Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Cet article explique comment utiliser l’activité de copie dans les pipelines Azure Data Factory et Synapse Analytics pour copier des données à partir d’un Amazon Redshift. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Important
Le connecteur Amazon Redshift version 2.0 offre une prise en charge native d’Amazon Redshift améliorée. Si vous utilisez le connecteur Amazon Redshift version 1.0 dans votre solution, mettez à niveau le connecteur Amazon Redshift comme version 1.0 est à la fin de la phase de support. Votre pipeline échoue après le 30 avril 2026. Pour plus de détails sur les différences entre la version 2.0 et la version 1.0, reportez-vous à cette section.
Fonctionnalités prises en charge
Ce connecteur Amazon Redshift est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | (1) (2) |
| Activité de recherche | (1) (2) |
(1) Moteur d'intégration Azure (2) Moteur d'intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Le service fournit un pilote intégré pour activer la connectivité. Par conséquent, vous n’avez pas besoin d’installer manuellement un pilote.
Le connecteur Amazon Redshift permet de récupérer des données à partir de Redshift en utilisant soit des requêtes, soit la prise en charge intégrée de Redshift UNLOAD.
Le connecteur prend en charge les versions Windows de ce article.
Conseil
Pour obtenir de meilleures performances lors de la copie de grandes quantités de données à partir de Redshift, utilisez le mécanisme Redshift intégré UNLOAD via Amazon S3. Consultez la section Utiliser UNLOAD pour copier des données à partir d’Amazon Redshift pour plus d’informations.
Prérequis
Si vous copiez des données dans un magasin de données local à l’aide de Integration Runtime hébergé, accordez Integration Runtime (utilisez l’adresse IP de l’ordinateur) l’accès au cluster Amazon Redshift. Pour davantage d’instructions, consultez la rubrique Authorize access to the cluster (Autoriser l’accès au cluster). Pour la version 2.0, votre version du runtime d’intégration auto-hébergée doit être 5.61 ou ultérieure.
Si vous copiez des données dans un magasin de données Azure, consultez les plages d’adresses IP du centre de données Azure pour connaître les plages des adresses IP de calcul et SQL utilisées par les centres de données Azure.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser le Azure Integration Runtime. Si l’accès est limité aux adresses IP approuvées dans les règles de pare-feu, vous pouvez ajouter adresses IP d'Azure Integration Runtime à la liste autorisée.
Vous pouvez également utiliser la fonctionnalité runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Prise en main
Pour effectuer l’activité de copie avec un pipeline, vous pouvez utiliser l’un des outils ou kits sdk suivants :
- Outil Copier des données
- portail Azure
- Kit de développement logiciel (SDK) .NET
- sdk Python
- Azure PowerShell
- REST API
- modèle Azure Resource Manager
Créer un service lié à Amazon Redshift à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Amazon Redshift dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, puis sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Amazon et sélectionnez le connecteur Amazon Redshift.
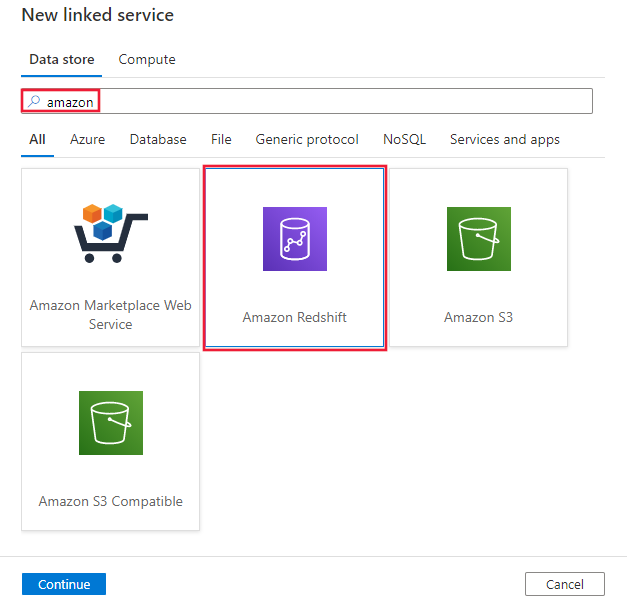
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
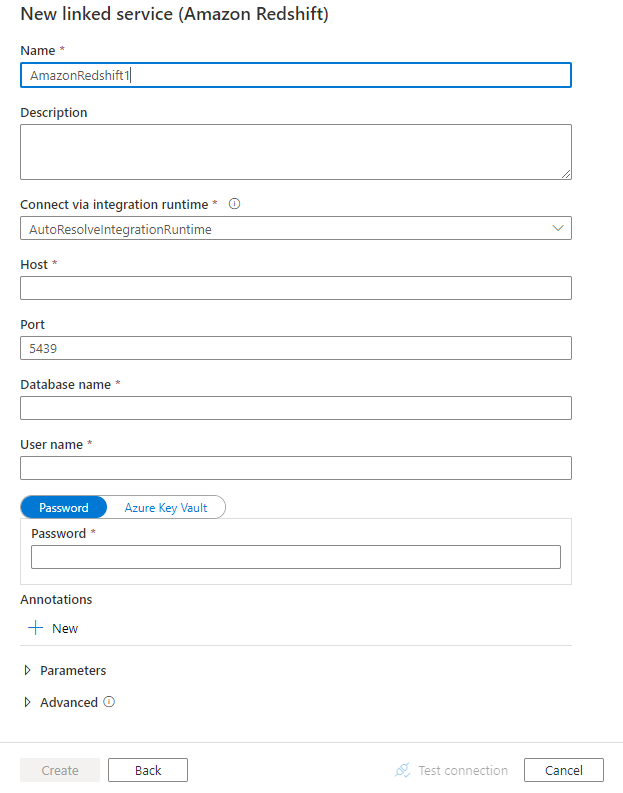
Détails de configuration du connecteur
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques du connecteur Amazon Redshift.
