Kopieren von Daten aus Teradata Vantage mithilfe von Azure Data Factory und Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- und Azure Synapse Analytics-Pipelines verwenden, um Daten aus Teradata Vantage zu kopieren. Der Artikel baut auf der Übersicht über die Kopieraktivität auf.
Unterstützte Funktionen
Dieser Teradata-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | 1.6 |
| Lookup-Aktivität | 1.6 |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Der Teradata-Connector unterstützt insbesondere Folgendes:
- Teradata, Version 14.10, 15.0, 15.10, 16.0, 16.10 und 16.20.
- Kopieren von Daten unter Verwendung der Standard-, Windows- oder LDAP-Authentifizierung.
- Paralleles Kopieren aus einer Teradata-Quelle. Weitere Informationen finden Sie im Abschnitt Paralleles Kopieren aus Teradata.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Wenn Sie die selbstgehostete Integration Runtime verwenden, beachten Sie, dass ein integrierter Teradata-Treiber ab Version 3.18 enthalten ist. Es ist keine manuelle Treiberinstallation erforderlich. Für den Treiber muss „Visual C++ Redistributable 2012 Update 4“ auf dem Computer mit der selbstgehosteten Integration Runtime vorhanden sein. Sollte diese Komponente noch nicht installiert sein, können Sie sie hier herunterladen.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts für Teradata über die Benutzeroberfläche
Erstellen Sie mit folgenden Schritten einen verknüpften Dienst für Teradata in der Azure-Portal-Benutzeroberfläche.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach Teradata, und wählen Sie den Teradata-Connector aus.
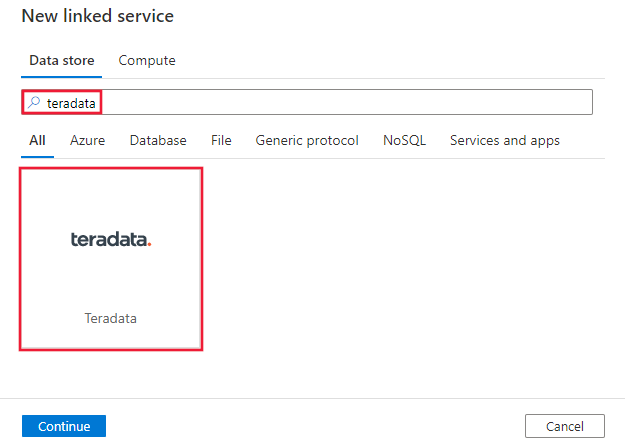
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
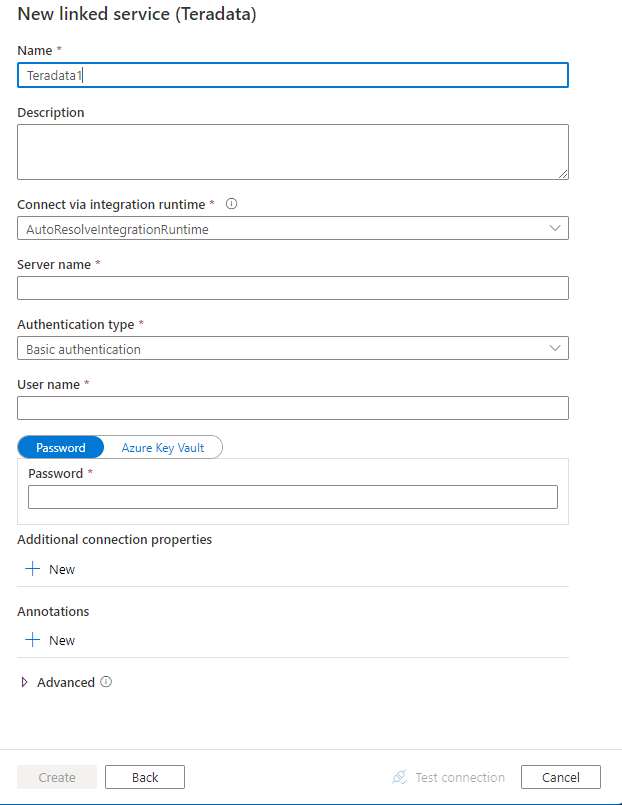
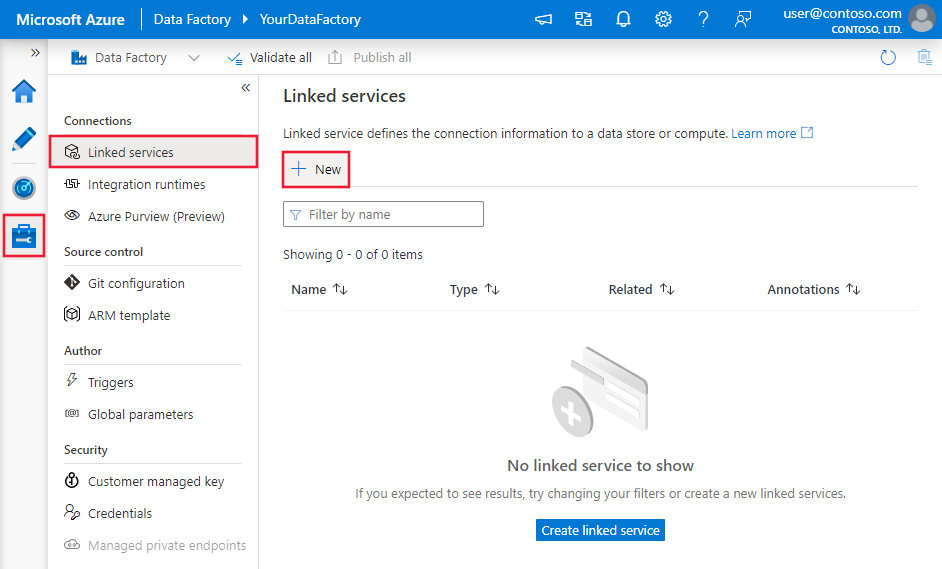
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren spezifischer Data Factory-Entitäten für den Teradata-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Der verknüpfte Teradata-Dienst unterstützt folgende Eigenschaften:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „type“ muss auf Teradata festgelegt sein. | Ja |
| connectionString | Gibt die erforderlichen Informationen für die Verbindungsherstellung mit der Teradata-Instanz an. Sehen Sie sich die folgenden Beispiele an. Sie können auch ein Kennwort in Azure Key Vault speichern und die password-Konfiguration aus der Verbindungszeichenfolge pullen. Ausführlichere Informationen finden Sie unter Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| username | Geben Sie einen Benutzernamen für die Verbindungsherstellung mit Teradata an. Gilt bei Verwendung der Windows-Authentifizierung. | Nein |
