Copier des données depuis/vers un système de fichiers à l’aide d’Azure Data Factory ou d’Azure Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment copier des données vers et depuis le système de fichiers. Pour en savoir plus, lisez l’article d’introduction pour Azure Data Factory ou Azure Synapse Analytics.
Fonctionnalités prises en charge
Ce connecteur de système de fichiers est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Activité de recherche | ① ② |
| Activité GetMetadata | ① ② |
| Supprimer l’activité | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Plus précisément, ce connecteur de système de fichiers prend en charge ce qui suit :
- Copie de fichiers vers/à partir d’un partage de fichiers réseau. Pour utiliser un partage de fichiers Linux, installez Samba sur votre serveur Linux.
- Copie de fichiers en utilisant une authentification Windows.
- Copie de fichiers en l'état ou analyse/génération de fichiers avec les formats de fichier et codecs de compression pris en charge.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié de système de fichiers à l’aide de l’interface utilisateur
Suivez les étapes suivantes pour créer un service lié à un système de fichiers dans l'interface utilisateur du portail Azure.
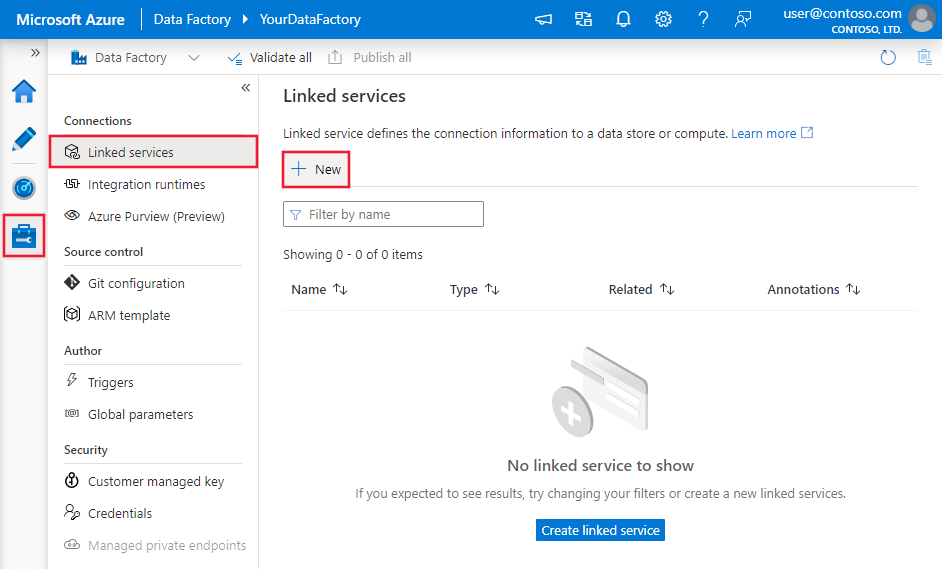
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis sélectionnez Nouveau :
Recherchez fichier et sélectionnez le connecteur du système de fichiers.
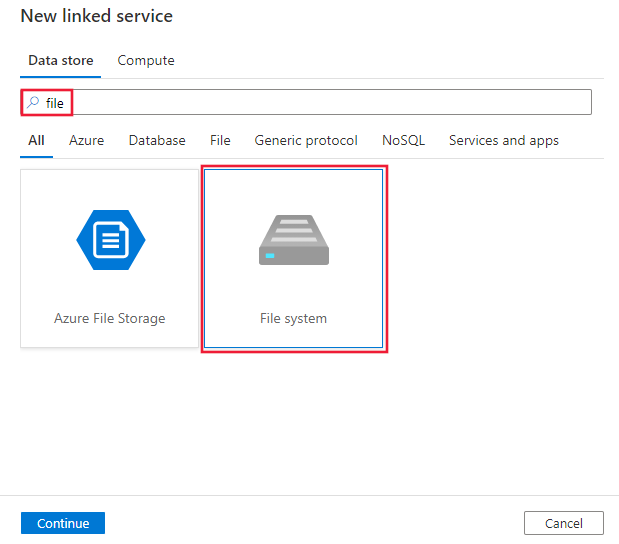
Configurez les informations du service, testez la connexion et créez le nouveau service lié.

