Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In Azure Machine Learning können Sie die Modellüberwachung verwenden, um die Leistung von Machine Learning-Modellen in der Produktion kontinuierlich nachzuverfolgen. Die Modellüberwachung bietet Ihnen einen breiten Überblick über Überwachungssignale. Außerdem werden Sie auf potenzielle Probleme aufmerksam. Wenn Sie Signale und Leistungsmetriken von Modellen in der Produktion überwachen, können Sie die inhärenten Risiken Ihrer Modelle kritisch bewerten. Sie können auch blinde Flecken identifizieren, die sich negativ auf Ihr Unternehmen auswirken können.
In diesem Artikel erfahren Sie, wie Sie die folgenden Aufgaben ausführen:
- Einrichten von sofort einsatzbereiten und erweiterten Überwachungen für Modelle, die für Azure Machine Learning-Onlineendpunkte bereitgestellt werden
- Überwachen von Leistungsmetriken für Modelle in der Produktion
- Überwachung für Modelle einrichten, die außerhalb von Azure Machine Learning oder an Batch-Endpunkten von Azure Machine Learning bereitgestellt werden
- Einrichten von benutzerdefinierten Signalen und Metriken für die Modellüberwachung
- Interpretieren von Überwachungsergebnissen
- Integrieren der Azure Machine Learning-Modellüberwachung in Azure Event Grid
Voraussetzungen
Die Azure CLI und die
mlErweiterung auf die Azure CLI, installiert und konfiguriert. Weitere Informationen finden Sie unter Installieren und Einrichten der CLI (v2).For more information, see Install and set up the CLI (v2).Eine Bash-Shell oder eine kompatible Shell, z. B. eine Shell auf einem Linux-System oder Windows-Subsystem für Linux. In den Azure CLI-Beispielen in diesem Artikel wird davon ausgegangen, dass Sie diesen Shelltyp verwenden.
Ein Azure Machine Learning-Arbeitsbereich. Anweisungen zum Erstellen eines Arbeitsbereichs finden Sie unter "Einrichten".
Ein Benutzerkonto mit mindestens einer der folgenden rollenbasierten Azure-Zugriffssteuerungsrollen (Azure RBAC):
- Eine Besitzerrolle für den Azure Machine Learning-Arbeitsbereich
- Mitwirkenderrolle für den Azure Machine Learning-Arbeitsbereich
- Eine benutzerdefinierte Rolle mit
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*Berechtigungen
Weitere Informationen finden Sie unter Verwalten des Zugriffs auf Azure Machine Learning-Arbeitsbereiche.
Für die Überwachung eines von Azure Machine Learning verwalteten Online-Endpunkts oder Kubernetes-Onlineendpunkts:
Ein Modell, das für den Azure Machine Learning-Onlineendpunkt bereitgestellt wird. Verwaltete Onlineendpunkte und Kubernetes-Onlineendpunkte werden unterstützt. Anweisungen zum Bereitstellen eines Modells auf einem Azure Machine Learning-Onlineendpunkt finden Sie unter Bereitstellen und Bewertung eines Machine Learning-Modells mithilfe eines Onlineendpunkts.
Aktivierte Datensammlung für Ihre Modellimplementierung. Sie können die Datensammlung während des Bereitstellungsschritts für Azure Machine Learning-Onlineendpunkte aktivieren. Weitere Informationen finden Sie unter Sammeln von Produktionsdaten aus Modellen, die für echtzeitbasierte Ableitungen bereitgestellt werden.
Zum Überwachen eines Modells, das auf einem Azure Machine Learning-Batchendpunkt bereitgestellt oder außerhalb von Azure Machine Learning bereitgestellt wird:
- Ein Mittel zum Sammeln von Produktionsdaten und zum Registrieren als Azure Machine Learning-Datenressource
- Ein Mittel zum kontinuierlichen Aktualisieren der registrierten Datenressource für die Modellüberwachung
- (Empfohlen) Registrierung des Modells in einem Azure Machine Learning-Arbeitsbereich für die Nachverfolgung von Linien
Konfigurieren eines serverlosen Spark-Computepools
Die Ausführung von Modellüberwachungsaufträgen ist für serverlose Spark-Computepools geplant. Die folgenden Azure Virtual Machines-Instanztypen werden unterstützt:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
Führen Sie die folgenden Schritte aus, um einen Instanztyp eines virtuellen Computers anzugeben, wenn Sie die in diesem Artikel beschriebenen Verfahren ausführen:
Wenn Sie die Azure CLI zum Erstellen eines Monitors verwenden, verwenden Sie eine YAML-Konfigurationsdatei. Legen Sie in dieser Datei den create_monitor.compute.instance_type Wert auf den Typ fest, den Sie verwenden möchten.
Einrichten der sofort einsatzbereiten Modellüberwachung
Ziehen Sie ein Szenario in Betracht, in dem Sie Ihr Modell in einem Azure Machine Learning-Onlineendpunkt bereitstellen und die Datensammlung während der Bereitstellung aktivieren. In diesem Fall sammelt Azure Machine Learning Produktions-Ableitungsdaten und speichert sie automatisch in Azure Blob Storage. Sie können die Azure Machine Learning-Modellüberwachung verwenden, um diese Produktionsferenzdaten kontinuierlich zu überwachen.
