Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Important
La mise à l’échelle automatique Lakebase est en version bêta dans les régions suivantes : eastus2, westeurope, westus.
La mise à l’échelle automatique Lakebase est la dernière version de Lakebase avec la mise à l’échelle automatique, la mise à l’échelle à zéro, la branchement et la restauration instantanée. Pour la comparaison des fonctionnalités avec Lakebase Provisioned, consultez le choix entre les versions.
L’API De données Lakebase est une interface RESTful compatible PostgREST qui vous permet d’interagir directement avec votre base de données Postgres Lakebase à l’aide de méthodes HTTP standard. Il offre des points de terminaison d’API dérivés de votre schéma de base de données, ce qui permet d’effectuer des opérations CRUD sécurisées (créer, lire, mettre à jour, supprimer) sur vos données sans avoir besoin de développement principal personnalisé.
Aperçu
L’API de données génère automatiquement des points de terminaison RESTful en fonction de votre schéma de base de données. Chaque table de votre base de données devient accessible via des requêtes HTTP, ce qui vous permet de :
- Interroger des données à l’aide de requêtes HTTP GET avec filtrage, tri et pagination flexibles
- Insérer des enregistrements à l’aide de requêtes HTTP POST
- Mettre à jour des enregistrements à l’aide de requêtes HTTP PATCH ou PUT
- Supprimer des enregistrements à l’aide de requêtes HTTP DELETE
- Exécuter des fonctions en tant que RPC à l’aide de requêtes HTTP POST
Cette approche élimine la nécessité d’écrire et de gérer du code d’API personnalisé, ce qui vous permet de vous concentrer sur votre logique d’application et le schéma de base de données.
Compatibilité postgREST
L’API De données Lakebase est compatible avec la spécification PostgREST . Vous pouvez:
- Utiliser les bibliothèques et outils clients PostgREST existants
- Suivez les conventions PostgREST pour le filtrage, l’ordre et la pagination
- Adapter la documentation et des exemples de la communauté PostgREST
Note
L’API De données Lakebase est l’implémentation d’Azure Databricks conçue pour être compatible avec la spécification PostgREST. Étant donné que l’API de données est une implémentation indépendante, certaines fonctionnalités PostgREST qui ne sont pas applicables à l’environnement Lakebase ne sont pas incluses. Pour plus d’informations sur la compatibilité des fonctionnalités, consultez la référence de compatibilité des fonctionnalités.
Pour plus d’informations sur les fonctionnalités d’API, les paramètres de requête et les fonctionnalités, consultez la référence de l’API PostgREST.
Cas d’usage
L’API De données Lakebase est idéale pour :
- Applications web : créer des serveurs frontaux qui interagissent directement avec votre base de données via des requêtes HTTP
- Microservices : créer des services légers qui accèdent aux ressources de base de données via des API REST
- Architectures serverless : intégrer des fonctions serverless et des plateformes d'edge computing
- Applications mobiles : fournir aux applications mobiles un accès direct à la base de données via une interface RESTful
- Intégrations tierces : permettre aux systèmes externes de lire et d’écrire des données en toute sécurité
Configurer l’API de données
Cette section vous guide tout au long de la configuration de l’API de données, de la création de rôles requis à la première requête d’API.
Conditions préalables
L’API de données nécessite un projet de base de données de mise à l’échelle automatique Postgres Lakebase. Si vous n’en avez pas, consultez Prise en main des projets de base de données.
Conseil / Astuce
Si vous avez besoin d’exemples de tables pour tester l’API De données, créez-les avant d’activer l’API De données. Consultez l’exemple de schéma pour obtenir un exemple de schéma complet.
Activer l’API de données
L’API de données permet à toutes les bases de données d’accéder par le biais d’un seul rôle Postgres nommé authenticator, qui ne nécessite aucune autorisation, sauf pour se connecter. Lorsque vous activez l’API de données via l’application Lakebase, ce rôle et l’infrastructure nécessaire sont créés automatiquement.
Pour activer l’API de données :
- Accédez à la page API de données de votre projet.
- Cliquez sur Activer l’API De données.
Cette opération effectue automatiquement toutes les étapes d’installation, notamment la création du rôle, la authenticator configuration du pgrst schéma et l’exposition du public schéma via l’API.
Note
Si vous devez exposer des schémas supplémentaires (au-delà public), vous pouvez modifier les schémas exposés dans les paramètres de l’API de données avancées.
Après l’activation de l’API de données
Après avoir activé l’API De données, l’application Lakebase affiche la page API de données avec deux onglets : API et paramètres.
