Hinweis
In diesem Artikel wird auf eine Open-Source-Bibliothek zurückgegriffen, die auf GitHub unter https://github.com/mspnp/spark-monitoring gehostet wird.
Die ursprüngliche Bibliothek unterstützt Azure Databricks Runtime-Versionen bis Version 10.x (Spark 3.2.x).
Databricks hat eine aktualisierte Version zur Unterstützung von Azure Databricks Runtime-Versionen ab Version 11.0 (Spark 3.3.x) für den Branch l4jv2 unter https://github.com/mspnp/spark-monitoring/tree/l4jv2 bereitgestellt.
Beachten Sie, dass das Release 11.0 aufgrund der unterschiedlichen Protokollierungssysteme, die in Databricks Runtime-Instanzen verwendet werden, nicht abwärtskompatibel ist. Achten Sie darauf, den richtigen Build für Ihre Databricks Runtime-Instanz zu verwenden. Die Bibliothek und das GitHub-Repository befinden sich im Wartungsmodus. Es gibt keine Pläne für weitere Releases, und der Support bei Problemen wird nur bestmöglich bereitgestellt. Wenn Sie weitere Fragen zu der Bibliothek oder zur Roadmap für die Überwachung und Protokollierung Ihrer Azure Databricks-Umgebungen haben, wenden Sie sich an azure-spark-monitoring-help@databricks.com.
Diese Lösung veranschaulicht Einblickmuster und -metriken, die die Verarbeitungsleistung eines Big Data-Systems mithilfe von Azure Databricks verbessern.
Aufbau

Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Diese Lösung beinhaltet die folgenden Einzelschritte:
Der Server sendet eine große GZIP-Datei, die nach Kunde gruppiert ist, an den Ordner Source in Azure Data Lake Storage.
Von Data Lake Storage wird dann eine erfolgreich extrahierte Kundendatei an Azure Event Grid übermittelt, wodurch die Daten der Kundendatei in mehrere Nachrichten unterteilt werden.
Azure Event Grid sendet die Nachrichten an den Azure Queue Storage-Dienst, der sie in einer Warteschlange ablegt.
Azure Queue Storage überträgt die Warteschlange zur Verarbeitung an die Datenanalyseplattform Azure Databricks.
Azure Databricks entpackt und verarbeitet die Warteschlangendaten. Zuletzt landen die Daten in einer verarbeiteten Datei, die an Data Lake Storage zurückgesandt wird:
Sofern die verarbeitete Datei gültig ist, wird sie im Ordner Landing („Eingang“) abgelegt.
Andernfalls landet die Datei in der Ordnerstruktur Bad („Ungültig“). Dabei kommt die Datei zunächst in den Unterordner Retry, und Data Lake Storage wiederholt den Versuch der Kunden Dateiverarbeitung (Schritt 2). Wenn Azure Databricks ungültige Dateien auch nach mehreren Wiederholungsversuchen noch zurückgibt, werden diese Dateien schließlich im Unterordner Failure („Fehlerhaft“) abgelegt.
Wenn Azure Databricks Daten im vorherigen Schritt entpackt und verarbeitet, sendet es auch Anwendungsprotokolle und Metriken zur Speicherung an Azure Monitor.
Ein Azure Log Analytics-Arbeitsbereich verarbeitet die Anwendungsprotokolle und Metriken aus Azure Monitor zwecks Problembehandlung und umfassender Diagnose mit Kusto-Abfragen.
Komponenten
- Azure Data Lake Storage bietet eine Reihe dedizierter Funktionen für die Big Data-Analyse.
- Mit Azure Event Grid kann ein Entwickler mühelos Anwendungen mit ereignisbasierten Architekturen erstellen.
- Azure Queue Storage ist ein Dienst für die Speicherung sehr vieler Nachrichten. Es bietet vollkommen standortunabhängigen Zugriff auf Nachrichten über authentifizierte Aufrufe per HTTP oder HTTPS. Sie können Warteschlangen verwenden, um ein Arbeitsbacklog zu erstellen, das asynchron verarbeitet werden kann.
- Azure Databricks ist eine Datenanalyseplattform, die für die Azure-Cloud-Plattform optimiert ist. Eine der beiden Umgebungen, die Azure Databricks für die Entwicklung datenintensiver Anwendungen anbietet, ist der Azure Databricks-Arbeitsbereich, eine auf Apache Spark basierende Unified-Analytics-Engine für die umfangreiche Datenverarbeitung.
- Azure Monitor erfasst und analysiert App-Telemetriedaten, z. B. Leistungsmetriken und Aktivitätsprotokolle.
- Azure Log Analytics ist ein Tool zur Bearbeitung und Ausführung von Protokollabfragen mit Daten.
Szenariodetails
Das Entwicklungsteam kann anhand von Einblickmustern und -metriken Engpässe ermitteln und die Leistung eines Big Data-Systems verbessern. Ihr Team muss hierzu Auslastungstests eines umfassenden Metrikdatenstroms für eine umfangreiche Anwendung vornehmen.
Das vorliegende Szenario bietet Anleitungen für die Leistungsoptimierung. Da das Szenario leistungsseitig eine Herausforderung für die kundenspezifische Protokollierung darstellt, wird Azure Databricks eingesetzt, da es in der Lage ist, die folgenden Elemente zuverlässig zu überwachen:
- Benutzerdefinierte Anwendungsmetriken
- Streamingabfrageereignisse
- Anwendungsprotokollmeldungen
Azure Databricks kann diese Überwachungsdaten an verschiedene Protokollierungsdienste wie z. B. Azure Log Analytics senden.
