusätzliche Nutzungsbedingungen und Preise.
Modellangebote im Azure Marketplace
Die folgenden Modelle sind im Azure Marketplace für Llama 3 verfügbar, wenn sie als Dienst mit nutzungsbasierter Bezahlung bereitgestellt werden:
Wenn Sie ein anderes Modell bereitstellen müssen, stellen Sie es stattdessen auf verwalteten Computeressourcen bereit.
Voraussetzungen
Ein Azure-Abonnement mit einer gültigen Zahlungsmethode. Kostenlose Versionen oder Testversionen von Azure-Abonnements funktionieren nicht. Wenn Sie noch kein Azure-Abonnement haben, erstellen Sie zunächst ein kostenpflichtiges Azure-Konto.
-
Wichtig
Für Meta Llama 3-Modelle ist das Modellimplementierungsangebot mit nutzungsbasierter Bezahlung nur mit Hubs verfügbar, die in den Regionen USA, Osten 2 und Schweden, Mitte erstellt wurden.
Ein KI Studio-Projekt in Azure KI Studio.
Die rollenbasierten Zugriffssteuerungen in Azure (Azure RBAC) werden verwendet, um Zugriff auf Vorgänge in Azure KI Studio zuzuweisen. Um die Schritte in diesem Artikel auszuführen, muss Ihrem Benutzerkonto die Rolle Besitzer oder Mitwirkender für das Azure-Abonnement zugewiesen werden. Alternativ kann Ihrem Konto eine benutzerdefinierte Rolle zugewiesen werden, die über die folgenden Berechtigungen verfügt:
Im Azure-Abonnement – zum Abonnieren des Azure Marketplace-Angebots für das KI Studio-Projekt, einmal für jedes Projekt, pro Angebot:
Microsoft.MarketplaceOrdering/agreements/offers/plans/readMicrosoft.MarketplaceOrdering/agreements/offers/plans/sign/actionMicrosoft.MarketplaceOrdering/offerTypes/publishers/offers/plans/agreements/readMicrosoft.Marketplace/offerTypes/publishers/offers/plans/agreements/readMicrosoft.SaaS/register/action
Für die Ressourcengruppe: Zum Erstellen und Verwenden der SaaS-Ressource:
Microsoft.SaaS/resources/readMicrosoft.SaaS/resources/write
Im KI Studio-Projekt – zum Bereitstellen von Endpunkten (die Rolle „Azure KI-Entwickler“ enthält diese Berechtigungen bereits):
Microsoft.MachineLearningServices/workspaces/marketplaceModelSubscriptions/*Microsoft.MachineLearningServices/workspaces/serverlessEndpoints/*
Weitere Informationen zu Berechtigungen finden Sie unter Rollenbasierte Zugriffssteuerung in Azure KI Studio.
Erstellen einer neuen Bereitstellung
So erstellen Sie eine Bereitstellung
Melden Sie sich beim Azure KI Studio an.
Wählen Sie das Modell, das Sie bereitstellen möchten, aus dem Azure KI Studio-Modellkatalog aus.
Alternativ können Sie die Bereitstellung initiieren, indem Sie mit Ihrem Projekt in KI Studio beginnen. Wählen Sie ein Projekt und dann Bereitstellungen>+ Erstellen aus.
Wählen Sie auf der Seite Details des Modells Bereitstellen und dann Serverlose API mit Azure KI Inhaltssicherheit aus.
Wählen Sie das Projekt, in dem Sie Ihre Modelle bereitstellen möchten. Um das Modellimplementierungsangebot mit nutzungsbasierter Bezahlung zu verwenden, muss Ihr Arbeitsbereich zur Region USA, Osten 2 oder Schweden, Mitte gehören.
Wählen Sie im Bereitstellungs-Assistenten den Link zu Azure Marketplace-Nutzungsbedingungen aus, um mehr über die Nutzungsbedingungen zu erfahren. Sie können auch die Registerkarte Marketplace – Angebotsdetails auswählen, um mehr über die Preise für das ausgewählte Modell zu erfahren.
Wenn Sie das Modell zum ersten Mal in Ihrem Projekt bereitstellen, müssen Sie Ihr Projekt für das jeweilige Angebot (z. B. Meta-Llama-3-70B) im Azure Marketplace abonnieren. Dieser Schritt erfordert, dass Ihr Konto über die Azure-Abonnementberechtigungen und Ressourcengruppenberechtigungen verfügt, die in den Voraussetzungen aufgeführt sind. Jedes Projekt hat sein eigenes Abonnement für das jeweilige Azure Marketplace-Angebot, mit dem Sie die Ausgaben kontrollieren und überwachen können. Wählen Sie Abonnieren und bereitstellen aus.
