Zonas de aterrizaje de datos
Las zonas de aterrizaje de datos están conectadas a su zona de aterrizaje de administración de datos mediante el emparejamiento de red virtual (VNet). Cada zona de aterrizaje de datos se considera una zona de aterrizaje relacionada con la arquitectura de la zona de aterrizaje de Azure.
Importante
Antes de aprovisionar una zona de aterrizaje de datos, asegúrese de que el modelo operativo DevOps y CI/CD y la zona de aterrizaje de administración de datos están implementados.
Cada zona de aterrizaje de datos tiene varias capas que permiten la agilidad de las integraciones de datos de servicios y productos de datos que contiene. Puede desplegar una nueva zona de aterrizaje de datos con un conjunto estándar de servicios que permiten que la zona de aterrizaje de datos comience a ingerir y analizar datos.
La suscripción de Azure asociada a la zona de aterrizaje de datos tiene la siguiente estructura:
Nota
Una aplicación de datos genera uno o varios productos de datos.
Arquitectura de la zona de aterrizaje de datos
La arquitectura de la zona de aterrizaje de datos ilustra las capas, sus grupos de recursos y los servicios que contiene cada grupo de recursos. La arquitectura también proporciona una visión general de todos los grupos y roles asociados a su zona de aterrizaje de datos, además del alcance de su acceso a sus planos de control y datos.

Sugerencia
Antes de implementar una zona de aterrizaje de datos, asegúrese de que tiene en cuenta el número de zonas de aterrizaje de datos iniciales que quiere implementar.
Use esta arquitectura como punto de partida. Descargue el archivo de Visio y modifíquelo para que se ajuste a sus requisitos técnicos y empresariales concretos al planear la implementación de la zona de aterrizaje de datos.
Nivel de servicios principales
El nivel de servicios principales incluye todos los servicios necesarios para habilitar la zona de aterrizaje de datos en el contexto del análisis de escala en la nube. En la tabla siguiente se enumeran los grupos de recursos que proporcionan el conjunto estándar de servicios disponibles en cada zona de aterrizaje de datos que implemente.
| Grupo de recursos | Obligatorio | Descripción |
|---|---|---|
| network-rg | Sí | Redes |
| databricks-monitoring-rg | Opcional | Supervisión de áreas de trabajo de Azure Databricks |
| hive-rg | Opcional | Metastore de Hive para Azure Databricks |
| storage-rg | Sí | Servicios de lagos de datos |
| external-data-rg | Sí | Almacenamiento de ingesta de carga |
| runtimes-rg | Sí | Entornos de ejecución de integración compartidos |
| mgmt-rg | Sí | Agentes CI/CD |
| metadata-ingestion-rg | Opcional | Ingesta de datos agnóstica |
| databricks-monitoring-rg | Opcional | Área de trabajo de Log Analytics para áreas de trabajo de Databricks en la zona de aterrizaje |
| shared-synapse-rg | Opcional | Azure Synapse compartido |
| shared-databricks-rg | Opcional | Espacio de trabajo Azure Databricks compartido |
Redes
El grupo de recursos de red contiene componentes básicos, como Azure Network Watcher, grupos de seguridad de red (NSG) y una red virtual. Todos estos servicios se implementan en un único grupo de recursos.
La red virtual de su zona de aterrizaje de datos se empareja automáticamente con su red virtual de la zona de aterrizaje de administración de datos y su red virtual de la suscripción de conectividad.
Monitorización de áreas de trabajo de Azure Databricks
Este grupo de recursos es opcional y solo se implementa con Azure Databricks.
El patrón de zona de aterrizaje de Azure recomienda que envíe todos los registros a un área de trabajo central de Log Analytics. Sin embargo, cada zona de aterrizaje de datos también incluye un grupo de recursos de supervisión para capturar los registros de Spark de Databricks. Cada grupo de recursos contiene un área de trabajo compartido de Log Analytics y Azure Key Vault para almacenar las claves de Log Analytics.
Importante
Use solo el área de trabajo de Log Analytics en su grupo de recursos de supervisión de Databricks para capturar los registros de Spark de Azure Databricks.
Para obtener más información, consulte Supervisión de Azure Databricks.
Metastore de Hive para Azure Databricks
Este grupo de recursos es opcional y solo se debe implementar con Azure Databricks.
