Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
En este artículo se describe cómo usar la actividad de copia en canalizaciones de Azure Data Factory o Synapse para copiar datos de y a Azure Synapse Analytics y usar Data Flow para transformar datos en Azure Data Lake Storage Gen2. Para obtener información sobre Azure Data Factory, lea el artículo introductory.
Funcionalidades admitidas
Este conector Azure Synapse Analytics se admite para las siguientes funcionalidades:
| Funcionalidades admitidas | IR | Punto de conexión privado administrado |
|---|---|---|
| Actividad de copia (origen/receptor) | 1 2 | ✓ |
| Flujo de datos de asignación (origen/receptor) | ① | ✓ |
| Actividad de búsqueda | 1 2 | ✓ |
| Actividad GetMetadata | 1 2 | ✓ |
| Actividad de script | 1 2 | ✓ |
| Actividad de procedimiento almacenado | 1 2 | ✓ |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Para Copy activity, este conector de Azure Synapse Analytics admite estas funciones:
- Copiar datos mediante la autenticación con SQL y la autenticación de tokens de aplicaciones de Microsoft Entra con una entidad de servicio o identidades administradas para recursos de Azure.
- Como origen, la recuperación de datos mediante una consulta SQL o un procedimiento almacenado. También puede elegir copiar en paralelo desde un origen de Azure Synapse Analytics, consulte la sección Parallel copy from Azure Synapse Analytics para obtener más información.
- Como receptor, la carga de datos mediante la instrucción COPY, PolyBase o la inserción masiva. Se recomienda usar la instrucción COPY o PolyBase para conseguir un mejor rendimiento de la copia. El conector también admite la creación automática de la tabla de destino con DISTRIBUTION = ROUND_ROBIN, si no existe, en función del esquema de origen.
Importante
Si copia datos mediante un Azure Integration Runtime, configure una regla de firewall a nivel de servidor para que los servicios de Azure puedan acceder al servidor SQL lógico. Si copia los datos mediante un entorno de ejecución de integración autohospedado, configure el firewall para permitir el intervalo IP apropiado. Este intervalo incluye la dirección IP de la máquina que se usa para conectarse a Azure Synapse Analytics.
Primeros pasos
Sugerencia
Para lograr el mejor rendimiento, use la instrucción PolyBase o COPY para cargar datos en Azure Synapse Analytics. Las secciones Uso de PolyBase para cargar datos en Azure Synapse Analytics y Uso de la instrucción COPY para cargar datos en Azure Synapse Analytics tienen detalles. Para ver un tutorial con un caso de uso, consulte Load 1 TB en Azure Synapse Analytics en menos de 15 minutos con Azure Data Factory.
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- Herramienta Copiar datos
- Azure Portal
- SDK de .NET
- SDK de Python
- Azure PowerShell
- REST API
- plantilla Azure Resource Manager
Creación de un servicio vinculado Azure Synapse Analytics mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado Azure Synapse Analytics en la interfaz de usuario del portal de Azure.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados y haga clic en Nuevo:
Busque Synapse y seleccione el conector Azure Synapse Analytics.
Configure los detalles del servicio, pruebe la conexión y cree el servicio vinculado.

Detalles de configuración del conector
En las secciones siguientes se proporcionan detalles sobre las propiedades que definen las entidades de canalización de Data Factory y Synapse específicas de un conector de Azure Synapse Analytics.
Propiedades del servicio vinculado
El conector de Azure Synapse Analytics versión Recomendada admite TLS 1.3. Consulte esta sección para actualizar la versión del conector de Azure Synapse Analytics desde heredado. Para obtener los detalles de la propiedad, consulte las secciones correspondientes.
Sugerencia
Al crear un servicio vinculado para un grupo de SQL de tipo serverless en Azure Synapse desde el portal de Azure:
- En Account selection method (Método de selección de cuenta), elija Indicar manualmente.
- Pegue el nombre de dominio completo del punto de conexión sin servidor. Puede encontrarlo en la página de Información General del portal de Azure para su área de trabajo de Synapse, en las propiedades bajo Punto de Conexión SQL sin Servidor. Por ejemplo,
myserver-ondemand.sql-azuresynapse.net. - En Nombre de base de datos, proporcione el nombre de la base de datos en el grupo de SQL sin servidor.
Sugerencia
Si se produce un error con código de error como "UserErrorFailedToConnectToSqlServer" y mensaje como "El límite de sesión de la base de datos es XXX y se ha alcanzado"., agregue Pooling=false a la connection string e inténtelo de nuevo.
Versión recomendada
Estas propiedades genéricas se admiten para un servicio vinculado de Azure Synapse Analytics cuando se aplica la versión Recomendada:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureSqlDW. | Sí |
| server | Nombre o dirección de red de la instancia de SQL Server a la que desea conectarse. | Sí |
| database | El nombre de la base de datos. | Sí |
| authenticationType | Tipo usado para la autenticación. Los valores permitidos son SQL (valor predeterminado), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Ve a la sección de autenticación pertinente sobre propiedades y requisitos previos específicos. | Sí |
| encrypt | Indica si se requiere cifrado TLS para todos los datos enviados entre el cliente y el servidor. Opciones: obligatorio (para true, valor predeterminado)/opcional (para falso)/restringido. | No |
| trustServerCertificate | Indique si el canal se cifrará al pasar la cadena de certificados para validar la confianza. | No |
| hostNameInCertificate | Nombre de host que se va a usar al validar el certificado de servidor para la conexión. Cuando no se especifica, el nombre del servidor se usa para la validación de certificados. | No |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Puede usar Azure Integration Runtime o un runtime de integración autohospedado (si el almacén de datos se encuentra en una red privada). Si no se especifica, usa el Azure Integration Runtime predeterminado. | No |
Para obtener más propiedades de conexión, consulte la tabla siguiente:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| applicationIntent | Tipo de carga de trabajo de aplicación al conectarse a un servidor. Los valores permitidos son ReadOnly y ReadWrite. |
No |
| connectTimeout | El período de tiempo (en segundos) que se espera a una conexión al servidor antes de finalizar el intento y generar un error. | No |
| connectRetryCount | Número de reconexión intentadas después de identificar un error de conexión inactiva. El valor debe ser un número entero entre 0 y 255. | No |
| connectRetryInterval | Cantidad de tiempo (en segundos) entre cada intento de reconexión después de identificar un error de conexión inactiva. El valor debe ser un entero entre 1 y 60. | No |
| loadBalanceTimeout | Tiempo mínimo (en segundos) para que la conexión resida en el grupo de conexiones antes de que se destruya la conexión. | No |
| commandTimeout | Tiempo de espera predeterminado (en segundos) antes de terminar el intento de ejecutar un comando y generar un error. | No |
| integratedSecurity | Los valores permitidos son true o false. Al especificar false, indique si userName y contraseña se especifican en la conexión. Al especificar true, indica si se usan las credenciales de cuenta de Windows actuales para la autenticación. |
No |
| failoverPartner | Nombre o dirección del servidor asociado al que se va a conectar si el servidor principal está inactivo. | No |
