Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
XML (Extensible Markup Language) ist ein textbasiertes Format für strukturierten Datenaustausch. In diesem Artikel wird beschrieben, wie Sie das XML-Format als Quelle in einer Kopieraktivitätspipeline in Data Factory in Microsoft Fabric konfigurieren.
Unterstützte Funktionen
Das XML-Format wird für die folgenden Aktivitäten und Verbindungen als Quelle unterstützt.
| Kategorie | Connector/Aktivität |
|---|---|
| Unterstützter Connector | Amazon S3 |
| Amazon S3-kompatibel | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Dateisystem | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse-Dateien | |
| Oracle Cloud Storage | |
| SFTP | |
| Unterstützte Aktivität | Kopieraktivität (Quelle/-) |
| Lookup-Aktivität | |
| GetMetadata-Aktivität | |
| Aktivität löschen |
XML-Format in Kopieraktivität
Um das XML-Format zu konfigurieren, wählen Sie Ihre Verbindung in der Quelle einer Pipelinekopieaktivität aus, und wählen Sie dann XML in der Dropdownliste des Dateiformats aus. Wählen Sie Einstellungen für die weitere Konfiguration dieses Formats aus.
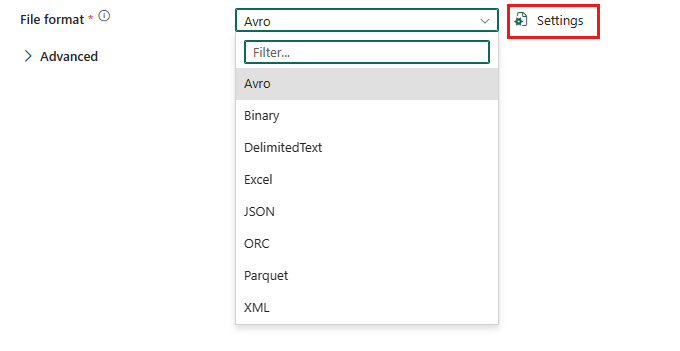
XML als Quelle
Nachdem Sie im Abschnitt Dateiformat die Option Einstellungen ausgewählt haben, werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
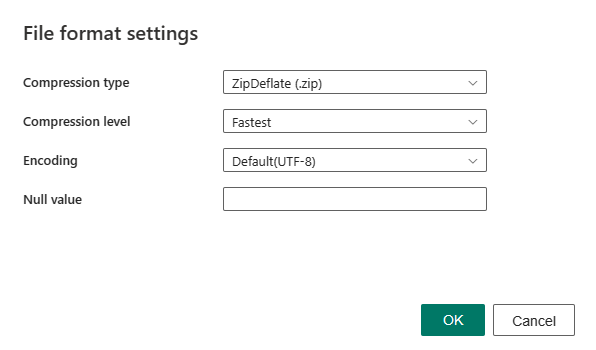
Komprimierungstyp: Der Komprimierungscodec, der zum Lesen von XML-Dateien verwendet wird. Sie können in der Dropdownliste zwischen den Typen Keiner, bzip2, gzip, deflate, ZipDeflate, TarGZip und tar auswählen.
Wenn Sie ZipDeflate als Komprimierungstyp auswählen, wird ZIP-Dateiname als Ordner beibehalten unter den Einstellungen Erweitert auf der Registerkarte Quelle angezeigt.
-
Namen der ZIP-Datei als Ordner beibehalten: Gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst entpackte Dateien in
<specified file path>/<folder named as source zip file>/. - Wenn dieses Kontrollkästchen deaktiviert ist, schreibt der Dienst entpackte Dateien direkt in
<specified file path>. Stellen Sie sicher, dass es in unterschiedlichen ZIP-Quelldateien keine doppelten Dateinamen gibt, um Wettlaufsituationen oder unerwartetes Verhalten zu vermeiden.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst entpackte Dateien in
Wenn Sie TarGZip/tar als Komprimierungstyp auswählen, wird Komprimierungsdateiname als Ordner beibehalten unter den Einstellungen Erweitert auf der Registerkarte Quelle angezeigt.
