Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Azure KI-Suche ist über das Azure Portal, REST-APIs und Azure SDKs verfügbar. Es unterstützt auch Foundry IQ, die verwaltete Wissensschicht, die Unternehmensinhalte in wiederverwendbare, berechtigungsfähige Wissensbasen für Agenten im Microsoft Foundry-Portal transformiert.
Vektoren sind hochdimensionale Einbettungen, die Text, Bilder und andere Inhalte mathematisch darstellen. Azure KI-Suche speichert Vektoren auf Feldebene, sodass Vektor- und Nichtvektorinhalte innerhalb desselben Search-Indexes koexistieren können.
Ein Suchindex wird zu einem Vektorindex , wenn Sie Vektorfelder und eine Vektorkonfiguration definieren. Zum Auffüllen von Vektorfeldern können Sie precomputed embeddings in sie übertragen oder integrierte Vektorisierung verwenden, eine integrierte Azure KI-Suche-Funktion, die während der Indizierung Einbettungen generiert.
Zur Abfragezeit ermöglichen die Vektorfelder in Ihrem Index die Ähnlichkeitssuche, bei der das System Dokumente abruft, deren Vektoren der Vektorabfrage am ähnlichsten sind. Sie können die Vektorsuche nur für Ähnlichkeitsvergleiche oder hybride Suchvorgänge für eine Kombination aus Ähnlichkeit und Stichwortabgleich verwenden.
In diesem Artikel werden die wichtigsten Konzepte zum Erstellen und Verwalten eines Vektorindexes behandelt, darunter:
- Vektorabrufmuster
- Inhalt (Vektorfelder und Konfiguration)
- Physische Datenstruktur
- Grundlegende Vorgänge
Tipp
Möchten Sie sofort loslegen? Siehe Erstellen eines Vektorindexes.
Vektorabrufmuster
Azure KI-Suche unterstützt zwei Muster für den Vektorabruf:
Klassische Suche. Dieses Muster verwendet eine Suchleiste, Abfrageeingabe und gerenderte Ergebnisse. Während der Abfrageausführung vektorisiert die Suchmaschine oder der Anwendungscode die Benutzereingabe. Die Suchmaschine führt dann die Vektorsuche über die Vektorfelder in Ihrem Index aus und formuliert eine Antwort, die Sie in einer Client-App rendern.
In Azure KI-Suche werden Ergebnisse als flacher Zeilensatz zurückgegeben, und Sie können auswählen, welche Felder in die Antwort einbezogen werden sollen. Obwohl die Suchmaschine mit Vektoren übereinstimmt, sollte Ihr Index über nicht-vektorisierten, menschenlesbaren Inhalt verfügen, um die Suchergebnisse zu füllen. Die klassische Suche unterstützt sowohl Vektorabfragen als auch Hybridabfragen.
Generative Suche. Sprachmodelle verwenden Daten aus Azure KI-Suche, um auf Benutzerabfragen zu reagieren. Eine Orchestrierungsebene koordiniert in der Regel Eingabeaufforderungen und pflegt den Kontext, indem sie Suchergebnisse in Chatmodelle wie GPT einspeist. Dieses Muster basiert auf der Retrieval-Augmented Generation (RAG)-Architektur, bei der der Suchindex Basisdaten bereitstellt.
Schema eines Vektorindexes
Das Schema eines Vektorindex erfordert Folgendes:
- Name
- Schlüsselfeld (Zeichenfolge)
- Mindestens ein Vektorfeld
- Vektorkonfiguration
Nichtvectorfelder sind nicht erforderlich, es wird jedoch empfohlen, sie für Hybridabfragen oder für das Zurückgeben von Verbatim-Inhalten, die kein Sprachmodell durchlaufen, einzugeben. Weitere Informationen finden Sie unter Erstellen eines Vektorindex.