El metastore de Hive para Azure Databricks aprovisiona una base de datos de Azure Database for MySQL y un almacén de claves. Todas las áreas de trabajo de Azure Databricks de la zona de aterrizaje de datos usan este metastore como su metastore de Apache Hive externo.
Para más información, consulte Metastore de Hive externo de Apache.
Servicios de Data Lake
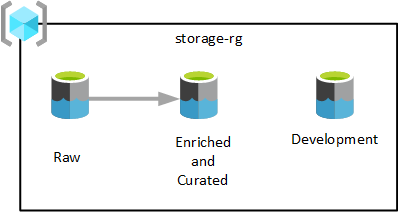
Como se muestra en el diagrama anterior, se aprovisionan tres cuentas de Azure Data Lake Storage Gen2 en un único grupo de recursos de servicios de lago de datos. Los datos transformados en diferentes fases se guardan en uno de sus lagos de datos de la zona de aterrizaje de datos. Los datos están disponibles para su consumo por parte de sus equipos de análisis, ciencia de datos y visualización.
Las capas de lago de datos usan terminología diferente en función de la tecnología y el proveedor. En esta tabla se proporcionan instrucciones sobre cómo aplicar términos para el análisis a escala de la nube:
| Análisis a escala de nube | Delta Lake | Otros términos | Descripción |
|---|---|---|---|
| Notificación sin procesar | Bronce | Aterrizaje y conformidad | Tablas de ingesta |
| Enriquecida | Plata | Zona de normalización | Tablas refinadas. Conjuntos de registros completos almacenados y listos para el consumo de sistemas de registro. |
| Mantenido | Oro | Zona de producto | Características o tablas agregadas. Zona principal para aplicaciones, equipos y usuarios para consumir productos de datos. |
| Desarrollo | -- | Zona de desarrollo | Ubicación para ingenieros de datos y científicos, que constan de un espacio aislado de análisis y una zona de desarrollo de productos. |
Nota
En el diagrama anterior, cada zona de aterrizaje de datos tiene tres lagos de datos. Sin embargo, en función de sus requisitos, es posible que desee consolidar las capas sin procesar, enriquecidas y seleccionadas en una cuenta de almacenamiento y mantener otra cuenta de almacenamiento denominada "desarrollo" para que los consumidores de datos incorporen otros productos de datos útiles.
Para más información, consulte:
- Introducción a Azure Data Lake Storage para el análisis en la nube
- Normalización de datos
- Aprovisionamiento de cuentas de Azure Data Lake Storage Gen2 para cada zona de aterrizaje de datos
- Consideraciones clave de Azure Data Lake Storage
- Control de acceso y configuraciones de lago de datos en Azure Data Lake Storage
Almacenamiento de ingesta de carga
Los publicadores de datos de terceros necesitan aterrizar datos en la plataforma para que los equipos de aplicaciones de datos puedan extraerlos en sus lagos de datos. Como se muestra en el diagrama siguiente, el grupo de recursos de almacenamiento de ingesta de carga le permite aprovisionar almacenes de blobs para terceros.
Los equipos de aplicaciones de datos solicitan estos blobs de almacenamiento. A continuación, el equipo de operaciones de la zona de aterrizaje de datos aprueba sus solicitudes. Los datos se deben quitar de su blob de almacenamiento de origen una vez que se extraen del blob de almacenamiento en sin procesar.
Importante
Dado que los blobs de Azure Storage se aprovisionan en función de las necesidades, debe desplegar inicialmente un grupo de recursos de servicios de almacenamiento vacío en cada zona de aterrizaje de datos.
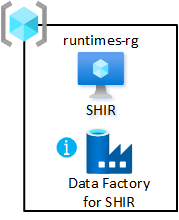
Entornos de ejecución de integración compartidos
Implemente una máquina virtual con entornos de ejecución de integración autohospedados en la zona de aterrizaje de datos. Hospede en el grupo de recursos de integración compartido. Esta implementación le permite incorporar rápidamente productos de datos a su zona de aterrizaje de datos.
Para eliminar el grupo de recursos:
- Cree al menos una Azure Data Factory en el grupo de recursos de integración compartidos de su zona de aterrizaje de datos. Utilícelo sólo para enlazar el tiempo de ejecución de integración compartido y autoalojado, no para las canalizaciones de datos.
