Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment utiliser l’activité de copie dans le pipeline Azure Data Factory ou Synapse Analytics pour copier des données de Hive. Il s’appuie sur l’article Vue d’ensemble de l’activité de copie.
Important
Le connecteur Hive version 2.0 (version préliminaire) offre une prise en charge native de Hive améliorée. Si vous utilisez le connecteur Hive version 1.0 dans votre solution, mettez à niveau votre connecteur Hive avant le 30 septembre 2025. Pour plus d’informations sur la différence entre la version 2.0 (préversion) et la version 1.0, consultez cette section .
Fonctionnalités prises en charge
Ce connecteur Hive est pris en charge pour les activités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | (1) (2) |
| Flux de données de mappage (source/-) | (1) |
| Activité de recherche | (1) (2) |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau Banques de données prises en charge.
Le service fournit un pilote intégré qui permet la connexion. Vous n’avez donc pas besoin d’installer manuellement un pilote à l’aide de ce connecteur.
Le connecteur prend en charge les versions Windows de cet article.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Hive à l’aide de l’interface utilisateur
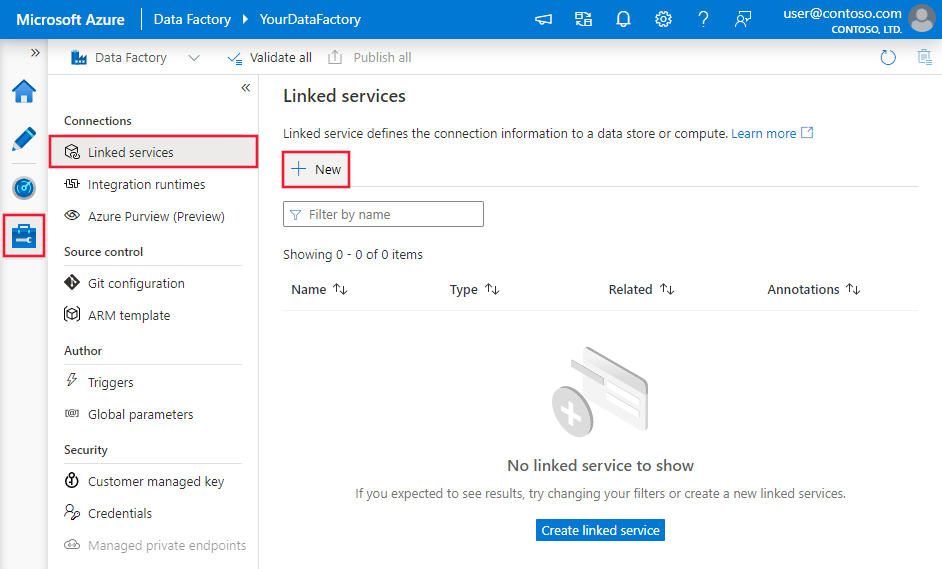
Procédez comme suit pour créer un service lié à Hive dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Hive et sélectionnez le connecteur Hive.
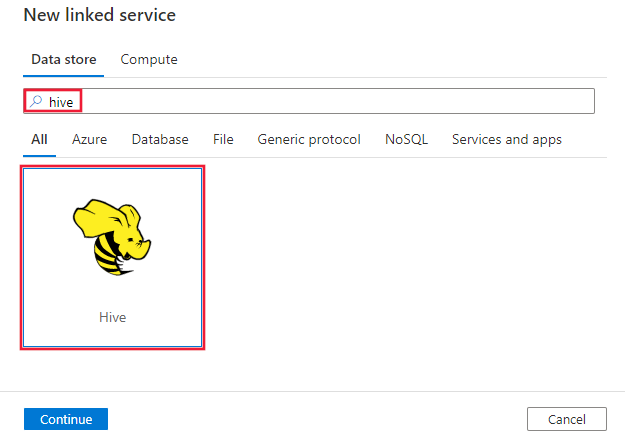
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
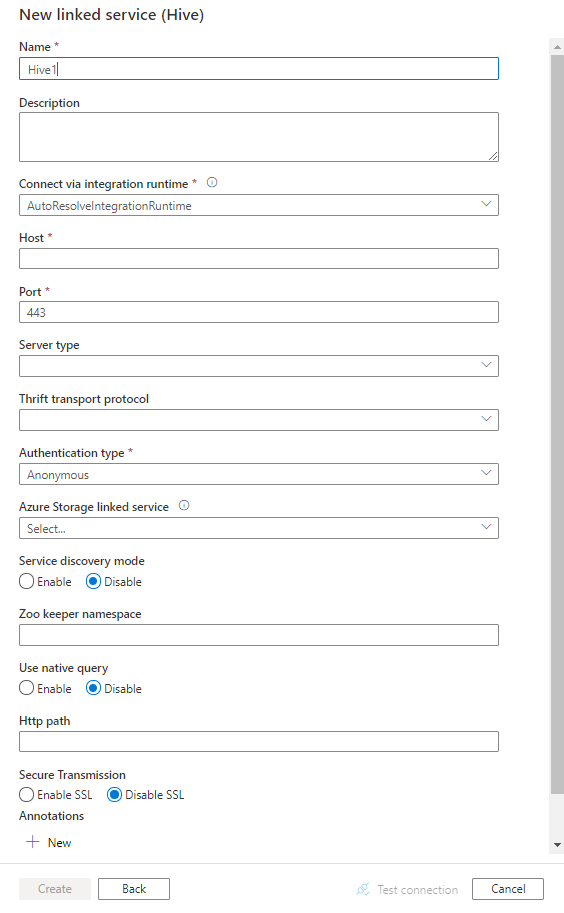
Informations de configuration du connecteur
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités Data Factory spécifiques du connecteur Hive.
Propriétés du service lié
Le connecteur Hive prend désormais en charge la version 2.0 (préversion). Reportez-vous à cette section pour mettre à niveau votre version de connecteur Hive à partir de la version 1.0. Pour plus d’informations sur la propriété, consultez les sections correspondantes.
Version 2.0 (préversion)
Le service lié Hive prend en charge les propriétés suivantes lors de l’application de la version 2.0 (préversion) :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : Hive | Oui |
| Version | Version que vous spécifiez. La valeur est 2.0. |
Oui |
| hôte | Adresse IP ou nom d’hôte du serveur Hive. | Oui |
| Port | Port TCP utilisé par le serveur Hive pour écouter les connexions clientes. Si vous êtes connecté à Azure HDInsight, spécifiez le port 443. | Oui |
| type de serveur | Type du serveur Hive. La valeur autorisée est : HiveServer2 |
Non |
| thriftTransportProtocol | Protocole de transport à utiliser dans la couche Thrift. La valeur autorisée est : Binary, SASL, HTTP |
Non |
| type d'authentification | Méthode d’authentification utilisée pour accéder au serveur Hive. Les valeurs autorisées sont : Anonymous, UsernameAndPassword, WindowsAzureHDInsightService. L’authentification Kerberos n’est pas prise en charge pour le moment. |
Oui |
| nom d'utilisateur | Nom d’utilisateur utilisé pour accéder au serveur Hive. | Non |
| mot de passe | Mot de passe correspondant à l’utilisateur. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Non |