| password | Geben Sie das Kennwort für das Benutzerkonto an, das Sie für den Benutzernamen angegeben haben. Sie können auch auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. Gilt, wenn Sie die Windows-Authentifizierung verwenden oder für die Standardauthentifizierung auf ein Kennwort in Key Vault verweisen. |
Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Weitere Verbindungseigenschaften, die Sie abhängig von Ihrem Anwendungsfall in der Verbindungszeichenfolge festlegen können:
| Eigenschaft | Beschreibung | Standardwert |
|---|---|---|
| TdmstPortNumber | Die Nummer des Ports für den Zugriff auf die Teradata-Datenbank. Ändern Sie diesen Wert nur, wenn Sie vom technischen Support dazu aufgefordert werden. |
1025 |
| UseDataEncryption | Mit dieser Eigenschaft wird angegeben, ob die gesamte Kommunikation mit der Teradata-Datenbank verschlüsselt werden soll. Zulässige Werte sind „0“ und „1“. - 0 (deaktiviert, Standardwert): Nur Authentifizierungsinformationen werden verschlüsselt. - 1 (aktiviert): Alle zwischen dem Treiber und der Datenbank übermittelten Daten werden verschlüsselt. |
0 |
| CharacterSet | Der Zeichensatz, der für die Sitzung verwendet werden soll. Beispiel: CharacterSet=UTF16.Bei diesem Wert kann es sich um einen benutzerdefinierten Zeichensatz oder um einen der folgenden vordefinierten Zeichensätze handeln: - ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows, DOS-kompatibel, KANJISJIS_0S) - EUC (Unix-kompatibel, KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | Die maximale Größe des Antwortpuffers für SQL-Anforderungen in Kilobytes (KB). Beispiel: MaxRespSize=10485760.Ab der Teradata Database-Version 16.00 beträgt der Höchstwert „7361536“. Bei Verbindungen mit älteren Versionen beträgt der Höchstwert „1048576“. |
65536 |
| MechanismName | Um das LDAP-Protokoll zum Authentifizieren der Verbindung zu verwenden, geben Sie MechanismName=LDAP an. |
– |
Beispiel mit Standardauthentifizierung
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel mit Windows-Authentifizierung
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel mit LDAP-Authentifizierung
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Hinweis
Die folgende Nutzlast wird weiterhin unterstützt. In Zukunft sollte jedoch die neue verwendet werden.
