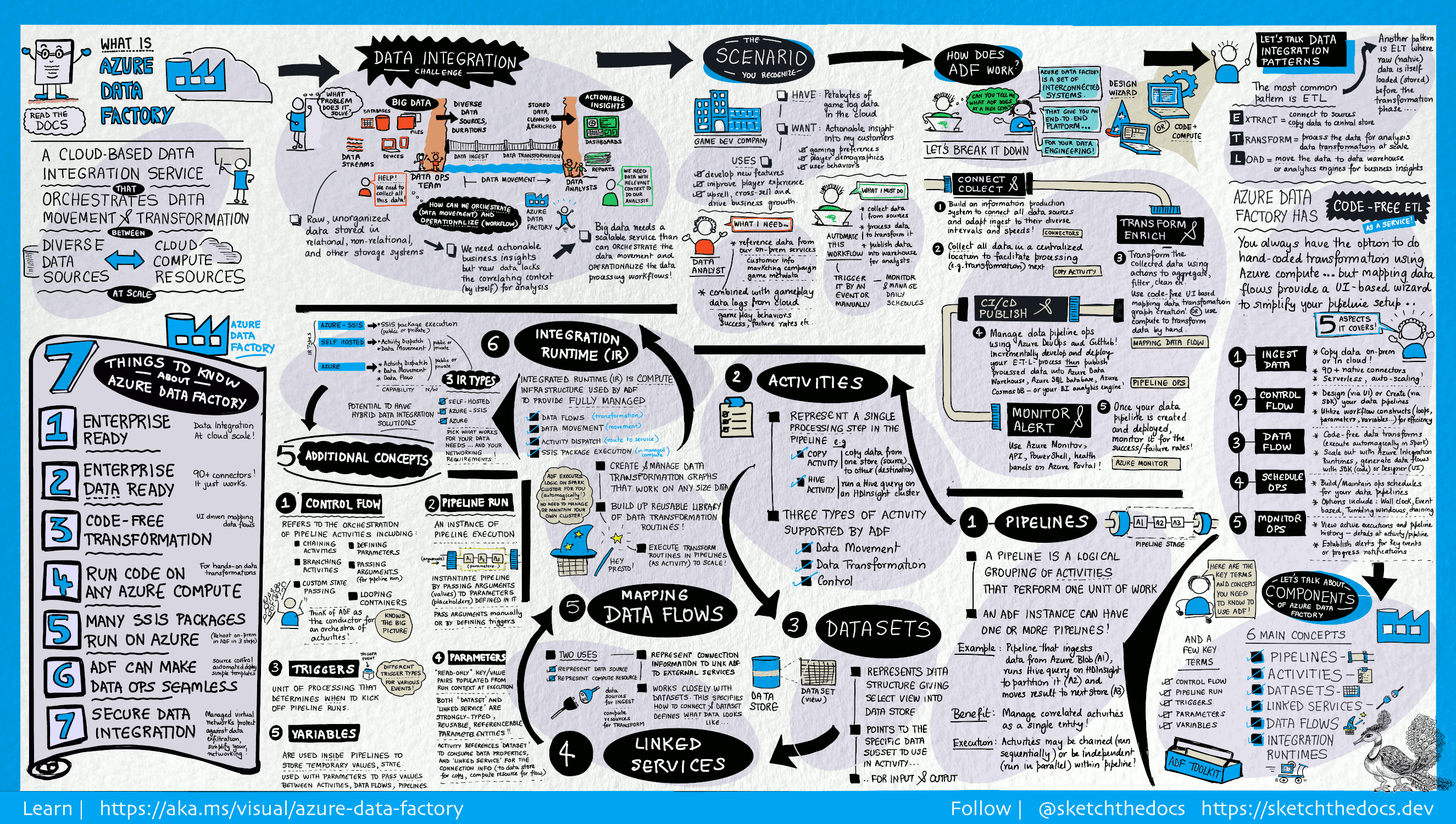
¿Qué es Azure Data Factory?
SE APLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En el mundo de los macrodatos, los datos sin procesar y desorganizados suelen almacenarse en sistemas de almacenamiento relacionales, no relacionales y de otros tipos. Sin embargo, en sí mismos, los datos sin procesar no tienen el contexto o el significado adecuados para proporcionar información significativa a los analistas, científicos de datos y responsables de decisiones empresariales.