| httpPath | URL partielle correspondant au serveur Hive. | Non |
| Activer SSL | Indique si les connexions au serveur sont chiffrées à l’aide du protocole TLS. La valeur par défaut est true. | Non |
| activerLaValidationDuCertificatDuServeur | Spécifiez s’il faut activer la validation des certificats SSL du serveur lorsque vous vous connectez. Utilisez toujours le magasin de confiance système. La valeur par défaut est true. | Non |
| référence de stockage | Référence au service lié du compte de stockage utilisé pour la mise en lots des données dans le flux de données de mappage. Cela est nécessaire uniquement lors de l’utilisation du service lié Hive dans le flux de données de mappage. | Non |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"version": "2.0",
"typeProperties": {
"host" : "<host>",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"serverType": "HiveServer2",
"thriftTransportProtocol": "HTTP",
"enableSsl": true,
"enableServerCertificateValidation": true
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Version 1.0
Les propriétés prises en charge pour le service lié Hive lors de l’application de la version 1.0 sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : Hive | Oui |
| hôte | Adresse IP ou nom d’hôte du serveur Hive, séparé par « ; » pour plusieurs hôtes (uniquement quand serviceDiscoveryMode est activé). | Oui |
| Port | Port TCP utilisé par le serveur Hive pour écouter les connexions clientes. Si vous êtes connecté à Azure HDInsight, spécifiez le port 443. | Oui |
| type de serveur | Type du serveur Hive. Les valeurs autorisées sont les suivantes : HiveServer1, HiveServer2, HiveThriftServer |
Non |
| thriftTransportProtocol | Protocole de transport à utiliser dans la couche Thrift. Les valeurs autorisées sont les suivantes : Binary, SASL, HTTP |
Non |
| type d'authentification | Méthode d’authentification utilisée pour accéder au serveur Hive. Les valeurs autorisées sont les suivantes : Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService. L’authentification Kerberos n’est pas prise en charge pour le moment. |
Oui |
| modeDécouverteDuService | Valeur true pour indiquer l’utilisation du service ZooKeeper, valeur false dans le cas contraire. | Non |
| zooKeeperNameSpace | Espace de noms sur ZooKeeper sous lequel les 2 nœuds du serveur Hive sont ajoutés. | Non |
| useNativeQuery | Indique si le pilote doit utiliser les requêtes HiveQL natives ou les convertir dans un format équivalent dans HiveQL. | Non |
| nom d'utilisateur | Nom d’utilisateur utilisé pour accéder au serveur Hive. | Non |
| mot de passe | Mot de passe correspondant à l’utilisateur. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. | Non |
| httpPath | URL partielle correspondant au serveur Hive. | Non |
| Activer SSL | Indique si les connexions au serveur sont chiffrées à l’aide du protocole TLS. La valeur par défaut est false. | Non |
| trustedCertPath | Chemin complet du fichier .pem contenant les certificats d’autorité de certification approuvés permettant de vérifier le serveur en cas de connexion TLS. Cette propriété n’est disponible que si le protocole TLS est utilisé sur un runtime d’intégration auto-hébergé. Valeur par défaut : le fichier cacerts.pem installé avec le runtime d’intégration. | Non |
