Uso de Azure Data Factory para migrar datos de un servidor de Netezza local a Azure
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Azure Data Factory proporciona un mecanismo eficaz, sólido y rentable para migrar datos a escala desde un servidor de Netezza local hasta una cuenta de Azure Storage o una base de datos de Azure Synapse Analytics.
En este artículo se proporciona la siguiente información para ingenieros de datos y desarrolladores:
- Rendimiento
- Resistencia de copia
- Seguridad de las redes
- Arquitectura de soluciones de alto nivel
- Procedimientos recomendados para la implementación
Rendimiento
Azure Data Factory ofrece una arquitectura sin servidor que permite el paralelismo en varios niveles. Si es desarrollador, esto significa que puede compilar canalizaciones para el uso completo del ancho de banda de red y de base de datos con el fin de aumentar el rendimiento del movimiento de datos en su entorno.
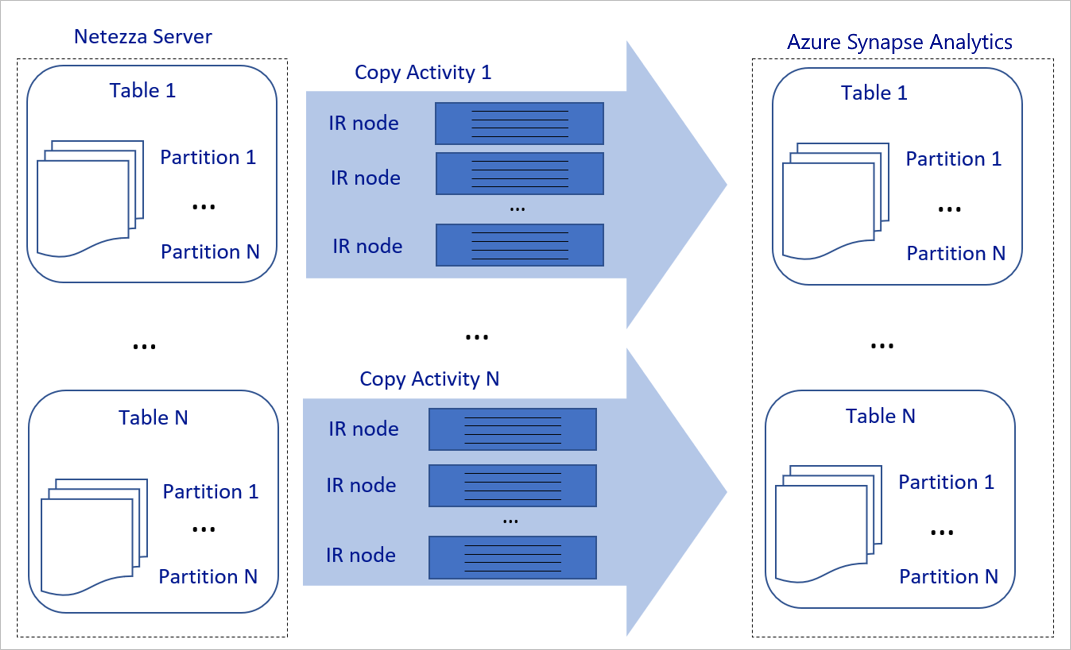
El diagrama anterior se puede interpretar de la siguiente manera:
Una sola actividad de copia puede aprovechar los recursos de proceso escalables. Al usar Azure Integration Runtime, puede especificar hasta 256 DIU para cada actividad de copia sin servidor. Con el entorno de ejecución de integración autohospedado (IR autohospedado), puede escalar verticalmente la máquina o escalar horizontalmente a varias máquinas de forma manual (hasta 4 nodos), y una única actividad de copia distribuye su partición entre todos los nodos.
Una única actividad de copia lee y escribe en el almacén de datos mediante varios subprocesos.
El flujo de control de Azure Data Factory puede iniciar varias actividades de copia en paralelo. Por ejemplo, puede iniciarlas mediante un bucle For Each.
Para más información, consulte Guía de escalabilidad y rendimiento de la actividad de copia.