In diesem Szenario wird die Erfassung eines umfangreichen Datenbestands beschrieben, der nach Kunden gruppiert und in einer GZIP-Archivdatei gespeichert wurde. Ausführliche Protokolle sind in Azure Databricks abgesehen von der Apache Spark™-Echtzeitbenutzeroberfläche nicht verfügbar. Daher braucht Ihr Team eine Möglichkeit, zunächst alle Daten für alle Kunden zu speichern und dann Benchmarks zu ermitteln und zu vergleichen. In einem derart umfangreichen Datenszenario ist es im Sinne einer möglichst schnellen Verarbeitung wichtig, einen optimalen Kombinationsexecutorpool und die bestmögliche Dimensionierung der VMs zu ermitteln. In diesem Geschäftsszenario ist die Gesamtanwendung auf eine möglichst schnelle Erfassung und die Abfrageanforderungen angewiesen, damit der Systemdurchsatz bei einer Erhöhung des Arbeitsvolumens nicht unerwartet sinkt. Das Szenario muss gewährleisten, dass das System Vereinbarungen zum Service Level (Service Level Agreements, SLAs) erfüllt, die mit Ihren Kunden vereinbart wurden.
Mögliche Anwendungsfälle
Nachfolgend sehen Sie Szenarios, die von dieser Lösung profitieren können:
- Systemüberwachung
- Leistungswartung
- Überwachung der täglichen Systemauslastung
- Erkennen von Tendenzen, die künftig Probleme verursachen könnten, wenn Sie nicht angegangen werden
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Berücksichtigen Sie die folgenden Aspekte, wenn Sie Überlegungen zur Architektur anstellen:
Azure Databricks kann die Computerressourcen, die für einen umfangreichen Auftrag erforderlich sind, automatisch belegen. Hierdurch werden Probleme vermieden, die bei Verwendung anderer Lösungen auftreten können. Beispielsweise kann bei der Verwendung der Databricks-optimierten automatischen Skalierung auf Apache Spark eine zu umfangreiche Bereitstellung zu einer suboptimalen Ressourcennutzung führen. Möglicherweise wissen Sie auch nicht, wie viele Executors für einen Auftrag erforderlich sind.
Eine Warteschlangennachricht in Azure Queue Storage kann bis zu 64 KB groß sein. Eine Warteschlange kann Millionen Warteschlangennachrichten enthalten– bis hin zum Ausschöpfen der Maximalkapazität eines Speicherkontos.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Verwenden Sie den Azure-Preisrechner, um die Kosten für die Implementierung dieser Lösung abschätzen zu können.
Bereitstellen dieses Szenarios
Hinweis
Die hier beschriebenen Bereitstellungsschritte gelten nur für Azure Databricks, Azure Monitor und Azure Log Analytics. Die Bereitstellung der übrigen Komponenten wird in diesem Artikel nicht behandelt.
Um alle Protokolle und Informationen des Prozesses zu erhalten, müssen Sie Azure Log Analytics und die Azure Databricks-Überwachungsbibliothek einrichten. Die Überwachungsbibliothek streamt Ereignisse auf Apache Spark-Ebene und Metriken für Spark Structured Streaming aus Ihren Aufträgen an Azure Monitor. Für diese Ereignisse und Metriken müssen Sie keine Änderungen an Ihrem Anwendungscode vornehmen.
Folgende Schritte sind zum Einrichten der Leistungsoptimierung für ein Big Data-System durchzuführen:
Erstellen Sie einen Azure Databricks-Arbeitsbereich im Azure-Portal. Kopieren und speichern Sie die Azure-Abonnement-ID (ein global eindeutiger Bezeichner (GUID)), den Ressourcengruppennamen, den Namen des Databricks-Arbeitsbereichs und die Portal-URL des Arbeitsbereichs zur späteren Verwendung.
Rufen Sie in einem Webbrowser die URL des Databricks-Arbeitsbereichs auf, und generieren Sie ein persönliches Databricks-Zugriffstoken. Kopieren und speichern Sie die Tokenzeichenfolge, die mit
dapiund einem 32 Zeichen langen Hexadezimalwert beginnt, zur späteren Verwendung.Klonen Sie das GitHub-Repository mspnp/spark-monitoring auf Ihren lokalen Computer. Dieses Repository enthält den Quellcode für die folgenden Komponenten:
- Die Azure Resource Manager-Vorlage (ARM-Vorlage) zum Erstellen eines Azure Log Analytics-Arbeitsbereichs, die außerdem vordefinierte Abfragen zur Erfassung von Spark-Metriken installiert
- Azure Databricks-Überwachungsbibliotheken
- Beispielanwendung zum Senden von Anwendungsmetriken und -protokollen von Azure Databricks an Azure Monitor
Erstellen Sie mit dem Azure CLI-Befehl zur Bereitstellung einer ARM-Vorlage einen Azure Log Analytics-Arbeitsbereich mit vordefinierten Spark-Metrikabfragen. Kopieren Sie in der Befehlsausgabe den für den neuen Log Analytics Arbeitsbereich generierten Namen (im Format spark-monitoring-<randomized-string>), und speichern Sie ihn.
Kopieren und speichern Sie im Azure-Portal Ihre Log Analytics-Arbeitsbereichs-ID und den zugehörigen Schlüssel zur späteren Verwendung.
