Supervisar la calidad y el uso de tokens de las aplicaciones de flujo de avisos implementadas
Importante
Algunas de las características descritas en este artículo solo pueden estar disponibles en versión preliminar. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
La supervisión de aplicaciones que se implementan en producción es una parte esencial del ciclo de vida de la aplicación de IA generativa. Los cambios en los datos y en el comportamiento de los consumidores pueden influir en su aplicación a lo largo del tiempo, dando lugar a sistemas obsoletos que afectan negativamente a los resultados empresariales y exponen a las organizaciones a riesgos de cumplimiento, económicos y de reputación.
La supervisión de Azure AI para aplicaciones de IA generativa le permite supervisar sus aplicaciones en producción para el uso de tokens, la calidad de generación y las métricas operativas.
Las integraciones para supervisar una implementación de flujo de aviso le permiten:
- Recopile datos de inferencia de producción de su aplicación de flujo de avisos implementada.
- Aplicar métricas de evaluación de la IA responsables, como la base, la coherencia, la fluidez y la relevancia, que son interoperables con las métricas de evaluación del flujo de avisos.
- Supervise los avisos, la finalización y el uso total de tokens en cada implementación de modelos en su flujo de avisos.
- Supervise las métricas operativas, como el recuento de solicitudes, la latencia y la tasa de errores.
- Use alertas preconfiguradas y valores predeterminados para ejecutar la supervisión de forma periódica.
- Consuma visualizaciones de datos y configure comportamientos avanzados en Inteligencia artificial de Azure Studio.
Requisitos previos
Antes de seguir los pasos de este artículo, asegúrese de que tiene los siguientes requisitos previos:
Una suscripción de Azure con un método de pago válido. Las suscripciones gratuitas o de evaluación de Azure no funcionarán. Si no tiene una suscripción de Azure, cree una cuenta de Azure de pago para comenzar.
Un flujo de avisos listo para la implementación. Si no tiene una, consulte Desarrollo de un flujo de avisos.
Los controles de acceso basado en rol de Azure (RBAC de Azure) se usan para conceder acceso a las operaciones en la inteligencia artificial de Azure Studio. Para realizar los pasos descritos en este artículo, la cuenta de usuario debe tener asignado el rol Desarrollador de Azure AI en el grupo de recursos. Para más información sobre los permisos, consulte control de acceso basado en rol en Inteligencia artificial de Azure Studio.
Requisitos para las métricas de supervisión
Las métricas de supervisión son generadas por determinados modelos de lenguaje GPT de última generación configurados con instrucciones de evaluación específicas (plantillas de avisos). Estos modelos actúan como modelos de evaluador para tareas de secuencia a secuencia. El uso de esta técnica para generar métricas de seguimiento muestra resultados empíricos sólidos y una alta correlación con el juicio humano en comparación con las métricas de evaluación de IA generativa estándar. Para obtener más información sobre la evaluación del flujo de avisos, consulte enviar pruebas masivas y evaluar un flujo y métricas de evaluación y supervisión para la inteligencia artificial generativa.
Los modelos GPT que generan métricas de supervisión son los siguientes. Estos modelos GPT se admiten, y se configurarán como su recurso de Azure OpenAI:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Métricas admitidas para la supervisión
Se admiten las siguientes métricas para supervisión:
| Métrica | Descripción |
|---|---|
| Base | Mide lo bien que se alinean las respuestas generadas por el modelo con la información de los datos de origen (contexto definido por el usuario). |