| maxPoolSize | Número máximo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| minPoolSize | Número mínimo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| multipleActiveResultSets | Los valores permitidos son true o false. Al especificar true, una aplicación puede mantener conjunto de resultados activo múltiple (MARS). Al especificar false, una aplicación debe procesar o cancelar todos los conjuntos de resultados de un lote para poder ejecutar cualquier otro lote en esa conexión. |
No |
| multiSubnetFailover | Los valores permitidos son true o false. Si la aplicación se conecta a un grupo de disponibilidad AlwaysOn (AG) en subredes diferentes, establecer esta propiedad en true proporciona una detección y conexión más rápidas con el servidor activo actualmente. |
No |
| packetSize | Tamaño en bytes de los paquetes de red usados para comunicarse con una instancia de servidor. | No |
| pooling | Los valores permitidos son true o false. Al especificar true, la conexión se agrupará. Al especificar false, la conexión se abrirá explícitamente cada vez que se solicite la conexión. |
No |
Autenticación SQL
Para usar la autenticación de SQL, además de las propiedades genéricas que se describen en la sección anterior, especifique las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| userName | Nombre de usuario usado para conectarse al servidor. | Sí |
| password | Contraseña del nombre de usuario. Marque este campo como SecureString para almacenarlo de forma segura. O bien, puede referenciar un secreto almacenado en Azure Key Vault. | Sí |
Ejemplo: uso de la autenticación de SQL
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: contraseña en Azure Key Vault
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de entidad de servicio
Para usar la autenticación de la entidad de servicio, además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalCredential | Credencial de entidad de servicio. Especifique la clave de la aplicación. Marque este campo como SecureString almacenarlo de forma segura o referenciar un secreto almacenado en Azure Key Vault. | Sí |
| tenant | Especifique la información del inquilino (nombre de dominio o identificador de inquilino) en el que reside la aplicación. Para recuperarlo, mantenga el mouse en la esquina superior derecha del portal de Azure. | Sí |
| azureCloudType | Para la autenticación de entidad de servicio, especifique el tipo de entorno en la nube de Azure al que está registrada la aplicación Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno en la nube de la canalización de Data Factory o Synapse. |
No |
También debe seguir los pasos siguientes:
Crear una aplicación de Microsoft Entra desde el portal de Azure. Anote el nombre de la aplicación y los siguientes valores, que definen el servicio vinculado:
- Identificador de aplicación
- Clave de la aplicación
- Id. de inquilino
Provisionar un administrador de Microsoft Entra para el servidor en el portal de Azure si aún no lo ha hecho. El administrador de Microsoft Entra puede ser un usuario Microsoft Entra o un grupo de Microsoft Entra. Si concede al grupo con identidad administrada un rol de administrador, omita los pasos 3 y 4. El administrador tendrá acceso completo a la base de datos.
Cree usuarios de bases de datos independientes para la entidad de servicio. Conéctese al almacenamiento de datos del que desea copiar datos (o en el que desea copiarlos) mediante alguna herramienta como SSMS, con una identidad de Microsoft Entra que tenga al menos el permiso ALTER ANY USER. Ejecute el T-SQL siguiente:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Conceda a la entidad de servicio los permisos necesarios, tal como lo haría normalmente para los usuarios de SQL, u otros usuarios. Ejecute el siguiente código, o consulte más opciones aquí. Si desea usar PolyBase para cargar los datos, infórmese sobre el permiso de base de datos necesario.
EXEC sp_addrolemember db_owner, [your application name];Configurar un servicio vinculado Azure Synapse Analytics en un área de trabajo de Azure Data Factory o Synapse.
Ejemplo de servicio vinculado que usa la autenticación de entidad de servicio
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Identidades administradas asignadas por el sistema para la autenticación de recursos de Azure
Una factoría de datos o un área de trabajo de Synapse se pueden asociar a una identidad administrada asignada por el sistema para los recursos de Azure que representa el recurso. Puede usar esta identidad administrada para Azure Synapse Analytics autenticación. Con esta identidad, el recurso designado puede acceder a la base de datos y copiar datos de o en ella.
Para usar la autenticación de identidad administrada asignada por el sistema, especifique las propiedades genéricas que se describen en la sección anterior y siga estos pasos.
Provisionar un administrador de Microsoft Entra para el servidor en el portal de Azure si aún no lo ha hecho. El administrador de Microsoft Entra puede ser un usuario Microsoft Entra o un grupo de Microsoft Entra. Si concede al grupo con identidad administrada asignada por el sistema un rol de administrador, omita los pasos 3 y 4. El administrador tendrá acceso completo a la base de datos.
Cree usuarios de bases de datos independientes para la identidad administrada asignada por el sistema. Conéctese al almacenamiento de datos del que desea copiar datos (o en el que desea copiarlos) mediante alguna herramienta como SSMS, con una identidad de Microsoft Entra que tenga al menos el permiso ALTER ANY USER. Ejecute el siguiente T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Conceda a la identidad administrada asignada por el sistema los permisos necesarios, tal como lo haría normalmente para los usuarios de SQL y otros usuarios. Ejecute el siguiente código, o consulte más opciones aquí. Si desea usar PolyBase para cargar los datos, infórmese sobre el permiso de base de datos necesario.
EXEC sp_addrolemember db_owner, [your_resource_name];Configurar un servicio vinculado Azure Synapse Analytics.
Ejemplo:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el usuario
Un área de trabajo de Data Factory o de Synapse se puede asociar con una identidad administrada asignada por el usuario que represente el recurso. Puede usar esta identidad administrada para Azure Synapse Analytics autenticación. Con esta identidad, el recurso designado puede acceder a la base de datos y copiar datos de o en ella.
Para usar la autenticación de identidad administrada asignada por el usuario, además de las propiedades genéricas descritas en la sección anterior, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
También debe seguir los pasos siguientes:
Provisionar un administrador de Microsoft Entra para el servidor en el portal de Azure si aún no lo ha hecho. El administrador de Microsoft Entra puede ser un usuario Microsoft Entra o un grupo de Microsoft Entra. Si concede al grupo con identidad administrada asignada por el usuario un rol de administrador, omita el paso 3. El administrador tendrá acceso completo a la base de datos.
Cree usuarios de bases de datos independientes para la identidad administrada asignada por el usuario. Conéctese al almacenamiento de datos del que desea copiar datos (o en el que desea copiarlos) mediante alguna herramienta como SSMS, con una identidad de Microsoft Entra que tenga al menos el permiso ALTER ANY USER. Ejecute el siguiente T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Cree una o varias identidades administradas asignadas por el usuario y conceda a la identidad administrada asignada por el usuario los permisos necesarios como haría normalmente para usuarios SQL y otros. Ejecute el siguiente código, o consulte más opciones aquí. Si desea usar PolyBase para cargar los datos, infórmese sobre el permiso de base de datos necesario.
EXEC sp_addrolemember db_owner, [your_resource_name];Asigne una o varias identidades administradas asignadas por el usuario a la factoría de datos y cree credenciales para cada identidad.
Configurar un servicio vinculado Azure Synapse Analytics.