Resistencia
Dentro de la ejecución de una única actividad de copia, Azure Data Factory tiene un mecanismo de reintento integrado que permite administrar cierto nivel de errores transitorios en los almacenes de datos o en la red subyacente.
Con la actividad de copia de Azure Data Factory, al copiar datos entre los almacenes de datos origen y receptor, tiene dos formas de administrar las filas no compatibles: Puede anular y suspender la actividad de copia u omitir las filas de datos incompatibles y seguir copiando el resto de los datos. Además, para conocer la causa del error, puede registrar las filas incompatibles en Azure Blob Storage o Azure Data Lake Store, corregir los datos en el origen de datos y reintentar la actividad de copia.
Seguridad de las redes
De forma predeterminada, Azure Data Factory transfiere los datos del servidor local de Netezza a una cuenta de almacenamiento de Azure o una base de datos de Azure Synapse Analytics utilizando una conexión cifrada a través del Protocolo seguro de transferencia de hipertexto (HTTPS). HTTPS proporciona cifrado de datos en tránsito y evita la interceptación y ataques de tipo "Man in the middle".
Como alternativa, si no quiere que los datos se transfieran a través de la red pública de Internet, puede lograr una mayor seguridad mediante la transferencia de datos a través de un vínculo de emparejamiento privado por medio de Azure ExpressRoute.
En la sección siguiente se describe cómo lograr una mayor seguridad.
Arquitectura de la solución
En esta sección se describen dos formas de migrar los datos.
Migración de datos a través de la red pública de Internet
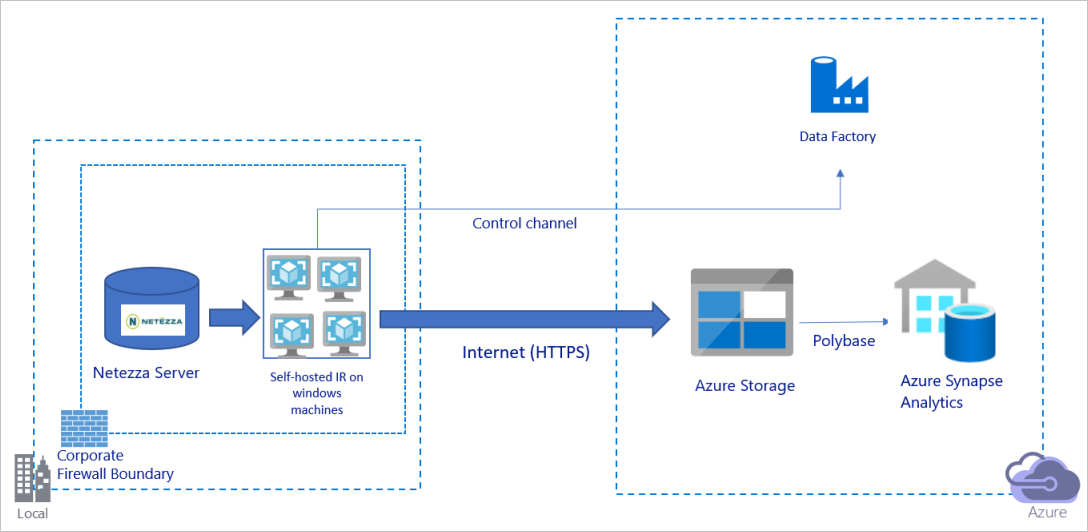
El diagrama anterior se puede interpretar de la siguiente manera:
En esta arquitectura, los datos se transfieren de forma segura mediante HTTPS a través de la red pública de Internet.
Para lograr esta arquitectura, debe instalar el entorno de ejecución de integración (autohospedado) de Azure Data Factory en una máquina Windows detrás de un firewall corporativo. Asegúrese de que este entorno de ejecución de integración pueda acceder directamente al servidor de Netezza. Puede usar completamente el ancho de banda de red y de los almacenes de datos para copiar datos, o puede escalar verticalmente su máquina o escalar horizontalmente a varias máquinas de forma manual.
Con esta arquitectura, puede migrar los datos de instantánea iniciales y los datos diferenciales.