- Cree y configure un entorno de ejecución de integración autohospedado en la máquina virtual.
- Asocie el entorno de ejecución de integración autohospedado con las fábricas de datos de Azure en las zonas de aterrizaje de datos.
- Configure Azure Automation para actualizar el entorno de ejecución de integración autohospedado periódicamente.
Nota:
La implementación anterior proporciona una única implementación de máquina virtual con entornos de ejecución de integración autohospedados. Puede asociar un entorno de ejecución de integración autohospedado con varias máquinas locales o máquinas virtuales en Azure. Estas máquinas se llaman nodos. Puede tener hasta cuatro nodos asociados con un entorno de ejecución de integración autohospedado. Las ventajas de tener varios nodos en máquinas locales que tienen una puerta de enlace instalada para una puerta de enlace lógica son:
- Mayor disponibilidad del entorno de ejecución de integración autohospedado, para que deje de ser el único punto de error de la solución de macrodatos o la integración de datos en la nube. Esta disponibilidad garantiza la continuidad al usar un máximo de cuatro nodos.
- Rendimiento mejorado durante el movimiento de datos entre almacenes de datos locales y en la nube. Obtenga más información sobre las comparaciones de rendimiento.
Puede asociar varios nodos mediante la instalación del software del entorno de ejecución de integración autohospedado desde el Centro de descarga. A continuación, regístrelo mediante cualquiera de las claves de autenticación obtenidas del cmdlet New-AzDataFactoryV2IntegrationRuntimeKey, tal como se describe en el tutorial.
En Alta disponibilidad y escalabilidad de Azure Data Factory se detalla información adicional.
Importante
Implemente entornos de ejecución de integración compartidos lo más cerca posible del origen de datos. Su implementación no restringe su implementación de entornos de ejecución de integración en de una zona de aterrizaje de datos o en nubes de terceros. En su lugar, proporciona una reserva para los orígenes de datos nativos y en la región en la nube.
Agentes CI/CD
Los agentes de CI/CD le ayudan a implementar aplicaciones de datos y cambios en la zona de aterrizaje de datos.
Para obtener más información, consulte agentes de canalización de Azure.
Ingesta de datos agnóstica
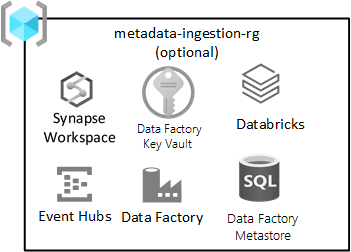
Este grupo de recursos es opcional y no le prohíbe implementar la zona de aterrizaje.
Este grupo de recursos se aplica si tiene (o está desarrollando) un motor de ingesta independiente de datos para ingerir datos automáticamente en función del registro de metadatos (incluidas las cadenas de conexión, la ruta de acceso para copiar datos de y hacia) y la programación de ingesta. El grupo de recursos de ingesta y procesamiento tiene servicios clave para este tipo de marco.
Implemente una instancia de Azure SQL Database para contener los metadatos usados por Azure Data Factory. Aprovisione una instancia de Azure Key Vault para almacenar secretos relacionados con los servicios de ingesta automatizados. Estos secretos pueden incluir:
- Credenciales del metastore de Azure Data Factory
- Credenciales de entidad de servicio para su proceso de ingesta automatizado
Para más información, consulte cómo los marcos de ingesta automatizada admiten el análisis en la nube en Azure.
Los servicios incluidos en este grupo de recursos son:
| Servicio | Obligatorio | Directrices |
|---|---|---|
| Azure Data Factory | Sí | Azure Data Factory es el motor de orquestación para la ingesta independiente de datos. |
| Azure SQL DB | Sí | Azure SQL DB es el metastore para Azure Data Factory. |
| Event Hubs o IoT Hub | Opcional | Los Event Hubs o Azure IoT Hub pueden proporcionar streaming en tiempo real a los Event Hubs, además de procesamiento por lotes y streaming a través de un área de trabajo de ingeniería de Databricks. |
| Azure Databricks | Opcional | Puede implementar Azure Databricks o Azure Synapse Spark para su uso con el motor de ingesta independiente de datos. |
| Azure Synapse | Opcional | Puede implementar Azure Databricks o Azure Synapse Spark para usarlo con el motor de ingesta independiente de datos. |
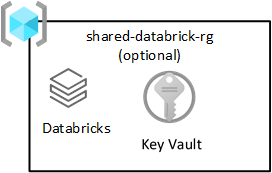
Databricks compartido
Este grupo de recursos es opcional y solo se implementa con Azure Databricks. Todos los usuarios de la zona de aterrizaje de datos pueden usar un área de trabajo de Databricks.