Ejemplo
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versión heredada
Estas propiedades genéricas son compatibles con un servicio vinculado de Azure Synapse Analytics cuando se aplica la versión Legacy:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureSqlDW. | Sí |
| connectionString | Especifique la información necesaria para conectarse a la instancia de Azure Synapse Analytics para la propiedad connectionString. Marque este campo como SecureString para almacenarlo de forma segura. También puede colocar la clave de contraseña o entidad de servicio en Azure Key Vault y si se trata de la autenticación de SQL, extraiga la configuración de password fuera de la cadena de conexión. Consulte el artículo Store credentials in Azure Key Vault para más detalles. |
Sí |
| connectVia | El entorno de ejecución de integración que se usará para conectarse al almacén de datos. Puede usar Azure Integration Runtime o un runtime de integración autohospedado (si el almacén de datos se encuentra en una red privada). Si no se especifica, usa el Azure Integration Runtime predeterminado. | No |
Para los distintos tipos de autenticación, consulte las secciones siguientes sobre propiedades y requisitos previos específicos, respectivamente:
- Autenticación de SQL para la versión heredada
- Autenticación de entidad de servicio para la versión heredada
- Autenticación de identidad administrada asignada por el sistema para la versión heredada
- Autenticación de identidad administrada asignada por el usuario para la versión heredada
Autenticación de SQL para la versión heredada
Para usar la autenticación de SQL, especifique las propiedades genéricas que se describen en la sección anterior.
Autenticación de entidad de servicio para la versión heredada
Para usar la autenticación de la entidad de servicio, además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalKey | Especifique la clave de la aplicación. Marque este campo como SecureString para almacenarlo de forma segura o referenciar un secreto almacenado en Azure Key Vault. | Sí |
| tenant | Especifique la información del inquilino, como el nombre de dominio o identificador de inquilino, en el que reside la aplicación. Para recuperarlo, mantenga el mouse en la esquina superior derecha del portal de Azure. | Sí |
| azureCloudType | Para la autenticación de entidad de servicio, especifique el tipo de entorno en la nube de Azure al que está registrada la aplicación Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno en la nube de la canalización de Data Factory o Synapse. |
No |
También debe seguir los pasos descritos en Autenticación de la entidad de servicio para conceder el permiso correspondiente.
Autenticación de identidad administrada asignada por el sistema para la versión heredada
Para usar la autenticación de identidad administrada asignada por el sistema, siga el mismo paso para la versión recomendada en Autenticación de identidad administrada asignada por el sistema.
Autenticación de identidad administrada asignada por el usuario para la versión heredada
Para usar la autenticación de identidad administrada asignada por el usuario, siga el mismo paso para la versión recomendada en Autenticación de identidad administrada asignada por el usuario.
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos.
Se admiten las siguientes propiedades para Azure Synapse Analytics conjunto de datos:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en AzureSqlDWTable. | Sí |
| esquema | Nombre del esquema. | No para el origen, sí para el receptor |
| table | Nombre de la tabla o vista. | No para el origen, sí para el receptor |
| tableName | Nombre de la tabla o vista con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Para la nueva carga de trabajo use schema y table. |
No para el origen, sí para el receptor |
Ejemplo de propiedades de un conjunto de datos
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades admitidas por el origen y el receptor de Azure Synapse Analytics.
Azure Synapse Analytics como origen
Sugerencia
Para cargar datos desde Azure Synapse Analytics de forma eficaz mediante la partición de datos, obtenga más información en Copia paralela desde Azure Synapse Analytics.
Para copiar datos de Azure Synapse Analytics, establezca la propiedad type en el origen de la actividad de copia en SqlDWSource. La sección source de la actividad de copia admite las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en SqlDWSource. | Sí |
| sqlReaderQuery | Use la consulta SQL personalizada para leer los datos. Ejemplo: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Nombre del procedimiento almacenado que lee datos de la tabla de origen. La última instrucción SQL debe ser una instrucción SELECT del procedimiento almacenado. | No |
| storedProcedureParameters | Parámetros del procedimiento almacenado. Los valores permitidos son pares de nombre o valor. Los nombres y las mayúsculas y minúsculas de los parámetros deben coincidir con las mismas características de los parámetros de procedimiento almacenado. |
No |
| isolationLevel | Especifica el comportamiento de bloqueo de transacción para el origen de SQL. Los valores permitidos son: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable y Snapshot. Si no se especifica, se usa el nivel de aislamiento predeterminado de la base de datos. Para obtener más información, consulte system.data.isolationlevel. | No |
| partitionOptions | Especifica las opciones de creación de particiones de datos que se usan para cargar datos de Azure Synapse Analytics. Los valores permitidos son: Ninguno (por defecto), PhysicalPartitionsOfTable, y DynamicRange. Cuando se habilita una opción de partición (es decir, no None), el grado de paralelismo para cargar datos simultáneamente desde un Azure Synapse Analytics se controla mediante la configuración de parallelCopies en la actividad de copia. |
No |
| partitionSettings | Especifique el grupo de configuración para la creación de particiones de datos. Se aplica si la opción de partición no es None. |
No |
En partitionSettings: |
||
| partitionColumnName | Especifique el nombre de la columna de origen de tipo entero o date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) que se va a usar en la creación de particiones por rangos para la copia en paralelo. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición.Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?DfDynamicRangePartitionCondition en la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionUpperBound | Valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionLowerBound | Valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
Tenga en cuenta el punto siguiente:
- Al usar el procedimiento almacenado del origen para recuperar datos, tenga en cuenta que, si está diseñado para devolver otro esquema cuando se pasa un valor de parámetro diferente, es posible que encuentre un error o vea un resultado inesperado al importar el esquema desde la interfaz de usuario, o bien al copiar datos en la base de datos SQL con la creación automática de tablas.
Ejemplo: con la consulta SQL
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplo: con el procedimiento almacenado
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplo de procedimiento almacenado:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics como vínculo
Azure Data Factory y canalizaciones de Synapse admiten tres maneras de cargar datos en Azure Synapse Analytics.
- Uso de la instrucción COPY
- Usar PolyBase
- Usar Inserción masiva
La forma más rápida y escalable de cargar datos es hacerlo mediante la instrucción CPOY o PolyBase.
Para copiar datos en Azure Synapse Analytics, establezca el tipo de receptor de la actividad de copia en SqlDWSink. La sección sink de la actividad de copia admite las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en SqlDWSink. | Sí |
| allowPolyBase | Indica si se debe usar PolyBase para cargar datos en Azure Synapse Analytics.
allowCopyCommand y allowPolyBase no pueden ser true. Consulte Use PolyBase para cargar datos en Azure Synapse Analytics sección para ver las restricciones y los detalles. Los valores válidos son True y False (valor predeterminado). |
No. Se aplica cuando se usa PolyBase. |
| polyBaseSettings | Un grupo de propiedades que se pueden especificar cuando el valor de la propiedad allowPolybase está establecido en true. |
No. Se aplica cuando se usa PolyBase. |
| allowCopyCommand | Indica si se va a usar la instrucción COPY para cargar datos en Azure Synapse Analytics.
