Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
APPLIES TO : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Suivez cet article si vous souhaitez analyser des fichiers JSON ou écrire des données au format JSON.
Le format JSON est pris en charge pour les connecteurs suivants :
- Amazon S3
- Stockage compatible Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Système de fichiers
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Stockage dans le cloud Oracle
- SFTP
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données JSON.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur Json. | Oui |
| location | Paramètres d’emplacement du ou des fichiers. Chaque connecteur basé sur un fichier possède ses propres type d’emplacement et propriétés prises en charge sous location.
Consultez les détails dans l’article du connecteur -> section des propriétés du jeu de données. |
Oui |
| encodingName | Le type de codage utilisé pour lire/écrire des fichiers de test. Les valeurs autorisées sont les suivantes : "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Non |
| compression | Groupe de propriétés pour configurer la compression de fichier. Configurez cette section lorsque vous souhaitez effectuer la compression/décompression lors de l’exécution de l’activité. | Non |
| type (sous compression ) |
Le codec de compression utilisé pour lire/écrire des fichiers JSON. Les valeurs autorisées sont bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy et lz4. La valeur par défaut n’est pas compressée. Note actuellement activité Copy ne prend pas en charge « snappy » et « lz4 » et le flux de données de mappage ne prend pas en charge « ZipDeflate », « TarGzip » et « Tar ». Remarque : Lorsque l’activité de copie est utilisée pour décompresser un ou plusieurs fichiers ZipDeflate/TarGzip/Tar et écrire dans un magasin de données récepteur basé sur des fichiers, les fichiers sont par défaut extraits dans le dossier <path specified in dataset>/<folder named as source compressed file>/. Utilisez preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder sur source de l’activité de copie pour déterminer si le nom du ou des fichiers compressés doit être conservé comme structure de dossier. |
Non. |
| level (sous compression ) |
Le taux de compression. Les valeurs autorisées sont Optimal ou Fastest. - Fastest (le plus rapide) : l’opération de compression doit se terminer le plus rapidement possible, même si le fichier résultant n’est pas compressé de façon optimale. - Optimal : l’opération de compression doit aboutir à une compression optimale, même si elle prend plus de temps. Pour plus d’informations, consultez la rubrique Niveau de compression . |
Non |
Voici un exemple de jeu de données JSON sur Stockage Blob Azure :
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
propriétés de activité Copy
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source et le récepteur JSON.
Découvrez la procédure d’extraction de données à partir de fichiers JSON et de mappage au magasin/format de données récepteur, ou inversement, à partir de la mise en correspondance du schéma.
JSON en tant que source
Les propriétés prises en charge dans la section *source* de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être JSONSource. | Oui |
| formatSettings | Un groupe de propriétés. Reportez-vous au tableau Paramètres de lecture JSON ci-dessous. | Non |
| storeSettings | Un groupe de propriétés sur la façon de lire les données d’un magasin de données. Chaque connecteur basé sur un fichier possède ses propres paramètres de lecture pris en charge sous storeSettings.
Détails de l’article du connecteur -> activité Copy section propriétés. |
Non |
Paramètres de lecture JSON pris en charge sous formatSettings :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | Le type de formatSettings doit être défini sur JsonReadSettings. | Oui |
| compressionProperties | Groupe de propriétés permettant de décompresser les données d’un codec de compression spécifique. | Non |
| preserveZipFileNameAsFolder (sous compressionProperties->type en tant que ZipDeflateReadSettings) |
S’applique lorsque le jeu de données d’entrée est configuré avec la compression ZipDeflate. Indique si le nom du fichier zip source doit être conservé en tant que structure de dossiers lors de la copie. – Lorsque la valeur est définie sur true (par défaut) , le service écrit les fichiers décompressés dans <path specified in dataset>/<folder named as source zip file>/.– Lorsque la valeur est définie sur false, le service écrit les fichiers décompressés directement dans <path specified in dataset>. Assurez-vous de ne pas avoir de noms de fichiers dupliqués dans les différents fichiers zip sources afin d’éviter toute course ou tout comportement inattendu. |
Non |
| preserveCompressionFileNameAsFolder (sous compressionProperties->type en tant que TarGZipReadSettings ou TarReadSettings) |
S'applique lorsque le jeu de données d'entrée est configuré avec la compression TarGzip/Tar. Indique si le nom du fichier source compressé doit être conservé en tant que structure de dossiers lors de la copie. – Lorsque la valeur est définie sur true (par défaut) , le service écrit les fichiers décompressés dans <path specified in dataset>/<folder named as source compressed file>/. – Lorsque la valeur est définie sur false, le service écrit les fichiers décompressés directement dans <path specified in dataset>. Assurez-vous de ne pas avoir de noms de fichiers en double dans différents fichiers sources afin d’éviter toute course ou tout comportement inattendu. |
Non |
JSON en tant que récepteur
Les propriétés prises en charge dans la section *récepteur* de l’activité de copie sont les suivantes.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur JSONSink. | Oui |
| formatSettings | Un groupe de propriétés. Reportez-vous au tableau Paramètres d’écriture JSON ci-dessous. | Non |
| storeSettings | Groupe de propriétés sur la méthode d’écriture de données dans un magasin de données. Chaque connecteur basé sur un fichier possède ses propres paramètres d’écriture pris en charge sous storeSettings.
