Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article shows you how to add Confluent Cloud for Apache Kafka source to an eventstream.
Confluent Cloud for Apache Kafka is a streaming platform offering powerful data streaming and processing functionalities using Apache Kafka. By integrating Confluent Cloud for Apache Kafka as a source within your eventstream, you can seamlessly process real-time data streams before routing them to multiple destinations within Fabric.
Prerequisites
- Access to a workspace in the Fabric capacity license mode (or) the Trial license mode with Contributor or higher permissions.
- A Confluent Cloud for Apache Kafka cluster and an API Key.
- Your Confluent Cloud for Apache Kafka cluster must be publicly accessible and not be behind a firewall or secured in a virtual network.
- If you don't have an eventstream, create an eventstream.
Launch the Select a data source wizard
If you haven't added any source to your eventstream yet, select the Use external source tile.

If you're adding the source to an already published eventstream, switch to Edit mode. On the ribbon, select Add source > External sources.

Configure and connect to Confluent Cloud for Apache Kafka
On the Select a data source page, select Confluent Cloud for Apache Kafka.
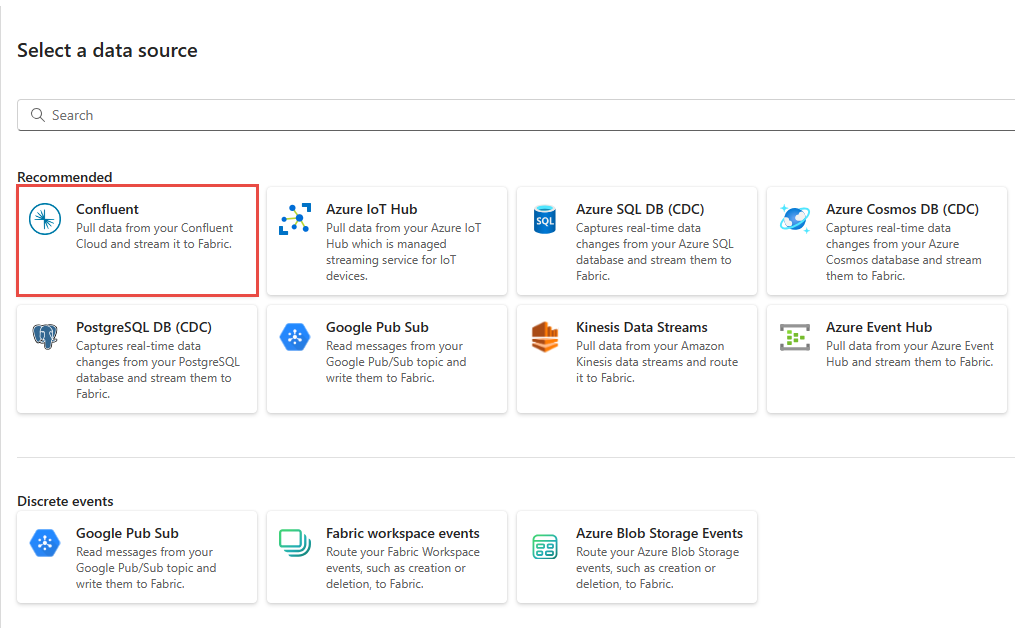
To create a connection to the Confluent Cloud for Apache Kafka source, select New connection.
