Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se explica cómo usar la actividad de copia para copiar datos de Amazon Simple Storage Service (Amazon S3) y Data Flow para transformar datos en Amazon S3. Para obtener más información, lea los artículos de introducción para Azure Data Factory y Synapse Analytics.
Sugerencia
Para más información sobre el escenario de migración de datos de Amazon S3 a Azure Storage, consulte el artículo Migración de datos de Amazon S3 a Azure Storage.
Funcionalidades admitidas
Este conector de Amazon S3 es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | ① ② |
| Flujo de datos de asignación (origen/receptor) | ① |
| Actividad de búsqueda | ① ② |
| Actividad GetMetadata | ① ② |
| Actividad de eliminación | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Concretamente, este conector de Amazon S3 admite la copia de archivos tal cual, o el análisis de los mismos con los códecs de compresión y los formatos de archivo compatibles. También puede optar por conservar los metadatos de archivo durante la copia. El conector usa AWS Signature versión 4 para autenticar las solicitudes a S3.
Sugerencia
Si desea copiar datos de cualquier proveedor de almacenamiento compatible con S3, consulte el artículo sobre el almacenamiento compatible con Amazon S3.
Permisos necesarios
Para copiar datos de Amazon S3, asegúrese de que se han concedido los permisos siguientes para las operaciones de objeto de Amazon S3: s3:GetObject y s3:GetObjectVersion.
Si usa la interfaz de usuario de Data Factory para crear, se requieren los permisos s3:ListAllMyBuckets y s3:ListBucket/s3:GetBucketLocation adicionales para operaciones como probar la conexión al servicio vinculado y examinar desde la raíz. Si no quiere conceder estos permisos, puede elegir las opciones "Test connection to file path" (Probar conexión con la ruta de acceso del archivo) o "Browse from specified path" (Examinar desde la ruta de acceso especificada) en la interfaz de usuario.
Para obtener la lista completa de los permisos de Amazon S3, consulte Specifying Permissions in a Policy (Especificación de permisos en una directiva) en el sitio de AWS.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado de Amazon Simple Storage Service (S3) mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado de Amazon S3 en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Amazon y seleccione el conector de Amazon S3.