Détails de l’article du connecteur -> activité Copy section propriétés. |
Non |
Paramètres d’écriture JSON pris en charge sous formatSettings :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | Le type de formatSettings doit être défini sur JsonWriteSettings. | Oui |
| filePattern | Indiquez le modèle des données stockées dans chaque fichier JSON. Les valeurs autorisées sont les suivantes : setOfObjects (lignes JSON) et arrayOfObjects. La valeur par défaut est setOfObjects. Consultez la section Modèles de fichiers JSON pour en savoir plus sur ces modèles. | Non |
Modèles de fichiers JSON
Lors de la copie de données à partir de fichiers JSON, l’activité de copie peut détecter et analyser automatiquement les modèles de fichiers JSON ci-dessous. Lorsque vous écrivez des données dans des fichiers JSON, vous pouvez configurer le modèle de fichier sur le récepteur de l’activité de copie.
Type I : setOfObjects
Chaque fichier contient un objet unique, des lignes JSON ou des objets concaténés.
Exemple de fichier JSON à un seul objet
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Lignes JSON (valeur par défaut pour le récepteur)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exemple de fichier JSON incluant des objets concaténés
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Type II : arrayOfObjects
Chaque fichier contient un tableau d’objets.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Propriétés du mappage de flux de données
Dans mapping des flux de données, vous pouvez lire et écrire dans le format JSON dans les magasins de données suivants : Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 et SFTP et vous pouvez lire le format JSON dans Amazon S3.
Propriétés sources
Le tableau ci-dessous liste les propriétés prises en charge par une source JSON. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Chemins génériques | Tous les fichiers correspondant au chemin générique seront traités. Remplace le chemin du dossier et du fichier défini dans le jeu de données. | non | String[] | wildcardPaths |
| Chemin racine de la partition | Pour les données de fichier qui sont partitionnées, vous pouvez entrer le chemin racine d’une partition pour pouvoir lire les dossiers partitionnés comme des colonnes. | non | String | partitionRootPath |
| Liste de fichiers | Si votre source pointe ou non vers un fichier texte qui liste les fichiers à traiter | non |
true ou false |
fileList |
| Colonne où stocker le nom du fichier | Crée une colonne avec le nom et le chemin du fichier source | non | String | rowUrlColumn |
| Après l’exécution | Supprime ou déplace les fichiers après le traitement. Le chemin du fichier commence à la racine du conteneur | non | Supprimer : true ou false Déplacer : ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrer par date de dernière modification | Pour filtrer les fichiers en fonction de leur date de dernière modification | non | Timestamp | modifiedAfter modifiedBefore |
| Document individuel | Les flux de données de mappage lisent un document JSON à partir de chaque fichier | non |
true ou false |
singleDocument |
| Noms de colonnes sans guillemets | Si Noms de colonnes sans guillemets est sélectionné, le mappage des flux de données lit les colonnes JSON qui ne sont pas entourées de guillemets. | non |
true ou false |
unquotedColumnNames |
| Comporte des commentaires | Sélectionnez Comporte des commentaires si les données JSON ont des commentaires de style C ou C++ | non |
true ou false |
asComments |
| Apostrophes simples | Lit les colonnes JSON qui ne sont pas entourées de guillemets | non |
true ou false |
singleQuoted |
| Barres obliques inverses d’échappement | Sélectionnez Barres obliques inverses d’échappement si les barres obliques inverses sont utilisées pour échapper les caractères dans les données JSON. | non |
true ou false |
backslashEscape |
| N’autoriser aucun fichier trouvé | Si la valeur est true, aucune erreur n’est levée si aucun fichier n’est trouvé | non |
true ou false |
ignoreNoFilesFound |
Jeu de données inlined
Les flux de données de mappage prennent en charge les « jeux de données inline » comme option pour définir votre source et votre récepteur. Un jeu de données JSON inline est défini directement à l’intérieur de vos transformations de source et de récepteur et n’est pas partagé en dehors du flux de données défini. Il est utile pour paramétriser les propriétés de jeu de données directement à l’intérieur de votre flux de données et peut bénéficier de performances améliorées par rapport aux jeux de données ADF partagés.
