Synchronisierung mit mehreren Modulen
Die meisten modernen GPUs enthalten mehrere unabhängige Engines, die spezielle Funktionen bereitstellen. Viele verfügen über eine oder mehrere dedizierte Kopier-Engines und eine Compute-Engine, die sich in der Regel von der 3D-Engine unterscheidet. Jede dieser Engines kann Befehle parallel ausführen. Direct3D 12 bietet einen differenzierten Zugriff auf die 3D-, Compute- und Kopier-Engines mithilfe von Warteschlangen und Befehlslisten.
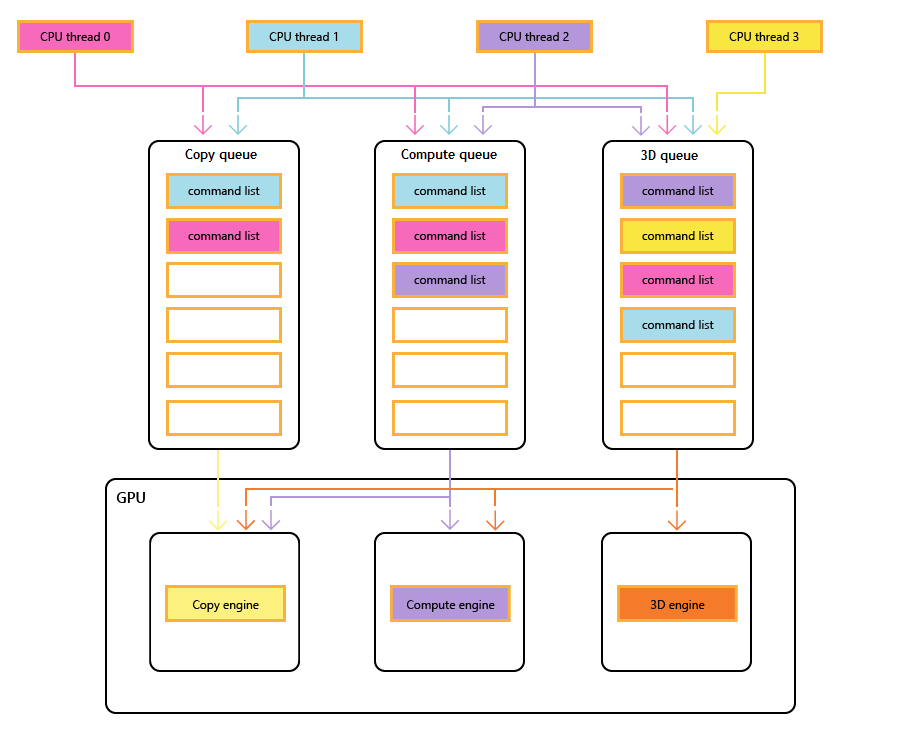
GPU-Engines
Das folgende Diagramm zeigt die CPU-Threads eines Titels, die jeweils eine oder mehrere der Kopier-, Compute- und 3D-Warteschlangen auffüllen. Die 3D-Warteschlange kann alle drei GPU-Engines antreiben. Die Computewarteschlange kann die Compute- und Kopier-Engines steuern. und die Kopierwarteschlange einfach die Kopier-Engine.
Da die verschiedenen Threads die Warteschlangen auffüllen, kann keine einfache Garantie für die Ausführungsreihenfolge gegeben werden, weshalb Synchronisierungsmechanismen erforderlich sind – wenn der Titel sie erfordert.
Die folgende Abbildung veranschaulicht, wie ein Titel die Arbeit über mehrere GPU-Engines hinweg planen kann, einschließlich der engineübergreifenden Synchronisierung, falls erforderlich: Es zeigt die Einzelnen-Engine-Workloads mit engineübergreifenden Abhängigkeiten. In diesem Beispiel kopiert die Kopier-Engine zuerst einige Geometrien, die für das Rendern erforderlich sind. Die 3D-Engine wartet auf den Abschluss dieser Kopien und rendert einen Vorabdurchlauf über die Geometrie. Diese wird dann von der Compute-Engine genutzt. Die Ergebnisse der Dispatch-Engine der Compute-Engine werden zusammen mit mehreren Texturkopievorgängen auf der Kopier-Engine von der 3D-Engine für den abschließenden Draw-Aufruf verwendet.