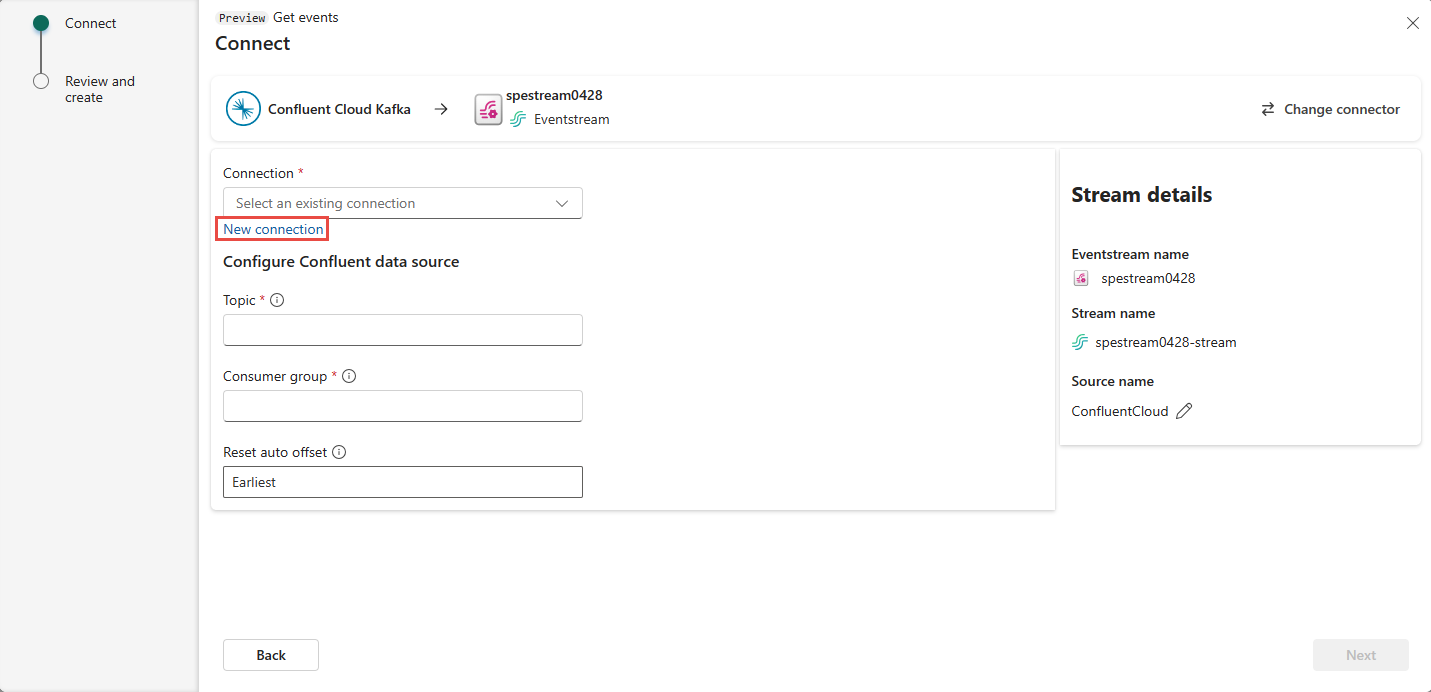
In the Connection settings section, enter Confluent Bootstrap Server. Navigate to your Confluent Cloud home page, select Cluster Settings, and copy the address to your Bootstrap Server.
In the Connection credentials section, If you have an existing connection to the Confluent cluster, select it from the dropdown list for Connection. Otherwise, follow these steps:
- For Connection name, enter a name for the connection.
- For Authentication kind, confirm that Confluent Cloud Key is selected.
- For API Key and API Key Secret:
Navigate to your Confluent Cloud.
Select API Keys on the side menu.
Select the Add key button to create a new API key.
Copy the API Key and Secret.
Paste those values into the API Key and API Key Secret fields.
Select Connect
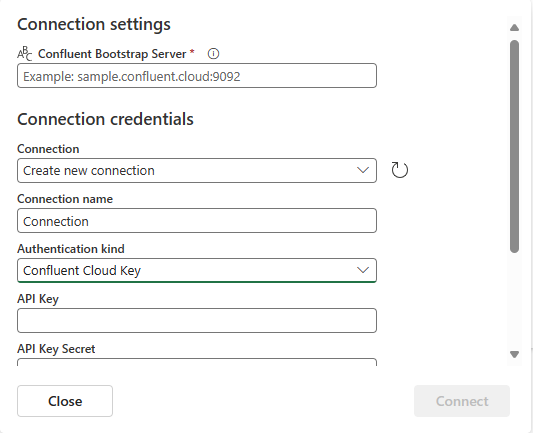
Scroll to see the Configure Confluent Cloud for Apache Kafka data source section on the page. Enter the information to complete the configuration of the Confluent data source.
For Topic name, enter a topic name from your Confluent Cloud. You can create or manage your topic in the Confluent Cloud Console.
For Consumer group, enter a consumer group of your Confluent Cloud. It provides you with the dedicated consumer group for getting the events from Confluent Cloud cluster.
For Reset auto offset setting, select one of the following values:
- Earliest – the earliest data available from your Confluent cluster.
- Latest – the latest available data.
- None – Do not automatically set the offset.
Note
The None option isn't available during this creation step. If a committed offset exists and you want to use None, you can first complete the configuration and then update the setting in the Eventstream edit mode.
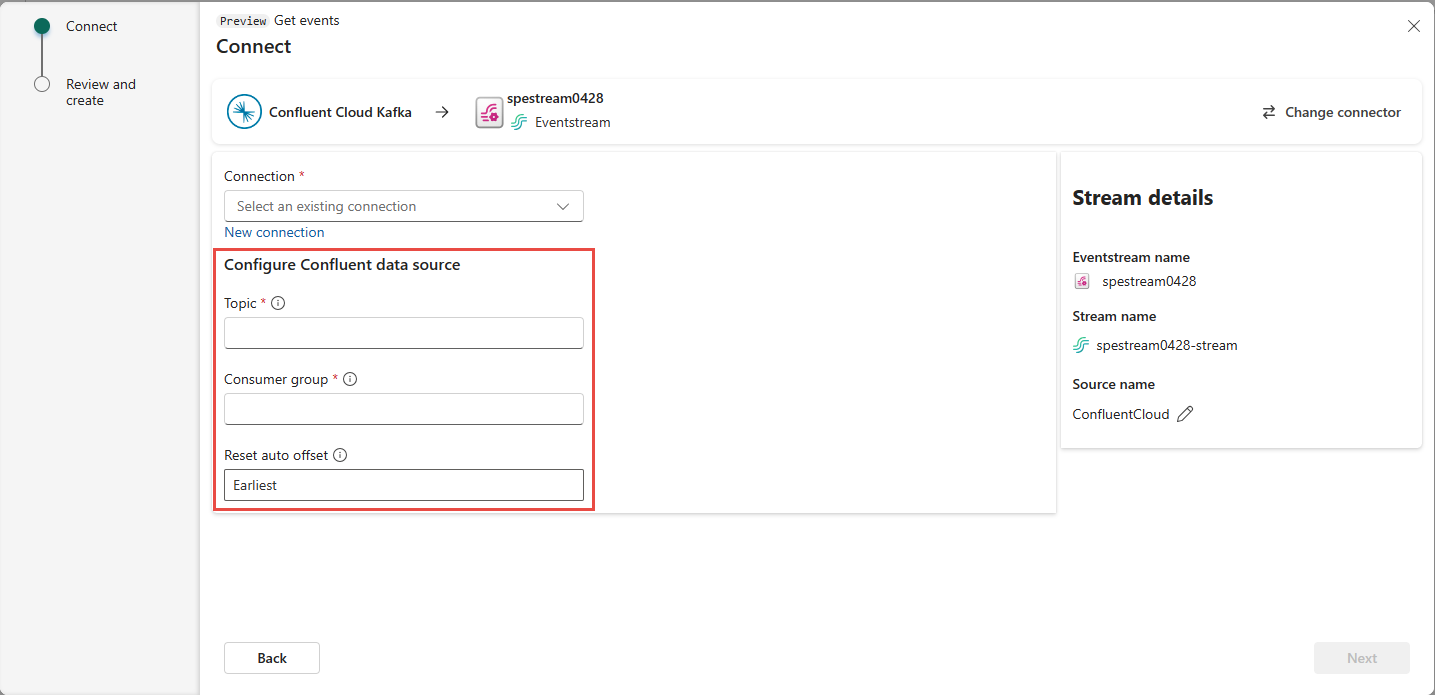
Depending on whether your data is encoded using Confluent Schema Registry:
- If not encoded, select Next. On the Review and create screen, review the summary, and then select Add to complete the setup.
- If encoded, proceed to the next step: Connect to Confluent schema registry to decode data (preview)
Connect to Confluent schema registry to decode data (preview)
Eventstream's Confluent Cloud for Apache Kafka streaming connector is capable of decoding data produced with Confluent serializer and its Schema Registry from Confluent Cloud. Data encoded with this serializer of Confluent schema registry require schema retrieval from the Confluent Schema Registry for decoding. Without access to the schema, Eventstream can't preview, process, or route the incoming data.