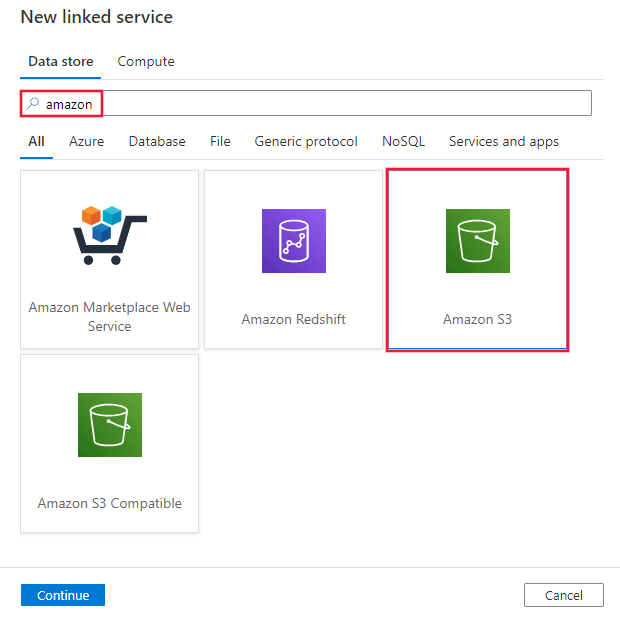
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
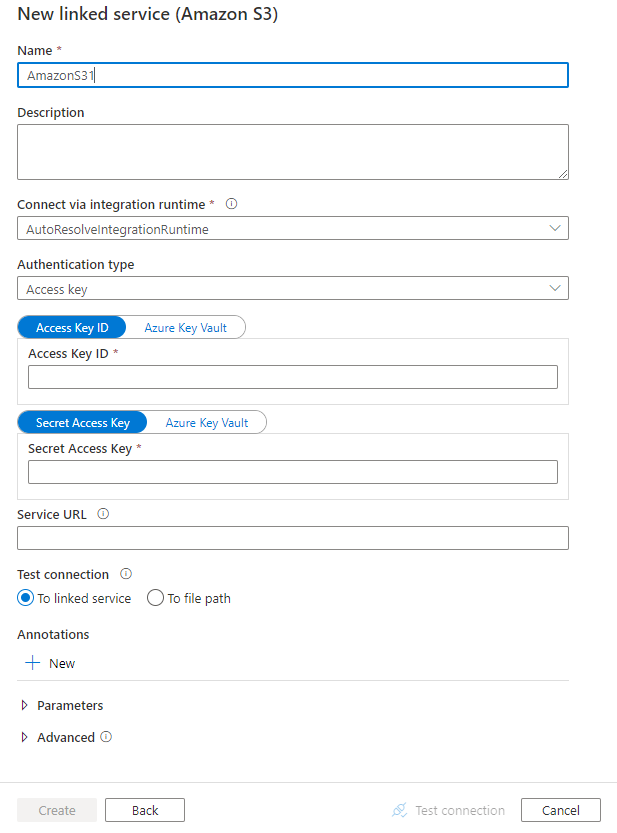

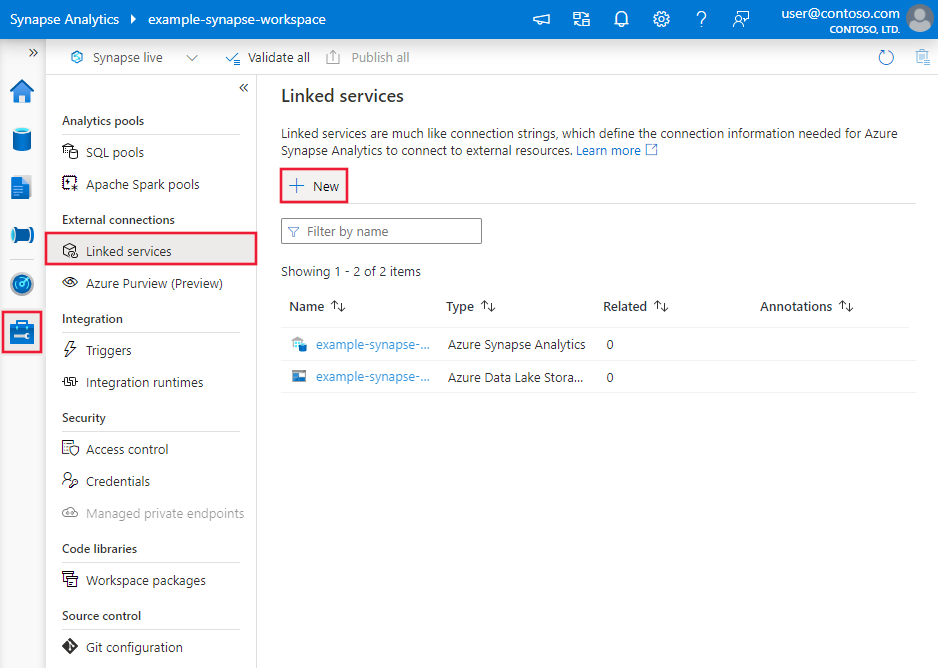
Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas de Amazon S3.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado de Amazon S3:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AmazonS3. | Sí |
| authenticationType | Especifique el tipo de autenticación empleado para conectarse a Amazon S3. Puede optar por usar las claves de acceso para una cuenta de administración de identidades y acceso (IAM) de AWS o credenciales de seguridad temporales. Los valores permitidos son: AccessKey (valor predeterminado) y TemporarySecurityCredentials. |
No |
| accessKeyId | Id. de la clave de acceso secreta. | Sí |
| secretAccessKey | La propia clave de acceso secreta. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí |
| SessionToken | Se aplica cuando se usa la autenticación con credenciales de seguridad temporales. Obtenga información sobre cómo solicitar credenciales de seguridad temporales de AWS. Tenga en cuenta que la credencial temporal de AWS expira al cabo de entre 15 minutos y 36 horas en función de la configuración. Asegúrese de que la credencial es válidas cuando se ejecuta la actividad, especialmente en el caso de la carga de trabajo operativa; por ejemplo, puede actualizarla periódicamente y almacenarla en Azure Key Vault. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. |
No |
| serviceUrl | Especifique el punto de conexión S3 personalizado https://<service url>.Cámbielo solo si quiere probar un punto de conexión de servicio diferente o quiere cambiar entre https y http. |
No |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado (si el almacén de datos está en una red privada). Si no se especifica esta propiedad, el servicio usa el valor predeterminado de Azure Integration Runtime. | No |
Ejemplo: uso de la autenticación mediante clave de acceso
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: uso de la autenticación mediante la credencial de seguridad temporal
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"authenticationType": "TemporarySecurityCredentials",
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"sessionToken": {
"type": "SecureString",
"value": "<session token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos.