Hinweis
Für das Abonnieren eines Projekts für ein bestimmtes Azure Marketplace-Angebot (in diesem Fall Meta-Llama-3-70B) muss Ihr Konto über Zugriff vom Typ Mitwirkender oder Besitzer auf der Abonnementebene verfügen, auf der das Projekt erstellt wird. Alternativ kann Ihrem Benutzerkonto eine benutzerdefinierte Rolle zugewiesen werden, die über die Azure-Abonnementberechtigungen und Ressourcengruppenberechtigungen verfügt, die in den Voraussetzungen aufgeführt sind.
Sobald Sie den Arbeitsbereich für das jeweilige Azure Marketplace-Angebot registriert haben, müssen nachfolgende Bereitstellungen desselben Angebots im selben Projekt nicht mehr abonniert werden. Daher müssen Sie nicht über die Berechtigungen auf Abonnementebene für nachfolgende Bereitstellungen verfügen. Wenn dieses Szenario für Sie gilt, wählen Sie Bereitstellung fortsetzen aus.
Geben Sie der Bereitstellung einen Namen. Dieser Name wird Teil der Bereitstellungs-API-URL. Diese URL muss in jeder Azure-Region eindeutig sein.
Klicken Sie auf Bereitstellen. Warten Sie, bis die Bereitstellung fertig ist und Sie auf die Seite Bereitstellungen weitergeleitet werden.
Wählen Sie Im Playground öffnen aus, um mit der Interaktion mit dem Modell zu beginnen.
Sie können zur Seite „Bereitstellungen“ zurückkehren, die Bereitstellung auswählen und die Ziel-URL des Endpunkts und den geheimen Schlüssel notieren, mit dem Sie die Bereitstellung aufrufen und Abschlüsse generieren können.
Sie können die Details, URL und Zugriffsschlüssel für den Endpunkt jederzeit abrufen, indem Sie zur Projektseite navigieren und im Menü auf der linken Seite Bereitstellungen auswählen.
Informationen zur Abrechnung für Meta Llama-Modelle, die mit nutzungsbasierter Bezahlung bereitgestellt werden, finden Sie unter Kosten- und Kontingentüberlegungen zu Llama 3-Modellen, die als Dienst bereitgestellt werden.




Nutzen von Meta Llama-Modellen als Dienst
Modelle, die als Dienst bereitgestellt werden, können entweder mithilfe der Chat- oder der Vervollständigungs-API genutzt werden, abhängig vom bereitgestellten Modelltyp.
Wählen Sie Ihr Projekt oder Ihren Hub und dann im linken Menü Bereitstellungen aus.
Suchen Sie die von Ihnen erstellte Bereitstellung, und wählen Sie sie aus.
Wählen Sie In Playground öffnen aus.
Wählen Sie Code anzeigen aus, und kopieren Sie die Endpunkt-URL und den Schlüssel-Wert.
Senden Sie eine API-Anforderung basierend auf dem Typ des bereitgestellten Modells.
- Verwenden Sie für Vervollständigungsmodelle wie
Meta-Llama-3-8Bdie/completions-API. - Verwenden Sie für Chatmodelle wie
Meta-Llama-3-8B-Instructdie/chat/completions-API.
Weitere Informationen zur Verwendung der APIs finden Sie im Abschnitt Referenz.
- Verwenden Sie für Vervollständigungsmodelle wie
Referenz für Meta Llama-Modelle, die als Dienst bereitgestellt werden
Llama-Modelle akzeptieren sowohl die Azure KI Model Inference-API auf der Route /chat/completions als auch eine Llama-Chat-API auf /v1/chat/completions. Auf die gleiche Weise können Textabschlusse mithilfe der Azure AI Model Inference-API auf der Route /completions oder einer Llama Completions-API auf /v1/completions generiert werden
Das Azure KI-Modellrückschluss-API-Schema finden Sie im Artikel Referenz für Chat-Fertigstellungen und unter OpenAPI-Spezifikation kann vom Endpunkt selbst abgerufen werden.
