Copier des données vers ou depuis Azure Data Lake Storage Gen1 à l’aide d’Azure Data Factory ou Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment copier des données vers et depuis Azure Data Lake Storage Gen1. Pour en savoir plus, lisez l’article d’introduction pour Azure Data Factory ou Azure Synapse Analytics.
Fonctionnalités prises en charge
Ce connecteur Azure Data Lake Storage Gen1 est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | |
| Mappage de flux de données (source/récepteur) | 0 |
| Activité de recherche | |
| Activité GetMetadata | |
| Supprimer l’activité |
① runtime d’intégration Azure ② runtime d’intégration auto-hébergé
Concrètement, avec ce connecteur, vous pouvez effectuer les opérations suivantes :
- Copier des fichiers à l’aide de l’une des méthodes d’authentification suivantes : principal de service ou identités managées pour les ressources Azure.
- Copier des fichiers tels quels, ou analyser ou générer des fichiers avec les formats de fichier et codecs de compression pris en charge.
- Conserver les listes de contrôle d’accès lors de la copie vers Azure Data Lake Storage Gen2.
Important
Si vous copiez des données à l’aide du runtime d’intégration auto-hébergé, configurez le pare-feu d’entreprise pour autoriser le trafic sortant vers <ADLS account name>.azuredatalakestore.net et login.microsoftonline.com/<tenant>/oauth2/token sur le port 443. Ce dernier est le service d’émission de jeton de sécurité Azure avec lequel le runtime d’intégration a besoin de communiquer pour obtenir le jeton d’accès.
Bien démarrer
Conseil
Pour obtenir une procédure pas à pas d’utilisation du connecteur Azure Data Lake Store, consultez Charger des données dans Azure Data Lake Store.
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Azure Data Lake Storage Gen1 à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Azure Data Lake Storage Gen1 dans l’interface utilisateur du Portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis sélectionnez Nouveau :
Recherchez Azure Data Lake Storage Gen1 et sélectionnez le connecteur Azure Data Lake Storage Gen1.
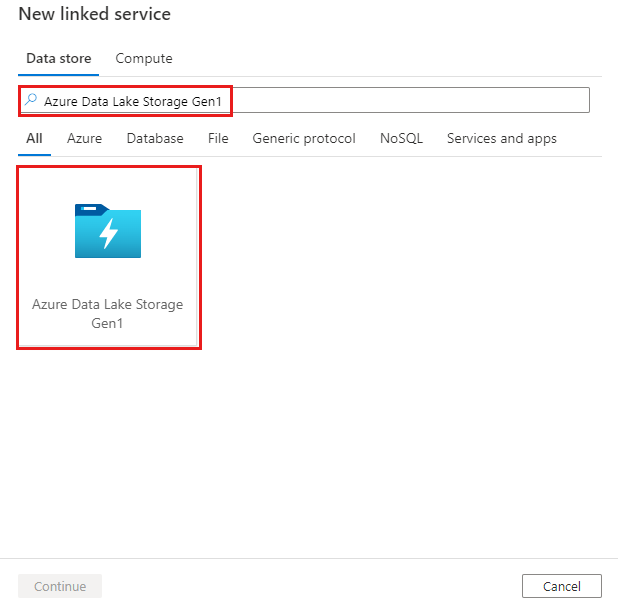
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
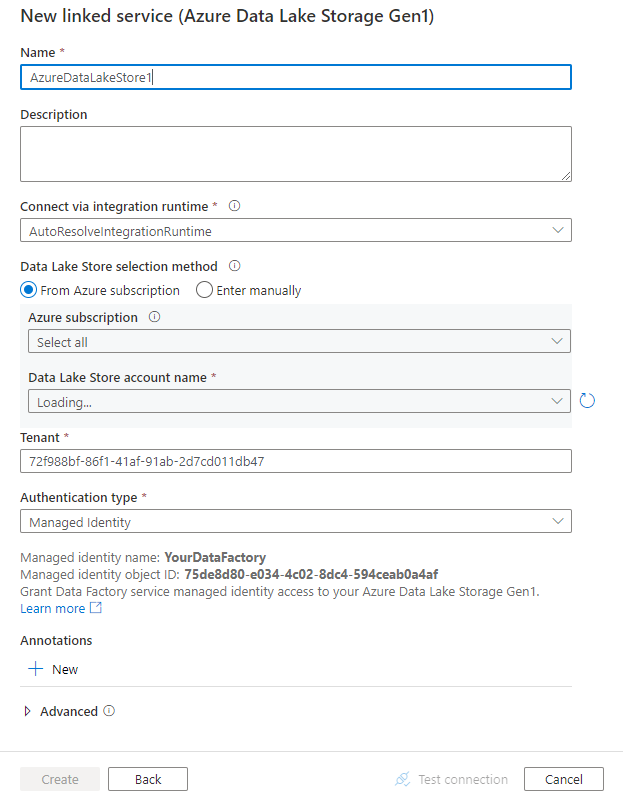
Informations de configuration des connecteurs
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités propres à Azure Data Lake Store Gen1.
Propriétés du service lié
Les propriétés suivantes sont prises en charge pour le service lié Azure Data Lake Store :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AzureDataLakeStore. |
Oui |
| dataLakeStoreUri | Informations à propos du compte Azure Data Lake Store. Cette information prend un des formats suivants : https://[accountname].azuredatalakestore.net/webhdfs/v1 ou adl://[accountname].azuredatalakestore.net/. |
Oui |
| subscriptionId | ID de l’abonnement Azure auquel appartient le compte Data Lake Store. | Requis pour le récepteur |
| resourceGroupName | Nom du groupe de ressources Azure auquel appartient le compte Data Lake Store. | Requis pour le récepteur |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. Si cette propriété n’est pas spécifiée, le runtime d’intégration Azure par défaut est utilisé. | Non |
Utiliser une authentification de principal de service
Pour l’authentification de principal de service, effectuez les étapes suivantes.
Inscrivez une entité d’application dans Microsoft Entra ID et accordez-lui l’accès à Data Lake Store. Consultez la page Authentification de service à service pour des instructions détaillées. Prenez note des valeurs suivantes, qui vous permettent de définir le service lié :
- ID de l'application
- Clé de l'application
- ID client
Accordez l’autorisation nécessaire au principal de service. Pour obtenir des exemples sur le fonctionnement des autorisations dans Data Lake Storage Gen1, consultez Contrôle d’accès dans Azure Data Lake Storage Gen1.
- En tant que source : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Lecture pour les fichiers à copier. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut. Il n’existe aucune exigence sur le contrôle d’accès au niveau du compte (IAM).
- En tant que récepteur : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Écriture pour le dossier récepteur. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut.
Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalKey | Spécifiez la clé de l’application. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. |
Oui |
| tenant | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) dans lesquels se trouve votre application. Vous pouvez le récupérer en pointant la souris dans le coin supérieur droit du portail Azure. | Oui |
| azureCloudType | Pour l’authentification du principal de service, spécifiez le type d’environnement cloud Azure auquel votre application Microsoft Entra est inscrite. Les valeurs autorisées sont AzurePublic, AzureChina, AzureUsGovernment et AzureGermany. Par défaut, l’environnement cloud du service est utilisé. |
Non |
Exemple :
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Utiliser l’authentification d’identité managée affectée par le système
Une fabrique de données ou un espace de travail Synapse peut être associé à une identité managée affectée par le système, qui représente le service d’authentification. Vous pouvez utiliser directement cette identité managée affectée par le système pour l’authentification Data Lake Store, ce qui revient à utiliser votre propre principal de service. Cela permet à la ressource désignée d’accéder aux données et de les copier depuis ou vers Data Lake Store.
Pour utiliser l’authentification par identité managée affectée par le système, effectuez les étapes suivantes.
Récupérez les informations d’identité managée affectée par le système en copiant la valeur de l’« ID d’application de l’identité du service » générée en même temps que votre fabrique ou espace de travail Synapse.
Accordez à l’identité managée affectée par le système l’accès à Data Lake Store. Pour obtenir des exemples sur le fonctionnement des autorisations dans Data Lake Storage Gen1, consultez Contrôle d’accès dans Azure Data Lake Storage Gen1.
- En tant que source : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Lecture pour les fichiers à copier. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut. Il n’existe aucune exigence sur le contrôle d’accès au niveau du compte (IAM).
- En tant que récepteur : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Écriture pour le dossier récepteur. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut.
Vous n’avez pas besoin de spécifier d’autres propriétés que les informations générales Data Lake Store du service lié.
Exemple :
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Utiliser l’authentification d’identité managée affectée par l’utilisateur
Une fabrique de données peut être affectée à une ou plusieurs identités managées par l’utilisateur. Vous pouvez utiliser cette identité managée affectée par l’utilisateur pour l’authentification du stockage Blob, qui permet d’accéder aux données et de les copier depuis ou vers Data Lake Store. Pour en savoir plus sur les identités managées pour les ressources Azure, consultez Identités managées pour les ressources Azure
Pour utiliser l’authentification par identité managée affectée par l’utilisateur, effectuez les étapes suivantes :
Créez une ou plusieurs identités managées affectées par l’utilisateur et accordez-leur l’accès à Azure Data Lake. Pour obtenir des exemples sur le fonctionnement des autorisations dans Data Lake Storage Gen1, consultez Contrôle d’accès dans Azure Data Lake Storage Gen1.
- En tant que source : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Lecture pour les fichiers à copier. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut. Il n’existe aucune exigence sur le contrôle d’accès au niveau du compte (IAM).
- En tant que récepteur : Dans l’Explorateur de données>Accès, accordez au moins l’autorisation Exécution à l’ensemble des dossiers en amont (y compris le dossier racine) et l’autorisation Écriture pour le dossier récepteur. Vous pouvez choisir d’ajouter l’autorisation à ce dossier et tous ses enfants pour les récurrences et de l’ajouter en tant qu’autorisation d’accès et entrée d’autorisation par défaut.
Attribuez une ou plusieurs identités managées affectées par l’utilisateur à votre fabrique de données et créez des informations d’identification pour chaque identité managée affectée par l’utilisateur.
La propriété suivante est prise en charge :
| Propriété | Description | Obligatoire |
|---|---|---|
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
Exemple :
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données.
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour Azure Data Lake Store Gen1 dans les paramètres location du jeu de données basé sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous location dans le jeu de données doit être définie sur AzureDataLakeStoreLocation. |
Oui |
| folderPath | Chemin d’accès du dossier. Si vous souhaitez utiliser un caractère générique pour filtrer les dossiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
| fileName | Nom de fichier dans le chemin d’accès folderPath donné. Si vous souhaitez utiliser un caractère générique pour filtrer les fichiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
Exemple :
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition des activités, consultez Pipelines. Cette section fournit la liste des propriétés prises en charge par Azure Data Lake Store en tant que source et récepteur.
Azure Data Lake Store en tant que source
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Les propriétés suivantes sont prises en charge pour Azure Data Lake Store Gen1 dans les paramètres storeSettings de la source de copie basée sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous storeSettings doit être définie sur AzureDataLakeStoreReadSettings. |
Oui |
| Recherchez les fichiers à copier : | ||
| OPTION 1 : chemin d’accès statique |
Copiez à partir du chemin d’accès au dossier/fichier spécifié dans le jeu de données. Si vous souhaitez copier tous les fichiers d’un dossier, spécifiez en plus wildcardFileName comme *. |
|
| OPTION 2 : plage de noms - listAfter |
Récupérez les dossiers/fichiers dont le nom se trouve après cette valeur par ordre alphabétique (exclusif). Elle utilise le filtre côté service pour ADLS Gen1, qui offre de meilleures performances qu’un filtre de caractères génériques. Le service applique ce filtre au chemin défini dans le jeu de données ; seul un niveau d’entité est pris en charge. Pour voir d’autres exemples, consultez Exemples de filtres de plages de noms. |
Non |
| OPTION 2 : plage de noms - listBefore |
Récupérez les dossiers/fichiers dont le nom se trouve avant cette valeur par ordre alphabétique (inclusif). Elle utilise le filtre côté service pour ADLS Gen1, qui offre de meilleures performances qu’un filtre de caractères génériques. Le service applique ce filtre au chemin défini dans le jeu de données ; seul un niveau d’entité est pris en charge. Pour voir d’autres exemples, consultez Exemples de filtres de plages de noms. |
Non |
| OPTION 3 : caractère générique - wildcardFolderPath |
Chemin d’accès du dossier avec des caractères génériques pour filtrer les dossiers sources. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de dossier contient effectivement ce caractère d’échappement ou générique. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Non |
| OPTION 3 : caractère générique - wildcardFileName |
Nom du fichier avec des caractères génériques situé dans le chemin d’accès folderPath/wildcardFolderPath donné pour filtrer les fichiers sources. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de fichier contient effectivement ce caractère d’échappement ou générique. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Oui |
| OPTION 4 : liste de fichiers - fileListPath |
Indique de copier un ensemble de fichiers donné. Pointez vers un fichier texte contenant la liste des fichiers que vous voulez copier, un fichier par ligne indiquant le chemin d’accès relatif configuré dans le jeu de données. Si vous utilisez cette option, ne spécifiez pas de nom de fichier dans le jeu de données. Pour plus d’exemples, consultez Exemples de listes de fichiers. |
Non |
| Paramètres supplémentaires : | ||
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Lorsque l’option « recursive » est définie sur true et que le récepteur est un magasin basé sur un fichier, un dossier vide ou un sous-dossier n’est pas copié ou créé sur le récepteur. Les valeurs autorisées sont true (par défaut) et false. Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| deleteFilesAfterCompletion | Indique si les fichiers binaires seront supprimés du magasin source après leur déplacement vers le magasin de destination. La suppression se faisant par fichier, lorsque l’activité de copie échoue, vous pouvez constater que certains fichiers ont déjà été copiés vers la destination et supprimés de la source, tandis que d’autres restent dans le magasin source. Cette propriété est valide uniquement dans un scénario de copie de fichiers binaires. La valeur par défaut est false. |
Non |
| modifiedDatetimeStart | Filtre de fichiers en fonction de l’attribut : Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés.Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| modifiedDatetimeEnd | Identique à ce qui précède. | Non |
| enablePartitionDiscovery | Pour les fichiers partitionnés, spécifiez s’il faut analyser les partitions à partir du chemin d’accès au fichier et les ajouter en tant que colonnes sources supplémentaires. Les valeurs autorisées sont false (par défaut) et true. |
Non |
| partitionRootPath | Lorsque la découverte de partition est activée, spécifiez le chemin d’accès racine absolu pour pouvoir lire les dossiers partitionnés en tant que colonnes de données. S’il n’est pas spécifié, par défaut, – Quand vous utilisez le chemin d’accès du fichier dans le jeu de données ou la liste des fichiers sur la source, le chemin racine de la partition est le chemin d’accès configuré dans le jeu de données. – Quand vous utilisez le filtre de dossiers de caractères génériques, le chemin racine de la partition est le sous-chemin avant le premier caractère générique. Par exemple, en supposant que vous configurez le chemin d’accès dans le jeu de données en tant que « root/folder/year=2020/month=08/day=27 » : – Si vous spécifiez le chemin racine de la partition en tant que « root/folder/year=2020 », l’activité de copie génère deux colonnes supplémentaires, month et day, ayant respectivement la valeur « 08 » et « 27 », en plus des colonnes contenues dans les fichiers.– Si le chemin racine de la partition n’est pas spécifié, aucune colonne supplémentaire n’est générée. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Store en tant que récepteur
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Les propriétés suivantes sont prises en charge pour Azure Data Lake Store Gen1 dans les paramètres storeSettings du récepteur de copie basée sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous storeSettings doit être définie sur AzureDataLakeStoreWriteSettings. |
Oui |
| copyBehavior | Définit le comportement de copie lorsque la source est constituée de fichiers d’une banque de données basée sur un fichier. Les valeurs autorisées sont les suivantes : - PreserveHierarchy (par défaut) : conserve la hiérarchie des fichiers dans le dossier cible. Le chemin relatif du fichier source vers le dossier source est identique au chemin relatif du fichier cible vers le dossier cible. - FlattenHierarchy : tous les fichiers du dossier source figurent dans le premier niveau du dossier cible. Les noms des fichiers cibles sont générés automatiquement. - MergeFiles : fusionne tous les fichiers du dossier source dans un seul fichier. Si le nom de fichier est spécifié, le nom de fichier fusionné est le nom spécifié. Dans le cas contraire, il s’agit d’un nom de fichier généré automatiquement. |
Non |
| expiryDateTime | Spécifie l’heure d’expiration des fichiers écrits. L’heure est appliquée à l’heure UTC au format « 2020-03-01T08:00:00Z ». Par défaut, la valeur est NULL, ce qui signifie que les fichiers écrits n’expirent jamais. | Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Exemples de filtres de plages
Cette section décrit le comportement résultant des filtres de plages de noms.