| UtiliserLeMagasinDeConfianceDuSystème | Indique s’il faut utiliser un certificat d’autorité de certification provenant du magasin de confiance du système ou d’un fichier PEM spécifié. La valeur par défaut est false. | Non |
| allowHostNameCNMismatch | Indique si le nom du certificat TLS/SSL émis par l’autorité de certification doit correspondre au nom d’hôte du serveur en cas de connexion TLS. La valeur par défaut est false. | Non |
| allowSelfSignedServerCert | Indique si les certificats auto-signés provenant du serveur sont autorisés ou non. La valeur par défaut est false. | Non |
| connectVia | Runtime d’intégration à utiliser pour la connexion à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
| référence de stockage | Référence au service lié du compte de stockage utilisé pour la mise en lots des données dans le flux de données de mappage. Uniquement nécessaire lors de l'utilisation du service lié Hive dans le flux de données de mappage. | Non |
Exemple :
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit la liste des propriétés prises en charge par le jeu de données Hive.
Pour copier des données de Hive, définissez la propriété de type du jeu de données sur HiveObject. Les propriétés prises en charge sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur : HiveObject | Oui |
| schéma | Nom du schéma. | Non (si « query » dans la source de l’activité est spécifié) |
| table | Nom de la table. | Non (si « query » dans la source de l’activité est spécifié) |
| tableName | Nom de la table incluant la partie de schéma. Cette propriété est prise en charge pour la compatibilité descendante. Pour les nouvelles charges de travail, utilisez schema et table. |
Non (si « query » dans la source de l’activité est spécifié) |
Exemple
{
"name": "HiveDataset",
"properties": {
"type": "HiveObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Hive linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par la source Hive.
HiveSource en tant que source
Pour copier des données de Hive, définissez le type de source dans l’activité de copie sur HiveSource. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité de copie doit être définie sur : HiveSource | Oui |
| requête | Utiliser la requête SQL personnalisée pour lire les données. Par exemple : "SELECT * FROM MyTable". |
Non (si « tableName » est spécifié dans dataset) |
Exemple :
"activities":[
{
"name": "CopyFromHive",
"type": "Copy",
"inputs": [
{
"referenceName": "<Hive input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "HiveSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Propriétés du mappage de flux de données
Le connecteur Hive est pris en charge en tant que source de jeu de données inlined dans les flux de données de mappage. À lire à l'aide d'une requête ou à partir d'une table Hive dans HDInsight. Les données Hive sont mises en lots dans un compte de stockage sous forme de fichiers Parquet avant d'être transformées dans le cadre d'un flux de données.
Propriétés de source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source Hive. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Descriptif | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Magasin | Le magasin doit être hive |
Oui | hive |
boutique |
| Format | Que la lecture soit effectuée à partir d'une table ou d'une requête | Oui |
table ou query |
format |
| Nom du schéma | En cas de lecture à partir d'une table, il s'agit du schéma de la table source | Oui, si le format est table |
Chaîne | nomDuSchéma |
| Nom de la table | En cas de lecture à partir d'une table, il s'agit du nom de la table | Oui, si le format est table |
Chaîne | tableName |
| Requête | Si le format est query, il s'agit de la requête source sur le service lié Hive |
Oui, si le format est query |
Chaîne | requête |
| Intermédiaire | La table Hive sera toujours intermédiaire. | Oui | true |
Organisé |
| Conteneur de stockage | Conteneur de stockage utilisé pour la mise en lots des données avant de les lire à partir de Hive ou d'écrire dans Hive. Le cluster Hive doit avoir accès à ce conteneur. | Oui | Chaîne | conteneur de stockage |
| Base de données de la zone de transit | Schéma ou base de données auquel ou à laquelle le compte d'utilisateur spécifié dans le service lié a accès. Utilisé(e) pour créer des tables externes lors de la mise en lots, avant d'être supprimé(e) | non |
true ou false |
stagingDatabaseName |
| Scripts pré-SQL | Code SQL à exécuter sur la table Hive avant de lire les données | non | Chaîne | preSQLs |
Exemple de source
Vous trouverez ci-dessous un exemple de configuration de source Hive :
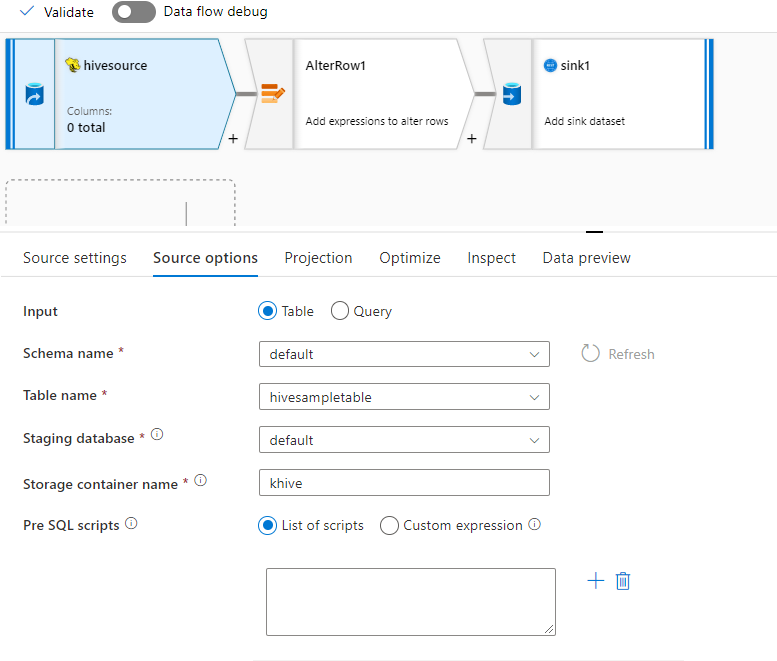
Ces paramètres sont convertis en script de flux de données :
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'table',
store: 'hive',
schemaName: 'default',
tableName: 'hivesampletable',
staged: true,
storageContainer: 'khive',
storageFolderPath: '',
stagingDatabaseName: 'default') ~> hivesource
Limitations connues
- Les types complexes tels que les tableaux, les mappages, les structs et les unions ne sont pas pris en charge pour la lecture.
- Le connecteur Hive prend uniquement en charge les tables Hive dans Azure HDInsight version 4.0 ou ultérieure (Apache Hive 3.1.0)
- Par défaut, le pilote Hive fournit « tableName.columnName » dans le récepteur. Si vous ne souhaitez pas voir le nom de la table dans le nom de la colonne, il existe deux façons de résoudre ce problème. a) Vérifiez le paramètre « hive.resultset.use.unique.column.names » côté serveur Hive et définissez-le sur false. b. Utilisez le mappage de colonnes pour renommer la colonne.
Mappage de type de données pour Hive
Lorsque vous copiez des données depuis et vers Hive, les mappages de types de données intermédiaires suivants sont utilisés dans le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, consultez Mappage de schéma dans l’activité de copie.
| Type de données Hive | Type de données de service intermédiaire (pour la version 2.0 (préversion)) | Type de données de service intermédiaire (pour la version 1.0) |
|---|---|---|
| TINYINT | Sbyte | Int16 |
| SMALLINT | Int16 | Int16 |
| INT | Int32 | Int32 |
| BIGINT | Int32 | Int64 |
| BOOLÉEN | Booléen | Booléen |
| FLOTTER | Unique | Unique |
| DOUBLE | Double | Double |
| DÉCIMAL | Décimal | Décimal |
| CORDE | Chaîne | Chaîne |
| VARCHAR | Chaîne | Chaîne |
| CARBONISER | Chaîne | Chaîne |
| HORODATAGE | DateTimeOffset | Date et heure |
| date | Date et heure | Date et heure |
| BINAIRE | Octet[] | Octet[] |
| TABLEAU | Chaîne | Chaîne |
| CARTE | Chaîne | Chaîne |
| STRUCT | Chaîne | Chaîne |
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Mettre à niveau le connecteur Hive
Voici les étapes qui vous aident à mettre à niveau le connecteur Hive :
Dans la page Modifier le service lié , sélectionnez la version 2.0 (préversion) et configurez le service lié en faisant référence aux propriétés du service lié version 2.0.
Le mappage de type de données pour le service lié Hive version 2.0 (préversion) diffère de celui de la version 1.0. Pour en savoir plus sur le mappage de type de données le plus récent, consultez Mappage de type de données pour Hive.
Différences entre Hive version 2.0 (préversion) et version 1.0
Le connecteur Hive version 2.0 (préversion) offre de nouvelles fonctionnalités et est compatible avec la plupart des fonctionnalités de la version 1.0. Le tableau suivant présente les différences de fonctionnalités entre la version 2.0 (préversion) et la version 1.0.
| Version 2.0 (préversion) | Version 1.0 |
|---|---|
| L’utilisation de « ; » pour séparer plusieurs hôtes (uniquement lorsque serviceDiscoveryMode est activé) n’est pas prise en charge. | L’utilisation de « ; » pour séparer plusieurs hôtes (uniquement lorsque serviceDiscoveryMode est activé) est prise en charge. |
HiveServer1 et HiveThriftServer ne sont pas pris en charge pour ServerType. |
Prise en charge de HiveServer1 et HiveThriftServer pour ServerType. |
| Le type d’authentification du nom d’utilisateur n’est pas pris en charge. Le protocole de transport SASL prend uniquement en charge le type d’authentification UsernameAndPassword. Le protocole de transport binaire prend uniquement en charge le type d’authentification anonyme. |
Prise en charge du type d’authentification du nom d’utilisateur. Les protocoles de transport SASL et Binary prennent en charge les types d’authentification Anonymous, Username, UsernameAndPassword et WindowsAzureHDInsightService. |
serviceDiscoveryMode
zooKeeperNameSpace et useNativeQuery ne sont pas pris en charge. |
serviceDiscoveryMode, zooKeeperNameSpace, useNativeQuery sont pris en charge. |
La valeur enableSSL par défaut est true.
trustedCertPath, useSystemTrustStoreallowHostNameCNMismatch et allowSelfSignedServerCert ne sont pas pris en charge.enableServerCertificateValidation est pris en charge. |
La valeur par défaut est enableSSL false.
trustedCertPath, useSystemTrustStoreallowHostNameCNMismatch et allowSelfSignedServerCert sont pris en charge.La fonction enableServerCertificateValidation n'est pas prise en charge. |
| Les mappages suivants sont utilisés à partir des types de données Hive pour le type de données de service intermédiaire. TINYINT -> SByte TIMESTAMP -> DateTimeOffset |
Les mappages suivants sont utilisés à partir des types de données Hive pour le type de données de service intermédiaire. TINYINT -> Int16 TIMESTAMP -> DateHeure |
Contenu connexe
Pour obtenir une liste des magasins de données pris en charge comme sources et récepteurs par l’activité de copie, consultez la section sur les magasins de données pris en charge.