Azure OpenAI sur vos données
Utilisez cet article pour en savoir plus sur Azure OpenAI sur vos données, qui facilite aux développeurs la connexion, l’ingestion et l’ancrage de leurs données d’entreprise afin de créer rapidement des copilotes personnalisés (préversion). Il améliore la compréhension des utilisateurs, accélère l’achèvement des tâches, améliore l’efficacité opérationnelle et aide à la prise de décision.
Azure OpenAI sur vos données : présentation
Azure OpenAI sur vos données vous permet d’exécuter des modèles d’IA avancés comme GPT-35-Turbo et GPT-4 sur vos propres données d’entreprise sans avoir à entraîner ou à affiner les modèles. Vous pouvez discuter et analyser vos données avec une plus grande précision. Vous pouvez spécifier des sources à l’appui des réponses en fonction des informations les plus récentes disponibles dans vos sources de données désignées. Vous pouvez accéder à Azure OpenAI sur vos données à l’aide d’une API REST, via le SDK ou l’interface web sur le Portail Azure AI Foundry. Vous pouvez également créer une application web qui se connecte à vos données pour activer une solution de conversation améliorée ou la déployer directement en tant que copilote dans le Copilot Studio (préversion).
Développer avec Azure OpenAI sur vos données
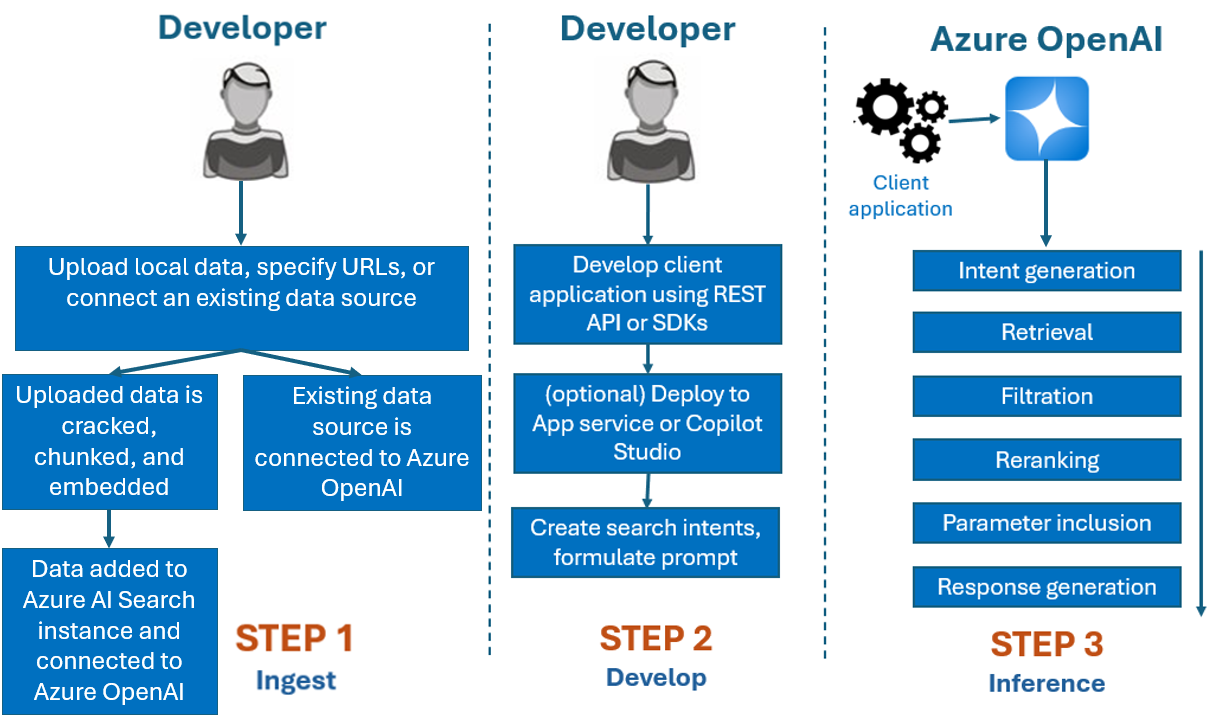
En règle générale, le processus de développement que vous utiliseriez avec Azure OpenAI Sur vos données est le suivant :
Ingestion : chargez des fichiers à l’aide du Portail Azure AI Foundry ou de l’API d’ingestion. Cela permet à vos données d’être craquelées, segmentées et incorporées dans une instance Recherche Azure AI qui peut être utilisée par les modèles Azure OpenAI. Si vous disposez d’une source de données prise en charge existante, vous pouvez également la connecter directement.
Développement : après avoir essayé Azure OpenAI sur vos données, commencez à développer votre application à l’aide de l’API REST et des SDK disponibles, qui sont disponibles dans plusieurs langages. Il créera des invites et des intentions de recherche à transmettre au service Azure OpenAI.
Inférence : une fois votre application déployée dans votre environnement préféré, il enverra des invites à Azure OpenAI, qui effectuera plusieurs étapes avant de retourner une réponse :
Génération d’intention : le service déterminera l’intention de l’invite de l’utilisateur pour déterminer une réponse appropriée.
Récupération : le service récupère les blocs de données disponibles pertinents à partir de la source de données connectée en l’interrogeant. Par exemple, à l’aide d’une recherche sémantique ou vectorielle. Les paramètres tels que la rigueur et le nombre de documents à récupérer sont utilisés pour influencer la récupération.