Los macrodatos requieren un servicio que pueda orquestar y operacionalizar los procesos para convertir estos enormes almacenes de datos sin procesar en información empresarial en función de la cual se puedan emprender acciones. Azure Data Factory es un servicio en la nube administrado creado para estos complejos proyectos híbridos de extracción, transformación y carga (ETL), extracción, carga y transformación (ELT) e integración de datos.
Características de Azure Data Factory
Compresión de datos: durante la actividad de copia de datos, es posible comprimir los datos y escribir los datos comprimidos en el origen de datos de destino. Esta característica ayuda a optimizar el uso del ancho de banda en la copia de datos.
Amplia compatibilidad de conectividad con orígenes de datos diferentes: Azure Data Factory proporciona una amplia compatibilidad con la conectividad para conectarse a diferentes orígenes de datos. Esto resulta útil cuando desea extraer o escribir datos de orígenes de datos diferentes.
Desencadenadores de eventos personalizados: Azure Data Factory permite automatizar el procesamiento de datos mediante desencadenadores de eventos personalizados. Esta característica permite ejecutar automáticamente una determinada acción cuando se produce un evento concreto.
Vista previa y validación de datos: durante la actividad de copia de datos, se proporcionan herramientas para obtener una vista previa y validar los datos. Esta característica le ayuda a asegurarse de que los datos se copian y se escriben en el origen de datos de destino correctamente.
Flujos de datos personalizables: Azure Data Factory permite crear flujos de datos personalizables. Esta característica permite agregar acciones personalizadas o pasos para el procesamiento de datos.
Seguridad integrada: Azure Data Factory ofrece características de seguridad integradas, como la integración de Entra ID y el control de acceso basado en rol para controlar el acceso a los flujos de datos. Esta característica aumenta la seguridad en el procesamiento de datos y protege los datos.
Escenarios de uso
Por ejemplo, imagine una empresa de juegos que recopila petabytes de registros de juegos generados por juegos en la nube. La empresa quiere analizar estos registros para obtener información sobre las preferencias de los clientes, los datos demográficos y el comportamiento de uso. También quiere identificar oportunidades de venta cruzada y vertical, desarrollar nuevas y atractivas características, impulsar el crecimiento empresarial y ofrecer una mejor experiencia a sus clientes.
Para analizar estos registros, la empresa debe usar datos de referencia, como información de clientes, información de juegos e información de campañas de marketing, que se encuentran en un almacén de datos local. La empresa quiere usar estos datos del almacén de datos local y combinarlos con datos de registro adicionales que tiene en un almacén de datos en la nube.
Para extraer información, espera procesar los datos combinados mediante un clúster de Spark en la nube (Azure HDInsight) y publicar los datos transformados en un almacenamiento de datos en la nube, como Azure Synapse Analytics, para generar fácilmente un informe a partir de él. Quieren automatizar este flujo de trabajo y supervisarlo y administrarlo según una programación diaria. También quieren ejecutarlo cuando los archivos lleguen a un contenedor de almacén de blobs.
Azure Data Factory es la plataforma que resuelve estos escenarios de datos. Se trata de un servicio de integración de datos y ETL basado en la nube que le permite crear flujos de trabajo orientados a datos a fin de coordinar el movimiento y la transformación de datos a escala. Con Azure Data Factory, puede crear y programar flujos de trabajo basados en datos (llamados canalizaciones) que pueden ingerir datos de distintos almacenes de datos. Puede crear procesos ETL complejos que transformen datos visualmente con flujos de datos o mediante servicios de proceso como Azure HDInsight Hadoop, Azure Databricks y Azure SQL Database.
Además, puede publicar los datos transformados en almacenes de datos, como Azure Synapse Analytics, para que los consuman aplicaciones de inteligencia empresarial (BI). En última instancia, mediante Azure Data Factory, los datos sin procesar se pueden organizar en almacenes de datos y Data Lakes significativos para tomar mejores decisiones empresariales.
¿Cómo funciona?
Data Factory contiene una serie de sistemas interconectados que proporcionan una plataforma completa de un extremo a otro para los ingenieros de datos.

En esta guía visual se proporciona información detallada sobre la totalidad de la arquitectura del servicio Data Factory:

Para obtener más detalles, seleccione la imagen anterior para acercarla o examine la imagen de alta resolución.
{kind=link}
Conectar y recopilar
Las empresas tienen datos de varios tipos que se encuentran en orígenes locales dispares, en la nube, estructurados, no estructurados y semiestructurados, que llegan todos según distintos intervalos y velocidades.