allowCopyCommand y allowPolyBase no pueden ser true. Consulte la sección "Use la instrucción COPY para cargar datos en Azure Synapse Analytics" para ver las restricciones y los detalles. Los valores válidos son True y False (valor predeterminado). |
No. Se aplica cuando se usa COPY. |
| copyCommandSettings | Un grupo de propiedades que se pueden especificar cuando el valor de la propiedad allowCopyCommand está establecido en TRUE. |
No. Se aplica cuando se usa COPY. |
| writeBatchSize | Número de filas que se va a insertar en la tabla SQL por lote. El valor que se permite es un entero (número de filas). De manera predeterminada, el servicio determina dinámicamente el tamaño adecuado del lote en función del tamaño de fila. |
No. Se aplica cuando se usa la inserción masiva. |
| writeBatchTimeout | El tiempo de espera para que se complete la operación de inserción, upsert y el procedimiento almacenado antes de que se agote el tiempo de espera. Los valores permitidos son para el intervalo de tiempo. Un ejemplo es "00:30:00" para 30 minutos. Si no se especifica ningún valor, el valor predeterminado es "00:30:00". |
No. Se aplica cuando se usa la inserción masiva. |
| preCopyScript | Especifique una consulta SQL para que se ejecute la actividad de copia antes de escribir datos en Azure Synapse Analytics en cada ejecución. Esta propiedad se usa para limpiar los datos cargados previamente. | No |
| tableOption | Especifica si se crea automáticamente la tabla de receptores según el esquema de origen, si no existe. Los valores permitidos son: none (valor predeterminado), autoCreate. |
No |
| disableMetricsCollection | El servicio recopila métricas como los DWUs de Azure Synapse Analytics para la optimización del rendimiento de copia y recomendaciones, lo que introduce la necesidad de un acceso adicional a la base de datos maestra. Si le preocupa este comportamiento, especifique true para desactivarlo. |
No (el valor predeterminado es false) |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
| WriteBehavior | Especifique el comportamiento de escritura de la actividad de copia para cargar datos en Azure Synapse Analytics. El valor permitido es Inserty Upsert. De forma predeterminada, el servicio usa Insert para cargar los datos. |
No |
| Configuración de "Upsert" (actualizar/insertar) | Especifique el grupo de la configuración para el comportamiento de escritura. Se aplica cuando la opción WriteBehavior es Upsert. |
No |
En upsertSettings: |
||
| claves | Especifique los nombres de columna para la identificación de fila única. Se puede usar una sola clave o una serie de claves. Si no se especifica, se usa la clave principal. | No |
| interimSchemaName | Especifique el esquema provisional para crear una tabla provisional. Nota: El usuario debe tener el permiso para crear y eliminar tablas. De forma predeterminada, la tabla provisional compartirá el mismo esquema que la tabla receptora. | No |
Ejemplo 1: Receptor de Azure Synapse Analytics
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Ejemplo 2: Datos de Upsert
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Copia en paralelo desde Azure Synapse Analytics
El conector de Azure Synapse Analytics en la actividad de copia ofrece particionamiento de datos integrado para copiar datos en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.
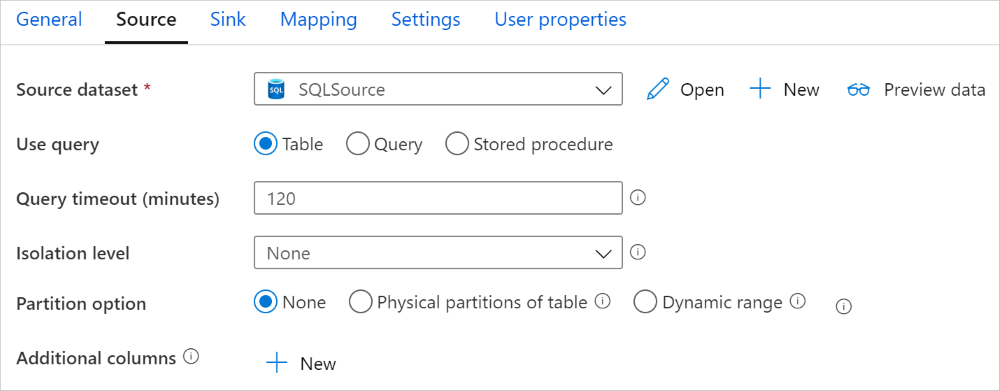
Al habilitar la copia con particiones, la actividad de copia ejecuta consultas paralelas en el origen de Azure Synapse Analytics para cargar datos por particiones. El grado en paralelo se controla mediante el valor parallelCopies de la actividad de copia. Por ejemplo, si establece parallelCopies en cuatro, el servicio genera y ejecuta simultáneamente cuatro consultas en función de la configuración y la opción de partición especificadas, y cada consulta recupera una parte de los datos de la Azure Synapse Analytics.
Se recomienda habilitar la copia en paralelo con la creación de particiones de datos, especialmente cuando se carga una gran cantidad de datos de la Azure Synapse Analytics. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. |
Opción de partición: Particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. Para comprobar si la tabla tiene una partición física o no, puede hacer referencia a esta consulta. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de tipo entero o datetime para la creación de particiones de datos. |
Opciones de partición: partición de intervalo dinámico. Columna de partición (opcional): especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de índice o clave principal. Partición de límite superior y partición de límite inferior (opcional): especifique si desea determinar el intervalo de partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas de la tabla y se copian. Si no se especifica, la actividad de copia detecta automáticamente los valores. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque con una columna de tipo entero o date/datetime para la creación de particiones de datos. |
Opciones de partición: partición de intervalo dinámico. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Partición de límite superior y partición de límite inferior (opcional): especifique si desea determinar el intervalo de partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas del resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. A continuación se muestran más consultas de ejemplo para distintos escenarios: 1. Consulta de la tabla completa: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Consulta de una tabla con selección de columnas y filtros adicionales de la cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Consulta con subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Consulta con partición en subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedimientos recomendados para cargar datos con la opción de partición:
- Seleccione una columna distintiva como columna de partición (como clave principal o clave única) para evitar la asimetría de datos.
- Si la tabla tiene una partición integrada, use la opción de partición "Particiones físicas de tabla" para obtener un mejor rendimiento.
- Si usa Azure Integration Runtime para copiar datos, puede establecer "unidades de integración de datos (DIU)" mayores (>4) para usar más recursos de cálculo. Compruebe los escenarios aplicables allí.
- "Grado de paralelismo de copia" controla los números de partición. Si se establece en un número demasiado grande, puede resentirse el rendimiento, así que se recomienda establecerlo como (DIU o número de nodos de IR autohospedados) * (2 a 4).
- Tenga en cuenta que Azure Synapse Analytics puede ejecutar un máximo de 32 consultas al mismo tiempo; si se configura un "Grado de paralelismo de copia" demasiado alto, puede provocar un problema de limitación en Synapse.
Ejemplo: carga completa de una tabla grande con particiones físicas
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Ejemplo: consulta con partición por rangos dinámica
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Consulta de ejemplo para comprobar la partición física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la tabla tiene una partición física, verá "HasPartition" como "yes".
Uso de la instrucción COPY para cargar datos en Azure Synapse Analytics
El uso de la instrucción COPY es una manera sencilla y flexible de cargar datos en Azure Synapse Analytics con un alto rendimiento. Para más información, consulte Inicio rápido: carga masiva de datos mediante la instrucción COPY.
- Si los datos de origen están en Azure Blob o Azure Data Lake Storage Gen2 y el format es compatible con la instrucción COPY, puede usar la actividad de copia para invocar directamente la instrucción COPY para permitir que Azure Synapse Analytics extraer los datos del origen. Consulte Copia directa mediante la instrucción COPY para obtener detalles.
- Si el formato y el almacén de datos de origen no es compatible originalmente con la instrucción COPY, use en su lugar la característica Copia almacenada provisionalmente mediante la instrucción COPY. La característica de copia almacenada provisionalmente también proporciona un mejor rendimiento. Convierte automáticamente los datos en formato compatible con la instrucción COPY, almacena los datos en Azure Blob Storage y, a continuación, llama a la instrucción COPY para cargar datos en Azure Synapse Analytics.