Ihr Indexschema sollte Ihr Vektorabrufmuster widerspiegeln. Dieser Abschnitt befasst sich hauptsächlich mit der Feldkomposition für die klassische Suche, bietet aber auch Schemaanleitungen für die generative Suche.
Grundlegende Vektorfeldkonfiguration
Vektorfelder weisen eindeutige Datentypen und Eigenschaften auf. So sieht ein Vektorfeld in einer Feldsammlung aus:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Nur bestimmte Datentypen werden für Vektorfelder unterstützt. Der am häufigsten verwendete Typ ist Collection(Edm.Single), aber die Verwendung schmaler Typen kann speichersparend sein.
Vektorfelder müssen durchsuchbar und abrufbar sein, können aber nicht gefiltert, facetable oder sortierbar sein. Sie können auch keine Analyse- oder Normalisierungsfunktionen oder Synonymzuordnungen haben.
Die dimensions Eigenschaft muss auf die Anzahl der Einbettungen festgelegt werden, die vom Einbettungsmodell generiert werden. Zum Beispiel werden 1.536 Einbettungen für jeden Textblock von „text-embedding-ada-002“ generiert.
Vektorfelder werden mithilfe von Algorithmen indiziert, die in einem Vektorsuchprofil angegeben sind, das an anderer Stelle im Index definiert und nicht in diesem Beispiel gezeigt wird. Weitere Informationen finden Sie unter Hinzufügen einer Vektorsuchkonfiguration.
Sammlung von Feldern für grundlegende Vektor-Workloads
Vektorindizes erfordern mehr als nur Vektorfelder. Beispielsweise müssen alle Indizes über ein Schlüsselfeld verfügen, das sich im folgenden Beispiel befindet id :
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Andere Felder, z. B. das content Feld, stellen die lesbare Entsprechung des content_vector Felds bereit. Wenn Sie Sprachmodelle ausschließlich für die Formulierung von Antworten verwenden, können Sie Nichtvektorinhaltsfelder weglassen, aber Lösungen, die Suchergebnisse direkt zu Client-Apps pushen, sollten Nichtvektorinhalte haben.
Metadatenfelder sind nützlich für Filter, insbesondere, wenn sie Ursprungsinformationen zum Quelldokument enthalten. Obwohl Sie nicht direkt nach einem Vektorfeld filtern können, können Sie prefilter-, postfilter- oder strict postfilter-Modi (Vorschau) festlegen, um vor oder nach der Vektorabfrageausführung zu filtern.
Vom Import-Assistenten generiertes Schema
Wir empfehlen den Assistenten für den Datenimport zur Evaluierung und für Proof-of-Concept-Tests. Der Assistent generiert das Beispielschema in diesem Abschnitt.
Der Assistent teilt Ihre Inhalte in kleinere Suchdokumente auf, was für RAG-Apps, die Sprachmodelle zur Formulierung von Antworten nutzen, von Vorteil ist. Chunking hilft Ihnen, innerhalb der Eingabegrenzen von Sprachmodellen und der Tokengrenzen des semantischen Rankers zu bleiben. Außerdem verbessert sie die Genauigkeit bei der Ähnlichkeitssuche, indem Abfragen mit Datenblöcken abgegleicht werden, die aus mehreren übergeordneten Dokumenten abgerufen werden. Weitere Informationen finden Sie unter Blockerstellung für große Dokumente für Vektorsuchlösungen.
Im folgenden Beispiel gibt es für jedes Suchdokument eine Block-ID, eine übergeordnete ID, einen Block, einen Titel und ein Vektorfeld. Der Assistent:
Füllt die Felder
chunk_idundparent_idmit base64-codierten BLOB-Metadaten (Pfad).Extrahiert das
chunk-Feld aus dem BLOB-Inhalt und dastitle-Feld aus dem blob-Namen.Erstellt das Feld
vectordurch Aufrufen eines Azure OpenAI-Einbettungsmodells, das Sie zum Vektorisieren des feldschunkbereitstellen. Nur das Vektorfeld wird während dieses Prozesses vollständig generiert.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schema für die generative Suche
Wenn Sie Vektorspeicher für RAG- und Chat-Stil-Apps entwerfen, können Sie zwei Indizes erstellen:
- Eine für statische Inhalte, die Sie indiziert und vektorisiert haben.
