Textformat mit Trennzeichen in Azure Data Factory in Microsoft Fabric
In diesem Artikel wird erläutert, wie Sie das durch Trennzeichen getrennte Textformat in der Datenpipeline von Data Factory in Microsoft Fabric konfigurieren.
Das durch Trennzeichen getrennte Textformat wird für die folgenden Aktivitäten und Connectors als Quelle und Ziel unterstützt.
| Kategorie | Connector/Aktivität |
|---|---|
| Unterstützter Connector | Amazon S3 |
| Amazon S3 Compatible | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Dateisystem | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse-Dateien | |
| Oracle Cloud Storage | |
| SFTP | |
| Unterstützte Aktivität | Kopieraktivität (Quelle/Ziel) |
| Lookup-Aktivität | |
| GetMetadata-Aktivität | |
| Delete-Aktivität |
Um das Textformat mit Trennzeichen zu konfigurieren, wählen Sie ihre Verbindung in der Quelle oder dem Ziel der Copy-Aktivität der Datenpipeline aus, und wählen Sie dann in der Dropdownliste Dateiformat die Option DelimitedText aus. Wählen Sie Einstellungen für die weitere Konfiguration dieses Formats aus.
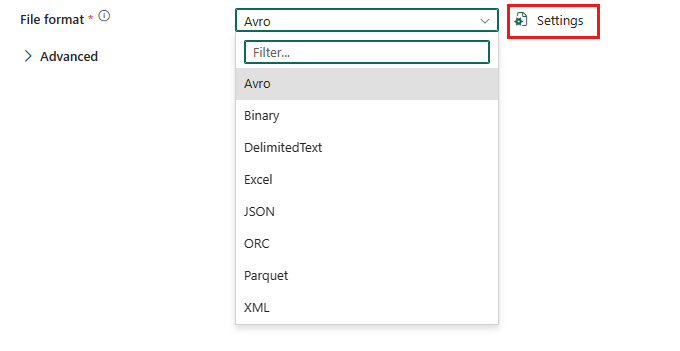
Nachdem Sie Einstellungen im Abschnitt Dateiformat ausgewählt haben, werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
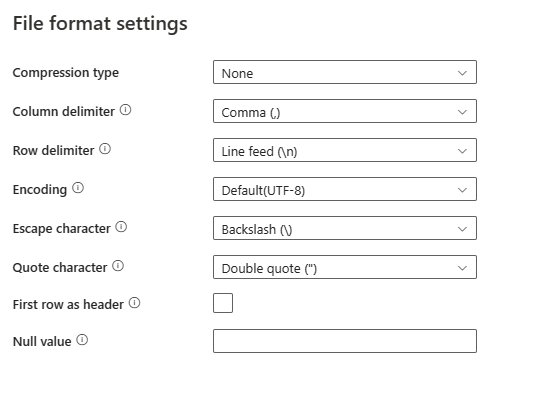
Komprimierungstyp: Der Komprimierungscodec, der zum Lesen von durch Trennzeichen getrennten Textdateien verwendet wird. Sie können in der Dropdownliste zwischen den Typen Keiner, bzip2, gzip, deflate, ZipDeflate, TarGzip und tar auswählen.
Wenn Sie ZipDeflate als Komprimierungstyp auswählen, wird Namen der ZIP-Datei als Ordner beibehalten unter den Einstellungen Erweitert auf der Registerkarte Quelle angezeigt.
- Namen der ZIP-Datei als Ordner beibehalten: Gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst entpackte Dateien in
<specified file path>/<folder named as source zip file>/. - Wenn dieses Kontrollkästchen deaktiviert ist, schreibt der Dienst entpackte Dateien direkt in
<specified file path>. Stellen Sie sicher, dass es in unterschiedlichen ZIP-Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst entpackte Dateien in
Wenn Sie TarGzip/tar als Komprimierungstyp auswählen, wird Namen der Komprimierungsdatei als Ordner beibehalten unter den Einstellungen Erweitert auf der Registerkarte Quelle angezeigt.