Sugerencia
Cuando se usa la instrucción COPY con Azure Integration Runtime, las unidades de integración de datos (DIU) eficaces siempre son dos. El ajuste de la DIU no afecta al rendimiento, ya que la carga de datos desde el almacenamiento funciona con el motor de Azure Synapse.
Copia directa mediante la instrucción COPY
Azure Synapse Analytics instrucción COPY admite directamente Azure Blob y Azure Data Lake Storage Gen2. Si los datos de origen cumplen los criterios descritos en esta sección, use la instrucción COPY para copiar directamente desde el almacén de datos de origen a Azure Synapse Analytics. De lo contrario, use Copia almacenada provisionalmente mediante la instrucción COPY. El servicio comprueba la configuración y produce un error en la ejecución de la actividad de copia si no se cumplen los criterios.
El formato y el servicio vinculado de origen tienen los siguientes tipos y métodos de autenticación:
Tipo de almacén de datos de origen admitido Formato admitido Tipo de autenticación de origen admitido Azure Blob Texto delimitado Autenticación de clave de cuenta, autenticación de firma de acceso compartido, autenticación de entidad de servicio (mediante ServicePrincipalKey), autenticación de identidad administrada asignada por el sistema Parquet Autenticación de clave de cuenta, autenticación de firma de acceso compartido ORC Autenticación de clave de cuenta, autenticación de firma de acceso compartido Azure Data Lake Storage Gen2 Texto delimitado
Parquet
ORCAutenticación de clave de cuenta, autenticación de entidad de servicio (mediante ServicePrincipalKey), autenticación de firma de acceso compartido, autenticación de identidad administrada asignada por el sistema Importante
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente.
- Si Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
Esta es la configuración de formato:
- Para Parquet:
compressionpuede ser no compression, Snappy oGZip. - Para ORC:
compressionpuede ser sin compresión,zlibo Snappy. - Para Texto delimitado:
-
rowDelimiterse establece explícitamente como carácter único o "\r\n"; no se admite el valor predeterminado. -
nullValuese deja con el valor predeterminado o se establece en cadena vacía (""). -
encodingNamese deja con el valor predeterminado o se establece en utf-8 o utf-16. -
escapeChardebe ser igual quequoteChary no está vacío. -
skipLineCountse deja como valor predeterminado o se establece en 0. -
compressionpuede establecerse como sin compresión oGZip.
-
- Para Parquet:
Si el origen es una carpeta,
recursivede la actividad de copia se debe establecer en True ywildcardFilenametiene que ser*o*.*.wildcardFolderPath,wildcardFilename(distinto de*o*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryyadditionalColumnsno se especifican.
Esta configuración de la instrucción COPY es compatible con allowCopyCommand en la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| defaultValues | Especifica los valores predeterminados para cada columna de destino en Azure Synapse Analytics. Los valores predeterminados de la propiedad sobrescriben el conjunto de restricciones predeterminado en el almacenamiento de datos, y la columna de identidad no puede tener un valor predeterminado. | No |
| additionalOptions | Opciones adicionales que se pasarán directamente a la instrucción COPY de Azure Synapse Analytics en la cláusula "With" de la instrucción COPY. Incluye el valor entre comillas si es necesario para ajustarlo a los requisitos de la instrucción COPY. | No |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Copia almacenada provisionalmente mediante la instrucción COPY
Cuando los datos de origen no son compatibles de forma nativa con la instrucción COPY, habilite la copia de datos a través de un almacenamiento provisional en Azure Blob Storage o Azure Data Lake Storage Gen2 (no puede ser Azure Premium Storage). En este caso, el servicio convierte automáticamente los datos para satisfacer los requisitos del formato de datos de la instrucción COPY. A continuación, invoca la instrucción COPY para cargar datos en Azure Synapse Analytics. Por último, limpia los datos temporales del almacenamiento. Consulte Copia almacenada provisionalmente para obtener más información sobre cómo copiar datos mediante el almacenamiento provisional.
Para usar esta característica, cree un servicio vinculado de Azure Blob Storage o un servicio vinculado de Azure Data Lake Storage Gen2 con autenticación por clave de cuenta o identidad administrada por el sistema que hace referencia a la cuenta de almacenamiento de Azure como almacenamiento provisional.
Importante
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento provisional, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente. También debe conceder permisos a la identidad administrada del área de trabajo de Azure Synapse Analytics en la cuenta de Azure Blob Storage de ensayo o Azure Data Lake Storage Gen2. Para información sobre cómo conceder este permiso, consulte: Concesión de permisos a una identidad administrada de área de trabajo.
- Si el almacenamiento provisional de Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
Importante
Si el almacenamiento provisional de Azure Storage está configurado con un punto de conexión privado administrado y tiene el firewall de almacenamiento habilitado, debe usar la autenticación de identidad administrada y conceder permisos de lector de datos de Storage Blob a la instancia de Synapse SQL Server para asegurarse de que puede acceder a los archivos almacenados provisionalmente durante la carga de la instrucción COPY.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Uso de PolyBase para cargar datos en Azure Synapse Analytics
El uso de PolyBase es una manera eficaz de cargar una gran cantidad de datos en Azure Synapse Analytics con un alto rendimiento. Verá una gran mejora en el rendimiento mediante el uso de PolyBase en lugar del mecanismo BULKINSERT predeterminado.
- Si los datos de origen están en Azure Blob o Azure Data Lake Storage Gen2 y el format es compatible con PolyBase, puede usar la actividad de copia para invocar directamente PolyBase para permitir que Azure Synapse Analytics extraer los datos del origen. Consulte Copia directa con PolyBase para obtener detalles.
- Si el formato y el almacenamiento de datos de origen no es compatible originalmente con PolyBase, use en su lugar la característica Copia almacenada provisionalmente con PolyBase. La característica de copia almacenada provisionalmente también proporciona un mejor rendimiento. Convierte automáticamente los datos en formato compatible con PolyBase, almacena los datos en Azure Blob Storage y, a continuación, llama a PolyBase para cargar datos en Azure Synapse Analytics.
Sugerencia
Más información en Prácticas recomendadas para usar PolyBase. Cuando se usa PolyBase con Azure Integration Runtime, las unidades de integración de datos (DIU) eficaces para el almacenamiento directo o provisional en Synapse siempre son dos. La optimización de la unidad de integración de datos no afecta al rendimiento, ya que la carga de datos desde el almacenamiento se basa en el motor de Synapse.
Esta configuración de PolyBase es compatible con polyBaseSettings en la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| rejectValue | Especifica el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta. Obtenga más información sobre las opciones de rechazo de PolyBase en la sección Argumentos de CREATE EXTERNAL TABLE (Transact-SQL). Los valores permitidos son 0 (valor predeterminado), 1, 2, etc. |
No |
| rejectType | Especifica si la opción rejectValue es un valor literal o un porcentaje. Los valores permitidos son Value (valor predeterminado) y Percentage. |
No |
| rejectSampleValue | Determina el número de filas que se van a recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas. Los valores permitidos son 1, 2, etc. |
Sí, si el valor de rejectType es percentage. |
| useTypeDefault | Especifica cómo administrar valores que faltan en archivos de texto delimitado cuando PolyBase recupera datos del archivo de texto. Obtenga más información sobre esta propiedad en la sección Argumentos de CREATE EXTERNAL FILE FORMAT (Transact-SQL). Los valores válidos son True y False (valor predeterminado). |
No |
Copia directa con PolyBase
Azure Synapse Analytics PolyBase admite directamente Azure Blob y Azure Data Lake Storage Gen2. Si los datos de origen cumplen los criterios descritos en esta sección, use PolyBase para copiar directamente desde el almacén de datos de origen a Azure Synapse Analytics. De lo contrario, use Copia almacenada provisionalmente con PolyBase.