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para Amazon S3 en la configuración location de un conjunto de datos basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type en la sección location de un conjunto de datos se debe establecer en AmazonS3Location. |
Sí |
| bucketName | Nombre del depósito de S3. | Sí |
| folderPath | Ruta de acceso a la carpeta del cubo especificado. Si quiere usar un carácter comodín para filtrar la carpeta, omita este valor y especifíquelo en la configuración del origen de actividad. | No |
| fileName | Nombre de archivo en el cubo y la ruta de acceso de la carpeta indicados. Si quiere usar un carácter comodín para filtrar archivos, omita este valor y especifíquelo en la configuración del origen de actividad. | No |
| version | La versión del objeto S3 si está habilitado el control de versiones de S3. Si no se especifica, se obtendrá la versión más reciente. | No |
Ejemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admite el origen de Amazon S3.
Amazon S3 como tipo de origen
Azure Data Factory admite los siguientes formatos de archivo. Consulte los artículos para conocer la configuración basada en el formato.
- Formato Avro
- Formato binario
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Las propiedades siguientes se admiten para Amazon S3 en la configuración storeSettings de un origen de la actividad de copia basado en formato:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de la sección storeSettings se debe establecer en AmazonS3ReadSettings. |
Sí |
| Buscar los archivos que se van a copiar: | ||
| OPCIÓN 1: ruta de acceso estática |
Realice la copia desde el cubo o la ruta de acceso de archivos o carpeta especificadas en el conjunto de datos. Si quiere copiar todos los archivos de un cubo o carpeta, especifique también wildcardFileName como *. |
|
| OPCIÓN 2: Prefijo S3 - prefix |
Prefijo del nombre de la clave de S3 en el cubo especificado que se configuró en el conjunto de datos para filtrar archivos de S3 de origen. Se seleccionan las claves de S3 cuyo nombre comienza con bucket_in_dataset/this_prefix. Emplea el filtro del servicio de S3, que proporciona un mejor rendimiento que el filtro de un carácter comodín.Al usar el prefijo y elegir copiar en el receptor basado en archivos con la opción de conservar la jerarquía, tenga en cuenta que la subruta de acceso después del último "/" en el prefijo se conserva. Por ejemplo, si tiene el archivo bucket/folder/subfolder/file.txt de origen y configura el prefijo como folder/sub, la ruta del archivo que se conserva es subfolder/file.txt. |
No |
| OPCIÓN 3: carácter comodín - wildcardFolderPath |
Ruta de acceso de carpeta con caracteres comodín en el cubo específico configurado en un conjunto de datos para filtrar las carpetas de origen. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre de la carpeta contiene un carácter comodín o este carácter de escape. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
No |
| OPCIÓN 3: carácter comodín - wildcardFileName |
Nombre de archivo con caracteres comodín en el cubo y la ruta de carpeta (o ruta de carpeta con carácter comodín) indicada para filtrar los archivos de origen. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter). Use ^ como escape si el nombre de archivo contiene un carácter comodín o este carácter de escape. Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. |
Sí |
| OPCIÓN 4: una lista de archivos - fileListPath |
Indica que se copie un conjunto de archivos determinado. Apunte a un archivo de texto que incluya una lista de los archivos que quiere copiar, con un archivo por línea, que sea la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos. Al usar esta opción, no especifique un nombre de archivo en el conjunto de datos. Ver más ejemplos en Ejemplos de lista de archivos. |
