Events
31 Mar, 23 - 2 Apr, 23
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Data flows are available both in Azure Data Factory and Azure Synapse Pipelines. This article applies to mapping data flows. If you are new to transformations, please refer to the introductory article Transform data using a mapping data flow.
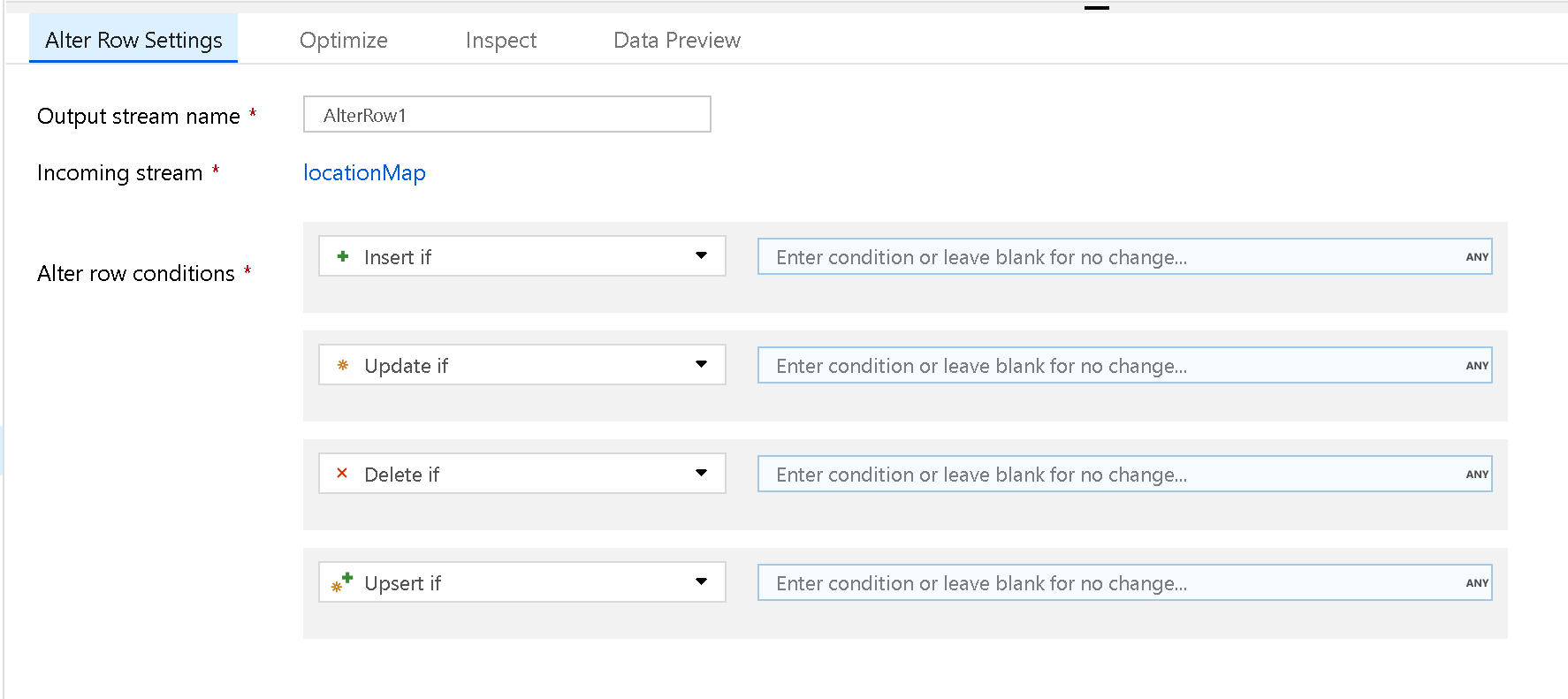
Use the Alter Row transformation to set insert, delete, update, and upsert policies on rows. You can add one-to-many conditions as expressions. These conditions should be specified in order of priority, as each row is marked with the policy corresponding to the first-matching expression. Each of those conditions can result in a row (or rows) being inserted, updated, deleted, or upserted. Alter Row can produce both DDL & DML actions against your database.
Alter Row transformations only operate on database, REST, or Azure Cosmos DB sinks in your data flow. The actions that you assign to rows (insert, update, delete, upsert) doesn't occur during debug sessions. To enact the alter row policies on your database tables, run an Execute Data Flow activity in a pipeline.
Note
An Alter Row transformation is not needed for Change Data Capture data flows that use native CDC sources like SQL Server or SAP. In those instances, ADF will automatically detect the row marker so Alter Row policies are unnecessary.
Create an Alter Row transformation and specify a row policy with a condition of true(). Each row that doesn't match any of the previously defined expressions is marked for the specified row policy. By default, each row that doesn't match any conditional expression is marked for Insert.