- Namen der Komprimierungsdatei als Ordner beibehalten: Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst dekompromierte Dateien in
<specified file path>/<folder named as source compressed file>/. - Wenn dieses Kontrollkästchen deaktiviert ist, schreibt der Dienst dekompromierte Dateien direkt in
<specified file path>. Stellen Sie sicher, dass es in unterschiedlichen ZIP-Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden.
- Wenn dieses Kontrollkästchen aktiviert ist (Standardeinstellung), schreibt der Dienst dekompromierte Dateien in
- Namen der ZIP-Datei als Ordner beibehalten: Gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll.
Komprimierungsgrad: Geben Sie das Komprimierungsverhältnis an, wenn Sie einen Komprimierungstyp auswählen. Sie können zwischen Optimal oder Schnellster wählen.
- Schnellstes: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist.
- Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt. Weitere Informationen finden Sie im Thema Komprimierungsstufe .
Spaltentrennzeichen: Das bzw. die Zeichen zum Trennen von Spalten in einer Datei. Der Standardwert ist das Komma (
,).Zeilentrennzeichen: Geben Sie das Zeichen an, das zum Trennen von Zeilen in einer Datei verwendet wird. Es ist nur ein Zeichen zulässig. Der Standardwert ist der Zeilenvorschub
\n.Codierung: Der zum Lesen/Schreiben von Testdateien verwendete Codierungstyp. Der Standardwert ist UTF-8.
Escapezeichen: Das einzelne Zeichen zum Escapen von Anführungszeichen innerhalb eines mit Anführungszeichen versehenen Werts. Der Standardwert ist ein umgekehrter Schrägstrich
\. Wenn das Escapezeichen als leere Zeichenfolge definiert wird, muss auch das Anführungszeichen als leere Zeichenfolge festgelegt werden. In diesem Fall ist darauf zu achten, dass die Spaltenwerte keine Trennzeichen enthalten.Anführungszeichen: Das einzelne Zeichen, um Spaltenwerte mit Anführungszeichen zu versehen, wenn sie ein Spaltentrennzeichen enthalten. Der Standardwert ist ein doppeltes Anführungszeichen
". Wenn Anführungszeichen als leere Zeichenfolge definiert ist, bedeutet dies, dass es kein Anführungszeichen gibt und der Spaltenwert nicht in Anführungszeichen eingeschlossen wird. Außerdem wird das Escapezeichen verwendet, um das Spaltentrennzeichen und sich selbst mit Escapezeichen zu versehen.Erste Zeile als Kopfzeile: Gibt an, ob die erste Zeile als Kopfzeile mit Spaltennamen behandelt bzw. zu dieser erklärt werden soll. Zulässige Werte sind „Aktiviert“ und „Deaktiviert“ (Standardeinstellung). Wenn die erste Zeile als Kopfzeile deaktiviert ist, generieren die UI-Datenvorschau und die Ausgabe der Lookupaktivität die Spaltennamen automatisch als Prop_{n} (beginnend mit 0), während die Copy-Aktivität eine explizite Zuordnung von der Quelle zum Ziel erfordert und die Spalten nach Ordnungszahlen (beginnend mit 1) ermittelt.
NULL-Wert: Gibt die Zeichenfolgendarstellung von des NULL-Werts an. Der Standardwert ist eine leere Zeichenfolge.
Unter den Einstellungen Erweitert auf der Registerkarte Quelle werden weitere durch Trennzeichen getrennte Textformateigenschaften angezeigt.
Nachdem Sie Einstellungen im Abschnitt Dateiformat ausgewählt haben, werden die folgenden Eigenschaften im Popupdialogfeld Dateiformateinstellungen angezeigt.
Komprimierungstyp: Der Komprimierungscodec, der zum Schreiben von durch Trennzeichen getrennten Textdateien verwendet wird. Sie können in der Dropdownliste zwischen den Typen Keiner, bzip2, gzip, deflate, ZipDeflate, TarGzip und tar auswählen.
Komprimierungsgrad: Geben Sie das Komprimierungsverhältnis an, wenn Sie einen Komprimierungstyp auswählen. Sie können zwischen Optimal oder Schnellster wählen.