Vervollständigungs-API
Verwenden Sie die Methode POST, um die Anforderung an die /v1/completions-Route zu senden:
Anforderung
POST /v1/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Anforderungsschema
Die Nutzlast ist eine JSON-formatierte Zeichenfolge mit den folgenden Parametern:
| Schlüssel | Typ | Standard | Beschreibung |
|---|---|---|---|
prompt |
string |
Keine Standardeinstellung. Dieser Wert muss angegeben werden. | Der Prompt, der an das Modell gesendet werden soll |
stream |
boolean |
False |
Beim Streaming können die generierten Token immer dann als vom Server gesendete Ereignisse (nur Daten) gesendet werden, wenn sie verfügbar sind. |
max_tokens |
integer |
16 |
Die maximale Anzahl von Token, die in der Vervollständigung generiert werden. Die Tokenanzahl Ihres Prompts plus max_tokens darf die Kontextlänge des Modells nicht überschreiten. |
top_p |
float |
1 |
Eine Alternative zur Stichprobenentnahme mit Temperatur, die sogenannte Kernstichprobenentnahme, bei dem das Modell die Ergebnisse der Token mit der Wahrscheinlichkeitsmasse top_p berücksichtigt. Daher bedeutet 0,1, dass nur die Token berücksichtigt werden, die die oberen 10 % der Wahrscheinlichkeitsmasse umfassen. Wir empfehlen im Allgemeinen, top_p oder temperature zu ändern, aber nicht beides. |
temperature |
float |
1 |
Die zu verwendende Temperatur für die Stichprobenentnahme zwischen 0 und 2. Je höher der Wert, desto breiter die Stichprobenentnahme für die Tokenverteilung. Null bedeutet eine „gierige“ Stichprobenentnahme. Wir empfehlen, dies oder top_p zu ändern, aber nicht beides. |
n |
integer |
1 |
Wie viele Vervollständigungen für jede Äußerung generiert werden sollen. Hinweis: Da dieser Parameter viele Vervollständigungen generiert, kann Ihr Tokenkontingent schnell aufgebraucht sein. |
stop |
array |
null |
Zeichenfolge oder eine Liste von Zeichenfolgen, die das Wort enthalten, bei dem die API das Generieren weiterer Token beendet. Der zurückgegebene Text wird die Beendigungssequenz nicht enthalten. |
best_of |
integer |
1 |
Generiert serverseitige best_of-Vervollständigungen und gibt die „beste“ zurück (diejenige mit der geringsten logarithmierten Wahrscheinlichkeit pro Token). Die Ergebnisse können nicht gestreamt werden. Wenn Sie diese Funktion zusammen mit n verwenden, steuert best_of die Anzahl der möglichen Vervollständigungen, und n gibt an, wie viele zurückgegeben werden sollen – best_of muss größer als n sein. Hinweis: Da dieser Parameter viele Vervollständigungen generiert, kann Ihr Tokenkontingent schnell aufgebraucht sein. |
logprobs |
integer |
null |
Eine Zahl, die angibt, dass die logarithmierten Wahrscheinlichkeiten für die wahrscheinlichsten Token von logprobs sowie die ausgewählten Token eingeschlossen werden sollen. Wenn logprobs z. B. 10 ist, gibt die API eine Liste der 10 wahrscheinlichsten Token zurück. Die API gibt immer „logprob“ des Tokens der Stichprobenentnahme zurück, sodass die Antwort bis zu „logprobs+1“ Elemente enthalten kann. |
presence_penalty |
float |
null |
Eine Zahl zwischen -2,0 und 2,0. Positive Werte benachteiligen neue Token, je nachdem, ob sie bereits im Text vorkommen, und erhöhen so die Wahrscheinlichkeit, dass das Modell über neue Themen spricht. |
ignore_eos |
boolean |
True |
Gibt an, ob das EOS-Token ignoriert und die Generierung von Token fortgesetzt werden soll, nachdem das EOS-Token generiert wurde. |
use_beam_search |
boolean |
False |
Gibt an, ob die Strahlsuche anstelle der Stichprobenentnahme verwendet werden soll. In diesem Fall muss best_of größer als 1 und temperature muss 0 sein. |
stop_token_ids |
array |
null |
Liste der IDs für Token, die beim Generieren die weitere Tokengenerierung beenden. Die zurückgegebene Ausgabe enthält die Stopptoken, es sei denn, die Stopptoken sind spezielle Token. |
skip_special_tokens |
boolean |
null |
Gibt an, ob spezielle Token in der Ausgabe übersprungen werden sollen. |
Beispiel
Text
{
"prompt": "What's the distance to the moon?",
"temperature": 0.8,
"max_tokens": 512
}
Antwortschema
Die Antwortnutzlast ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Beschreibung |
|---|---|---|
id |
string |
Eindeutiger Bezeichner für die Vervollständigung |
choices |
array |
Die Liste der Vervollständigungsoptionen, die das Modell für die Eingabeaufforderung generiert hat |
created |
integer |
Der Unix-Zeitstempel (in Sekunden) des Zeitpunkts, zu dem die Vervollständigung erstellt wurde |
model |
string |
Die für die Vervollständigung verwendete Modell-ID (model_id) |
object |
string |
Der Objekttyp, der immer text_completion ist. |
usage |
object |
Nutzungsstatistiken für die Vervollständigungsanforderung |
Tipp
Im Streamingmodus ist finish_reason für jeden Antwortblock immer null, mit Ausnahme des letzten, der durch die Nutzlast [DONE] beendet wird.