Propriétés du service lié
Les propriétés prises en charge pour le service lié Amazon Redshift sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonRedshift | Oui |
| version | Version que vous spécifiez. | Oui pour la version 2.0. |
| serveur | Nom d’hôte ou adresse IP du serveur Amazon Redshift. | Oui |
| port | Le numéro du port TCP utilisé par le serveur Amazon Redshift pour écouter les connexions clientes. | Non, la valeur par défaut est 5439 |
| base de données | Nom de la base de données Amazon Redshift. | Oui |
| nom d'utilisateur | Nom d’utilisateur ayant accès à la base de données. | Oui |
| mot de passe | Mot de passe du compte d’utilisateur. Marquez ce champ en tant que SecureString pour le stocker en toute sécurité, ou reference un secret stocké dans Azure Key Vault. | Oui |
| sslmode | Mode de vérification du certificat SSL à utiliser lors de la connexion à Amazon Redshift. Cette propriété est uniquement prise en charge dans la version 2.0. - Verify_full : Connectez-vous uniquement à l’aide de SSL, d’une autorité de certification approuvée et d’un nom de serveur qui correspond au certificat. - Verify_ca : connectez-vous uniquement à l’aide de SSL et d’une autorité de certification approuvée. - Obligatoire : Connectez-vous uniquement à l’aide de SSL. - Préféré : Connectez-vous à l’aide du protocole SSL si disponible. Sinon, connectez-vous sans utiliser SSL. - Autorisé : par défaut, connectez-vous sans utiliser SSL. Si le serveur requiert des connexions SSL, utilisez SSL. - Désactivé : Se connecter sans utiliser SSL. Options : verify-full (par défaut) / verify-ca / require / prefer / allow / disable |
Non, la valeur par défaut est verify-full |
| connectVia | Le Integration Runtime à utiliser pour se connecter au stockage de données. Vous pouvez utiliser Azure Integration Runtime ou des Integration Runtime auto-hébergés (si votre magasin de données se trouve dans un réseau privé). S’il n’est pas spécifié, il utilise la Azure Integration Runtime par défaut. | Non |
Note
La version 2.0 prend en charge les Azure Integration Runtime et les Integration Runtime auto-hébergés version 5.61 ou ultérieure. L’installation du pilote n’est plus nécessaire avec les Integration Runtime auto-hébergés version 5.61 ou ultérieure.
Exemple : version 2.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"version": "2.0",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : version 1.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Amazon Redshift.
Pour copier des données à partir d’Amazon Redshift, les propriétés suivantes sont prises en charge :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : AmazonRedshiftTable | Oui |
| schéma | Nom du schéma. | Non (si « query » dans la source de l’activité est spécifié) |
| tableau | Nom de la table. | Non (si « query » dans la source de l’activité est spécifié) |
| tableName | Nom de la table avec le schéma. Cette propriété est prise en charge pour la compatibilité descendante. Utilisez schema et table pour une nouvelle charge de travail. |
Non (si « query » dans la source de l’activité est spécifié) |
Exemple
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Si vous utilisiez un dataset typé RelationalTable, il reste pris en charge tel quel, mais nous vous suggérons d’utiliser désormais le nouveau dataset.
Propriétés de l'activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par Amazon Redshift en tant que source.