Migrar datos a través de una red privada
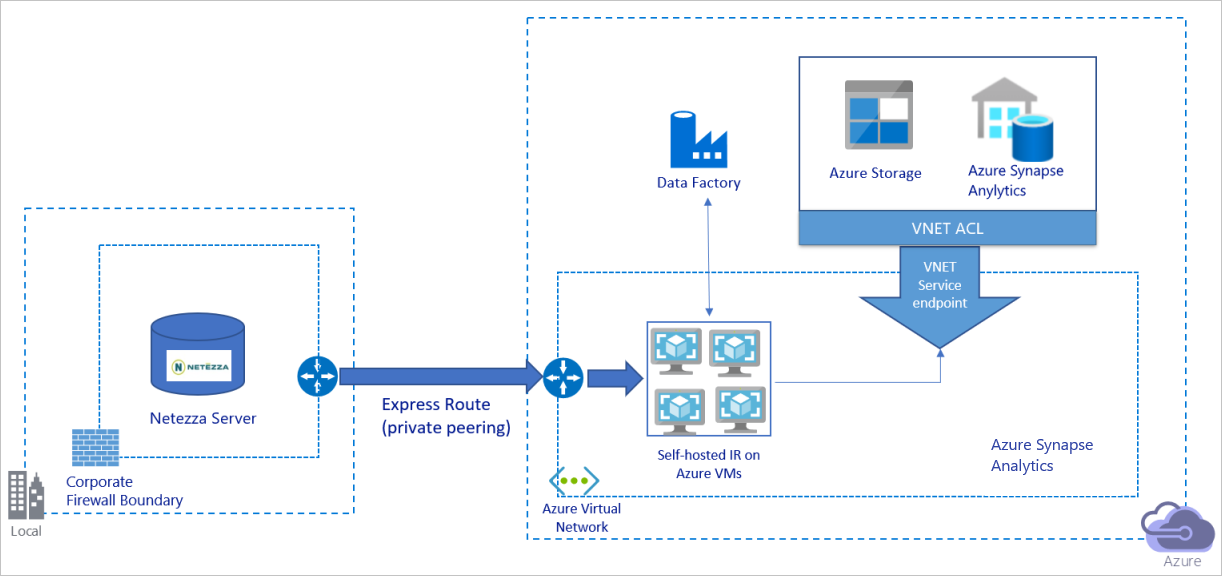
El diagrama anterior se puede interpretar de la siguiente manera:
En esta arquitectura, los datos se migran a través de un vínculo de emparejamiento privado mediante Azure ExpressRoute, de modo que nunca atraviesan la red pública de Internet.
Para lograr esta arquitectura, debe instalar el entorno de ejecución de integración (autohospedado) de Azure Data Factory en una máquina virtual (VM) Windows dentro de la red virtual de Azure. Para usar totalmente el ancho de banda de red y de los almacenes de datos para copiar los datos, puede escalar verticalmente la máquina virtual o escalar horizontalmente a varias máquinas virtuales de forma manual.
Con esta arquitectura, puede migrar los datos de instantánea iniciales y los datos diferenciales.
Procedimientos recomendados de implementación
Administración de la autenticación y las credenciales
Para autenticarse en Netezza, puede usar la autenticación ODBC a través de la cadena de conexión.
Para autenticarse en Azure Blob Storage:
Se recomienda encarecidamente usar identidades administradas para recursos de Azure. Creadas sobre una identidad de Azure Data Factory administrada automáticamente en Microsoft Entra ID, las identidades administradas le permiten configurar canalizaciones sin tener que proporcionar credenciales en la definición de servicio vinculado.
Como alternativa, puede autenticarse en Azure Blob Storage mediante la entidad de servicio, la firma de acceso compartido o la clave de la cuenta de almacenamiento.
Para autenticarse en Azure Data Lake Storage Gen2:
Se recomienda encarecidamente usar identidades administradas para recursos de Azure.
También puede usar la entidad de servicio o la clave de cuenta de almacenamiento.
Para autenticarse en Azure Synapse Analytics:
Se recomienda encarecidamente usar identidades administradas para recursos de Azure.
También puede usar la entidad de servicio o la autenticación de SQL.