-
Namen der Komprimierungsdatei als Ordner beibehalten: Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst dekompromierte Dateien in
<specified file path>/<folder named as source compressed file>/. - Wenn dieses Kontrollkästchen deaktiviert ist, schreibt der Dienst dekompromierte Dateien direkt in
<specified file path>. Vergewissern Sie sich, dass keine doppelten Dateinamen in verschiedenen Quelldateien vorhanden sind, um Racebedingungen oder unerwartetes Verhalten zu vermeiden.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst dekompromierte Dateien in
-
Namen der ZIP-Datei als Ordner beibehalten: Gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
Komprimierungsgrad: Geben Sie das Komprimierungsverhältnis an, wenn Sie einen Komprimierungstyp auswählen. Außerdem können Sie zwischen Schnellste oder Optimal auswählen.
- Schnellstes: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist.
- Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt. Weitere Informationen finden Sie im Thema Komprimierungsstufe .
Codierung: Geben Sie den Codierungstyp an, der zum Lesen von Textdateien verwendet wird. Wählen Sie einen Typ aus der Dropdownliste aus. Der Standardwert ist UTF-8.
NULL-Wert: Gibt die Zeichenfolgendarstellung des NULL-Werts an. Der Standardwert ist eine leere Zeichenfolge.
Auf der Registerkarte Quelle werden in den Einstellungen unter Erweitert die folgenden Eigenschaften zum XML-Format angezeigt.
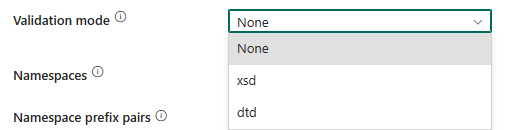
Validierungsmodus: Gibt an, ob das XML-Schema validiert werden soll. Wählen Sie einen Modus aus der Dropdownliste aus.
- Keine: Wählen Sie diese Option aus, um den Validierungsmodus nicht zu verwenden.
- xsd: Wählen Sie diese Option, um das XML-Schema mithilfe von XSD zu validieren.
- dtd: Wählen Sie diese Option, um das XML-Schema mithilfe von DTD zu validieren.
Namespaces: Geben Sie an, ob beim Auswerten der XML-Dateien der Namespace aktiviert werden soll. Standardmäßig ist diese Option aktiviert.
Namespace-Präfix-Paare: Wenn Namespaces aktiviert ist, wählen Sie + Neu aus, und geben Sie die URL und Präfix an. Sie können weitere Paare hinzufügen, indem Sie +Neuauswählen.
Namespace-URI für die Präfixzuordnung wird zum Benennen von Feldern beim Auswerten der XML-Datei verwendet. Wenn eine XML-Datei einen Namespace aufweist und der Namespace aktiviert ist, entspricht der Feldname standardmäßig dem im XML-Dokument. Wenn für den Namespace-URI in dieser Zuordnung ein Element definiert ist, lautet der Feldnameprefix:fieldName.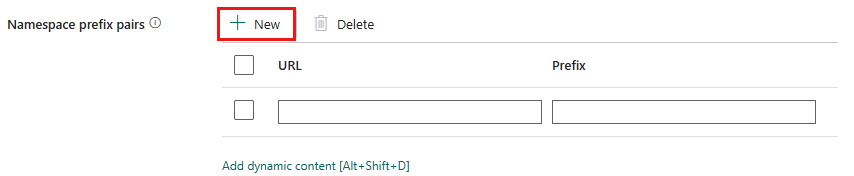
Datentyp erkennen: Geben Sie an, ob die Datentypen „integer“, „double“ und „boolesch“ erkannt werden sollen. Standardmäßig ist diese Option aktiviert.