- Einen für Unterhaltungen, die in Eingabeaufforderungsflüssen verwendet werden können.
Für veranschauliche Zwecke verwendet dieser Abschnitt den chat-with-your-data-solution-accelerator, um die Indizes chat-index und conversations zu erstellen.
Die folgenden Felder von chat-index unterstützen generative Suchfunktionen:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Die folgenden Felder aus conversations unterstützen die Orchestrierung und den Chatverlauf:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
Der folgende Screenshot zeigt Suchergebnisse für conversations im Such-Explorer:
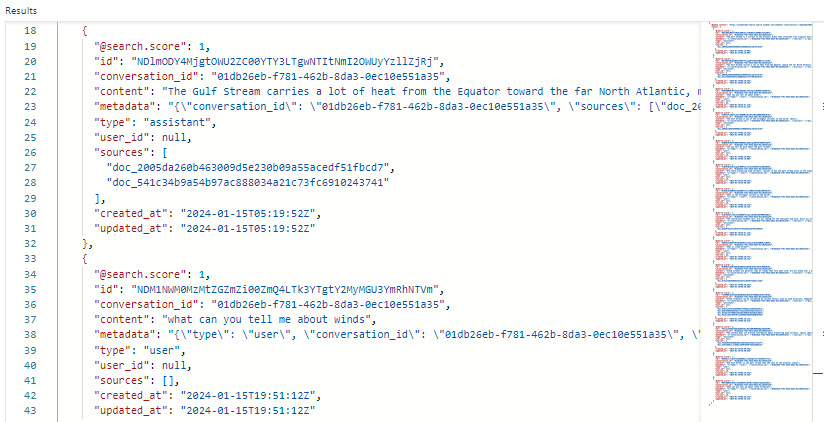
In unserem Beispiel ist die Suchbewertung 1,00, da die Suche nicht qualifiziert ist. Mehrere Felder unterstützen Orchestrierungs- und Eingabeaufforderungsflüsse:
-
conversation_ididentifiziert jede Chatsitzung. -
typegibt an, ob der Inhalt vom Benutzer oder vom Assistenten stammt. -
created_atundupdated_atentfernen Chats aus dem Verlauf.
Physische Struktur und Größe
In Azure KI-Suche ist die physische Struktur eines Indexes weitgehend eine interne Implementierung. Sie können auf das Schema zugreifen, seinen Inhalt laden und abfragen, seine Größe überwachen und seine Kapazität verwalten. Microsoft verwaltet jedoch die Infrastruktur und physischen Datenstrukturen, die mit Ihrem Suchdienst gespeichert sind.
Die Größe und der Stoff eines Indexes werden durch folgendes bestimmt:
Menge und Zusammensetzung Ihrer Dokumente.
Attribute für einzelne Felder. Für filterbare Felder ist beispielsweise mehr Speicherplatz erforderlich.
Indexkonfiguration, einschließlich der Vektorkonfiguration, die angibt, wie die internen Navigationsstrukturen erstellt werden. Sie können HNSW oder umfassende KNN für die Ähnlichkeitssuche auswählen.
Azure KI-Suche erzwingt Grenzwerte für den Vektorspeicher, wodurch ein ausgewogenes und stabiles System für alle Workloads erhalten bleibt. Um Ihnen zu helfen, unter den Grenzwerten zu bleiben, wird die Vektornutzung im Azure Portal und programmgesteuert über Dienst- und Indexstatistiken nachverfolgt und separat gemeldet.