Installieren Sie die Community Edition von IntelliJ IDEA, einer integrierten Entwicklungsumgebung (IDE) mit integrierter Unterstützung für das Java Development Kit (JDK) und Apache Maven. Fügen Sie das Scala-Plug-In hinzu.
Erstellen Sie die Azure Databricks Überwachungsbibliotheken mithilfe von IntelliJ IDEA. Zur eigentlichen Erstellung wählen Sie Ansicht>Toolfenster>Maven aus, um das Maven-Toolfenster anzuzeigen. Dann wählen Sie Execute Maven Goal> (Maven-Ziel ausführen) mvn package aus.
Installieren Sie mithilfe eines Python-Paketinstallationstools die Azure Databricks-CLI, und richten Sie die Authentifizierung mit dem persönlichen Databricks-Zugriffstoken ein, das Sie zuvor kopiert haben.
Konfigurieren Sie den Azure Databricks-Arbeitsbereich. Hierzu ändern Sie das Databricks-Initialisierungsskript mit den zuvor kopierten Databricks-und Log Analytics-Werten ab. Danach kopieren Sie die Azure Databricks-CLI, das Initialisierungsskript und die Azure Databricks-Überwachungsbibliotheken in Ihren Databricks-Arbeitsbereich.
In Ihrem Databricks-Arbeitsbereichsportal erstellen und konfigurieren Sie einen Azure Databricks-Cluster.
In IntelliJ IDEA erstellen Sie die Beispielanwendung mit Maven. Führen Sie dann in Ihrem Databricks-Arbeitsbereichsportal die Beispielanwendung aus, um Beispielprotokolle und -metriken für Azure Monitor zu generieren.
Während der Beispielauftrag in Azure Databricks ausgeführt wird, rufen Sie das Azure-Portal auf um die Ereignistypen (Anwendungsprotokolle und -metriken) auf der Log Analytics-Oberfläche anzuzeigen und abzufragen:
- Wählen Sie Tabellen>Custom Logs („Benutzerdefinierte Protokolle“) aus, um das Tabellenschema für Spark-Listenerereignisse (SparkListenerEvent_CL), Spark-Protokollierungsereignisse (SparkLoggingEvent_CL) und Spark-Metriken (SparkMetric_CL) anzuzeigen.
- Wählen Sie Abfrage-Explorer>Gespeicherte Abfragen>Spark-Metriken aus, um die Abfragen, die beim Erstellen des Log Analytics-Arbeitsbereichs hinzugefügt wurden, anzuzeigen und auszuführen.
Weitere Informationen zum Anzeigen und Ausführen von vor- und benutzerdefinierten Abfragen finden Sie im nächsten Abschnitt.
Protokolle und Metriken in Azure Log Analytics abfragen
Auf vordefinierte Abfragen zugreifen
Die Namen der vordefinierten Abfragen zum Abrufen von Spark-Metriken sind nachfolgend aufgeführt.
- % CPU Time Per Executor (CPU-Zeit pro Executor (%))
- % Deserialize Time Per Executor (Deserialisierungszeit pro Executor (%))
- % JVM Time Per Executor (JVM-Zeit pro Executor (%))
- % Serialize Time Per Executor (Serialisierungszeit pro Executor (%))
- Disk Bytes Spilled (Datenträgerüberlauf (Bytes))
- Error Traces (Bad Record Or Bad Files) (Fehlerablaufverfolgungen (ungültiger Datensatz oder ungültige Dateien))
- File System Bytes Read Per Executor (Gelesene Dateisystembytes pro Executor)
- File System Bytes Write Per Executor (Geschriebene Dateisystembytes pro Executor)
- Job Errors Per Job (Auftragsfehler pro Auftrag)
- Job Latency Per Job (Batch Duration) (Auftragslatenz pro Auftrag (Batchdauer))
- Job Throughput (Auftragsdurchsatz)
- Running Executors (Ausgeführte Executors)
- Shuffle Bytes Read (Gelesene umsortierte Bytes)
- Shuffle Bytes Read Per Executor (Gelesene umsortierte Bytes pro Executor)
- Shuffle Bytes Read To Disk Per Executor (Auf Datenträger gelesene umsortierte Bytes pro Executor)
- Shuffle Client Direct Memory (Umsortierter direkter Arbeitsspeicher auf Client)
- Shuffle Client Memory Per Executor (Umsortierter Clientarbeitsspeicher pro Executor)
- Shuffle Disk Bytes Spilled Per Executor (Überlauf umsortierter Datenträgerbytes pro Executor)
- Shuffle Heap Memory Per Executor (Umsortierter Heapspeicher pro Executor)
- Shuffle Memory Bytes Spilled Per Executor (Überlauf umsortierter Arbeitsspeicherbytes pro Executor)
- Stage Latency Per Stage (Stage Duration) (Phasenlatenz pro Phase (Phasendauer))
- Stage Throughput Per Stage (Phasendurchsatz pro Phase)
- Streaming Errors Per Stream (Streamingfehler pro Stream)
- Streaming Latency Errors Per Stream (Streaminglatenz pro Stream)
- Streaming Throughput Input Rows/Sec (Streamingdurchsatz (Eingabezeilen/Sek.))
- Streaming Throughput Processed Rows/Sec (Streamingdurchsatz (verarbeitete Zeilen/Sek.))