No |
| Configuración adicional: | ||
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Tenga en cuenta que cuando recursive se establece en true y el receptor es un almacén basado en archivos, no se crea una carpeta o una subcarpeta vacía en el receptor. Los valores permitidos son: True (valor predeterminado) y False. Esta propiedad no se aplica al configurar fileListPath. |
No |
| deleteFilesAfterCompletion | Indica si los archivos binarios se eliminarán del almacén de origen después de moverse correctamente al almacén de destino. Cada archivo se elimina individualmente, de modo que cuando se produzca un error en la actividad de copia, algunos archivos ya se habrán copiado al destino y se habrán eliminado del origen, mientras que otros seguirán aún en el almacén de origen. Esta propiedad solo es válida en el escenario de copia de archivos binarios. El valor predeterminado es false. |
No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a una zona horaria UTC en el formato "2018-12-01T05:00:00Z". Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora.Esta propiedad no se aplica al configurar fileListPath. |
No |
| modifiedDatetimeEnd | Igual que el anterior. | No |
| enablePartitionDiscovery | En el caso de archivos con particiones, especifique si quiere analizar las particiones de la ruta de acceso del archivo y agregarlas como columnas de origen adicionales. Los valores permitidos son false (valor predeterminado) y true. |
No |
| partitionRootPath | Cuando esté habilitada la detección de particiones, especifique la ruta de acceso raíz absoluta para poder leer las carpetas con particiones como columnas de datos. Si no se especifica, de forma predeterminada, - Cuando se usa la ruta de acceso de archivo en un conjunto de datos o una lista de archivos del origen, la ruta de acceso raíz de la partición es la ruta de acceso configurada en el conjunto de datos. - Cuando se usa el filtro de carpeta con caracteres comodín, la ruta de acceso raíz de la partición es la subruta antes del primer carácter comodín. - Cuando se usa un prefijo, la ruta de acceso raíz de la partición es la subruta antes del último "/". Por ejemplo, supongamos que configura la ruta de acceso en el conjunto de datos como "root/folder/year=2020/month=08/day=27": - Si especifica la ruta de acceso raíz de la partición como "root/folder/year=2020", la actividad de copia generará dos columnas más, month y day, con el valor "08" y "27", respectivamente, además de las columnas de los archivos.- Si no se especifica la ruta de acceso raíz de la partición, no se generará ninguna columna adicional. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3ReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplos de filtros de carpetas y archivos
Esta sección describe el comportamiento resultante de la ruta de acceso de la carpeta y el nombre de archivo con los filtros de carácter comodín.
| bucket | key | recursive | Resultado de estructura de carpeta de origen y filtro (se recuperan los archivos en negrita) |
|---|---|---|---|
| bucket | Folder*/* |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/* |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
false | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| bucket | Folder*/*.csv |
true | bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Ejemplos de lista de archivos
En esta sección se describe el comportamiento resultante de usar una ruta de acceso de la lista de archivos en un origen de la actividad de copia.