Informations de configuration des connecteurs
Les sections suivantes fournissent des informations détaillées sur les propriétés utilisées pour définir les entités de pipeline Data Factory et Synapse spécifiques du système de fichiers.
Propriétés du service lié
Les propriétés prises en charge pour le service lié de système de fichiers sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : FileServer. | Oui |
| host | Spécifie le chemin d’accès racine du dossier que vous souhaitez copier. Utilisez le caractère d’échappement "" pour les caractères spéciaux contenus dans la chaîne. Consultez la section Exemples de définitions de jeux de données et de service liés pour obtenir des exemples. | Oui |
| userId | Spécifiez l’ID de l’utilisateur qui a accès au serveur. | Oui |
| mot de passe | Spécifiez le mot de passe de l’utilisateur (userid). Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Oui |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemples de définitions de jeux de données et de service liés
| Scénario | « host » dans la définition du service lié | « folderPath » dans la définition du jeu de données |
|---|---|---|
| Dossier partagé distant : Exemples : \\myserver\share\* ou \\myserver\share\folder\subfolder\* |
Dans JSON : \\\\myserver\\shareSur l’interface utilisateur : \\myserver\share |
Dans JSON : .\\ ou folder\\subfolderSur l’interface utilisateur : .\ ou folder\subfolder |
Notes
Lors d’une création via l’interface utilisateur, vous n’avez pas besoin d’entrer la double barre oblique inverse (\\) pour générer une séquence d’échappement comme vous le faites via JSON. Spécifiez simplement une barre oblique inverse unique.
Notes
La copie de fichiers à partir d’un ordinateur local n’est pas prise en charge dans Azure Integration Runtime.
Reportez-vous aux informations sur la ligne de commande à partir de cette section pour activer l’accès à l’ordinateur local sous le runtime d’intégration auto-hébergé. Par défaut, elle est désactivée.
Exemple :
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données.
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour le système de fichiers sous les paramètres location dans le jeu de données basé sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous location dans le jeu de données doit être définie sur FileServerLocation. |
Oui |
| folderPath | Chemin d’accès du dossier. Si vous souhaitez utiliser un caractère générique pour filtrer le dossier, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. Vous devez configurer l’emplacement du partage de fichiers dans votre environnement Windows ou Linux pour exposer le dossier au partage. | Non |
| fileName | Nom de fichier dans le chemin d’accès folderPath donné. Si vous souhaitez utiliser un caractère générique pour filtrer les fichiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
Exemple :
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par le système de fichiers en tant que source et récepteur.
Système de fichiers en tant que source
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour le système de fichiers sous les paramètres storeSettings dans la source de copie basée sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type sous storeSettings doit être définie sur FileServerReadSettings. |
Oui |
| Recherchez les fichiers à copier : | ||
| OPTION 1 : chemin d’accès statique |
Copiez à partir du chemin d’accès au dossier/fichier spécifié dans le jeu de données. Si vous souhaitez copier tous les fichiers d’un dossier, spécifiez en plus wildcardFileName comme *. |
|
| OPTION 2 : filtre côté serveur - fileFilter |
Filtre natif côté serveur de fichiers, qui offre de meilleures performances que le filtre de caractères génériques OPTION 3. Utilisez * pour faire correspondre zéro ou plusieurs caractères et ? pour faire correspondre zéro ou un caractère. Apprenez-en davantage sur la syntaxe et les remarques dans Remarques sous cette section. |
Non |
| OPTION 3 : filtre côté client - wildcardFolderPath |
Chemin d’accès du dossier avec des caractères génériques pour filtrer les dossiers sources. Ce filtre au niveau du service énumère les dossiers/fichiers situés sous le chemin donné, puis applique le filtre de caractères génériques. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de dossier contient effectivement ce caractère d’échappement ou générique. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Non |
| OPTION 3 : filtre côté client - wildcardFileName |
Nom du fichier avec des caractères génériques situé dans le chemin d’accès folderPath/wildcardFolderPath donné pour filtrer les fichiers sources. Ce filtre au niveau du service énumère les fichiers situés sous le chemin donné, puis applique le filtre de caractères génériques. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de fichier contient effectivement ce caractère d’échappement ou générique.Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Oui |
