Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Créez un assistant RH intelligent à l’aide de LangChain.js et de services Azure. Cet agent aide les employés de la société NorthWind fictive à trouver des réponses aux questions sur les ressources humaines en recherchant dans la documentation de l’entreprise.
Vous utiliserez Azure AI Search pour rechercher des documents pertinents et Azure OpenAI pour générer des réponses précises. L’infrastructure LangChain.js gère la complexité de l’orchestration des agents, ce qui vous permet de vous concentrer sur vos besoins métier spécifiques.
Ce que vous allez apprendre :
- Déployer des ressources Azure à l’aide d’Azure Developer CLI
- Créer un agent LangChain.js qui s’intègre aux services Azure
- Implémenter la génération augmentée de récupération (RAG) pour la recherche de documents
- Tester et déboguer votre agent localement et dans Azure
À la fin de ce tutoriel, vous disposez d’une API REST opérationnelle qui répond aux questions rh à l’aide de la documentation de votre entreprise.
Vue d’ensemble de l’architecture
NorthWind s’appuie sur deux sources de données :
- Documentation RH accessible à tous les employés
- Base de données RH confidentielle contenant des données d’employé sensibles.
Ce tutoriel se concentre sur la création d’un agent LangChain.js qui détermine si la question d’un employé peut être répondue à l’aide des documents RH publics. Dans ce cas, l’agent LangChain.js fournit directement la réponse.
Conditions préalables
Pour utiliser cet exemple dans Codespace ou le conteneur de développement local, notamment la génération et l’exécution de l’agent LangChain.js, vous avez besoin des éléments suivants :
- Un compte Azure actif. Créez un compte gratuitement si vous n’en avez pas.
Si vous exécutez l’exemple de code localement sans conteneur de développement, vous avez également besoin des éléments suivants :
- Node.js LTS installé sur votre système.
- TypeScript pour l’écriture et la compilation du code TypeScript.
- Azure Developer CLI (azd) installé et configuré.
- LangChain.js bibliothèque pour générer l’agent.
- Facultatif : LangSmith pour surveiller l’utilisation de l’IA. Vous avez besoin du nom, de la clé et du point de terminaison du projet.
- Facultatif : LangGraph Studio pour le débogage des chaînes LangGraph et des agents LangChain.js.
Ressources Azure
Les ressources Azure suivantes sont requises. Ils sont créés pour vous dans cet article à l’aide de l’interface CLI pour développeurs Azure et des modèles Bicep à l’aide de modules vérifiés Azure(AVM). Les ressources sont créées à la fois avec un accès sans mot de passe et par clé à des fins d’apprentissage. Ce tutoriel utilise votre compte de développeur local pour l’authentification sans mot de passe :
- Identité managée pour l’authentification sans mot de passe auprès des services Azure.
- Azure Container Registry pour stocker l’image Docker pour le serveur d’API Fastify Node.js.
- Azure Container App pour héberger le serveur d’API Fastify Node.js.
- Ressource Recherche d’IA Azure pour la recherche vectorielle.
-
Ressource Azure OpenAI avec les modèles suivants :
- Un modèle d'embeddings comme
text-embedding-3-small. - Un modèle de langage volumineux (LLM) comme
'gpt-4.1-mini.
- Un modèle d'embeddings comme

Architecture de l’agent
La structure LangChain.js fournit un flux de décision pour la création d’agents intelligents en tant qu'un LangGraph. Dans ce tutoriel, vous allez créer un agent LangChain.js qui s’intègre à Azure AI Search et Azure OpenAI pour répondre aux questions relatives aux ressources humaines. L’architecture de l’agent est conçue pour :
- Déterminez si une question s’applique à la documentation générale sur les RH disponible pour tous les employés.
- Récupérez des documents pertinents à partir d’Azure AI Search en fonction de la requête utilisateur.
- Utilisez Azure OpenAI pour générer une réponse basée sur les documents récupérés et le modèle LLM.
Composants clés :
Structure de graphe : l’agent LangChain.js est représenté sous la forme d’un graphique, où :
- Les nœuds effectuent des tâches spécifiques, telles que la prise de décision ou la récupération de données.
- Les arêtes définissent le flux entre les nœuds, déterminant la séquence d’opérations.
Intégration d’Azure AI Search :
- Utilise un modèle d’incorporation pour créer des vecteurs.
- Insère des documents RH (*.md, *.pdf) dans la base de données vectorielle. Les documents sont les suivants :
- Informations sur l’entreprise
- Manuel des employés
- Manuel des avantages
- Bibliothèque de rôles d’employé
- Récupère les documents pertinents en fonction de l’invite de l’utilisateur.
-
Intégration d’Azure OpenAI :
- Utilise un modèle de langage volumineux pour :
- Détermine si une question est accessible à partir de documents RH impersonnels.
- Génère une réponse avec invite à l’aide du contexte à partir de documents et de questions utilisateur.
- Utilise un modèle de langage volumineux pour :
Le tableau suivant présente des exemples de questions utilisateur qui sont ou ne sont pas pertinentes et auxquelles il est possible de répondre à partir de documents de ressources humaines généraux :
| Question | Pertinent | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Oui | Les documents RH, tels que le guide de l'employé, doivent, fournir une réponse. |
How much of my perks + benefits have I spent? |
Non | Cette question nécessite l’accès aux données confidentielles des employés, qui se trouvent en dehors de l’étendue de cet agent. |
En utilisant l’infrastructure LangChain.js, vous évitez une grande partie du code réutilisable agentique généralement requis pour les agents et l’intégration du service Azure, ce qui vous permet de vous concentrer sur vos besoins métier.
Cloner l’exemple de référentiel de code
Dans un nouveau répertoire, clonez l’exemple de référentiel de code et passez au nouveau répertoire :
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
Cet exemple fournit le code dont vous avez besoin pour créer des ressources Azure sécurisées, générer l’agent LangChain.js avec Azure AI Search et Azure OpenAI, et utiliser l’agent à partir d’un serveur d’API Fastify Node.js.
S’authentifier auprès d’Azure CLI et d’Azure Developer CLI
Connectez-vous à Azure avec Azure Developer CLI, créez les ressources Azure et déployez le code source. Étant donné que le processus de déploiement utilise Azure CLI et Azure Developer CLI, connectez-vous à Azure CLI, puis configurez Azure Developer CLI pour utiliser votre authentification à partir d’Azure CLI :
az login
azd config set auth.useAzCliAuth true
Créer des ressources et déployer du code avec Azure Developer CLI
Commencez le processus de déploiement en exécutant la azd up commande :
azd up
Pendant la azd up commande, répondez aux questions suivantes :
-
Nouveau nom d’environnement : entrez un nom d’environnement unique tel que
langchain-agent. Ce nom d’environnement est utilisé dans le cadre du groupe de ressources Azure. - Sélectionnez un abonnement Azure : sélectionnez l’abonnement dans lequel les ressources sont créées.
-
Sélectionnez une région : par
eastus2exemple.
Le déploiement prend environ 10 à 15 minutes. Azure Developer CLI orchestre le processus à l’aide de phases et de hooks définis dans le azure.yaml fichier :
Phase d’approvisionnement (équivalente à azd provision) :
- Crée des ressources Azure définies dans
infra/main.bicep:- Application conteneur Azure
- OpenAI
- Recherche AI
- Registre de conteneurs
- Identité managée
-
Hook après fourniture : vérifie si l’index de recherche Azure AI existe déjà
- Si l’index n’existe pas : exécute
npm installetnpm run load_datapour charger des documents RH à l’aide de LangChain.js et du chargeur PDF et du client d'incorporation - Si l’index existe : ignore le chargement des données pour éviter les doublons (vous pouvez recharger manuellement en supprimant l’index ou en cours d’exécution
npm run load_data) Phase de déploiement (équivalente àazd deploy) :
- Si l’index n’existe pas : exécute
- Hook prédéployé : génère l’image Docker pour le serveur d’API Fastify et l’envoie (push) vers Azure Container Registry
- Déploie le serveur d’API conteneurisé sur Azure Container Apps
Une fois le déploiement terminé, les variables d’environnement et les informations de ressource sont enregistrées dans le fichier à la .env racine du référentiel. Vous pouvez afficher les ressources dans le portail Azure.
Les ressources sont créées à la fois avec un accès sans mot de passe et par clé à des fins d’apprentissage. Ce didacticiel d’introduction utilise votre compte de développeur local pour l’authentification sans mot de passe. Pour les applications de production, utilisez uniquement l’authentification sans mot de passe avec des identités managées. En savoir plus sur l’authentification sans mot de passe.
Utiliser l’exemple de code localement
Maintenant que les ressources Azure sont créées, vous pouvez exécuter l’agent LangChain.js localement.
Installer des dépendances
Installez les packages Node.js pour ce projet.
npm installCette commande installe les dépendances définies dans les deux
package.jsonfichiers dupackages-v1répertoire, notamment :-
./packages-v1/server-api:- Fastify pour le serveur web
-
./packages-v1/langgraph-agent:- LangChain.js pour créer l’agent
- Bibliothèque cliente SDK Azure
@azure/search-documentspour intégrer avec la ressource Recherche IA d'Azure. La documentation de référence est ici.
-
Générez les deux packages : le serveur d’API et l’agent IA.
npm run buildCette commande crée un lien entre les deux packages afin que le serveur d’API puisse appeler l’agent IA.
Exécuter le serveur d’API localement
Azure Developer CLI a créé les ressources Azure requises et configuré les variables d’environnement dans le fichier racine .env . Cette configuration incluait un hook de post-approvisionnement pour charger les données dans le magasin vectoriel. À présent, vous pouvez exécuter le serveur d’API Fastify qui héberge l’agent LangChain.js. Démarrez le serveur d’API Fastify.
npm run dev
Le serveur démarre et écoute sur le port 3000. Vous pouvez tester le serveur en accédant à [http://localhost:3000] dans votre navigateur web. Vous devez voir un message de bienvenue indiquant que le serveur est en cours d’exécution.
Utiliser l’API pour poser des questions
Vous pouvez utiliser un outil tel que le client REST ou curl envoyer une requête POST au /ask point de terminaison avec un corps JSON contenant votre question.
Les requêtes clientes Rest sont disponibles dans le packages-v1/server-api/http répertoire.
Exemple utilisant curl :
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
Vous devez recevoir une réponse JSON avec la réponse de l’agent LangChain.js.
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
Plusieurs exemples de questions sont disponibles dans le packages-v1/server-api/http répertoire. Ouvrez les fichiers dans Visual Studio Code avec REST Client pour les tester rapidement.
Comprendre le code de l’application
Cette section explique comment l’agent LangChain.js s’intègre aux services Azure. L’application du référentiel est organisée en tant qu’espace de travail npm avec deux packages principaux :
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
Décisions architecturales clés :
- Structure Monorepo : les espaces de travail npm autorisent les dépendances partagées et les packages liés
-
Séparation des problèmes : la logique de l’agent (
langgraph-agent) est indépendante du serveur d’API (server-api) -
Authentification centralisée : les fichiers dans
./langgraph-agent/src/azuregèrent à la fois l'authentification par clés, l'authentification sans mot de passe et l'intégration du service Azure.
Authentification auprès des services Azure
L’application prend en charge les méthodes d’authentification sans clé et sans mot de passe, contrôlées par la variable d’environnement SET_PASSWORDLESS . L’API DefaultAzureCredential de la bibliothèque d’identités Azure est utilisée pour l’authentification sans mot de passe, ce qui permet à l’application de s’exécuter en toute transparence dans les environnements de développement local et Azure. Vous pouvez voir cette authentification dans l’extrait de code suivant :
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
Lorsque vous utilisez des bibliothèques tierces comme LangChain.js ou la bibliothèque OpenAI pour accéder à Azure OpenAI, vous avez besoin d’une fonction de fournisseur de jetons au lieu de transmettre directement un objet d’informations d’identification. La getBearerTokenProvider fonction de la bibliothèque d’identités Azure résout ce problème en créant un fournisseur de jetons qui récupère et actualise automatiquement les jetons du porteur OAuth 2.0 pour une étendue de ressource Azure spécifique (par exemple). "https://cognitiveservices.azure.com/.default" Vous configurez l’étendue une fois lors de l’installation, et le fournisseur de jetons gère automatiquement toutes les gestions des jetons. Cette approche fonctionne avec toutes les informations d’identification de la bibliothèque d’identités Azure, notamment les informations d’identification d’identité managée et d’Azure CLI. Bien que les bibliothèques du Kit de développement logiciel (SDK) Azure acceptent DefaultAzureCredential directement, les bibliothèques tierces comme LangChain.js nécessitent ce modèle de fournisseur de jetons pour combler l’écart d’authentification.
Intégration d’Azure AI Search
La ressource Recherche d’IA Azure stocke les incorporations de documents et active la recherche sémantique du contenu pertinent. L’application AzureAISearchVectorStore utilise LangChain pour gérer le magasin vectoriel sans avoir à définir le schéma d’index.
Le magasin vectoriel est créé avec la configuration pour les opérations d’administration (écriture) et de requête (lecture) afin que le chargement et l’interrogation de documents puissent utiliser différentes configurations. Il est important que vous utilisiez des clés ou une authentification sans mot de passe avec des identités managées.
Le déploiement Azure Developer CLI inclut un hook post-déploiement qui charge les documents dans le stockage vectoriel avec le chargeur PDF LangChain.js et le client d'incorporation. Ce hook post-déploiement est la dernière étape de la azd up commande après la création de la ressource Recherche d’IA Azure. Le script de chargement de documents utilise la logique de traitement par lots et de nouvelle tentative pour gérer les limites de débit de service.
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Utilisez le fichier racine .env créé par Azure Developer CLI, vous pouvez vous authentifier auprès de la ressource Recherche d’IA Azure et créer le client AzureAISearchVectorStore :
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
Lorsque vous effectuez une requête, la base de vecteurs convertit la requête de l'utilisateur en un vecteur d'incorporation, recherche des documents possédant des représentations vectorielles similaires, et retourne les blocs les plus pertinents.
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
Étant donné que le magasin de vecteurs est basé sur LangChain.js, il extrait la complexité de l’interaction directe avec le magasin vectoriel. Une fois que vous avez appris l’interface de magasin de vecteurs LangChain.js, vous pouvez facilement basculer vers d’autres implémentations de magasin de vecteurs à l’avenir.
Intégration d’Azure OpenAI
L’application utilise Azure OpenAI pour les incorporations et les fonctionnalités LLM (Large Language Model). La AzureOpenAIEmbeddings classe de LangChain.js est utilisée pour générer des incorporations pour les documents et les requêtes. Une fois que vous avez créé le client d’incorporations, LangChain.js l’utilise pour créer les incorporations.
Intégration d’Azure OpenAI pour les incorporations
Utilisez le fichier racine .env créé par Azure Developer CLI pour s’authentifier auprès de la ressource Azure OpenAI et créer le client AzureOpenAIEmbeddings :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
Intégration d’Azure OpenAI pour LLM
Utilisez le fichier racine .env créé par Azure Developer CLI pour vous authentifier auprès de la ressource Azure OpenAI et créer le client AzureChatOpenAI :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 100,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
L’application utilise la AzureChatOpenAI classe de LangChain.js @langchain/openai pour interagir avec les modèles Azure OpenAI.
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
Flux de travail de l’agent LangGraph
L’agent utilise LangGraph pour définir un flux de travail de décision qui détermine si une question peut être répondue à l’aide de documents RH.
Structure de graphe :
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
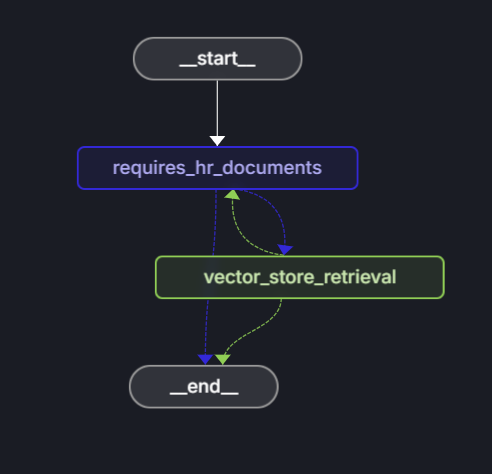
Le flux de travail comprend les étapes suivantes :
- Début : l’utilisateur envoie une question.
- nœud requires_hr_documents : LLM détermine si la question est répondable à partir de documents RH généraux.
-
Routage conditionnel :
- Si c’est le cas, passe au
get_answernœud. - Si ce n’est pas le cas, retourne un message indiquant que la question nécessite des données RH personnelles.
- Si c’est le cas, passe au
- get_answer node : récupère des documents et génère une réponse.
- Fin : retourne la réponse à l’utilisateur.
Cette vérification de pertinence est importante, car toutes les questions RH ne peuvent pas être répondues à partir de documents généraux. Les questions personnelles telles que « Combien d’PTO ai-je ? » nécessitent l’accès aux bases de données des employés qui contiennent des données individuelles des employés. En vérifiant d’abord la pertinence, l’agent évite d’halluciner les réponses aux questions qui ont besoin d’informations personnelles auxquelles il n’a pas accès.
Décider si la question nécessite des documents RH
Le requires_hr_documents nœud utilise un LLM pour déterminer si la question de l’utilisateur peut être répondue à l’aide de documents RH généraux. Il utilise un modèle d'invite qui indique au modèle de répondre avec YES ou NO en fonction de la pertinence de la question. Elle retourne la réponse dans un message structuré, qui peut être transmise le long du flux de travail. Le nœud suivant utilise cette réponse pour orienter le flux de travail soit vers le END, soit vers le ANSWER_NODE.
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
Obtenir les documents RH requis
Une fois qu’il est déterminé que la question nécessite des documents RH, le flux de travail utilise getAnswer pour récupérer les documents pertinents à partir du magasin vectoriel, les ajouter au contexte de l’invite et transmettre l’invite entière au LLM.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
Si aucun document pertinent n’est trouvé, l’agent retourne un message indiquant qu’il n’a pas pu trouver de réponse dans les documents RH.
Résolution des problèmes
Pour tout problème lié à la procédure, créez un problème sur l’exemple de référentiel de code
Nettoyer les ressources
Vous pouvez supprimer le groupe de ressources, qui contient la ressource Recherche Azure AI et la ressource Azure OpenAI ou utiliser l’interface CLI développeur Azure pour supprimer immédiatement toutes les ressources créées par ce didacticiel.
azd down --purge