Der folgende Screenshot zeigt einen S1-Dienst, der mit einer Partition und einem Replikat konfiguriert ist. Dieser Dienst verfügt über 24 kleine Indizes, jeweils mit einem Mittelwert eines Vektorfelds, das aus 1.536 Einbettungen besteht. Die zweite Kachel zeigt das Kontingent und die Nutzung der Vektorindizes an. Da es sich bei einem Vektorindex um eine interne Datenstruktur handelt, die für jedes Vektorfeld erstellt wird, ist der Speicher für Vektorindizes immer ein Bruchteil des vom Index verwendeten Gesamtspeichers. Nichtvectorfelder und andere Datenstrukturen verbrauchen den Rest.
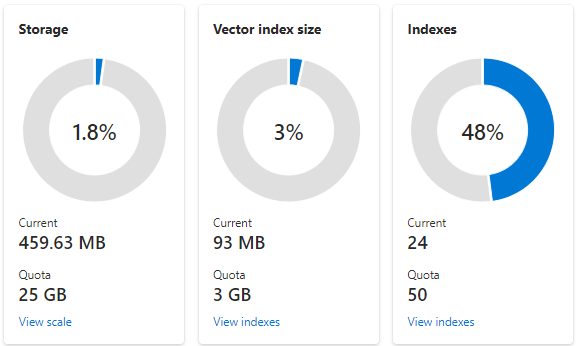
Vektorindexgrenzwerte und Schätzungen werden in einem anderen Artikel behandelt, aber zwei Punkte hervorzuheben sind, dass der maximale Speicher vom Erstellungsdatum und dem Preisniveau Ihres Suchdiensts abhängt. Neuere Dienste der gleichen Ebene weisen deutlich mehr Kapazität für Vektorindizes auf. Aus diesen Gründen sollten Sie:
Überprüfen Sie das Erstellungsdatum Ihres Suchdiensts. Wenn sie vor dem 3. April 2024 erstellt wurde, können Sie Ihren Dienst möglicherweise für eine höhere Kapazität aktualisieren.
Wählen Sie eine skalierbare Ebene aus, wenn Sie von Schwankungen der Anforderungen an den Vektorspeicher ausgehen. Bei älteren Suchdiensten ist die Stufe "Einfach" auf einer Partition festgelegt. Berücksichtigen Sie Standard 1 (S1) und höher, um mehr Flexibilität und schnellere Leistung zu erzielen. Sie können auch zwischen den Ebenen "Basic" und "Standard" (S1, S2 und S3) wechseln.
Grundlegende Vorgänge und Interaktionen
In diesem Abschnitt werden Vektorlaufzeitvorgänge eingeführt, einschließlich der Verbindung mit und dem Sichern eines einzelnen Indexes.
Hinweis
Es gibt keine Portal- oder API-Unterstützung für das Verschieben oder Kopieren eines Indexes. In der Regel verweisen Sie die Anwendungsbereitstellung auf einen anderen Suchdienst (unter Verwendung desselben Indexnamens) oder überarbeiten Sie den Namen, um eine Kopie in Ihrem aktuellen Suchdienst zu erstellen und dann zu entwickeln.
Indexisolierung
In Azure KI-Suche arbeiten Sie jeweils mit einem Index. Alle indexbezogenen Vorgänge zielen auf einen einzelnen Index ab. Es gibt kein Konzept für verwandte Indizes oder die Verknüpfung unabhängiger Indizes, weder für die Indizierung noch für die Abfrage.
Ständig verfügbar
Ein Index ist sofort für Abfragen verfügbar, sobald das erste Dokument indiziert wird, aber es ist erst dann vollständig funktionsfähig, wenn alle Dokumente indiziert werden. Intern wird ein Index über Partitionen verteilt und auf Replikaten ausgeführt. Der physische Index wird intern verwaltet. Sie verwalten den logischen Index.