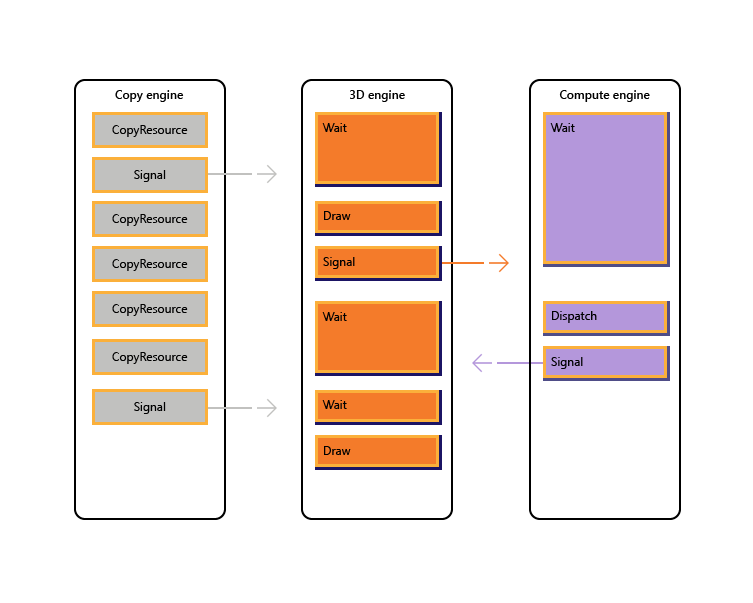
Der folgende Pseudocode veranschaulicht, wie ein Titel eine solche Workload übermitteln kann.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Der folgende Pseudocode veranschaulicht die Synchronisierung zwischen den Kopier- und 3D-Engines, um eine heapähnliche Speicherbelegung über einen Ringpuffer zu erreichen. Titel haben die Flexibilität, das richtige Gleichgewicht zwischen der Maximierung der Parallelität (über einen großen Puffer) und der Verringerung des Arbeitsspeicherverbrauchs und der Latenz (über einen kleinen Puffer) zu wählen.
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Szenarien mit mehreren Engines
Mit Direct3D 12 können Sie vermeiden, dass versehentlich aufgrund unerwarteter Synchronisierungsverzögerungen in Ineffizienzen geraten. Außerdem können Sie die Synchronisierung auf einer höheren Ebene einführen, auf der die erforderliche Synchronisierung mit größerer Sicherheit bestimmt werden kann. Ein zweites Problem, das mit mehreren Engines behoben wird, besteht darin, teure Vorgänge expliziter zu machen, einschließlich Übergängen zwischen 3D und Video, die aufgrund der Synchronisierung zwischen mehreren Kernelkontexten üblicherweise teuer waren.
Insbesondere die folgenden Szenarien können mit Direct3D 12 behandelt werden.
- Asynchrone GPU-Arbeit mit niedriger Priorität. Dies ermöglicht die gleichzeitige Ausführung von GPU-Arbeitsvorgängen mit niedriger Priorität und atomaren Vorgängen, die es einem GPU-Thread ermöglichen, die Ergebnisse eines anderen nicht synchronisierten Threads ohne Blockierung zu nutzen.
- Computearbeit mit hoher Priorität. Mit der Hintergrundcompute ist es möglich, das 3D-Rendering zu unterbrechen, um eine kleine Menge an Computearbeit mit hoher Priorität zu erledigen. Die Ergebnisse dieser Arbeit können frühzeitig für die zusätzliche Verarbeitung der CPU abgerufen werden.
- Computearbeit im Hintergrund. Eine separate Warteschlange mit niedriger Priorität für Computeworkloads ermöglicht es einer Anwendung, freie GPU-Zyklen zu verwenden, um Hintergrundberechnungen ohne negative Auswirkungen auf die primären Renderingaufgaben (oder andere) durchzuführen. Hintergrundaufgaben können die Dekomprimierung von Ressourcen oder das Aktualisieren von Simulationen oder Beschleunigungsstrukturen umfassen. Hintergrundaufgaben sollten selten (etwa einmal pro Frame) auf der CPU synchronisiert werden, um zu verhindern, dass die Arbeit im Vordergrund verzögert oder verlangsamt wird.
- Streaming und Hochladen von Daten. Eine separate Kopierwarteschlange ersetzt die D3D11-Konzepte der anfänglichen Daten und der Aktualisierung von Ressourcen. Obwohl die Anwendung für weitere Details im Direct3D 12-Modell verantwortlich ist, kommt diese Verantwortung mit Energie ein. Die Anwendung kann steuern, wie viel Systemarbeitsspeicher für das Puffern von Uploaddaten aufgewendet wird. Die App kann auswählen, wann und wie (CPU im Vergleich zu GPU, blockierend oder nicht blockierend) synchronisiert werden soll, und kann den Fortschritt nachverfolgen und den Umfang der Arbeit in der Warteschlange steuern.