Sugerencia
Para copiar datos de forma eficaz en Azure Synapse Analytics, obtenga más información acerca de cómo Azure Data Factory hace aún más sencillo y cómodo descubrir información valiosa de los datos al usar Data Lake Store con Azure Synapse Analytics.
Si no se cumplen los requisitos, el servicio comprueba la configuración y vuelve automáticamente al mecanismo BULKINSERT para realizar el movimiento de datos.
El servicio vinculado de origen tiene los siguientes tipos y métodos de autenticación:
Tipo de almacén de datos de origen admitido Tipo de autenticación de origen admitido Azure Blob Autenticación de clave de cuenta, autenticación de identidad administrada asignada por el sistema Azure Data Lake Storage Gen2 Autenticación de clave de cuenta, autenticación de identidad administrada asignada por el sistema Importante
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente.
- Si Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
El formato de datos de origen es de Parquet, ORC, o texto delimitado, con las siguientes configuraciones:
- La ruta de acceso de la carpeta no contiene el filtro de comodín.
- El nombre de archivo está vacío o apunta a un solo archivo. Si especifica un nombre de archivo de comodín en la actividad de copia, solo puede ser
*o*.*. -
rowDelimiteres valor predeterminado, \n, \r\n o \r. -
nullValuese deja con el valor predeterminado o se establece en empty string ("") ytreatEmptyAsNullse deja con el valor predeterminado o se establece en True. -
encodingNamese deja con el valor predeterminado o se establece en utf-8. -
quoteChar,escapeCharyskipLineCountno están especificados. Fila de encabezado de omisión de compatibilidad de PolyBase que se puede configurar comofirstRowAsHeader. -
compressionpuede ser no compression,GZip, o Deflate.
Si el origen es una carpeta,
recursivede la actividad de copia se debe establecer en True.wildcardFolderPath,wildcardFilename,modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryyadditionalColumnsno se especifican.
Nota:
Si el origen es una carpeta, observe que PolyBase recupera archivos de la carpeta y todas sus subcarpetas y no recupera datos de los archivos para los cuales el nombre de archivo empieza con un guion bajo (_) o un punto (.), tal como se documenta aquí, en el argumento LOCATION.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Copia almacenada provisionalmente con PolyBase
Cuando los datos de origen no son compatibles de forma nativa con PolyBase, habilite la copia de datos mediante un área de preparación provisional en Azure Blob o Azure Data Lake Storage Gen2 (no puede ser Azure Premium Storage). En este caso, el servicio convierte automáticamente los datos para satisfacer los requisitos del formato de datos de PolyBase. A continuación, invoca PolyBase para cargar datos en Azure Synapse Analytics. Por último, limpia los datos temporales del almacenamiento. Consulte Copia almacenada provisionalmente para obtener más información sobre cómo copiar datos mediante el almacenamiento provisional.
Para usar esta característica, cree un servicio vinculado de Azure Blob Storage o un servicio vinculado de Azure Data Lake Storage Gen2 con autenticación mediante clave de cuenta o identidad administrada que haga referencia a la cuenta de almacenamiento de Azure como almacenamiento temporal.
Importante
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento provisional, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente. También debe conceder permisos a la identidad administrada del área de trabajo de Azure Synapse Analytics en la cuenta de Azure Blob Storage de ensayo o Azure Data Lake Storage Gen2. Para información sobre cómo conceder este permiso, consulte: Concesión de permisos a una identidad administrada de área de trabajo.
- Si el almacenamiento provisional de Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
Importante
Si el Azure Storage de almacenamiento provisional está configurado con un punto de conexión privado administrado y tiene habilitado el firewall de almacenamiento, debe usar la autenticación de identidad administrada y conceder permisos de lector de datos de Storage Blob al SQL Server de Synapse para asegurarse de que puede acceder a los archivos almacenados provisionalmente durante la carga de PolyBase.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Prácticas recomendadas para usar PolyBase
En las secciones siguientes se proporcionan procedimientos recomendados además de esos procedimientos mencionados en Prácticas más importantes para Azure Synapse Analytics.
Permiso de base de datos necesario
Para usar PolyBase, el usuario que carga datos en Azure Synapse Analytics debe tener permiso "CONTROL" en la base de datos de destino. Una manera de conseguirlo es agregar el usuario como miembro del rol db_owner. Obtenga información sobre cómo hacerlo en la descripción general de Azure Synapse Analytics.
Límites del tipo de datos y del tamaño de fila
Las cargas de PolyBase están limitadas a filas más pequeñas que 1 MB. No se puede usar para cargar en VARCHR(MAX), NVARCHAR(MAX) ni VARBINARY(MAX). Para obtener más información, consulte Azure Synapse Analytics límites de capacidad del servicio.
Cuando los datos de origen tienen filas mayores de 1 MB, es aconsejable dividir verticalmente las tablas de origen en otras más pequeñas. Asegúrese de que el tamaño mayor de cada fila no excede el límite. Después, las tablas más pequeñas se pueden cargar mediante PolyBase y combinarse en Azure Synapse Analytics.
Como alternativa, para los datos con estas columnas anchas, puede usar una opción distinta de PolyBase para cargar los datos de uso, para ello desactive el valor para permitir PolyBase.
Clase de recurso de Azure Synapse Analytics
Para lograr el mejor rendimiento posible, asigne una clase de recursos más grande al usuario que cargue datos en Azure Synapse Analytics a través de PolyBase.
Solución de problemas de PolyBase
Carga en una columna decimal
Si los datos de origen están en formato de texto u otros tipos de almacenamiento no compatibles con PolyBase (usando la copia provisional y PolyBase), y contienen un valor vacío que se va a cargar en la columna Decimal de Azure Synapse Analytics, puede obtener el siguiente error:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
La solución consiste en anular la selección de la opción "Usar tipo predeterminado" (como falsa) en el receptor de la actividad de copia -> configuración de PolyBase. "USE_TYPE_DEFAULT" es una configuración nativa PolyBase que especifica cómo administrar los valores que faltan en archivos de texto delimitados cuando PolyBase recupera datos del archivo de texto.
Compruebe la propiedad tableName en Azure Synapse Analytics
En la siguiente tabla se proporcionan ejemplos de cómo especificar la propiedad tableName en el conjunto de datos JSON. Se muestran varias combinaciones de esquema y nombres de tabla.
| Esquema de base de datos | Nombre de la tabla | Propiedad JSON tableName |
|---|---|---|
| dbo | MyTable | MyTable o dbo.MyTable o [dbo].[MyTable] |
| dbo1 | MyTable | dbo1.MyTable o [dbo1].[MyTable] |
| dbo | My.Table | [My.Table] o [dbo].[My.Table] |
| dbo1 | My.Table | [dbo1].[My.Table] |
Si ve el siguiente error, el problema podría ser el valor especificado para la propiedad tableName. Consulte en la tabla anterior la forma correcta de especificar los valores para la propiedad tableName de JSON.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Columnas con valores predeterminados
Actualmente, la característica PolyBase solo acepta el mismo número de columnas que la tabla de destino. Un ejemplo sería una tabla con cuatro columnas y que una de ellas esté definida con un valor predeterminado. Los datos de entrada siguen necesitando cuatro columnas. Un conjunto de datos de entrada de tres columnas producirá un error parecido al siguiente mensaje:
All columns of the table must be specified in the INSERT BULK statement.