Das choices-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Beschreibung |
|---|---|---|
index |
integer |
Auswahlindex. Bei best_of> 1 hat der Index in diesem Array möglicherweise nicht die richtige Reihenfolge und ist u. U. nicht 0 bis n-1. |
text |
string |
Vervollständigungsergebnis |
finish_reason |
string |
Der Grund, warum das Modell das Generieren von Token beendet hat: - stop: Das Modell trifft auf einen natürlichen Beendigungspunkt oder auf eine bereitgestellte Beendigungssequenz. - length: Die maximale Anzahl von Token wurde erreicht. - content_filter: RAI führt die Moderation aus, und CMP erzwingt die Moderation. - content_filter_error: Fehler während der Moderation. Es konnte keine Entscheidung über die Antwort getroffen werden. - null: Die API-Antwort wird noch ausgeführt oder ist unvollständig. |
logprobs |
object |
Die logarithmierten Wahrscheinlichkeiten der generierten Token im Ausgabetext |
Das usage-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Wert |
|---|---|---|
prompt_tokens |
integer |
Anzahl der Token im Prompt. |
completion_tokens |
integer |
Die Anzahl der Token, die in der Vervollständigung generiert werden |
total_tokens |
integer |
Token insgesamt |
Das logprobs-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Wert |
|---|---|---|
text_offsets |
array von integers |
Die Position oder der Index der einzelnen Token in der Vervollständigungsausgabe. |
token_logprobs |
array von float |
Ausgewählte logprobs-Werte aus dem Wörterbuch im Array top_logprobs |
tokens |
array von string |
Ausgewählte Token |
top_logprobs |
array von dictionary |
Array des Wörterbuchs. In jedem Wörterbuch ist der Schlüssel das Token, und der Wert ist die Wahrscheinlichkeit. |
Beispiel
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "text_completion",
"created": 217877,
"choices": [
{
"index": 0,
"text": "The Moon is an average of 238,855 miles away from Earth, which is about 30 Earths away.",
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 23,
"completion_tokens": 16
}
}
Chat-API
Verwenden Sie die Methode POST, um die Anforderung an die /v1/chat/completions-Route zu senden:
Anforderung
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Anforderungsschema
Die Nutzlast ist eine JSON-formatierte Zeichenfolge mit den folgenden Parametern:
| Schlüssel | Typ | Standard | Beschreibung |
|---|---|---|---|
messages |
string |
Keine Standardeinstellung. Dieser Wert muss angegeben werden. | Die Nachricht oder der Verlauf von Nachrichten, die bzw. der als Prompt für das Modell fungieren soll. |
stream |
boolean |
False |
Beim Streaming können die generierten Token immer dann als vom Server gesendete Ereignisse (nur Daten) gesendet werden, wenn sie verfügbar sind. |
max_tokens |
integer |
16 |
Die maximale Anzahl von Token, die in der Vervollständigung generiert werden. Die Tokenanzahl Ihres Prompts plus max_tokens darf die Kontextlänge des Modells nicht überschreiten. |
top_p |
float |
1 |
Eine Alternative zur Stichprobenentnahme mit Temperatur, die sogenannte Kernstichprobenentnahme, bei dem das Modell die Ergebnisse der Token mit der Wahrscheinlichkeitsmasse top_p berücksichtigt. Daher bedeutet 0,1, dass nur die Token berücksichtigt werden, die die oberen 10 % der Wahrscheinlichkeitsmasse umfassen. Wir empfehlen im Allgemeinen, top_p oder temperature zu ändern, aber nicht beides. |
temperature |
float |
1 |
Die zu verwendende Temperatur für die Stichprobenentnahme zwischen 0 und 2. Je höher der Wert, desto breiter die Stichprobenentnahme für die Tokenverteilung. Null bedeutet eine „gierige“ Stichprobenentnahme. Wir empfehlen, dies oder top_p zu ändern, aber nicht beides. |