Quand vous lisez un grand nombre de dossiers et de fichiers sources, vous pouvez améliorer les performances de la découverte de fichiers de flux de données en définissant l’option « Schéma projeté par l’utilisateur » dans la Boîte de dialogue Projection | Options de schéma. Cette option désactive la découverte automatique de schémas par défaut d’ADF et améliore considérablement les performances de la découverte de fichiers. Avant de définir cette option, veillez à importer la projection JSON afin qu’ADF dispose d’un schéma existant pour la projection. Cette option ne fonctionne pas avec la dérive de schéma.
Options de format source
L’utilisation d’un jeu de données JSON comme source dans votre flux de données vous permet de définir cinq paramètres supplémentaires. Ces paramètres se trouvent sous l’accordéon Paramètres JSON sous l’onglet Options de la source. Pour le paramètre Forme de document, vous pouvez sélectionner l’un des types suivants : Document unique, Document par ligne ou Tableau de documents.
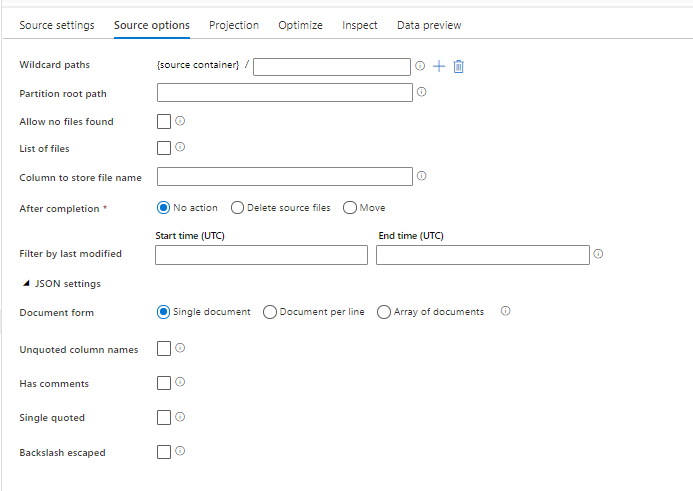
Default
Par défaut, les données JSON sont lues dans le format suivant.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Document individuel
Si Document unique est sélectionné, le mappage de flux de données lit un document JSON à partir de chaque fichier.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Si Document par ligne est sélectionné, le flux de données de mappage lit un document JSON ligne par ligne.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Si Tableau de documents est sélectionné, le flux de données de mappage lit un tableau de documents à partir d’un fichier.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Remarque
Si les flux de données génèrent une erreur indiquant « corrupt_record » lorsque vous affichez un aperçu de vos données JSON, il est probable que vos données contiennent un seul document dans votre fichier JSON. Le paramètre « document unique » doit effacer cette erreur.
Noms de colonnes sans guillemets
Si Noms de colonnes sans guillemets est sélectionné, le mappage des flux de données lit les colonnes JSON qui ne sont pas entourées de guillemets.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Comporte des commentaires
Sélectionnez Comporte des commentaires si les données JSON ont des commentaires de style C ou C++.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Apostrophes simples
Sélectionnez Apostrophes simples si les champs et valeurs JSON utilisent des guillemets simples au lieu de guillemets doubles.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Barres obliques inverses d’échappement
Sélectionnez Barres obliques inverses d’échappement si les barres obliques inverses sont utilisées pour échapper les caractères dans les données JSON.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Propriétés du récepteur
Le tableau ci-dessous liste les propriétés prises en charge par un récepteur JSON. Vous pouvez modifier ces propriétés sous l’onglet Paramètres.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Effacer le contenu du dossier | Si le dossier de destination est vidé avant l’écriture | non |
true ou false |
truncate |
| Option de nom de fichier | Format de nommage des données écrites. Par défaut, un fichier par partition au format part-#####-tid-<guid> |
non | Modèle : Chaîne Par partition : Chaîne[] Comme des données d’une colonne : Chaîne Sortie dans un fichier unique : ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Création de structures JSON dans une colonne dérivée
Vous pouvez ajouter une colonne complexe à votre flux de données à l’aide du générateur d’expressions de la colonne dérivée. Dans la transformation de colonne dérivée, ajoutez une nouvelle colonne et ouvrez le générateur d’expressions en cliquant sur la zone bleue. Pour rendre une colonne complexe, vous pouvez entrer la structure JSON manuellement ou utiliser l’expérience utilisateur pour ajouter des sous-colonnes de manière interactive.
Utilisation de l’expérience utilisateur pour le générateur d’expressions
Dans le volet latéral du schéma de sortie, pointez sur une colonne, puis cliquez sur l’icône plus. Sélectionnez Ajouter une sous-colonne pour transformer la colonne en type complexe.
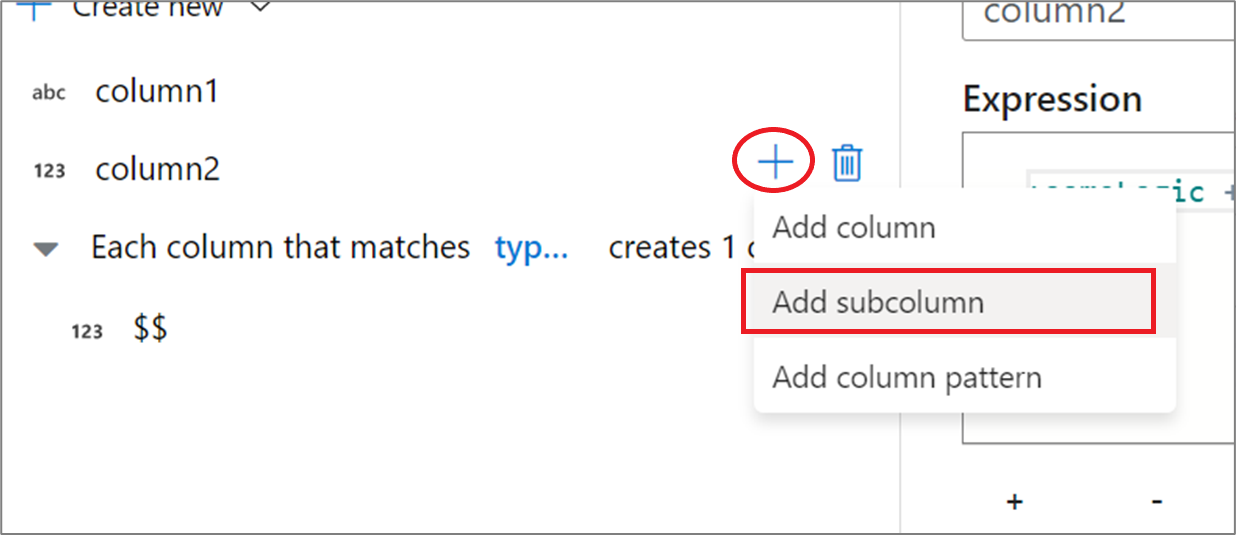
Vous pouvez ajouter des colonnes et des sous-colonnes supplémentaires de la même façon. Pour chaque champ non complexe, une expression peut être ajoutée dans l’éditeur d’expressions vers la droite.
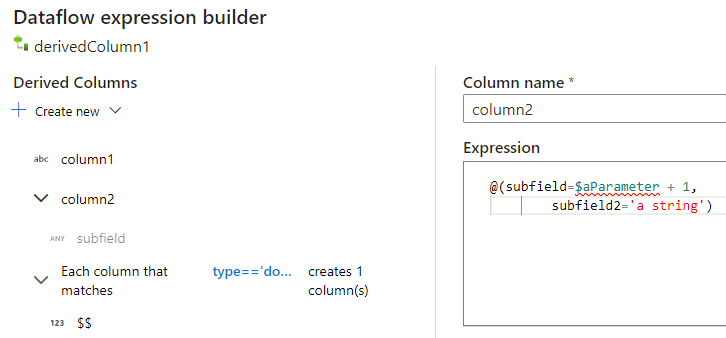
Saisie manuelle de la structure JSON
Pour ajouter manuellement une structure JSON, ajoutez une nouvelle colonne et entrez l’expression dans l’éditeur. L’expression suit le format général suivant :
@(
field1=0,
field2=@(
field1=0
)
)
Si cette expression était entrée pour une colonne nommée « complexColumn », elle serait écrite dans le récepteur sous la forme du code JSON suivant :
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Exemple de script manuel pour une définition hiérarchique complète
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Formats et connecteurs associés
Voici quelques connecteurs et formats courants liés au format JSON :