Suponga que tiene la siguiente estructura de carpetas de origen y quiere copiar los archivos en negrita:
| Estructura de origen de ejemplo | Contenido de FileListToCopy.txt | Configuración |
|---|---|---|
| bucket FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadatos FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
En el conjunto de datos: - Cubo: bucket- Ruta de acceso de la carpeta: FolderAEn el origen de la actividad de copia: - Ruta de acceso de la lista de archivos: bucket/Metadata/FileListToCopy.txt La ruta de acceso de la lista de archivos apunta a un archivo de texto en el mismo almacén de datos que incluye una lista de los archivos que se quieren copiar, con un archivo por línea, con la ruta de acceso relativa a la ruta de acceso configurada en el conjunto de datos. |
Conservación de los metadatos durante la copia
Al copiar archivos de Amazon S3 en Azure Data Lake Storage Gen2 o Azure Blob Storage, puede optar por conservar los metadatos de archivo junto con los datos. Más información en Conservación de metadatos.
Propiedades de Asignación de instancias de Data Flow
Al transformar datos de flujos de datos de asignación, puede leer archivos de Amazon S3 en los siguientes formatos:
La configuración específica de formato se encuentra en la documentación de ese formato. Para obtener más información, vea Transformación de origen en flujo de datos de asignación.
Transformación de origen
En la transformación de origen puede leer de un contenedor, una carpeta o un archivo individual de Amazon S3. Use la pestaña Opciones de origen para administrar cómo se leen los archivos.
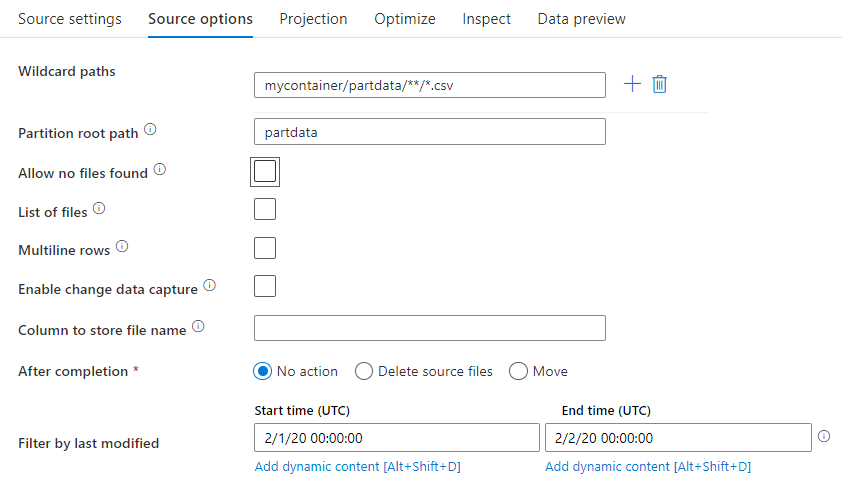
Rutas con carácter comodín: el uso de un patrón de caracteres comodín indicará al servicio que recorra todos los archivos y carpetas que coincidan en una única transformación del origen. Se trata de una manera eficaz de procesar varios archivos en un único flujo. Agregue varios patrones de coincidencia de caracteres comodín con el signo más que aparece al desplazar el puntero sobre el patrón de caracteres comodín existente.
En el contenedor de origen, elija una serie de archivos que coincidan con un patrón. Solo se puede especificar un contenedor en el conjunto de datos. La ruta de acceso con carácter comodín, por tanto, también debe incluir la ruta de acceso de la carpeta de la carpeta raíz.
Ejemplos de caracteres comodín:
*Representa cualquier conjunto de caracteres.**Representa el anidamiento recursivo de directorios.?Reemplaza un carácter.[]Coincide con al menos uno de los caracteres entre corchetes./data/sales/**/*.csvObtiene todos los archivos .csv que se encuentran en /data/sales./data/sales/20??/**/Obtiene todos los archivos del siglo XX./data/sales/*/*/*.csvObtiene los archivos .csv dos niveles debajo de /data/sales./data/sales/2004/*/12/[XY]1?.csvObtiene todos los archivos .csv de diciembre de 2004 que comienzan con X o Y precedido por un número de dos dígitos.