Vorherige Nutzlast:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Teradata-Dataset unterstützt werden. Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Beim Kopieren von Daten aus Teradata werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „type“ des Datasets muss auf TeradataTable festgelegt werden. |
Ja |
| database | Der Name der Teradata-Instanz. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| table | Der Name der Tabelle in der Teradata-Instanz. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Hinweis
Datasets vom Typ RelationalTable werden weiterhin unterstützt. Es wird jedoch empfohlen, das neue Dataset zu verwenden.
Vorherige Nutzlast:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Eigenschaften der Kopieraktivität
Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Quelle „Teradata“ unterstützt werden. Eine vollständige Liste der verfügbaren Abschnitte und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines.
Teradata als Quelle
Tipp
Weitere Informationen zum effizienten Laden von Daten aus Teradata mithilfe der Datenpartitionierung finden Sie unter Parallele Kopie von Teradata.
Beim Kopieren von Daten aus Teradata werden die folgenden Eigenschaften im Abschnitt source der Copy-Aktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „type“ der Quelle der Kopieraktivität muss auf TeradataSource festgelegt werden. |
Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. z. B. "SELECT * FROM MyTable".Wenn Sie partitioniertes Laden aktivieren, müssen Sie die entsprechenden integrierten Partitionsparameter in Ihre Abfrage integrieren. Beispiele finden Sie im Abschnitt Paralleles Kopieren aus Teradata. |
Nein (wenn „table“ im Dataset angegeben ist) |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, mit denen Daten aus Teradata geladen werden. Zulässige Werte sind: None (Standardwert), Hash und DynamicRange. Wenn eine Partitionsoption aktiviert ist (nicht None), wird der Grad an Parallelität zum gleichzeitigen Laden von Daten aus Teradata durch die Einstellung parallelCopies für die Kopieraktivität gesteuert. |
Nein |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
| partitionColumnName | Geben Sie den Namen der Quellspalte an, die von der Bereichspartitionierung oder Hashpartitionierung für den parallelen Kopiervorgang verwendet wird. Wenn kein Wert angegeben ist, wird der primäre Index der Tabelle automatisch erkannt und als Partitionsspalte verwendet. Verwenden Sie diese Option, wenn die Partitionsoption Hash oder DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfHashPartitionCondition oder ?AdfRangePartitionColumnName in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Parallele Kopie von Teradata. |
Nein |
| partitionUpperBound | Der Höchstwert der Partitionsspalte zum Herauskopieren von Daten. Verwenden Sie ihn, wenn die Partitionsoption DynamicRange lautet. Wenn Sie Quelldaten per Abfrage abrufen, integrieren Sie ?AdfRangePartitionUpbound in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Teradata. |
Nein |
| partitionLowerBound | Der Mindestwert der Partitionsspalte zum Herauskopieren von Daten. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionLowbound in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Teradata. |
Nein |
Hinweis
Kopierquellen vom Typ RelationalSource werden zwar weiterhin unterstützt, das neue integrierte parallele Laden aus Teradata (Partitionsoptionen) wird allerdings nicht unterstützt. Es wird jedoch empfohlen, das neue Dataset zu verwenden.