- Erhöhte Parallelität. Anwendungen können tiefere Warteschlangen für Hintergrundworkloads (z. B. Videodecodierung) verwenden, wenn sie über separate Warteschlangen für Vordergrundarbeit verfügen.
In Direct3D 12 ist das Konzept einer Befehlswarteschlange die API-Darstellung einer ungefähr seriellen Arbeitssequenz, die von der Anwendung übermittelt wird. Barrieren und andere Techniken ermöglichen die Ausführung dieser Arbeit in einer Pipeline oder in einer nicht ordnungsgemäßen Reihenfolge, aber die Anwendung sieht nur einen einzelnen Abschluss Zeitleiste. Dies entspricht dem unmittelbaren Kontext in D3D11.
Synchronisierungs-APIs
Geräte und Warteschlangen
Das Direct3D 12-Gerät verfügt über Methoden zum Erstellen und Abrufen von Befehlswarteschlangen unterschiedlicher Typen und Prioritäten. Die meisten Anwendungen sollten die Standardbefehlswarteschlangen verwenden, da diese die gemeinsame Nutzung durch andere Komponenten ermöglichen. Anwendungen mit zusätzlichen Parallelitätsanforderungen können zusätzliche Warteschlangen erstellen. Warteschlangen werden durch den Befehlslistentyp angegeben, den sie nutzen.
Weitere Informationen finden Sie in den folgenden Erstellungsmethoden von ID3D12Device.
- CreateCommandQueue : Erstellt eine Befehlswarteschlange basierend auf Informationen in einer Direct3D-12_COMMAND_QUEUE_DESC-Struktur .
- CreateCommandList : Erstellt eine Befehlsliste vom Typ Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : Erstellt einen Zaun und notiert dabei die Flags in Direct3D 12_FENCE_FLAGS. Zäune werden verwendet, um Warteschlangen zu synchronisieren.
Warteschlangen aller Typen (3D, Compute und Kopieren) nutzen dieselbe Schnittstelle und basieren alle auf Befehlslisten.
Weitere Informationen finden Sie in den folgenden Methoden von ID3D12CommandQueue.
- ExecuteCommandLists : übermittelt ein Array von Befehlslisten zur Ausführung. Jede Befehlsliste, die durch ID3D12CommandList definiert wird.
- Signal : Legt einen Zaunwert fest, wenn die Warteschlange (die auf der GPU ausgeführt wird) einen bestimmten Punkt erreicht.
- Wait : Die Warteschlange wartet, bis der angegebene Zaun den angegebenen Wert erreicht.
Beachten Sie, dass Bundles nicht von Warteschlangen genutzt werden, sodass dieser Typ nicht zum Erstellen einer Warteschlange verwendet werden kann.
Zäune
Die API mit mehreren Engines stellt explizite APIs zum Erstellen und Synchronisieren mithilfe von Zäunen bereit. Ein Zaun ist ein Synchronisierungskonstrukt, das von einem UINT64-Wert gesteuert wird. Zaunwerte werden von der Anwendung festgelegt. Ein Signalvorgang ändert den Zaunwert, und ein Wartevorgang blockiert, bis der Zaun den angeforderten Wert oder höher erreicht hat. Ein Ereignis kann ausgelöst werden, wenn ein Zaun einen bestimmten Wert erreicht.
Weitere Informationen finden Sie in den Methoden der ID3D12Fence-Schnittstelle .
- GetCompletedValue : Gibt den aktuellen Wert des Zauns zurück.
- SetEventOnCompletion : Bewirkt, dass ein Ereignis ausgelöst wird, wenn der Zaun einen bestimmten Wert erreicht.
- Signal : Legt den Zaun auf den angegebenen Wert fest.
Zäune ermöglichen cpu-Zugriff auf den aktuellen Zaunwert und CPU-Wartevorgänge und -signale.
Die Signal-Methode auf der ID3D12Fence-Schnittstelle aktualisiert einen Zaun von der CPU-Seite. Dieses Update erfolgt sofort. Die Signal-Methode für ID3D12CommandQueue aktualisiert einen Zaun von der GPU-Seite. Dieses Update erfolgt, nachdem alle anderen Vorgänge in der Befehlswarteschlange abgeschlossen wurden.
Alle Knoten in einem Setup mit mehreren Engines können lesen und darauf reagieren, dass jeder Zaun den richtigen Wert erreicht.
Anwendungen legen ihre eigenen Zaunwerte fest. Ein guter Ausgangspunkt könnte die Erhöhung eines Zauns einmal pro Frame sein.