n |
integer |
1 |
Wie viele Vervollständigungen für jede Äußerung generiert werden sollen. Hinweis: Da dieser Parameter viele Vervollständigungen generiert, kann Ihr Tokenkontingent schnell aufgebraucht sein. |
stop |
array |
null |
Zeichenfolge oder eine Liste von Zeichenfolgen, die das Wort enthalten, bei dem die API das Generieren weiterer Token beendet. Der zurückgegebene Text wird die Beendigungssequenz nicht enthalten. |
best_of |
integer |
1 |
Generiert serverseitige best_of-Vervollständigungen und gibt die „beste“ zurück (diejenige mit der geringsten logarithmierten Wahrscheinlichkeit pro Token). Die Ergebnisse können nicht gestreamt werden. Wenn Sie diese Funktion zusammen mit n verwenden, steuert best_of die Anzahl der möglichen Vervollständigungen, und n gibt an, wie viele zurückgegeben werden sollen – best_of muss größer als n sein. Hinweis: Da dieser Parameter viele Vervollständigungen generiert, kann Ihr Tokenkontingent schnell aufgebraucht sein. |
logprobs |
integer |
null |
Eine Zahl, die angibt, dass die logarithmierten Wahrscheinlichkeiten für die wahrscheinlichsten Token von logprobs sowie die ausgewählten Token eingeschlossen werden sollen. Wenn logprobs z. B. 10 ist, gibt die API eine Liste der 10 wahrscheinlichsten Token zurück. Die API gibt immer „logprob“ des Tokens der Stichprobenentnahme zurück, sodass die Antwort bis zu „logprobs+1“ Elemente enthalten kann. |
presence_penalty |
float |
null |
Eine Zahl zwischen -2,0 und 2,0. Positive Werte benachteiligen neue Token, je nachdem, ob sie bereits im Text vorkommen, und erhöhen so die Wahrscheinlichkeit, dass das Modell über neue Themen spricht. |
ignore_eos |
boolean |
True |
Gibt an, ob das EOS-Token ignoriert und die Generierung von Token fortgesetzt werden soll, nachdem das EOS-Token generiert wurde. |
use_beam_search |
boolean |
False |
Gibt an, ob die Strahlsuche anstelle der Stichprobenentnahme verwendet werden soll. In diesem Fall muss best_of größer als 1 und temperature muss 0 sein. |
stop_token_ids |
array |
null |
Liste der IDs für Token, die beim Generieren die weitere Tokengenerierung beenden. Die zurückgegebene Ausgabe enthält die Stopptoken, es sei denn, die Stopptoken sind spezielle Token. |
skip_special_tokens |
boolean |
null |
Gibt an, ob spezielle Token in der Ausgabe übersprungen werden sollen. |
Das messages-Objekt weist die folgenden Felder auf:
| Schlüssel | type | Wert |
|---|---|---|
content |
string |
Der Inhalt der Nachricht. Inhalt ist für alle Nachrichten erforderlich. |
role |
string |
Die Rolle des Erstellers oder der Erstellerin der Nachricht. Einer der folgenden Werte: system, user oder assistant. |
Beispiel
Text
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Antwortschema
Die Antwortnutzlast ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Beschreibung |
|---|---|---|
id |
string |
Eindeutiger Bezeichner für die Vervollständigung |
choices |
array |
Die Liste der Vervollständigungsoptionen, die das Modell für die Eingabenachrichten generiert hat |
created |
integer |
Der Unix-Zeitstempel (in Sekunden) des Zeitpunkts, zu dem die Vervollständigung erstellt wurde |
model |
string |
Die für die Vervollständigung verwendete Modell-ID (model_id) |
object |
string |
Der Objekttyp, der immer chat.completion ist. |
usage |
object |
Nutzungsstatistiken für die Vervollständigungsanforderung |
Tipp
Im Streamingmodus ist finish_reason für jeden Antwortblock immer null, mit Ausnahme des letzten, der durch die Nutzlast [DONE] beendet wird. In jedem choices-Objekt wird der Schlüssel für messages durch delta geändert.