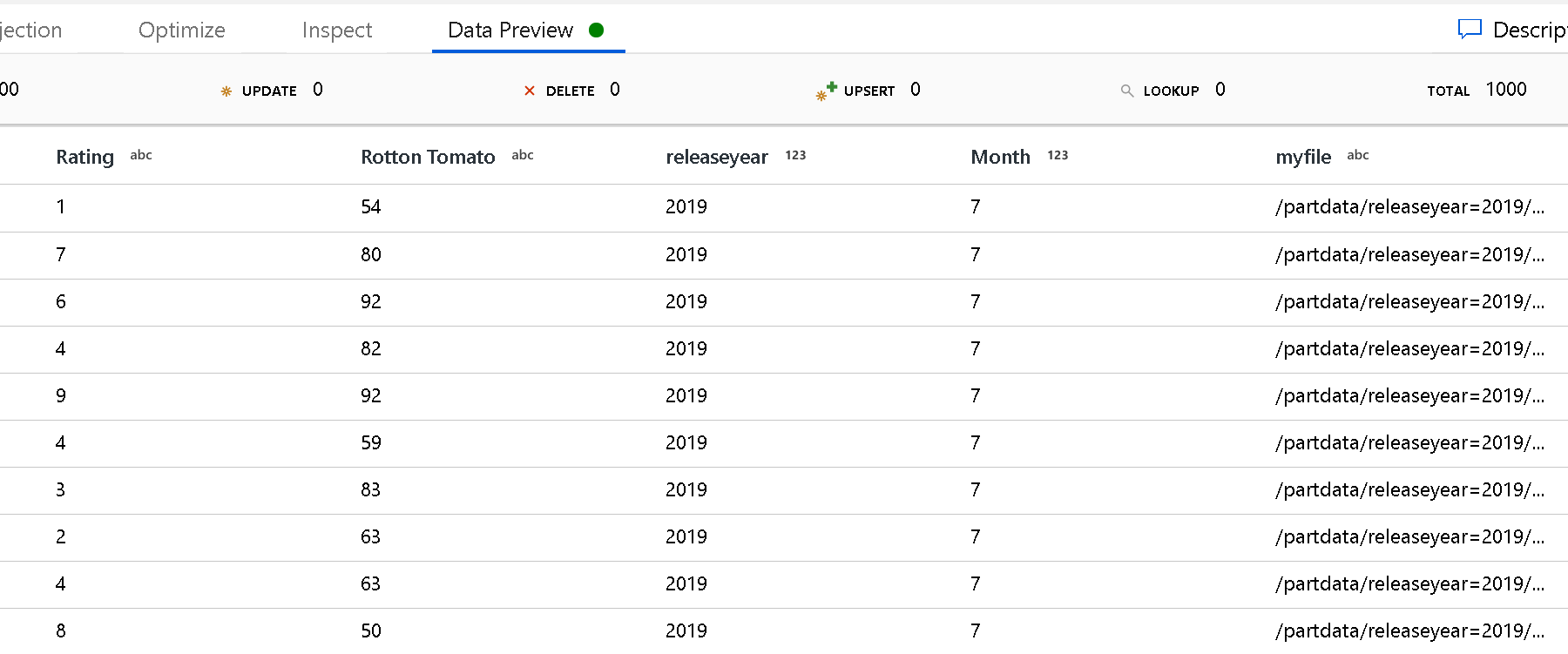
Ruta de acceso raíz de la partición: si tiene carpetas con particiones en el origen de archivo con formato key=value (por ejemplo, year=2019), puede asignar el nivel superior del árbol de carpetas de la partición a un nombre de columna del flujo de datos.
En primer lugar, establezca un comodín que incluya todas las rutas de acceso que sean carpetas con particiones y, además, los archivos de hoja que quiera leer.
