Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In dieser Schnellstartanleitung erstellen Sie einen logischen Server in Azure und eine Hyperscale-Datenbank in Azure SQL-Datenbank über das Azure-Portal, ein PowerShell-Skript oder ein Azure CLI-Skript, mit der Möglichkeit, ein oder mehrere Hochverfügbarkeitsreplikate (High Availability, HA) zu erstellen. Wenn Sie einen vorhandenen logischen Server in Azure verwenden möchten, können Sie auch eine Hyperscale-Datenbank mithilfe von Transact-SQL erstellen.
Tipp
Vereinfachte Preise für den SQL-Datenbankservice Hyperscale im Dezember 2023 eingeführt. Ausführlichere Informationen dazu finden Sie im Hyperscale-Preisblog.
Voraussetzungen
- Ein aktives Azure-Abonnement. Falls Sie nicht über ein Abonnement verfügen, können Sie ein kostenloses Konto erstellen.
- Die neueste Version von Azure PowerShell oder Azure CLI, wenn Sie den Schnellstart programmgesteuert befolgen möchten. Alternativ können Sie den Schnellstart im Azure-Portal abschließen.
- Wenn Sie eine Hyperscale-Datenbank mit Transact-SQL erstellen möchten, ist ein vorhandener logischer Server in Azure erforderlich. Für diesen Ansatz müssen Sie Transact-SQL über den Azure-Portalabfrage-Editor, SQL Server Management Studio (SSMS), sqlcmd oder den Client Ihrer Wahl ausführen.
Berechtigungen
Zum Erstellen von Datenbanken über Transact-SQL: CREATE DATABASE-Berechtigungen sind erforderlich. Damit eine Datenbank erstellt werden kann, muss eine Anmeldung entweder als Serveradministrator (erstellt bei der Bereitstellung des logischen Servers für Azure SQL-Datenbank), als Microsoft Entra-Administrator des Servers oder als Mitglied der Datenbankrolle „dbmanager“ in master erfolgen. Weitere Informationen finden Sie unter CREATE DATABASE.
Zum Erstellen von Datenbanken über das Azure-Portal, PowerShell, die Azure CLI oder REST-API: Azure RBAC-Berechtigungen sind erforderlich, insbesondere die Azure RBAC-Rolle „Mitwirkender“, „SQL-DB-Mitwirkender“ oder „SQL Server-Mitwirkender“. Weitere Informationen finden Sie unter Integrierte Azure RBAC-Rollen.
Erstellen einer Hyperscale-Datenbank
In dieser Schnellstartanleitung wird eine Einzeldatenbank in der Hyperscale-Dienstebene erstellt.
So erstellen Sie eine einzelne Datenbank im Azure-Portal:
Wechseln Sie zum Azure SQL-Hub bei aka.ms/azuresqlhub. Wählen Sie im Bereich für Azure SQL-Datenbank Hyperscaledie Option "Erstellen" aus.