Das choices-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Beschreibung |
|---|---|---|
index |
integer |
Auswahlindex. Bei best_of> 1 hat der Index in diesem Array möglicherweise nicht die richtige Reihenfolge und ist u. U. nicht 0 bis n-1. |
messages oder delta |
string |
Ergebnis der Chatvervollständigung im messages-Objekt. Wenn der Streamingmodus verwendet wird, wird der Schlüssel delta verwendet. |
finish_reason |
string |
Der Grund, warum das Modell das Generieren von Token beendet hat: - stop: Das Modell trifft auf einen natürlichen Beendigungspunkt oder auf eine bereitgestellte Beendigungssequenz. - length: Die maximale Anzahl von Token wurde erreicht. - content_filter: RAI führt die Moderation aus, und CMP erzwingt die Moderation. - content_filter_error: Fehler während der Moderation. Es konnte keine Entscheidung über die Antwort getroffen werden. - null: Die API-Antwort wird noch ausgeführt oder ist unvollständig. |
logprobs |
object |
Die logarithmierten Wahrscheinlichkeiten der generierten Token im Ausgabetext |
Das usage-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Wert |
|---|---|---|
prompt_tokens |
integer |
Anzahl der Token im Prompt. |
completion_tokens |
integer |
Die Anzahl der Token, die in der Vervollständigung generiert werden |
total_tokens |
integer |
Token insgesamt |
Das logprobs-Objekt ist ein Wörterbuch mit den folgenden Feldern:
| Schlüssel | type | Wert |
|---|---|---|
text_offsets |
array von integers |
Die Position oder der Index der einzelnen Token in der Vervollständigungsausgabe. |
token_logprobs |
array von float |
Ausgewählte logprobs-Werte aus dem Wörterbuch im Array top_logprobs |
tokens |
array von string |
Ausgewählte Token |
top_logprobs |
array von dictionary |
Array des Wörterbuchs. In jedem Wörterbuch ist der Schlüssel das Token, und der Wert ist die Wahrscheinlichkeit. |
Beispiel
Im Folgenden sehen Sie eine Beispielantwort:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Bereitstellen von Meta Llama-Modellen für verwaltete Computeressourcen
Neben der Bereitstellung mit dem verwalteten Dienst mit nutzungsbasierter Bezahlung können Sie Meta Llama-Modelle auch auf verwalteten Computeressourcen in KI Studio bereitstellen. Bei der Bereitstellung auf verwalteten Computeressourcen können Sie alle Details zu der Infrastruktur auswählen, in der das Modell ausgeführt wird, einschließlich der zu verwendenden VMs und der Anzahl der Instanzen, die für die Verarbeitung der erwarteten Last verwendet werden. Auf verwalteten Computeressourcen bereitgestellte Modelle verbrauchen das Kontingent Ihres Abonnements. Alle Modelle in der Llama-Familie können auf verwalteten Computeressourcen bereitgestellt werden.
Führen Sie diese Schritte aus, um ein Modell wie beispielsweise Llama-2-7b-chat für einen Echtzeitendpunkt in Azure KI Studio bereitzustellen.
Wählen Sie das Modell, das Sie bereitstellen möchten, aus dem Azure KI Studio-Modellkatalog aus.
Alternativ können Sie die Bereitstellung initiieren, indem Sie mit Ihrem Projekt in KI Studio beginnen. Wählen Sie Ihr Projekt und dann Bereitstellungen>+ Erstellen aus.
Wählen Sie auf der Seite Details des Modells die Option Bereitstellen neben der Schaltfläche Lizenz anzeigen aus.