- Schnellstes: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist.
- Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt. Weitere Informationen finden Sie im Thema Komprimierungsstufe .
Spaltentrennzeichen: Das bzw. die Zeichen zum Trennen von Spalten in einer Datei. Der Standardwert ist das Komma (
,).Zeilentrennzeichen: Das Zeichen, das zum Trennen von Zeilen in einer Datei verwendet wird. Es ist nur ein Zeichen zulässig. Der Standardwert ist der Zeilenvorschub
\n.Codierung: Der zum Schreiben von Testdateien verwendete Codierungstyp. Der Standardwert ist UTF-8.
Escapezeichen: Das einzelne Zeichen zum Escapen von Anführungszeichen innerhalb eines mit Anführungszeichen versehenen Werts. Der Standardwert ist ein umgekehrter Schrägstrich
\. Wenn das Escapezeichen als leere Zeichenfolge definiert wird, muss auch das Anführungszeichen als leere Zeichenfolge festgelegt werden. In diesem Fall ist darauf zu achten, dass die Spaltenwerte keine Trennzeichen enthalten.Anführungszeichen: Das einzelne Zeichen, um Spaltenwerte mit Anführungszeichen zu versehen, wenn sie ein Spaltentrennzeichen enthalten. Der Standardwert ist ein doppeltes Anführungszeichen
". Wenn Anführungszeichen als leere Zeichenfolge definiert ist, bedeutet dies, dass es kein Anführungszeichen gibt und der Spaltenwert nicht in Anführungszeichen eingeschlossen wird. Außerdem wird das Escapezeichen verwendet, um das Spaltentrennzeichen und sich selbst mit Escapezeichen zu versehen.Erste Zeile als Kopfzeile: Gibt an, ob die erste Zeile als Kopfzeile mit Spaltennamen behandelt bzw. zu dieser erklärt werden soll. Zulässige Werte sind „Aktiviert“ und „Deaktiviert“ (Standardeinstellung). Wenn die erste Zeile als Kopfzeile deaktiviert ist, generieren die UI-Datenvorschau und die Ausgabe der Lookupaktivität die Spaltennamen automatisch als Prop_{n} (beginnend mit 0), während die Copy-Aktivität eine explizite Zuordnung von der Quelle zum Ziel erfordert und die Spalten nach Ordnungszahlen (beginnend mit 1) ermittelt.
NULL-Wert: Gibt die Zeichenfolgendarstellung von des NULL-Werts an. Der Standardwert ist eine leere Zeichenfolge.
Unter den Einstellungen Erweitert auf der Registerkarte Ziel werden weitere durch Trennzeichen getrennte Textformateigenschaften angezeigt.
Anführungszeichen: Schließen Sie alle Werte in Anführungszeichen ein.
Dateierweiterung: Die Dateierweiterung, mit der die Ausgabedateien benannt werden, z. B.
.csvoder.txt.Max. Anzahl Zeilen pro Datei: Wenn Sie Daten in einen Ordner schreiben, können Sie wahlweise in mehrere Dateien schreiben und die maximale Anzahl von Zeilen pro Datei angeben.
Dateinamenpräfix: Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt:
<fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft gilt nicht, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist.