Wählen Sie auf der Registerkarte Grundeinstellungen des Formulars SQL-Datenbank erstellen unter Projektdetails das gewünschte Abonnement für Azure aus.
Wählen Sie bei Ressourcengruppe die Option Neu erstellen aus, geben Sie myResourceGroup ein, und wählen Sie OK aus.
Geben Sie für Datenbankname den Namen mySampleDatabase ein.
Wählen Sie unter Server die Option Neu erstellen aus, und füllen Sie das Formular Neuer Server mit den folgenden Werten aus:
- Servername: Geben Sie mysqlserver ein, und fügen Sie einige weitere Zeichen hinzu, um einen eindeutigen Wert zu erhalten. Wir können keinen exakten Servernamen zur Verwendung angeben, weil Servernamen für alle Server in Azure global eindeutig sein müssen (und nicht nur innerhalb eines Abonnements eindeutig sind). Geben Sie einen Namen wie mysqlserver12345 ein. Das Portal teilt Ihnen mit, ob dieser verfügbar ist.
- Serveradministratoranmeldung: Geben Sie azureuser ein.
- Kennwort: Geben Sie ein geeignetes Kennwort ein, und wiederholen Sie die Eingabe im Feld Kennwort bestätigen.
- Standort: Wählen Sie in der Dropdownliste einen Standort aus.
Von Bedeutung
Schließen Sie keine persönlichen, sensiblen oder vertraulichen Informationen in das Anmeldefeld des Serveradministrators ein. In diesem Feld eingegebene Daten werden nicht als Kundendaten betrachtet.
Klicken Sie auf OK.
Wählen Sie unter Compute + Speicher die Option Datenbank konfigurieren aus.
Mit dieser Schnellstartanleitung wird eine Hyperscale-Datenbank erstellt. Wählen Sie für die Dienstebene die Option Hyperscale aus.
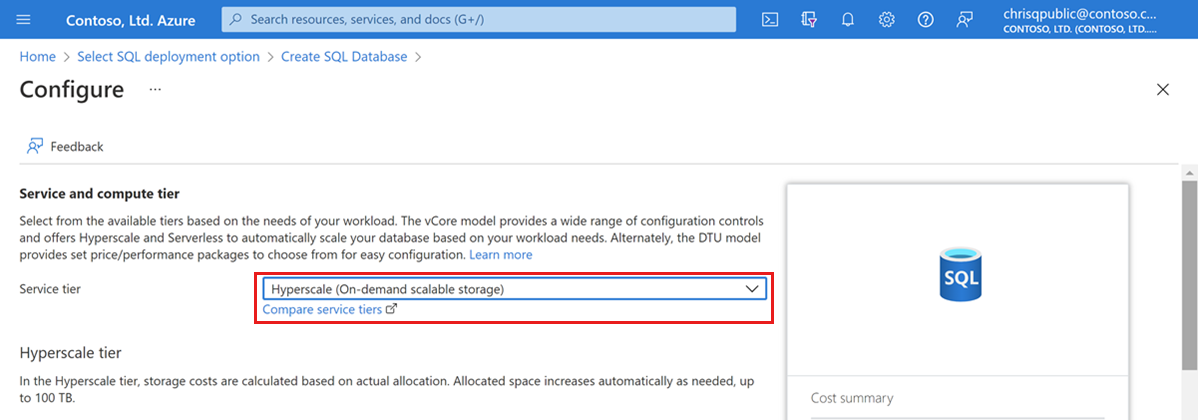
Wählen Sie unter Computehardware die Option Konfiguration ändern aus. Überprüfen Sie die verfügbaren Hardwarekonfigurationen, und wählen Sie die am besten geeignete Konfiguration für Ihre Datenbank aus. In diesem Beispiel wählen Sie die Konfiguration Standard-Serie (Gen5) aus.
Wählen Sie OK aus, um die Hardwaregeneration zu bestätigen.
Optional passen Sie den Schieberegler für virtuelle Kerne an, wenn Sie die Anzahl virtueller Kerne für Ihre Datenbank erhöhen möchten. In diesem Beispiel wählen wir 2 vCPUs als Auswahl.
Passen Sie den Schieberegler für sekundäre Hochverfügbarkeitsreplikate an, um ein Hochverfügbarkeitsreplikat (HA) zu erstellen.
Wählen Sie Übernehmen.
Berücksichtigen Sie beim Erstellen einer Hyperscale-Datenbank sorgfältig die Konfigurationsoption für Sicherungsspeicherredundanz. Die Speicherredundanz kann nur während der Erstellung einer Hyperscale-Datenbank angegeben werden. Sie können lokalredundanten, zonenredundanten oder georedundanten Speicher wählen. Die ausgewählte Speicherredundanzoption wird während der gesamten Lebensdauer der Datenbank sowohl für die Datenspeicherredundanz als auch für die Sicherungsspeicherredundanz verwendet. Vorhandene Datenbanken können mithilfe einer Datenbankkopie oder einer Point-in-Time-Wiederherstellung zu einer anderen Speicherredundanz migriert werden.