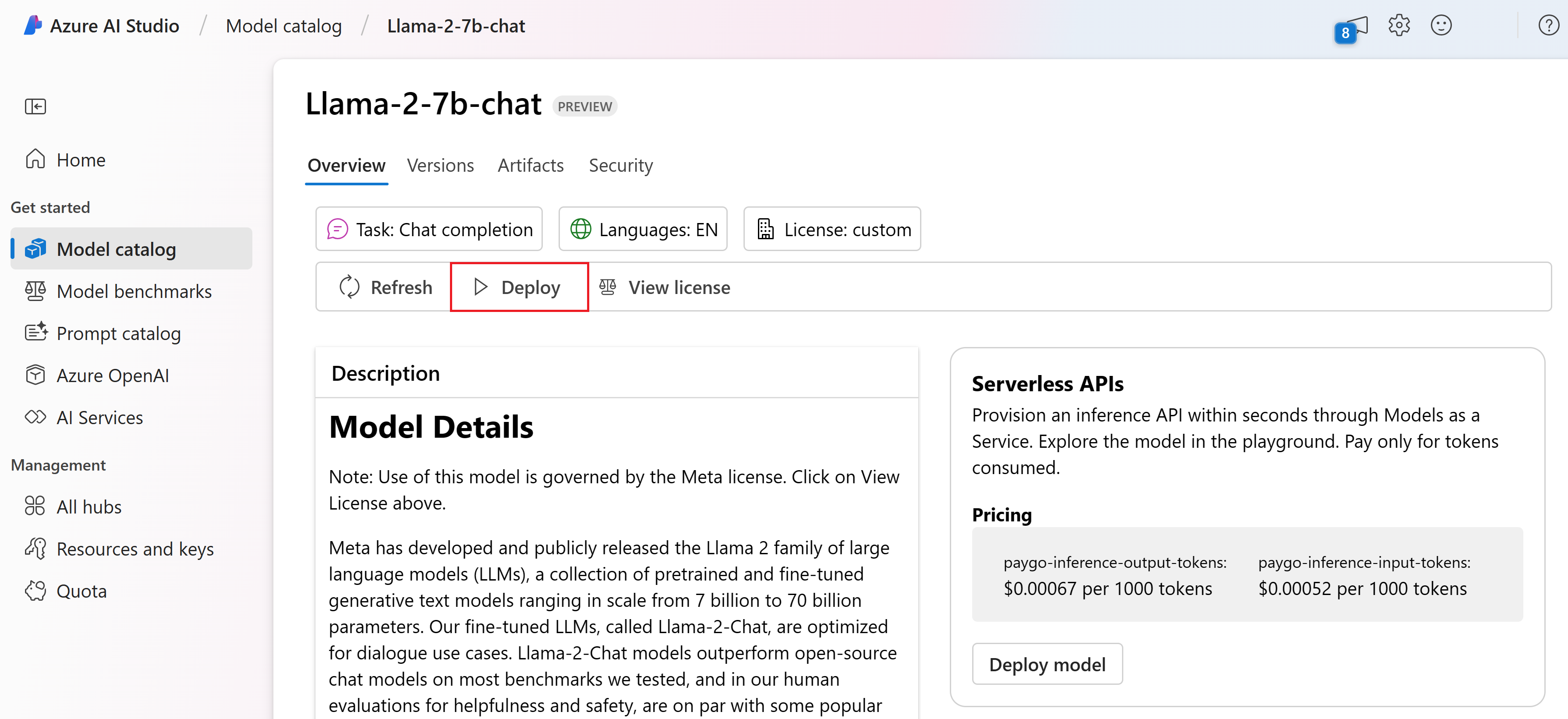
Wählen Sie auf der Seite Mit Azure KI Inhaltssicherheit bereitstellen (Vorschau) die Option Azure KI Inhaltssicherheit überspringen aus, damit Sie das Modell weiterhin mithilfe der Benutzeroberfläche bereitstellen können.
Tipp
Im Allgemeinen wird empfohlen, Azure KI Inhaltssicherheit aktivieren (empfohlen) für die Bereitstellung des Llama-Modells auszuwählen. Diese Bereitstellungsoption wird derzeit nur mit dem Python SDK unterstützt und erfolgt in einem Notebook.
Wählen Sie Proceed (Fortfahren) aus.
Wählen Sie das Projekt aus, in dem Sie eine Bereitstellung erstellen möchten.
Tipp
Wenn im ausgewählten Projekt nicht genügend Kontingent verfügbar ist, können Sie die Option Ich möchte das freigegebene Kontingent verwenden und bestätige, dass dieser Endpunkt in 168 Stunden gelöscht wird. verwenden.
Wählen Sie die VM und die Anzahl der Instanzen aus, die Sie der Bereitstellung zuweisen möchten.
Wählen Sie aus, ob Sie diese Bereitstellung als Teil eines neuen oder eines vorhandenen Endpunkts erstellen möchten. Endpunkte können mehrere Bereitstellungen hosten, wobei die Ressourcenkonfiguration für jede dieser Bereitstellungen exklusiv bleibt. Bereitstellungen unter demselben Endpunkt teilen sich den Endpunkt-URI und seine Zugriffsschlüssel.
Geben Sie an, ob Sie Rückschlussdatensammlung (Vorschau) aktivieren möchten.
Klicken Sie auf Bereitstellen. Nach einigen Augenblicken wird die Seite Details des Endpunkts geöffnet.