Beispiel: Kopieren von Daten mit einer einfachen Abfrage ohne Partition
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Parallele Kopie von Teradata
Der Teradata-Connector verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten aus Teradata. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.

Wenn Sie partitioniertes Kopieren aktivieren, führt der Dienst parallele Abfragen an die Teradata-Quelle aus, um Daten partitionsweise zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier einstellen, generiert der Dienst gleichzeitig vier Abfragen auf der Grundlage der von Ihnen angegebenen Partitionsoption und -einstellungen und führt sie aus, wobei jede Abfrage einen Teil der Daten aus Teradata abruft.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung zu aktivieren. Das gilt insbesondere, wenn Sie große Datenmengen aus Ihrer Teradata-Instanz laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus großer Tabelle | Partitionsoption: Hash Der Dienst erkennt während der Ausführung automatisch die Primärindexspalte, wendet einen Hash darauf an und kopiert Daten anhand von Partitionen. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage | Partitionsoption: Hash Abfrage: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Hashpartitionierung an. Ohne Angabe erkennt der Dienst automatisch die Primärschlüsselspalte der Tabelle, die Sie im Teradata-Dataset angegeben haben. Der Dienst ersetzt ?AdfHashPartitionCondition während der Ausführung durch die Hashpartitionierungslogik und sendet die Daten an Teradata. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage, wenn eine Integerspalte mit gleichmäßig verteilten Werten für die Bereichspartitionierung vorhanden ist | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Die Partitionierung kann auf der Grundlage der Spalte mit dem Datentyp „Integer“ erfolgen. Obergrenze der Partition und Untergrenze der Partition: Geben Sie an, ob Sie anhand der Partitionsspalte filtern möchten, um nur Daten zwischen der Ober- und der Untergrenze zu erhalten. Der Dienst ersetzt ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound und ?AdfRangePartitionLowbound während der Ausführung durch die tatsächlichen Spaltennamen und Wertebereiche für jede Partition und sendet sie an Teradata. Wenn z. B. für die Partitionsspalte „ID“ die untere Grenze auf 1 und die obere Grenze auf 80 festgelegt ist und die Parallelkopie auf 4 eingestellt ist, ruft der Dienst Daten für jeweils 4 Partitionen ab. Die ID-Bereiche sehen dann wie folgt aus: [1–20], [21–40], [41–60] und [61–80]. |
Beispiel: Abfrage mit Hashpartition
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Datentypzuordnung für Teradata
Beim Kopieren von Daten aus Teradata gelten die folgenden Zuordnungen von Teradata-Datentypen zu den vom Dienst intern verwendeten Zwischendatentypen. Weitere Informationen dazu, wie die Kopieraktivität das Quellschema und den Datentyp zur Senke zuordnet, finden Sie unter Schema- und Datentypzuordnungen.
| Teradata-Datentyp | Zwischendatentyp des Diensts |
|---|---|
| BigInt | Int64 |
| Blob | Byte[] |
| Byte | Byte[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | Datetime |
| Decimal | Decimal |
| Double | Double |
| Graphic | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Integer | Int32 |
| Interval Day | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Day To Hour | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Day To Minute | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Day To Second | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Hour | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Hour To Minute | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Hour To Second | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Minute | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Minute To Second | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Month | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Second | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Year | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Interval Year To Month | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Number | Double |
| Zeitraum (Datum) | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Zeitraum (Zeit) | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Zeitraum (Zeit mit Zeitzone) | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Zeitraum (Zeitstempel) | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Zeitraum (Zeitstempel mit Zeitzone) | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| SmallInt | Int16 |
| Time | TimeSpan |
| Time With Time Zone | TimeSpan |
| Timestamp | Datetime |
| Timestamp With Time Zone | Datetime |
| VarByte | Byte[] |
| VarChar | String |
| VarGraphic | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
| Xml | Wird nicht unterstützt. Wenden Sie explizite Umwandlungen in der Quellabfrage an. |
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.