Démarrage rapide : créer votre premier flux de données pour obtenir et transformer des données
Les flux de données sont une technologie de préparation des données en libre-service, basée sur le cloud. Dans cet article, vous créez votre premier flux de données, vous obtenez des données pour votre flux de données, puis vous transformez les données et publiez le flux de données.
Prérequis
Les prérequis suivants sont requis avant de commencer :
- Un compte de locataire Microsoft Fabric avec un abonnement actif. Créez un compte gratuit.
- Vérifiez que vous disposez d’un espace de travail avec Microsoft Fabric : Créer un espace de travail.
Créer un flux de données
Dans cette section, vous créez votre premier flux de données.
Passez à l’expérience Data Factory.
Accédez à votre espace de travail Microsoft Fabric.
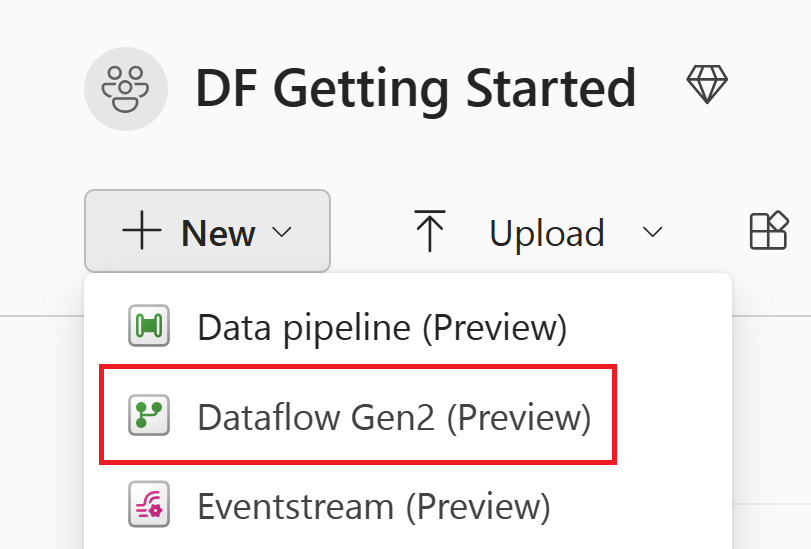
Sélectionnez Nouveau, puis Flux de données Gen2.

Obtenir des données
Nous allons maintenant obtenir des données. Dans cet exemple, vous obtenez des données à partir d’un service OData. Procédez comme suit pour obtenir des données dans votre flux de données.
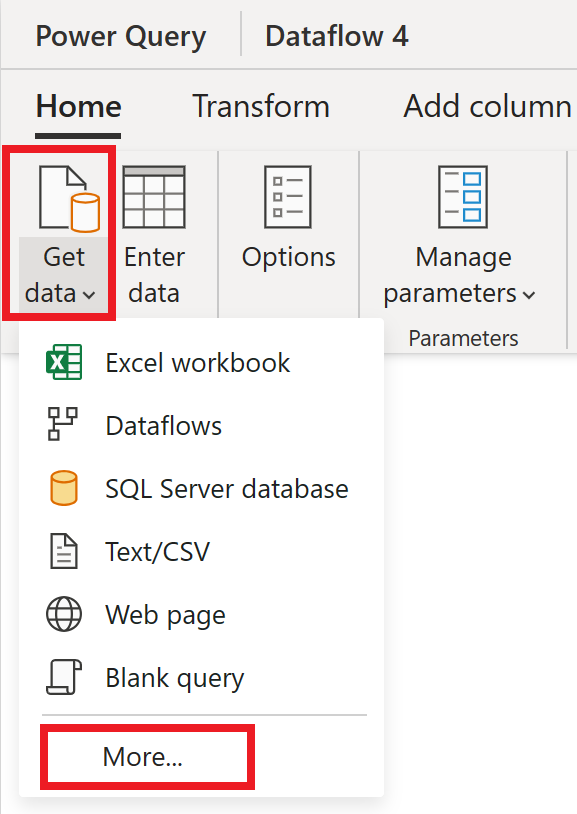
Dans l’éditeur de flux de données, sélectionnez Obtenir des données, puis Plus.
Dans Choisir une source de données, sélectionnez Afficher plus.
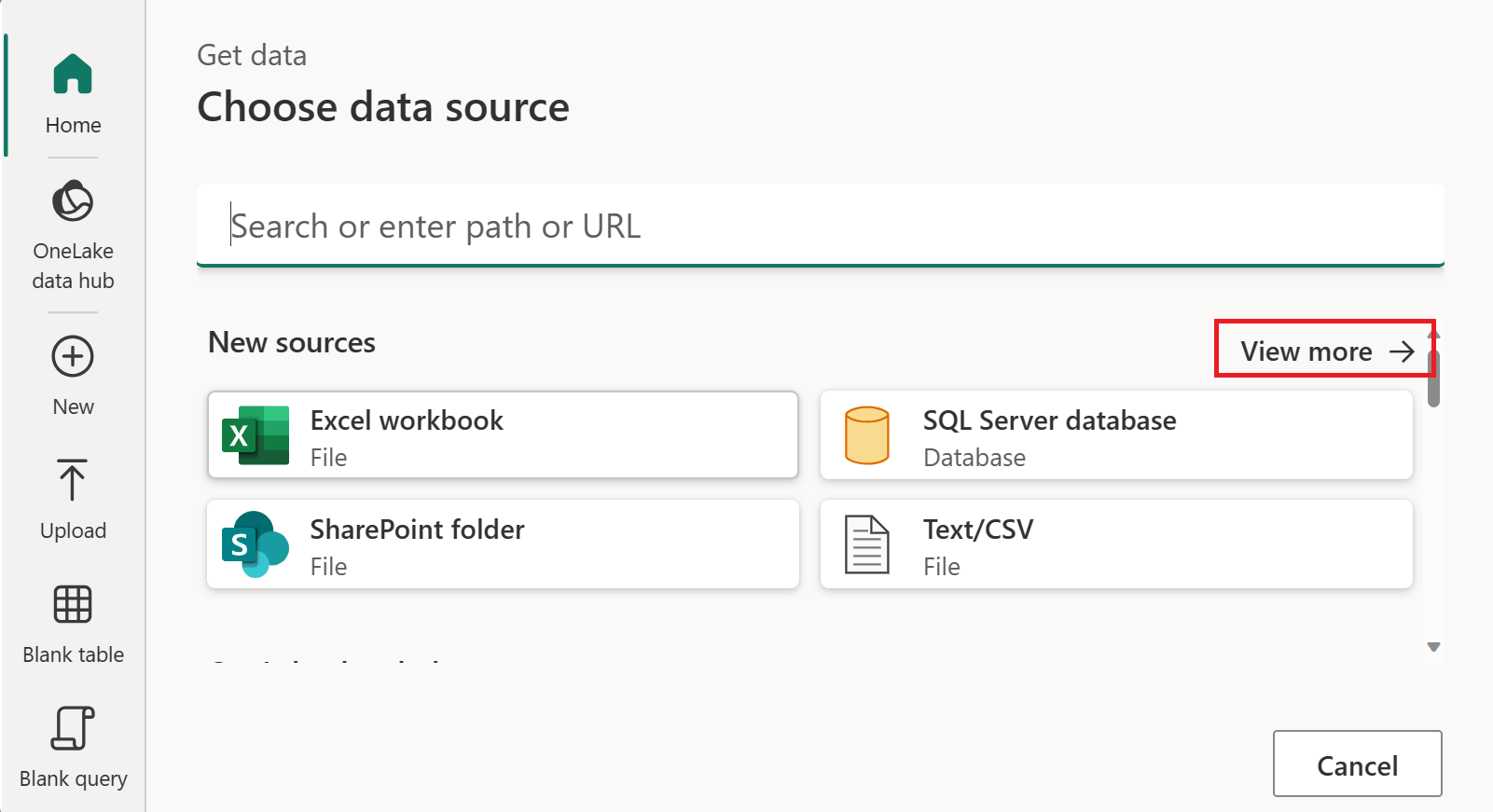
Dans Nouvelle source, sélectionnez Autre>OData comme source de données.

Entrez l’URL
https://services.odata.org/v4/northwind/northwind.svc/, puis sélectionnez Suivant.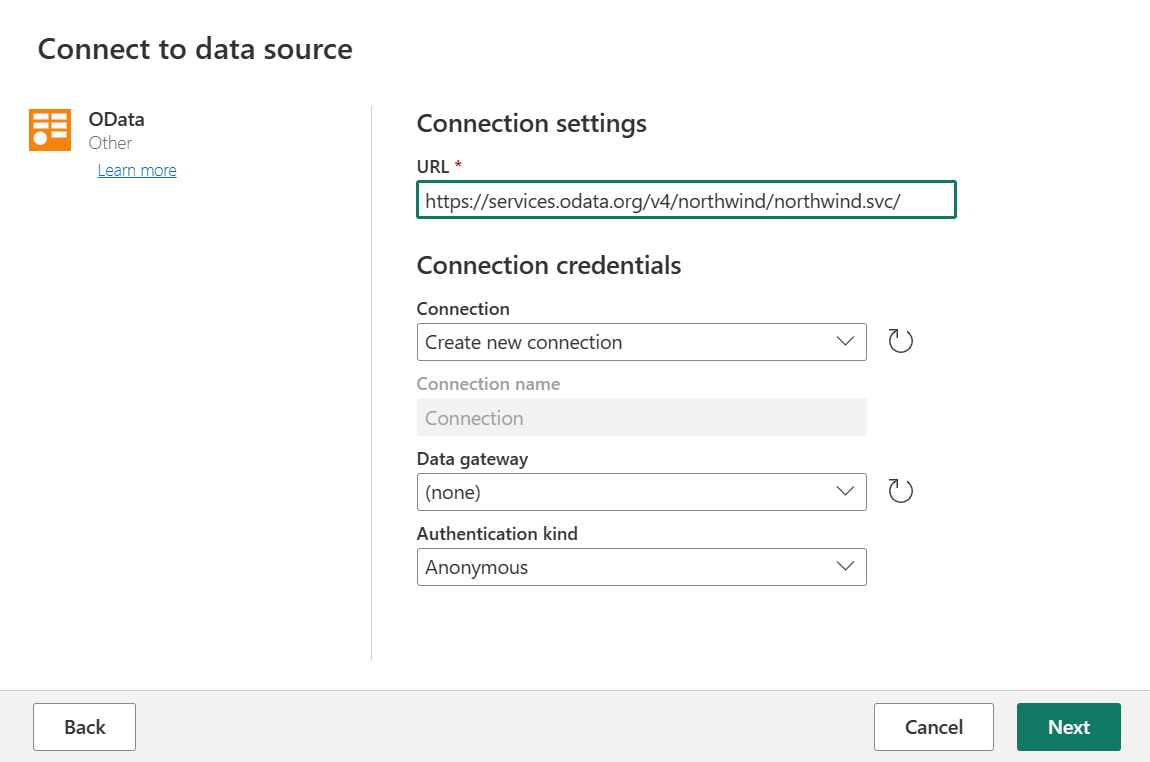
Sélectionnez les tables Commandes et Clients, puis cliquez sur Créer.
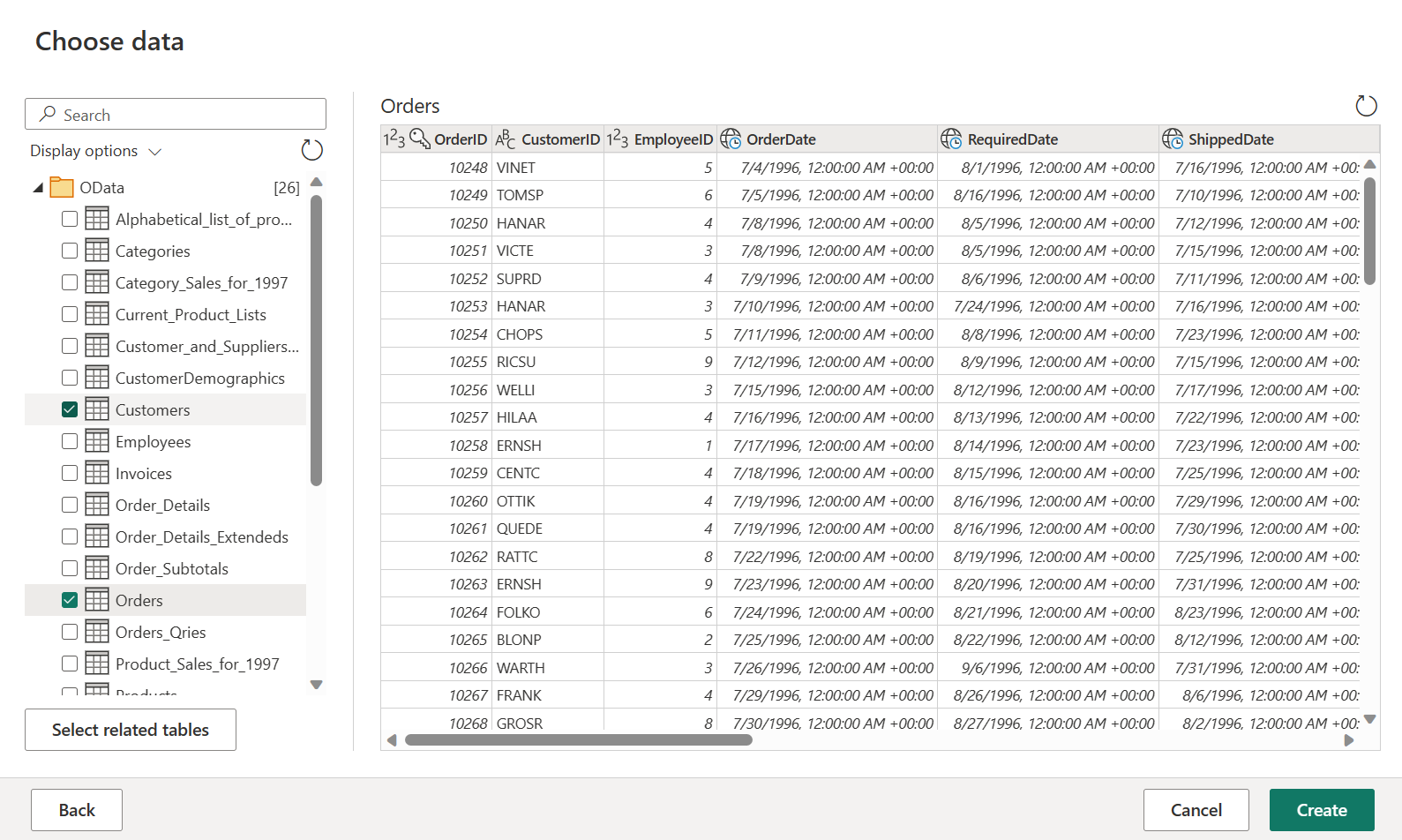



Pour en savoir plus sur l’expérience et les fonctionnalités d’obtention de données, consultez Vue d’ensemble de l’obtention de données.
Appliquer des transformations et publier
Vous avez maintenant chargé vos données dans votre premier flux de données. Félicitations ! Il est maintenant temps d’appliquer quelques transformations afin de donner à ces données la forme souhaitée.
Vous effectuez cette tâche à partir de l’éditeur Power Query. Vous trouverez une vue d’ensemble détaillée de l’éditeur Power Query dans Interface utilisateur Power Query.
Procédez comme suit pour appliquer des transformations et publier :
Vérifiez que les outils de profilage des données sont activés en accédant àAccueil>Options>Options globales.
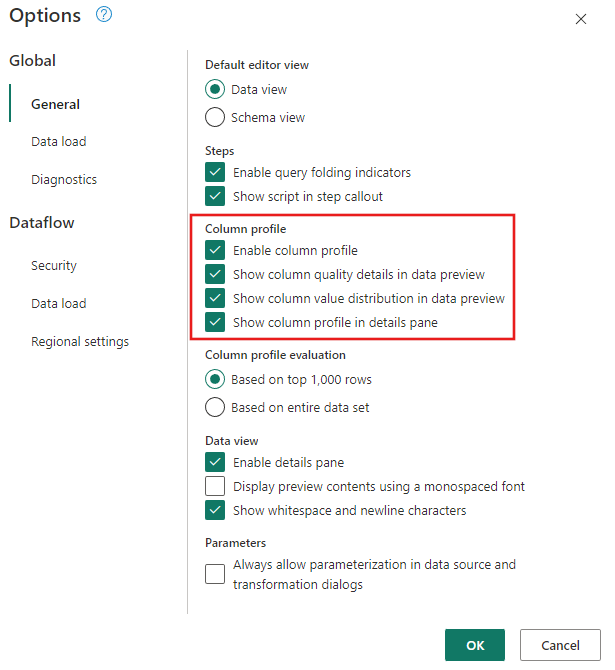
Veillez également à activer la vue du diagramme à l'aide des options de l'onglet Afficher dans le ruban de l'éditeur Power Query, ou en sélectionnant l'icône d'affichage du diagramme dans la partie inférieure droite de la fenêtre Power Query.
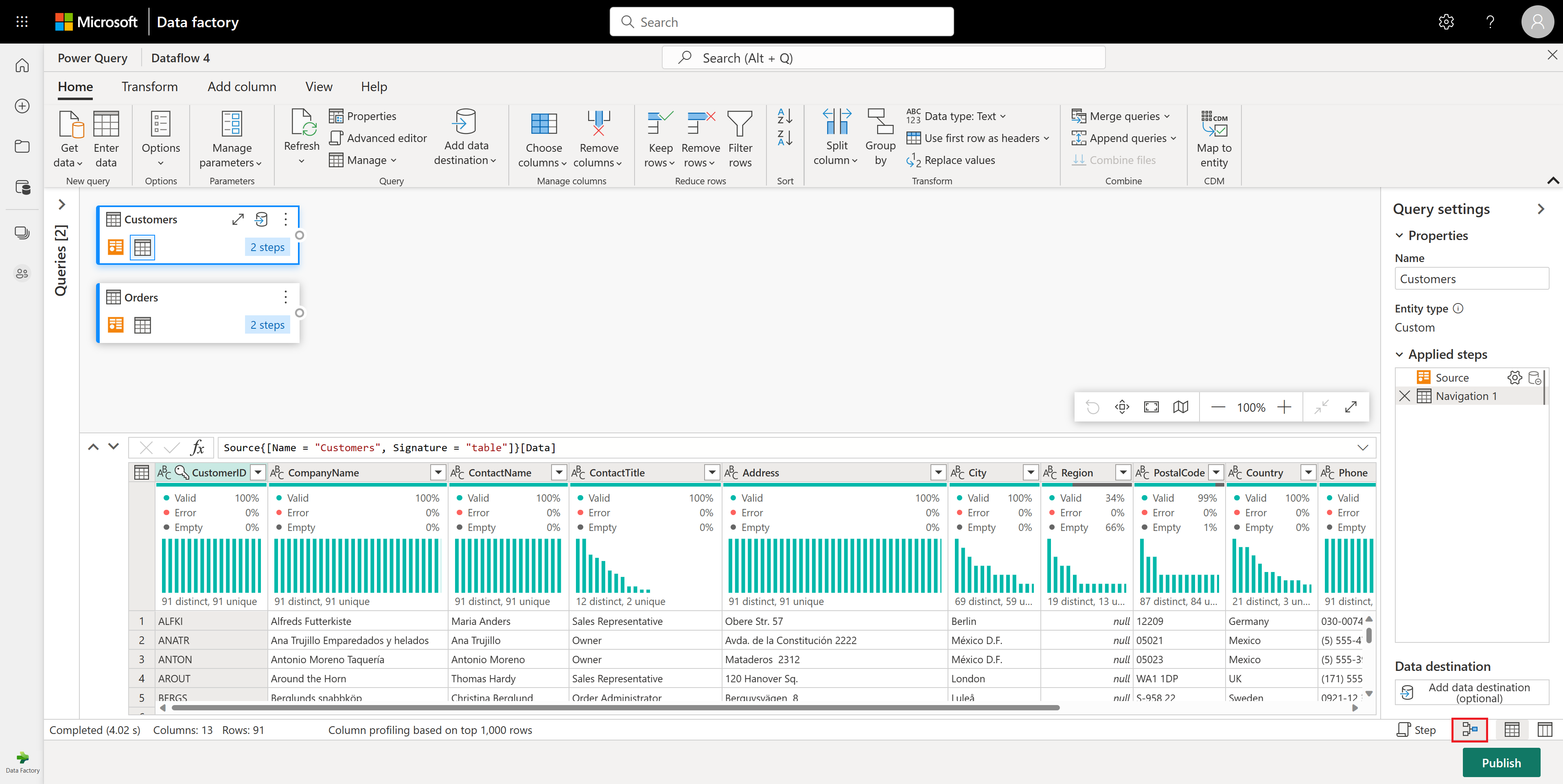
Dans la table Commandes, vous calculez le nombre total de commandes par client. Pour atteindre cet objectif, sélectionnez la colonne CustomerID dans l’aperçu des données, puis sélectionnez Regrouper par sous l’onglet Transformer dans le ruban.
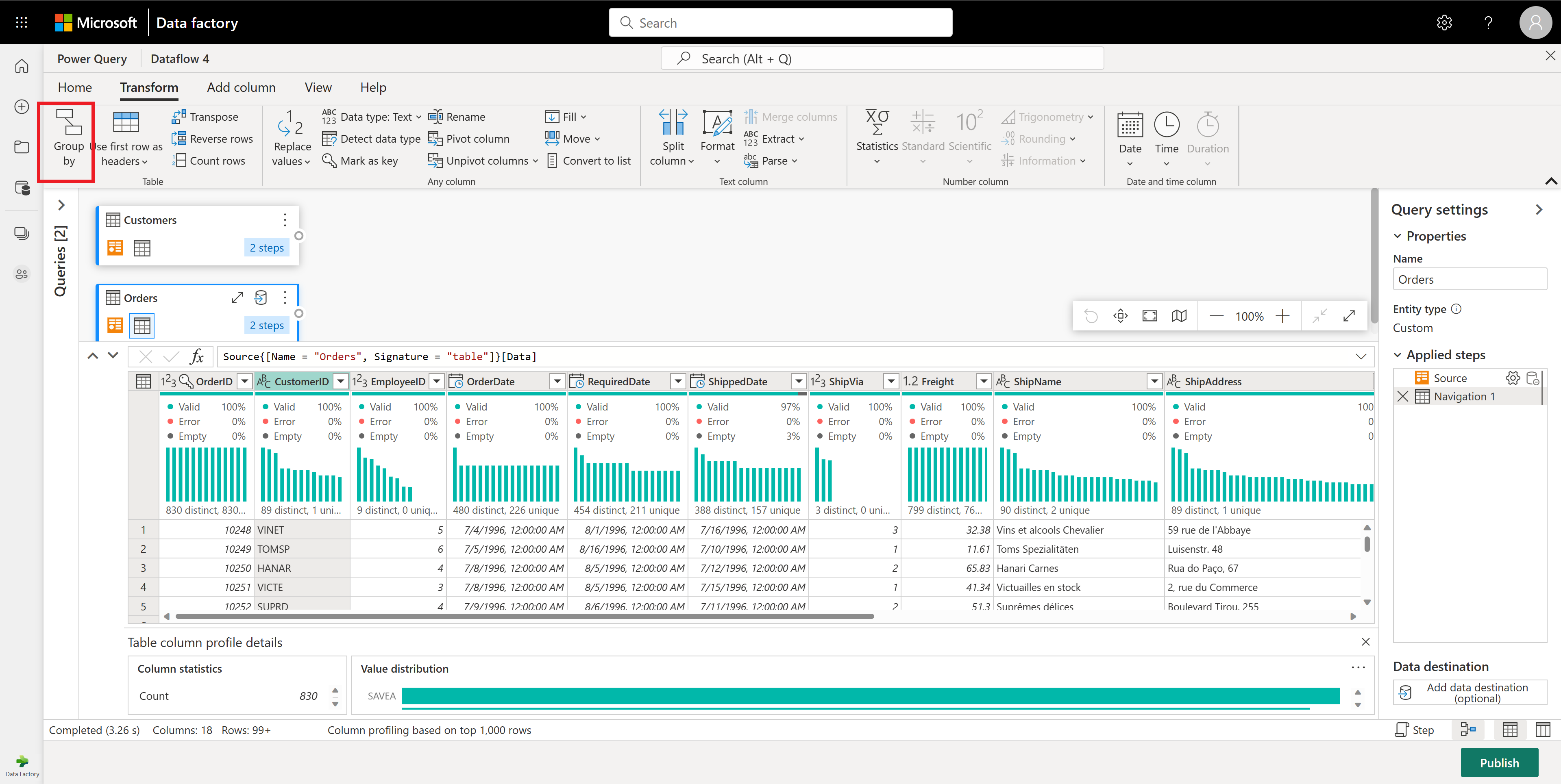
Vous effectuez un compte des lignes en tant qu’agrégation dans Regrouper par. Pour en savoir plus sur les fonctionnalités deRegrouper par, consultez Regroupement ou synthèse des lignes.
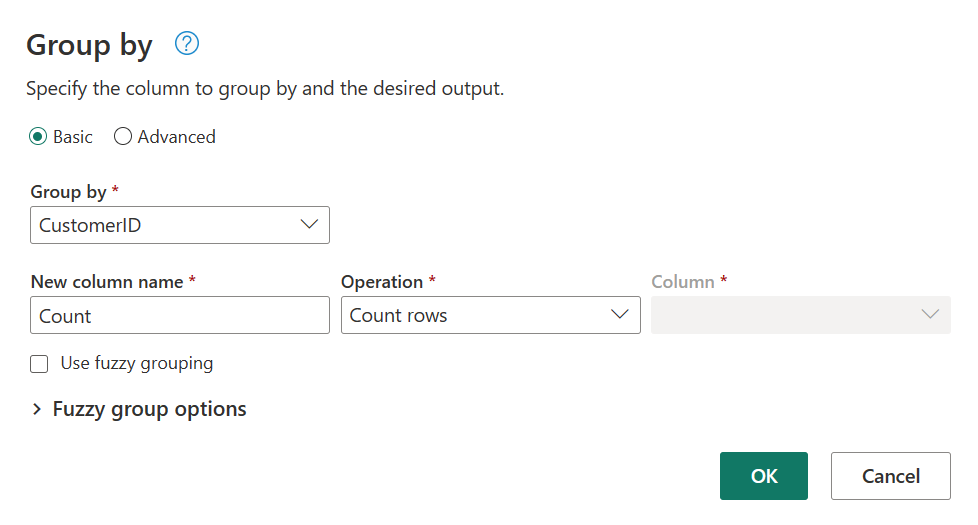
Après avoir groupé les données dans la table Commandes, nous obtenons une table avec deux colonnes : CustomerID et Compte.
Ensuite, vous souhaitez combiner les données de la table Clients avec le nombre de commandes par client. Pour combiner des données, sélectionnez la requête Clients dans l’affichage des diagramme et utilisez le menu « ⋮ » pour accéder à la transformation Fusionner les requêtes en tant que nouvelles transformation.
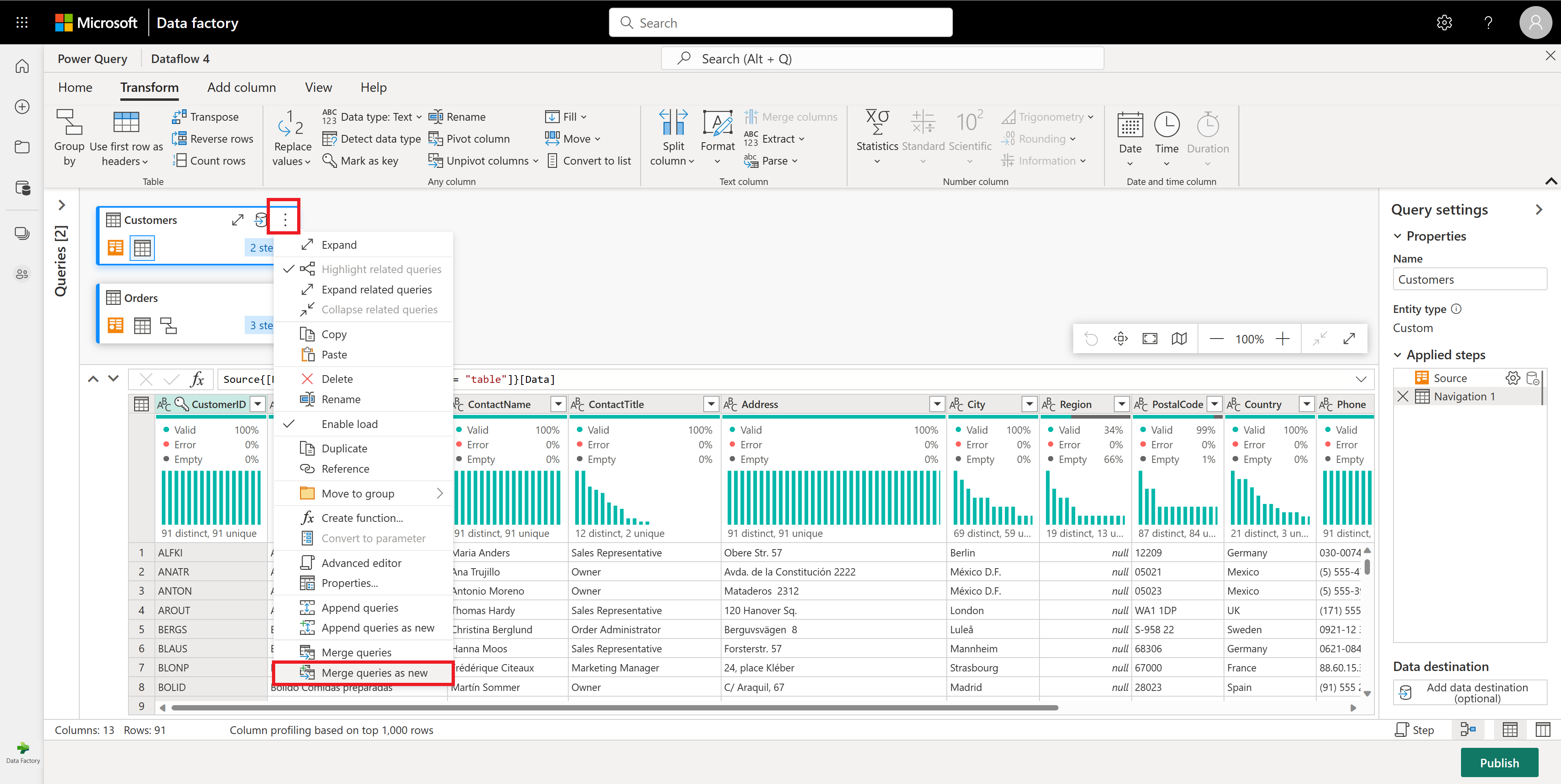
Configurez l’opération de fusion comme illustré dans la capture d’écran suivante en sélectionnant CustomerID comme colonne correspondante dans les deux tables. Sélectionnez ensuite Ok.
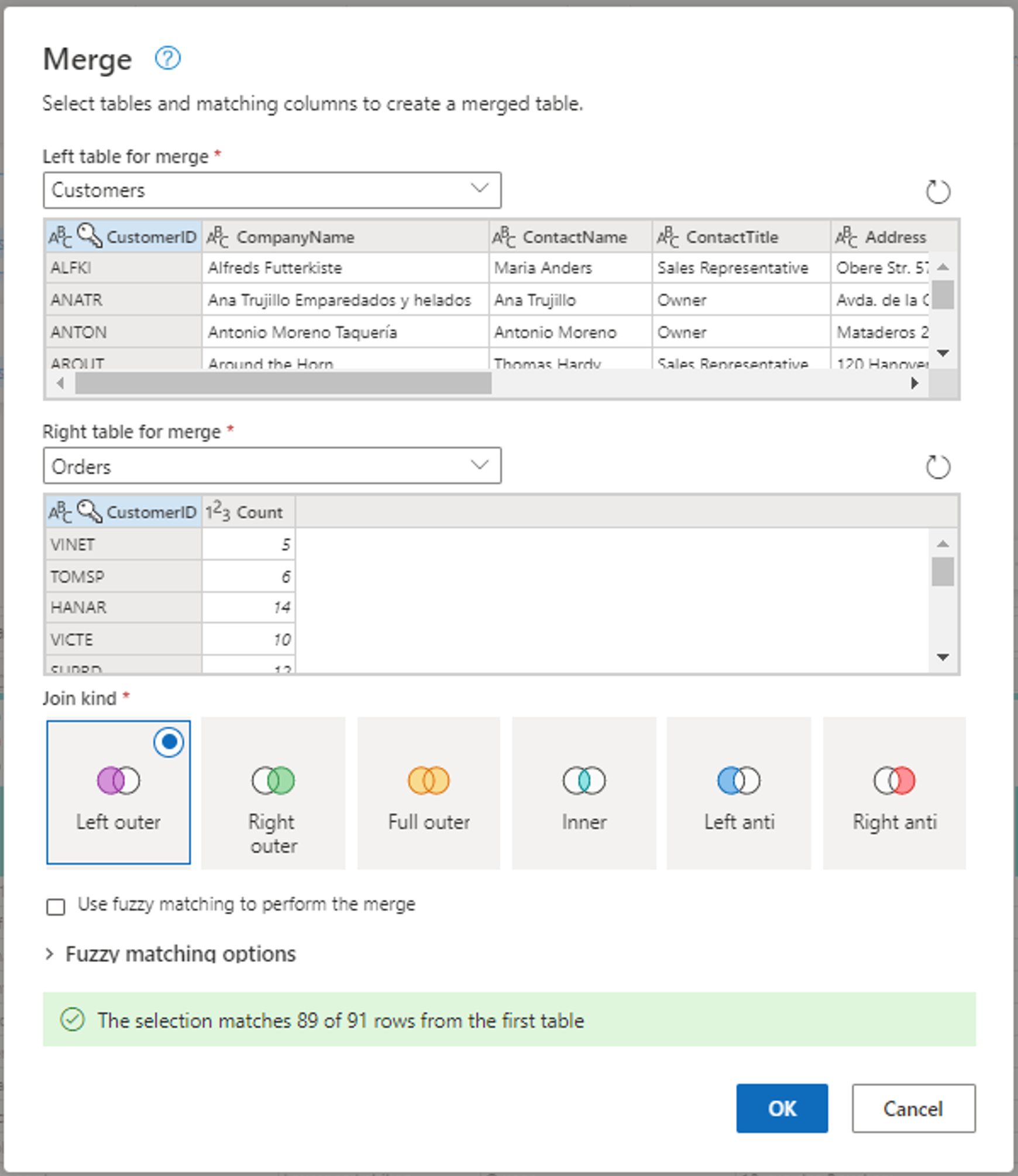
Capture d’écran de la fenêtre Fusionner, avec la table de gauche pour la fusion définie sur la table Clients et la table de droite pour la fusion définie sur la table Commandes. La colonne CustomerID est sélectionnée pour les tables Clients et Commandes. En outre, l’option Type de jointure est définie sur Externe gauche. Toutes les autres sélections sont définies sur leur valeur par défaut.
Lors de l’exécution de l’opération Fusionner les requêtes comme nouvelles, vous obtenez une nouvelle requête avec toutes les colonnes de la table Clients et une colonne avec des données imbriquées de la table Commandes.
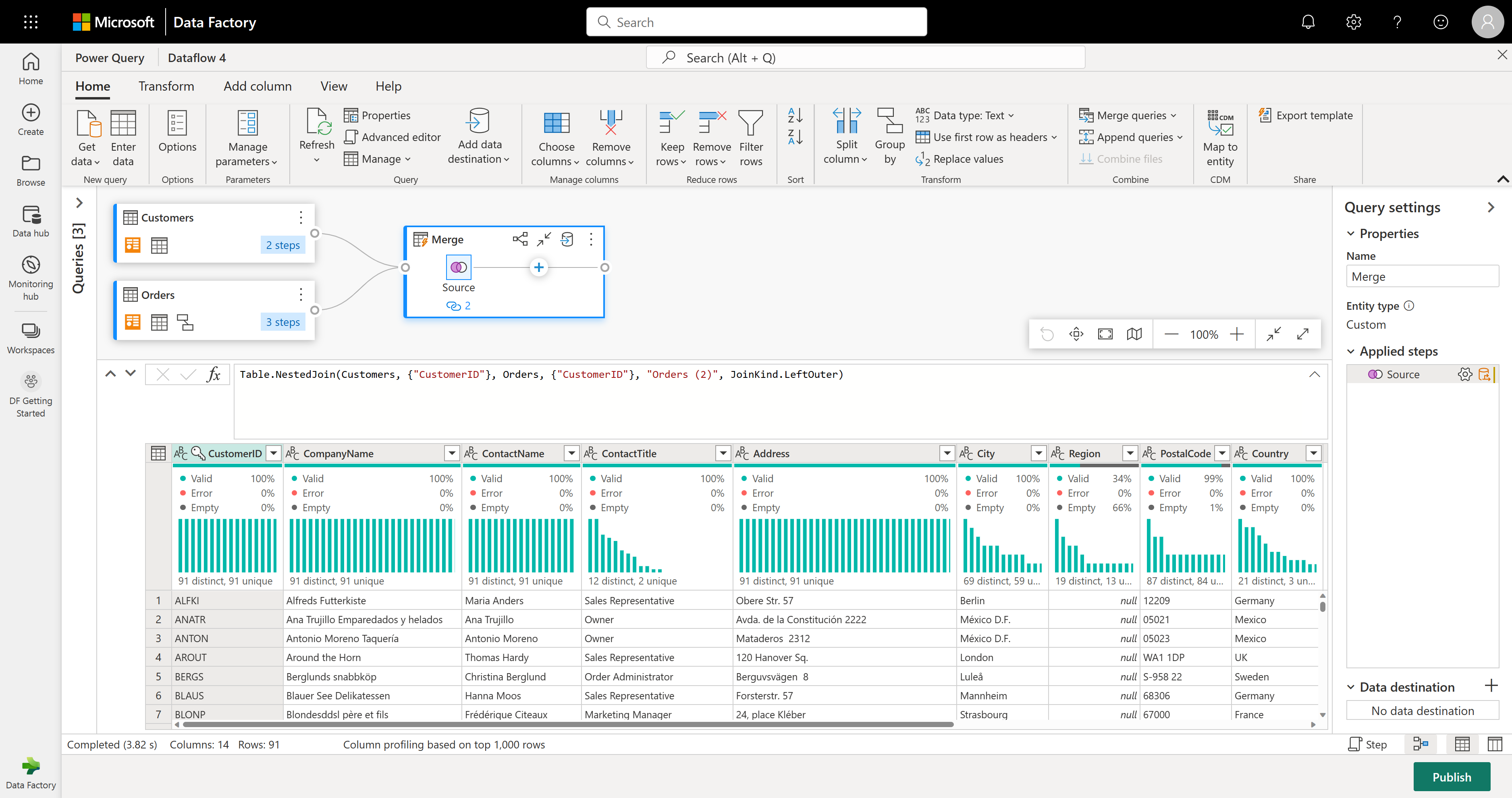
Dans cet exemple, vous ne vous intéressez qu’à un sous-ensemble de colonnes dans la table Clients. Vous sélectionnez ces colonnes à l’aide de la vue de schéma. Activez la vue de schéma avec le bouton bascule dans le coin inférieur droit de l’éditeur de flux de données.
La vue de schéma fournit une vue ciblée sur les informations de schéma d’une table, y compris les noms de colonnes et les types de données. La vue schéma comporte un ensemble d’outils de schéma disponibles via un onglet contextuel du ruban. Dans ce scénario, vous sélectionnez les colonnes CustomerID, CompanyNameet Commandes (2), puis le bouton Supprimer les colonnes, puis Supprimer d’autres colonnes sous l’onglet Outils de schéma.
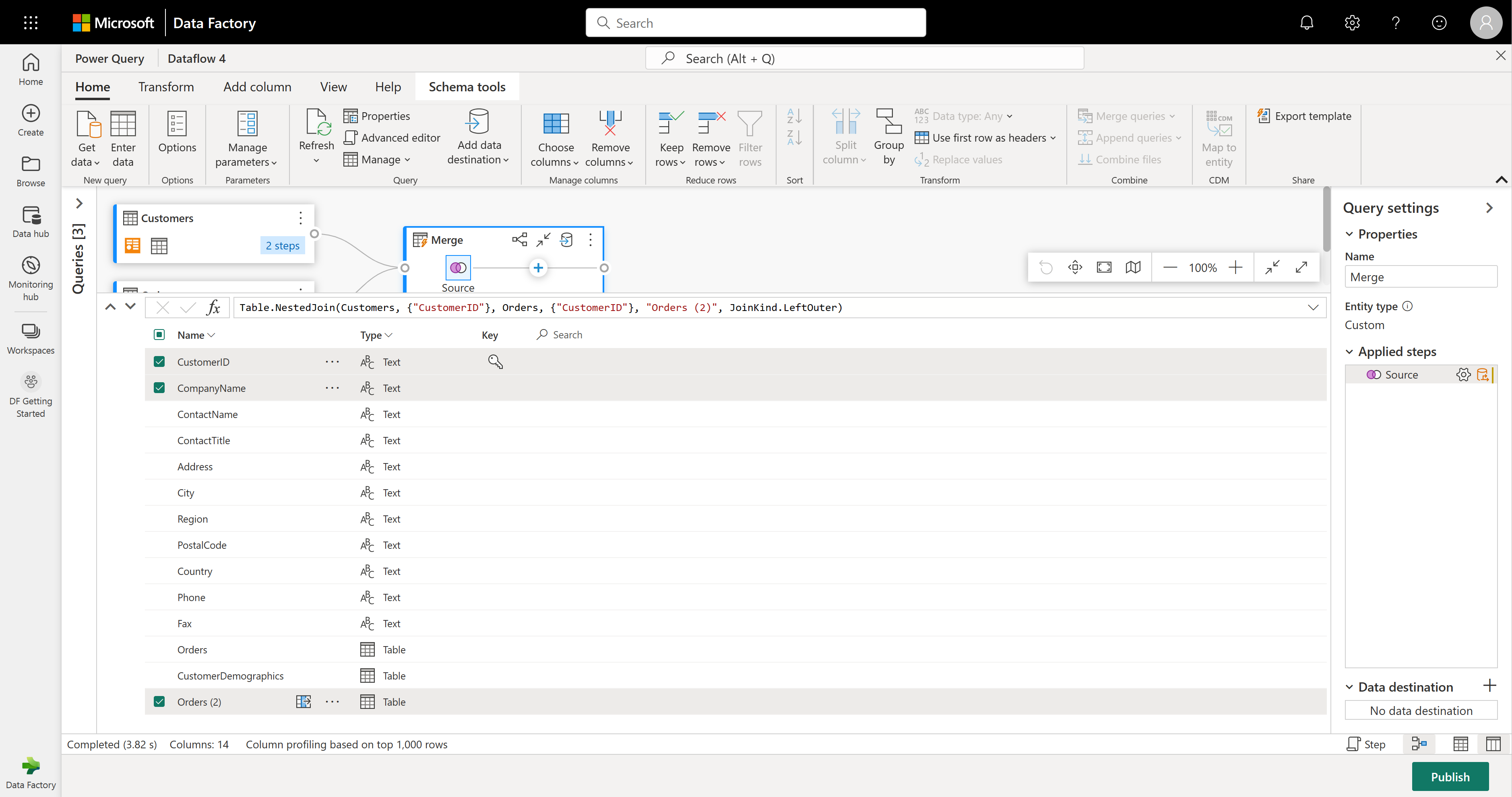
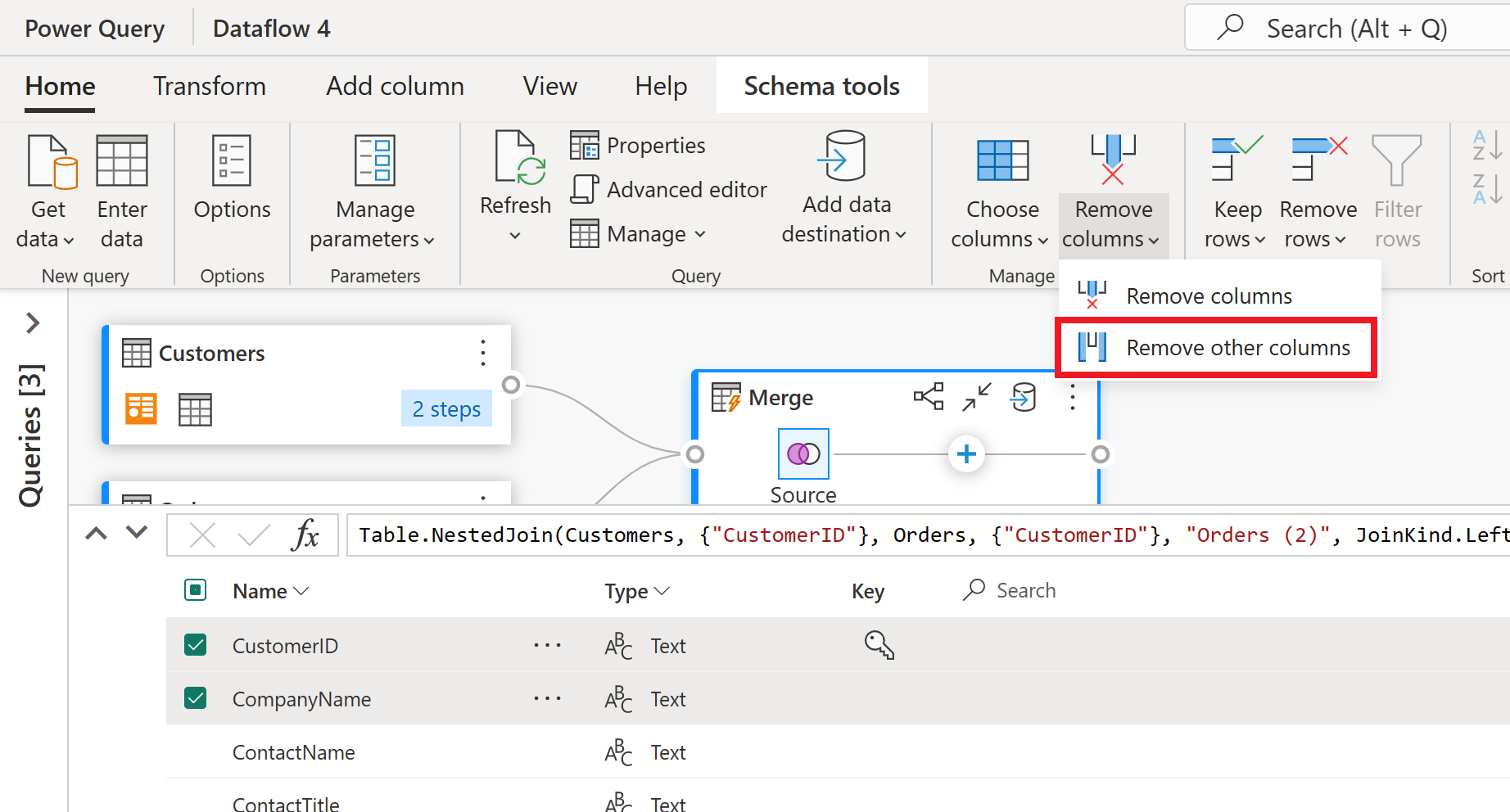
La colonne Orders (2) contient des informations imbriquées résultant de l’opération de fusion que vous avez effectuée il y a quelques étapes. À présent, revenez à la vue de données en sélectionnant le bouton Afficher la vue Données en regard du bouton Afficher la vue de schéma dans le coin inférieur droit de l’interface utilisateur. Utilisez ensuite la transformation Développer la colonne dans l’en-tête de colonne Orders (2) pour sélectionner la colonne Count .

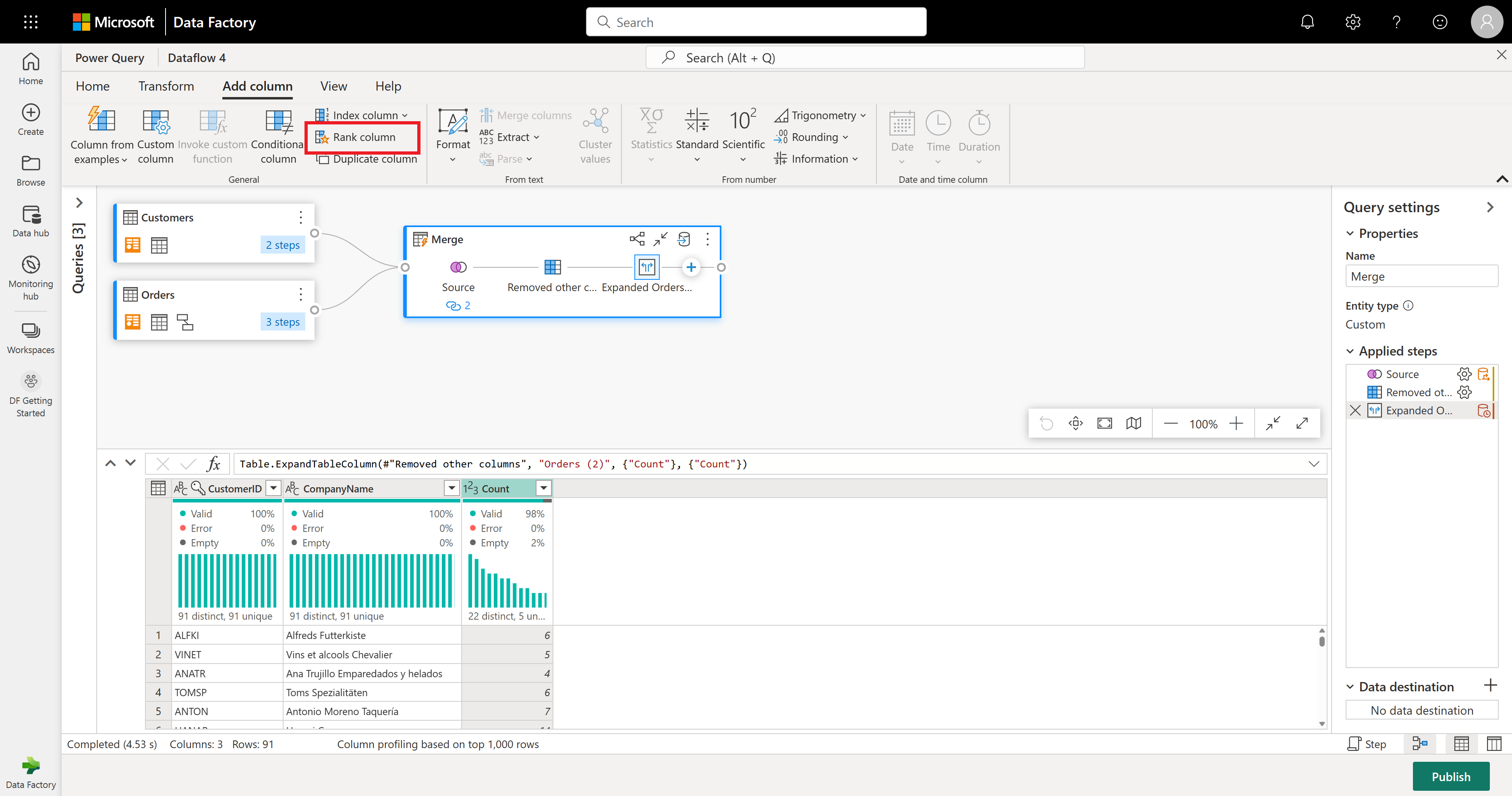
Pour votre dernière opération, vous souhaitez classer vos clients en fonction de leur nombre de commandes. Sélectionnez la colonne Count, puis sélectionnez le bouton Colonne de rang sous l’onglet Ajouter une colonne dans le ruban.
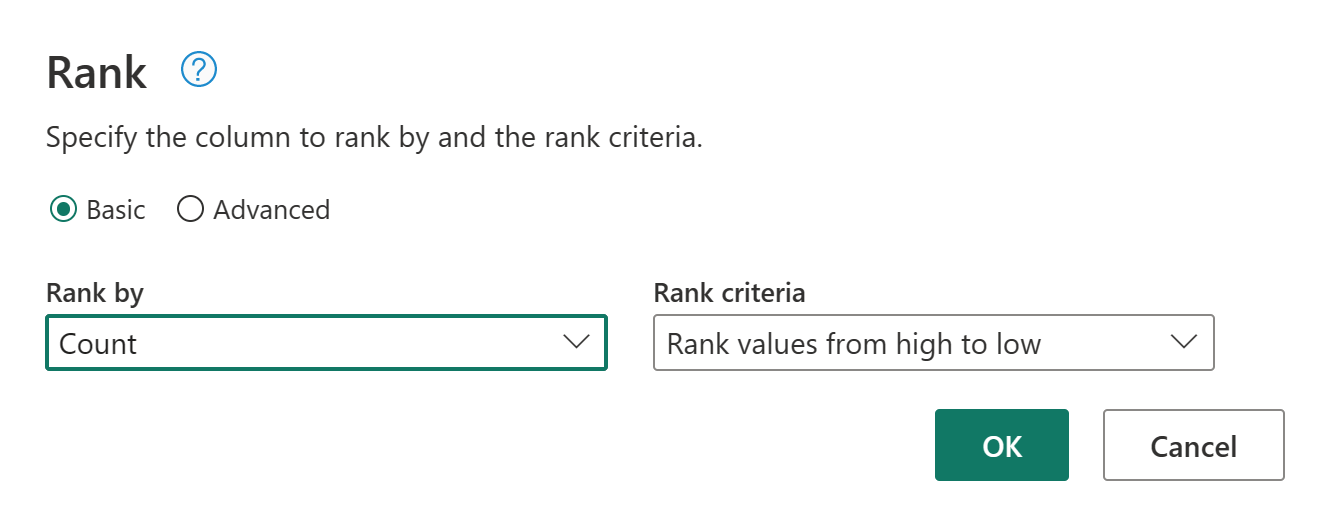
Conservez les paramètres par défaut dans Colonne de rang. Sélectionnez ensuite OK pour appliquer cette transformation.
À présent, renommez la requête obtenue en Clients classés à l’aide du volet Paramètres de la requête sur le côté droit de l’écran.
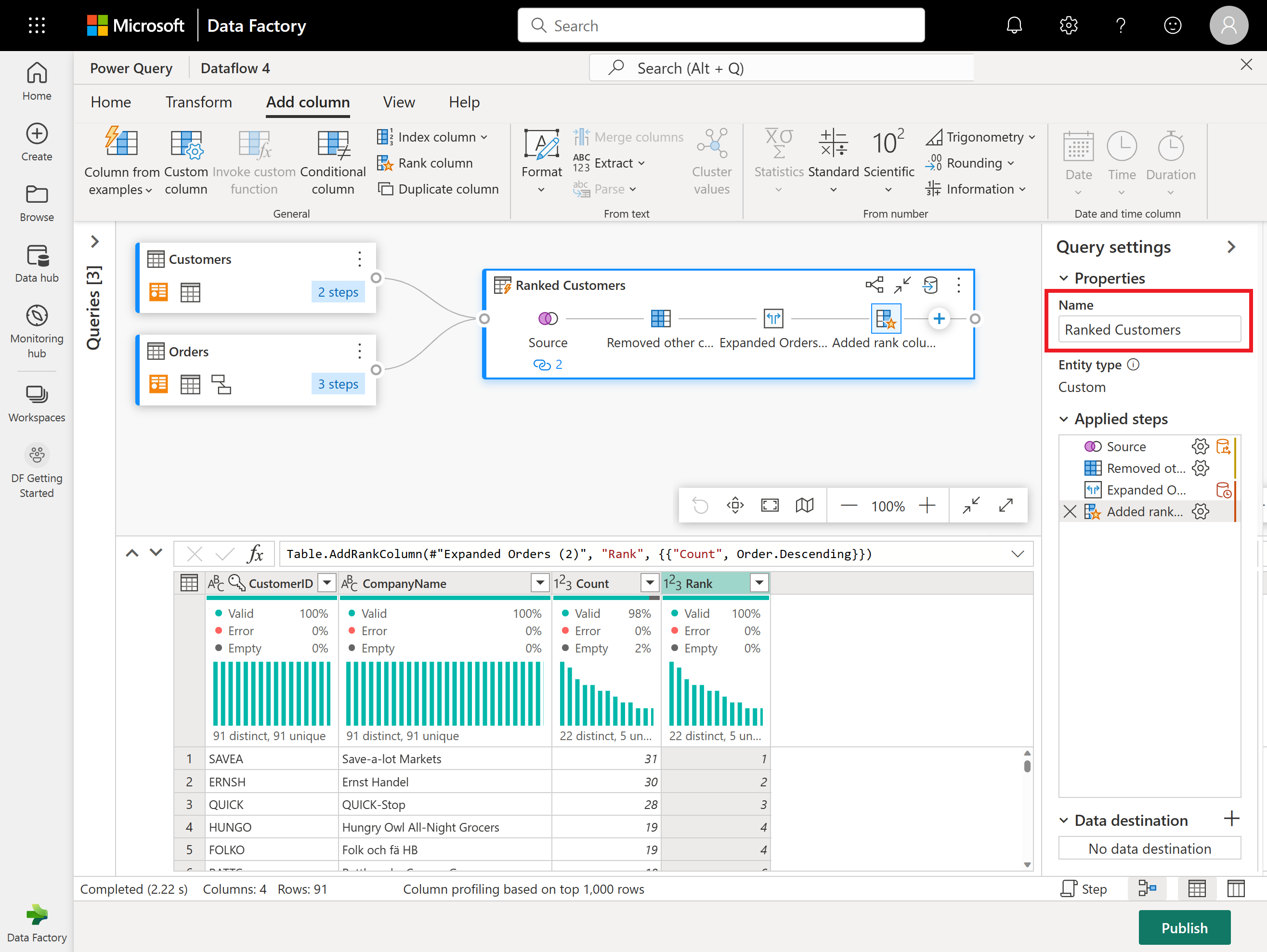
Maintenant que vous avez terminé de transformer et de combiner vos données, vous pouvez configurer ses paramètres de destination de sortie. Sélectionnez Choisir la destination des données en bas du volet Paramètres de la requête.
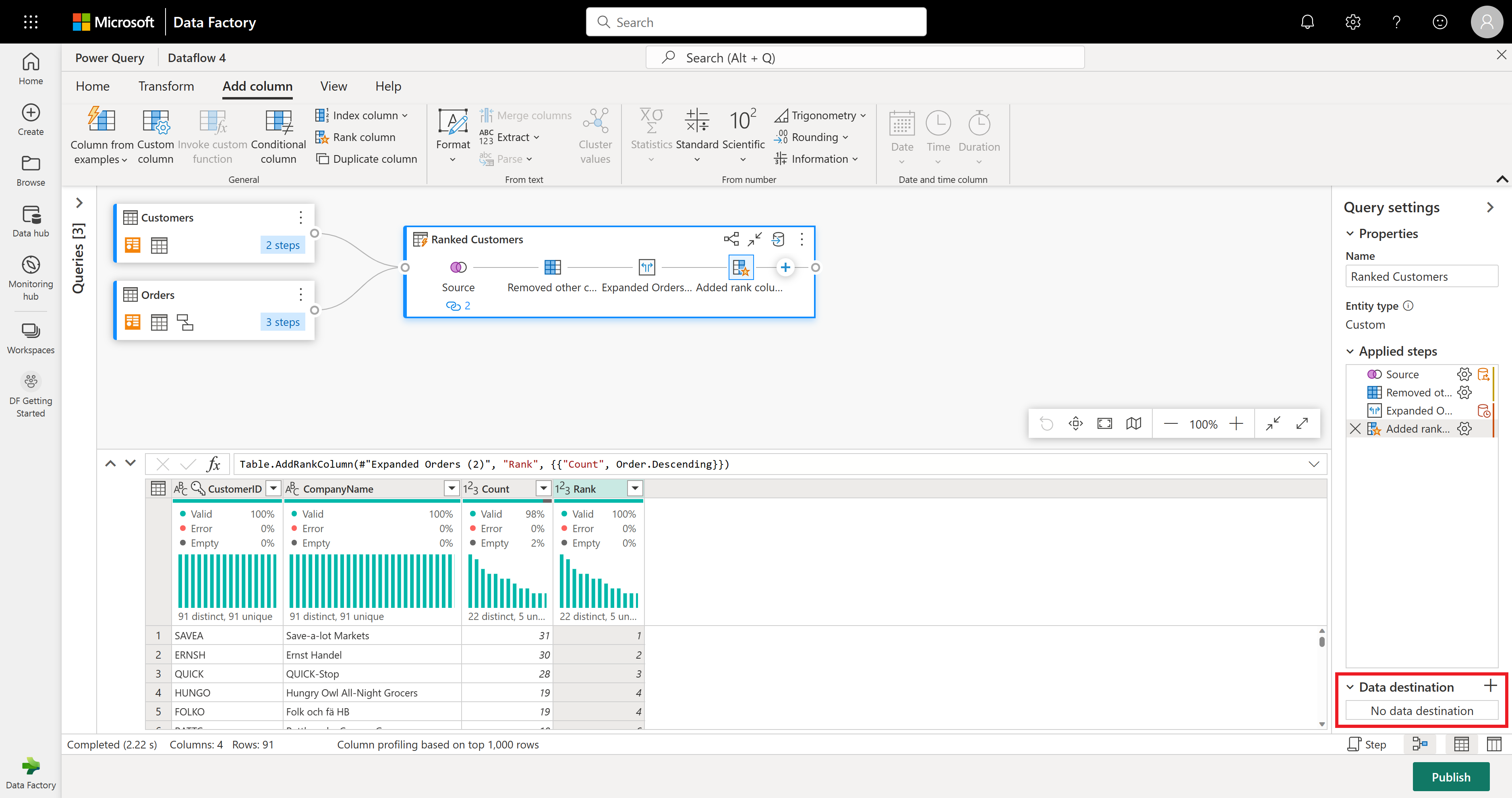
Pour cette étape, vous pouvez configurer une sortie sur votre lakehouse, si vous en avez un de disponible, ou ignorez cette étape si ce n’est pas le cas. Dans cette expérience, vous pouvez configurer le lakehouse de destination et la table pour vos résultats de requête, en plus de la méthode de mise à jour (Ajouter ou Remplacer).
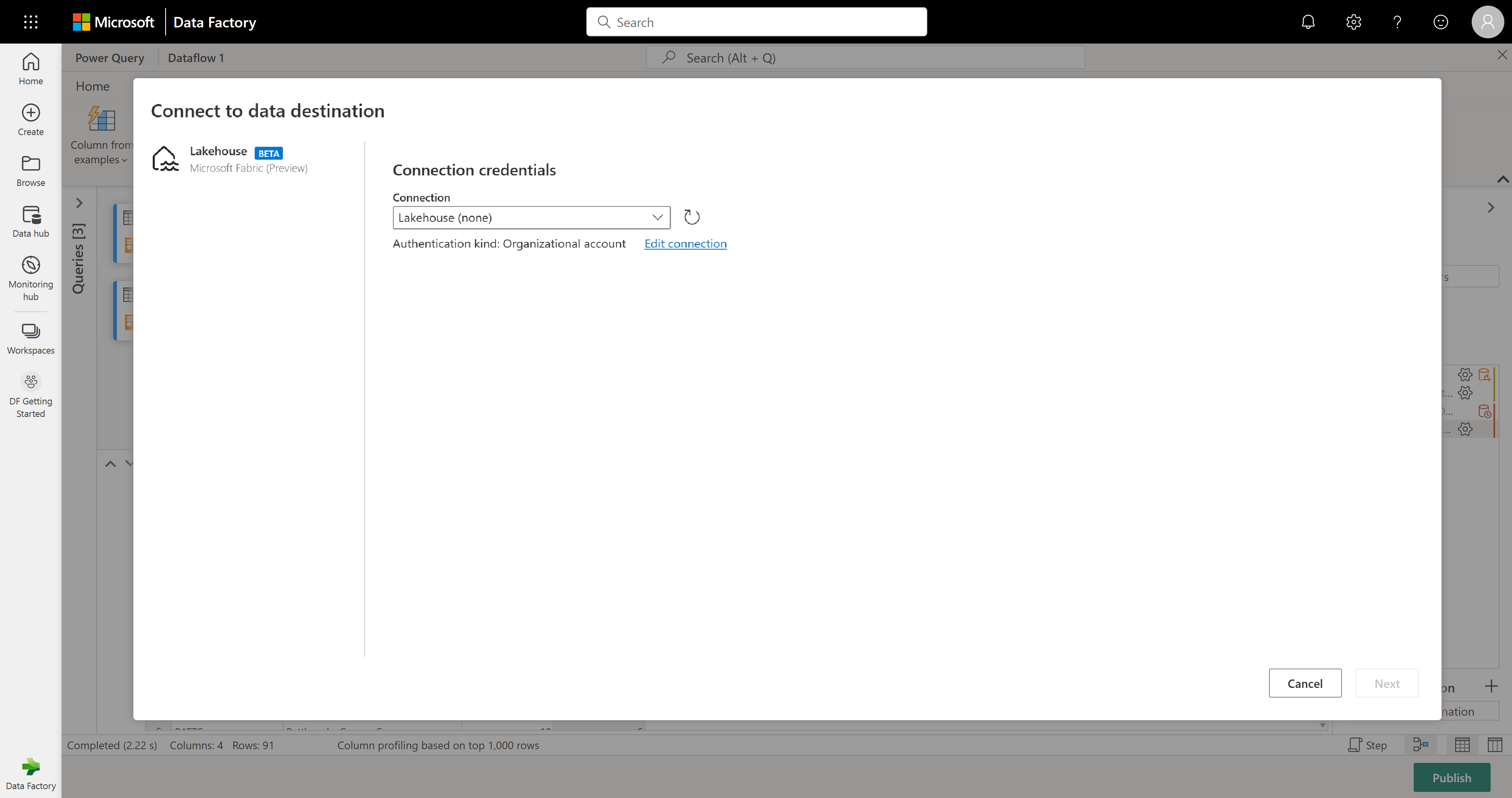
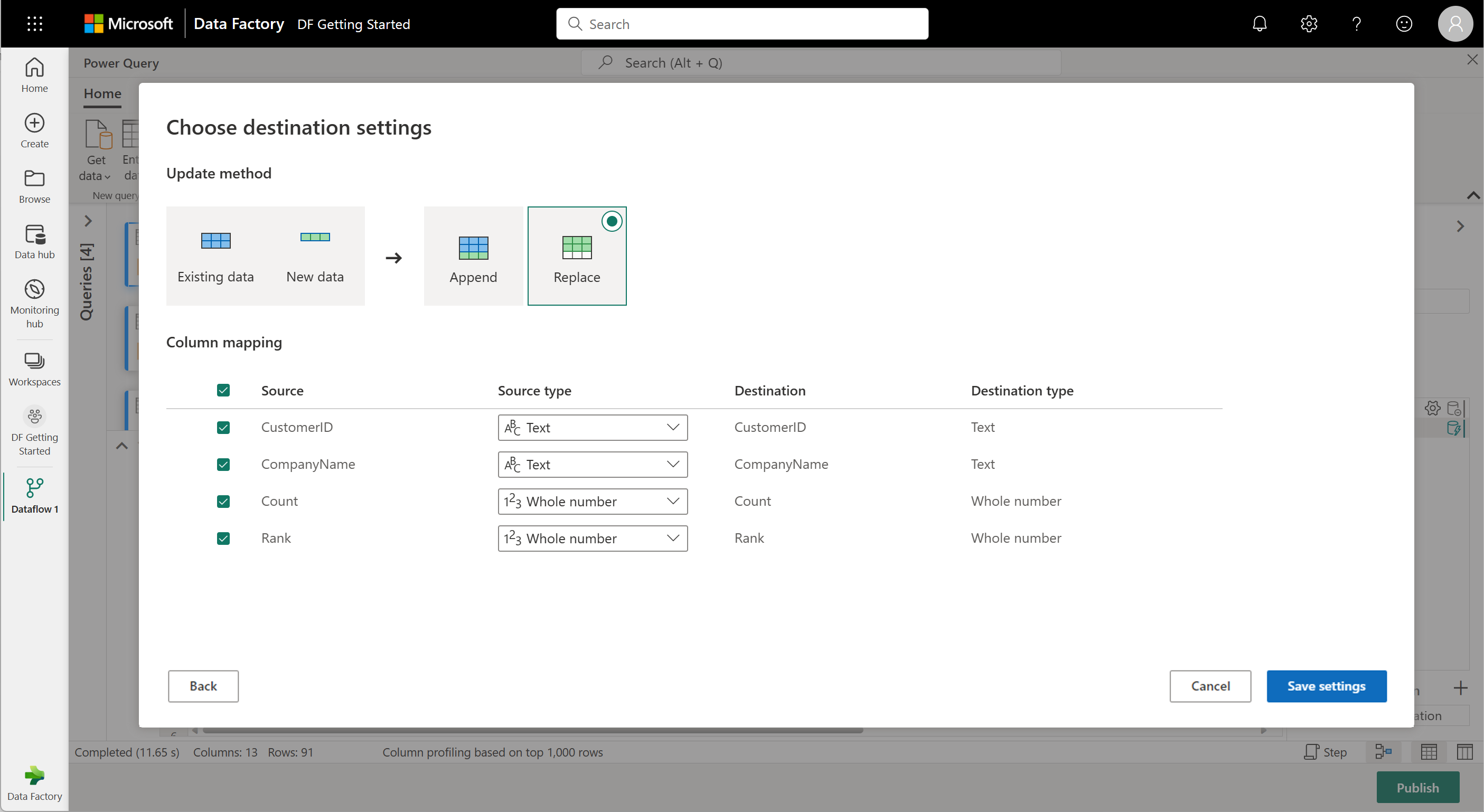
Votre flux de données est maintenant prêt à être publié. Passez en revue les requêtes dans la vue des diagrammes, puis sélectionnez Publier.
Vous êtes de nouveau dans l’espace de travail. Une icône de boucle de rotation en regard du nom de votre flux de données indique que la publication est en cours. Une fois la publication terminée, votre flux de données est prêt à être actualisé.
Important
Lorsque le premier Dataflow Gen2 est créé dans un espace de travail, les éléments lakehouse et entrepôt sont approvisionnés, ainsi que leur point de terminaison d’analytique SQL et leurs modèles sémantiques associés. Ces éléments sont partagés par tous les flux de données de l’espace de travail et sont requis pour que Dataflow Gen2 fonctionne. Ils ne doivent pas être supprimés et ne doivent pas être utilisés directement par les utilisateurs. Les éléments sont un détail d’implémentation de Dataflow Gen2. Les éléments ne sont pas visibles dans l’espace de travail, mais peuvent être accessibles dans d’autres expériences telles que les expériences notebook, point de terminaison d’analytique SQL, lakehouse et entrepôt. Vous pouvez reconnaître les éléments par leur préfixe dans le nom. Le préfixe des éléments est « DataflowsStaging ».
Dans votre espace de travail, sélectionnez l’icône Planifier l’actualisation.

Activez l’actualisation planifiée, sélectionnez Ajouter un autre horaire, puis configurez l’actualisation comme illustré dans la capture d’écran suivante.
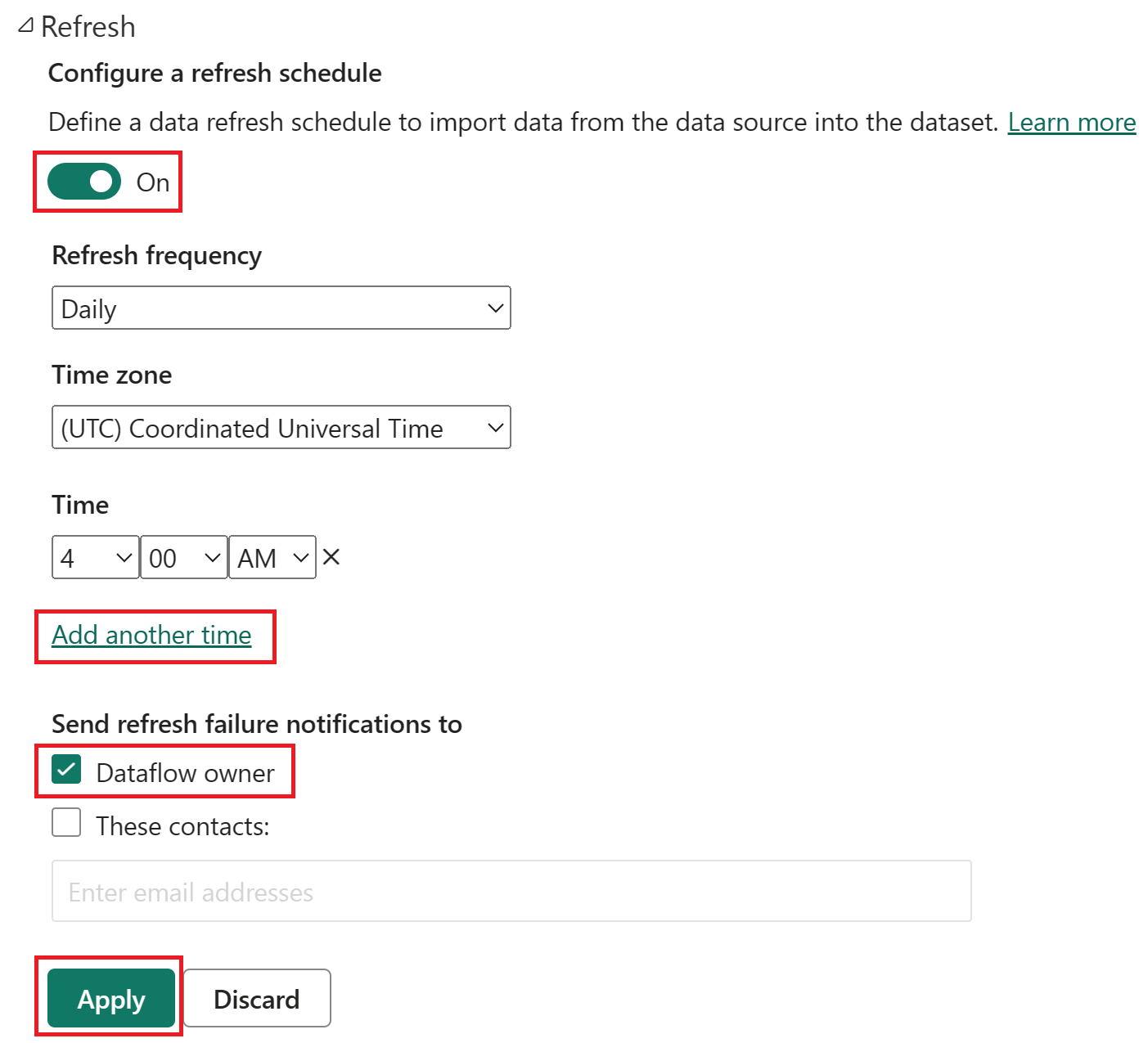
Capture d’écran des options d’actualisation planifiée, avec l’actualisation planifiée activée, la fréquence d’actualisation définie sur Quotidienne, le fuseau horaire défini sur l’heure universelle coordonnée et l’horaire défini sur 4h00. Le bouton activé, la sélection Ajouter un autre horaire, le propriétaire du flux de données et le bouton appliquer sont tous mis en évidence.













Nettoyer les ressources
Si vous ne prévoyez pas de continuer à utiliser ce flux de données, supprimez-le en effectuant les étapes suivantes :
Accédez à votre espace de travail Microsoft Fabric.
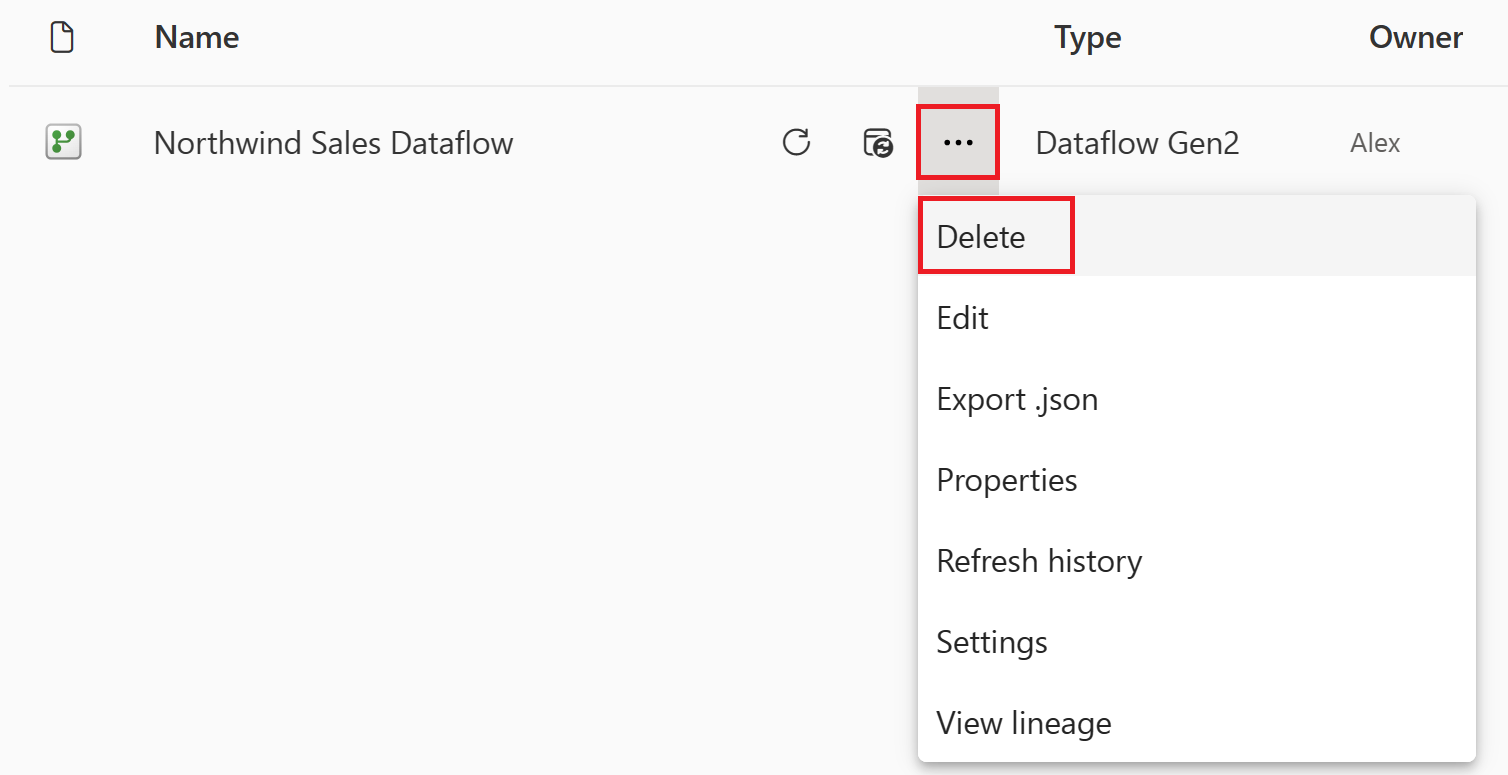
Sélectionnez les ellipses verticales en regard du nom de votre flux de données, puis sélectionnez Supprimer.
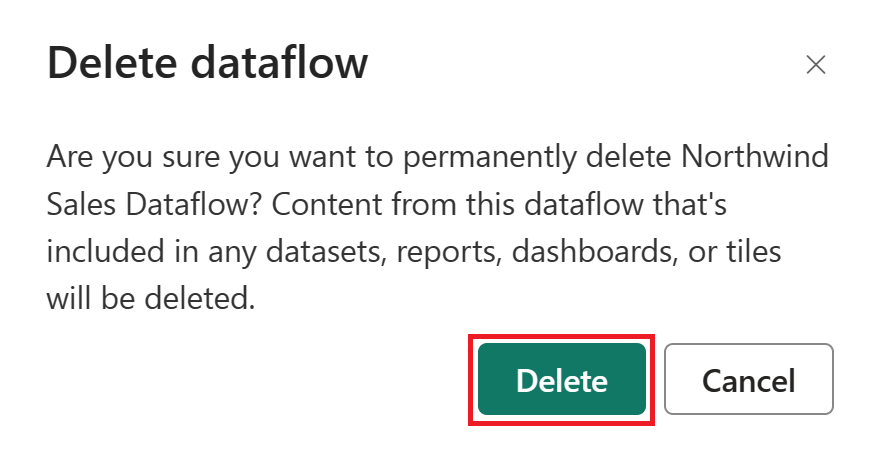
Sélectionnez Supprimer pour confirmer la suppression de votre flux de données.
Contenu connexe
Le flux de données de cet exemple vous montre comment charger et transformer des données dans Flux de données Gen2. Vous avez appris à :
- Créer un Flux de données Gen2.
- Transformer les données.
- Configurez les paramètres de destination pour les données transformées.
- Exécutez et planifiez votre pipeline de données.
Passez à l’article suivant pour découvrir comment créer un pipeline de données.