Ein Zaun kannumgewickelt werden. Dies bedeutet, dass der Zaunwert nicht nur erhöht werden muss. Wenn ein Signalvorgang in zwei verschiedene Befehlswarteschlangen eingereiht wird oder zwei CPU-Threads Signal in einem Zaun aufrufen, kann es zu einem Rennen kommen, um zu bestimmen, welches Signal zuletzt abgeschlossen wird, und daher der verbleibende Zaunwert. Wenn ein Zaun umgewickelt wird, werden alle neuen Wartevorgänge (einschließlich SetEventOnCompletion-Anforderungen ) mit dem neuen niedrigeren Zaunwert verglichen und werden daher möglicherweise nicht erfüllt, auch wenn der Zaunwert zuvor hoch genug war, um sie zu erfüllen. Wenn ein Rennen auftritt, zwischen einem Wert, der eine ausstehende Wartezeit erfüllt, und einem niedrigeren Wert, der nicht erfolgt, wird die Wartezeit erfüllt, unabhängig davon, welcher Wert danach verbleibt.
Die Zaun-APIs bieten leistungsstarke Synchronisierungsfunktionen, können aber möglicherweise zu schwierigen Problemen beim Debuggen führen. Es wird empfohlen, dass jeder Zaun nur verwendet wird, um den Fortschritt auf einer Zeitleiste anzuzeigen, um Rennen zwischen Signalgebern zu verhindern.
Kopieren und Berechnen von Befehlslisten
Alle drei Typen von Befehlslisten verwenden die ID3D12GraphicsCommandList-Schnittstelle , jedoch wird nur eine Teilmenge der Methoden für Das Kopieren und Berechnen unterstützt.
Kopier- und Computebefehlslisten können die folgenden Methoden verwenden.
Computebefehlslisten können auch die folgenden Methoden verwenden.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Computebefehlslisten müssen beim Aufrufen von SetPipelineState einen Compute-PSO festlegen.
Bundles können nicht mit Compute- oder Kopierbefehlslisten oder Warteschlangen verwendet werden.
Beispiel für Pipelinecompute und Grafiken
In diesem Beispiel wird gezeigt, wie die Zaunsynchronisierung verwendet werden kann, um eine Pipeline mit Computearbeit für eine Warteschlange (referenziert von pComputeQueue) zu erstellen, die von Grafiken in der Warteschlange pGraphicsQueueverwendet wird. Die Compute- und Grafikarbeit wird mit der Grafikwarteschlange pipelineiert, die das Ergebnis der Computearbeit aus mehreren Frames nutzt, und ein CPU-Ereignis wird verwendet, um die Gesamtarbeit insgesamt in der Warteschlange zu drosseln.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Um dieses Pipelining zu unterstützen, muss ein Puffer aus ComputeGraphicsLatency+1 verschiedenen Kopien der Daten vorhanden sein, die von der Computewarteschlange an die Grafikwarteschlange übergeben werden. Die Befehlslisten müssen UAVs und Dereferenzierung verwenden, um aus der entsprechenden "Version" der Daten im Puffer zu lesen und zu schreiben. Die Computewarteschlange muss warten, bis die Grafikwarteschlange das Lesen aus den Daten für Frame N abgeschlossen hat, bevor sie frame N+ComputeGraphicsLatencyschreiben kann.
Beachten Sie, dass die Menge der im Verhältnis zur CPU ausgeführten Computewarteschlange nicht direkt von der erforderlichen Pufferung abhängt. Die GPU-Warteschlangenarbeit über den verfügbaren Pufferspeicher hinaus ist jedoch weniger wertvoll.
Ein alternativer Mechanismus zur Vermeidung der Dereferenzierung wäre das Erstellen mehrerer Befehlslisten, die jeder der "umbenannten" Versionen der Daten entsprechen. Im nächsten Beispiel wird diese Technik verwendet, während das vorherige Beispiel erweitert wird, damit die Compute- und Grafikwarteschlangen asynchroner ausgeführt werden können.
Beispiel für asynchrone Compute- und Grafikverarbeitung
In diesem nächsten Beispiel können Grafiken asynchron aus der Computewarteschlange gerendert werden. Es gibt immer noch eine feste Menge gepufferter Daten zwischen den beiden Phasen, aber jetzt wird die Grafikarbeit unabhängig fortgesetzt und verwendet das aktuellste Ergebnis der Computephase, wie es für die CPU bekannt ist, wenn die Grafikarbeit in die Warteschlange eingereiht wird. Dies wäre nützlich, wenn die Grafikarbeit von einer anderen Quelle aktualisiert wird, z. B. von Benutzereingaben. Es müssen mehrere Befehlslisten vorhanden sein, damit die ComputeGraphicsLatency Grafikframes gleichzeitig ausgeführt werden können, und die Funktion UpdateGraphicsCommandList stellt das Aktualisieren der Befehlsliste dar, um die neuesten Eingabedaten einzuschließen und aus den Computedaten aus dem entsprechenden Puffer zu lesen.