- Sum Task Execution Per Host (Aufgabenausführungssumme pro Host)
- Task Deserialization Time (Aufgabendeserialisierungszeit)
- Task Errors Per Stage (Aufgabenfehler pro Phase)
- Task Executor Compute Time (Data Skew Time) (Computezeit für Aufgabenexecutor (Datenschiefezeit))
- Task Input Bytes Read (Gelesene Aufgabeneingabebytes)
- Task Latency Per Stage (Tasks Duration) (Aufgabenlatenz pro Phase (Aufgabendauer))
- Task Result Serialization Time (Serialisierungszeit der Aufgabenergebnisse)
- Task Scheduler Delay Latency (Latenz durch Taskplanerverzögerung)
- Task Shuffle Bytes Read (Gelesene umsortierte Aufgabenbytes)
- Task Shuffle Bytes Written Read (Geschriebene umsortierte Aufgabenbytes)
- Task Shuffle Read Time (Lesedauer für umsortierte Aufgabendaten)
- Task Shuffle Write Time (Schreibdauer für umsortierte Aufgabendaten)
- Task Throughput (Sum Of Tasks Per Stage) (Aufgabendurchsatz (Summe der Aufgaben pro Phase))
- Task Per Executor (Sum Of Tasks Per Stage) (Aufgaben pro Executor (Summe der Aufgaben pro Executor))
- Tasks Per Stage (Aufgaben pro Phase)
Benutzerdefinierte Abfragen schreiben
Sie können auch eigene Abfragen in der Kusto Query Language (KQL) schreiben. Wählen Sie einfach den oberen mittleren Bereich aus, der bearbeitet werden kann, und passen Sie die Abfrage an Ihre Bedürfnisse an.
Die folgenden beiden Abfragen rufen Daten aus den Spark-Protokollierungsereignissen ab:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Die nächsten beiden Beispiele sind Abfragen für das Spark-Metrikprotokoll:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Abfrageterminologie
In der folgenden Tabelle werden einige der Begriffe erläutert, die beim Erstellen einer Abfrage von Anwendungsprotokollen und -metriken verwendet werden.
| Begriff | ID | Hinweise |
|---|---|---|
| Cluster_init | Anwendungs-ID | |
| Warteschlange | Run ID | Eine Run-ID entspricht mehreren Batches. |
| Batch | Batch-ID | Ein Batch entspricht zwei Aufträgen. |
| Auftrag | Auftrags-ID | Ein Auftrag entspricht zwei Phasen. |
| Phase | Phasen-ID | Eine Phase umfasst je nach Aufgabe (Lesen, Umsortieren oder Schreiben) 100 bis 200 Aufgaben-IDs. |
| Aufgaben | Aufgaben-ID | Einem Executor wird genau eine Aufgabe zugewiesen. Zugewiesen wird die Aufgabe, ein partitionBy für eine Partition durchzuführen. Bei ca. 200 Kunden sollte dies 200 Aufgaben ergeben. |
In den folgenden Abschnitten finden Sie die typischen in diesem Szenario verwendeten Metriken zum Überwachen des Systemdurchsatzes, des Ausführungsstatus des Spark-Auftrags und zum Systemressourcenverbrauch.
Systemdurchsatz
| Name | Messung | Einheiten |
|---|---|---|
| Streamdurchsatz | Durchschnittliche Eingangsrate bezogen auf die durchschnittliche Verarbeitungsrate pro Minute | Zeilen pro Minute |
| Auftragsdauer | Durchschnittliche Dauer abgeschlossener Spark-Aufträge pro Minute | Dauer pro Minute |
| Auftragsanzahl | Durchschnittliche Anzahl abgeschlossener Spark-Aufträge pro Minute | Anzahl Aufträge pro Minute |
| Phasendauer | Durchschnittliche Dauer abgeschlossener Phasen pro Minute | Dauer pro Minute |
| Phasenanzahl | Durchschnittliche Anzahl abgeschlossener Phasen pro Minute | Anzahl Phasen pro Minute |
| Aufgabendauer | Durchschnittliche Dauer abgeschlossener Aufgaben pro Minute | Dauer pro Minute |
| Aufgabenanzahl | Durchschnittliche Anzahl abgeschlossener Aufgaben pro Minute | Anzahl Aufgaben pro Minute |
Ausführungsstatus des Spark-Auftrags
| Name | Messung | Einheiten |
|---|---|---|
| Anzahl Schedulerpools | Anzahl der individueller Schedulerpools pro Minute (Anzahl der Warteschlangen in Betrieb) | Anzahl von Schedulerpools |
| Anzahl ausgeführter Executors | Anzahl ausgeführter Executors pro Minute | Anzahl ausgeführter Executors |
| Fehlerablaufverfolgung | Alle Fehlerprotokolle mit Error-Stufe und der entsprechenden Aufgaben-/Stufen-ID (siehe thread_name_s) |
Systemressourcenauslastung
| Name | Messung | Einheiten |
|---|---|---|
| Durchschnittliche CPU-Auslastung pro Executor/gesamt | Anteil der CPU-Auslastung pro Minute | % pro Minute |
| Durchschnittlich verwendeter direkter Speicher (MB) pro Host | Durchschnittlich verwendeter direkter Speicher pro Executor und Minute | MB pro Minute |
| Speicherüberlauf pro Host | Durchschnittlicher Speicherüberlauf pro Executor | MB pro Minute |
| Überwachen der Auswirkung der Datenschiefe auf die Dauer | Messbereich und Differenz zwischen dem 70. und 90. bzw. dem 90. und 100. Perzentil in der Aufgabendauer | Nettodifferenz zwischen 100 %, 90 % und 70 %; prozentuale Differenz zwischen 100 %, 90 % und 70 % |
Entscheiden Sie, wie Sie die in einer GZIP-Archiv Datei zusammengeführten Kundeeingabedaten mit einer bestimmten Azure Databricks-Ausgabedatei verknüpfen, da Azure Databricks den gesamten Batchvorgang als Einheit betrachtet. Hier wenden Sie Granularität auf die Ablaufverfolgung an. Sie können auch benutzerdefinierte Metriken verwenden, um genau eine Ausgabedatei für die ursprüngliche Eingabedatei zu erfassen.