Sie können die Azure CLI, das Python SDK oder das Studio für eine sofort einsatzbereite Einrichtung der Modellüberwachung verwenden. Die vordefinierte Modellüberwachungskonfiguration bietet die folgenden Überwachungsfunktionen:
- Azure Machine Learning erkennt automatisch die Produktionsdatenressource, die einer Azure Machine Learning-Onlinebereitstellung zugeordnet ist, und verwendet die Datenressource für die Modellüberwachung.
- Die Verweisdatenobjekt des Vergleichs wird das Produktionsrückschluss-Datenobjekt der jüngsten Vergangenheit festgelegt.
- Das Überwachungssetup umfasst und verfolgt automatisch die folgenden integrierten Überwachungssignale: Datendrift, Vorhersagedrift und Datenqualität. Für jedes Überwachungssignal verwendet Azure Machine Learning Folgendes:
- Das Produktionsrückschluss-Datenobjekt der jüngsten Vergangenheit als Verweisdatenobjekt des Vergleichs.
- Intelligente Standardwerte für Metriken und Schwellenwerte.
- Ein Überwachungsauftrag ist so konfiguriert, dass er regelmäßig ausgeführt wird. Dieser Auftrag erfasst Überwachungssignale und wertet jedes Metrikergebnis anhand seines entsprechenden Schwellenwerts aus. Wenn ein Schwellenwert überschritten wird, sendet Azure Machine Learning standardmäßig eine Benachrichtigungs-E-Mail an den Benutzer, der den Monitor eingerichtet hat.
Führen Sie die folgenden Schritte aus, um die sofort einsatzbereite Modellüberwachung einzurichten.
In der Azure CLI verwenden Sie az ml schedule, um einen Überwachungsauftrag zu planen.
Erstellen Sie eine Überwachungsdefinition in einer YAML-Datei. Eine vordefinierte Beispieldefinition finden Sie im folgenden YAML-Code, der auch im Repository „azureml-examples“ verfügbar ist.
Bevor Sie diese Definition verwenden, passen Sie die Werte an Ihre Umgebung an. Verwenden Sie für
endpoint_deployment_ideinen Wert im Formatazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comFühren Sie den folgenden Befehl aus, um das Modell zu erstellen:
az ml schedule create -f ./out-of-box-monitoring.yaml


Einrichten der erweiterten Modellüberwachung
Azure Machine Learning bietet viele Funktionen für die kontinuierliche Modellüberwachung. Eine umfassende Liste dieser Funktionen finden Sie unter "Funktionen der Modellüberwachung". In vielen Fällen müssen Sie die Modellüberwachung einrichten, die erweiterte Überwachungsaufgaben unterstützt. Im folgenden Abschnitt finden Sie einige Beispiele für die erweiterte Überwachung:
- Verwendung mehrerer Überwachungssignale für eine breite Ansicht
- Verwendung von Historischen Modellschulungsdaten oder Validierungsdaten als Vergleichsreferenzdatenressource
- Überwachung der wichtigsten N-Features und einzelner Features
Konfigurieren der Featurerelevanz
Die Feature-Wichtigkeit stellt die relative Wichtigkeit jedes Eingabefeatures für die Ausgabe eines Modells dar. Die Temperatur kann z. B. für die Vorhersage eines Modells wichtiger sein als die Erhöhung. Wenn Sie Featurerelevanz aktivieren, können Sie festlegen, welche Features in der Produktion nicht abweichen oder Datenqualitätsprobleme aufweisen dürfen.
Um Featurerelevanz mit jedem Ihrer Signale (z. B. Datendrift oder Datenqualität) zu aktivieren, müssen Sie Folgendes bereitstellen:
- Ihr Trainingsdatenobjekt als
reference_data-Datenobjekt. - Die
reference_data.data_column_names.target_column-Eigenschaft ist der Name der Ausgabespalte oder Vorhersagespalte Ihres Modells.
Nachdem Sie die Feature-Wichtigkeit aktiviert haben, wird für jedes Feature, das Sie im Azure Machine Learning Studio überwachen, eine Feature-Wichtigkeit angezeigt.
Sie können Benachrichtigungen für jedes Signal aktivieren oder deaktivieren, indem Sie die alert_enabled Eigenschaft festlegen, wenn Sie das Python SDK oder die Azure CLI verwenden.
Sie können die Azure CLI, das Python SDK oder das Studio verwenden, um die erweiterte Modellüberwachung einzurichten.
Erstellen Sie eine Überwachungsdefinition in einer YAML-Datei. Eine erweiterte Beispieldefinition finden Sie im folgenden YAML-Code, der auch im Azureml-Beispiel-Repository verfügbar ist.