Note
To mark all rows with one policy, you can create a condition for that policy and specify the condition as true().
Use debug mode to view the results of your alter row policies in the data preview pane. A data preview of an alter row transformation doesn't produce DDL or DML actions against your target.

An icon for each alter row policy indicates whether an insert, update, upsert, or deleted action occurs. The top header shows how many rows each policy affects in the preview..
For the alter row policies to work, the data stream must write to a database or Azure Cosmos DB sink. In the Settings tab in your sink, enable which alter row policies are allowed for that sink.

The default behavior is to only allow inserts. To allow updates, upserts, or deletes, check the box in the sink corresponding to that condition. If updates, upserts, or, deletes are enabled, you must specify which key columns in the sink to match on.
Note
If your inserts, updates, or upserts modify the schema of the target table in the sink, the data flow will fail. To modify the target schema in your database, choose Recreate table as the table action. This will drop and recreate your table with the new schema definition.
The sink transformation requires either a single key or a series of keys for unique row identification in your target database. For SQL sinks, set the keys in the sink settings tab. For Azure Cosmos DB, set the partition key in the settings and also set the Azure Cosmos DB system field "ID" in your sink mapping. For Azure Cosmos DB, it's mandatory to include the system column "ID" for updates, upserts, and deletes.
Data Flows support merges against Azure SQL Database and Azure Synapse database pool (data warehouse) with the upsert option.
However, you could run into scenarios where your target database schema utilized the identity property of key columns. The service requires you to identify the keys that you use to match the row values for updates and upserts. But if the target column has the identity property set and you're using the upsert policy, the target database doesn't allow you to write to the column. You may also run into errors when you try to upsert against a distributed table's distribution column.
Here are ways to fix that:
Go to the Sink transformation Settings and set "Skip writing key columns". This tells the service to not write the column that you have selected as the key value for your mapping.
If that key column isn't the column that is causing the issue for identity columns, then you can use the Sink transformation preprocessing SQL option: SET IDENTITY_INSERT tbl_content ON. Then, turn it off with the post-processing SQL property: SET IDENTITY_INSERT tbl_content OFF.
For both the identity case and the distribution column case, you can switch your logic from Upsert to using a separate update condition and a separate insert condition using a Conditional Split transformation. This way, you can set the mapping on the update path to ignore the key column mapping.
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
The below example is an alter row transformation named CleanData that takes an incoming stream SpecifyUpsertConditions and creates three alter row conditions. In the previous transformation, a column named alterRowCondition is calculated that determines whether or not a row is inserted, updated, or deleted in the database. If the value of the column has a string value that matches the alter row rule, it's assigned that policy.
In the UI, this transformation looks like the below image:
The data flow script for this transformation is in the snippet below:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
After the Alter Row transformation, you might want to sink your data into a destination data store.
Events
31 Mar, 23 - 2 Apr, 23
The biggest Fabric, Power BI, and SQL learning event. March 31 – April 2. Use code FABINSIDER to save $400.
Register todayTraining
Module
Code-free transformation at scale with Azure Data Factory - Training
Perform code-free transformation at scale with Azure Data Factory or Azure Synapse Pipeline