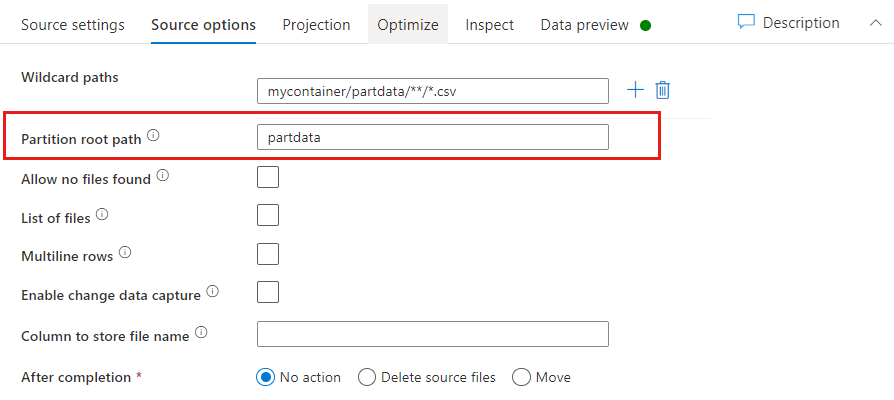
Use el valor de Partition root path (Ruta de acceso de la raíz de la partición) para definir cuál es el nivel superior de la estructura de carpetas. Cuando vea el contenido de los datos mediante una vista previa, verá que el servicio agregará las particiones resueltas que se encuentran en cada uno de los niveles de carpeta.
Lista de archivos: Se trata de un conjunto de archivos. Cree un archivo de texto que incluya una lista de archivos de ruta de acceso relativa para procesar. Apunte a este archivo de texto.
Column to store file name: (Columna para almacenar el nombre de archivo) Almacene el nombre del archivo de origen en una columna de los datos. Escriba aquí el nombre de una nueva columna para almacenar la cadena de nombre de archivo.
After completion: (Tras finalizar) Elija no hacer nada con el archivo de origen después de que se ejecute el flujo de datos o bien elimine o mueva el archivo de origen. Las rutas de acceso para mover los archivos de origen son relativas.
Para mover archivos de origen a otra ubicación posterior al procesamiento, primero seleccione "Mover" para la operación de archivo. A continuación, establezca el directorio "from". Si no usa ningún carácter comodín para la ruta de acceso, la configuración de "from" será la misma carpeta que la carpeta de origen.
Si tiene una ruta de acceso de origen con un comodín, su sintaxis será así:
/data/sales/20??/**/*.csv
Puede especificar "from" como:
/data/sales
Y puede especificar "to" como:
/backup/priorSales
En este caso, todos los archivos cuyo origen se encuentra en /data/sales se mueven a /backup/priorSales.
Nota
Las operaciones de archivo solo se ejecutan cuando el flujo de datos se inicia desde una ejecución de canalización (depuración o ejecución de canalización) que usa la actividad de ejecución de Data Flow de una canalización. Las operaciones de archivo no se ejecutan en modo de depuración de Data Flow.
Filter by last modified: (Filtrar últimos modificados) Puede filtrar los archivos que desea procesar especificando un intervalo de fechas de la última vez que se modificaron. Todos los valores datetime están en formato UTC.
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte la actividad GetMetadata.
Propiedades de la actividad de eliminación
Para información detallada sobre las propiedades, consulte Actividad de eliminación.
Modelos heredados
Nota
Estos modelos siguen siendo compatibles con versiones anteriores. Se recomienda usar el nuevo modelo mencionado anteriormente. La interfaz de usuario de creación se ha cambiado para generar el nuevo modelo.