Eigenschaften der XML-Kopieraktivität
XML als Quelle
Die folgenden Eigenschaften werden im Abschnitt Quelle der Copy-Aktivität unterstützt, wenn das XML-Format verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | XML | Ja | Typ (unter datasetSettings):Xml |
| Komprimierungstyp | Der Komprimierungscodec, der zum Lesen von XML-Dateien verwendet wird. |
None bzip2 gzip deflate ZipDeflate TarGZip tar |
Nein | Typ (unter compression):BZIP2 gzip deflate ZipDeflate TarGZip tar |
| Komprimierungsgrad | Das Komprimierungsverhältnis. |
Schnellste Optimal |
Nein | Ebene (unter compression):Schnellsten Optimal |
| Codieren | Der Codierungstyp, der zum Lesen von Textdateien verwendet wird. | UTF-8 (Standardwert), UTF-8 ohne BOM, UTF-16LE, UTF-16BE, UTF-32LE, UTF-32BE, US-ASCII, UTF-7, BIG5, EUC-JP, EUC-KR, GB2312, GB18030, JOHAB, SHIFT-JIS, CP875, CP866, IBM00858, IBM037, IBM273, IBM437, IBM500, IBM737, IBM775, IBM850, IBM852, IBM855, IBM857, IBM860, IBM861, IBM863, IBM864, IBM865, IBM869, IBM870, IBM01140, IBM01141, IBM01142, IBM01143, IBM01144, IBM01145, IBM01146, IBM01147, IBM01148, IBM01149, ISO-2022-JP, ISO-2022-KR, ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4, ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-13, ISO-8859-15, WINDOWS-874, WINDOWS-1250, WINDOWS-1251, WINDOWS-1252, WINDOWS-1253, WINDOWS-1254, WINDOWS-1255, WINDOWS-1256, WINDOWS-1257, WINDOWS-1258 | Nein | encodingName |
| Namen der ZIP-Datei als Ordner beibehalten | Gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. | Ausgewählt (Standardwert) oder nicht ausgewählt | Nein | preserveZipFileNameAsFolder (unter compressionProperties>type als ZipDeflateReadSettings):TRUE (Standardwert) oder FALSE |
| Namen der Komprimierungsdatei als Ordner beibehalten | Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. | Ausgewählt (Standardwert) oder nicht ausgewählt | Nein | bewahreKomprimierungsDateinameAlsOrdnerAuf (unter compressionProperties->type als TarGZipReadSettings oder TarReadSettings):TRUE (Standardwert) oder FALSE |
| NULL-Wert | Die Zeichenfolgendarstellung des NULL-Werts. |
<Ihr NULL-Wert> Leere Zeichenfolge (Standardwert) |
Nein | Nullwert |
| Validierungsmodus | Ob das XML-Schema validiert werden soll. |
None xsd dtd |
Nein | validationMode: xsd dtd |
| Namespaces | Ob der Namespace beim Auswerten der XML-Dateien aktiviert werden soll. | Ausgewählt (Standardwert) oder nicht ausgewählt | Nein | namespaces: TRUE (Standardwert) oder FALSE |
| Namespace-Präfix-Paare | Namespace-URI für die Präfixzuordnung, die zum Benennen von Feldern beim Auswerten der XML-Datei verwendet wird. Wenn eine XML-Datei einen Namespace aufweist und der Namespace aktiviert ist, entspricht der Feldname standardmäßig dem im XML-Dokument. Wenn für den Namespace-URI in dieser Zuordnung ein Element definiert ist, lautet der Feldname prefix:fieldName. |
< URL >:< Präfix > | Nein | namespacePrefixes: (Namensraum-Präfixe) < URL >:< Präfix > |
| Datentyp erkennen | Gibt an, ob die Datentypen „integer“, „double“ und „boolesch“ erkannt werden sollen. | Ausgewählt (Standardwert) oder nicht ausgewählt | Nein | detectDataType: TRUE (Standardwert) oder FALSE |