Ausführlichere Definitionen der einzelnen Metriken finden Sie unter Visualisierungen in den Dashboards auf dieser Website. Weitere Informationen finden Sie im Abschnitt Metriken in der Apache Spark-Dokumentation.
Optionen zur Leistungsoptimierung bewerten
Baselinedefinition
Sie und Ihr Entwicklungsteam sollten eine Baseline aufstellen, um künftig eine Vergleichsgrundlage für Anwendungszustände zu haben.
Messen Sie die Leistung Ihrer Anwendung in quantitativer Hinsicht. In diesem Szenario ist die wichtigste Metrik die Auftragslatenz, die in den meisten Fällen für die Vorverarbeitung und Erfassung von Daten typisch ist. Versuchen Sie, die Datenverarbeitungsdauer zu beschleunigen, und legen Sie den Schwerpunkt wie im folgenden Diagramm gezeigt auf die Latenzmessung:
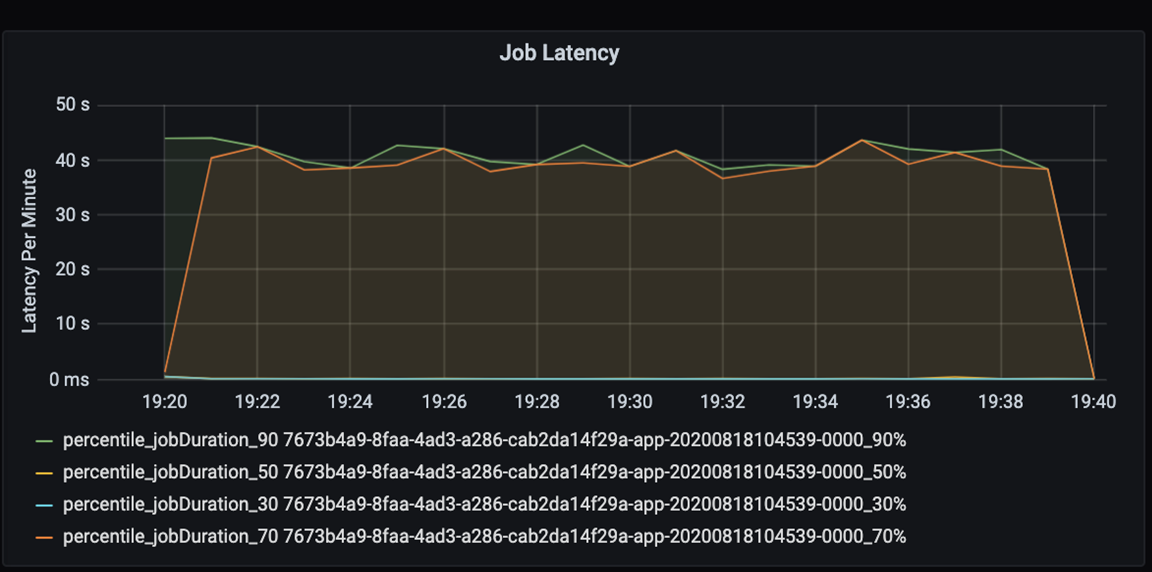
Messung der Ausführungslatenz für einen Auftrag: Grobansicht der Auftragsgesamtleistung und Auftragsausführungsdauer vom Beginn bis zum Abschluss (Mikrobatchzeit). Im obigen Diagramm werden bei der Markierung „19:30“ etwa 40 Sekunden für die Auftragsbearbeitung benötigt.
Wenn Sie sich diese 40 Sekunden genauer ansehen, erkennen Sie die folgenden Daten für die einzelnen Phasen:
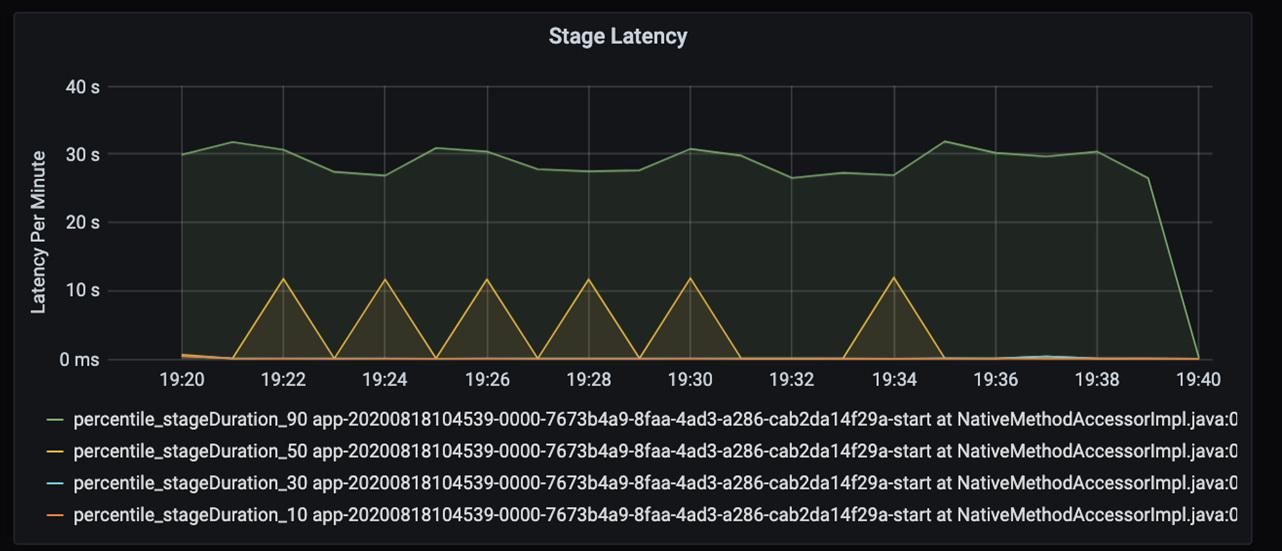
Bei der Markierung „19:30“ gibt es zwei Phasen: eine orangefarbene Phase von 10 Sekunden Länge und eine grüne Phase von 30 Sekunden. Führen Sie eine Überwachung auf Phasenspitzenwerte durch, da ein solcher Spitzenwert eine Verzögerung in einer Phase signalisiert.