Warten Sie, bis die Erstellung und die Bereitstellung des Endpunkts abgeschlossen sind. Dies kann einige Minuten in Anspruch nehmen.
Wählen Sie die Registerkarte Nutzen der Bereitstellung aus, um Codebeispiele anzuzeigen, die zum Verwenden des bereitgestellten Modells in Ihrer Anwendung genutzt werden können.

Nutzen von Llama 2-Modellen, die auf verwalteten Computeressourcen bereitgestellt werden
Informationen zum Aufrufen von Llama-Modellen, die auf verwalteten Computeressourcen bereitgestellt werden, finden Sie auf der Modellkarte im Azure KI Studio-Modellkatalog. Die Karten der einzelnen Modelle enthalten eine Übersichtsseite, die eine Beschreibung des Modells, Beispiele für codebasierte Rückschlüsse, Optimierung und Modellauswertung enthält.
Modellrückschluss: Beispiele
| Paket | Beispielnotebook |
|---|---|
| CLI mit CURL- und Python-Webanforderungen – Command R | command-r.ipynb |
| CLI mit CURL- und Python-Webanforderungen – Command R+ | command-r-plus.ipynb |
| OpenAI SDK (experimentell) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere-SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
Kosten und Kontingente
Kosten- und Kontingentüberlegungen zu Llama-Modellen, die als Dienst bereitgestellt werden
Llama-Modelle, die als Dienst bereitgestellt werden, werden von Meta über den Azure Marketplace angeboten und zur Verwendung in Azure KI Studio integriert. Die Azure Marketplace-Preise werden bei der Bereitstellung oder bei der Optimierung der Modelle angezeigt.
Jedes Mal, wenn ein Projekt ein bestimmtes Angebot aus dem Azure Marketplace abonniert, wird eine neue Ressource erstellt, um die mit der Nutzung verbundenen Kosten nachzuverfolgen. Die gleiche Ressource wird zum Nachverfolgen der Kosten im Zusammenhang mit Rückschluss und Optimierung verwendet. Es stehen jedoch mehrere Verbrauchseinheiten zur Verfügung, um die einzelnen Szenarien unabhängig voneinander nachzuverfolgen.
Weitere Informationen zum Nachverfolgen von Kosten finden Sie unter Überwachen der Kosten für Modelle, die über den Azure Marketplace angeboten werden.

Das Kontingent wird pro Bereitstellung verwaltet. Jede Bereitstellung hat eine Rate von 200.000 Token pro Minute und 1.000 API-Anforderungen pro Minute. Derzeit wird jedoch eine Bereitstellung pro Modell und Projekt beschränkt. Wenden Sie sich an den Microsoft Azure-Support, wenn die aktuellen Ratenbegrenzungen für Ihre Szenarien nicht ausreichen.
Kosten- und Kontingentüberlegungen zu Llama-Modellen, die als verwaltete Computeressourcen bereitgestellt werden
Für die Bereitstellung und für Rückschlüsse von Llama-Modellen mit verwalteten Computeressourcen nutzen Sie das Kernkontingent für VMs, das Ihrem Abonnement für die jeweilige Region zugewiesen ist. Wenn Sie sich für Azure KI Studio registrieren, erhalten Sie ein Standard-VM-Kontingent für mehrere VM-Familien, die in der Region verfügbar sind. Sie können weiterhin Bereitstellungen erstellen, bis Sie ihr Kontingentlimit erreicht haben. Sobald Sie diesen Grenzwert erreicht haben, können Sie eine Kontingenterhöhung anfordern.
Inhaltsfilterung
Modelle, die als serverlose API mit nutzungsbasierter Bezahlung bereitgestellt werden, werden durch Azure KI Inhaltssicherheit geschützt. Bei der Bereitstellung auf verwalteten Computeressourcen können Sie diese Funktion deaktivieren. Wenn Azure KI Inhaltssicherheit aktiviert ist, durchlaufen sowohl Prompt als auch Vervollständigung ein Ensemble von Klassifizierungsmodellen, das darauf abzielt, die Ausgabe schädlicher Inhalte zu erkennen und zu verhindern. Das Inhaltsfiltersystem erkennt bestimmte Kategorien potenziell schädlicher Inhalte sowohl in Eingabeeingabeaufforderungen als auch in Ausgabeabschlüssen und ergreift entsprechende Maßnahmen. Erfahren Sie mehr über Azure KI Inhaltssicherheit.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für