| Relevancia | Evalúa la medida en que las respuestas generadas del modelo son pertinentes y directamente relacionadas con las preguntas formuladas. |
| Coherencia | Mide hasta qué punto las respuestas generadas por el modelo son lógicamente coherentes y están conectadas. |
| Fluidez | Mide la competencia gramatical de la respuesta predicha por una inteligencia artificial generativa. |
Asignación de nombres de columna
Cuando cree su flujo, debe asegurarse de que los nombres de las columnas están asignados. Los siguientes nombres de columnas de datos de entrada son necesarios para medir la seguridad y la calidad de la generación:
| Nombre de columna de entrada | Definición | Obligatorio/opcional |
|---|---|---|
| Pregunta | La solicitud original especificada (también conocida como "entradas" o "pregunta") | Obligatorio |
| Respuesta | La finalización de la llamada API que se devuelve (también conocida como "salidas" o "respuesta") | Obligatorio |
| Context | Los datos de contexto que se envían a la llamada API, junto con la solicitud original. Por ejemplo, si espera obtener resultados de búsqueda solo de determinados orígenes de información certificados o sitios web, puede definir este contexto en los pasos de evaluación. | Opcionales |
Parámetros necesarios para las métricas
Los parámetros configurados en su recurso de datos dictan qué métricas puede producir, según esta tabla:
| Métrica | Pregunta | Respuesta | Context |
|---|---|---|---|
| Coherencia | Obligatorio | Obligatorio | - |
| Fluidez | Obligatorio | Obligatorio | - |
| Base | Obligatorio | Obligatorio | Obligatorio |
| Relevancia | Obligatorio | Obligatorio | Obligatorio |
Para obtener más información sobre los requisitos de asignación de datos específicos para cada métrica, consulte Requisitos de métricas de respuesta a preguntas.
Configurar la supervisión del flujo de avisos
Para configurar la supervisión de su aplicación de flujo de avisos, primero tiene que implementar su aplicación de flujo de avisos con recopilación de datos de inferencias y luego puede configurar la supervisión de la aplicación implementada.
Implemente su aplicación de flujo de avisos con recopilación de datos de inferencias
En esta sección, aprenderá a implementar su flujo de avisos con la recopilación de datos de inferencia habilitada. Para obtener información detallada sobre cómo implementar el flujo de avisos, consulte Implementación de un flujo para la inferencia en tiempo real.
Inicie sesión en Azure AI Studio.
Vaya al proyecto de Inteligencia artificial de Azure Studio.
En la barra de navegación izquierda, vaya a Herramientas>Flujo de avisos.
Seleccione el flujo de aviso que creó anteriormente.
Nota:
Este artículo asume que usted ya ha creado un flujo de avisos que está listo para su implementación. Si no tiene una, consulte Desarrollo de un flujo de avisos.
Confirme que su flujo se ejecuta correctamente y que las entradas y salidas necesarias están configuradas para las métricas que desea evaluar.
El suministro de los parámetros mínimos necesarios (pregunta/entrada y respuesta/salida) solo proporciona dos métricas: coherencia y fluidez. Debe configurar el flujo como se describe en la sección Requisitos para las métricas de supervisión. En este ejemplo se usa
question(Pregunta) ychat_history(Contexto) como entradas de flujo yanswer(Respuesta) como salida del flujo.Seleccione Implementar para empezar a implementar el flujo.
En la ventana de implementación, asegúrese de que la recopilación de datos de inferencia está habilitada, lo que recopilará sin problemas los datos de inferencia de su aplicación en Blob Storage. Esta recopilación de datos es necesaria para la supervisión.
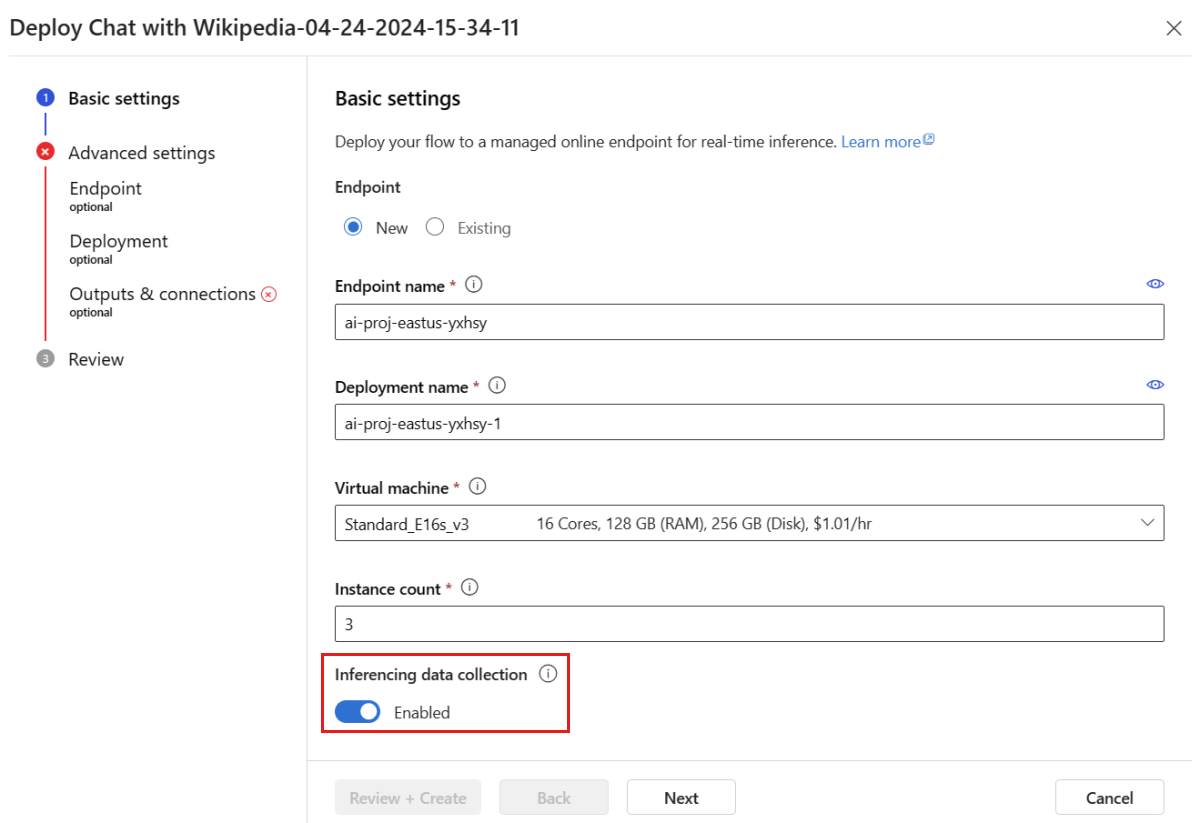
Siga los pasos descritos en la ventana de implementación para completar la Configuración avanzada.
En la página "Revisión", revise la configuración de implementación y seleccione Crear para implementar el flujo.