Bevor Sie diese Definition verwenden, passen Sie die folgenden Einstellungen und alle anderen Einstellungen an die Anforderungen Ihrer Umgebung an:
- Verwenden Sie für
endpoint_deployment_ideinen Wert im Formatazureml:<endpoint-name>:<deployment-name>. - Verwenden Sie für
pathin Abschnitten der Verweiseingabedaten einen Wert im Formatazureml:<reference-data-asset-name>:<version>. - Verwenden Sie für
target_columnden Namen der Ausgabespalte, die Werte enthält, die das Modell vorhersagt, wie beispielsweiseDEFAULT_NEXT_MONTH. - Listen Sie die Features für
featuresauf, wieSEX,EDUCATION, undAGE, die Sie in einem erweiterten Signal für Datenqualität verwenden möchten. - Listen Sie unter
emailsdie E-Mail-Adressen auf, die Sie für Benachrichtigungen verwenden möchten.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- Verwenden Sie für
Führen Sie den folgenden Befehl aus, um das Modell zu erstellen:
az ml schedule create -f ./advanced-model-monitoring.yaml






Einrichten der Modellleistungsüberwachung
Wenn Sie die Azure Machine Learning-Modellüberwachung verwenden, können Sie die Leistung Ihrer Modelle in der Produktion nachverfolgen, indem Sie deren Leistungsmetriken berechnen. Die folgenden Modellleistungsmetriken werden derzeit unterstützt:
- Für Klassifizierungsmodelle:
- Präzision
- Genauigkeit
- Abruf
- Für Regressionsmodelle:
- Mittlerer absoluter Fehler (MAE)
- Mittlerer quadratischer Fehler (MSE)
- Mittlere quadratische Gesamtabweichung (RMSE)
Voraussetzungen für die Modellleistungsüberwachung
Ausgabedaten für das Produktionsmodell (die Vorhersagen des Modells) mit einer eindeutigen ID für jede Zeile. Wenn Sie den Azure Machine Learning-Datensammler zum Sammeln von Produktionsdaten verwenden, wird für jede Rückschlussanforderung für Sie eine Korrelations-ID bereitgestellt. Der Datensammler bietet auch die Möglichkeit, Ihre eigene eindeutige ID aus Ihrer Anwendung zu protokollieren.
Hinweis
Für die Leistungsüberwachung des Azure Machine Learning-Modells wird empfohlen, den Azure Machine Learning-Datensammler zu verwenden, um Ihre eindeutige ID in einer eigenen Spalte zu protokollieren.
Grundwahrheitsdaten (Ist-Werte) mit einer eindeutigen ID für jede Zeile. Die eindeutige ID für eine bestimmte Zeile sollte mit der eindeutigen ID für die Modellausgabedaten für diese bestimmte Ableitungsanforderung übereinstimmen. Diese eindeutige ID wird verwendet, um Ihren Grundwahrheitsdatensatz mit der Modelldaten-Ausgabe zu verknüpfen.
Wenn Sie keine Bodendaten haben, können Sie keine Modellleistungsüberwachung durchführen. Da sich Grundwahrheitsdaten auf Anwendungsebene befinden, liegt es in Ihrer Verantwortung, sie zu sammeln, sobald sie verfügbar werden. Sie sollten auch eine Datenressource in Azure Machine Learning verwalten, die diese Grundwahrheitsdaten enthält.
(Optional) Eine vordefinierte tabellarische Datenressource mit Modellausgabedaten und Boden-Wahrheitsdaten, die bereits miteinander verbunden sind.
Anforderungen für die Modellleistungsüberwachung, wenn Sie den Datensammler verwenden
Azure Machine Learning generiert eine Korrelations-ID für Sie, wenn Sie die folgenden Kriterien erfüllen:
- Sie verwenden den Azure Machine Learning-Datensammler , um Produktionsableitungsdaten zu sammeln.
- Sie geben für jede Zeile keine eigene eindeutige ID als separate Spalte an.
Die generierte Korrelations-ID ist im protokollierten JSON-Objekt enthalten. Der Datensammler bündelt jedoch Zeilen, die innerhalb kurzer Zeitintervalle gesendet werden. Batchzeilen fallen in dasselbe JSON-Objekt. Innerhalb jedes Objekts weisen alle Zeilen dieselbe Korrelations-ID auf.
Um zwischen den Zeilen in einem JSON-Objekt zu unterscheiden, verwendet azure Machine Learning-Modellleistungsüberwachung die Indizierung, um die Reihenfolge der Zeilen innerhalb des Objekts zu bestimmen. Wenn ein Batch beispielsweise drei Zeilen enthält und die Korrelations-ID lautet test, hat die erste Zeile eine ID von test_0, die zweite Zeile hat eine ID von test_1, und die dritte Zeile hat eine ID von test_2. Um die eindeutigen IDs Ihrer Grundwahrheitsdaten mit den IDs Ihrer gesammelten Ausgabedaten Ihres Produktionsrückschlussmodells abzugleichen, wenden Sie auf jede Korrelations-ID einen geeigneten Index an. Wenn Ihr protokolliertes JSON-Objekt nur eine Zeile enthält, verwenden Sie correlationid_0 als Wert für correlationid.
Um diese Indizierung zu vermeiden, empfiehlt es sich, Ihre eindeutige ID in einer eigenen Spalte zu protokollieren. Platzieren Sie diese Spalte innerhalb des Pandas-Datenrahmens, den der Azure Machine Learning-Datensammler protokolliert. In Ihrer Modellüberwachungskonfiguration können Sie dann den Namen dieser Spalte angeben, um Ihre Modellausgabedaten mit Ihren Boden-Wahrheitsdaten zu verknüpfen. Solange die IDs für jede Zeile in beiden Datenbeständen identisch sind, kann die Azure Machine Learning-Modellüberwachung die Leistung des Modells überwachen.