El primer paso en la creación de un sistema de producción de información es conectarse a todos los orígenes de datos y procesamiento necesarios, como servicios de software como servicio (SaaS), bases de datos, recursos compartidos de archivos y servicios web FTP. El siguiente paso es mover los datos según sea necesario a una ubicación centralizada para su posterior procesamiento.
Sin Data Factory, las empresas deben crear componentes de movimiento de datos personalizados o escribir servicios personalizados para integrar estos orígenes de datos y procesamientos. Estos sistemas son costosos y difíciles de mantener e integrar. Además, con frecuencia carecen de la supervisión de grado empresarial, las alertas y los controles que puede ofrecer un servicio totalmente administrado.
Con Data Factory, puede usar la actividad de copia en una canalización de datos para mover los datos desde almacenes de datos de origen locales y en la nube a un almacén de datos de centralización en la nube para su posterior análisis. Por ejemplo, puede recopilar datos de Azure Data Lake Storage y transformarlos posteriormente mediante un servicio de proceso de Azure Data Lake Analytics. También puede recopilar datos de Azure Blob Storage y transformarlos más adelante mediante un clúster de Azure HDInsight Hadoop.
Transformar y enriquecer
Cuando los datos están presentes en un almacén de datos centralizado en la nube, procese o transforme los datos recopilados mediante flujos de datos de asignación de ADF. Los flujos de datos permiten a los ingenieros de datos crear y mantener gráficos de transformación de datos que se ejecutan en Spark sin necesidad de comprender los clústeres de Spark o la programación de Spark.
Si prefiere codificar las transformaciones a mano, ADF admite actividades externas para ejecutar las transformaciones en servicios de proceso como HDInsight Hadoop, Spark, Data Lake Analytics y Machine Learning.
CI/CD y publicación
Data Factory ofrece compatibilidad total con CI/CD de sus canalizaciones de datos mediante Azure DevOps y GitHub. Esto le permite desarrollar y distribuir incrementalmente los procesos ETL antes de publicar el producto terminado. Después de refinar los datos sin procesar a un formato compatible listo para empresas, cargue los datos en Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB o en cualquier motor de análisis al que puedan apuntar los usuarios mediante las herramientas de inteligencia empresarial.
Supervisión
Una vez creada e implementada correctamente la canalización de integración de datos, que proporciona un valor empresarial a partir de datos procesados, supervise las canalizaciones y las actividades programadas para ver las tasas de éxito y error. Azure Data Factory tiene compatibilidad integrada para la supervisión de canalizaciones mediante Azure Monitor, API, PowerShell, los registros de Azure Monitor y los paneles de mantenimiento de Azure Portal.
Conceptos de nivel superior
Una suscripción de Azure puede tener una o varias instancias de Azure Data Factory (o factorías de datos). Azure Data Factory se compone de los siguientes componentes clave:
- Pipelines
- Actividades
- Conjuntos de datos
- Servicios vinculados
- Flujos de datos
- Integration Runtime
Estos componentes funcionan juntos para proporcionar la plataforma en la que pueda crear flujos de trabajo basados en datos con pasos para moverlos y transformarlos.
Canalización
Una factoría de datos puede tener una o más canalizaciones. La canalización es una agrupación lógica de actividades para realizar una unidad de trabajo. Juntas, las actividades de una canalización realizan una tarea. Por ejemplo, una canalización puede contener un grupo de actividades que ingiere datos de un blob de Azure y luego ejecutar una consulta de Hive en un clúster de HDInsight para particionar los datos.
La ventaja de esto es que la canalización le permite administrar las actividades como un conjunto en lugar de tener que administrar cada una de ellas individualmente. Las actividades de una canalización se pueden encadenar juntas para operar de forma secuencial o pueden funcionar de forma independiente en paralelo.
Asignación de flujos de datos
Cree y administre gráficos de lógica de transformación de datos que puede usar para transformar datos de cualquier tamaño. Puede crear una biblioteca reutilizable de rutinas de transformación de datos y ejecutar esos procesos con escalabilidad horizontal desde las canalizaciones de ADF. Data Factory ejecutará la lógica en un clúster de Spark que se pone en marcha y se detiene cuando lo necesita. Nunca tendrá que administrar o mantener clústeres.
Actividad
Las actividades representan un paso del procesamiento en una canalización. Por ejemplo, puede usar una actividad de copia para copiar datos de un almacén de datos a otro. De igual forma, puede usar una actividad de Hive, que ejecuta una consulta de Hive en un clúster de Azure HDInsight para transformar o analizar los datos. Data Factory admite tres tipos de actividades: actividades de movimiento de datos, actividades de transformación de datos y actividades de control.