Klicken Sie auf Weiter: Netzwerk aus (im unteren Bereich der Seite).
Wählen Sie auf der Registerkarte Netzwerk als Konnektivitätsmethode die Option Öffentlicher Endpunkt aus.
Legen Sie bei Firewallregeln die Option Aktuelle Client-IP-Adresse hinzufügen auf Ja fest. Behalten Sie für Azure-Diensten und -Ressourcen den Zugriff auf diese Servergruppe gestatten den Wert Nein bei.
Wählen Sie Weiter: Sicherheit unten auf der Seite aus.

Aktivieren Sie optional Microsoft Defender für SQL.
Klicken Sie auf Weiter: Zusätzliche Einstellungen aus (im unteren Bereich der Seite).
Wählen Sie auf der Registerkarte Zusätzliche Einstellungen im Abschnitt Datenquelle unter Vorhandene Daten verwenden die Option Beispiel aus. Dadurch wird eine AdventureWorksLT-Beispieldatenbank erstellt, sodass es einige Tabellen und Daten, die Sie abfragen und mit denen Sie experimentieren können, im Gegensatz zu einer leeren Datenbank gibt.
Wählen Sie unten auf der Seite die Option Überprüfen + erstellen aus:

Wählen Sie nach Überprüfung auf der Seite Überprüfen + erstellen die Option Erstellenaus.






Abfragen der Datenbank
Nach der Erstellung der Datenbank können Sie mithilfe des Abfrage-Editors (Vorschau) im Azure-Portal eine Verbindung mit der Datenbank herstellen und die Daten abfragen. Bei Bedarf können Sie die Datenbank alternativ abfragen, indem Sie eine Verbindung mit SQL Server Management Studio (SSMS) oder dem Client Ihrer Wahl herstellen, um Transact-SQL Befehle (sqlcmd usw.) auszuführen.
Suchen Sie im Portal nach SQL-Datenbanken, und wählen Sie SQL-Datenbanken aus. Wählen Sie anschließend Ihre Datenbank aus der Liste.
Wählen Sie auf der Seite für Ihre Datenbank im Menü auf der linken Seite die Option Abfrage-Editor (Vorschau) aus.
Geben Sie Ihre Serveradministrator-Anmeldeinformationen ein, und wählen Sie OK aus.