Untersuchen Sie, wann eine bestimmte Phase langsam ausgeführt wird. Im Partitionierungsszenario gibt es in der Regel mindestens zwei Phasen: eine zum Lesen einer Datei und eine zweite zum Umsortieren, Partitionieren und Schreiben der Datei. Wenn die Latenz insbesondere in der Schreibphase hoch ist, liegt möglicherweise ein Engpass bei der Partitionierung vor.
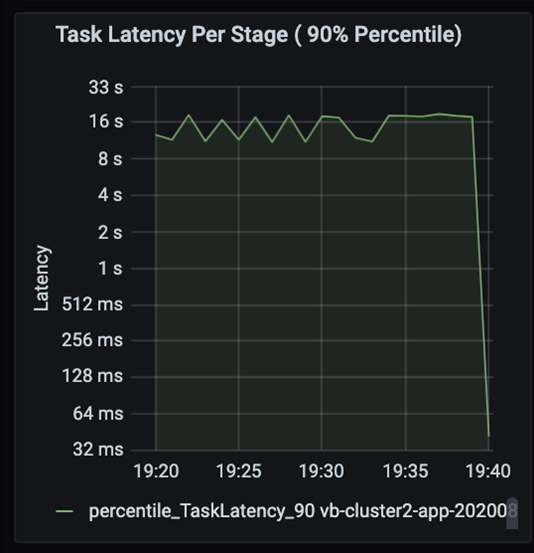
Behalten Sie die Aufgaben im Auge, während die Phasen eines Auftrags nacheinander ausgeführt werden, wobei frühere Phasen spätere blockieren. Wenn innerhalb einer Phase eine Aufgabe eine Sortierpartition langsamer als andere Aufgaben ausführt, müssen alle Aufgaben im Cluster warten, bis die langsamere Aufgabe fertig gestellt ist, damit die Phase abgeschlossen ist. Aufgaben stellen dann eine Möglichkeit dar, die Datenschiefe und mögliche Engpässe zu überwachen. Im oben gezeigten Diagramm sehen Sie, dass alle Aufgaben gleichmäßig verteilt sind.
Überwachen Sie nun die Verarbeitungszeit. Weil es sich hierbei um ein Streamingszenario handelt, betrachten Sie nun den Streamingdurchsatz.
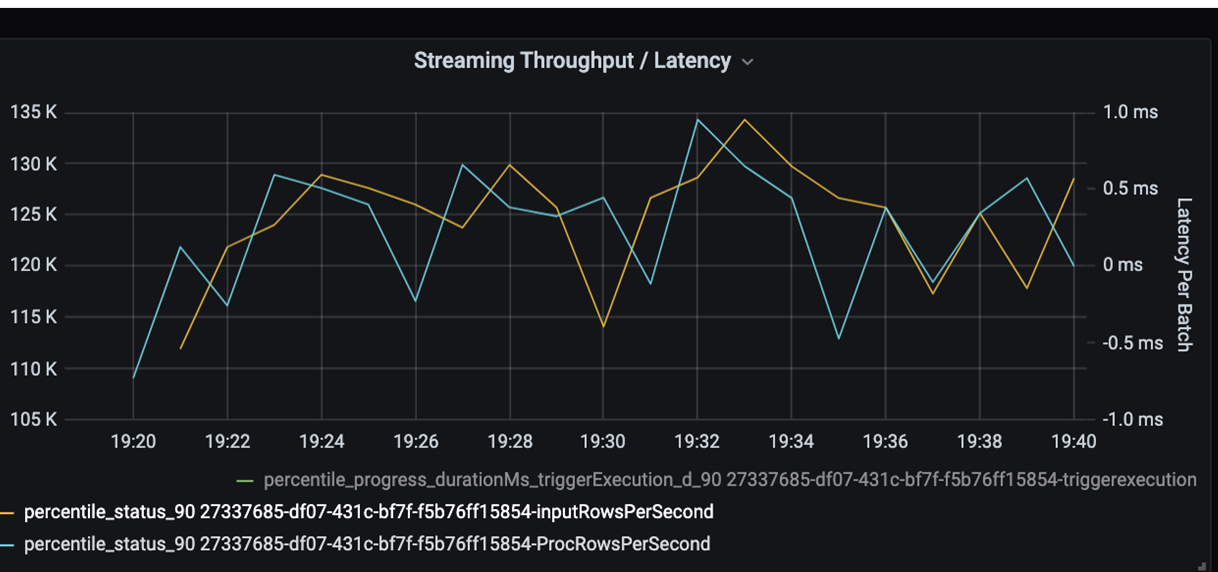
Im obigen Diagramm für Streamingdurchsatz bzw. Batchlatenz steht die orangefarbene Linie für die Eingangsrate (Eingabezeilen pro Sekunde). Die blaue Linie stellt die Verarbeitungsrate (verarbeitete Zeilen pro Sekunde) dar. An manchen Stellen hält die Verarbeitungsrate mit der Eingangsrate nicht Schritt. Das potenzielle Problem besteht hier darin, dass die Eingabedateien die Warteschlange füllen.