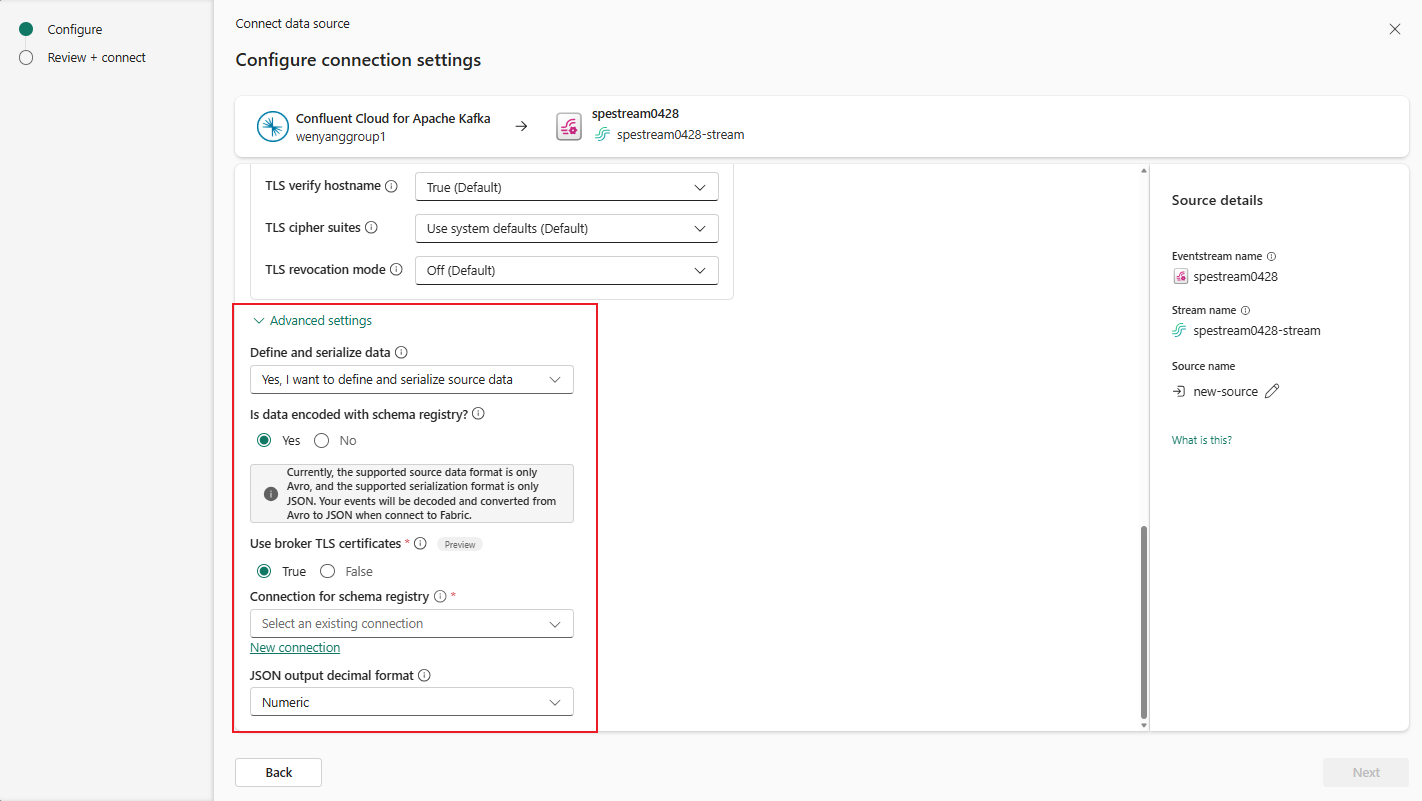
You may expand Advanced settings to configure Confluent Schema Registry connection:
Define and serialize data: Select Yes allows you to serialize the data into a standardized format. Select No keeps the data in its original format and passes it through without modification.
If your data is encoded using a schema registry, select Yes when choosing whether the data is encoded with a schema registry. Then, select New connection to configure access to your Confluent Schema Registry:
- Schema Registry URL: The public endpoint of your schema registry.
- API Key and API Key Secret: Navigate to Confluent Cloud Environment's Schema Registry to copy the API Key and API Secret. Ensure the account used to create this API key has DeveloperRead or higher permission on the schema.
- Privacy Level: Choose from None, Private, Organizational, or Public.
JSON output decimal format: Specifies the JSON serialization format for Decimal logical type values in the data from the source.
- NUMERIC: Serialize as numbers.
- BASE64: Serialize as base64 encoded data.
Select Next. On the Review and create screen, review the summary, and then select Add to complete the setup.
You see that the Confluent Cloud for Apache Kafka source is added to your eventstream on the canvas in Edit mode. To implement this newly added Confluent Cloud for Apache Kafka source, select Publish on the ribbon.

After you complete these steps, the Confluent Cloud for Apache Kafka source is available for visualization in Live view.

Note
To preview events from this Confluent Cloud for Apache Kafka source, ensure that the API key used to create the cloud connection has read permission for consumer groups prefixed with "preview-". If the API key was created using a user account, no additional steps are required, as this type of key already has full access to your Confluent Cloud for Apache Kafka resources, including read permission for consumer groups prefixed with "preview-". However, if the key was created using a service account, you need to manually grant read permission to consumer groups prefixed with "preview-" in order to preview events.
For Confluent Cloud for Apache Kafka sources, preview is supported for messages in Confluent AVRO format when the data is encoded using Confluent Schema Registry. If the data is not encoded using Confluent Schema Registry, only JSON formatted messages can be previewed.

Related content
Other connectors: