Cloud-scale analytics data products in Azure
Data products are data served as product and computed, saved, and served by polyglot persistence services, which can be required by certain use cases. The process of creating and serving a data product can require services and technologies that aren't included in the data landing zone core services. An example of this would be reporting with niche requirements, such as compliance and tax reporting.
Design considerations
A data landing zone can be served multiple data products created by ingesting data from within the same data landing zone or from across multiple data landing zones. This is showing in the following diagram.
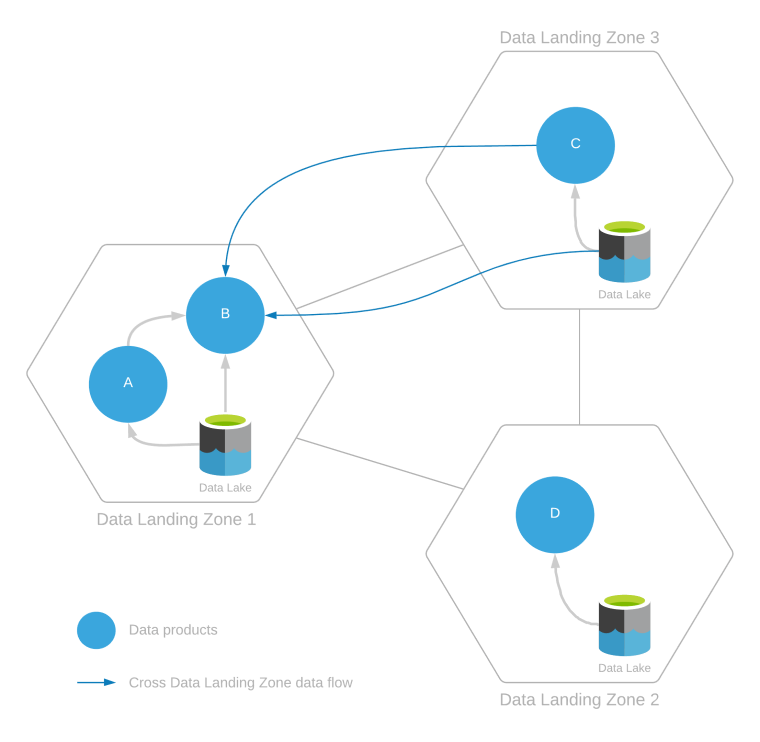
The example above shows:
- Intrazone data consumption:
- Data product B consumes data from data product A and other data or data products existing in the data lake within its own landing zone.
- Data products C and D only consume data from within their own respective data landing zones.
- Interzone data consumption:
- Data product B also consumes data from data product C and the data in landing zone 3's data lake.
Important
In the case of interzone data consumption, since data product B is created by reading from data landing zone 3, this read access requires approval from the data landing zone operations and integration operations teams of data landing zone 3.
Important
Data product B consumes data from data products A and C. Before this can happen, data product B must register its consumption of data products via data sharing agreements. This data sharing agreement should update the lineage from data product A to data product B and from data product C to data product B.
The resource group for a data product includes all services required to create and maintain it. We can call this resource group a data application. Examples of services that might be part of a data application include Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL Database, Azure Database for MySQL, and Azure Cosmos DB. For more information, see data application samples.
Data products have data from READ data sources that have had some data transformations applied. Examples might be a newly curated dataset or a BI report.
Design recommendations
Build data products within your data landing zone by adhering to design principles that allow you to scale with data governance. The following sections provide design recommendations to help as you plan your data application ecosystem.
Deploy multiple resource groups
Each data application is a resource group. Since data applications are compute services, polyglot persistence services, or both, they can only be required depending on certain use cases. As such, they're considered an optional data landing zone component. In a case where you do need data applications, create multiple resource groups by data application as the following diagram shows.

Set guardrails
Azure Policy drives the default configuration of services within a data landing zone. Think of operational analytics as multiple resource groups that your data product team can request from a standard service catalog. Using Azure Policy, you can configure the security boundary and required feature set.
Important
To drive consistency, configure one Azure Policy for each data application.
Consume data from multiple places
Data applications manage, organize, and make sense of data from multiple data assets and present any insights gained. A data product is the result of data from one or many data applications within data landing zones. Allow your data applications to access data from multiple and various sources when necessary.
Scale as needed
Services that make up data applications are incremental deployments to the data landing zone. Scale your data applications as needed.
Enable data discovery
Automatically register your data products in a data catalog such as Azure Purview to allow data scanning.
Identify your data products
While starting to plan a data landing zone, identify as many data products (and the data applications that output and maintain them) as necessary to help drive your data product application architecture. Conformity to implemented platform governance should play the largest role in your decisions.
Focus on how your data applications are data producers and consumers for others. For example, assume you've identified a suite of data products (A, B, C, and D) which are produced and consumed data. You require data products A and D as sources for the data in Data Application B for data product B. Data product B is created from the data that Data Application B consumes from data products A and D. Data Application B acts as a data producer itself, and also produces data for data product C.
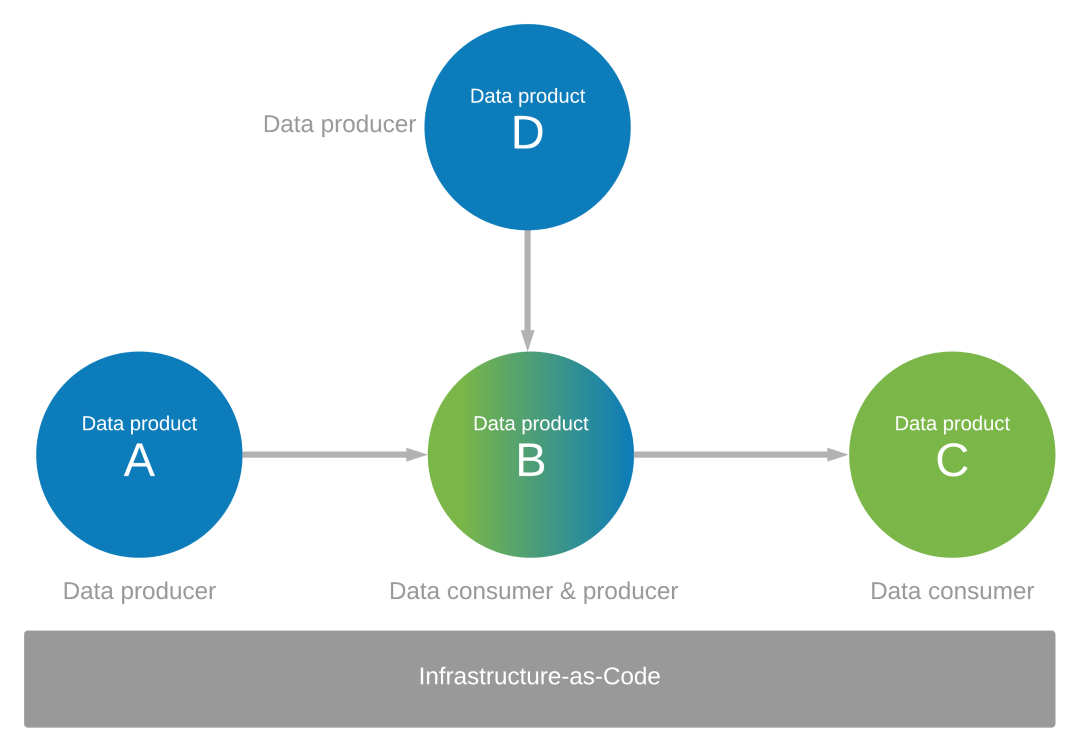
Control your data application environment with infrastructure-as-code
Governance and infrastructure-as-code should control the data application environment across your data products ecosystem, as shown in the previous diagram.
Publish data models
Your data product teams should publish their data models in a modeling repository.
Set expectations for data product users
Update your data sharing contracts with service-level agreements and certifications for your data products so you to convey accurate expectations to potential users of the data product.
Capture lineage
If data product B is created from data coming from data products A and D, lineage must be captured from A and D to B. Further lineage should also be captured for data product C, since it's created using data from data product B. Updated lineage should be captured in a data lineage application before every release of your data product.
Note
Using Azure Pipelines allows you to build approval gates and invoke functions that can make sure metadata, lineage, and SLAs are registered in the correct governance service.
Define data application architecture
You must create a detailed architecture for each data product that fully defines its relationship to other data products, its dependencies, and its access requirements.
Example design scenario
To understand the architecture definition process, explore the following example of a financial institution and its credit monitoring data product.
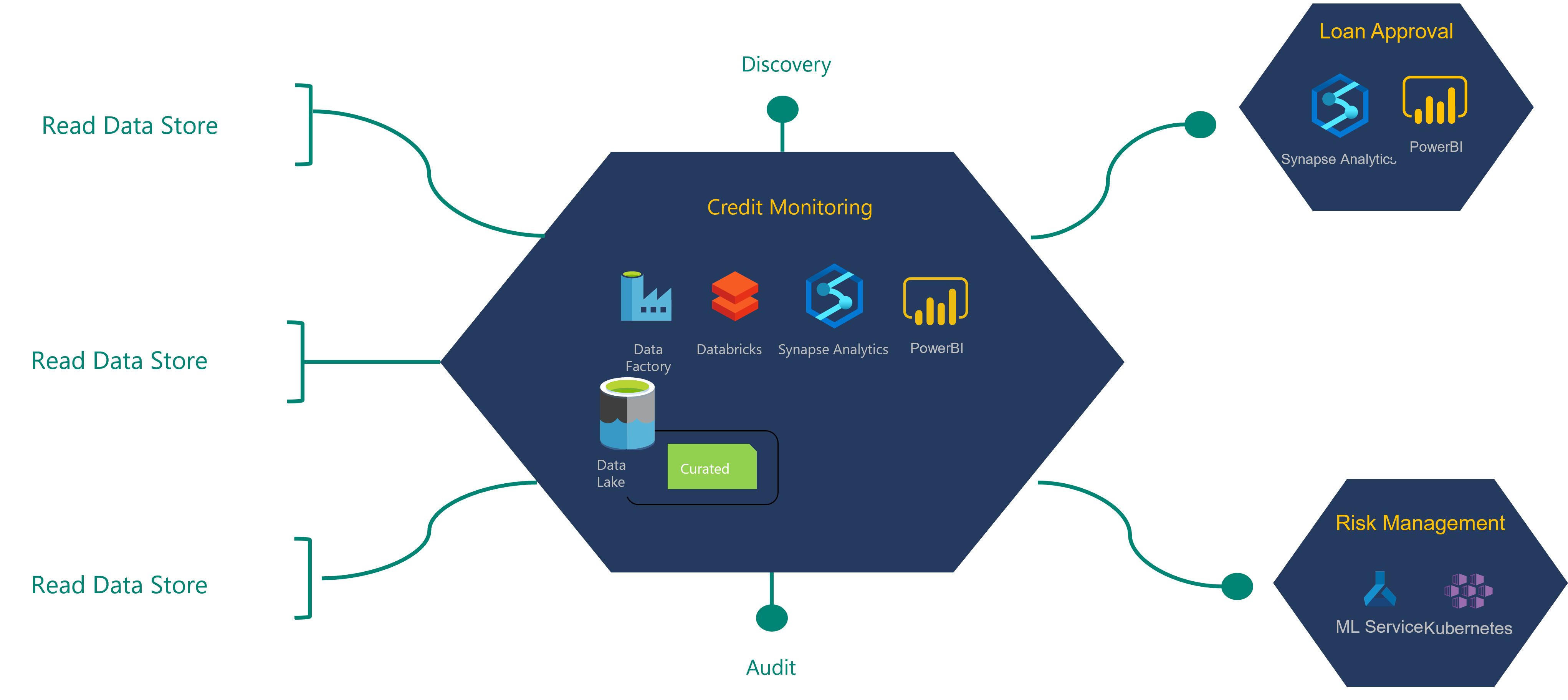
The credit monitoring data product shown in this diagram consumes data from a read data store that has been ingested by the integration operations team. It produces data product(s) also consumed by two other data products.
Note
A read data source or store is also known as a golden record source. These data sources have been cleaned but haven't had any transformations applied to them.
The credit monitoring data product team requests read access to read data stores they need for their data product creation. Their requests are routed to the owners of the data for approval. Once they receive approval, the product team can begin building their data application.
Data from the read data source is transformed into the credit monitoring data product(s). Any new data products get stored in the data lake's curated layer. These new data products and the new data lineage should be registered as part of the DevOps deployment process. A function can check registered metadata with the physical structure of the data asset. It should register the dependency on the read data source data assets and data products.
The loan approval data product team has a dependency on some of the credit monitoring data products. They loan approval team might request read access to the credit monitoring data products they require for their data products. Once they release their loan approval data product and its data application, all data product assets, lineage, and models should be registered in the relevant governance services.
Sample data applications
The following sections contain sample data applications to further illustrate data application scenarios.
Data analytics and data science data application
An application for data analytics and data science might contain the services shown in sample data application product-analytics-rg.

Note
You can use the preceding data application as a template. This template deploys a set of services that you can use for data analytics and data science. You can use this data product application template to quickly create environments for cross-functional teams. You must explicitly disable any services that you don't require.
The Data Product Analytics template contains all templates for deploying a data product for analytics and data science inside a cloud-scale analytics scenario data landing zone.
The deployment and code artifacts include the following services:
- Machine Learning
- Key Vault
- Application Insights
- Storage
- Container Registry
- Cognitive Services (optional)
- Data Factory (select between Data Factory and Synapse)
- Synapse Workspace (select between Data Factory and Synapse)
- Azure Search (optional)
- SQL Pool (optional)
- BigData Pool (optional)
Batch Data Application
The Batch Data Application template contains all templates for deploying a data product for batch data processing inside a cloud-scale analytics scenario data landing zone.
The deployment and code artifacts include the following services:

- Key Vault
- Data Factory (select between Data Factory and Synapse)
- Azure Cosmos DB (optional)
- Synapse Workspace (select between Data Factory and Synapse)
- MySQL Database (optional)
- Azure SQL Database (optional)
- PostgreSQL Database (optional)
- MariaDB Database (optional)
- SQL Pool (optional)
- SQL Server (optional)
- SQL Elastic Pool (optional)
- BigData Pool
Streaming Data Application
The Streaming Data Application template contains all templates for deploying a data product for real-time data processing inside a cloud-scale analytics scenario data landing zone
The deployment and code artifacts include the following services:

- Key Vault
- Event Hubs
- IoT Hub
- Stream Analytics (optional)
- Azure Cosmos DB (optional)
- Synapse Workspace
- Azure SQL Database (optional)
- SQL Pool (optional)
- SQL Server (optional)
- SQL Elastic Pool (optional)
- BigData Pool
- Data Explorer (optional)
To find the repositories containing the previously-mentioned deployment templates, refer to deployment templates for cloud-scale analytics