| OPTION 3 : liste de fichiers - fileListPath |
Indique de copier un ensemble de fichiers donné. Pointez vers un fichier texte contenant la liste des fichiers que vous voulez copier, un fichier par ligne indiquant le chemin d’accès relatif configuré dans le jeu de données. Si vous utilisez cette option, ne spécifiez pas de nom de fichier dans le jeu de données. Pour plus d’exemples, consultez Exemples de listes de fichiers. |
Non |
| Paramètres supplémentaires : | ||
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Lorsque l’option « recursive » est définie sur true et que le récepteur est un magasin basé sur un fichier, un dossier vide ou un sous-dossier n’est pas copié ou créé sur le récepteur. Les valeurs autorisées sont true (par défaut) et false. Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| deleteFilesAfterCompletion | Indique si les fichiers binaires sont supprimés du magasin source après leur déplacement vers le magasin de destination. La suppression des fichiers se fait par fichier, Cela signifie que lorsque l’activité échoue, vous voyez certains fichiers déjà copiés dans la destination et supprimés de la source, tandis que d’autres restent dans le magasin source. Cette propriété est valide uniquement dans un scénario de copie de fichiers binaires. La valeur par défaut est false. |
Non |
| modifiedDatetimeStart | Filtre de fichiers en fonction de l’attribut : Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format AAAA-MM-JJTHH:mm:ssZ. Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés.Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| modifiedDatetimeEnd | Identique à modifiedDateTimeStart. | Non |
| enablePartitionDiscovery | Pour les fichiers partitionnés, spécifiez s’il faut analyser les partitions à partir du chemin d’accès au fichier et les ajouter en tant que colonnes sources supplémentaires. Les valeurs autorisées sont false (par défaut) et true. |
Non |
| partitionRootPath | Lorsque la découverte de partition est activée, spécifiez le chemin d’accès racine absolu pour pouvoir lire les dossiers partitionnés en tant que colonnes de données. S’il n’est pas spécifié, par défaut, – Quand vous utilisez le chemin d’accès du fichier dans le jeu de données ou la liste des fichiers sur la source, le chemin racine de la partition est le chemin d’accès configuré dans le jeu de données. – Quand vous utilisez le filtre de dossiers de caractères génériques, le chemin racine de la partition est le sous-chemin avant le premier caractère générique. Par exemple, en supposant que vous configurez le chemin d’accès dans le jeu de données en tant que « root/folder/year=2020/month=08/day=27 » : – Si vous spécifiez le chemin racine de la partition en tant que « root/folder/year=2020 », l’activité de copie génère deux colonnes supplémentaires, month et day, ayant respectivement la valeur « 08 » et « 27 », en plus des colonnes contenues dans les fichiers.– Si le chemin racine de la partition n’est pas spécifié, aucune colonne supplémentaire n’est générée. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Système de fichiers en tant que récepteur
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Remarque
L’option MergeFiles copyBehavior est disponible uniquement dans des pipelines Azure Data Factory et non dans des pipelines Synapse Analytics.
Les propriétés suivantes sont prises en charge pour le système de fichiers sous les paramètres storeSettings dans le récepteur de copie basé sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type sous storeSettings doit être définie sur FileServerWriteSettings. |
Oui |
| copyBehavior | Définit le comportement de copie lorsque la source est constituée de fichiers d’une banque de données basée sur un fichier. Les valeurs autorisées sont les suivantes : - PreserveHierarchy (par défaut) : conserve la hiérarchie des fichiers dans le dossier cible. Le chemin d’accès relatif du fichier source vers le dossier source est identique au chemin d’accès relatif du fichier cible vers le dossier cible. - FlattenHierarchy : tous les fichiers du dossier source figurent dans le premier niveau du dossier cible. Les noms des fichiers cibles sont générés automatiquement. - MergeFiles : fusionne tous les fichiers du dossier source dans un seul fichier. Si le nom de fichier est spécifié, le nom de fichier fusionné est le nom spécifié. Dans le cas contraire, il s’agit d’un nom de fichier généré automatiquement. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Exemples de filtres de dossier et de fichier
Cette section décrit le comportement résultant de l’utilisation de filtres de caractères génériques dans les noms de fichier et les chemins de dossier.
| folderPath | fileName | recursive | Structure du dossier source et résultat du filtrage (les fichiers en gras sont récupérés) |
|---|---|---|---|
Folder* |
(vide, utiliser la valeur par défaut) | false | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
(vide, utiliser la valeur par défaut) | true | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
false | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
true | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Exemples de liste de fichiers
Cette section décrit le comportement résultant de l’utilisation du chemin d’accès à la liste de fichiers dans la source de l’activité de copie.
En supposant que vous disposez de la structure de dossiers source suivante et que vous souhaitez copier les fichiers en gras :
| Exemple de structure source | Contenu de FileListToCopy.txt | Configuration du pipeline |
|---|---|---|
| root DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv Métadonnées FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
Dans le jeu de données : - chemin d’accès du dossier : root/FolderADans la source de l’activité de copie : - chemin d’accès à la liste de fichiers : root/Metadata/FileListToCopy.txt Le chemin d’accès à la liste de fichiers pointe vers un fichier texte dans le même magasin de données. Il inclut une liste de fichiers que vous souhaitez copier. Chaque ligne contient le chemin d’accès relatif du fichier en fonction du chemin d’accès racine configuré dans le jeu de données. |
exemples de valeurs recursive et copyBehavior
Cette section décrit le comportement résultant de l’opération de copie pour différentes combinaisons de valeurs recursive et copyBehavior.
| recursive | copyBehavior | Structure du dossier source | Cible obtenue |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré de la même manière que la source : Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5. |
| true | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 nom généré automatiquement pour Fichier3 nom généré automatiquement pour Fichier4 nom généré automatiquement pour Fichier5 |
| true | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Le contenu de Fichier1 + Fichier2 + Fichier3 + Fichier4 + Fichier5 est fusionné dans un fichier portant le nom généré automatiquement |
| false | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit Folder1 Fichier1 Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit Folder1 Le contenu de Fichier1 + Fichier2 est fusionné dans un fichier avec un nom de fichier généré automatiquement. nom généré automatiquement pour Fichier1 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Propriétés de l’activité Delete
Pour en savoir plus sur les propriétés, consultez Activité Delete.
Modèles hérités
Notes
Les Modèles suivants sont toujours pris en charge tels quels à des fins de compatibilité descendante. Il est recommandé d’utiliser le nouveau modèle mentionné dans les sections ci-dessus à partir de maintenant. L’interface utilisateur de création peut désormais générer ce nouveau modèle.
Modèle de jeu de données hérité
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : FileShare | Oui |
| folderPath | Chemin d'accès au dossier. Le filtre de caractères génériques est pris en charge. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de dossier contient effectivement ce caractère d’échappement ou générique. Exemples : dossier_racine/sous-dossier/ ; pour voir d’autres exemples, consultez Exemples de définitions de jeux de données et de service liés et Exemples de filtres de dossier et de fichier. |
Non |
| fileName | Filtre de noms ou de caractères génériques pour les fichiers sous le chemin « folderPath » spécifié. Si vous ne spécifiez pas de valeur pour cette propriété, le jeu de données pointe vers tous les fichiers du dossier. Dans le filtre, les caractères génériques autorisés sont les suivants : * (correspond à zéro caractère ou plus) et ? (correspond à zéro ou un caractère).- Exemple 1 : "fileName": "*.csv"- Exemple 2 : "fileName": "???20180427.txt"Utilisez ^ comme caractère d’échappement si votre nom de fichier réel contient des caractères génériques ou ce caractère d’échappement.Lorsque fileName n’est pas spécifié pour un jeu de données de sortie et que preserveHierarchy n’est pas spécifié dans le récepteur d’activité, l’activité de copie génère automatiquement le nom de fichier suivant ce modèle : « Data.[GUID de l’ID d’exécution de l’activité].[GUID si FlattenHierarchy].[format si configuré].[compression si configurée] », par exemple « Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz ». Si vous copiez à partir d’une source tabulaire à l’aide du nom de table au lieu de la requête, le modèle de nom est « [nom de la table].[format].[compression si configurée] », par exemple « MyTable.csv ». |
Non |
| modifiedDatetimeStart | Filtre de fichiers en fonction de l’attribut : Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format AAAA-MM-JJTHH:mm:ssZ. Sachez que le niveau de performance global du déplacement des données est affecté par l’activation de ce paramètre lorsque vous souhaitez filtrer des fichiers parmi de grandes quantités de fichiers. Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés. |
Non |
| modifiedDatetimeEnd | Filtre de fichiers en fonction de l’attribut : Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Sachez que le niveau de performance global du déplacement des données est affecté par l’activation de ce paramètre lorsque vous souhaitez filtrer des fichiers parmi de grandes quantités de fichiers. Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés. |
Non |
| format | Si vous souhaitez copier des fichiers en l’état entre des magasins de fichiers (copie binaire), ignorez la section Format dans les deux définitions de jeu de données d’entrée et de sortie. Si vous souhaitez analyser ou générer des fichiers dans un format spécifique, les types de format de fichier suivants sont pris en charge : TextFormat, JsonFormat, AvroFormat, OrcFormat et ParquetFormat. Définissez la propriété type située sous Format sur l’une de ces valeurs. Pour en savoir plus, consultez les sections relatives à format Text, format Json, format Avro, format Orc et format Parquet. |
Non (uniquement pour un scénario de copie binaire) |
| compression | Spécifiez le type et le niveau de compression pour les données. Pour plus d’informations, voir Formats de fichier et de codecs de compression pris en charge. Types pris en charge : GZip, Deflate, BZip2 et ZipDeflate. Niveaux pris en charge : Optimal et Fastest. |
Non |
Conseil
Pour copier tous les fichiers d’un dossier, spécifiez folderPath uniquement.
Pour copier un seul fichier avec un nom donné, spécifiez folderPath avec la partie dossier et fileName avec le nom du fichier.
Pour copier un sous-ensemble de fichiers d’un dossier, spécifiez folderPath avec la partie dossier et fileName avec le filtre de caractères génériques.
Notes
Si vous utilisez la propriété « fileFilter » pour le filtre de fichiers, il est toujours pris en charge tel quel, mais il est conseillé d’utiliser la nouvelle fonctionnalité de filtre ajoutée à « fileName » à l’avenir.
Exemple :
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modèle hérité de la source d’activité de copie
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur : FileSystemSource | Oui |
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Notez que lorsque l’option récursive est définie sur la valeur true et que le récepteur est un magasin basé sur des fichiers, le dossier/sous-dossier vide n’est pas copié/créé dans le récepteur. Valeurs autorisées : true (par défaut) et false |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modèle hérité du récepteur d’activité de copie
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur d’activité de copie doit être définie sur : FileSystemSink | Oui |
| copyBehavior | Définit le comportement de copie lorsque la source est constituée de fichiers d’une banque de données basée sur un fichier. Les valeurs autorisées sont les suivantes : - PreserveHierarchy (par défaut) : conserve la hiérarchie des fichiers dans le dossier cible. Le chemin d’accès relatif du fichier source vers le dossier source est identique au chemin d’accès relatif du fichier cible vers le dossier cible. - FlattenHierarchy : tous les fichiers du dossier source figurent dans le premier niveau du dossier cible. Les noms de fichiers cibles sont gérés automatiquement. - MergeFiles : fusionne tous les fichiers du dossier source dans un seul fichier. Aucune déduplication des enregistrements n’est effectuée pendant la fusion. Si le nom de fichier est spécifié, le nom de fichier fusionné est le nom spécifié. Dans le cas contraire, le nom de fichier est généré automatiquement. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Contenu connexe
Pour obtenir une liste des magasins de données pris en charge comme sources et récepteurs par l’activité de copie, consultez la section sur les magasins de données pris en charge.