Ein Index ist kontinuierlich verfügbar und kann nicht angehalten oder offline geschaltet werden. Da sie für den kontinuierlichen Betrieb konzipiert ist, erfolgen Aktualisierungen des Inhalts und Ergänzungen des Indexes selbst in Echtzeit. Wenn eine Anforderung mit einer Dokumentaktualisierung übereinstimmt, können Abfragen vorübergehend unvollständige Ergebnisse zurückgeben.
Die Abfragekontinuität ist für Dokumentvorgänge vorhanden, z. B. aktualisieren oder löschen, und für Änderungen, die sich nicht auf die vorhandene Struktur oder Integrität eines Indexes auswirken, z. B. das Hinzufügen neuer Felder. Strukturelle Aktualisierungen, z. B. das Ändern vorhandener Felder, werden in der Regel mithilfe eines Drop-and-Rebuild-Workflows in einer Entwicklungsumgebung oder durch Erstellen einer neuen Version des Indexes für den Produktionsdienst verwaltet.
Um eine Indexneuerstellung zu vermeiden, erstellen einige Kunden, die kleine Änderungen vornehmen, eine neue Version eines Feldes, die mit einer früheren Version koexistiert. Im Laufe der Zeit führt dies zu verwaisten Inhalten durch veraltete Felder und veraltete benutzerdefinierte Analysedefinitionen, insbesondere in einem Produktionsindex, der teuer zu replizieren ist. Sie können diese Probleme während geplanter Aktualisierungen des Indexes im Rahmen der Indexlebenszyklusverwaltung beheben.
Endpunktverbindung
Alle Indizierungs- und Abfrageanforderungen für Vektoren zielen auf einen Index ab. Endpunkte sind in der Regel einer der folgenden:
| Endpunkt | Verbindung und Zugangskontrolle |
|---|---|
<your-service>.search.windows.net/indexes |
Zielt auf die Sammlung der Indizes. Wird bei der Erstellung, Auflistung oder Löschung eines Index verwendet. Administratorrechte sind für diese Vorgänge erforderlich und stehen über Administrator-API-Schlüssel oder eine Rolle "Mitwirkender suchen" zur Verfügung. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Zielt auf die Dokumentensammlung eines einzelnen Indexes ab. Wird beim Abfragen eines Indexes oder einer Datenaktualisierung verwendet. Für Abfragen sind Leserechte ausreichend und über Abfrage-API-Schlüssel oder eine Datenleserrolle verfügbar. Für die Datenaktualisierung sind Administratorrechte erforderlich. |
So stellen Sie eine Verbindung mit Azure KI-Suche her
Stellen Sie sicher, dass Sie Berechtigungen haben oder über einen API-Zugriffsschlüssel verfügen. Es sei denn, Sie fragen einen vorhandenen Index ab, benötigen Sie Administratorrechte oder eine Zuweisung der Rolle Mitwirkender, um Inhalte in einem Suchdienst zu verwalten und anzuzeigen.
Starten Sie mit dem Azure-Portal. Die Person, die den Suchdienst erstellt hat, kann diesen anzeigen und verwalten, einschließlich der Gewährung von Zugriffsrechten auf der Seite Access Control (IAM).
Wechseln Sie zu anderen Clients für den programmgesteuerten Zugriff. Für erste Schritte empfehlen wir Quickstart: Vektorsuche mit REST und dem Repository azure-search-vector-samples.
Verwalten von Vektorspeichern
Azure stellt eine monitoring-Plattform bereit, die die Diagnoseprotokollierung und Warnung umfasst. Wir empfehlen Ihnen:
- Diagnoseprotokollierung aktivieren.
- Einrichten von Warnungen.
- Analysieren Sie die Abfrage- und Indexleistung.
Sicherer Zugriff auf Vektordaten
Azure KI-Suche implementiert Datenverschlüsselung, private Verbindungen für Szenarien ohne Internet und Rollenzuweisungen für den sicheren Zugriff über Microsoft Entra ID. Weitere Informationen zu Unternehmenssicherheitsfeatures finden Sie unter "Daten", "Datenschutz" und "Integrierte Schutzmaßnahmen".