Filtrage et reclassement : les résultats de recherche de l’étape de récupération sont améliorés en classant et en filtrant les données pour affiner la pertinence.
Génération de réponse : les données résultantes sont envoyées avec d’autres informations telles que le message système au grand modèle de langage (LLM) et la réponse est renvoyée à l’application.
Pour commencer, connectez votre source de données à l’aide du Portail Azure AI Foundry et commencez à poser des questions et à converser sur vos données.
Contrôles d’accès en fonction du rôle Azure (RBAC Azure) pour l’ajout de sources de données
Pour utiliser complètement Azure OpenAI sur vos données, vous devez définir un ou plusieurs rôles RBAC Azure. Pour plus d’informations, consultez Configuration d’Azure OpenAI sur vos données.
Formats de données et types de fichiers
Azure OpenAI sur vos données prend en charge les types de fichiers suivants :
.txt.md.html.docx.pptx.pdf
Il existe une limite de chargement et quelques mises en garde concernant la structure du document et la façon dont elle peut affecter la qualité des réponses du modèle :
Si vous convertissez des données d’un format non pris en charge en un format pris en charge, optimisez la qualité de la réponse du modèle en vous assurant que la conversion :
- N’entraîne pas de perte de données significative.
- N’ajoute pas de bruit inattendu à vos données.
Si vos fichiers ont une mise en forme spéciale, comme des tables et des colonnes ou des points à puces, préparez vos données avec le script de préparation des données disponible sur GitHub.
Pour les documents et les jeux de données avec du texte long, il vous est conseillé d’utiliser le script de préparation des données disponible. Le script segmente les données afin que les réponses du modèle soient plus précises. Ce script prend également en charge les images et fichiers PDF analysés.
Sources de données prises en charge
Vous devez vous connecter à une source de données pour charger vos données. Lorsque vous souhaitez utiliser vos données pour discuter avec un modèle Azure OpenAI, vos données sont segmentées dans un index de recherche afin que les données pertinentes soient trouvées en fonction des requêtes utilisateur.
La base de données vectorielle intégrée dans Azure Cosmos DB for MongoDB basé sur vCore prend en charge l’intégration en mode natif à Azure OpenAI sur vos données.
Pour certaines sources de données, telles que le chargement de fichiers à partir de votre ordinateur local (préversion) ou les données contenues dans un compte de stockage d’objets blob (préversion), Recherche Azure AI est utilisé. Lorsque vous choisissez les sources de données suivantes, vos données sont ingérées dans un index Recherche Azure AI.
| Données ingérées avec la Recherche Azure AI | Description |
|---|---|
| Azure AI Search | Utilisez un index Recherche Azure AI existant avec Azure OpenAI sur vos données. |
| Charger des fichiers (préversion) | Chargez des fichiers à partir de votre ordinateur local à stocker dans une base de données Stockage Blob Azure et ingérés dans Recherche Azure AI. |
| URL/Adresse web (préversion) | Le contenu web des URL est stocké dans Stockage Blob Azure. |
| Stockage Blob Azure (préversion) | Chargez des fichiers à partir du Stockage Blob Azure pour les ingérer dans un index Recherche Azure AI. |

- Azure AI Search
- Base de données vectorielle dans Azure Cosmos DB for MongoDB
- Stockage Blob Azure (préversion)
- Charger des fichiers (préversion)
- URL/Adresse web (préversion)
- Elasticsearch (préversion)
- MongoDB Atlas (préversion)
Vous devriez envisager d’utiliser un index Recherche Azure AI lorsque vous souhaitez :
- Personnaliser le processus de création d’index.
- Réutiliser un index créé auparavant en ingérant des données à partir d’autres sources de données.
Remarque
- Pour pouvoir utiliser un index existant, ce dernier doit avoir au moins un champ pouvant faire l’objet d’une recherche.
- Définissez l’option CORS Autoriser le type d’origine sur
allet l’option Origines autorisées sur*.
Rechercher dans les types
Azure OpenAI sur vos données fournit les types de recherche suivants que vous pouvez utiliser lorsque vous ajoutez votre source de données.
Recherche vectorielle à l’aide de modèles d’incorporation Ada, disponibles dans les régions sélectionnées
Pour activer la recherche vectorielle, vous avez besoin d’un modèle d’incorporation existant déployé dans votre ressource Azure OpenAI. Sélectionnez votre déploiement d’incorporation lors de la connexion de vos données, puis sélectionnez l’un des types de recherche vectorielle sous Gestion des données. Si vous utilisez Recherche Azure AI comme source de données, vérifiez que vous disposez d’une colonne vectorielle dans l’index.
Si vous utilisez votre propre index, vous pouvez personnaliser le mappage de champs lorsque vous ajoutez votre source de données pour définir les champs qui seront mappés lors de la réponse aux questions. Pour personnaliser le mappage de champs, sélectionnez Utiliser le mappage de champs personnalisé dans la page Source de données lors de l’ajout de votre source de données.
Important
- La recherche sémantique est soumise à des tarifs supplémentaires. Vous devez choisir Référence SKU de base ou supérieure pour activer la recherche sémantique ou la recherche vectorielle. Pour plus d’informations, consultez Différences de niveau tarifaire et limites de service.
- Afin d’améliorer la qualité de la récupération des informations et de la réponse du modèle, nous vous recommandons d’activer la recherche sémantique pour les langues de source de données suivantes : anglais, français, espagnol, portugais, italien, allemand, chinois (zh), japonais, coréen, russe et arabe.
| Option de recherche | Type de récupération | Une tarification supplémentaire ? | Avantages |
|---|---|---|---|
| mot clé | Recherche par mot clé | Pas de tarification supplémentaire. | Effectue une analyse et une comparaison rapides et flexibles des requêtes sur des champs de recherche, en utilisant des termes ou des phrases dans n’importe quelle langue prise en charge, avec ou sans opérateurs. |
| sémantique | Recherche sémantique | Une tarification supplémentaire pour l’utilisation de la recherche sémantique. | Améliore la précision et la pertinence des résultats de recherche à l’aide d’un reranker (avec des modèles IA) pour comprendre la signification sémantique des termes de requête et des documents retournés par le ranker de recherche initial |
| vector | Recherche vectorielle | Une Tarification supplémentaire sur votre compte Azure OpenAI suite à l’appel du modèle d’incorporation. | Vous permet de rechercher des documents similaires à une entrée de requête donnée en fonction des incorporations vectorielles du contenu. |
| hybride (vecteur + mot clé) | Un hybride de recherche vectorielle et de recherche par mot clé | Une Tarification supplémentaire sur votre compte Azure OpenAI suite à l’appel du modèle d’incorporation. | Effectue une recherche de similarité sur les champs vectoriels à l’aide d’incorporations vectorielles, tout en prenant en charge l’analyse flexible des requêtes et la recherche en texte intégral sur les champs alphanumériques à l’aide de requêtes de termes. |
| hybride (vecteur + mot clé) + sémantique | Hybride de recherche vectorielle, de recherche sémantique et de recherche par mot clé. | Une Tarification supplémentaire sur votre compte Azure OpenAI en raison de l’appel du modèle d’incorporation, et une tarification supplémentaire pour l’utilisation de la recherche sémantique. | Utilise les incorporations vectorielles, la compréhension du langage et l’analyse des requêtes flexibles pour créer des expériences de recherche enrichies et des applications d’IA génératives capables de gérer des scénarios de récupération d’informations complexes et diversifiés. |
Recherche intelligente
Azure OpenAI sur vos données a activé la recherche intelligente pour vos données. La recherche sémantique est activée par défaut si vous avez à la fois la recherche sémantique et la recherche par mot clé. Si vous avez des modèles d’incorporation, la recherche intelligente par défaut est « hybride + sémantique ».
Contrôle d’accès au niveau du document
Remarque
Le contrôle d’accès au niveau du document est pris en charge lorsque vous sélectionnez Recherche Azure AI comme source de données.
Azure OpenAI sur vos données vous permet de limiter les documents qui peuvent être utilisés dans les réponses pour différents utilisateurs avec des filtres de sécurité Recherche Azure AI. Quand vous activez l’accès au niveau des documents, les résultats de la recherche retournés par Recherche Azure AI et qui sont utilisés pour générer une réponse sont tronqués en fonction de l’appartenance de l’utilisateur au groupe Microsoft Entra. Vous pouvez activer l’accès au niveau des documents seulement sur les index Recherche Azure AI existants. Pour plus d’informations, consultez Configuration du réseau et de l’accès d’Azure OpenAI sur vos données.
Mappage de champs d’index
Si vous utilisez votre propre index, vous êtes invité sur le Portail Azure AI Foundry à définir les champs que vous souhaitez mapper pour répondre aux questions lorsque vous ajoutez votre source de données. Vous pouvez fournir plusieurs champs pour les données de contenu. Vous devez inclure tous les champs qui ont du texte relatif à votre cas d’usage.

Dans cet exemple, les champs mappés à Données de contenu et Titre fournissent des informations au modèle pour répondre aux questions. Titre est également utilisé pour titrer le texte de citation. Le champ mappé à Nom de fichier génère les noms de citation dans la réponse.
Le mappage correct de ces champs permet de garantir une meilleure qualité de réponse et de citation du modèle. Vous pouvez également configurer cela dans l’API à l’aide du paramètre fieldsMapping.
Filtre de recherche (API)
Si vous souhaitez implémenter des critères basés sur des valeurs supplémentaires pour l’exécution de requête, vous pouvez configurer un filtre de recherche à l’aide du paramètre filter dans l’API REST.
Comment les données sont ingérées dans la recherche Azure AI
À compter de septembre 2024, les API d’ingestion sont passées à la vectorisation intégrée. Cette mise à jour ne modifie pas les contrats d’API existants. La vectorisation intégrée, une nouvelle offre de Recherche Azure AI, utilise des compétences prédéfinies pour la segmentation et l’incorporation des données d’entrée. Azure OpenAI sur votre service d’ingestion des données n’utilise plus de compétences personnalisées. Après la migration vers la vectorisation intégrée, le processus d’ingestion a subi certaines modifications et, par conséquent, seules les ressources suivantes sont créées :
{job-id}-index{job-id}-indexer, si une planification horaire ou quotidienne est spécifiée, sinon, l’indexeur est nettoyé à la fin du processus d’ingestion.{job-id}-datasource
Le conteneur de blocs n’est plus disponible, car cette fonctionnalité est désormais gérée par Recherche Azure AI.