Wenn Sie Ihre Hyperscale-Datenbank aus der AdventureWorksLT-Beispieldatenbank erstellt haben, geben Sie die folgende Abfrage im Abfrage-Editorbereich ein.
SELECT TOP 20 pc.Name as CategoryName, p.name as ProductName FROM SalesLT.ProductCategory pc JOIN SalesLT.Product p ON pc.productcategoryid = p.productcategoryid;Wenn Sie eine leere Datenbank mithilfe des Transact-SQL Beispielcodes erstellt haben, geben Sie eine weitere Beispielabfrage im Abfrage-Editorbereich ein, z. B. Folgendes:
CREATE TABLE dbo.TestTable( TestTableID int IDENTITY(1,1) NOT NULL, TestTime datetime NOT NULL, TestMessage nvarchar(4000) NOT NULL, CONSTRAINT PK_TestTable_TestTableID PRIMARY KEY CLUSTERED (TestTableID ASC) ) GO ALTER TABLE dbo.TestTable ADD CONSTRAINT DF_TestTable_TestTime DEFAULT (getdate()) FOR TestTime GO INSERT dbo.TestTable (TestMessage) VALUES (N'This is a test'); GO SELECT TestTableID, TestTime, TestMessage FROM dbo.TestTable; GOKlicken Sie auf Ausführen, und sehen Sie sich dann die Abfrageergebnisse im Bereich Ergebnisse an.
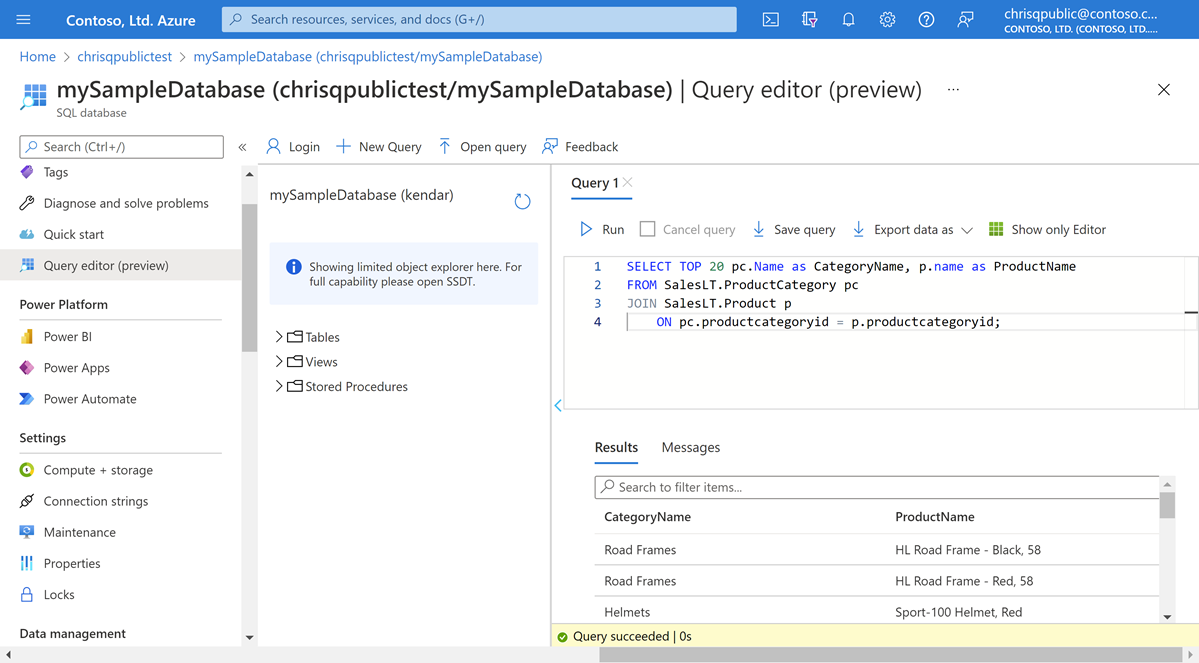
Schließen Sie die Seite Abfrage-Editor, und klicken Sie auf OK, um Ihre nicht gespeicherten Änderungen zu verwerfen, wenn Sie dazu aufgefordert werden.


Bereinigen von Ressourcen
Behalten Sie die Ressourcengruppe, den Server und die Einzeldatenbank für die nächsten Schritte bei, und informieren Sie sich darüber, wie Sie für Ihre Datenbank mit unterschiedlichen Methoden die Verbindungsherstellung und Abfragen durchführen.
Wenn Sie die Verwendung dieser Ressourcen beendet haben, können Sie die erstellte Ressourcengruppe löschen. Hierbei werden auch der Server und die darin enthaltene Einzeldatenbank gelöscht.
Löschen Sie myResourceGroup und alle zugehörigen Ressourcen wie folgt über das Azure-Portal:
- Suchen Sie im Portal nach Ressourcengruppen, und wählen Sie die Option aus. Wählen Sie anschließend in der Liste die Option myResourceGroup aus.
- Wählen Sie auf der Ressourcengruppenseite die Option Ressourcengruppe löschen aus.
- Geben Sie unter Geben Sie den Ressourcengruppennamen ein den Namen myResourceGroup ein, und wählen Sie anschließend Löschen aus.
Zugehöriger Inhalt
Führen Sie für Ihre Datenbank die Verbindungsherstellung und Abfragen mit unterschiedlichen Tools und Sprachen durch:
- Verbinden und Abfragen mit SQL Server Management Studio (SSMS)
- Die Mssql-Erweiterung für Visual Studio Code
- sqlcmd
- Abfrage-Editor für Azure SQL-Datenbank im Azure-Portal
Weitere Informationen zu Hyperscale-Datenbanken finden Sie in den folgenden Artikeln: