Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Important
La mise à l’échelle automatique Lakebase est en version bêta dans les régions suivantes : eastus2, westeurope, westus.
Lakebase Autoscaling est la dernière version de Lakebase avec la mise à l’échelle automatique, la mise à l’échelle jusqu'à zéro, le branchement, et la restauration instantanée. Pour la comparaison des fonctionnalités avec Lakebase Provisioned, consultez le choix entre les versions.
Inverse ETL dans Lakebase synchronise les tables du Unity Catalog dans Postgres afin que les applications puissent directement utiliser les données organisées du lakehouse. Le lakehouse est optimisé pour l’analytique et l’enrichissement, tandis que Lakebase est conçu pour les charges de travail opérationnelles qui nécessitent des requêtes rapides et une cohérence transactionnelle.
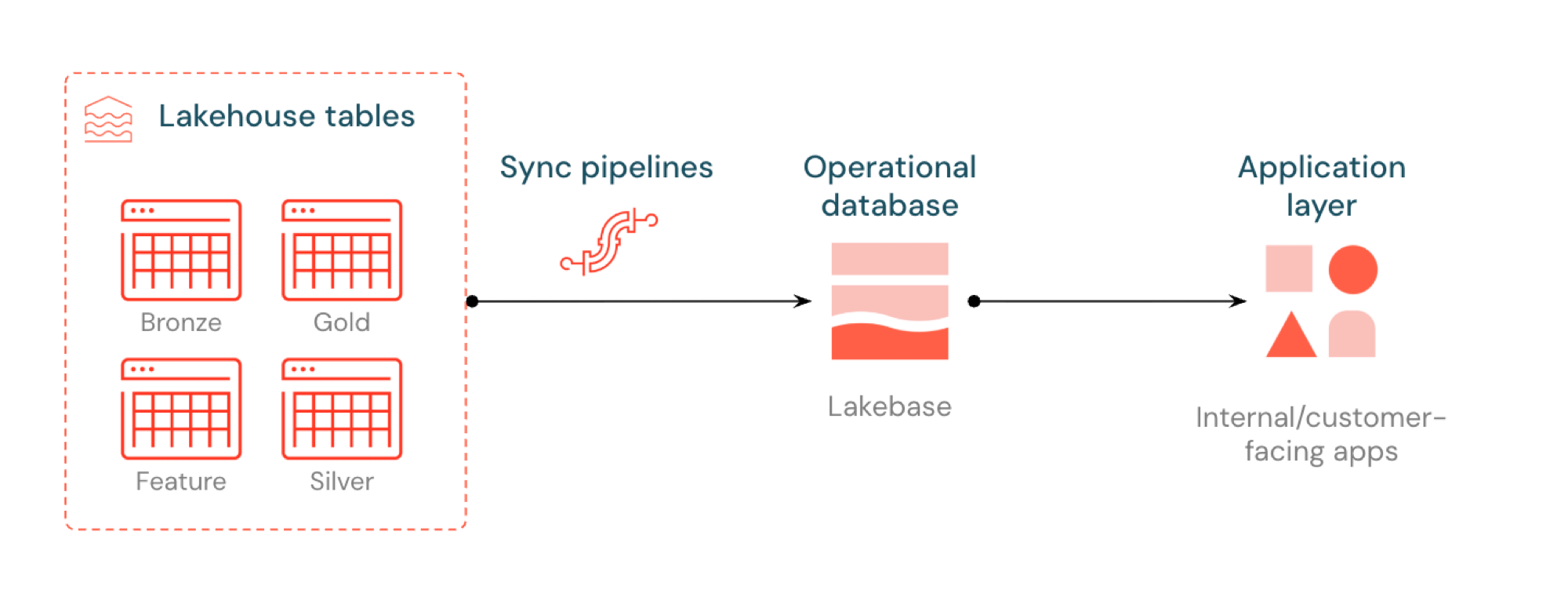
Qu’est-ce que l’ETL inverse ?
Inverse ETL vous permet de déplacer des données de niveau analytique de Unity Catalog vers Postgres Lakebase, où vous pouvez la rendre disponible pour les applications qui ont besoin de requêtes à faible latence (sous-10 ms) et de transactions ACID complètes. Il permet de combler l’écart entre le stockage analytique et les systèmes opérationnels en conservant les données organisées utilisables dans les applications en temps réel.
Fonctionnement
Les tables synchronisées Databricks créent une copie managée de vos données Unity Catalog dans Lakebase. Lorsque vous créez une table synchronisée, vous obtenez :
- Nouvelle table de catalogue Unity (en lecture seule, gérée par le pipeline de synchronisation)
- Une table Postgres dans Lakebase (interrogeable par vos applications)
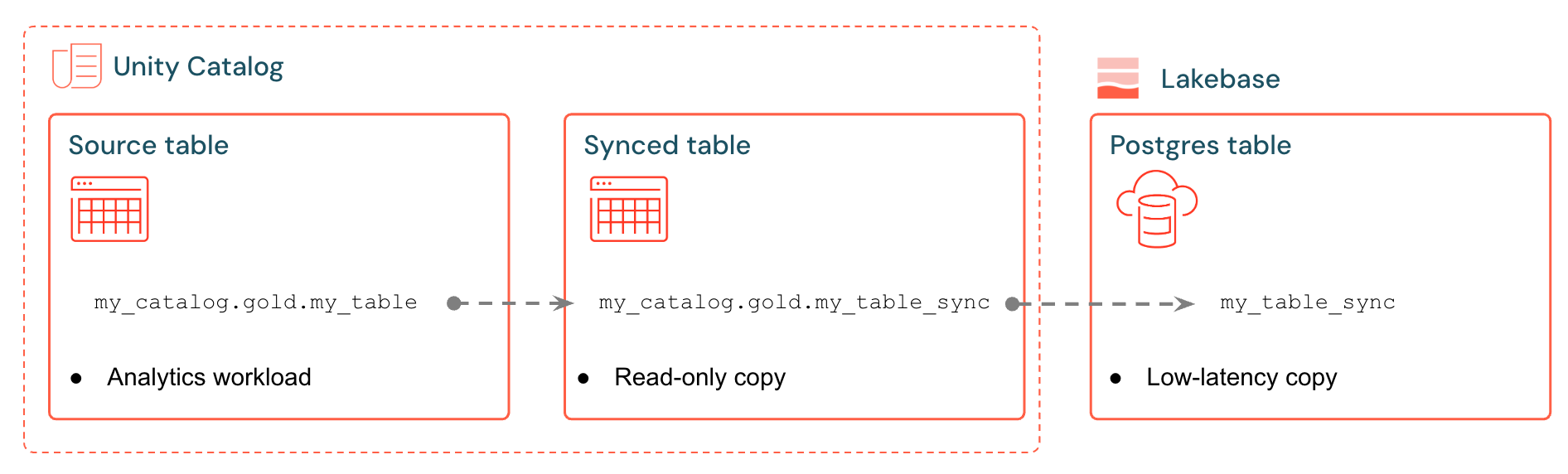
Par exemple, vous pouvez synchroniser des tables d'or, des fonctions conçues ou des sorties ML depuis analytics.gold.user_profiles vers une nouvelle table analytics.gold.user_profiles_synced synchronisée. Dans Postgres, le nom du schéma du catalogue Unity devient le nom du schéma Postgres. Cela s’affiche donc comme "gold"."user_profiles_synced"suit :
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Les applications se connectent avec des pilotes Postgres standard et interrogent les données synchronisées en même temps que leur propre état opérationnel.
Les pipelines de synchronisation utilisent les pipelines déclaratifs Spark managés Lakeflow pour mettre à jour continuellement la table synchronisée Unity Catalog et la table Postgres avec les modifications de la table source. Chaque synchronisation peut utiliser jusqu’à 16 connexions à votre base de données Lakebase.
Lakebase Postgres prend en charge jusqu’à 1 000 connexions simultanées avec des garanties transactionnelles, afin que les applications puissent lire des données enrichies tout en gérant les insertions, mises à jour et suppressions dans la même base de données.
Modes de synchronisation
Choisissez le mode de synchronisation approprié en fonction des besoins de votre application :
| Mode | Descriptif | Idéal pour | Performance |
|---|---|---|---|
| Snapshot | Copie unique de toutes les données | Configuration initiale ou analyse historique | 10x plus efficace si vous modifiez >10% de données sources |
| Déclenché | Mises à jour planifiées qui s’exécutent à la demande ou à intervalles | Tableaux de bord, mis à jour toutes les heures/tous les jours | Bon équilibre des coûts et des retards. Coûteux à des intervalles de 5 minutes< |
| En continu | Diffusion en temps réel avec secondes de latence | Applications actives (coût plus élevé en raison d’un calcul dédié) | Retard le plus bas, coût le plus élevé. Intervalles minimum de 15 secondes |
Les modes déclenchés et continus nécessitent que le flux de données modifiées (CDF) soit activé sur votre table source. Si CDF n’est pas activé, un avertissement s’affiche dans l’interface utilisateur avec la commande exacte ALTER TABLE à exécuter. Pour plus d’informations sur le flux de données modifiées, consultez Utiliser le flux de données modifiées Delta Lake sur Databricks.
Exemples de cas d’utilisation
Inverse ETL avec Lakebase prend en charge les scénarios opérationnels courants :
- Moteurs de personnalisation nécessitant de nouveaux profils utilisateur synchronisés dans Databricks Apps
- Applications qui fournissent des prédictions de modèle ou des valeurs de caractéristiques calculées dans le « lakehouse »
- Tableaux de bord orientés client qui affichent des indicateurs de performance clés en temps réel
- Services de détection des fraudes nécessitant des scores de risque disponibles pour une action immédiate
- Outils de support qui enrichissent les enregistrements des clients avec des données organisées à partir de lakehouse
Créer une table synchronisée (interface utilisateur)
Le flux de travail de l’interface utilisateur est décrit ci-dessous.
Prerequisites
Tu as besoin de:
- Un espace de travail Databricks avec Lakebase activé.
- Un projet Lakebase (voir Créer un projet).
- Table de catalogue Unity avec des données organisées.
- Autorisations pour créer des tables synchronisées.
Pour la planification de la capacité et la compatibilité des types de données, consultez La planification des types de données et de la compatibilité et de la capacité.
Étape 1 : Sélectionner votre table source
Accédez au catalogue dans la barre latérale de l’espace de travail et sélectionnez la table catalogue Unity que vous souhaitez synchroniser.
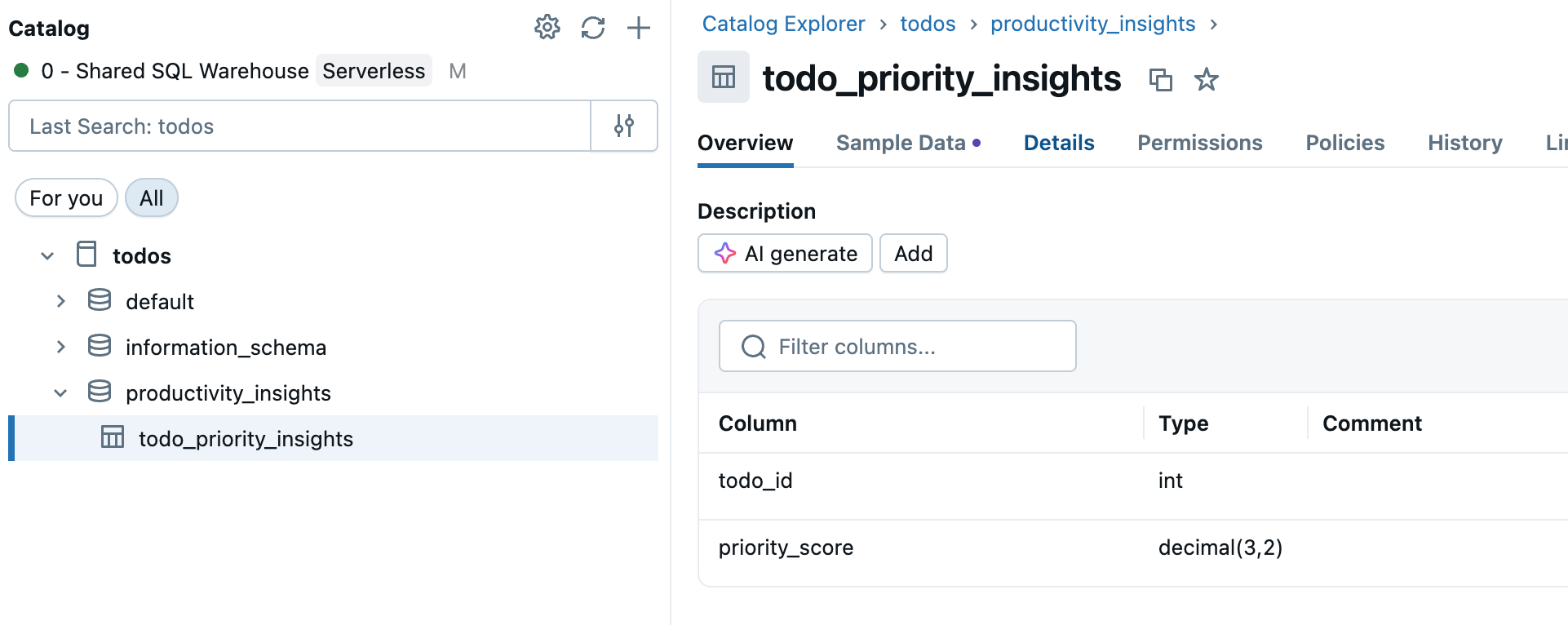
Étape 2 : Activer le flux de données modifiées (si nécessaire)
Si vous envisagez d’utiliser des modes de synchronisation déclenchée ou continue , votre table source a besoin d’un flux de données modifiées activé. Vérifiez si votre table a déjà le CDF activé, ou exécutez cette commande dans un éditeur SQL ou un notebook :
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Remplacez your_catalog.your_schema.your_table par le nom réel de votre table.
Étape 3 : Créer une table synchronisée
Cliquez sur Créer une>table synchronisée à partir de la vue détails de la table.
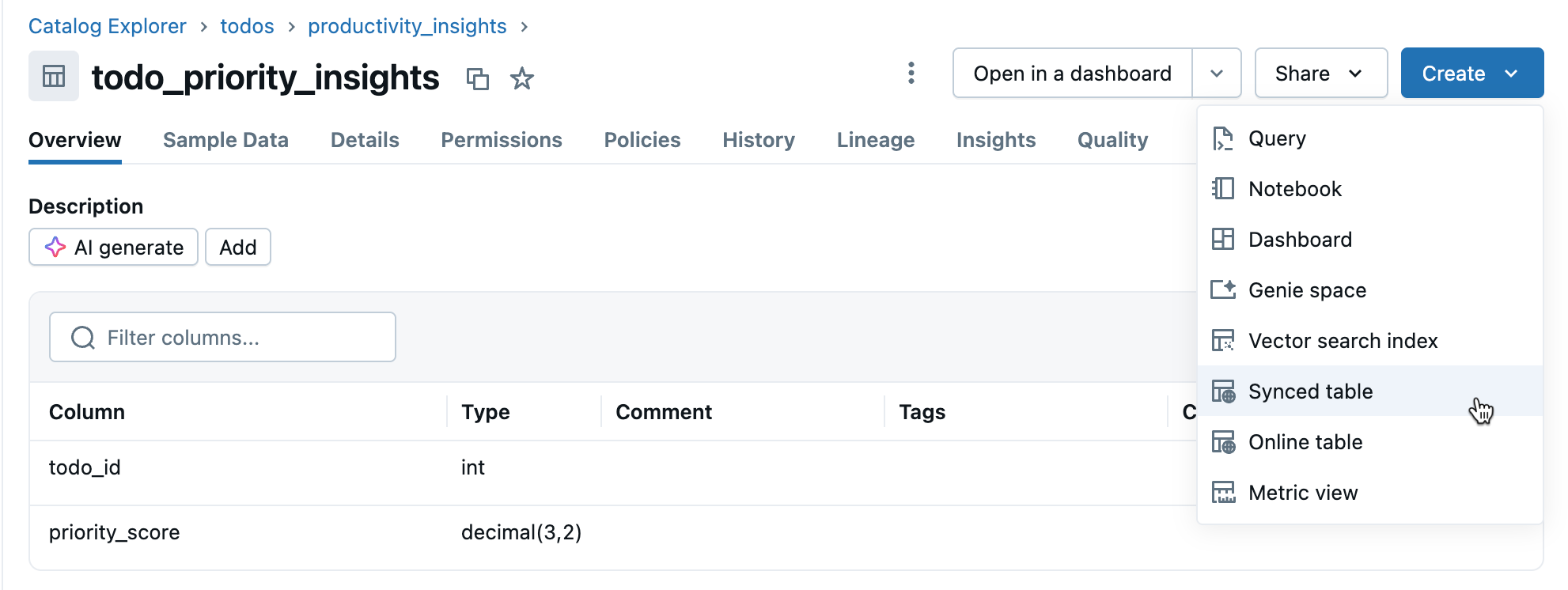
Étape 4 : Configurer
Dans la boîte de dialogue Créer une table synchronisée :
- Nom de la table : entrez un nom pour votre table synchronisée (elle est créée dans le même catalogue et le même schéma que votre table source). Cela crée une table synchronisée de catalogue Unity et une table Postgres que vous pouvez interroger.
- Type de base de données : Choisissez Lakebase Serverless (mise à l’échelle automatique).
- Mode de synchronisation : choisissez instantané, déclenché ou continu en fonction de vos besoins (voir les modes de synchronisation ci-dessus).
- Configurez vos sélections de projet, de branche et de base de données.
- Vérifiez que la clé primaire est correcte (généralement détectée automatiquement).
Si vous avez choisi le mode déclenché ou continu et n’avez pas encore activé le flux de données modifiées, vous verrez un avertissement avec la commande exacte à exécuter. Pour connaître les questions de compatibilité des types de données, consultez Types de données et compatibilité.
Cliquez sur Créer pour créer la table synchronisée.
Étape 5 : Surveiller
Après la création, surveillez la table synchronisée dans le catalogue. L’onglet Vue d’ensemble affiche l’état de synchronisation, la configuration, l’état du pipeline et le dernier horodatage de synchronisation. Utilisez La synchronisation maintenant pour l’actualisation manuelle.
Types de données et compatibilité
Les types de données du catalogue Unity sont mappés aux types Postgres lors de la création de tables synchronisées. Les types complexes (ARRAY, MAP, STRUCT) sont stockés en tant que JSONB dans Postgres.
| Type de colonne source | Type de colonne Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | NUMÉRIQUE |
| DOUBLE | DOUBLE PRÉCISION |
| FLOAT | RÉEL |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | TEXTE |
| TIMESTAMP | TIMESTAMP AVEC FUSEAU HORAIRE |
| TIMESTAMP_NTZ | TIMESTAMP SANS FUSEAU HORAIRE |
| TINYINT | SMALLINT |
| ARRAY<elementType> | JSONB |
| MAP<typeClé,typeValeur> | JSONB |
| STRUCT<fieldName :fieldType[, ...]> | JSONB |
Note
Les types GEOGRAPHY, GEOMETRY, VARIANT et OBJECT ne sont pas pris en charge.
Gérer les caractères non valides
Certains caractères tels que les octets Null (0x00) sont autorisés dans les colonnes STRING, ARRAY, MAP ou STRUCT du catalogue Unity, mais pas prises en charge dans les colonnes TEXT ou JSONB Postgres. Cela peut entraîner des échecs de synchronisation avec des erreurs telles que :
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Solutions :
Nettoyer les champs de chaîne : supprimez les caractères non pris en charge avant la synchronisation. Pour les octets null dans les colonnes STRING :
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableConvertir en BINARY : pour les colonnes STRING où la conservation des octets bruts est nécessaire, convertissez en type BINARY.
Planification de la capacité
Lors de la planification de votre implémentation ETL inverse, tenez compte des besoins en ressources suivants :
- Utilisation de la connexion : chaque table synchronisée utilise jusqu’à 16 connexions à votre base de données Lakebase, qui comptent vers la limite de connexion de l’instance.
- Limites de taille : la limite totale de taille des données logiques sur toutes les tables synchronisées est de 8 To. Les tables individuelles n’ont pas de limites, mais Databricks recommande de ne pas dépasser 1 To pour les tables nécessitant des actualisations.
-
Exigences de nommage : Les noms de base de données, de schéma et de table peuvent contenir uniquement des caractères alphanumériques et des traits de soulignement (
[A-Za-z0-9_]+). - Évolution du schéma : seules les modifications de schéma additifs (comme l’ajout de colonnes) sont prises en charge pour les modes déclenchés et continus.
- Taux de mise à jour : Pour la mise à l’échelle automatique de Lakebase, le pipeline de synchronisation prend en charge les écritures en continu et déclenchées à environ 150 lignes par seconde par unité de capacité (CU) et les écritures d’instantanés jusqu’à 2 000 lignes par seconde par CU.
Supprimer une table synchronisée
Pour supprimer une table synchronisée, vous devez la supprimer du catalogue Unity et de Postgres :
Supprimer du catalogue Unity : dans le catalogue, recherchez votre table synchronisée, cliquez sur l’icône de
 Menu, puis sélectionnez Supprimer. Cela arrête les actualisations de données, mais laisse la table dans Postgres.
Menu, puis sélectionnez Supprimer. Cela arrête les actualisations de données, mais laisse la table dans Postgres.Supprimez Postgres : Connectez-vous à votre base de données Lakebase et supprimez la table pour libérer de l’espace :
DROP TABLE your_database.your_schema.your_table;
Vous pouvez utiliser l’éditeur SQL ou les outils externes pour vous connecter à Postgres.
Learn more
| Tâche | Descriptif |
|---|---|
| Créer un projet | Configurer un projet Lakebase |
| Se connecter à votre base de données | Découvrir les options de connexion pour Lakebase |
| Inscrire une base de données dans le catalogue Unity | Rendre vos données Lakebase visibles dans le catalogue Unity pour la gouvernance unifiée et les requêtes inter sources |
| Intégration du catalogue Unity | Comprendre la gouvernance et les autorisations |
Autres options
Pour synchroniser des données dans des systèmes autres que Databricks, consultez les solutions ETL inversées Partner Connect telles que Census ou Hightouch.