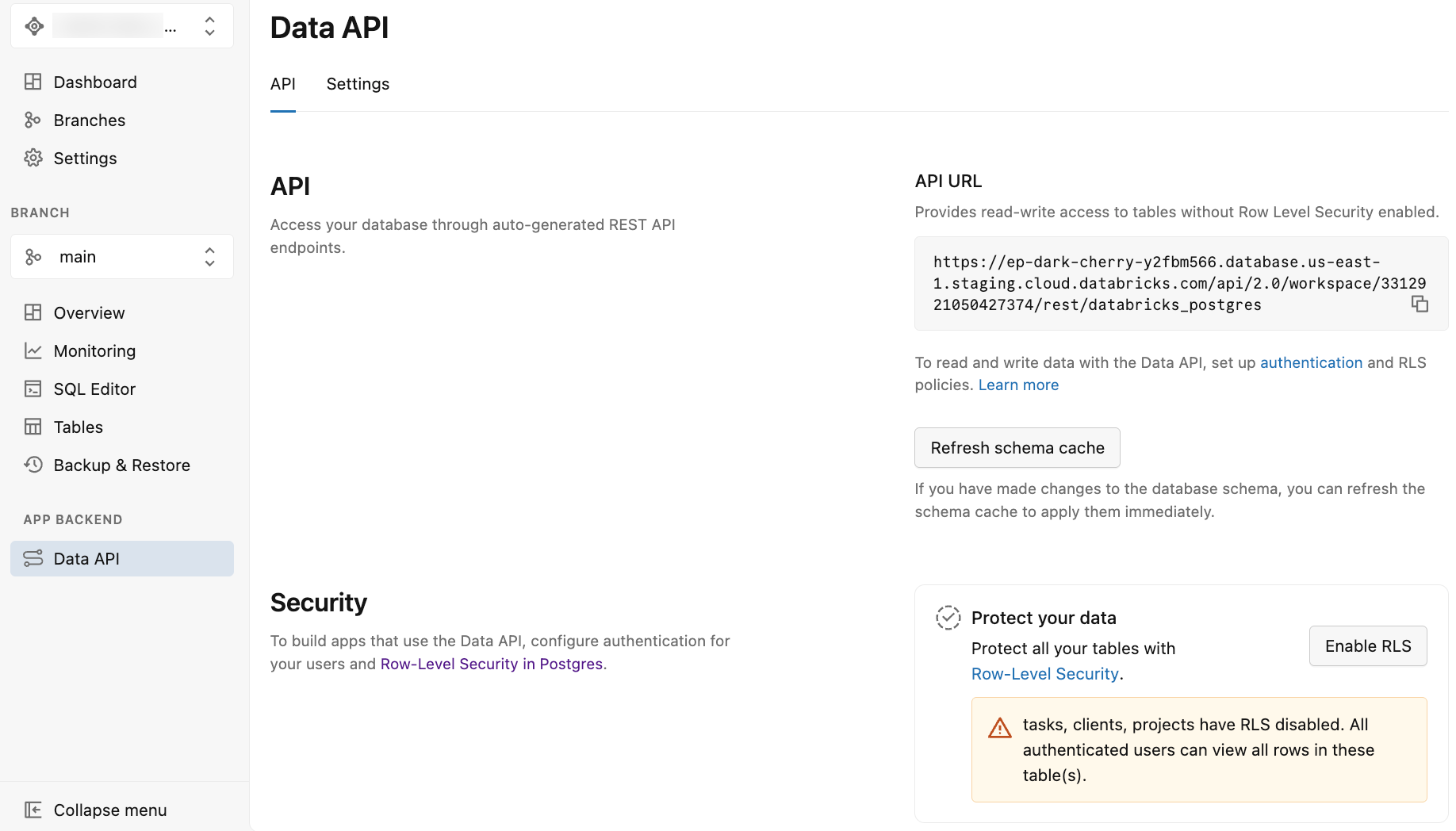
L’onglet API fournit les éléments suivants :
-
URL de l’API : URL du point de terminaison REST à utiliser dans le code de votre application et les demandes d’API. L’URL affichée n’inclut pas le schéma. Vous devez donc ajouter le nom du schéma (par exemple
/public) à l’URL lors de l’exécution de requêtes d’API. - Actualiser le cache de schéma : bouton permettant d’actualiser le cache de schéma de l’API après avoir apporté des modifications à votre schéma de base de données. Consultez Actualiser le cache de schéma.
- Protégez vos données : options permettant d’activer la sécurité au niveau des lignes Postgres (RLS) pour vos tables. Consultez Activer la sécurité au niveau des lignes.
L’onglet Paramètres fournit des options pour configurer le comportement de l’API, comme les schémas exposés, les lignes maximales, les paramètres CORS, etc. Consultez les paramètres de l’API De données avancées.