Azure Databricks es un consumidor clave del servicio Azure Data Lake Storage. Las operaciones de archivos atómicos están optimizadas para los motores analíticos de Spark. Esta optimización acelera la finalización de los trabajos de Spark que emite el servicio Azure Databricks.
Importante
Un área de trabajo de Azure Databricks llamado Azure Databricks (analytics) se aprovisiona para todos los científicos de datos y DataOps, como se muestra en el grupo de recursos de productos compartidos.
Puede configurar este área de trabajo para conectarse a su Azure Data Lake utilizando el paso de Microsoft Entra o el control de acceso a la tabla. En función de su caso de uso, puede configurar el acceso condicional como otra medida de seguridad.
Siga los procedimientos recomendados de análisis de escala en la nube para integrar Azure Databricks:
- Proteja el acceso a Azure Data Lake Gen2 desde Azure Databricks
- Procedimientos recomendados de Azure Databricks
El patrón de zona de aterrizaje de Azure recomienda que envíe todos los registros a un área de trabajo central de Log Analytics. Sin embargo, cada zona de aterrizaje de datos también contiene un grupo de recursos de supervisión para capturar los registros de Spark de Databricks.
Análisis de Azure Synapse compartido
Este grupo de recursos es opcional.
Durante la configuración inicial de una zona de aterrizaje de datos, se despliega un único área de trabajo de Azure Synapse Analytics para que lo utilicen todos los analistas y científicos de datos de su grupo de recursos de productos compartidos.
Puede configurar más áreas de trabajo de sinapsis para los productos de datos si se requiere la gestión de costes y la recarga. Sus equipos de aplicaciones de datos podrían hacer uso de áreas de trabajo dedicadas de Azure Synapse Analytics para crear grupos dedicados de Azure SQL Database como almacén de datos de lectura utilizado por su capa de visualización.
Importante
Evite el uso de su área de trabajo compartido de Azure Synapse para la creación de productos de datos bloqueando el espacio de trabajo para permitir únicamente las consultas SQL On-demand. Sólo está disponible para fines de explotación.
Aplicación de datos
Cada zona de aterrizaje de datos puede tener varios productos de datos. Puede crear estos productos de datos mediante la ingesta de datos desde el origen. También puede crear productos de datos a partir de otros productos de datos dentro de la misma zona de destino de datos o de otras zonas de destino de datos. La creación de los productos de datos está sujeta a la aprobación del administrador de datos.
Grupo de recursos del producto de datos
Su producto de grupo de recursos de productos de datos incluye todos los servicios necesarios para realizar ese producto de datos. Por ejemplo, se requiere una instancia de Azure Database para MySQL, que usa una herramienta de visualización. Los datos deben ser ingeridos y transformados antes de llegar a esa base de datos MySQL. En este caso, puede implementar Azure Database for MySQL y una Azure Data Factory en el grupo de recursos de productos de datos.
Sugerencia
Si decide no implementar un motor independiente de datos para ingerir una vez desde orígenes operativos, o si las conexiones complejas no se facilitan en el motor de datos independiente de los datos, cree una aplicación de datos alineada con el origen. Para más información, consulte Aplicaciones de datos (alineados con el origen)
Para obtener más información sobre cómo incorporar productos de datos, consulte Productos de datos analíticos a escala de la nube en Azure.
Visualización
Para cada zona de aterrizaje de datos, se crea un grupo de recursos de visualización vacío. Rellene este grupo de recursos con los servicios que necesita para implementar la solución de visualización. El uso de su VNet existente permite que su solución se conecte a los productos de datos.
Este grupo de recursos puede hospedar máquinas virtuales para servicios de visualización de terceros.
Sugerencia
Debido a los costes de las licencias, podría ser más económico desplegar productos de visualización de terceros en su zona de aterrizaje de gestión de datos, y que esos productos se conecten a través de las zonas de aterrizaje de datos para extraer datos.