Connexion de données
Vous devez sélectionner la façon dont vous souhaitez authentifier la connexion à partir d’Azure OpenAI, de Recherche Azure AI et de Stockage Blob Azure. Vous pouvez choisir Identité managée affectée par le système ou Clé API. En sélectionnant Clé API comme type d’authentification, le système remplit automatiquement la clé API pour vous permettre de vous connecter à vos ressources Recherche Azure AI, Azure OpenAI et Stockage Blob Azure. En sélectionnant Identité managée affectée par le système, l’authentification est basée sur l’attribution de rôle dont vous disposez. L’option Identité managée affectée par le système est sélectionnée par défaut pour des raisons de sécurité.

Une fois le bouton Suivant sélectionné, votre configuration est automatiquement validée pour utiliser la méthode d’authentification sélectionnée. Si vous rencontrez une erreur, consultez l’article sur les attributions de rôles pour mettre à jour votre configuration.
Une fois la configuration corrigée, sélectionnez à nouveau Suivant pour valider et continuer. Les utilisateurs d’API peuvent également configurer l’authentification avec une identité managée et des clés API affectées.










Déployer sur un copilote (préversion), une application Teams (préversion) ou une application web
Une fois que vous avez connecté Azure OpenAI à vos données, vous pouvez le déployer à l’aide du bouton Déployer sur du Portail Azure AI Foundry.

Cela vous permet de disposer de plusieurs options pour déployer votre solution.
Vous pouvez effectuer un déploiement sur un copilote dans Copilot Studio (préversion) directement à partir du Portail Azure AI Foundry, ce qui vous permet d’apporter des expériences conversationnelles à divers canaux tels que Microsoft Teams, sites web, Dynamics 365 et d’autres canaux Azure Bot Service. Le même locataire doit être utilisé dans le service Azure OpenAI et Copilot Studio (préversion). Si vous souhaitez obtenir plus d’informations, consultez Utiliser une connexion à Azure OpenAI sur vos données.
Remarque
Le déploiement sur un copilote dans Copilot Studio (préversion) n’est disponible que dans les régions américaines.
Configurer l’accès et la mise en réseau pour Azure OpenAI sur vos données
Vous pouvez utiliser Azure OpenAI sur vos données et protéger les données et les ressources avec le contrôle d’accès en fonction du rôle Microsoft Entra ID, des réseaux virtuels et des points de terminaison privés. Vous pouvez aussi limiter les documents qui peuvent être utilisés dans les réponses pour différents utilisateurs avec des filtres de sécurité Recherche Azure AI. Consultez Configuration du réseau et de l’accès d’Azure OpenAI sur vos données.
Bonnes pratiques
Utilisez les sections suivantes pour apprendre à améliorer la qualité des réponses données par le modèle.
Paramètres d’ingestion
Lorsque vos données sont ingérées dans Recherche Azure AI, vous pouvez modifier les paramètres supplémentaires suivants dans le studio ou l’API d’ingestion.
Taille de bloc (préversion)
Azure OpenAI sur vos données traite vos documents en les divisant en blocs avant de les ingérer. La taille de bloc est la taille maximale en termes de nombre de jetons de n’importe quel bloc dans l’index de recherche. Ensemble, la taille de bloc et le nombre de documents récupérés contrôlent la quantité d’informations (jetons) figurant dans le prompt envoyé au modèle. En général, pour obtenir le nombre total de jetons envoyés au modèle, multipliez la taille de bloc par le nombre de documents récupérés.
Définition de la taille de bloc pour votre cas d’usage
La taille de bloc par défaut est de 1 024 jetons. Toutefois, compte tenu du caractère unique de vos données, il se peut qu’une taille de bloc différente (256, 512 ou 1 536 jetons, par exemple) soit plus efficace.
L’ajustement de la taille de bloc peut améliorer les performances de votre chatbot. Bien qu'il faille procéder par tâtonnements pour trouver la taille optimale du bloc, commencez par tenir compte de la nature de votre ensemble de données. Une taille de bloc plus petite est généralement préférable pour les jeux de données contenant des faits directs et moins de contexte, tandis qu’une taille de bloc plus grande peut être bénéfique pour des informations plus contextuelles, bien qu’elle puisse affecter les performances de récupération.
Une petite taille de bloc, comme 256, produit des segments plus granulaires. Cette taille signifie également que le modèle utilise moins de jetons pour générer sa sortie (sauf si le nombre de documents récupérés est très élevé), ce qui peut coûter moins cher. Par ailleurs, avec des blocs plus petits, le modèle n’a pas besoin de traiter et d’interpréter de longues sections de texte, réduisant ainsi le bruit et la distraction. Cette granularité et cette concentration posent toutefois un problème potentiel. Les informations importantes peuvent ne pas figurer parmi les principaux blocs récupérés, en particulier si le nombre de documents récupérés est défini sur une valeur faible comme 3.
Conseil
N’oubliez pas que la modification de la taille de bloc nécessite la réingestion de vos documents. Il est donc utile d’ajuster d’abord les paramètres du runtime comme la rigueur et le nombre de documents récupérés. Envisagez de modifier la taille de bloc si vous n’obtenez toujours pas les résultats souhaités :
- Si vous rencontrez un nombre élevé de réponses de type « Je ne sais pas » pour des questions dont les réponses doivent figurer dans vos documents, envisagez de réduire la taille de bloc à 256 ou 512 pour améliorer la granularité.
- Si le chatbot fournit des détails corrects mais que d’autres sont manquants, ce qui apparaît clairement dans les citations, vous pouvez essayer d’augmenter la taille de bloc à 1 536 pour capturer des informations plus contextuelles.
Paramètres de runtime
Vous pouvez modifier les paramètres supplémentaires suivants dans la section Paramètres de données du Portail Azure AI Foundry et dans l’API. Vous n’avez pas besoin de ré-ingérer vos données quand vous mettez à jour ces paramètres.
| Nom du paramètre | Description |
|---|---|
| Limiter les réponses à vos données | Cet indicateur configure l'approche du robot conversationnel pour traiter les requêtes qui ne sont pas liées à la source de données ou lorsque les documents de recherche sont insuffisants pour obtenir une réponse complète. Lorsque ce paramètre est désactivé, le modèle complète ses réponses avec ses propres connaissances en plus de vos documents. Lorsque ce paramètre est activé, le modèle tente de ne s'appuyer que sur vos documents pour répondre. Il s’agit du paramètre inScope dans l’API, qui est défini sur true par défaut. |
| Documents récupérés | Ce paramètre est un nombre entier qui peut être fixé à 3, 5, 10 ou 20. Il contrôle le nombre de morceaux de documents fournis au modèle de langage étendu pour formuler la réponse finale. Par défaut, elle a la valeur 5. Le processus de recherche peut être bruyant et parfois, en raison du découpage en morceaux, les informations pertinentes peuvent être réparties sur plusieurs morceaux dans l'index de recherche. La sélection d'un nombre top-K, comme 5, garantit que le modèle peut extraire des informations pertinentes, malgré les limites inhérentes à la recherche et au découpage. Cependant, si le nombre est trop élevé, le modèle risque d’être faussé. En outre, le nombre maximal de documents pouvant être utilisés efficacement dépend de la version du modèle, car chaque version a une taille de contexte et une capacité de traitement des documents différentes. Si vous constatez que les réponses manquent d’un contexte important, essayez d’augmenter ce paramètre. Il s’agit du paramètre topNDocuments dans l’API, qui est défini sur 5 par défaut. |
| Sévérité | Détermine l'agressivité du système dans le filtrage des documents de recherche sur la base de leurs scores de similarité. Le système interroge Azure Search ou d'autres magasins de documents, puis décide quels documents fournir à de grands modèles de langage comme ChatGPT. Le filtrage des documents non pertinents peut améliorer considérablement les performances du robot conversationnel de bout en bout. Certains documents sont exclus des résultats top-K s'ils ont de faibles scores de similarité avant d'être transmis au modèle. Ceci est contrôlé par une valeur entière comprise entre 1 et 5. En fixant cette valeur à 1, le système filtrera au minimum les documents sur la base de la similarité de recherche avec la requête de l'utilisateur. À l'inverse, un paramètre de 5 indique que le système filtrera agressivement les documents, en appliquant un seuil de similarité très élevé. Si vous constatez que le robot conversationnel omet des informations pertinentes, diminuez la rigueur du filtre (rapprochez la valeur de 1) afin d'inclure davantage de documents. Inversement, si des documents non pertinents distraient les réponses, augmentez le seuil (rapprochez la valeur de 5). Il s’agit du paramètre strictness dans l’API, qui est défini sur 3 par défaut. |
Références non citées
Il est possible que le modèle retourne "TYPE":"UNCITED_REFERENCE" au lieu de "TYPE":CONTENT dans l’API pour les documents qui sont récupérés à partir de la source de données, mais qui ne sont pas inclus dans la citation. Cela peut être utile pour le débogage, et vous pouvez contrôler ce comportement en modifiant les paramètres de runtime Rigueur et Documents récupérés décrits ci-dessus.
Message système
Vous pouvez définir un message système pour diriger la réponse du modèle lors de l’utilisation d’Azure OpenAI sur vos données. Ce message vous permet de personnaliser vos réponses en plus du modèle de génération augmentée de récupération (RAG) qu’Azure OpenAI sur vos données utilise. Le message système est utilisé en plus d’une invite de base interne pour fournir l’expérience. Pour ce faire, nous tronquons le message système après un nombre de jetons spécifique pour nous assurer que le modèle peut répondre aux questions à l’aide de vos données. Si vous définissez un comportement supplémentaire en plus de l’expérience par défaut, vérifiez que votre invite système est détaillée et explique la personnalisation exacte attendue.
Une fois que vous avez sélectionné et ajouté votre jeu de données, vous pouvez utiliser la section Message système du Portail Azure AI Foundry ou le paramètre role_information dans l’API.

Modèles d’utilisation potentiels
Définir un rôle
Vous pouvez définir un rôle que vous souhaitez pour votre assistant. Par exemple, si vous créez un bot de support, vous pouvez ajouter « Vous êtes un assistant expert de support aux incidents qui aide les utilisateurs à résoudre de nouveaux problèmes. ».
Définir le type de données récupérées
Vous pouvez également ajouter la nature des données que vous fournissez à l’assistant.
- Définissez la rubrique ou l’étendue de votre jeu de données, comme « rapport financier », « article universitaire » ou « rapport d’incident ». Par exemple, pour du support technique, vous pouvez ajouter « Vous répondez aux requêtes en utilisant des informations provenant d’incidents similaires dans les documents extraits. ».
- Si vos données ont certaines caractéristiques, vous pouvez ajouter ces détails au message système. Par exemple, si vos documents sont en japonais, vous pouvez ajouter « Vous extrayez des documents en japonais, et vous devez les lire attentivement en japonais et répondre en japonais. ».
- Si vos documents incluent des données structurées telles que des tables à partir d’un rapport financier, vous pouvez également ajouter ce fait à l’invite système. Par exemple, si vos données ont des tables, vous pouvez ajouter « Vous recevez des données sous forme de tables concernant des résultats financiers et vous devez lire la table ligne par ligne pour effectuer des calculs afin de répondre aux questions des utilisateurs. ».
Définir le style de sortie
Vous pouvez également modifier la sortie du modèle en définissant un message système. Par exemple, si vous souhaitez vous assurer que l’Assistant répond en français, vous pouvez ajouter une invite telle que « Vous êtes un assistant IA qui aide les utilisateurs qui comprennent le français à trouver des informations. Les questions utilisateur peuvent être en anglais ou en français. Lisez attentivement les documents récupérés et répondez-leur en français. Traduisez les connaissances des documents en français pour que toutes les réponses soient en français. ».
Confirmer le comportement critique
Azure OpenAI sur vos données fonctionne en envoyant des instructions à un modèle de langage volumineux sous la forme d’invites pour répondre aux requêtes utilisateur à l’aide de vos données. Si un certain comportement est critique pour l’application, vous pouvez répéter le comportement dans le message système pour augmenter sa précision. Par exemple, pour guider le modèle à répondre uniquement à partir de documents, vous pouvez ajouter « Veuillez répondre à l’aide de documents récupérés uniquement et sans utiliser vos connaissances. Générez des citations des documents récupérés à l’appui de chaque affirmation contenue dans votre réponse. S’il est impossible de répondre à la question de l’utilisateur à l’aide de documents récupérés, expliquez le raisonnement par lequel les documents sont pertinents pour les requêtes utilisateur. Dans tous les cas, ne répondez pas en utilisant vos propres connaissances. ».
Astuces d’ingénierie d’invite
L’ingénierie d’invite recèle de nombreuses astuces pour essayer d’améliorer la sortie. L’un des exemples est l’invite à la réflexion dans laquelle vous pouvez ajouter « Considérons pas à pas les informations des documents récupérés pour répondre aux requêtes des utilisateurs. Extrayez les connaissances pertinentes pour les requêtes utilisateur des documents étape par étape et formez une réponse selon une approche ascendante à partir des informations extraites des documents pertinents. ».
Remarque
Le message système est utilisé pour modifier la façon dont l’assistant GPT répond à une question utilisateur en fonction de la documentation récupérée. Cela n’affecte pas le processus de récupération. Si vous souhaitez fournir des instructions pour le processus de récupération, il est préférable de les inclure dans les questions. Le message système est uniquement une aide. Le modèle peut ne pas adhérer à toutes les instructions spécifiées, car il a été amorcé avec certains comportements tels que l’objectivité et l’évitement d’instructions controversées. Un comportement inattendu peut se produire si le message système est en contradiction avec ces comportements.
Temps de réponse maximal
Définissez une limite pour le nombre de jetons par réponse de modèle. La limite supérieure d’Azure OpenAI sur vos données est de 1 500. Cela équivaut à définir le paramètre max_tokens dans l’API.
Limiter les réponses à vos données
Cette option encourage le modèle à répondre à l’aide de vos données uniquement et est sélectionnée par défaut. Si vous désélectionnez cette option, le modèle peut appliquer plus facilement ses connaissances internes pour répondre. Déterminez la sélection correcte en fonction de votre cas d’usage et de votre scénario.
Interaction avec le modèle
Utilisez les pratiques suivantes pour obtenir de meilleurs résultats lors de la conversation avec le modèle.
Historique des conversations
- Avant de commencer une nouvelle conversation (ou de poser une question qui n’est pas liée aux précédentes), effacez l’historique des conversations.
- Vous pouvez vous attendre à obtenir des réponses différentes pour la même question entre le premier tour conversationnel et les tours suivants, car l’historique des conversations modifie l’état actuel du modèle. Si vous recevez des réponses incorrectes, signalez-le comme un bogue de qualité.
Réponse du modèle
Si vous n’êtes pas satisfait de la réponse du modèle pour une question spécifique, essayez de rendre la question plus spécifique ou plus générique pour voir comment le modèle répond et reformuler votre question en conséquence.
Il a été démontré que les invites en chaîne de pensée étaient efficaces pour que le modèle produise les sorties souhaitées pour des questions/tâches complexes.
Longueur de la question
Évitez de poser de longues questions et décomposez-les en plusieurs questions si possible. Les modèles GPT ont des limites quant au nombre de jetons qu’ils peuvent accepter. Les limites de jeton sont comptabilisées pour : la question de l’utilisateur, le message système, les documents de recherche récupérés (blocs), les invites internes, l’historique des conversations (le cas échéant) et la réponse. Si la question dépasse la limite des jetons, elle est tronquée.
Prise en charge multilingue
Actuellement, la recherche par mot clé et la recherche sémantique dans les requêtes de support Azure OpenAI sur vos données sont dans la même langue que les données de l’index. Par exemple, si vos données sont en japonais, les requêtes d’entrée doivent être en japonais. Pour la récupération de documents multilingues, nous vous recommandons de créer l’index avec la recherche vectorielle activée.
Pour améliorer la qualité de la récupération des informations et de la réponse du modèle, nous vous recommandons d’activer la recherche sémantique pour les langues suivantes : anglais, Français, espagnol, portugais, italien, allemand, chinois (Zh), japonais, coréen, russe, arabe
Nous vous recommandons d’utiliser un message système pour informer le modèle que vos données sont dans une autre langue. Par exemple :
*« *Vous êtes un assistant IA conçu pour aider les utilisateurs à extraire des informations à partir de documents japonais récupérés. Examinez attentivement les documents japonais avant de formuler une réponse. La requête de l’utilisateur sera en japonais, et vous devez également répondre en japonais. »
Si vous avez des documents dans plusieurs langues, nous vous recommandons de créer un index pour chaque langue et de les connecter séparément à Azure OpenAI.
Diffusion de données
Vous pouvez envoyer une demande de diffusion en continu à l’aide du paramètre stream, ce qui permet d’envoyer et de recevoir des données de manière incrémentielle, sans attendre l’intégralité de la réponse de l’API. Cela peut améliorer les performances et l’expérience utilisateur, en particulier pour les données volumineuses ou dynamiques.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Historique des conversations pour de meilleurs résultats
Lorsque vous discutez avec un modèle, fournir un historique de la conversation permet au modèle de retourner des résultats de meilleure qualité. Vous n’avez pas besoin d’inclure la propriété context des messages d’assistant dans vos requêtes d’API pour une meilleure qualité de réponse. Pour obtenir des exemples, consultez la documentation de référence sur les API.
Appel de fonction
Certains modèles Azure OpenAI vous permettent de définir des paramètres tools et tool_choice pour activer l’appel de fonction. Vous pouvez configurer l’appel de fonction via l’API REST /chat/completions. Si tools et les sources de données figurent dans la requête, la stratégie suivante est appliquée.
- Si
tool_choiceestnone, les outils sont ignorés et seules les sources de données sont utilisées pour générer la réponse. - Sinon, si
tool_choicen’est pas spécifié ou s’il est défini surautoou un objet, les sources de données sont ignorées et la réponse contient le nom des fonctions sélectionnées et les arguments (le cas échéant). Même si le modèle décide qu’aucune fonction n’est sélectionnée, les sources de données sont toujours ignorées.
Si la stratégie ci-dessus ne répond pas à vos besoins, envisagez d’autres options (par exemple, un flux d’invite ou l’API Assistants).
Estimation de l’utilisation des jetons pour Azure OpenAI sur vos données
Azure OpenAI sur votre génération augmentée d’extraction (RAG) de données est un service qui tire parti à la fois d’un service de recherche (comme Recherche Azure AI) et de génération (modèles Azure OpenAI) pour permettre aux utilisateurs d’obtenir des réponses à leurs questions en fonction des données fournies.
Dans le cadre de ce pipeline RAG, il existe trois étapes à un niveau élevé :
Reformulez la requête utilisateur dans une liste d’intentions de recherche. Pour ce faire, effectuez un appel au modèle avec une invite qui inclut des instructions, la question de l’utilisateur et l’historique des conversations. Nous allons appeler ceci une invite d’intention.
Pour chaque intention, plusieurs blocs de document sont récupérés à partir du service de recherche. Après avoir filtré les blocs non pertinents en fonction du seuil spécifié par l’utilisateur de la rigueur et de la reclassement/agrégation des blocs en fonction de la logique interne, le nombre spécifié par l’utilisateur de blocs de document est choisi.
Ces blocs de document, ainsi que la question utilisateur, l’historique des conversations, les informations de rôle et les instructions sont envoyées au modèle pour générer la réponse finale du modèle. Appelons ceci l’invite de génération.
Au total, il existe deux appels effectués au modèle :
Pour le traitement de l’intention : l’estimation du jeton pour le prompt d’intention inclut les estimations pour la question de l’utilisateur, l’historique des conversations et les instructions envoyées au modèle pour la génération d’intention.
Pour générer la réponse : l’estimation du jeton pour le prompt de génération inclut les estimations pour la question de l’utilisateur, l’historique des conversations, la liste récupérée des blocs de documents, les informations de rôle et les instructions envoyées à celui-ci pour la génération.
Les jetons de sortie générés par le modèle (à la fois les intentions et la réponse) doivent être pris en compte pour l’estimation totale des jetons. La somme des quatre colonnes ci-dessous donne les jetons totaux moyens utilisés pour générer une réponse.
| Modèle | Nombre de jetons d’invite de génération | Nombre de jetons d’invite d’intentions | Nombre de jetons de réponse | Nombre de jetons d’intention |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Les nombres ci-dessus sont basés sur des tests sur un jeu de données avec :
- 191 conversations
- 250 questions
- 10 jetons moyens par question
- 4 tours conversationnels par conversation en moyenne
Et les paramètres de suivants.
| Paramètre | Valeur |
|---|---|
| Nombre de documents récupérés | 5 |
| Sévérité | 3 |
| Taille de bloc | 1 024 |
| Limiter les réponses aux données ingérées ? | True |
Ces estimations varient en fonction des valeurs définies pour les paramètres ci-dessus. Par exemple, si le nombre de documents récupérés est défini sur 10 et que la rigueur est définie sur 1, le nombre de jetons augmente. Si les réponses retournées ne sont pas limitées aux données ingérées, il y a moins d’instructions données au modèle et le nombre de jetons tombe en panne.
Les estimations dépendent également de la nature des documents et des questions posées. Par exemple, si les questions sont ouvertes, les réponses sont susceptibles d’être plus longues. De même, un message système plus long contribue à une invite plus longue qui consomme plus de jetons et si l’historique des conversations est long, l’invite sera plus longue.
| Modèle | Nombre maximal de jetons pour le message système |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1 000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
Le tableau ci-dessus montre le nombre maximal de jetons qui peuvent être utilisés pour le message système. Pour afficher les jetons maximum de la réponse du modèle, consultez l’article des modèles. En outre, les éléments suivants consomment également des jetons :
Invite de métadonnées : si vous limitez les réponses du modèle au contenu de données de base (
inScope=Truedans l’API), le nombre maximal de jetons est supérieur. Sinon (par exemple, siinScope=False) la valeur maximale est inférieure. Ce nombre varie en fonction de la longueur du jeton de la question de l’utilisateur et de l’historique des conversations. Cette estimation inclut l’invite de base et les invites de réécriture de requête pour la récupération.Question de l’utilisateur et historique : variables mais limités à 2 000 jetons.
Documents récupérés (blocs) : le nombre de jetons utilisés par les blocs de documents récupérés dépend de plusieurs facteurs. La limite supérieure est le nombre de blocs de documents récupérés multiplié par la taille de bloc. Toutefois, elle est tronquée en fonction des jetons disponibles pour le modèle spécifique utilisé après avoir compté le reste des champs.
20 % des jetons disponibles sont réservés à la réponse du modèle. Les 80 % restants des jetons disponibles incluent la méta-invite, la question de l’utilisateur et l’historique des conversations, ainsi que le message système. Le budget de jetons restant est utilisé par les blocs de documents récupérés.
Pour calculer le nombre de jetons consommés par votre entrée (par exemple, votre question, les informations de message/rôle système), utilisez l’exemple de code suivant.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Dépannage
Pour résoudre les problèmes liés aux opérations ayant échoué, recherchez toujours les erreurs ou les avertissements spécifiés dans la réponse de l’API ou sur le Portail Azure AI Foundry. Voici quelques messages d’erreur et avertissements courants :
Échec des travaux d’ingestion
Problème de limitation de quota
Impossible de créer un index portant le nom X dans le service Y. Le quota d’index a été dépassé pour ce service. Vous devez d’abord supprimer les index inutilisés, ajouter un délai entre les demandes de création d’index ou mettre à niveau le service pour augmenter les limites.
Le quota d’indexeur standard de X a été dépassé pour ce service. Vous disposez actuellement de X indexeurs standard. Vous devez d’abord supprimer les indexeurs inutilisés, modifier l’indexeur « executionMode » ou mettre à niveau le service pour augmenter les limites.
Résolution :
Passez à un niveau tarifaire supérieur ou supprimez les ressources inutilisées.
Problèmes de délai d’attente de prétraitement
Impossible d’exécuter la compétence en raison de l’échec de la requête de l’API web
Impossible d’exécuter la compétence parce que la réponse concernant la compétence de l’API web n’est pas valide
Résolution :
Décomposez les documents d’entrée en documents plus petits et réessayez.
Problèmes d’autorisations
Cette requête n’est pas autorisée à effectuer cette opération
Résolution :
Cela signifie que le compte de stockage n'est pas accessible avec les informations d’identification données. Dans ce cas, passez en revue les informations d’identification du compte de stockage transmises à l’API et vérifiez que le compte de stockage n’est pas masqué derrière un point de terminaison privé (si un point de terminaison privé n’est pas configuré pour cette ressource).
Erreurs 503 lors de l’envoi de requêtes avec Recherche Azure AI
Chaque message utilisateur peut se traduire par plusieurs requêtes de recherche qui sont toutes envoyées en parallèle à la ressource de recherche. Cela peut aboutir à un comportement de limitation lorsque le nombre de réplicas et de partitions de recherche est faible. Le nombre maximal de requêtes par seconde qui peuvent être prises en charge par une seule partition et un seul réplica peut être insuffisant. Dans ce cas, envisagez d’augmenter vos réplicas et partitions ou d’ajouter une logique de veille/nouvelle tentative dans votre application. Pour plus d’informations, consultez la documentation de Recherche Azure AI.
Disponibilité régionale et prise en charge du modèle
| Région | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Australie Est | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Est du Canada | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| USA Est | ✅ | ✅ | ✅ | |||||
| USA Est 2 | ✅ | ✅ | ✅ | ✅ | ||||
| France Centre | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Japon Est | ✅ | |||||||
| Centre-Nord des États-Unis | ✅ | ✅ | ✅ | |||||
| Norvège Est | ✅ | ✅ | ||||||
| États-Unis - partie centrale méridionale | ✅ | ✅ | ||||||
| Inde Sud | ✅ | ✅ | ||||||
| Suède Centre | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Suisse Nord | ✅ | ✅ | ✅ | |||||
| Sud du Royaume-Uni | ✅ | ✅ | ✅ | ✅ | ||||
| USA Ouest | ✅ | ✅ | ✅ |
**Il s’agit d’une implémentation au format texte uniquement.
Si votre ressource Azure OpenAI se trouve dans une autre région, vous ne pourrez pas utiliser Azure OpenAI sur vos données.