Conjuntos de datos
Los conjuntos de datos representan las estructuras de datos de los almacenes de datos que simplemente apuntan o hacen referencia a los datos que desea utilizar en sus actividades como entradas o salidas.
Servicios vinculados
Los servicios vinculados son muy similares a las cadenas de conexión que definen la información de conexión necesaria para que Data Factory se conecte a recursos externos. Considérelos de esta forma: un servicio vinculado define la conexión al origen de datos y un conjunto de datos representa la estructura de los datos. Por ejemplo, un servicio vinculado de Azure Storage especifica la cadena de conexión para conectarse a la cuenta de Azure Storage. Además, un conjunto de datos de Azure Blob especifica el contenedor de blobs y la carpeta que contiene los datos.
Los servicios vinculados se utilizan con dos fines en Data Factory:
Para representar un almacén de datos que incluye, entre otros, una base de datos de SQL Server, una base de datos de Oracle, un recurso compartido de archivos o una cuenta de Azure Blob Storage. Para obtener una lista de almacenes de datos compatibles, consulte el artículo actividad de copia.
Para representar un recurso de proceso que puede hospedar la ejecución de una actividad. Por ejemplo, la actividad HDInsightHive se ejecuta en un clúster de Hadoop para HDInsight. Consulte el artículo sobre transformación de datos para ver una lista de los entornos de proceso y las actividades de transformación admitidos.
Integration Runtime
En Data Factory, una actividad define la acción que se realizará. Un servicio vinculado define un almacén de datos o un servicio de proceso de destino. Una instancia de Integration Runtime proporciona el puente entre la actividad y los servicios vinculados. La actividad o el servicio vinculado hace referencia a él, y proporciona el entorno de proceso donde se ejecuta la actividad o desde donde se distribuye. De esta manera, la actividad puede realizarse en la región más cercana posible al almacén de datos o servicio de proceso de destino de la manera con mayor rendimiento, a la vez que se satisfacen las necesidades de seguridad y cumplimiento.
Desencadenadores
Los desencadenadores representan una unidad de procesamiento que determina cuándo es necesario poner en marcha una ejecución de canalización. Existen diferentes tipos de desencadenadores para diferentes tipos de eventos.
Ejecuciones de la canalización
Una ejecución de la canalización es una instancia de la ejecución de la canalización. Normalmente, las instancias de ejecuciones de canalización se crean al pasar argumentos a los parámetros definidos en las canalizaciones. Los argumentos se pueden pasar manualmente o dentro de la definición del desencadenador.
Parámetros
Los parámetros son pares clave-valor de configuración de solo lectura. Los parámetros se definen en la canalización. Los argumentos de los parámetros definidos se pasan durante la ejecución desde el contexto de ejecución creado por un desencadenador o una canalización que se ejecuta manualmente. Las actividades dentro de la canalización consumen los valores de parámetro.
Un conjunto de datos es un parámetro fuertemente tipado y una entidad reutilizable o a la que se puede hacer referencia. Una actividad puede hacer referencia a conjuntos de datos y puede consumir las propiedades definidas en la definición del conjunto de datos.
Un servicio vinculado también es un parámetro fuertemente tipado que contiene la información de conexión a un almacén de datos o a un entorno de proceso. También es una entidad reutilizable o a la que se puede hacer referencia.
Flujo de control
El flujo de control es una orquestación de actividades de canalización que incluye el encadenamiento de actividades en una secuencia, la bifurcación, la definición de parámetros en el nivel de canalización y el paso de argumentos mientras se invoca la canalización a petición o desde un desencadenador. También incluye el paso a un estado personalizado y contenedores de bucle, es decir, los iteradores Para cada.
variables
Las variables se pueden usar dentro de las canalizaciones para almacenar valores temporales y también se pueden usar junto con parámetros para habilitar el paso de valores entre canalizaciones, flujos de datos y otras actividades.
Contenido relacionado
Estos son los documentos importantes del paso siguiente que se van a explorar:
- Dataset and linked services (Conjuntos de datos y servicios vinculados)
- Canalizaciones y actividades
- Integration runtime (Tiempo de ejecución de integración)
- Asignación de flujos de datos
- Interfaz de usuario de Data Factory en Azure Portal
- Herramienta Copiar datos de Azure Portal
- PowerShell
- .NET
- Python
- REST
- Plantilla de Azure Resource Manager
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de