Beispielworkflow für die Überwachung der Modellleistung
Um die Konzepte zu verstehen, die der Modellleistungsüberwachung zugeordnet sind, sollten Sie den folgenden Beispielworkflow berücksichtigen. Es gilt für ein Szenario, in dem Sie ein Modell bereitstellen, um vorherzusagen, ob Kreditkartentransaktionen betrügerisch sind:
- Konfigurieren Sie Ihre Bereitstellung so, dass der Datensammler verwendet wird, um die Produktionsrückschlussdaten (Eingabe- und Ausgabedaten) des Modells zu sammeln. Speichern Sie die Ausgabedaten in einer Spalte mit dem Namen
is_fraud. - Protokollieren Sie für jede Zeile der gesammelten Rückschlussdaten eine eindeutige ID. Die eindeutige ID kann aus Ihrer Anwendung stammen, oder Sie können den Wert verwenden, den
correlationidAzure Machine Learning für jedes protokollierte JSON-Objekt eindeutig generiert. - Wenn die Grundwahrheitsdaten
is_fraud(oder Ist-Werte) verfügbar sind, protokollieren Sie jede Zeile und ordnen Sie sie derselben eindeutigen ID zu, die für die entsprechende Zeile in den Ausgabedaten des Modells protokolliert wurde. - Registrieren Sie eine Datenressource in Azure Machine Learning, und verwenden Sie sie zum Sammeln und Verwalten der Boden-Wahrheitsdaten
is_fraud. - Erstellen Sie mithilfe der eindeutigen ID-Spalten ein Modellleistungsüberwachungssignal, das die Produktionsrückschluss- und Grundwahrheitsdatenobjekte des Modells verknüpft.
- Berechnen sie die Modellleistungsmetriken.
Nachdem Sie die Voraussetzungen für die Modellleistungsüberwachung erfüllt haben, führen Sie die folgenden Schritte aus, um die Modellüberwachung einzurichten:
Erstellen Sie eine Überwachungsdefinition in einer YAML-Datei. Die folgende Beispielspezifikation definiert die Modellüberwachung mit Produktions-Ableitungsdaten. Bevor Sie diese Definition verwenden, passen Sie die folgenden Einstellungen und alle anderen Einstellungen an die Anforderungen Ihrer Umgebung an:
- Für
endpoint_deployment_ideinen Wert im Formatazureml:<endpoint-name>:<deployment-name>verwenden. - Verwenden Sie für jeden
pathWert in einem Eingabedatenabschnitt einen Wert im Formatazureml:<data-asset-name>:<version>. - Verwenden Sie für den
predictionWert den Namen der Ausgabespalte, die Werte enthält, die vom Modell vorhergesagt werden. - Verwenden Sie für den
actualWert den Namen der Ground-Truth-Spalte, die die tatsächlichen Werte enthält, die vom Modell vorhergesagt werden sollen. - Verwenden Sie für die
correlation_idWerte die Namen der Spalten, die verwendet werden, um die Ausgabedaten und die Boden-Wahrheitsdaten zu verknüpfen. - Listen Sie unter
emailsdie E-Mail-Adressen auf, die Sie für Benachrichtigungen verwenden möchten.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- Für
Führen Sie den folgenden Befehl aus, um das Modell zu erstellen:
az ml schedule create -f ./model-performance-monitoring.yaml





Einrichten der Modellüberwachung von Produktionsdaten
Sie können auch Modelle überwachen, die Sie auf Azure Machine Learning-Batchendpunkten bereitstellen oder die Sie außerhalb von Azure Machine Learning bereitstellen. Wenn Sie nicht über eine Bereitstellung verfügen, aber über Produktionsdaten verfügen, können Sie die Daten verwenden, um eine kontinuierliche Modellüberwachung durchzuführen. Um diese Modelle zu überwachen, müssen Sie folgende Möglichkeiten haben:
- Sammeln Sie Produktionsinferenzdaten aus Modellen, die in der Produktionsumgebung bereitgestellt werden.
- Registrieren Sie die Produktionsinferenzdaten als Azure Machine Learning-Datenressource, und stellen Sie eine kontinuierliche Aktualisierungen der Daten sicher.
- Stellen Sie eine benutzerdefinierte Datenvorverarbeitungskomponente bereit, und registrieren Sie sie als Azure Machine Learning-Komponente, wenn Sie den Datensammler nicht zum Sammeln von Daten verwenden. Ohne diese benutzerdefinierte Datenvorverarbeitungskomponente kann das Azure Machine Learning-Modellüberwachungssystem Ihre Daten nicht in ein tabellarisches Formular verarbeiten, das zeitfenstern unterstützt.
Ihre benutzerdefinierte Vorverarbeitungskomponente muss über die folgenden Eingabe- und Ausgabesignaturen verfügen:
| Eingabe oder Ausgabe | Signaturname | type | Beschreibung | Beispielswert |
|---|---|---|---|---|
| Eingabe | data_window_start |
Literal, Zeichenfolge | Startzeit des Datenfensters im ISO8601 Format | 2023-05-01T04:31:57.012Z |
| Eingabe | data_window_end |
Literal, Zeichenfolge | Endzeit des Datenfensters im ISO8601 Format | 2023-05-01T04:31:57.012Z |
| Eingabe | input_data |
uri_folder | Die gesammelten Produktionsferenzdaten, die als Azure Machine Learning-Datenressource registriert sind | azureml:myproduction_inference_data:1 |
| Ausgabe | preprocessed_data |
MLTable | Eine tabellarische Datenressource, die einer Teilmenge des Referenzdatenschemas entspricht |
Ein Beispiel für eine benutzerdefinierte Datenvorverarbeitungskomponente finden Sie unter custom_preprocessing im GitHub-Repository „azuremml-examples“.
Anweisungen zum Registrieren einer Azure Machine Learning-Komponente finden Sie unter Registrieren der Komponente in Ihrem Arbeitsbereich.
Nachdem Sie Die Produktionsdaten und die Vorverarbeitungskomponente registriert haben, können Sie die Modellüberwachung einrichten.
Erstellen Sie eine YAML-Überwachungsdefinitionsdatei, die dem folgenden ähnelt. Bevor Sie diese Definition verwenden, passen Sie die folgenden Einstellungen und alle anderen Einstellungen an die Anforderungen Ihrer Umgebung an:
- Verwenden Sie für
endpoint_deployment_ideinen Wert im Formatazureml:<endpoint-name>:<deployment-name>. - Verwenden Sie für
pre_processing_componenteinen Wert im Formatazureml:<component-name>:<component-version>. Geben Sie die genaue Version an, wie1.0.0, nicht1. - Verwenden Sie für jedes
path, einen Wert im Formatazureml:<data-asset-name>:<version>. - Verwenden Sie für den
target_columnWert den Namen der Ausgabespalte, die Werte enthält, die vom Modell vorhergesagt werden. - Listen Sie unter
emailsdie E-Mail-Adressen auf, die Sie für Benachrichtigungen verwenden möchten.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- Verwenden Sie für
Führen Sie den folgenden Befehl aus, um das Modell zu erstellen.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Einrichten der Modellüberwachung mit benutzerdefinierten Signalen und Metriken
Wenn Sie die Azure Machine Learning-Modellüberwachung verwenden, können Sie ein benutzerdefiniertes Signal definieren und eine beliebige Metrik Ihrer Wahl implementieren, um Ihr Modell zu überwachen. Sie können Ihr benutzerdefiniertes Signal als Azure Machine Learning-Komponente registrieren. Wenn ihr Modellüberwachungsauftrag im angegebenen Zeitplan ausgeführt wird, berechnet er die Metriken, die innerhalb Ihres benutzerdefinierten Signals definiert sind, genau wie für die Datenabweichung, Vorhersageabweichung und vordefinierte Datenqualitätssignale.
Um ein benutzerdefiniertes Signal für die Modellüberwachung einzurichten, müssen Sie zuerst das benutzerdefinierte Signal definieren und als Azure Machine Learning-Komponente registrieren. Die Azure Machine Learning-Komponente muss über die folgenden Eingabe- und Ausgabesignaturen verfügen.
Signatur der Komponenteneingabe
Der Komponenteneingabedatenframe sollte die folgenden Elemente enthalten:
- Eine
mltableStruktur, die die verarbeiteten Daten aus der Vorverarbeitungskomponente enthält. - Eine beliebige Anzahl von Literalen, die jeweils eine implementierte Metrik als Teil der benutzerdefinierten Signalkomponente darstellen. Wenn Sie beispielsweise die
std_deviationMetrik implementieren, benötigen Sie eine Eingabe fürstd_deviation_threshold. Im Allgemeinen sollte eine Eingabe mit dem Namen<metric-name>_thresholdpro Metrik vorhanden sein.
| Signaturname | type | Beschreibung | Beispielswert |
|---|---|---|---|
production_data |
MLTable | Eine tabellarische Datenressource, die einer Teilmenge des Referenzdatenschemas entspricht | |
std_deviation_threshold |
Literal, Zeichenfolge | Der entsprechende Schwellenwert für die implementierte Metrik | 2 |
Signatur der Komponentenausgabe
Der Komponentenausgabeport sollte die folgende Signatur aufweisen:
| Signaturname | type | Beschreibung |
|---|---|---|
signal_metrics |
MLTable | Die mltable-Struktur, die die berechneten Metriken enthält. Das Schema dieser Signatur finden Sie im nächsten Abschnitt signal_metrics Schemas. |
signal_metrics Schema
Der Datenrahmen für die Komponentenausgabe sollte vier Spalten enthalten: group, , metric_name, metric_valueund threshold_value.
| Signaturname | type | Beschreibung | Beispielswert |
|---|---|---|---|
group |
Literal, Zeichenfolge | Die logische Gruppierung der obersten Ebene, die auf die benutzerdefinierte Metrik angewendet werden soll | TRANSACTIONAMOUNT |
metric_name |
Literal, Zeichenfolge | Der Name der benutzerdefinierten Metrik | std_deviation |
metric_value |
Numerisch | Der Wert der benutzerdefinierten Metrik | 44.896,082 |
threshold_value |
Numerisch | Der Schwellenwert für die benutzerdefinierte Metrik | 2 |
Die folgende Tabelle zeigt die Beispielausgabe einer benutzerdefinierten Signalkomponente, die die std_deviation Metrik berechnet:
| Gruppe | Metrikwert | metric_name | Schwellenwert |
|---|---|---|---|
| Transaktionsbetrag | 44.896,082 | std_deviation | 2 |
| Ortszeit | 3,983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54.004,902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7,238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5,509 | std_deviation | 2 |
Ein Beispiel für eine Definition einer benutzerdefinierten Signalkomponente und eines metrischen Berechnungscodes finden Sie unter custom_signal im Azureml-Beispiel-Repository.
Anweisungen zum Registrieren einer Azure Machine Learning-Komponente finden Sie unter Registrieren der Komponente in Ihrem Arbeitsbereich.
Nachdem Sie Ihre benutzerdefinierte Signalkomponente in Azure Machine Learning erstellt und registriert haben, führen Sie die folgenden Schritte aus, um die Modellüberwachung einzurichten:
Erstellen Sie eine Überwachungsdefinition in einer YAML-Datei, die dem folgenden ähnelt. Bevor Sie diese Definition verwenden, passen Sie die folgenden Einstellungen und alle anderen Einstellungen an die Anforderungen Ihrer Umgebung an:
- Verwenden Sie für
component_ideinen Wert im Formatazureml:<custom-signal-name>:1.0.0. pathVerwenden Sie im Abschnitt "Eingabedaten" einen Wert im Formatazureml:<production-data-asset-name>:<version>.- Für
pre_processing_component:- Wenn Sie den Datensammler zum Sammeln Ihrer Daten verwenden, können Sie die
pre_processing_componentEigenschaft weglassen. - Wenn Sie den Datensammler nicht verwenden und eine Komponente zum Vorverarbeitung von Produktionsdaten verwenden möchten, verwenden Sie einen Wert im Format
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Wenn Sie den Datensammler zum Sammeln Ihrer Daten verwenden, können Sie die
- Listen Sie unter
emailsdie E-Mail-Adressen auf, die Sie für Benachrichtigungen verwenden möchten.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- Verwenden Sie für
Führen Sie den folgenden Befehl aus, um das Modell zu erstellen:
az ml schedule create -f ./custom-monitoring.yaml
Interpretieren von Überwachungsergebnissen
Nachdem Sie den Modellmonitor und die erste Ausführung konfiguriert haben, können Sie die Ergebnisse im Azure Machine Learning Studio anzeigen.
Wählen Sie im Studio unter "Verwalten" die Option "Überwachung" aus. Wählen Sie auf der Seite "Überwachung" den Namen Ihres Modellmonitors aus, um die Zugehörige Übersichtsseite anzuzeigen. Diese Seite zeigt das Überwachungsmodell, den Endpunkt und die Bereitstellung an. Außerdem werden detaillierte Informationen zu konfigurierten Signalen bereitgestellt. Die folgende Abbildung zeigt eine Überwachungsübersichtsseite, die Datenabweichungs- und Datenqualitätssignale enthält.
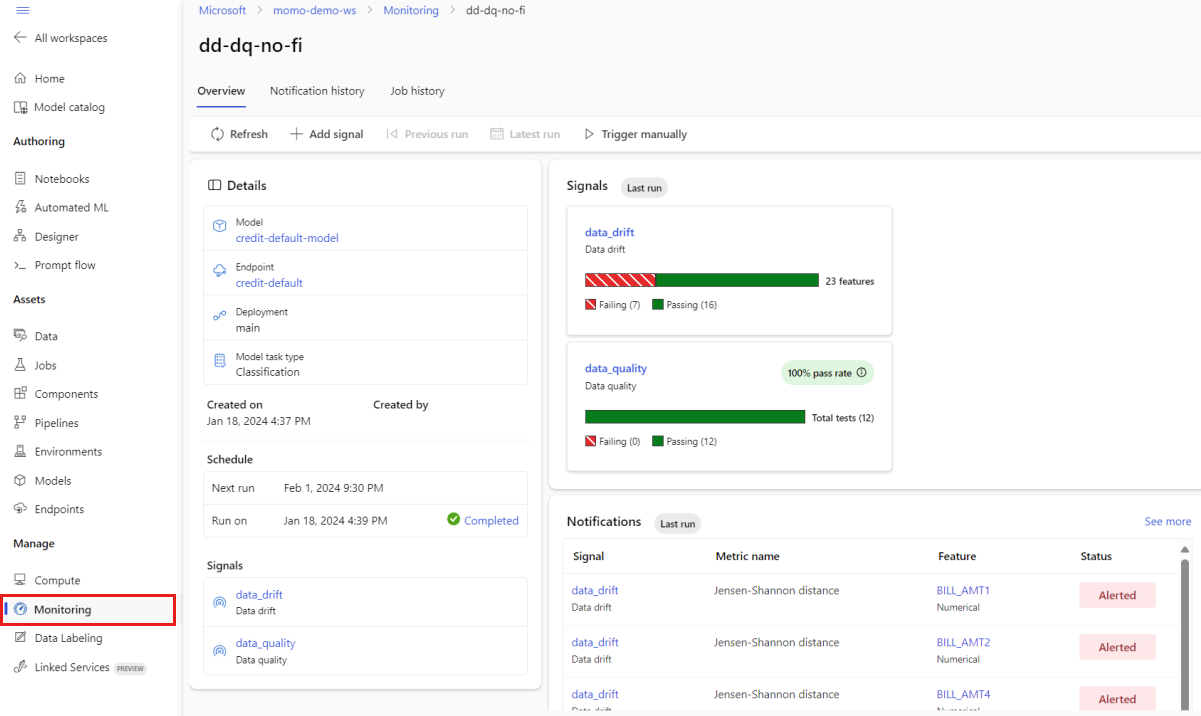
Suchen Sie im Abschnitt "Benachrichtigungen" der Übersichtsseite. In diesem Abschnitt sehen Sie das Feature für jedes Signal, das den konfigurierten Schwellenwert für die jeweilige Metrik verletzt.
Wählen Sie im Abschnitt "Signale " data_drift aus, um detaillierte Informationen zum Datenabweichungssignal anzuzeigen. Auf der Detailseite können Sie den Metrikwert der Datenabweichung für jedes numerische und kategorisierte Feature sehen, das ihre Überwachungskonfiguration enthält. Wenn Ihr Monitor mehrere Durchläufe aufweist, wird für jede Funktion eine Trendlinie angezeigt.