Die folgenden Eigenschaften werden im Abschnitt Quelle der Copy-Aktivität unterstützt, wenn das Textformat mit Trennzeichen verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | DelimitedText | Ja | Typ (unter datasetSettings):DelimitedText |
| Komprimierungstyp | Der zum Lesen von Textdateien mit Trennzeichen verwendete Komprimierungscodec. | Dabei können Sie wählen zwischen: None bzip2 gzip deflate ZipDeflate TarGzip tar |
Nein | Typ (unter compression):BZIP2 gzip deflate ZipDeflate TarGzip tar |
| Namen der ZIP-Datei als Ordner beibehalten | Sie gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. Gilt, wenn Sie ZipDeflate-Komprimierung auswählen. | Aktiviert oder deaktiviert | Ohne | preserveZipFileNameAsFolder (unter compressionProperties->type als ZipDeflateReadSettings) |
| Namen der Komprimierungsdatei als Ordner beibehalten | Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. Gilt, wenn Sie TarGzip/tar-Komprimierung auswählen. | Aktiviert oder deaktiviert | Nein | preserveCompressionFileNameAsFolder (unter compressionProperties->type als TarGZipReadSettings oder TarReadSettings) |
| Komprimierungsgrad | Das Komprimierungsverhältnis. Zulässige Werte sind Optimal oder Sehr schnell. | Optimal oder Schnellster | Ohne | Grad (unter compression):Fastest Optimal |
| Spaltentrennzeichen | Das Zeichen, das in einer Datei zum Trennen von Spalten verwendet wird. | < das ausgewählte Spaltentrennzeichen > Komma , (Standardwert) |
Nein | columnDelimiter |
| Zeilentrennzeichen | Das Zeichen, das zum Trennen von Zeilen in einer Datei verwendet wird. | < das ausgewählte Zeilentrennzeichen > \r,\n (Standardwert) oder r\n |
Ohne | rowDelimiter |
| Codieren | Der zu Lesen/Schreiben von Testdateien verwendete Codierungstyp. | "UTF-8" (Standardwert),"UTF-8 ohne BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Ohne | encodingName |
| Escapezeichen | Das einzelne Zeichen zum Escapen von Anführungszeichen innerhalb eines mit Anführungszeichen versehenen Wertes. Wenn das Escapezeichen als leere Zeichenfolge definiert wird, muss auch das Anführungszeichen als leere Zeichenfolge festgelegt werden. In diesem Fall ist darauf zu achten, dass die Spaltenwerte keine Trennzeichen enthalten. | < Ihr ausgewähltes Escapezeichen > Umgekehrter Schrägstrich \ (Standardwert) |
Nein | escapeChar |
| Anführungszeichen | Das einzelne Zeichen, um Spaltenwerte mit Anführungszeichen zu versehen, wenn es ein Spaltentrennzeichen enthält. Wenn Anführungszeichen als leere Zeichenfolge definiert ist, bedeutet dies, dass es kein Anführungszeichen gibt und der Spaltenwert nicht in Anführungszeichen eingeschlossen wird. Außerdem wird das Escapezeichen verwendet, um das Spaltentrennzeichen und sich selbst mit Escapezeichen zu versehen. | < Ihr ausgewähltes Anführungszeichen > Doppelte Anführungszeichen " (Standardwert) |
Nein | quoteChar |
| Erste Zeile als Kopfzeile | Gibt an, ob die erste Zeile des jeweiligen Arbeitsblatts bzw. Bereichs als Headerzeile mit den Namen der Spalten behandelt werden soll. | Aktiviert oder deaktiviert | Nein | firstRowAsHeader: TRUE oder FALSE (Standardwert) |
| NULL-Wert | Gibt eine Zeichenfolgendarstellung von Null-Werten an. Der Standardwert ist eine leere Zeichenfolge. | < Die Zeichenfolgendarstellung des NULL-Werts > Leere Zeichenfolge (Standardwert) |
Nein | nullValue |
Die folgenden Eigenschaften werden im Abschnitt Ziel der Copy-Aktivität unterstützt, wenn das Textformat mit Trennzeichen verwendet wird.