Nota:
De forma predeterminada, todas las entradas y salidas de su aplicación de flujo de avisos implementada se recopilan en su Blob Storage. A medida que la implementación es invocada por los usuarios, los datos se recopilan para ser utilizados por su supervisión.
Seleccione la pestaña Prueba de la página de implementación y pruebe la implementación para asegurarse de que funciona correctamente.

Nota:
La supervisión requiere que al menos un punto de datos proceda de un origen distinto de la pestaña Prueba de la implementación. Recomendamos utilizar la API de REST disponible en la pestaña Consumir para enviar solicitudes de muestra a su implementación. Para obtener más información sobre cómo enviar solicitudes de muestra a su implementación, consulte Crear una implementación en línea.




Configuración de la supervisión
En esta sección, aprenderá a configurar la supervisión de su aplicación de flujo de avisos implementada.
En la barra de navegación izquierda, vaya a Componentes>Implementaciones.
Seleccione la implementación del flujo de aviso que acaba de crear.
Seleccione Habilitar en el cuadro Habilitar supervisión de la calidad de generación.

Comience a configurar la supervisión seleccionando las métricas deseadas.
Confirme que los nombres de sus columnas están asignados desde su flujo tal y como se define en Asignación de nombres de columnas.
Seleccione la conexión de Azure OpenAI y la Implementación que desea utilizar para realizar la supervisión de su aplicación de flujo de avisos.
Seleccione Opciones avanzadas para ver más opciones para configurar.

Ajuste la frecuencia de muestreo, los umbrales de las métricas configuradas y especifique las direcciones de correo electrónico que deben recibir alertas cuando la puntuación media de una métrica determinada caiga por debajo del umbral.

Nota:
Si la implementación no tiene habilitada la recopilación de datos, la creación de un monitor habilitará la recopilación de datos de inferencia en Azure Blob Storage, que tardará la implementación sin conexión durante unos minutos.
Seleccione Crear para crear el supervisor.