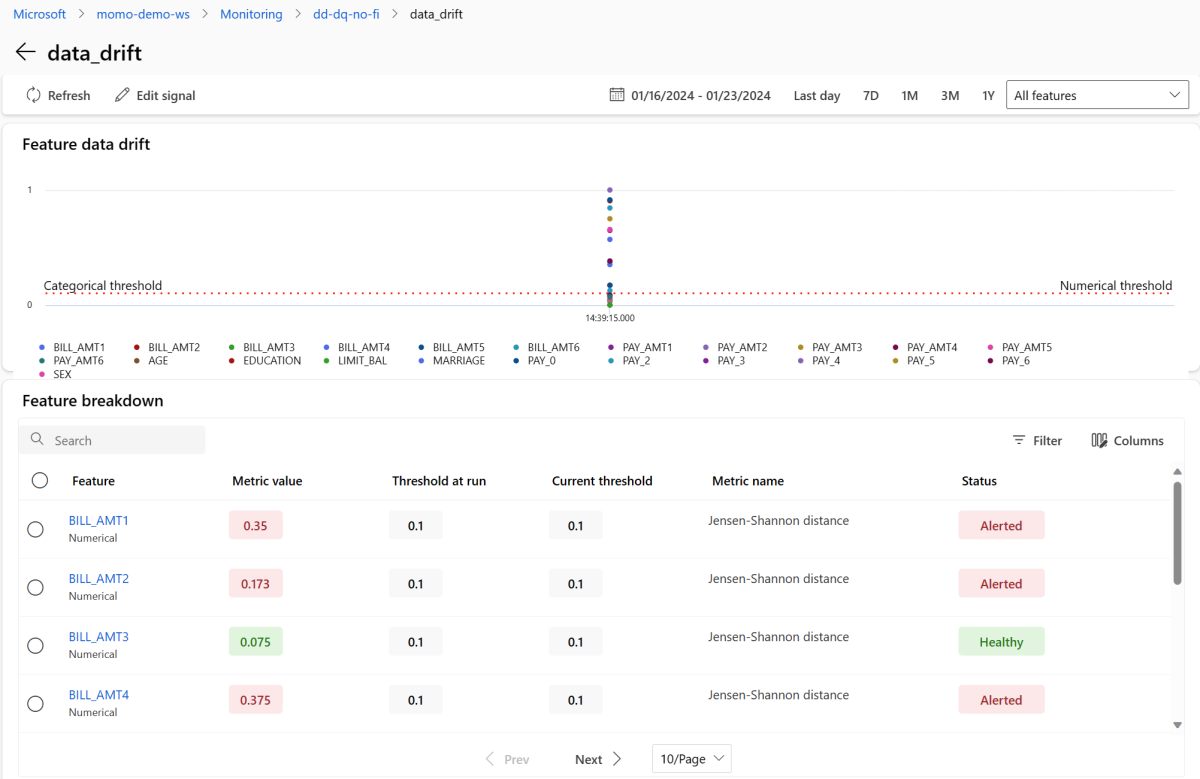
Wählen Sie auf der Detailseite den Namen eines einzelnen Features aus. Eine detaillierte Ansicht wird geöffnet, in der die Produktionsverteilung im Vergleich zur Referenzverteilung angezeigt wird. Sie können diese Ansicht auch verwenden, um den Drift im Laufe der Zeit für das Feature nachzuverfolgen.

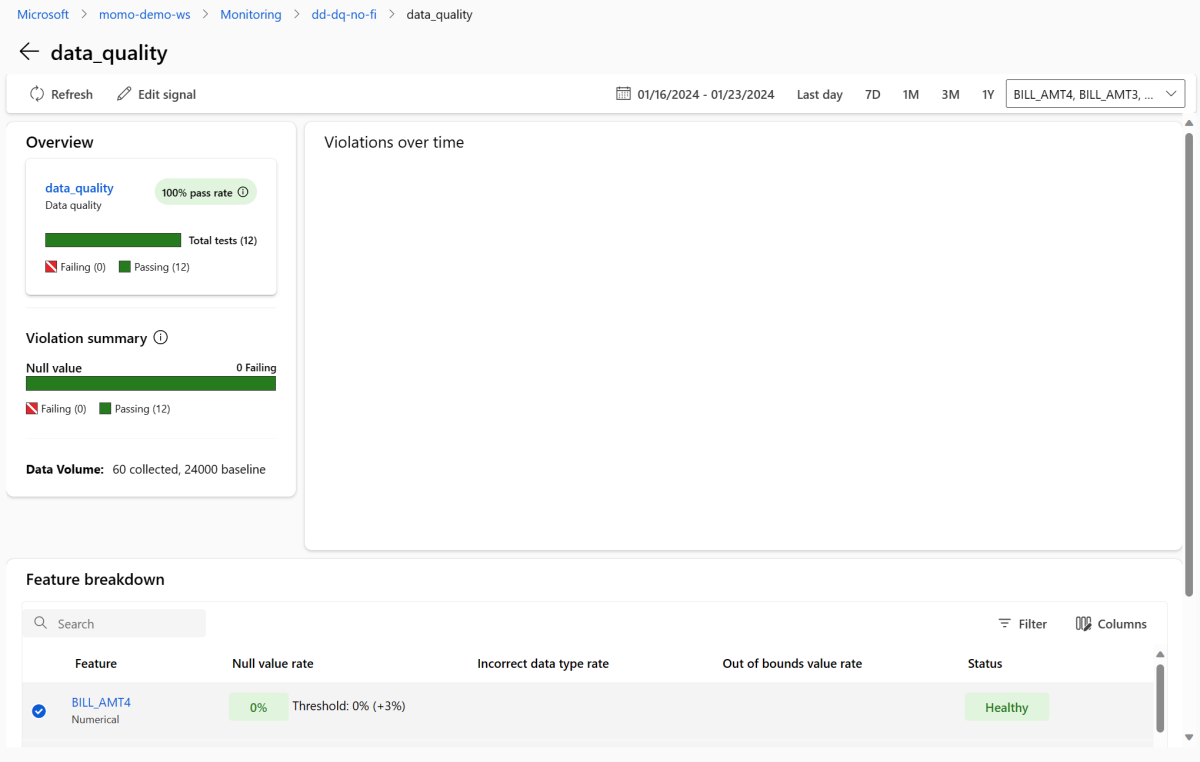
Kehren Sie zur Überwachungsübersichtsseite zurück. Wählen Sie im Abschnitt "Signale " data_quality aus, um detaillierte Informationen zu diesem Signal anzuzeigen. Auf dieser Seite können Sie die Nullwertsätze, Grenzwertüberschreitungsraten und Datentypfehlerraten für jedes Feature anzeigen, das Sie überwachen.