El valor NULL es una forma especial del valor predeterminado. Si la columna acepta valores nulos, los datos de entrada del blob para esa columna pueden estar vacíos. Pero no puede faltar del conjunto de datos de entrada. PolyBase inserta NULL para los valores que faltan en Azure Synapse Analytics.
Error de acceso a un archivo externo
Si recibe el siguiente error, asegúrese de que usa la autenticación de identidad administrada y ha concedido permisos de lector de datos de Storage Blob a la identidad administrada del área de trabajo de Azure Synapse.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Para más información, consulte Concesión de permisos a una identidad administrada después de la creación del área de trabajo.
Propiedades de Asignación de instancias de Data Flow
Al transformar datos en Asignación de Data Flow, puede leer y escribir en las tablas de Azure Synapse Analytics. Para más información, vea la transformación de origen y la transformación de receptor en Asignación de Data Flow.
Transformación de origen
La configuración específica de Azure Synapse Analytics está disponible en la pestaña Source Options de la transformación de origen.
Entrada Seleccione si desea señalar el origen en una tabla (equivale a Select * from <table-name>) o escribir una consulta SQL personalizada.
Enable Staging Se recomienda encarecidamente usar esta opción en cargas de trabajo de producción con orígenes de Azure Synapse Analytics. Al ejecutar una actividad de flujo de datos con orígenes de Azure Synapse Analytics desde una canalización, se le solicitará una cuenta de almacenamiento de ubicación provisional que se usará para la carga de los datos almacenados provisionalmente. Es el mecanismo más rápido para cargar datos de Azure Synapse Analytics.
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente.
- Si Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
- Si un grupo de SQL sin servidor de Azure Synapse como origen, no se admite la habilitación del almacenamiento provisional.
Consulta si selecciona Consulta en el campo de entrada, escriba una consulta SQL para el origen. Esta configuración invalidará cualquier tabla que haya elegido en el conjunto de datos. Las cláusulas Ordenar por no se admiten aquí, pero puede establecer una instrucción SELECT FROM completa. También puede usar las funciones de tabla definidas por el usuario. select * from udfGetData() es un UDF in SQL que devuelve una tabla. Esta consulta genera una tabla de origen que puede usar en el flujo de datos. El uso de consultas también es una excelente manera de reducir las filas para pruebas o búsquedas.
Ejemplo de SQL: Select * from MyTable where customerId > 1000 and customerId < 2000
Tamaño del lote: escriba un tamaño de lote para fragmentar datos grandes en lecturas. En los flujos de datos, se usará esta configuración para establecer el almacenamiento en caché de columnas de Spark. Se trata de un campo de opción que usará los valores predeterminados de Spark si se deja en blanco.
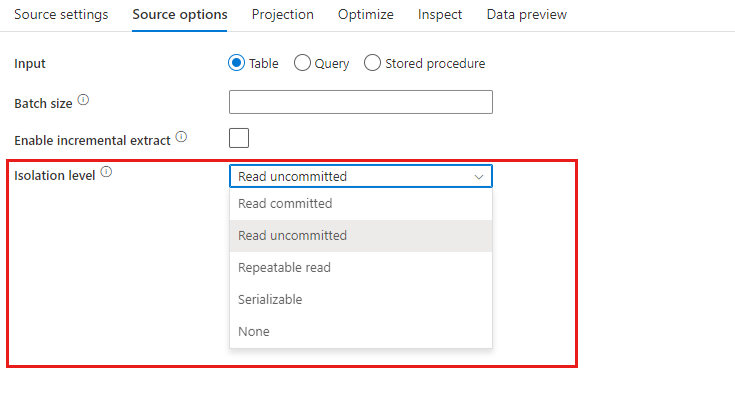
Nivel de aislamiento: el valor predeterminado de los orígenes de SQL en el flujo de datos de asignación es de lectura no confirmada. Puede cambiar el nivel de aislamiento aquí a uno de estos valores:
- Lectura confirmada
- Lectura no confirmada
- Lectura repetible
- Serializable
- Ninguno (ignorar el nivel de aislamiento)
Transformación de receptor
La configuración específica de Azure Synapse Analytics está disponible en la pestaña Configuración de la transformación de receptor.
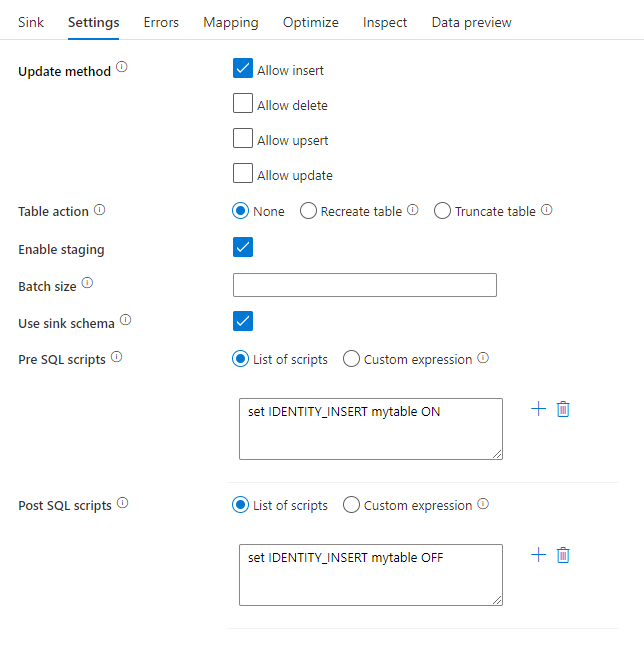
Método de actualización: determina qué operaciones se permiten en el destino de la base de datos. El valor predeterminado es permitir solamente las inserciones. Para realizar las operaciones update, upsert o delete rows, se requiere una transformación de alteración de filas para etiquetar esas acciones. En el caso de las actualizaciones, upserts y eliminaciones, se debe establecer una o varias columnas de clave para determinar la fila que se va a modificar.
Acción de tabla: determina si se deben volver a crear o quitar todas las filas de la tabla de destino antes de escribir.
- None (Ninguna): no se realizará ninguna acción en la tabla.
- Recreate (Volver a crear): se quitará la tabla y se volverá a crear. Obligatorio si se crea una nueva tabla dinámicamente.
- Truncate (Truncar): se quitarán todas las filas de la tabla de destino.
Permitir almacenamiento provisional: permite la carga en grupos de SQL de Azure Synapse Analytics mediante el comando copy y se recomienda para la mayoría de los receptores de Synapse. El almacenamiento de preparación se configura en la actividad Ejecutar Flujo de Datos.
- Al usar la autenticación de identidad administrada para el servicio vinculado de almacenamiento, conozca las configuraciones necesarias para Azure Blob y Azure Data Lake Storage Gen2 respectivamente.
- Si Azure Storage está configurado con el punto de conexión de servicio de red virtual, tiene que utilizar la autenticación de identidad administrada con la opción para permitir el servicio de Microsoft de confianza habilitada en la cuenta de almacenamiento; consulte Efectos del uso de puntos de conexión de servicio de la red virtual con Azure Storage.