Da die Verarbeitungsrate niedriger ist als die Eingangsrate, sollten Sie nach Möglichkeiten suchen, die Verarbeitungsrate passend zur Eingangsrate zu erhöhen. Ein möglicher Grund kann ein Ungleichgewicht der Kundendaten in den einzelnen Partitionsschlüsseln sein, was zu einem Engpass führt. Machen Sie sich für einen nächsten Schritt und eine mögliche Lösung die Skalierbarkeit von Azure Databricks zunutze.
Untersuchung der Partitionierung
Ermitteln Sie zuerst die korrekte Anzahl der Skalierungsexecutors, die Sie bei Azure Databricks benötigen. Wenden Sie hierzu die Faustregel an, jeder Partition in laufenden Executors eine dedizierte CPU zuzuweisen. Wenn Sie beispielsweise 200 Partitionsschlüssel haben, sollte die Anzahl der CPUs multipliziert mit der Anzahl der Executors 200 betragen. (Das würde beispielsweise für acht CPUs in Kombination mit 25 Executors gelten.) Bei 200 Partitionsschlüsseln kann jeder Executor nur eine Aufgabe bearbeiten, wodurch die Wahrscheinlichkeit eines Engpasses sinkt.
Da es in diesem Szenario einige langsame Partitionen gibt, untersuchen Sie die hohe Varianz bei der Aufgabendauer. Prüfen Sie dabei auf Ausreißer bei der Aufgabendauer. Eine Aufgabe behandelt eine Partition. Wenn für eine Aufgabe mehr Zeit erforderlich ist, ist die Partition möglicherweise zu groß und verursacht dadurch einen Engpass.
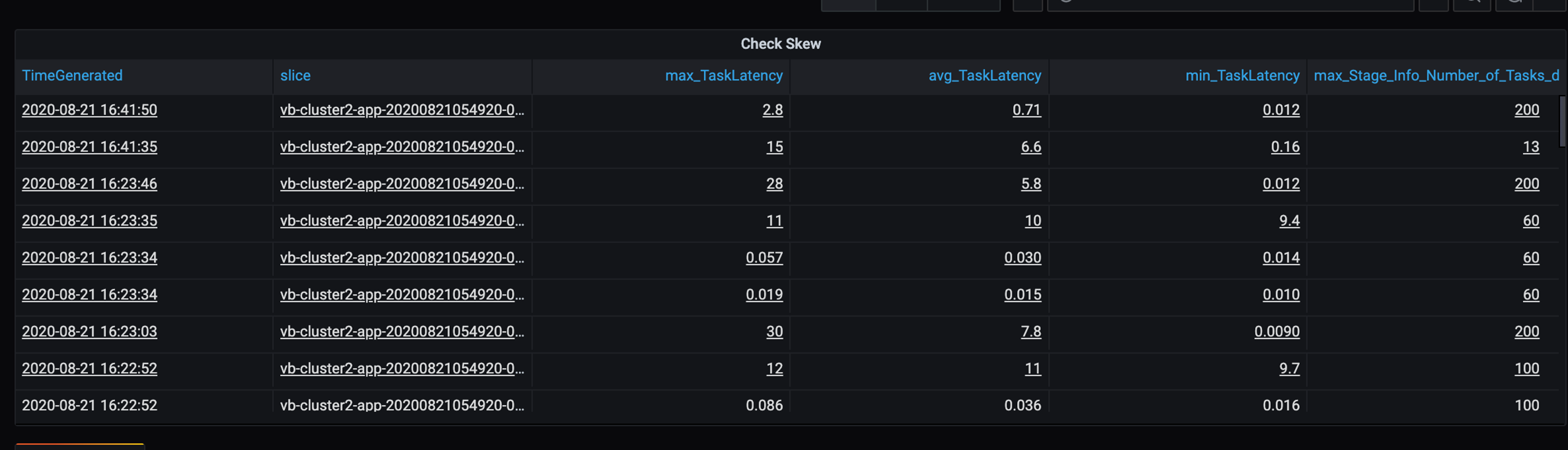
Fehlerablaufverfolgung
Fügen Sie ein Dashboard für die Fehlerablaufverfolgung hinzu, um kundenspezifische Datenfehler erkennen zu können. Bei der Datenvorverarbeitung kommt es vor, dass Dateien beschädigt sind und Datensätze in einer Datei nicht dem Datenschema entsprechen. Im folgenden Dashboard werden viele fehlerhafte Dateien und ungültige Datensätze abgefangen.
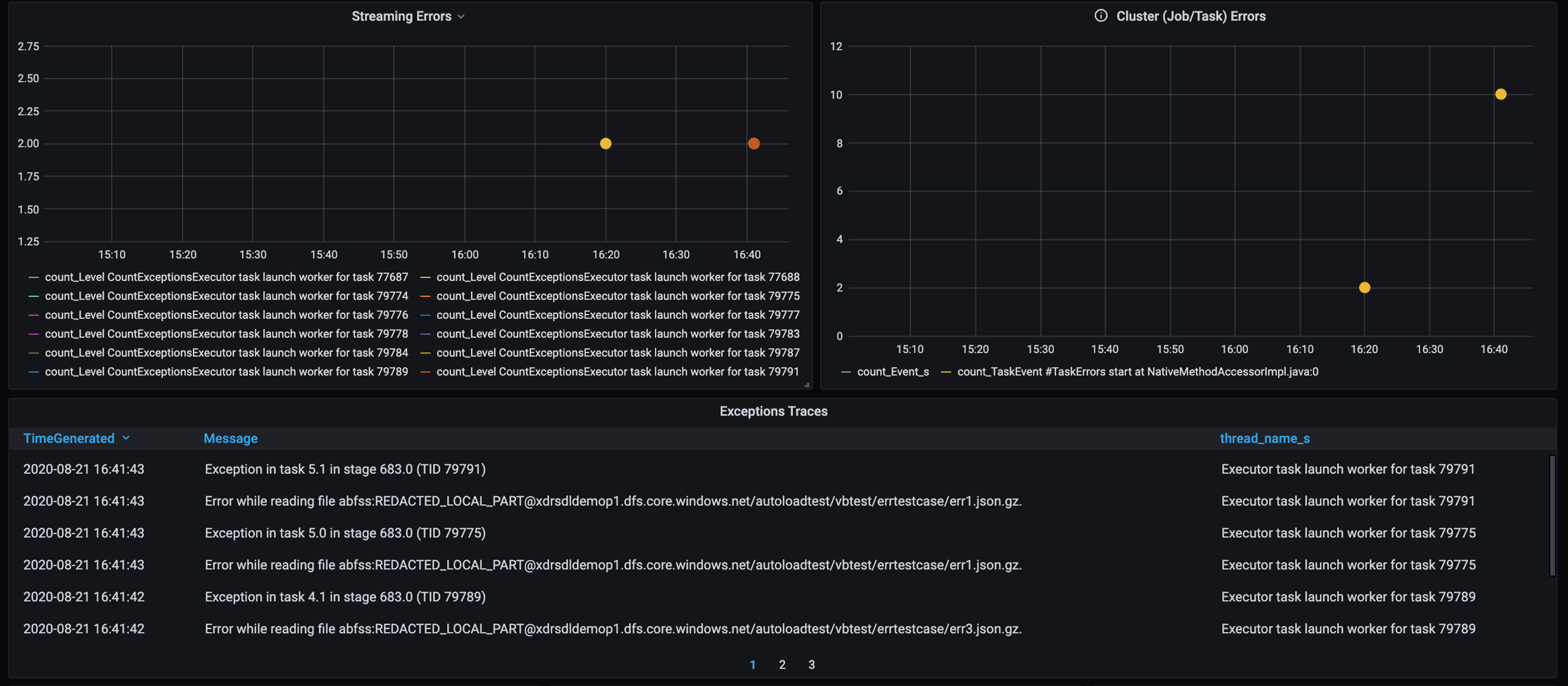
Das Dashboard zeigt die Fehleranzahl, die Fehlermeldung und die Aufgaben-ID zum Debuggen an. Dank der Meldung können Sie den Fehler in der Fehlerdatei ganz leicht zurückverfolgen. Beim Lesen sind bei mehreren Dateien Fehler aufgetreten. Kontrollieren Sie die obere Zeitachse, und untersuchen Sie die konkreten Punkte in unserem Diagramm (16:20 und 16:40).
Weitere Engpässe
Weitere Beispiele und Anleitungen finden Sie unter Behandeln von Leistungsengpässen in Azure Databricks.
Zusammenfassung zur Leistungsoptimierungsbewertung
In diesem Szenario haben sich aus diesen Metriken die folgenden Beobachtungen ergeben:
- Im Staginglatenzdiagramm nehmen die Schreibphasen den Großteil der Verarbeitungszeit in Anspruch.
- Im Aufgabenlatenzdiagramm ist die Aufgabenlatenz stabil.
- Im Streamingdurchsatzdiagramm ist die Ausgaberate an manchen Stellen niedriger als die Eingaberate.
- In der Aufgabendauertabelle erkennen Sie Schwankungen bei den Aufgaben, die auf Unausgewogenheiten bei den Kundendaten zurückzuführen sind.
- Zum Optimieren der Leistung in der Partitionierungsphase sollte die Anzahl der Skalierungsexecutors mit der Anzahl der Partitionen identisch sein.
- Es sind Ablaufverfolgungsfehler aufgetreten, wie z. B. fehlerhafte Dateien und ungültige Datensätze.
Zur Diagnose dieser Probleme haben Sie die folgenden Metriken verwendet:
- Auftragslatenz
- Phasenlatenz
- Aufgabenlatenz
- Streamingdurchsatz
- Aufgabendauer (max., Mittelwert, min.) je Phase
- Fehlerablaufverfolgung (Anzahl, Meldung, Aufgaben-ID)
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- David McGhee | Principal Program Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Lesen Sie das Log Analytics-Tutorial.
- Überwachen von Azure Databricks in einem Azure Log Analytics-Arbeitsbereich
- Bereitstellung von Azure Log Analytics mit Spark-Metriken
- Beobachtbarkeitsmuster