| Exemple de structure source | Configuration | Résultats |
|---|---|---|
| root a file.csv ax file2.csv ax.csv b file3.csv bx.csv c file4.csv cx.csv |
Dans le jeu de données : - chemin d’accès du dossier : rootDans la source de l’activité de copie : - listAfter : a- listBefore : b |
Ensuite, les fichiers suivants sont copiés : root ax file2.csv ax.csv b file3.csv |
Exemples de filtres de dossier et de fichier
Cette section décrit le comportement résultant de l’utilisation de filtres de caractères génériques dans les noms de fichier et les chemins de dossier.
| folderPath | fileName | recursive | Structure du dossier source et résultat du filtrage (les fichiers en gras sont récupérés) |
|---|---|---|---|
Folder* |
(vide, utiliser la valeur par défaut) | false | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
(vide, utiliser la valeur par défaut) | true | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
false | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
true | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Exemples de liste de fichiers
Cette section décrit le comportement résultant de l’utilisation du chemin d’accès à la liste de fichiers dans la source de l’activité de copie.
En supposant que vous disposez de la structure de dossiers source suivante et que vous souhaitez copier les fichiers en gras :
| Exemple de structure source | Contenu de FileListToCopy.txt | Configuration |
|---|---|---|
| root DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv Métadonnées FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
Dans le jeu de données : - chemin d’accès du dossier : root/FolderADans la source de l’activité de copie : - chemin d’accès à la liste de fichiers : root/Metadata/FileListToCopy.txt Le chemin d’accès à la liste de fichiers pointe vers un fichier texte dans le même magasin de données qui contient la liste de fichiers que vous voulez copier, un fichier par ligne étant le chemin d’accès relatif au chemin d’accès configuré dans le jeu de données. |
Exemples de comportement de l’opération de copie
Cette section décrit le comportement obtenu de l’opération de copie avec différentes combinaisons de valeurs recursive et copyBehavior.
| recursive | copyBehavior | Structure du dossier source | Cible obtenue |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le Dossier1 cible est créé et structuré de la même manière que la source : Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5. |
| true | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 nom généré automatiquement pour Fichier3 nom généré automatiquement pour Fichier4 nom généré automatiquement pour Fichier5 |
| true | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Le contenu de Fichier1 + Fichier2 + Fichier3 + Fichier4 + Fichier5 est fusionné dans un fichier avec un nom de fichier généré automatiquement. |
| false | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Fichier1 Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Le contenu de Fichier1 + Fichier2 est fusionné dans un fichier avec un nom de fichier généré automatiquement. nom généré automatiquement pour Fichier1 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
Conserver les listes de contrôle d’accès (ACL) dans Data Lake Storage Gen2
Conseil
Pour copier des données à partir d’Azure Data Lake Storage Gen1 dans Gen2 en général, consultez l’article Copier les données depuis Azure Data Lake Storage Gen1 vers Gen2 pour obtenir une procédure pas à pas et découvrir les meilleures pratiques.
Si vous souhaitez répliquer les listes de contrôle d’accès (ACL) ainsi que les fichiers de données lorsque vous migrez de Data Lake Storage Gen1 vers Data Lake Storage Gen2, consultez Conserver les listes de contrôle d’accès à partir de Data Lake Storage Gen1.
Propriétés du mappage de flux de données
Lorsque vous transformez des données en flux de données de mappage, vous pouvez lire et écrire des fichiers à partir d’Azure Data Lake Storage Gen1 aux formats suivants :
Les paramètres spécifiques au format se trouvent dans la documentation de ce format. Pour plus d’informations, consultez Transformation de source en flux de données de mappage et Transformation de récepteur en flux de données de mappage.
Transformation de la source
Dans la transformation de la source, vous pouvez lire à partir d’un conteneur, d’un dossier ou d’un fichier individuel dans Azure Data Lake Storage Gen1. L’onglet Options de la source vous permet de gérer la façon dont les fichiers sont lus.
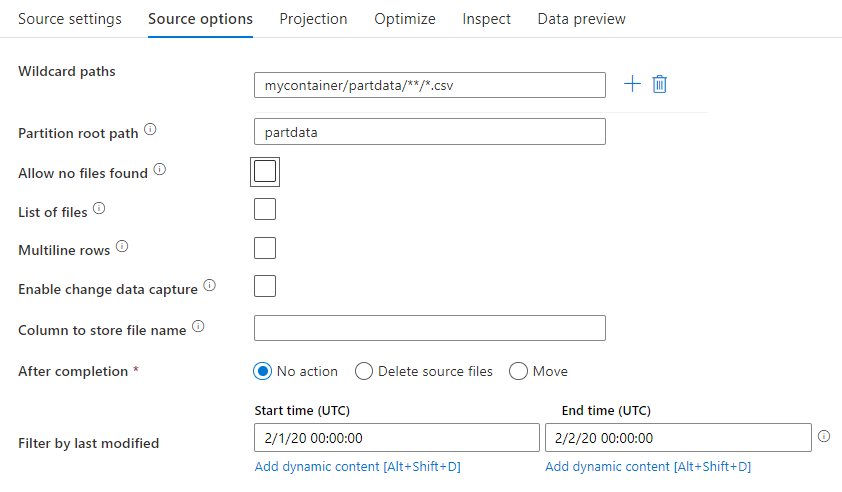
Chemin d’accès à caractères génériques : L’utilisation d’un modèle à caractères génériques donne pour instruction au service de parcourir en boucle chaque dossier et fichier correspondant dans une même transformation de la source. Il s’agit d’un moyen efficace de traiter plusieurs fichiers dans un seul et même flux. Ajoutez plusieurs modèles de correspondance à caractères génériques avec le signe + qui apparaît quand vous placez le pointeur sur votre modèle existant.
Dans le conteneur source, choisissez une série de fichiers qui correspondent à un modèle. Seul le conteneur peut être spécifié dans le jeu de données. Votre chemin contenant des caractères génériques doit donc également inclure le chemin de votre dossier à partir du dossier racine.
Exemples de caractères génériques :
*Représente n’importe quel ensemble de caractères**Représente une imbrication de répertoires récursifs?Remplace un caractère[]Met en correspondance un ou plusieurs caractères indiqués entre crochets/data/sales/**/*.csvObtient tous les fichiers CSV se trouvant sous /data/sales/data/sales/20??/**/Obtient tous les fichiers de manière récursive dans tous les dossiers 20xx correspondants/data/sales/*/*/*.csvObtient les fichiers CSV à deux niveaux sous /data/sales/data/sales/2004/12/[XY]1?.csvObtient tous les fichiers CSV depuis décembre 2004 commençant par X ou Y, suivi de 1 et de tout caractère unique
Chemin racine de la partition : si vous avez partitionné des dossiers dans votre source de fichier avec un format key=value (par exemple, année=2019), vous pouvez attribuer le niveau supérieur de cette arborescence de dossiers de partitions à un nom de colonne dans votre flux de données.
Tout d’abord, définissez un caractère générique pour inclure tous les chemins d’accès aux dossiers partitionnés, ainsi qu’aux fichiers feuilles que vous souhaitez lire.
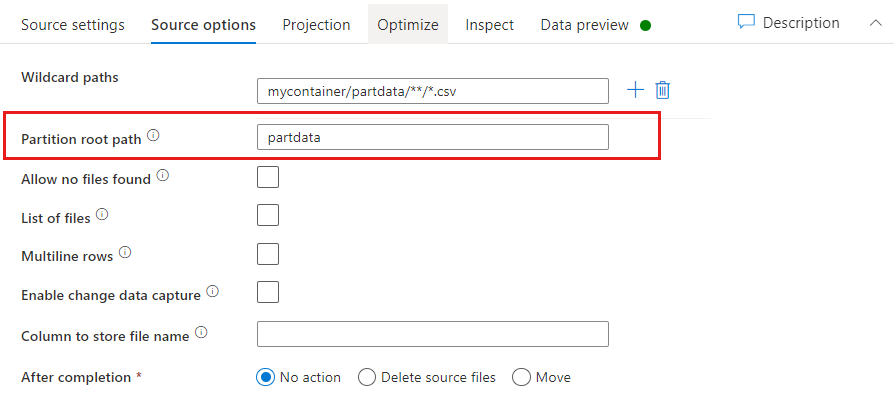
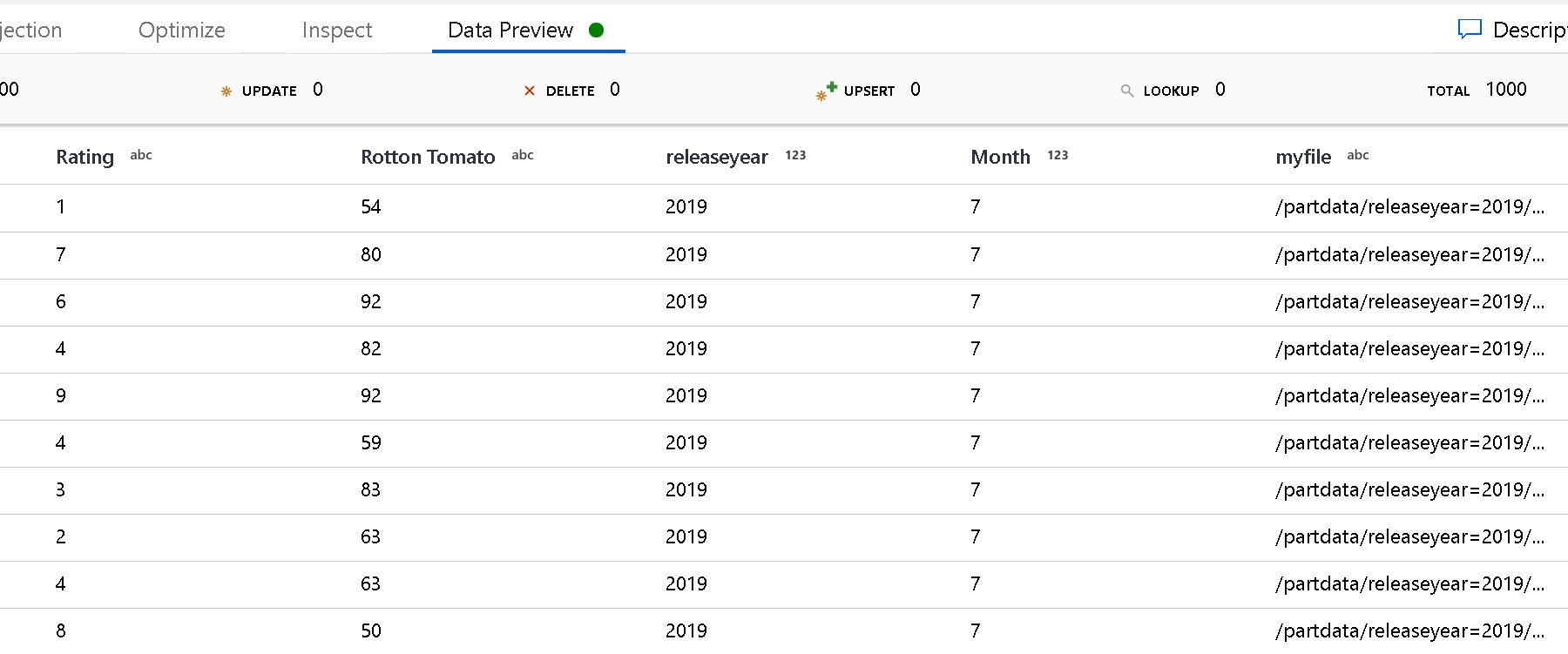
Utilisez le paramètre Chemin racine de la partition pour définir le niveau supérieur de la structure de dossiers. Quand vous affichez le contenu de vos données à l’aide d’un aperçu des données, vous voyez que le service ajoute les partitions résolues trouvées dans chacun de vos niveaux de dossiers.
Liste de fichiers : Il s’agit d’un ensemble de fichiers. Créez un fichier texte qui inclut une liste de fichiers avec chemin relatif à traiter. Pointez sur ce fichier texte.
Colonne où stocker le nom du fichier : Stockez le nom du fichier source dans une colonne de vos données. Entrez un nouveau nom de colonne pour stocker la chaîne de nom de fichier.
Après l’exécution : après l’exécution du flux de données, choisissez de ne rien faire avec le fichier source, de le supprimer ou de le déplacer. Pour le déplacement, les chemins sont des chemins relatifs.
Pour déplacer les fichiers sources vers un autre emplacement de post-traitement, sélectionnez tout d’abord « Déplacer » comme opération de fichier. Définissez ensuite le répertoire de provenance (« from »). Si vous n’utilisez pas de caractères génériques pour votre chemin, le paramètre « from » correspond au même dossier que votre dossier source.
Si vous avez un chemin d’accès source avec caractère générique, votre syntaxe se présente comme suit :
/data/sales/20??/**/*.csv
vous pouvez spécifier «from» sous la forme
/data/sales
et « to » sous la forme
/backup/priorSales
Dans le cas présent, tous les fichiers qui provenaient de /data/sales sont déplacés dans /backup/priorSales.
Notes
Les opérations de fichier s’exécutent uniquement quand vous démarrez le flux de données à partir d’une exécution de pipeline (débogage ou exécution) qui utilise l’activité Exécuter le flux de données dans un pipeline. Les opérations de fichiers ne s’exécutent pas en mode de débogage de flux de données.
Filtrer par date de dernière modification : Vous pouvez filtrer les fichiers traités en spécifiant une plage de dates sur laquelle les fichiers ont été modifiés pour la dernière fois. Toutes les dates et heures sont exprimées en UTC.
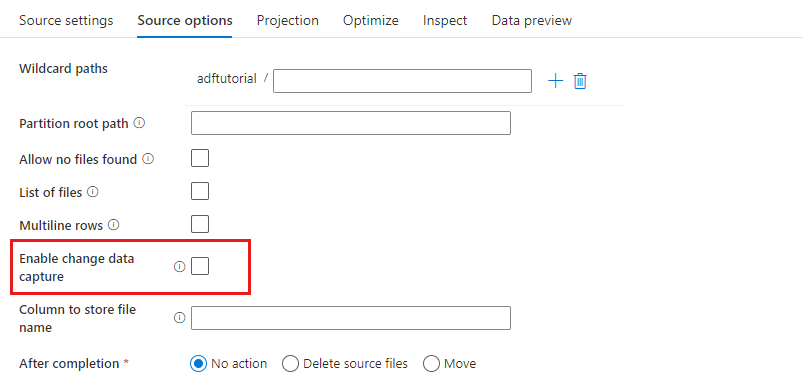
Activer la capture des changements de données : si ce paramètre est activé, vous obtenez les fichiers nouveaux ou modifiés uniquement à partir de la dernière exécution. Vous obtiendrez toujours le chargement initial des données d’instantané complètes lors de la première exécution, suivi de la capture des fichiers modifiés uniquement lors des prochaines exécutions. Pour plus d’informations, consultez Capture des changements de données.
Propriétés du récepteur
Dans la transformation du récepteur, vous pouvez écrire dans un conteneur ou un dossier dans Azure Data Lake Storage Gen1. L’onglet Paramètres vous permet de gérer la façon dont les fichiers sont écrits.
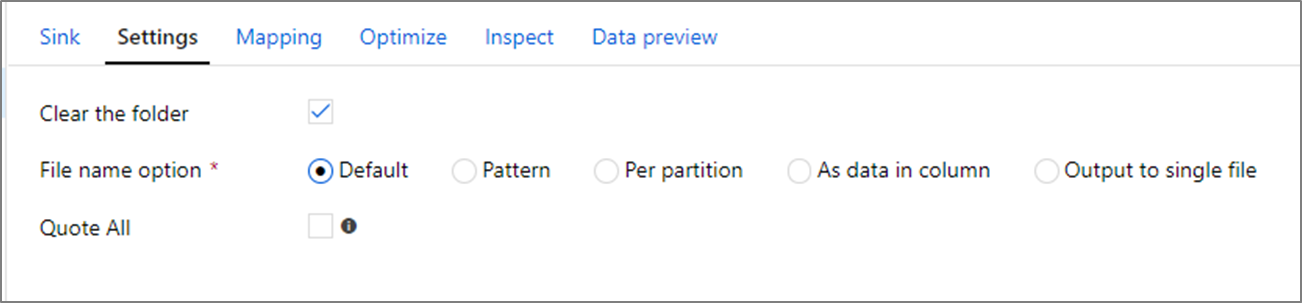
Effacer le contenu du dossier : Détermine si le contenu du dossier de destination doit être effacé avant l’écriture des données.
Option de nom de fichier : Détermine la façon dont les fichiers de destination sont nommés dans le dossier de destination. Les options de nom de fichier sont les suivantes :
- Par défaut : Autorisez Spark à nommer les fichiers en fonction des valeurs par défaut de la partition.
- Modèle : Entrez un modèle qui énumère vos fichiers de sortie par partition. Par exemple, loans[n].csv crée loans1.csv, loans2.csv, etc.
- Par partition : Entrez un nom de fichier pour chaque partition.
- Comme les données de la colonne : Définissez le fichier de sortie sur la valeur d’une colonne. Le chemin est relatif au conteneur du jeu de données et non pas au dossier de destination. Si vous avez un chemin de dossier dans votre jeu de données, il est remplacé.
- Sortie d’un seul fichier : Combinez les fichiers de sortie partitionnés en un seul fichier nommé. Le chemin est relatif au dossier du jeu de données. Notez que cette opération de fusion peut échouer en fonction de la taille du nœud. Cette option n’est pas recommandée pour des jeux de données volumineux.
Tout mettre entre guillemets : Détermine si toutes les valeurs doivent être placées entre guillemets
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Propriétés de l’activité Delete
Pour en savoir plus sur les propriétés, consultez Activité Delete.
Modèles hérités
Notes
Les Modèles suivants sont toujours pris en charge tels quels à des fins de compatibilité descendante. Il est recommandé d’utiliser le nouveau modèle mentionné dans les sections ci-dessus à partir de maintenant. L’interface utilisateur de création peut désormais générer ce nouveau modèle.
Modèle de jeu de données hérité
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type du jeu de données doit être définie sur AzureDataLakeStoreFile. | Oui |
| folderPath | Chemin vers le dossier dans Data Lake Store. Si non spécifié, il pointe vers la racine. Le filtre de caractères génériques est pris en charge. Les caractères génériques autorisés sont les suivants : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère). Utilisez ^ comme caractère d’échappement si le nom réel de votre dossier contient un caractère générique ou ce caractère d’échappement. Par exemple : dossierracine/sous-dossier/. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Non |
| fileName | Filtre de noms ou de caractères génériques pour les fichiers sous le chemin « folderPath » spécifié. Si vous ne spécifiez pas de valeur pour cette propriété, le jeu de données pointe vers tous les fichiers du dossier. Dans le filtre, les caractères génériques autorisés sont * (correspond à zéro caractère ou plus) et ? (correspond à zéro ou un caractère).- Exemple 1 : "fileName": "*.csv"- Exemple 2 : "fileName": "???20180427.txt"Utilisez ^ comme caractère d’échappement si votre nom de fichier réel contient des caractères génériques ou ce caractère d’échappement.Lorsque fileName n’est pas spécifié pour un jeu de données de sortie et que preserveHierarchy n’est pas spécifié dans le récepteur d’activité, l’activité de copie génère automatiquement le nom de fichier suivant ce modèle : « Data.[ID GUID d’exécution d’activité].[GUID si FlattenHierarchy].[format si configuré].[compression si configurée] », par exemple, « Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz ». Si vous effectuez la copie à partir d’une source tabulaire à l’aide d’un nom de tableau au lieu d’une requête, le modèle du nom est « [nom_tableau].[format].[compression si configurée] », par exemple « MyTable.csv ». |
Non |
| modifiedDatetimeStart | Filtre de fichiers en fonction de l’attribut Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Les performances globales du déplacement des données sont influencées par l’activation de ce paramètre lorsque vous souhaitez appliquer un filtre sur de grandes quantités de fichiers. Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés. |
Non |
| modifiedDatetimeEnd | Filtre de fichiers en fonction de l’attribut Dernière modification. Les fichiers sont sélectionnés si leur dernière heure de modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Les performances globales du déplacement des données sont influencées par l’activation de ce paramètre lorsque vous souhaitez appliquer un filtre sur de grandes quantités de fichiers. Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés. |
Non |
| format | Si vous souhaitez copier des fichiers en l’état entre des magasins de fichiers (copie binaire), ignorez la section Format dans les deux définitions de jeu de données d’entrée et de sortie. Si vous souhaitez analyser ou générer des fichiers dans un format spécifique, les types de format de fichier suivants sont pris en charge : TextFormat, JsonFormat, AvroFormat, OrcFormat et ParquetFormat. Définissez la propriété type située sous Format sur l’une de ces valeurs. Pour en savoir plus, voir les sections Format Text, Format JSON, Format Avro, Format Orc et Format Parquet. |
Non (uniquement pour un scénario de copie binaire) |
| compression | Spécifiez le type et le niveau de compression pour les données. Pour plus d’informations, voir Formats de fichier et de codecs de compression pris en charge. Les types pris en charge sont : GZip, Deflate, BZip2 et ZipDeflate. Les niveaux pris en charge sont Optimal et Fastest. |
Non |
Conseil
Pour copier tous les fichiers d’un dossier, spécifiez folderPath uniquement.
Pour copier un seul fichier portant un nom particulier, spécifiez folderPath avec la partie dossier et fileName avec le nom du fichier.
Pour copier un sous-ensemble de fichiers d’un dossier, spécifiez folderPath avec la partie dossier et fileName avec un filtre de caractères génériques.
Exemple :
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modèle hérité de la source d’activité de copie
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur AzureDataLakeStoreSource. |
Oui |
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Lorsque l’option recursive est définie sur true et que le récepteur est un magasin basé sur un fichier, aucun dossier ou sous-dossier vide n’est copié ou créé au niveau du récepteur. Les valeurs autorisées sont true (par défaut) et false. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modèle hérité du récepteur d’activité de copie
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur d’activité de copie doit être définie sur AzureDataLakeStoreSink. |
Oui |
| copyBehavior | Définit le comportement de copie lorsque la source est constituée de fichiers d’une banque de données basée sur un fichier. Les valeurs autorisées sont les suivantes : - PreserveHierarchy (par défaut) : conserve la hiérarchie des fichiers dans le dossier cible. Le chemin relatif du fichier source vers le dossier source est identique au chemin relatif du fichier cible vers le dossier cible. - FlattenHierarchy : tous les fichiers du dossier source figurent dans le premier niveau du dossier cible. Les noms des fichiers cibles sont générés automatiquement. - MergeFiles : fusionne tous les fichiers du dossier source dans un seul fichier. Si le nom de fichier est spécifié, le nom de fichier fusionné est le nom spécifié. Dans le cas contraire, le nom de fichier est généré automatiquement. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Capture des changements de données (préversion)
Azure Data Factory peut obtenir des fichiers nouveaux ou modifiés uniquement à partir d’Azure Data Lake Storage Gen1 en activant l’option Activer la capture des changements de données (préversion) dans la transformation source du flux de données de mappage. Avec cette option de connecteur, vous pouvez lire les fichiers nouveaux ou mis à jour uniquement et appliquer des transformations avant de charger les données transformées dans les jeux de données de destination de votre choix.
Veillez à ne pas changer le nom du pipeline et de l’activité, afin que le point de contrôle puisse toujours être enregistré à partir de la dernière exécution et que vous puissiez obtenir les modifications à partir de ce moment-là. Si vous changez le nom de votre pipeline ou de votre activité, le point de contrôle est réinitialisé et vous recommencez depuis le début lors de la prochaine exécution.
Lorsque vous déboguez le pipeline, Activer la capture des changements de données (préversion) fonctionne également. Le point de contrôle est réinitialisé quand vous actualisez votre navigateur lors de l’exécution du débogage. Une fois que vous êtes satisfait du résultat de l’exécution du débogage, vous pouvez publier et déclencher le pipeline. Il commencera toujours depuis le début, quel que soit le point de contrôle précédent enregistré par l’exécution du débogage.
Dans la section de monitoring, vous avez toujours la possibilité de réexécuter un pipeline. Dans ce cas, les modifications sont toujours récupérées à partir de l’enregistrement de point de contrôle dans votre exécution de pipeline sélectionnée.
Contenu connexe
Pour obtenir une liste des magasins de données pris en charge comme sources et récepteurs par l’activité de copie, consultez la section sur les magasins de données pris en charge.