Si no va a usar identidades administradas para recursos de Azure, es muy recomendable almacenar las credenciales en Azure Key Vault para facilitar la administración y la rotación de las claves de forma centralizada sin modificar los servicios vinculados de Azure Data Factory. Este es también uno de los procedimientos recomendados para CI/CD.
Migración de datos de instantánea iniciales
En el caso de tablas pequeñas (es decir, tablas con un volumen por debajo de 100 GB o que se pueden migrar a Azure al cabo de dos horas), puede hacer que cada trabajo de copia cargue los datos por cada tabla. Para un mejor rendimiento, puede ejecutar varios trabajos de copia de Azure Data Factory para cargar distintas tablas de manera simultánea.
Dentro de cada trabajo de copia, si quiere ejecutar consultas en paralelo y copiar datos mediante particiones, también puede llegar a cierto nivel de paralelismo mediante la configuración de la propiedad parallelCopies con cualquiera de las siguientes opciones de partición de datos:
Para obtener una mayor eficacia, le recomendamos que comience con un segmento de datos. Asegúrese de que el valor de la opción
parallelCopiessea menor que el número total de particiones de segmentos de datos de la tabla en el servidor de Netezza.Si el volumen de cada partición de segmento de datos sigue siendo grande (por ejemplo, 10 GB o más), le recomendamos que cambie a una partición por rangos dinámica. Esta opción le ofrece una mayor flexibilidad para definir el número de particiones y el volumen de cada partición por columna de partición, límite superior y límite inferior.
Para tablas más grandes (es decir, tablas con un volumen de 100 GB o más o que no se pueden migrar a Azure en dos horas), se recomienda crear particiones de los datos por consulta personalizada y, luego, hacer que cada trabajo de copia copie una partición cada vez. Para mejorar el rendimiento, puede ejecutar varios trabajos de copia de Azure Data Factory a la vez. Para cada destino de trabajo de copia de la carga de una partición mediante una consulta personalizada, puede habilitar el paralelismo mediante un segmento de datos o un intervalo dinámico con el fin de mejorar el rendimiento.
Si se produce un error en alguno de los trabajos de copia debido a una incidencia transitoria de la red o del almacén de datos, puede volver a ejecutar el trabajo de copia con error para volver a cargar esa partición específica desde la tabla. Otros trabajos de copia que cargan otras particiones no se ven afectados.
Cuando cargue datos en una base de datos de Azure Synapse Analytics, es conveniente que habilite PolyBase en el trabajo de copia utilizando Azure Blob Storage como almacenamiento provisional.
Migración de datos diferenciales
Para identificar las filas nuevas o actualizadas de la tabla, use una columna de marca de tiempo o una clave de incremento en el esquema. Después, puede almacenar el valor más reciente como límite máximo en una tabla externa y, luego, usarlo para filtrar los datos diferenciales la próxima vez que cargue los datos.
Cada tabla puede usar una columna de marca de agua diferente para identificar sus filas nuevas o actualizadas. Se recomienda crear una tabla de control externa. En la tabla, cada fila representa una tabla en el servidor de Netezza con su nombre de columna de marca de agua específico y el valor de límite máximo.
Configuración de un entorno de ejecución de integración autohospedado
Si va a migrar datos del servidor de Netezza a Azure, tanto si el servidor está en el entorno local detrás del firewall corporativo como dentro de un entorno de red virtual, debe instalar un IR autohospedado en una máquina virtual o máquina Windows, que es el motor que se usa para mover los datos. Durante la instalación del IR autohospedado, se recomienda el siguiente enfoque:
En cada máquina virtual o máquina Windows, empiece con una configuración de 32 vCPU y 128 GB de memoria. Puede seguir supervisando el uso de la CPU y memoria de la máquina de IR durante la migración de datos para ver si necesita escalar verticalmente la máquina para mejorar el rendimiento o reducirla verticalmente para ahorrar costos.
También, para escalar horizontalmente, puede asociar hasta cuatro nodos a un único IR autohospedado. Un único trabajo de copia que se ejecute en un entorno de ejecución de integración autohospedado aplicará automáticamente todos los nodos de máquina virtual para copiar los datos en paralelo. Para lograr una alta disponibilidad, comience con cuatro nodos de máquina virtual para evitar un único punto de error durante la migración de datos.
Limitación de las particiones
Como procedimiento recomendado, lleve a cabo una prueba de concepto de rendimiento (POC) con un conjunto de datos de ejemplo representativo, a fin de determinar el tamaño de partición adecuado para cada actividad de copia. Se recomienda cargar cada partición en Azure en dos horas.
Para copiar una tabla, comience con una única actividad de copia con una sola máquina de IR autohospedado. Aumente gradualmente el valor de parallelCopies en función del número de particiones de segmentos de datos de la tabla. Vea si toda la tabla se puede cargar en Azure en dos horas, según el rendimiento resultante del trabajo de copia.
Si no es posible, y la capacidad del nodo de IR autohospedado y el almacén de datos no se usan por completo, aumente de manera gradual el número de actividades de copia simultáneas hasta alcanzar el límite de la red o el límite de ancho de banda de los almacenes de datos.
Siga supervisando el uso de CPU y memoria en la máquina de IR autohospedado y prepárese para escalar verticalmente la máquina o escalar horizontalmente a varias máquinas cuando vea que estos valores alcanzan la capacidad máxima.
Si se encuentra con errores de limitación que notifica la actividad de copia de Azure Data Factory, reduzca el valor de simultaneidad o de parallelCopies en Azure Data Factory o considere la posibilidad de aumentar los límites de ancho de banda o de las operaciones IOPS por segundo de la red y los almacenes de datos.
Cálculo de los precios
Observe la siguiente canalización, que se ha creado para migrar datos del servidor local de Netezza a una base de datos de Azure Synapse Analytics:
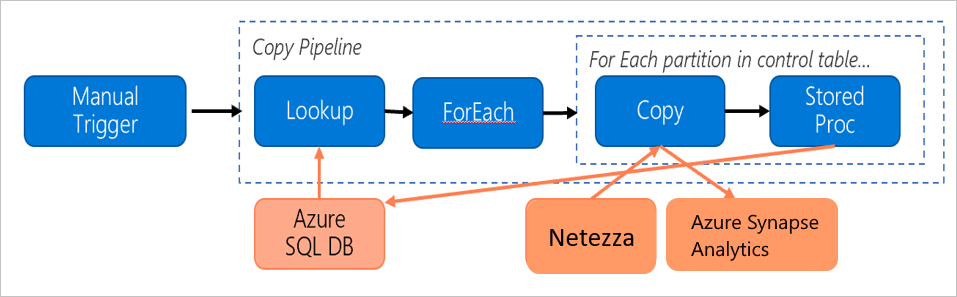
Supongamos que las siguientes instrucciones son verdaderas:
El volumen total de datos es de 50 terabytes (TB).
Los datos se van a migrar con la primera arquitectura de la solución (el servidor de Netezza está en el entorno local detrás del firewall).
El volumen de 50 TB se divide en 500 particiones y cada actividad de copia mueve una partición.
Cada actividad de copia está configurada con un IR autohospedado en cuatro máquinas y logra un rendimiento de 20 megabytes por segundo (MBps). (Dentro de la actividad de copia,
parallelCopiesestá establecido en 4 y cada subproceso para cargar datos de la tabla alcanza un rendimiento de 5 MBps).La simultaneidad de ForEach se establece en 3 y el rendimiento agregado es de 60 MBps.
En total, la migración tarda 243 horas en completarse.
En función de las suposiciones anteriores, este es el precio estimado:
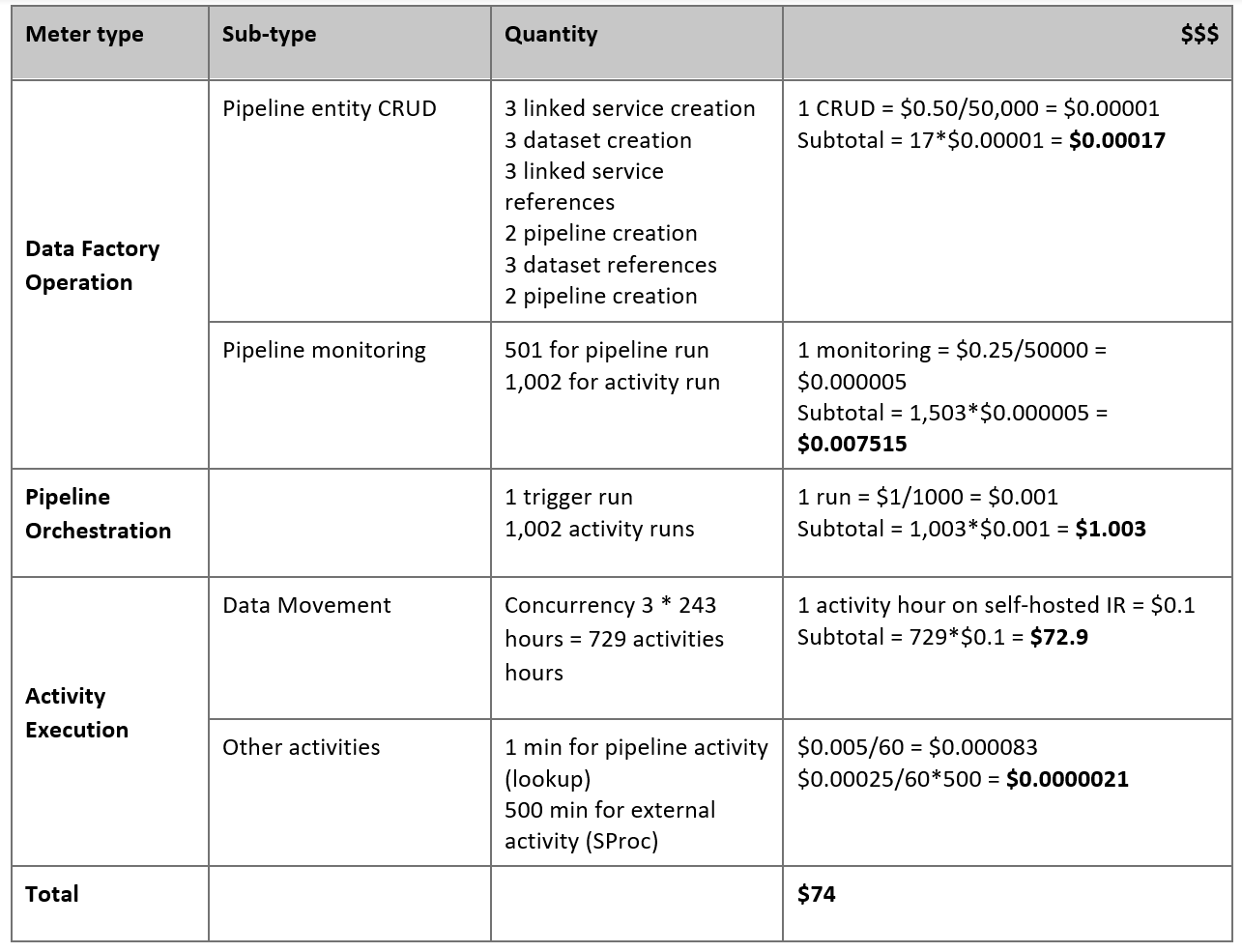
Nota:
Los precios que se muestran en la tabla anterior son hipotéticos. Los precios reales dependen del rendimiento real de su entorno. No se incluye el precio de la máquina Windows (con el IR autohospedado instalado).
Referencias adicionales
Para más información, consulte los artículos y guías siguientes:
- Conector de Netezza
- Conector ODBC
- Conector de Azure Blob Storage
- Conector de Azure Data Lake Storage Gen2
- Conector de Azure Synapse Analytics
- Guía de optimización y rendimiento de la actividad de copia
- Creación y configuración de un entorno de ejecución de integración autohospedado
- Alta disponibilidad y escalabilidad de un entorno de ejecución de integración autohospedado
- Consideraciones sobre la seguridad del movimiento de datos
- Almacenamiento de credenciales en Azure Key Vault
- Copia de datos incremental desde una tabla
- Copia de datos incremental desde varias tablas
- Página de precios de Azure Data Factory
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de