Modelo de conjunto de datos heredado
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en 8AmazonS3Object. | Sí |
| bucketName | Nombre del depósito de S3. No se admite el filtros con caracteres comodín. | Sí, para la actividad de copia o búsqueda; no, para la actividad GetMetadata |
| key | El filtro de nombre o de carácter comodín de la clave del objeto S3 del cubo especificado. Solo se aplica cuando no se especifica la propiedad prefix. El filtro de comodín se admite tanto para el elemento de carpeta como para el elemento del nombre de archivo. Los caracteres comodín permitidos son: * (equivale a cero o a varios caracteres) y ? (equivale a cero o a un único carácter).- Ejemplo 1: "key": "rootfolder/subfolder/*.csv"- Ejemplo 2: "key": "rootfolder/subfolder/???20180427.txt"Ver más ejemplos en Ejemplos de filtros de carpetas y archivos. Use ^ como escape si el nombre real de la carpeta o archivo contiene un carácter comodín o este carácter de escape. |
No |
| prefix | Prefijo de la clave del objeto S3. Se seleccionan objetos cuyas claves comienzan por este prefijo. Solo se aplica cuando no se especifica la propiedad key. | No |
| version | La versión del objeto S3 si está habilitado el control de versiones de S3. Si no se especifica una versión, se obtendrá la más reciente. | No |
| modifiedDatetimeStart | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato "2018-12-01T05:00:00Z". Tenga en cuenta que al habilitar esta configuración se verá afectado el rendimiento general del movimiento de datos cuando quiera filtrar grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora. |
No |
| modifiedDatetimeEnd | Los archivos se filtran en función del atributo Last Modified. Los archivos se seleccionarán si la hora de la última modificación es mayor o igual que modifiedDatetimeStart y menor que modifiedDatetimeEnd. La hora se aplica a la zona horaria UTC en el formato "2018-12-01T05:00:00Z". Tenga en cuenta que al habilitar esta configuración se verá afectado el rendimiento general del movimiento de datos cuando quiera filtrar grandes cantidades de archivos. Las propiedades pueden ser NULL, lo que significa que no se aplica ningún filtro de atributo de archivo al conjunto de datos. Cuando modifiedDatetimeStart tiene un valor de fecha y hora, pero modifiedDatetimeEnd es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea mayor o igual que el valor de fecha y hora. Cuando modifiedDatetimeEnd tiene un valor de fecha y hora, pero modifiedDatetimeStart es NULL, significa que se seleccionarán los archivos cuyo último atributo modificado sea menor que el valor de fecha y hora. |
No |
| format | Si quiere copiar los archivos tal cual entre los almacenes basados en archivos (copia binaria), omita la sección de formato en las definiciones de los conjuntos de datos de entrada y salida. Si quiere analizar o generar archivos con un formato concreto, se admiten los siguientes tipos de formato de archivo: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Establezca la propiedad type en format en uno de los siguientes valores. Para más información, consulte las secciones Formato de texto, Formato JSON, Formato AVRO, Formato ORC y Formato Parquet. |
No (solo para el escenario de copia binaria) |
| compression | Especifique el tipo y el nivel de compresión de los datos. Para más información, consulte el artículo sobre códecs de compresión y formatos de archivo compatibles. Los tipos admitidos son GZip, Deflate, BZip2 y ZipDeflate. Niveles admitidos son Optimal y Fastest. |
No |
Sugerencia
Para copiar todos los archivos en una carpeta, especifique bucketName para el cubo y prefix para el elemento de carpeta.
Para copiar un único archivo con un nombre determinado, especifique bucketName para el cubo y key para el elemento de carpeta más el nombre del archivo.
Para copiar un subconjunto de archivos en una carpeta, especifique bucketName para el cubo y key para el elemento de carpeta más el filtro de comodín.
Ejemplo: uso de prefijo
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3Object",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"prefix": "testFolder/test",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Ejemplo: uso de clave y versión (opcional)
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"key": "testFolder/testfile.csv.gz",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origen heredado para la actividad de copia
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en FileSystemSource. | Sí |
| recursive | Indica si los datos se leen de forma recursiva de las subcarpetas o solo de la carpeta especificada. Tenga en cuenta que cuando recursive esté establecido en true y el receptor sea un almacén basado en archivos, no se copiará ni creará una subcarpeta o carpeta vacía en el receptor. Los valores permitidos son: True (valor predeterminado) y False. |
No |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
Ejemplo:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon S3 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Contenido relacionado
Para obtener una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos admitidos.