Exemple de schéma (facultatif)
Les exemples de cette documentation utilisent le schéma suivant. Vous pouvez créer vos propres tables ou utiliser cet exemple de schéma pour les tests. Exécutez ces instructions SQL à l’aide de l’éditeur SQL Lakebase ou d’un client SQL :
-- Create clients table
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
company TEXT,
phone TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create projects table with foreign key to clients
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
client_id INTEGER NOT NULL REFERENCES clients(id) ON DELETE CASCADE,
status TEXT DEFAULT 'active',
start_date DATE,
end_date DATE,
budget DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create tasks table with foreign key to projects
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT,
project_id INTEGER NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
status TEXT DEFAULT 'pending',
priority TEXT DEFAULT 'medium',
assigned_to TEXT,
due_date DATE,
estimated_hours DECIMAL(5,2),
actual_hours DECIMAL(5,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO clients (name, email, company, phone) VALUES
('Acme Corp', 'contact@acme.com', 'Acme Corporation', '+1-555-0101'),
('TechStart Inc', 'hello@techstart.com', 'TechStart Inc', '+1-555-0102'),
('Global Solutions', 'info@globalsolutions.com', 'Global Solutions Ltd', '+1-555-0103');
INSERT INTO projects (name, description, client_id, status, start_date, end_date, budget) VALUES
('Website Redesign', 'Complete overhaul of company website with modern design', 1, 'active', '2024-01-15', '2024-06-30', 25000.00),
('Mobile App Development', 'iOS and Android app for customer management', 1, 'planning', '2024-07-01', '2024-12-31', 50000.00),
('Database Migration', 'Migrate legacy system to cloud database', 2, 'active', '2024-02-01', '2024-05-31', 15000.00),
('API Integration', 'Integrate third-party services with existing platform', 3, 'completed', '2023-11-01', '2024-01-31', 20000.00);
INSERT INTO tasks (title, description, project_id, status, priority, assigned_to, due_date, estimated_hours, actual_hours) VALUES
('Design Homepage', 'Create wireframes and mockups for homepage', 1, 'in_progress', 'high', 'Sarah Johnson', '2024-03-15', 16.00, 8.00),
('Setup Development Environment', 'Configure local development setup', 1, 'completed', 'medium', 'Mike Chen', '2024-02-01', 4.00, 3.50),
('Database Schema Design', 'Design new database structure', 3, 'completed', 'high', 'Alex Rodriguez', '2024-02-15', 20.00, 18.00),
('API Authentication', 'Implement OAuth2 authentication flow', 4, 'completed', 'high', 'Lisa Wang', '2024-01-15', 12.00, 10.50),
('User Testing', 'Conduct usability testing with target users', 1, 'pending', 'medium', 'Sarah Johnson', '2024-04-01', 8.00, NULL),
('Performance Optimization', 'Optimize database queries and caching', 3, 'in_progress', 'medium', 'Alex Rodriguez', '2024-04-30', 24.00, 12.00);
Configurer les autorisations utilisateur
Vous devez authentifier toutes les demandes d’API de données à l’aide des jetons du porteur OAuth Azure Databricks, qui sont envoyés via l’en-tête Authorization . L’API de données limite l’accès aux identités Azure Databricks authentifiées, avec Postgres régissant les autorisations sous-jacentes.
Le authenticator rôle suppose l’identité de l’utilisateur demandeur lors du traitement des demandes d’API. Pour que cela fonctionne, chaque identité Azure Databricks qui accède à l’API de données doit avoir un rôle Postgres correspondant dans votre base de données. Si vous devez d’abord ajouter des utilisateurs à votre compte Azure Databricks, consultez Ajouter des utilisateurs à votre compte.
Ajouter des rôles Postgres
Utilisez l’extension databricks_auth pour créer des rôles Postgres qui correspondent aux identités Azure Databricks :
Créez l’extension :
CREATE EXTENSION IF NOT EXISTS databricks_auth;
Ajoutez un rôle Postgres :
SELECT databricks_create_role('user@databricks.com', 'USER');
Pour obtenir des instructions détaillées, consultez Créer un rôle OAuth pour une identité Azure Databricks à l’aide de SQL.
Important
N’utilisez pas votre compte propriétaire de base de données (l’identité Azure Databricks qui a créé le projet Lakebase) pour accéder à l’API de données. Le authenticator rôle nécessite la possibilité d’assumer votre rôle et cette autorisation ne peut pas être accordée pour les comptes disposant de privilèges élevés.
Si vous tentez d’accorder le rôle de propriétaire de la base de données à authenticator, vous recevez cette erreur :
ERROR: permission denied to grant role "db_owner_user@databricks.com"
DETAIL: Only roles with the ADMIN option on role "db_owner_user@databricks.com" may grant this role.
Accorder des autorisations aux utilisateurs
Maintenant que vous avez créé des rôles Postgres correspondants pour vos identités Azure Databricks, vous devez accorder des autorisations à ces rôles Postgres. Ces autorisations contrôlent les objets de base de données (schémas, tables, séquences, fonctions) avec lesquels chaque utilisateur peut interagir via des requêtes d’API.
Accordez des autorisations à l’aide d’instructions SQL GRANT standard. Cet exemple utilise le public schéma ; si vous exposez un autre schéma, remplacez public par votre nom de schéma :
-- Allow authenticator to assume the identity of the user
GRANT "user@databricks.com" TO authenticator;
-- Allow user@databricks.com to access everything in public schema
GRANT USAGE ON SCHEMA public TO "user@databricks.com";
GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO "user@databricks.com";
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO "user@databricks.com";
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO "user@databricks.com";
Cet exemple accorde un accès complet au schéma public pour l’identité user@databricks.com. Remplacez cela par l’identité Azure Databricks réelle et ajustez les autorisations en fonction de vos besoins.
Important
Implémenter la sécurité au niveau des lignes : les autorisations ci-dessus accordent l’accès au niveau de la table, mais la plupart des cas d’utilisation d’API nécessitent des restrictions au niveau des lignes. Par exemple, dans les applications mutualisées, les utilisateurs ne doivent voir que leurs propres données ou les données de leur organisation. Utilisez des stratégies de sécurité au niveau des lignes PostgreSQL pour appliquer un contrôle d’accès affiné au niveau de la base de données. Consultez Implémenter la sécurité au niveau des lignes.
Authentification
Pour accéder à l’API de données, vous devez fournir un jeton OAuth Azure Databricks dans l’en-tête Authorization de votre requête HTTP. L’identité Azure Databricks authentifiée doit avoir un rôle Postgres correspondant (créé aux étapes précédentes) qui définit ses autorisations de base de données.
Obtenir un jeton OAuth
Connectez-vous à votre espace de travail en tant qu’identité Azure Databricks pour laquelle vous avez créé un rôle Postgres au cours des étapes précédentes et obtenez un jeton OAuth. Consultez l’authentification pour obtenir des instructions.
Création d’une demande
Avec votre jeton OAuth et votre URL d’API (disponible à partir de l’onglet API dans l’application Lakebase), vous pouvez effectuer des requêtes d’API à l’aide de curl ou de n’importe quel client HTTP. N’oubliez pas d’ajouter le nom du schéma (par exemple) /publicà l’URL de l’API. Les exemples suivants supposent que vous avez exporté les variables d'environnement DBX_OAUTH_TOKEN et REST_ENDPOINT.
Voici un exemple d’appel avec la sortie attendue (à l’aide de l’exemple de schéma clients/projets/tâches) :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Exemple de réponse :
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Pour plus d’exemples et des informations détaillées sur les opérations d’API, consultez la section référence de l’API . Pour plus d’informations sur les paramètres de requête et les fonctionnalités d’API, consultez la référence de l’API PostgREST. Pour obtenir des informations de compatibilité spécifiques à Lakebase, consultez la compatibilité PostgREST.
Avant d’utiliser largement l’API, configurez la sécurité au niveau des lignes pour protéger vos données.
Gérer l’API de données
Après avoir activé l’API de données, vous pouvez gérer les modifications de schéma et les paramètres de sécurité via l’application Lakebase.
Actualiser le cache de schéma
Lorsque vous apportez des modifications à votre schéma de base de données (ajout de tables, de colonnes ou d’autres objets de schéma), vous devez actualiser le cache de schéma. Cela rend vos modifications immédiatement disponibles via l’API de données.
Pour actualiser le cache de schéma :
- Accédez à l’API De données dans la section Back-end d’application de votre projet.
- Cliquez sur Actualiser le cache de schéma.
L’API de données reflète désormais vos dernières modifications de schéma.
Activer la sécurité au niveau des lignes
L’application Lakebase offre un moyen rapide d’activer la sécurité au niveau des lignes (RLS) pour les tables de votre base de données. Quand des tables existent dans votre schéma, l’onglet API affiche une section Protéger vos données qui affiche :
- Tables avec RLS activé
- Tables avec RLS désactivées (avec avertissements)
- Bouton Activer la liste de révocation de certificats pour activer la liste de révocation de certificats pour toutes les tables
Important
L’activation de la sécurité au niveau des lignes via l’application Lakebase active cette fonctionnalité pour vos tables. Lorsque la RLS est activée, toutes les lignes deviennent inaccessibles aux utilisateurs par défaut (à l'exception des propriétaires de tables, des rôles avec l'attribut BYPASSRLS et des superutilisateurs, bien que les superutilisateurs ne soient pas pris en charge sur Lakebase). Vous devez créer des stratégies RLS pour accorder l’accès à des lignes spécifiques en fonction de vos exigences de sécurité. Consultez la sécurité au niveau des lignes pour plus d’informations sur la création de stratégies.
Pour activer RLS sur vos tables :
- Accédez à l’API De données dans la section Back-end d’application de votre projet.
- Dans la section Protéger vos données , passez en revue les tables qui n’ont pas de SRLS activées.
- Cliquez sur Activer la sécurité au niveau des lignes pour activer la sécurité pour toutes les tables.
Vous pouvez également activer RLS pour des tables individuelles à l’aide de SQL. Pour plus d’informations, consultez la sécurité au niveau des lignes .
Paramètres avancés de l’API De données
La section Paramètres avancés de l’onglet API de l’application Lakebase contrôle la sécurité, les performances et le comportement de votre point de terminaison d’API de données.
Schémas exposés
Par défaut:public
Définit les schémas PostgreSQL exposés en tant que points de terminaison d’API REST. Par défaut, seul le public schéma est accessible. Si vous utilisez d’autres schémas (par exemple, api, ), v1sélectionnez-les dans la liste déroulante pour les ajouter.
Note
Les autorisations s’appliquent : L’ajout d’un schéma expose ici les points de terminaison, mais le rôle de base de données utilisé par l’API doit toujours avoir USAGE des privilèges sur le schéma et SELECT les privilèges sur les tables.
Nombre maximal de lignes
Par défaut: Vide
Applique une limite stricte au nombre de lignes à retourner dans une seule réponse d’API. Cela empêche une dégradation accidentelle des performances des requêtes volumineuses. Les clients doivent utiliser des limites de pagination pour récupérer des données au sein de ce seuil. Cela empêche également les coûts de sortie inattendus des transferts de données volumineux.
Origines autorisées CORS
Par défaut: Vide (Autorise toutes les origines)
Contrôle les domaines web qui peuvent extraire des données de votre API à l’aide d’un navigateur.
-
Vide: Autorise
*(n’importe quel domaine). Utile pour le développement. -
Production: Répertoriez vos domaines spécifiques (par exemple)
https://myapp.compour empêcher les sites web non autorisés d’interroger votre API.
Spécification OpenAPI
Par défaut: Désactivé
Contrôle si un schéma OpenAPI 3 généré automatiquement est disponible à l’adresse /openapi.json. Ce schéma décrit vos tables, colonnes et points de terminaison REST. Lorsque cette option est activée, vous pouvez l’utiliser pour :
- Générer la documentation de l’API (interface utilisateur Swagger, Redoc)
- Créer des bibliothèques clientes typées (TypeScript, Python, Go)
- Importer votre API dans Postman
- Intégrer à des passerelles d’API et à d’autres outils OpenAPI
En-têtes de chronométrage du serveur
Par défaut: Désactivé
Lorsqu'elle est activée, l'API de données inclut Server-Timing en-têtes dans chaque réponse. Ces en-têtes indiquent la durée de traitement des différentes parties de la demande (par exemple, le temps d’exécution de la base de données et le temps de traitement interne). Vous pouvez utiliser ces informations pour déboguer des requêtes lentes, mesurer les performances et résoudre les problèmes de latence dans votre application.
Note
Après avoir apporté des modifications à tous les paramètres avancés, cliquez sur Enregistrer pour les appliquer.
Sécurité au niveau des lignes
Les stratégies de sécurité au niveau des lignes fournissent un contrôle d’accès précis en limitant les lignes auxquelles les utilisateurs peuvent accéder dans une table.
Fonctionnement de RLS avec l’API de données : lorsqu’un utilisateur effectue une demande d’API, le authenticator rôle suppose l’identité de cet utilisateur. Toutes les stratégies de sécurité réseau définies pour le rôle de cet utilisateur sont automatiquement appliquées par PostgreSQL, en filtrant les données auxquelles ils peuvent accéder. Cela se produit au niveau de la base de données. Ainsi, même si le code d’application tente d’interroger toutes les lignes, la base de données retourne uniquement les lignes que l’utilisateur est autorisé à voir. Cela fournit une sécurité de défense en profondeur sans nécessiter de logique de filtrage dans votre code d’application.
Pourquoi RLS est essentiel pour les API : contrairement aux connexions de base de données directes où vous contrôlez le contexte de connexion, les API HTTP exposent votre base de données à plusieurs utilisateurs via un seul point de terminaison. Seuls les autorisations au niveau de la table signifient que si un utilisateur peut accéder à la clients table, il peut accéder à tous les enregistrements clients, sauf si vous implémentez le filtrage. Les stratégies RLS garantissent que chaque utilisateur voit automatiquement uniquement ses données autorisées.
RLS est essentiel pour :
- Applications multi-locataires : isoler les données entre différents clients ou organisations
- Données appartenant à l’utilisateur : assurez-vous que les utilisateurs accèdent uniquement à leurs propres enregistrements
- Accès en équipe : limiter la visibilité aux membres de l’équipe ou à des groupes spécifiques
- Exigences de conformité : appliquer des restrictions d’accès aux données au niveau de la base de données
Activer la sécurité au niveau de la ligne
Vous pouvez activer RLS via l’application Lakebase ou à l’aide d’instructions SQL. Pour obtenir des instructions sur l’utilisation de l’application Lakebase, consultez Activer la sécurité au niveau des lignes.
Avertissement
Si vous avez des tables sans RLS activées, l’onglet API de l’application Lakebase affiche un avertissement indiquant que les utilisateurs authentifiés peuvent afficher toutes les lignes de ces tables. L’API de données interagit directement avec votre schéma Postgres et, étant donné que l’API est accessible sur Internet, il est essentiel d’appliquer la sécurité au niveau de la base de données à l’aide de la sécurité au niveau des lignes PostgreSQL.
Pour activer RLS à l’aide de SQL, exécutez la commande suivante :
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Créer des politiques RLS
Après avoir activé RLS sur une table, vous devez créer des stratégies qui définissent des règles d’accès. Sans stratégie, les utilisateurs ne peuvent pas accéder à des lignes (toutes les lignes sont masquées par défaut).
Fonctionnement des stratégies : lorsque RLS est activé sur une table, les utilisateurs ne peuvent voir que des lignes qui correspondent à au moins une stratégie. Toutes les autres lignes sont filtrées. Les propriétaires de tables, les rôles avec l’attribut BYPASSRLS et les superutilisateurs peuvent contourner le système de sécurité des lignes (bien que les superutilisateurs ne soient pas pris en charge sur Lakebase).
Note
Dans Lakebase, current_user retourne l’adresse e-mail de l’utilisateur authentifié (par exemple, user@databricks.com). Utilisez-la dans vos stratégies RLS pour identifier l’utilisateur qui effectue la requête.
Syntaxe de stratégie de base :
CREATE POLICY policy_name ON table_name
[TO role_name]
USING (condition);
- policy_name : nom descriptif de la stratégie
- table_name : Table pour appliquer la stratégie
- TO role_name : facultatif. Spécifie le rôle de cette stratégie. Omettez cette clause pour appliquer la stratégie à tous les rôles.
- USING (condition) : condition qui détermine quelles lignes sont visibles
Tutoriel RLS
Le tutoriel suivant utilise l’exemple de schéma de cette documentation (clients, projets, tables de tâches) pour montrer comment implémenter la sécurité au niveau des lignes.
Scénario : vous avez plusieurs utilisateurs qui ne doivent voir que leurs clients affectés et leurs projets associés. Restreindre l’accès afin que :
-
alice@databricks.compeut uniquement afficher les clients avec des ID 1 et 2 -
bob@databricks.compeut uniquement afficher les clients avec les ID 2 et 3
Étape 1 : Activer RLS sur la table des clients
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Étape 2 : Créer une stratégie pour Alice
CREATE POLICY alice_clients ON clients
TO "alice@databricks.com"
USING (id IN (1, 2));
Étape 3 : Créer une stratégie pour Bob
CREATE POLICY bob_clients ON clients
TO "bob@databricks.com"
USING (id IN (2, 3));
Étape 4 : Tester les stratégies
Quand Alice effectue une requête d’API :
# Alice's token in the Authorization header
curl -H "Authorization: Bearer $ALICE_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Réponse (Alice voit uniquement les clients 1 et 2) :
[
{ "id": 1, "name": "Acme Corp" },
{ "id": 2, "name": "TechStart Inc" }
]
Lorsque Bob effectue une requête d’API :
# Bob's token in the Authorization header
curl -H "Authorization: Bearer $BOB_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Réponse (Bob voit uniquement les clients 2 et 3) :
[
{ "id": 2, "name": "TechStart Inc" },
{ "id": 3, "name": "Global Solutions" }
]
Modèles RLS courants
Ces modèles couvrent les exigences de sécurité classiques pour l’API de données :
Propriété de l’utilisateur : limite les lignes à l’utilisateur authentifié :
CREATE POLICY user_owned_data ON tasks
USING (assigned_to = current_user);
Isolation du locataire : limite les lignes à l’organisation de l’utilisateur :
CREATE POLICY tenant_data ON clients
USING (tenant_id = (
SELECT tenant_id
FROM user_tenants
WHERE user_email = current_user
));
Appartenance à l’équipe : limite les lignes aux équipes de l’utilisateur :
CREATE POLICY team_projects ON projects
USING (client_id IN (
SELECT client_id
FROM team_clients
WHERE team_id IN (
SELECT team_id
FROM user_teams
WHERE user_email = current_user
)
));
Accès en fonction du rôle : limite les lignes en fonction de l’appartenance au rôle :
CREATE POLICY manager_access ON tasks
USING (
status = 'pending' OR
pg_has_role(current_user, 'managers', 'member')
);
En lecture seule pour des rôles spécifiques - Différentes stratégies pour différentes opérations :
-- Allow all users to read their assigned tasks
CREATE POLICY read_assigned_tasks ON tasks
FOR SELECT
USING (assigned_to = current_user);
-- Only managers can update tasks
CREATE POLICY update_tasks ON tasks
FOR UPDATE
TO "managers"
USING (true);
Ressources supplémentaires
Pour obtenir des informations complètes sur l’implémentation de RLS, notamment les types de stratégie, les meilleures pratiques de sécurité et les modèles avancés, consultez la documentation sur les stratégies de sécurité des lignes PostgreSQL.
Pour plus d’informations sur les autorisations, consultez Gérer les autorisations.
Informations de référence sur l’API
Cette section suppose que vous avez effectué les étapes d’installation, les autorisations configurées et implémenté la sécurité au niveau des lignes. Les sections suivantes fournissent des informations de référence sur l’utilisation de l’API de données, notamment les opérations courantes, les fonctionnalités avancées, les considérations de sécurité et les détails de compatibilité.
Opérations de base
Enregistrements de requête
Récupérer des enregistrements à partir d’une table à l’aide de HTTP GET:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients"
Exemple de réponse :
[
{ "id": 1, "name": "Acme Corp", "email": "contact@acme.com", "company": "Acme Corporation", "phone": "+1-555-0101" },
{
"id": 2,
"name": "TechStart Inc",
"email": "hello@techstart.com",
"company": "TechStart Inc",
"phone": "+1-555-0102"
}
]
Filtrer les résultats
Utilisez les paramètres de requête pour filtrer les résultats. Cet exemple récupère les clients dont id la valeur est supérieure ou égale à 2 :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=gte.2"
Exemple de réponse :
[
{ "id": 2, "name": "TechStart Inc", "email": "hello@techstart.com" },
{ "id": 3, "name": "Global Solutions", "email": "info@globalsolutions.com" }
]
Sélectionner des colonnes spécifiques et joindre des tables
Utilisez le select paramètre pour récupérer des colonnes spécifiques et joindre des tables associées :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Exemple de réponse :
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Insérer des enregistrements
Créez de nouveaux enregistrements à l’aide de HTTP POST :
curl -X POST \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "New Client",
"email": "newclient@example.com",
"company": "New Company Inc",
"phone": "+1-555-0104"
}' \
"$REST_ENDPOINT/public/clients"
Mettre à jour les enregistrements
Mettez à jour les enregistrements existants à l’aide de HTTP PATCH :
curl -X PATCH \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{"phone": "+1-555-0199"}' \
"$REST_ENDPOINT/public/clients?id=eq.1"
Supprimer les enregistrements
Supprimer des enregistrements à l’aide de HTTP DELETE :
curl -X DELETE \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=eq.5"
Fonctionnalités avancées
Numérotation des pages
Contrôlez le nombre d’enregistrements retournés à l’aide des paramètres limit et offset.
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?limit=10&offset=0"
Tri
Triez les résultats à l’aide du order paramètre :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?order=due_date.desc"
Filtrage complexe
Combinez plusieurs conditions de filtre :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?status=eq.in_progress&priority=eq.high"
Opérateurs de filtre courants :
-
eq-Égale -
gte- supérieur ou égal à -
lte- inférieur ou égal à -
neq- non égal -
like- Correspondance de motifs -
in- correspond à n’importe quelle valeur dans la liste
Pour plus d’informations sur les paramètres de requête pris en charge et les fonctionnalités d’API, consultez la référence de l’API PostgREST. Pour obtenir des informations de compatibilité spécifiques à Lakebase, consultez la compatibilité PostgREST.
Informations de référence sur la compatibilité des fonctionnalités
Cette section répertorie les fonctionnalités PostgREST qui ont un comportement différent ou qui ne sont pas prises en charge dans l’API De données Lakebase.
Authentification et autorisation
| Caractéristique | Statut | Détails |
|---|---|---|
| Configuration JWT | Sans objet | L’API De données Lakebase utilise des jetons OAuth Azure Databricks au lieu de l’authentification JWT. Les options de configuration spécifiques à JWT (secrets personnalisés, clés RS256, validation d’audience) ne sont pas disponibles. |
Incorporation de ressources
| Caractéristique | Statut | Détails |
|---|---|---|
| Relations calculées | Non prise en charge | Les relations personnalisées définies par le biais de fonctions de base de données qui retournent SETOF ou d’enregistrements uniques ne sont pas prises en charge. Seules les relations de clé étrangère peuvent être incorporées. |
Incorporation de jointure interne (!inner indicateur) |
Non prise en charge | L’indicateur !inner qui convertit les jointures externes en jointures internes pour filtrer les lignes parentes en fonction des critères enfants n’est pas pris en charge. Exemple : ?select=*,clients!inner(*)&clients.id=eq.1 |
Formats de réponse
| Caractéristique | Statut | Détails |
|---|---|---|
| Gestionnaires de types de média personnalisés | Non prise en charge | Les formats de sortie personnalisés par le biais d’agrégats PostgreSQL (formats binaires, XML, mémoires tampons de protocole) ne sont pas pris en charge. |
| Nulls supprimés | Non prise en charge | Le nulls=stripped paramètre de type multimédia qui supprime les champs Null des réponses JSON n’est pas pris en charge. Exemple : Accept: application/vnd.pgrst.object+json;nulls=stripped |
| PostGIS GeoJSON | Partiellement pris en charge | Les colonnes de géométrie PostGIS peuvent être interrogées, mais la mise en forme GeoJSON automatique via Accept: application/geo+json l’en-tête n’est pas disponible. |
Pagination et comptage
| Caractéristique | Statut | Détails |
|---|---|---|
| Nombre planifié | Non prise en charge | L’option Prefer: count=planned qui utilise le planificateur de requêtes de PostgreSQL pour estimer le nombre de résultats n’est pas prise en charge. Utilisez Prefer: count=exact à la place. |
| Nombre estimé | Non prise en charge | L’option Prefer: count=estimated qui utilise les statistiques PostgreSQL pour les nombres approximatifs n’est pas prise en charge. Utilisez Prefer: count=exact à la place. |
Préférences de demande
| Caractéristique | Statut | Détails |
|---|---|---|
| Préférence de fuseau horaire | Partiellement pris en charge | La gestion des fuseaux horaires existe, mais l’en-tête pour remplacer le Prefer: timezone=America/Los_Angeles fuseau horaire du serveur n’est pas pris en charge. Configurez le fuseau horaire du serveur ou utilisez des fonctions de fuseau horaire au niveau de la base de données. |
| Contrôle de transaction | Non prise en charge | Le contrôle de transaction via Prefer: tx=commit et Prefer: tx=rollback en-têtes n’est pas pris en charge. |
| Modes de gestion des préférences | Non prise en charge | Les options Prefer: handling=strict et Prefer: handling=lenient de gestion des préférences non valides ne sont pas prises en charge. |
Observability
L’API Lakebase Data implémente ses propres fonctionnalités d’observabilité. Les fonctionnalités d’observabilité PostgREST suivantes ne sont pas prises en charge :
| Caractéristique | Statut | Détails |
|---|---|---|
| Présentation du plan de requête | Non prise en charge | L’en-tête Accept: application/vnd.pgrst.plan+json qui expose la sortie PostgreSQL EXPLAIN pour l’analyse des performances n’est pas pris en charge. |
| en-tête Server-Timing | Non prise en charge | L’en-tête Server-Timing qui fournit les détails de chronométrage des requêtes n’est pas pris en charge. Lakebase implémente ses propres fonctionnalités d’observabilité. |
| Propagation de l’en-tête de trace | Non prise en charge | La propagation des en-têtes de trace personnalisés et de X-Request-Id pour le suivi distribué n’est pas prise en charge. Lakebase implémente ses propres fonctionnalités d’observabilité. |
Configuration avancée
| Caractéristique | Statut | Détails |
|---|---|---|
| Paramètres d’application (GUCs) | Non prise en charge | Le passage de valeurs de configuration personnalisées aux fonctions de base de données via les GUCs PostgreSQL n’est pas pris en charge. |
| Fonction de pré-requête | Non prise en charge | La configuration db-pre-request qui permet de spécifier une fonction de base de données à exécuter avant le traitement de chaque requête n'est pas prise en charge. |
Pour plus d’informations sur les fonctionnalités PostgREST, consultez la documentation PostgREST.
Considérations relatives à la sécurité
L’API de données applique le modèle de sécurité de votre base de données à plusieurs niveaux :
- Authentification : toutes les demandes nécessitent une authentification de jeton OAuth valide
- Accès en fonction du rôle : les autorisations au niveau de la base de données contrôlent les tables et les opérations auxquelles les utilisateurs peuvent accéder
- Sécurité au niveau des lignes : les stratégies RLS appliquent le contrôle d’accès affiné, en limitant les lignes spécifiques que les utilisateurs peuvent voir ou modifier
- Contexte utilisateur : l’API suppose l’identité de l’utilisateur authentifié, en garantissant que les autorisations et les stratégies de base de données s’appliquent correctement
Pratiques de sécurité recommandées
Pour les déploiements de production :
- Implémenter la sécurité au niveau des lignes : utilisez des stratégies RLS pour restreindre l’accès aux données au niveau de la ligne. Cela est particulièrement important pour les applications mutualisées et les données appartenant à l’utilisateur. Voir sécurité au niveau de la ligne.
-
Accorder des autorisations minimales : accordez uniquement les autorisations dont les utilisateurs ont besoin (
SELECT,INSERT,UPDATE,DELETE) sur des tables spécifiques plutôt que d’accorder un accès étendu. - Utilisez des rôles distincts par application : créez des rôles dédiés pour différentes applications ou services plutôt que de partager un rôle unique.
- Auditez régulièrement l’accès : passez en revue les autorisations accordées et les stratégies RLS régulièrement pour vous assurer qu’elles correspondent à vos exigences de sécurité.
Pour plus d’informations sur la gestion des rôles et des autorisations, consultez :