Amazon Redshift en tant que source
Pour copier des données d’Amazon Redshift, définissez AmazonRedshiftSource comme type de source dans l’activité de copie. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur AmazonRedshiftSource | Oui |
| requête | Utilise la requête personnalisée pour lire des données. Par exemple : select * from MyTable. | Non (si « tableName » est spécifié dans dataset) |
| redshiftUnloadSettings | Groupe de propriétés lors de l’utilisation du mécanisme UNLOAD d’Amazon Redshift. | Non |
| s3LinkedServiceName | Fait référence à un service Amazon S3 à utiliser comme magasin temporaire en spécifiant un nom de service lié de type « AmazonS3 ». | Oui, en cas d’utilisation de UNLOAD |
| bucketName | Indiquez le compartiment S3 pour stocker les données intermédiaires. S’il n’est pas spécifié, le service le génère automatiquement. | Oui, en cas d’utilisation de UNLOAD |
Exemple : source Amazon Redshift dans une activité de copie utilisant UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Apprenez-en davantage sur l’utilisation de UNLOAD pour copier efficacement des données d’Amazon Redshift en lisant la section suivante.
Utiliser UNLOAD pour copier des données à partir d’Amazon Redshift
UNLOAD est un mécanisme fourni par Amazon Redshift qui peut décharger les résultats d’une requête dans un ou plusieurs fichiers sur Amazon Simple Storage Service (Amazon S3). C’est le moyen recommandé par Amazon pour copier un jeu de données volumineux à partir de Redshift.
Example : copiez des données d’Amazon Redshift vers Azure Synapse Analytics à l’aide de UNLOAD, d’une copie intermédiaire et de PolyBase
Pour cet exemple de cas d’usage, l’activité de copie décharge les données d’Amazon Redshift vers Amazon S3 comme configuré dans « redshiftUnloadSettings », puis copie les données d’Amazon S3 vers Azure Blob comme spécifié dans « stagingSettings », enfin utiliser PolyBase pour charger des données dans Azure Synapse Analytics. Tous les formats intermédiaires sont gérés correctement par l’activité de copie.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Mappage de type de données pour Amazon Redshift
Lorsque vous copiez des données à partir d’Amazon Redshift, les mappages suivants s’appliquent des types de données d’Amazon Redshift aux types de données internes utilisés par le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, consultez Mappage de schéma dans l’activité de copie.
| Type de données d’Amazon Redshift | Type de données de service intermédiaire (pour la version 2.0) | Type de données de service intermédiaire (pour la version 1.0) |
|---|---|---|
| bigint | Int64 | Int64 |
| BOOLEAN | Booléen | Chaîne |
| CHAR | Chaîne | Chaîne |
| DATE | Date et heure | Date et heure |
| DECIMAL (Précision <= 28) | Decimal | Decimal |
| DÉCIMAL (Précision > 28) | Chaîne | Chaîne |
| DOUBLE PRÉCISION | Double | Double |
| INTEGER | Int32 | Int32 |
| real | Unique | Unique |
| SMALLINT | Int16 | Int16 |
| TEXT | Chaîne | Chaîne |
| TIMESTAMP | Date et heure | Date et heure |
| VARCHAR | Chaîne | Chaîne |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Cycle de vie et mise à niveau du connecteur Amazon Redshift
Le tableau suivant présente l’étape de mise en production et les journaux des modifications pour différentes versions du connecteur Amazon Redshift :
| Version | Phase de mise en production | Journal des modifications |
|---|---|---|
| Version 1.0 | Fin du support annoncé | / |
| Version 2.0 | Version en disponibilité générale disponible | • Prend en charge Azure Integration Runtime et les Integration Runtime auto-hébergés version 5.61 ou ultérieure. L’installation du pilote n’est plus nécessaire avec les Integration Runtime auto-hébergés version 5.61 ou ultérieure. • BOOLEAN est lu en tant que type de données booléen. • Prise en charge de sslmode dans le service lié. |
Mettre à niveau le connecteur Amazon Redshift de la version 1.0 vers la version 2.0
Dans la page Modifier le service lié , sélectionnez la version 2.0 et configurez le service lié en faisant référence aux propriétés du service lié.
Le mappage de type de données pour le service lié Amazon Redshift version 2.0 est différent de celui de la version 1.0. Pour découvrir le mappage de type de données le plus récent, consultez Mappage de type de données pour Amazon Redshift.
Appliquez un runtime d’intégration auto-hébergé avec la version 5.61 ou ultérieure. L’installation du pilote n’est plus nécessaire avec les Integration Runtime auto-hébergés version 5.61 ou ultérieure.
Contenu connexe
Consultez les banques de données prises en charge pour obtenir la liste des banques de données prises en charge en tant que sources et récepteurs par l’activité de copie.