Consumir los resultados de la supervisión
Una vez creado el supervisor, se ejecutará diariamente para calcular el uso de tokens y las métricas de calidad de generación.
Vaya a la pestaña Supervisión (versión preliminar) desde la implementación para ver los resultados de la supervisión. Aquí verá información general sobre los resultados de la supervisión durante el período de tiempo seleccionado. Puede usar el selector de fechas para cambiar la ventana temporal de los datos que está supervisando. Las siguientes métricas están disponibles en este resumen:
- Recuento total de solicitudes: el número total de solicitudes enviadas a la implementación durante la ventana de tiempo seleccionada.
- Recuento total de tokens: el número total de tokens usados por la implementación durante el período de tiempo seleccionado.
- Recuento de tokens de aviso: el número de tokens de aviso utilizados por la implementación durante la ventana de tiempo seleccionada.
- Recuento de tokens de finalización: el número de tokens de finalización utilizados por la implementación durante la ventana de tiempo seleccionada.
Visualice las métricas en la pestaña Uso de token (esta pestaña está seleccionada de manera predeterminada). Aquí puede ver el uso de tokens de su aplicación a lo largo del tiempo. También puede ver la distribución de tokens de aviso y de finalización a lo largo del tiempo. Puede cambiar el ámbito de Trendline para supervisar todos los tokens de toda la aplicación o el uso de tokens para una implementación concreta (por ejemplo, gpt-4) utilizada dentro de su aplicación.

Vaya a la pestaña Calidad de la generación para supervisar la calidad de su aplicación a lo largo del tiempo. En el gráfico de tiempo se muestran las siguientes métricas:
- Recuento de infracciones: el recuento de infracciones para una métrica determinada (por ejemplo, Fluidez) es la suma de infracciones a lo largo de la ventana temporal seleccionada. Se produce una infracción para una métrica cuando se calculan las métricas (el valor predeterminado es diariamente) si el valor calculado para la métrica cae por debajo del valor umbral establecido.
- Puntuación media: la puntuación media de una métrica determinada (por ejemplo, Fluidez) es la suma de las puntuaciones de todas las instancias (o solicitudes) dividida por el número de instancias (o solicitudes) durante la ventana de tiempo seleccionada.
La tarjeta Generación de infracciones de calidad muestra la tasa de infracciones en la ventana de tiempo seleccionada. La tasa de infracciones es el número de infracciones divididas por el número total de posibles infracciones. Puede ajustar los umbrales de las métricas en la configuración. De forma predeterminada, las métricas se calculan diariamente; esta frecuencia también se puede ajustar en la configuración.

En la pestaña Supervisión (versión preliminar), también puede ver una tabla completa de todas las solicitudes muestreadas enviadas a la implementación durante la ventana de tiempo seleccionada.
Nota:
La supervisión establece la frecuencia de muestreo predeterminada al 10 %. Esto significa que si se envían 100 solicitudes a su implementación, se muestrean 10 y se utilizan para calcular las métricas de calidad de generación. Puede ajustar la frecuencia de muestreo en la configuración.

Seleccione el botón Seguimiento situado a la derecha de una fila de la tabla para ver los detalles de seguimiento de una solicitud determinada. Esta vista proporciona detalles de seguimiento completos para la solicitud a la aplicación.

Cierre la vista Seguimiento.
Vaya a la pestaña Operativo para ver las métricas operativas de la implementación casi en tiempo real. Admitimos las siguientes métricas operativas:
- Recuento de solicitudes
- Latencia
- Frecuencia de errores






Los resultados en la pestaña Supervisión (versión preliminar) de la implementación proporcionan información para ayudarle a mejorar proactivamente el rendimiento de la aplicación de flujo de avisos.
Configuración avanzada de la supervisión con SDK v2
La supervisión también admite opciones de configuración avanzadas con el SDK v2. Se admiten los siguientes escenarios:
Habilitar la supervisión del uso de tokens
Si solo está interesado en habilitar la supervisión del uso de tokens para la aplicación de flujo de avisos implementada, puede adaptar el siguiente script a su escenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Habilitar la supervisión de la calidad de la generación
Si solo está interesado en habilitar la supervisión de calidad de generación para la aplicación de flujo de avisos implementada, puede adaptar el siguiente script a su escenario:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
workspace_name = "INSERT YOUR WORKSPACE NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=workspace_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Una vez que haya creado su supervisión desde el SDK, podrá consumir los resultados de la supervisión en AI Studio.
Contenido relacionado
- Más información sobre lo que puede hacer en Inteligencia artificial de Azure Studio
- Obtenga respuestas a las preguntas más frecuentes en el artículo preguntas más frecuentes sobre Azure AI.