Modellüberwachung ist ein kontinuierlicher Prozess. Wenn Sie die Azure Machine Learning-Modellüberwachung verwenden, können Sie mehrere Überwachungssignale konfigurieren, um einen umfassenden Überblick über die Leistung Ihrer Modelle in der Produktion zu erhalten.
Integrieren der Azure Machine Learning-Modellüberwachung in das Ereignisraster
Wenn Sie Event Grid verwenden, können Sie Ereignisse konfigurieren, die von der Azure Machine Learning-Modellüberwachung generiert werden, um Anwendungen, Prozesse und CI/CD-Workflows auszulösen. Sie können Ereignisse über verschiedene Ereignishandler empfangen, beispielsweise mit Azure Event Hubs, Azure Functions und Azure Logic Apps. Wenn Ihre Monitore Abweichung erkennen, können Sie programmgesteuert Maßnahmen ergreifen, z. B. indem Sie eine Machine Learning-Pipeline ausführen, um ein Modell neu zu trainieren und erneut bereitzustellen.
Führen Sie die Schritte in den folgenden Abschnitten aus, um die Azure Machine Learning-Modellüberwachung in das Event Grid zu integrieren.
Erstellen eines Systemthemas
Wenn Sie nicht über ein Ereignisrastersystemthema verfügen, das für die Überwachung verwendet werden soll, erstellen Sie eins. Anweisungen finden Sie unter Erstellen, Anzeigen und Verwalten von Ereignisrastersystemthemen im Azure-Portal.
Erstellen eines Ereignisabonnements
Wechseln Sie im Azure-Portal zu Ihrem Azure Machine Learning-Arbeitsbereich.
Wählen Sie Ereignisse und dann Ereignis-Abonnement aus.
Geben Sie neben Name einen Namen für Ihr Ereignisabonnement ein, z. B. MonitoringEvent.
Wählen Sie unter Ereignistypen nur Ausführungsstatus geändert aus.
Warnung
Wählen Sie nur Geänderter Ausführungsstatus als Ereignistyp aus. Wählen Sie nicht Datasetdrift erkannt aus, da dies für Datendrift v1 gilt, nicht für die Azure Machine Learning-Modellüberwachung.
Wählen Sie die Registerkarte "Filter" aus . Wählen Sie unter "Erweiterte Filter" die Option " Neuen Filter hinzufügen" aus, und geben Sie dann die folgenden Werte ein:
- Geben Sie unter Schlüssel die Zeichenfolge data.RunTags.azureml_modelmonitor_threshold_breached ein.
- Wählen Sie unter Operator die Option Zeichenfolge enthält aus.
- Unter "Wert" ist die Eingabe aufgrund eines oder mehrerer Features fehlgeschlagen, die metrische Schwellenwerte verletzen.

Wenn Sie diesen Filter verwenden, werden Ereignisse generiert, wenn sich der Ausführungsstatus eines Monitors in Ihrem Azure Machine Learning-Arbeitsbereich ändert. Der Ausführungsstatus kann von „Abgeschlossen“ in „Fehlgeschlagen“ oder von „Fehlgeschlagen“ in „Abgeschlossen“ geändert werden.
Um auf Überwachungsebene zu filtern, wählen Sie erneut neuen Filter hinzufügen aus, und geben Sie dann die folgenden Werte ein:
- Geben Sie unter Schlüssel die Zeichenfolge data.RunTags.azureml_modelmonitor_threshold_breached ein.
- Wählen Sie unter Operator die Option Zeichenfolge enthält aus.
- Geben Sie unter "Wert" den Namen eines Monitorsignals ein, nach dem Sie Ereignisse filtern möchten, z. B. credit_card_fraud_monitor_data_drift. Der eingegebene Name muss mit dem Namen des Überwachungssignals übereinstimmen. Jedes Signal, das Sie beim Filtern verwenden, sollte einen Namen im Format
<monitor-name>_<signal-description>aufweisen, das den Monitornamen und eine Beschreibung des Signals enthält.
Wählen Sie die Registerkarte " Grundlagen " aus. Konfigurieren Sie den Endpunkt, den Sie als Ereignishandler verwenden möchten, z. B. Event Hubs.
Wählen Sie Erstellen aus, um das Ereignisabonnement zu erstellen.

Anzeigen von Ereignissen
Nachdem Sie Ereignisse erfasst haben, können Sie sie auf der Seite des Ereignishandlerendpunkts anzeigen:

Sie können Ereignisse auch auf der Registerkarte Metriken von Azure Monitor anzeigen:
