Supervisión de Azure Service Fabric
En este artículo se describe:
- Los tipos de datos de supervisión que puede recopilar para este servicio.
- Formas de analizar esos datos.
Nota:
Si ya está familiarizado con este servicio o Azure Monitor y solo quiere saber cómo analizar los datos de supervisión, consulte la sección Analizar cerca del final de este artículo.
Cuando tenga aplicaciones críticas y procesos empresariales que dependan de los recursos de Azure, deberá supervisar y obtener alertas para el sistema. El servicio Azure Monitor recopila y agrega métricas y registros de todos los componentes del sistema. Azure Monitor proporciona una vista de la disponibilidad, el rendimiento y la resistencia, y le notifica los problemas. Puede usar Azure Portal, PowerShell, la CLI de Azure, la API de REST o las bibliotecas cliente para configurar y ver los datos de supervisión.
- Para más información sobre Azure Monitor, consulte la Información general de Azure Monitor.
- Para más información sobre cómo supervisar los recursos de Azure en general, consulte Supervisión de recursos de Azure con Azure Monitor.
Supervisión de Azure Service Fabric
Azure Service Fabric tiene las siguientes capas que se pueden supervisar:
- Control de aplicaciones: Las aplicaciones que se ejecutan en los nodos. Puede supervisar las aplicaciones con el SDK o la clave de Application Insights, EventStore o el registro principal de ASP.NET.
- Supervisión de la plataforma (clúster): Métricas, registros y eventos de cliente para los nodos de plataforma o clúster, incluidas las métricas de contenedor. Las métricas y los registros son diferentes para los nodos de Linux o Windows.
- Supervisión de la infraestructura (rendimiento): Contadores de rendimiento y estado del servicio para la infraestructura del servicio.
Puede supervisar cómo se usan las aplicaciones, las acciones que realiza la plataforma Service Fabric, el uso de recursos con los contadores de rendimiento y el estado general del clúster. Los registros de Azure Monitor y Application Insights ofrecen integración integrada con Service Fabric.
- Para obtener información sobre los procedimientos recomendados, vea Procedimientos recomendados de supervisión y diagnóstico para Azure Service Fabric.
- Para ver un tutorial que muestra cómo ver los eventos y los informes de estado de Service Fabric, consultar las API de EventStore y supervisar los contadores de rendimiento, consulte el Tutorial: Supervisión de un clúster de Service Fabric en Azure.
- Para obtener información sobre cómo configurar los registros de Azure Monitor para supervisar los contenedores de Windows orquestados en Service Fabric, consulte Tutorial: Supervisión de contenedores de Windows en Service Fabric mediante los registros de Azure Monitor.
Service Fabric Explorer
Service Fabric Explorer, una aplicación de escritorio para Windows, macOS y Linux, es una herramienta de código abierto para inspeccionar y administrar clústeres de Azure Service Fabric. Para habilitar la automatización, todas las acciones que pueden realizarse a través de Service Fabric Explorer también pueden realizarse a través de PowerShell o una API de REST.
Supervisión de aplicaciones
La supervisión de aplicaciones realiza un seguimiento del uso de las características y componentes de una aplicación. Le recomendamos supervisar las aplicaciones para asegurarse de que se detectan los problemas que afectan a los usuarios. La responsabilidad de la supervisión de las aplicaciones es de los usuarios que desarrollan una aplicación y sus servicios, ya que es única para la lógica de negocios de la aplicación. La supervisión de las aplicaciones puede ser útil en los siguientes escenarios:
- ¿Cuánto tráfico experimenta mi aplicación? - ¿Necesita escalar los servicios para satisfacer las demandas del usuario o abordar un potencial cuello de botella en la aplicación?
- ¿Mis llamadas de servicio a servicio se han realizado correctamente y se ha llevado a cabo su seguimiento?
- ¿Qué acciones realizan los usuarios de mi aplicación? - La recopilación de datos de telemetría puede guiar el desarrollo de futuras características y un mejor diagnóstico de los errores de la aplicación
- ¿Mi aplicación está iniciando excepciones no controladas?
- ¿Qué ocurre en los servicios que se ejecutan en mis contenedores?
Lo mejor de la supervisión de la aplicación es que los desarrolladores pueden usar las herramientas y el marco que quieran, puesto que reside en el contexto de la aplicación. Para más información sobre la solución de Azure para la supervisión de aplicaciones con Azure Monitor: Application Insights, consulte Análisis de eventos con Application Insights.
También tenemos un tutorial con instrucciones para configurarlo para las aplicaciones de .NET. En este tutorial se incluyen instrucciones para instalar las herramientas adecuadas, un ejemplo para escribir telemetría personalizada en la aplicación y la visualización de telemetría y diagnósticos de la aplicación en Azure Portal.
Registro de aplicaciones
La instrumentación del código no es solo una manera de obtener información acerca de los usuarios, sino el único método para saber si algo va mal en la aplicación y para diagnosticar qué debe corregirse. Aunque técnicamente es posible que conectar un depurador a un servicio de producción, no es un procedimiento habitual. Por lo tanto, es importante disponer de datos de instrumentación detallados.
Algunos productos instrumentan el código automáticamente. Aunque estas soluciones pueden funcionar bien, la instrumentación manual casi siempre debe ser específica para su lógica de negocios. Al final, debe tener suficiente información para depurar desde la aplicación de manera forense. Las aplicaciones de Service Fabric se pueden instrumentar con cualquier marco de registro. En esta sección se describen algunos enfoques diferentes para instrumentar el código y se indica cuándo elegir uno u otro.
SDK de Application Insights: SDK de Application Insights consigue una eficaz integración con Service Fabric directamente, sin necesidad de configuraciones adicionales. Los usuarios pueden agregar los paquetes de NuGet de Service Fabric de AI y recibir datos y registros creados y recopilados que pueden verse en Azure Portal. Además, se aconseja que los usuarios agreguen su propia telemetría para poder diagnosticar y depurar sus aplicaciones y rastrear cuáles son los servicios y las partes de su aplicación que más se usan. La clase TelemetryClient del SDK ofrece muchas formas de rastrear la telemetría en sus aplicaciones. Para obtener más información, consulte Análisis y visualización de eventos con Application Insights.
Consulte un ejemplo de cómo instrumentar y agregar Application Insights a su aplicación en nuestro tutorial para supervisar y diagnosticar una aplicación .NET.
EventSource: Cuando se crea una solución de Service Fabric a partir de una plantilla en Visual Studio, se genera una clase derivada de EventSource (ServiceEventSource o ActorEventSource). Se crea una plantilla en la que podrá agregar eventos para la aplicación o el servicio. El nombre de EventSourcedebe ser único y debe cambiarse a partir de la cadena de plantilla predeterminada de MyCompany-<solution>-<project>. El hecho de tener varias definiciones de EventSource con el mismo nombre genera un problema en tiempo de ejecución. Cada evento definido debe tener un identificador único. Si el identificador no es único, se produce un error en tiempo de ejecución. En algunas organizaciones se asignan previamente rangos de valores para los identificadores, lo cual evita conflictos entre los equipos de desarrollo independientes. Para más información, consulte el blog de Vance o la documentación de MSDN.
Registro en ASP.NET Core: Es importante planear minuciosamente la instrumentación del código. Un plan de instrumentación correcto puede ayudarle a evitar que se desestabilice el código base y sea necesario volver a instrumentarlo. Para reducir el riesgo, puede elegir una biblioteca de instrumentación como Microsoft.Extensions.Logging, componente de Microsoft ASP.NET Core. ASP.NET Core tiene una interfaz ILogger que puede usar con su proveedor preferido al tiempo que reduce al mínimo el efecto sobre el código existente. Puede utilizar el código de ASP.NET Core en Windows y Linux, y en .NET Framework completo, por lo que el código de instrumentación es estándar.
Para ver ejemplos sobre cómo usar estas sugerencias, consulte Adición del registro a la aplicación de Service Fabric.
Supervisión de plataforma (clúster)
Un usuario controla qué telemetría procede de su aplicación, puesto que escribe el propio código, pero ¿qué sucede con los diagnósticos de la plataforma Service Fabric? Uno de los objetivos de Service Fabric es que las aplicaciones sean resistentes a los errores de hardware. Esto se logra gracias a la capacidad que tienen los servicios del sistema de la plataforma de detectar problemas de infraestructura y conmutar por error las cargas de trabajo rápidamente a otros nodos del clúster. Pero en este caso particular, ¿qué ocurre si los propios servicios del sistema tienen problemas? ¿O, si al intentar implementar o mover una carga de trabajo, se infringen las reglas de ubicación de los servicios? Service Fabric proporciona diagnósticos para estos y otros casos, a fin de garantizar que esté informado de las actividades que tienen lugar en su clúster. Algunos escenarios de ejemplo de la supervisión del clúster son:
Para obtener más información acerca de la supervisión de la plataforma (clúster), vea Supervisión del clúster.
Eventos de Service Fabric
Service Fabric proporciona un conjunto completo de eventos de diagnóstico listos para usar, a los que puede acceder a través de EventStore o el canal de eventos operativo que expone la plataforma. Estos eventos de Service Fabric muestran las acciones que realiza la plataforma en entidades diferentes, como nodos, aplicaciones, servicios, particiones, etc. Los mismos eventos están disponibles en los clústeres de Windows y Linux.
Canales de eventos de Service Fabric: En Windows, los eventos de Service Fabric están disponibles en un solo proveedor de seguimiento de eventos para Windows (ETW) con un conjunto de
logLevelKeywordFiltersrelevantes que se usan para elegir entre el canal operativo y el canal de datos y mensajería. Esta es la manera en que separamos los eventos salientes de Service Fabric que se filtrarán según sea necesario. En Linux, los eventos de Service Fabric proceden de LTTng y se colocan en una tabla de almacenamiento, desde la cual pueden filtrarse según sea necesario. Estos canales contienen eventos estructurados protegidos que pueden utilizarse para comprender mejor el estado del clúster. Los diagnósticos se habilitan de forma predeterminada en el momento de la creación del clúster, donde se crea una tabla de Azure Storage donde se envían los eventos de estos canales para que pueda consultarlos en el futuro.EventStore es una característica que muestra eventos de plataforma de Service Fabric en Service Fabric Explorer y mediante programación a través de la API REST de la Biblioteca cliente de Service Fabric. Puede ver una vista de instantánea de lo que está ocurriendo en el clúster para cada nodo, servicio, aplicación y consulta según la hora del evento. Las API de EventStore solo se encuentran disponibles para los clústeres de Windows que se ejecutan en Azure. En máquinas Windows, estos eventos se introducen en el registro de eventos, por lo que puede ver los eventos de Service Fabric en el Visor de eventos.
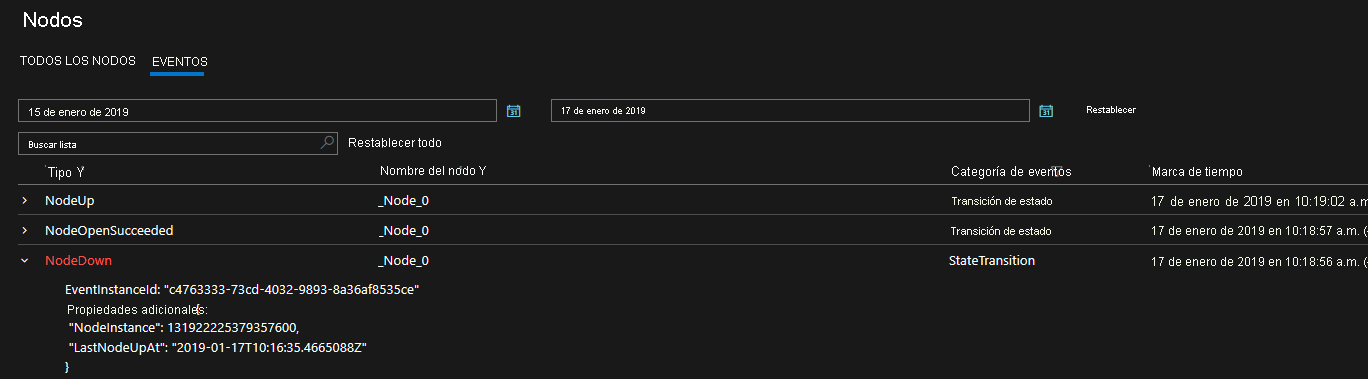
Los diagnósticos se proporcionan en forma de un conjunto completo de eventos predefinidos. Estos eventos de Service Fabric muestran las acciones que realiza la plataforma en entidades diferentes, como nodos, aplicaciones, servicios, particiones, etc. En el último escenario de los anteriores, si un nodo dejara de funcionar, la plataforma emitiría un evento NodeDown y podría recibir una notificación inmediatamente de la herramienta de supervisión de su elección. Otros ejemplos comunes son ApplicationUpgradeRollbackStarted o PartitionReconfigured durante una conmutación por error. Los mismos eventos están disponibles en los clústeres de Windows y Linux.
Los eventos se envían a través de canales estándar en Windows y Linux, y se pueden leer con cualquier herramienta de supervisión que los admita. La solución de Azure Monitor son los registros de Azure Monitor. Puede obtener más información sobre nuestra integración de registros de Azure Monitor, que incluye un panel operativo personalizado para el clúster y algunas consultas de ejemplo a partir de las que puede crear alertas. Existen más conceptos de supervisión del clúster disponibles en Generación de eventos y registros de nivel de plataforma.
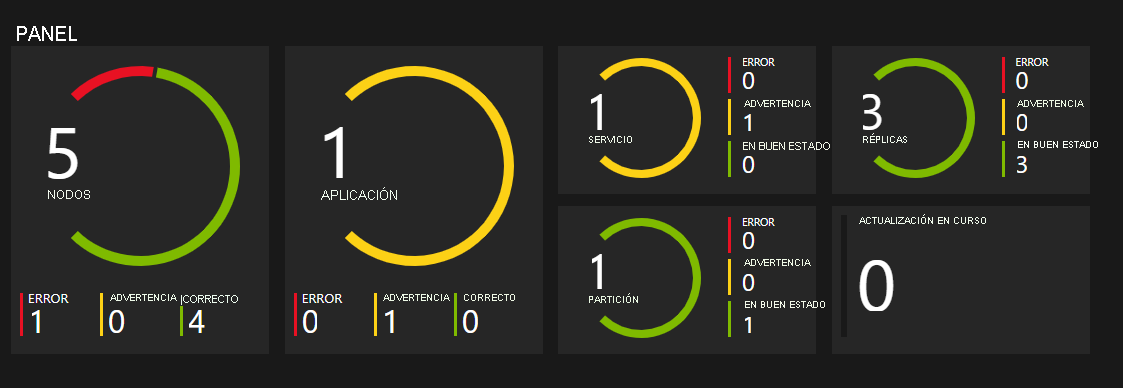
Supervisión del estado
La plataforma Service Fabric incluye un modelo de estado, el cual proporciona informes de estado extensibles para el estado de las entidades de un clúster. Cada nodo, aplicación, servicio, participación, réplica o instancia tiene un estado de mantenimiento que se actualiza continuamente. El estado de mantenimiento puede ser "Correcto", "Advertencia" o "Error". Piense en los eventos de Service Fabric como verbos de acciones que realiza el clúster en varias entidades y en el estado como un adjetivo para cada entidad. Cada vez que cambie el estado de una entidad determinada, también se emitirá un evento. De esta forma, puede configurar consultas y alertas para eventos de estado en la herramienta de supervisión de su elección, al igual que cualquier otro evento.
Asimismo, también permitimos que los usuarios invaliden el estado de entidades. Si la aplicación se somete a una actualización y se producen errores en las pruebas de validación, puede escribir a Service Fabric Health mediante la API de mantenimiento para indicar que el estado de la aplicación ya no es correcto, y Service Fabric revertirá automáticamente la actualización. Para obtener más información sobre el modelo de estado, consulte Introducción a la supervisión del mantenimiento de Service Fabric.
Guardianes
Por lo general, un guardián es un servicio independiente que vigila el mantenimiento y la carga de los servicios, hace ping a los puntos de conexión e informa acerca de los eventos de mantenimiento inesperados del clúster. Esto puede ayudar a evitar errores que se podrían pasar pasan por alto si solo se tuviera en cuenta el rendimiento de un servicio. Los guardianes son también un buen lugar para hospedar código que realice acciones de subsanación que no requieran interacción del usuario, como limpiar los archivos de registro de almacenamiento a determinados intervalos de tiempo. Si quiere un servicio de vigilancia de SF de código abierto totalmente implementado que incluya un modelo de extensibilidad de vigilancia fácil de usar y que se ejecute en clústeres de Windows y Linux, consulte el proyecto FabricObserver. FabricObserver es un software listo para producción. Le recomendamos que implemente FabricObserver en los clústeres de producción y de prueba, y que lo amplíe para satisfacer sus necesidades, ya sea a través de su modelo de complementos o mediante su bifurcación y la escritura de sus propios observadores integrados. El primero (complementos) es el enfoque recomendado.
Supervisión de la infraestructura (rendimiento)
Ahora que hemos analizado los diagnósticos en la aplicación y la plataforma, ¿cómo sabemos si el hardware funciona según lo previsto? La supervisión de la infraestructura subyacente es una parte fundamental del conocimiento del estado del clúster y la utilización de los recursos. La medición del rendimiento del sistema depende de muchos factores, que pueden ser subjetivos según las cargas de trabajo. Estos factores se miden normalmente mediante contadores de rendimiento. Estos contadores de rendimiento pueden proceder de diversos orígenes, como el sistema operativo, .NET Framework o la propia plataforma de Service Fabric. Algunos escenarios en los que podrían ser útiles son los siguientes:
- ¿Estoy usando mi hardware de manera eficiente? Es posible que quiera utilizar el hardware con un rendimiento de la CPU del 90 % o del 10 %. Esto resulta útil al escalar el clúster u optimizar los procesos de la aplicación.
- ¿Puedo predecir problemas de infraestructura de manera proactiva? Muchos problemas vienen precedidos de cambios bruscos (caídas) del rendimiento, por lo que puede utilizar los contadores de rendimiento, como las E/S de la red y la utilización de la CPU, para predecir y diagnosticar los problemas de forma proactiva.
Encontrará una lista de contadores de rendimiento que deberían recopilarse en el nivel de infraestructura en el artículo sobre Métricas de rendimiento.
Los registros de Azure Monitor se recomiendan para la supervisión de eventos de nivel de clúster. Después de configurar el agente de Log Analytics con el área de trabajo, puede recopilar:
- Métricas de rendimiento, como el uso de CPU.
- Contadores de rendimiento de .NET, como el uso de CPU de nivel de proceso.
- Contadores de rendimiento de Service Fabric, como el número de excepciones de un servicio confiable.
- Métricas de contenedor, como el uso de CPU.
Tipos de recursos
Azure usa el concepto de tipos de recursos e identificadores para identificar todo el contenido de una suscripción. Los tipos de recursos también forman parte de los identificadores de recursos para cada recurso que se ejecuta en Azure. Por ejemplo, un tipo de recurso para una máquina virtual es Microsoft.Compute/virtualMachines. Para obtener una lista de los servicios y sus tipos de recursos asociados, consulte Proveedores de recursos.
De forma similar, Azure Monitor organiza los datos principales de supervisión en métricas y registros en función de tipos de recursos, que también se denominan espacios de nombres. Hay diferentes métricas y registros disponibles para distintos tipos de recursos. Es posible que el servicio esté asociado a más de un tipo de recurso.
Para obtener más información sobre los tipos de recursos para Azure Service Fabric, consulte Referencia de datos de supervisión de Service Fabric.
Almacenamiento de datos
Para Azure Monitor:
- Los datos de métricas se almacenan en la base de datos de métricas de Azure Monitor.
- Los datos de registro se almacenan en el almacén de registros de Azure Monitor. Log Analytics es una herramienta de Azure Portal que puede hacer consultas en este almacén.
- El registro de actividad de Azure es un almacén independiente con su propia interfaz en Azure Portal.
Opcionalmente, puede enrutar los datos del registro de actividad y las métricas al almacén de registros de Azure Monitor. A continuación, puede usar Log Analytics para consultar los datos y correlacionarlos con otros datos de registro.
Muchos servicios pueden usar la configuración de diagnóstico para enviar datos de métricas y de registro a otras ubicaciones de almacenamiento fuera de Azure Monitor. Algunos ejemplos son Azure Storage, sistemas de asociados hospedados y sistemas de asociados que no son de Azure mediante Event Hubs.
Para obtener información detallada sobre cómo Azure Monitor almacena datos, consulte Plataforma de datos de Azure Monitor.
Métricas de plataforma de Azure Monitor
Azure Monitor proporciona métricas de plataforma para muchos servicios. Para obtener una lista de todas las métricas que es posible recopilar para todos los recursos de Azure Monitor, consulte Métricas admitidas en Azure Monitor.
Este servicio no recopila métricas de plataforma.
Métricas no basadas en Azure Monitor
Este servicio proporciona otras métricas que no se incluyen en la base de datos de métricas de Azure Monitor.
Métricas de SO invitado
Las métricas del sistema operativo invitado (SO) que se ejecuta en los nodos del clúster de Service Fabric se deben recopilar a través de uno o varios agentes que se ejecutan en el SO invitado. Las métricas del sistema operativo invitado incluyen los contadores de rendimiento que realizan el seguimiento del porcentaje de las CPU invitadas o el uso de la memoria, ya que se usan con frecuencia para el realizar el escalado automático o las alertas.
Un procedimiento recomendado es usar y configurar el agente de Azure Monitor para enviar métricas de rendimiento del SO invitado a través de la API de métricas personalizadas a la base de datos de métricas de Azure Monitor. Puede enviar las métricas del SO invitado a los registros de Azure Monitor mediante el mismo agente. A continuación, puede consultar esas métricas y registros mediante Log Analytics.
Nota:
El agente de Azure Monitor reemplaza la extensión Azure Diagnostics y el agente de Log Analytics para el enrutamiento del SO invitado. Para más información, consulte Información general sobre los agentes de Azure Monitor.
Registros de recursos de Azure Monitor
Los registros de recursos proporcionan información sobre las operaciones realizadas por un recurso de Azure. Los registros se generan automáticamente, pero debe enrutarlos a los registros de Azure Monitor para guardarlos o consultarlos. Los registros se organizan en categorías. Un espacio de nombres determinado puede tener varias categorías de registro de recursos que se pueden recopilar.
Este servicio no recopila registros de recursos, pero puede encontrar información sobre ellos en Datos de supervisión de recursos de Azure.
Registros y eventos de Service Fabric
Service Fabric puede recopilar los registros siguientes:
- En el caso de los clústeres de Windows, puede configurar la supervisión de clústeres con el agente de Diagnostics y registros de Azure Monitor.
- En el caso de los clústeres de Linux, los registros de Azure Monitor son también la herramienta recomendada para la supervisión de la infraestructura y plataforma de Azure. Los diagnósticos de la plataforma Linux requieren una configuración diferente. Para obtener más información, consulte Eventos de clúster Linux de Service Fabric en Syslog.
- Puede configurar el agente de Azure Monitor para enviar registros del SO invitado a los registros de Azure Monitor, donde puede consultarlos mediante Log Analytics.
- Puede escribir registros de contenedor de Service Fabric en stdout o stderr para que estén disponibles en los registros de Azure Monitor.
- Puede configurar la solución de supervisión de contenedores para registros de Azure Monitor para ver eventos de contenedor.
Otras soluciones de registro
Aunque las dos soluciones recomendadas (registros de Azure Monitor y Application Insights) tienen incorporada la integración con Service Fabric, muchos eventos se escriben mediante proveedores de ETW y pueden ampliarse con otras soluciones de registro. También necesita consultar Elastic Stack (especialmente, si planea ejecutar un clúster en un entorno sin conexión), Dynatrace o cualquier otra plataforma que prefiera. Para obtener una lista de asociados integrados, consulte Asociados de supervisión de Azure Service Fabric.
Los puntos clave para cualquier plataforma que elija deben incluir su grado de comodidad con la interfaz de usuario, las funcionalidades de consulta, las visualizaciones y los paneles personalizados disponibles, y las herramientas adicionales que proporcionen para mejorar la experiencia de supervisión.
Registro de actividades de Azure
El registro de actividad contiene eventos de nivel de suscripción que realizan el seguimiento de las operaciones de cada recurso de Azure, tal como se ve desde fuera de ese recurso; por ejemplo, crear un recurso o iniciar una máquina virtual.
Recopilación: los eventos del registro de actividad se generan y recopilan automáticamente en un almacén independiente para su visualización en Azure Portal.
Enrutamiento: puedes enviar datos del registro de actividad a los registros de Azure Monitor para poder analizarlos junto con otros datos de registro. También están disponibles otras ubicaciones como Azure Storage, Azure Event Hubs y determinados asociados de supervisión de Microsoft. Para más información sobre cómo enrutar el registro de actividad, consulte Información general del registro de actividad de Azure.
Analizar los datos de supervisión
Hay muchas herramientas para analizar los datos de supervisión.
Herramientas de Azure Monitor
Azure Monitor admite las siguientes herramientas básicas:
Explorador de métricas: una herramienta de Azure Portal que le permite ver y analizar métricas de recursos de Azure. Para obtener más información, consulte Análisis de métricas con el explorador de métricas de Azure Monitor.
Log Analytics, una herramienta de Azure Portal que le permite consultar y analizar datos de registro mediante el lenguaje de consulta Kusto (KQL). Para más información, consulte Introducción a las consultas de registro en Azure Monitor.
El registro de actividad: que tiene una interfaz de usuario en Azure Portal para visualización y búsquedas básicas. Para realizar un análisis más detallado, debe enrutar los datos a los registros de Azure Monitor y ejecutar consultas más complejas en Log Analytics.
Entre las herramientas que permiten una visualización más compleja se incluyen:
- Paneles que permiten combinar diferentes tipos de datos en un único panel de Azure Portal.
- Libros: informes personalizables que se pueden crear en Azure Portal. Los libros pueden incluir texto, métricas y consultas de registro.
- Grafana: una herramienta de plataforma abierta que se destaca en los paneles operativos. Puede usar Grafana para crear paneles que incluyan datos de varios orígenes distintos de Azure Monitor.
- Power BI: un servicio de análisis empresarial que proporciona visualizaciones interactivas en varios orígenes de datos. Puede configurar Power BI para que los datos de registro se importen automáticamente desde Azure Monitor y utilizar estas otras adicionales.
Para obtener información general sobre los escenarios comunes de análisis de supervisión de Service Fabric, consulte Diagnóstico de escenarios comunes con Service Fabric.
Herramientas de exportación de Azure Monitor
Puede obtener datos de Azure Monitor en otras herramientas mediante los siguientes métodos:
Métricas: con la API de REST para métricas puede extraer datos de métricas de la base de datos de métricas de Azure Monitor. La API admite expresiones de filtro para refinar los datos recuperados. Para obtener más información, consulte Referencia de la API de REST de Azure Monitor.
Registros: use la API de REST o las bibliotecas de cliente asociadas.
Otra opción es la exportación de datos del área de trabajo.
Para empezar a trabajar con la API de REST para Azure Monitor, consulte Tutorial de la API de REST de supervisión de Azure.
Consultas de Kusto
Puedes analizar datos de supervisión en el almacén de registros de Azure Monitor o Log Analytics mediante el lenguaje de consulta Kusto (KQL).
Importante
Al seleccionar Registros en el menú del servicio del portal, Log Analytics se abre con el ámbito de consulta establecido en el servicio actual. Este ámbito significa que las consultas de registro solo incluirán datos de ese tipo de recurso. Si quiere ejecutar una consulta que incluya datos de otros servicios de Azure, seleccione Registros en el menú Azure Monitor. Consulte Ámbito e intervalo de tiempo de una consulta de registro en Log Analytics de Azure Monitor para obtener más información.
Para obtener una lista de las consultas comunes de cualquier servicio, consulte Interfaz de consultas de Log Analytics.
Consultas de ejemplo
Las siguientes consultas devuelven eventos de Service Fabric, incluidas las acciones en los nodos. Para ver otras consultas útiles, consulte Eventos de Service Fabric.
Devolver eventos operativos registrados en la última hora:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Devolver informes de mantenimiento con HealthState == 3 (Error) y extraer más propiedades del campo EventMessage:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Obtener eventos operativos de Service Fabric agregados con el servicio y el nodo específicos:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Alertas
Las alertas de Azure Monitor le informan de forma proactiva cuando se detectan condiciones específicas en los datos que se supervisan. Las alertas permiten identificar y solucionar las incidencias en el sistema antes de que los clientes puedan verlos. Para obtener más información, vea Alertas de Azure Monitor.
Hay muchos orígenes de alertas comunes para los recursos de Azure. Para obtener ejemplos de alertas comunes para recursos de Azure, consulte Consultas de alertas de registro de ejemplo. El sitio de Alertas de línea de base de Azure Monitor (AMBA) proporciona un método semiautomatizado para implementar alertas, paneles e instrucciones importantes de métricas de plataforma. El sitio se aplica a un subconjunto de servicios de Azure que se expande continuamente, incluidos todos los servicios que forman parte de la zona de aterrizaje de Azure (ALZ).
El esquema de alerta común normaliza el consumo de notificaciones de alerta de Azure Monitor. Para obtener más información, consulte Esquema de alertas comunes.
Tipos de alertas
Puede alertar sobre cualquier métrica o fuente de datos de registro en la plataforma de datos de Azure Monitor. Hay muchos tipos diferentes de alertas en función de los servicios que está supervisando y de los datos de supervisión que está recopilando. Los distintos tipos de alertas tienen varias ventajas y desventajas. Para obtener más información, consulte Elegir el tipo de alerta de supervisión adecuado.
En la siguiente lista se describen los tipos de alertas de Azure Monitor que puede crear:
- Alertas de métricas: evalúan las métricas de recursos a intervalos regulares. Las métricas pueden ser métricas de plataforma, métricas personalizadas, registros de Azure Monitor convertidos en métricas o métricas de Application Insights. Las alertas de métricas también pueden aplicar varias condiciones y umbrales dinámicos.
- Alertas de registro: permiten a los usuarios emplear una consulta de Log Analytics para evaluar los registros de recursos con una frecuencia predefinida.
- Alertas del registro de actividad: se desencadenan cuando se produce un nuevo evento del registro de actividad que coincide con las condiciones definidas. Las alertas de Resource Health y de Service Health son alertas del registro de actividad que informan sobre el servicio y el estado de los recursos.
Algunos servicios de Azure también admiten alertas de detección inteligente, alertas de Prometheus, o reglas de alerta recomendadas.
Para algunos servicios, puede supervisar a escala aplicando la misma regla de alertas de métricas a varios recursos del mismo tipo que existen en la misma región de Azure. Se envían notificaciones individuales para cada recurso supervisado. Para obtener servicios y nubes de Azure compatibles, consulte Supervisión de varios recursos con una regla de alerta.
Reglas de alerta de Service Fabric
En la siguiente tabla se enumeran algunas reglas de alerta para Service Fabric. Estas alertas son solo ejemplos. Puede configurar alertas para cualquier métrica, entrada de registro o entrada de registro de actividad que figura en la Referencia de datos de supervisión de Service Fabric o la Lista de eventos de Service Fabric.
| Tipo de alerta | Condición | Descripción |
|---|---|---|
| Evento de nodo | El nodo deja de funcionar | ServiceFabricOperationalEvent donde EventID >= 25622 y EventID <= 25626. Estos identificadores de evento se encuentran en la Referencia de eventos de nodo. |
| Datos de registro de | Reversión de actualizaciones de aplicaciones | ServiceFabricOperationalEvent donde EventID == 29623 o EventID == 29624. Estos identificadores de evento se encuentran en la Referencia de eventos de aplicación. |
| Estado de los recursos | Servicio de actualización inaccesible o no disponible | El clúster va al estado UpgradeServiceUnreachable. |
Recomendaciones de Advisor
Para algunos servicios, si se producen condiciones críticas o cambios inminentes durante las operaciones de recursos, se muestra una alerta en la página Información general del servicio del portal. Puede encontrar más información y correcciones recomendadas para la alerta en Recomendaciones de Advisor en Supervisión en el menú izquierdo. Durante las operaciones normales, no se muestran recomendaciones de Advisor.
Para más información sobre Azure Advisor, consulte Introducción a Azure Advisor.
Configuración recomendada
Después de repasar cada área de los escenarios de supervisión y ejemplo, aquí tiene un resumen de las herramientas de supervisión de Azure y la configuración necesarias para supervisar todas las áreas anteriores.
- Supervisión de aplicaciones con Application Insights
- Supervisión de clústeres con el agente de Azure Diagnostics y registros de Azure Monitor
- Supervisión de la infraestructura con registros de Azure Monitor
También puede utilizar y modificar la plantilla de ARM de ejemplo para automatizar la implementación de todos los recursos y agentes necesarios.
Contenido relacionado
- Consulte Referencia de datos de supervisión de Service Fabric para obtener una referencia de las métricas, registros y otros valores importantes creados para Service Fabric.
- Consulte Supervisión de recursos de Azure con Azure Monitor para obtener información general sobre la supervisión de recursos de Azure.
- Consulte la Lista de eventos de Service Fabric.