| Name | Beschreibung | Wert | Erforderlich | JSON-Skripteigenschaft |
|---|---|---|---|---|
| Dateiformat | Das Dateiformat aus, das Sie verwenden möchten. | DelimitedText | Ja | Typ (unter datasetSettings):DelimitedText |
| Komprimierungstyp | Der zum Schreiben von Textdateien mit Trennzeichen verwendete Komprimierungscodec. | Dabei können Sie wählen zwischen: None bzip2 gzip deflate ZipDeflate TarGzip tar |
Nein | Typ (unter compression):BZIP2 gzip deflate ZipDeflate TarGzip tar |
| Namen der ZIP-Datei als Ordner beibehalten | Sie gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. | Aktiviert oder deaktiviert | Ohne | preserveZipFileNameAsFolder (unter compressionProperties->type als ZipDeflateReadSettings) |
| Namen der Komprimierungsdatei als Ordner beibehalten | Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. | Aktiviert oder deaktiviert | Nein | preserveCompressionFileNameAsFolder (unter compressionProperties->type als TarGZipReadSettings oder TarReadSettings) |
| Komprimierungsgrad | Das Komprimierungsverhältnis. Zulässige Werte sind Optimal oder Sehr schnell. | Optimal oder Schnellster | Ohne | Grad (unter compression):Fastest Optimal |
| Spaltentrennzeichen | Das Zeichen, das in einer Datei zum Trennen von Spalten verwendet wird. | < das ausgewählte Spaltentrennzeichen > Komma , (Standardwert) |
Nein | columnDelimiter |
| Zeilentrennzeichen | Das Zeichen, das zum Trennen von Zeilen in einer Datei verwendet wird. | < das ausgewählte Zeilentrennzeichen > \r,\n (Standardwert) oder r\n |
Ohne | rowDelimiter |
| Codieren | Der zu Lesen/Schreiben von Testdateien verwendete Codierungstyp. | "UTF-8" (Standardwert),"UTF-8 ohne BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Ohne | encodingName |
| Escapezeichen | Das einzelne Zeichen zum Escapen von Anführungszeichen innerhalb eines mit Anführungszeichen versehenen Wertes. Wenn das Escapezeichen als leere Zeichenfolge definiert wird, muss auch das Anführungszeichen als leere Zeichenfolge festgelegt werden. In diesem Fall ist darauf zu achten, dass die Spaltenwerte keine Trennzeichen enthalten. | < Ihr ausgewähltes Escapezeichen > Umgekehrter Schrägstrich \ (Standardwert) |
Nein | escapeChar |
| Anführungszeichen | Das einzelne Zeichen, um Spaltenwerte mit Anführungszeichen zu versehen, wenn es ein Spaltentrennzeichen enthält. Wenn Anführungszeichen als leere Zeichenfolge definiert ist, bedeutet dies, dass es kein Anführungszeichen gibt und der Spaltenwert nicht in Anführungszeichen eingeschlossen wird. Außerdem wird das Escapezeichen verwendet, um das Spaltentrennzeichen und sich selbst mit Escapezeichen zu versehen. | < Ihr ausgewähltes Anführungszeichen > Doppelte Anführungszeichen " (Standardwert) |
Nein | quoteChar |
| Erste Zeile als Kopfzeile | Gibt an, ob die erste Zeile des jeweiligen Arbeitsblatts bzw. Bereichs als Headerzeile mit den Namen der Spalten behandelt werden soll. | Aktiviert oder deaktiviert | Nein | firstRowAsHeader: TRUE oder FALSE (Standardwert) |
| Anführungszeichen für gesamten Text | Gibt an, das alle Werte in Anführungszeichen eingeschlossen werden. | Aktiviert (Standardwert) oder deaktiviert | Nein | quoteAllText: TRUE (Standardwert) oder FALSE |
| Dateierweiterung | Die Dateierweiterung, mit der die Ausgabedateien benannt werden. | < Ihre Dateierweiterung > .txt (Standardwert) |
Nein | fileExtension |
| Maximale Anzahl Zeilen pro Datei | Wenn Sie Daten in einen Ordner schreiben, können Sie in mehrere Dateien zu schreiben und die maximale Anzahl von Zeilen pro Datei angeben. | <Ihre maximale Anzahl Zeilen pro Datei > | Nein | maxRowsPerFile |
| Dateinamenpräfix | Wird angewendet, wenn Max. Anzahl Zeilen pro Datei konfiguriert ist. Geben Sie das Dateinamenpräfix beim Schreiben von Daten in mehrere Dateien an, das zu diesem Muster führt: <fileNamePrefix>_00000.<fileExtension>. Wenn keine Angabe erfolgt, wird das Dateinamenpräfix automatisch generiert. Diese Eigenschaft gilt nicht, wenn die Quelle ein dateibasierter Speicher oder ein Datenspeicher mit aktivierter Partitionsoption ist. |
< Ihr Dateinamenpräfix > | Nein | fileNamePrefix |