Die Computewarteschlange muss weiterhin warten, bis die Grafikwarteschlange mit den Pipepuffern fertig ist, aber es wird ein dritter Zaun (pGraphicsComputeFence) eingeführt, damit der Fortschritt der Grafikleseleistung im Vergleich zum Grafikfortschritt im Allgemeinen nachverfolgt werden kann. Dies spiegelt die Tatsache wider, dass jetzt aufeinanderfolgende Grafikframes aus demselben Computeergebnis lesen oder ein Computeergebnis überspringen könnten. Ein effizienterer, aber etwas komplizierterer Entwurf würde nur den einzelnen Grafikzaun verwenden und eine Zuordnung zu den Computeframes speichern, die von jedem Grafikframe verwendet werden.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Ressourcenzugriff mit mehreren Warteschlangen
Um auf eine Ressource in mehr als einer Warteschlange zugreifen zu können, muss eine Anwendung die folgenden Regeln einhalten.
Der Ressourcenzugriff (siehe Direct3D-12_RESOURCE_STATES) wird durch die Warteschlangentypklasse und nicht durch das Warteschlangenobjekt bestimmt. Es gibt zwei Typklassen von Warteschlange: Compute/3D-Warteschlange ist eine Typklasse, Copy ist eine zweite Typklasse. Daher kann eine Ressource, die eine Barriere für den NON_PIXEL_SHADER_RESOURCE Zustand in einer 3D-Warteschlange aufweist, in diesem Zustand in jeder 3D- oder Compute-Warteschlange verwendet werden, vorbehaltlich der Synchronisierungsanforderungen, die die meisten Schreibvorgänge erfordern, serialisiert werden. Die Ressourcenzustände, die zwischen den beiden Typklassen (COPY_SOURCE und COPY_DEST) gemeinsam verwendet werden, werden als unterschiedliche Zustände für jede Typklasse betrachtet. Wenn also eine Ressource zu COPY_DEST in einer Kopierwarteschlange übergeht, ist sie nicht als Kopierziel aus 3D- oder Compute-Warteschlangen zugänglich und umgekehrt.
Zusammenfassend.
- Eine "Objekt"-Warteschlange ist eine einzelne Warteschlange.
- Ein Warteschlangentyp ist eine der folgenden drei: Compute, 3D und Copy.
- Eine "Typklasse" der Warteschlange ist eine der beiden folgenden: Compute/3D und Copy.
Die als Anfangszustände verwendeten COPY-Flags (COPY_DEST und COPY_SOURCE) stellen Zustände in der 3D/Compute-Typklasse dar. Um eine Ressource zunächst in einer Kopierwarteschlange zu verwenden, sollte sie im Common-Zustand gestartet werden. Der COMMON-Zustand kann für alle Verwendungen in einer Kopierwarteschlange mithilfe der impliziten Zustandsübergänge verwendet werden.
Obwohl der Ressourcenstatus für alle Compute- und 3D-Warteschlangen gemeinsam genutzt wird, ist es nicht zulässig, gleichzeitig in verschiedene Warteschlangen in die Ressource zu schreiben. "Gleichzeitig" bedeutet hier, dass die nicht synchronisierte Ausführung auf irgendeiner Hardware nicht möglich ist. Es gelten die folgenden Regeln.
- Nur eine Warteschlange kann gleichzeitig in eine Ressource schreiben.
- Mehrere Warteschlangen können aus der Ressource lesen, solange sie nicht die Bytes lesen, die vom Writer geändert werden (das Lesen von Bytes, die gleichzeitig geschrieben werden, führt zu undefinierten Ergebnissen).
- Ein Zaun muss für die Synchronisierung nach dem Schreiben verwendet werden, bevor eine andere Warteschlange die geschriebenen Bytes lesen oder Schreibzugriff gewähren kann.
Zurückpuffer, die angezeigt werden, müssen sich im Direct3D-12_RESOURCE_STATE_COMMON Zustand befinden.
Zugehörige Themen
Direct3D 12-Programmierhandbuch
Verwenden von Ressourcenbarrieren zum Synchronisieren von Ressourcenzuständen in Direct3D 12