Tamaño del lote: controla el número de filas que se escriben en cada cubo. Los tamaños de lote más grandes mejoran la compresión y la optimización de memoria, pero se arriesgan a obtener excepciones de memoria al almacenar datos en caché.
Usar esquema de receptor: de forma predeterminada, se creará una tabla temporal en el esquema receptor como almacenamiento provisional. También puede desactivar la opción Usar esquema receptor y, en su lugar, en Seleccionar esquema de base de datos de usuario, especifique un nombre de esquema con el que Data Factory creará una tabla de almacenamiento provisional para cargar datos ascendentes y limpiarlos automáticamente al finalizar. Asegúrese de que tiene permiso para crear tablas en la base de datos y modificar permisos en el esquema.

Scripts SQL anteriores y posteriores: escriba scripts de SQL de varias líneas que se ejecutarán antes (preprocesamiento) y después (procesamiento posterior) de que los datos se escriban en la base de datos del receptor
Sugerencia
- Se recomienda dividir los scripts por lotes únicos con varios comandos en varios lotes.
- Tan solo las instrucciones de lenguaje de definición de datos (DDL) y lenguaje de manipulación de datos (DML) que devuelven un recuento de actualizaciones sencillo se pueden ejecutar como parte de un lote. Obtenga más información en Realización de operaciones por lotes
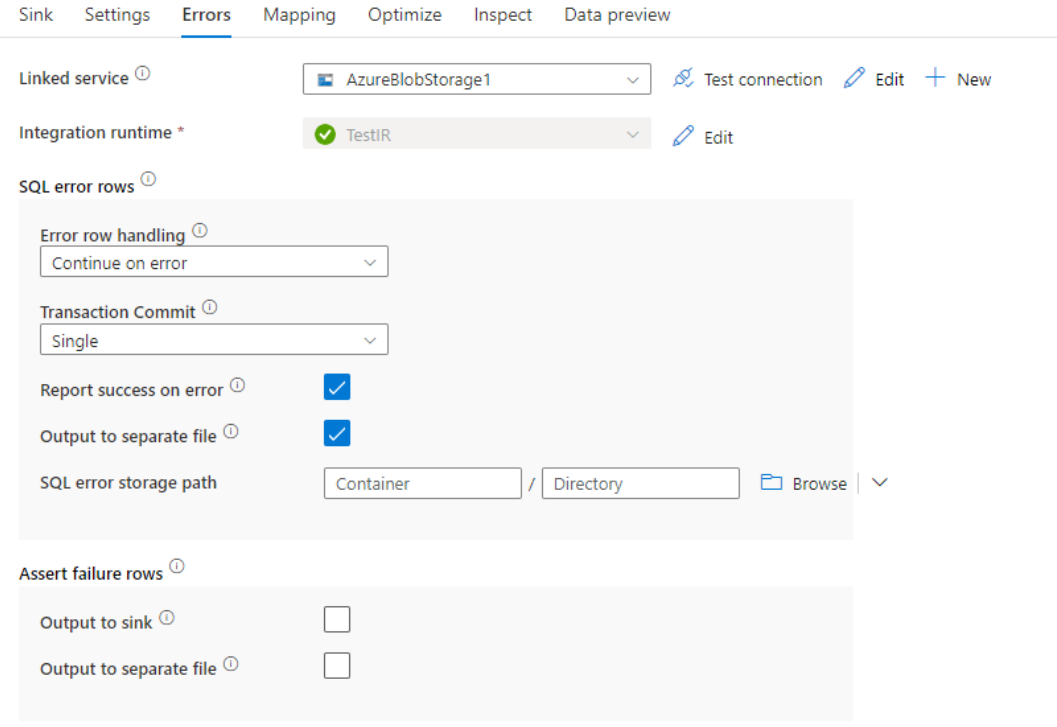
Control de filas de errores
Al escribir en Azure Synapse Analytics, es posible que se produzca un error en determinadas filas de datos debido a restricciones establecidas por el destino. Estos son algunos de los errores comunes:
- Los datos binarios o de tipo cadena se truncarían en una tabla.
- No se puede insertar el valor NULL en la columna.
- Error de conversión al convertir el valor al tipo de datos.
De forma predeterminada, la ejecución de un flujo de datos no funcionará al recibir el primer error. Puede optar por Continuar en caso de error, que permite que el flujo de datos se complete, aunque haya filas individuales con errores. El servicio proporciona diferentes opciones para controlar estas filas de error.
Confirmación de transacción: elija si los datos se escriben en una única transacción o en lotes. Una sola transacción proporcionará mejor rendimiento y ningún dato escrito será visible para otros usuarios hasta que finalice la transacción. Las transacciones por lotes tienen un rendimiento peor, pero pueden funcionar con grandes conjuntos de datos.
Salida de datos rechazados: Si está habilitada, puede generar las filas con errores en un archivo CSV en Azure Blob Storage o en una cuenta de Azure Data Lake Storage Gen2 de su elección. Las filas de error se escribirán con tres columnas adicionales: la operación SQL, como INSERT o UPDATE, el código de error de flujo de datos y el mensaje de error de la fila.
Notificar éxito cuando hay error: si está habilitada, el flujo de datos se marcará como correcto, aunque se encuentren filas de error.
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte Actividad de obtención de metadatos.
Asignación de tipos de datos para Azure Synapse Analytics
Al copiar datos desde o hacia Azure Synapse Analytics, se aplican las siguientes asignaciones de tipos de datos de Azure Synapse Analytics a tipos de datos provisionales de Azure Data Factory. Estas asignaciones también se usan al copiar datos desde o hacia Azure Synapse Analytics mediante canalizaciones de Synapse, ya que las canalizaciones también implementan Azure Data Factory dentro de Azure Synapse. Para obtener información acerca de la forma en que la actividad de copia asigna el esquema de origen y el tipo de datos al receptor, consulte Asignación de esquemas en la actividad de copia.
Sugerencia
Consulte el artículo Tipos de datos de tabla en Azure Synapse Analytics sobre los tipos de datos admitidos en Azure Synapse Analytics y las soluciones alternativas para los tipos no admitidos.
| tipo de datos de Azure Synapse Analytics | Tipo de datos provisionales de Data Factory |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | DateTime |
| Datetime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| Atributo FILESTREAM (varbinary(max)) | Byte[] |
| Float | Double |
| imagen | Byte[] |
| int | Int32 |
| money | Decimal |
| NCHAR | String, Char[] |
| NUMERIC | Decimal |
| NVARCHAR | String, Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| SMALLINT | Int16 |
| SMALLMONEY | Decimal |
| time | TimeSpan |
| TINYINT | Byte |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
Actualización de la versión de Azure Synapse Analytics
Para actualizar la versión de Azure Synapse Analytics, en Edit linked service página, seleccione Recommended en Version y configure el servicio vinculado haciendo referencia a las propiedades del servicio Linked para la versión recomendada.
Diferencias entre la versión recomendada y la heredada
En la tabla siguiente se muestran las diferencias entre Azure Synapse Analytics mediante la versión recomendada y la versión heredada.
| Versión recomendada | Versión heredada |
|---|---|
Admite TLS 1.3 a través de encrypt como strict. |
No se admite TLS 1.3. |
Contenido relacionado
Consulte los formatos y almacenes de datos compatibles para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores.